

Autor |. Eines Tages
Einführung
In diesem Artikel werden hauptsächlich die Konzepte und Anwendungen von Business Intelligence (BI) und Turing Data Analysis (TDA) vorgestellt. BI hilft Unternehmen, bessere Entscheidungen und strategische Planung zu treffen, indem es Daten sammelt, organisiert, analysiert und präsentiert. Allerdings gibt es bei traditionellen BI-Konstruktionsideen Probleme, wie z. B. die Notwendigkeit einer Neuentwicklung, wenn sich die Datenanforderungen des Unternehmens ändern, und die geringe Effizienz der Analyse zugrunde liegender Daten. Daher hat sich TDA zu einer zentralen Self-Service-Analyseplattform entwickelt. Sie erstellt öffentliche Datensätze nach Analysethemen auf der Grundlage detaillierter Daten. Benutzer können die Ergebnisse per Drag-and-Drop mit einem Klick speichern und mit anderen teilen andere zum Ansehen. Der Aufbau von TDA steht jedoch auch vor Herausforderungen wie umfassenden Analysedimensionsindikatoren, genauer Datenkalibrierung und Abfrageleistung. Als Reaktion auf diese Herausforderungen formulieren wir die Ziele Vollständigkeit, Genauigkeit, Effizienz und Geschwindigkeit und erreichen diese Ziele durch Prozessmechanismen und Funktionskonstruktion sowie die MPP-Daten-Engine.
Der Volltext umfasst 4766 Wörter und die geschätzte Lesezeit beträgt 15 Minuten.
01 Hintergrund und Ziele
BI steht für Business Intelligence und hilft Unternehmen, ihren Mitbewerbern einen Schritt voraus zu sein und durch das Sammeln, Organisieren, Analysieren und Präsentieren von Daten bessere Geschäftsentscheidungen und strategische Planungen zu treffen. Der Prozess des Sammelns und Organisierens ist der Aufbau eines Data Warehouse, und die Analyse und Präsentation von Daten ist der Aufbau einer visuellen Analyseplattform.
Eine gängige BI-Konstruktionsidee in der Branche: Wenn das Unternehmen die Datenänderungen eines bestimmten Indikators sehen möchte, fordert es das Middle Office an, die Daten RD Schicht für Schicht von ODS>DWD>DWS>ADS zu modellieren und dann anzupassen Die ADS-Ergebnistabelle wird in Palo/Mysql entwickelt und implementiert. Anschließend werden mehrere Diagramme konfiguriert und in Berichten zur geschäftlichen Anzeige gespeichert. Obwohl diese Konstruktionsidee den Datenanalyseanforderungen des Unternehmens entspricht, gibt es zwei Probleme: 1. Wenn das Unternehmen die Datenanforderungen ändert, muss die ADS-Ergebnistabelle erneut angepasst und entwickelt werden, was wiederholt Forschungs- und Entwicklungsarbeitskräfte in Anspruch nimmt. 2. Es löst nur das Problem Problem der Geschäftsanalyse: Wenn Sie die Gründe für Schwankungen weiter aufschlüsseln und analysieren möchten, ist dies schwierig, da es sich bei der zugrunde liegenden Tabelle um eine aggregierte Tabelle handelt, die nur die aktuellen Diagrammdaten enthält die detaillierten Daten und analysieren Sie sie dann mit Excel oder anderen Methoden, was relativ ineffizient ist.
TDA (Turing Data Analysis) ist eine Self-Service-Analyseplattform aus einer Hand, die entwickelt wurde, um das oben erwähnte Problem langer Analyselinks in BI zu lösen.
Die Konstruktionsidee von TDA: Basierend auf der detaillierten breiten Tabelle des DWD werden öffentliche Datensätze entsprechend dem Analysethema erstellt (eintägige Daten umfassen mehrere zehn Millionen). Benutzer können Analysen basierend auf den öffentlichen Datensätzen per Drag-and-Drop erstellen frei, und die Analyseergebnisse können in persönlichen Dashboards gespeichert oder mit einem Klick veröffentlicht werden. Erstellen Sie ein öffentliches Dashboard und teilen Sie es mit anderen. Sie können den Fluktuationstrend auf dem öffentlichen Dashboard überprüfen und einen Drilldown zur visuellen Analyseseite durchführen Ursachen von Schwankungen und Vervollständigung der One-Stop-Analyse „Trends erkennen, Dimensionen aufschlüsseln und Details herausfinden“ Drei Achsen.
Die folgende Abbildung zeigt den Gesamtprozess der TDA-Konstruktionsideen:
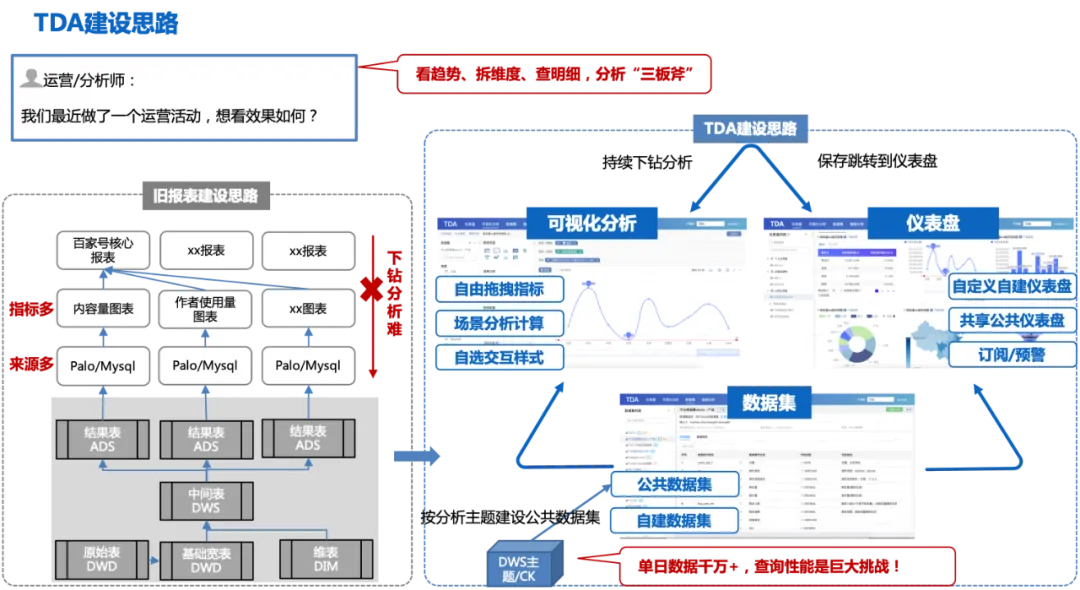
Auch diese Bauidee wird vor einigen Herausforderungen stehen:
1. Die Analysedimensionsindikatoren müssen vollständig sein, andernfalls müssen mehrere Datensätze erstellt werden, was zu vielen und verstreuten Datensätzen führt, das gleiche Problem wie bei der vorherigen Berichtskonstruktion;
2. Das Datenkaliber muss genau und maßgeblich sein;
3. Bei zig Millionen Daten an einem einzigen Tag ist die Abfrageleistung eine große Herausforderung.
Als Reaktion auf die oben genannten Herausforderungen haben wir auch entsprechende Ziele formuliert, um den Anforderungen einer effizienten Geschäftsanalyse gerecht zu werden:
1. Vollständig (Analysedimensionsindikatoren müssen vollständig sein und mehr als 80 % der Geschäftsanforderungen abdecken);
2. Genau (einheitliches Kaliber, genaue Daten);
3. Aktualität (die Aktualität der Datenausgabe beträgt T+10h);
4. Schnell (Datenabfrage auf 1-Milliarden-Ebene innerhalb von 10 Sekunden).
Die TDA-Plattform gewährleistet eine vollständige, genaue und effiziente Datensatzkonstruktion aus Sicht des Prozessmechanismus und der Funktionskonstruktion, stellt in Kombination mit der MPP-Daten-Engine die Abfrageleistung sicher und verbessert die Analyseeffizienz der Benutzer durch visuelles Drag-and-Drop und Szenenanalyse von BI. Self-Service-Modellierung und andere Funktionen.
02 Technische Lösung
Basierend auf der obigen Analyse ist die Produktpositionierung von TDA eine BI-Plattform, die es Benutzern ermöglicht, eine Self-Service-Abfrage aus einer Hand zu erreichen. Benutzer können Datensätze frei per Drag-and-Drop verschieben, visuelle Datenanalysen durchführen und Kern-Dashboards erstellen. Helfen Sie Benutzern, die Abfrageanalyse aus den folgenden Perspektiven aus einer Hand zu erleben:
Geschäfts-Kanban-Iteration und Effizienzverbesserung (Selbstbedienung) : Der Datenbericht-Iterationsmodus hat sich geändert, vom PM-Anforderungs-RD-Planungsmodus hin zur schrittweisen Umstellung auf PM/Betriebs-Selbstbedienungsbetrieb (Erstellung von Kanban/Analyse von Daten).
Verbesserung der Effizienz der Analyse von Dateneinblicken (extrem schnell) : Eine einzelne Datenabfrage wird von Minuten auf Sekunden reduziert, die Effizienz der Analyse von Indikatorschwankungen wird um das Zwanzigfache erhöht und die End-to-End-Analyse der Zuordnung einzelner Indikatorschwankungen erfolgt innerhalb von 2 Stunden -> 5 Minuten.
Self-Service-Geschäftsanalyse aus einer Hand (aus einer Hand) : Realisiert Datentrendbeobachtung, dimensionale Drilldown-Analyse, detaillierten Export und andere Funktionen und realisiert so ein integriertes Erlebnis der Datenüberwachung und Datenanalyse.
Die Funktionsmatrix dieses Produkts ist wie folgt:
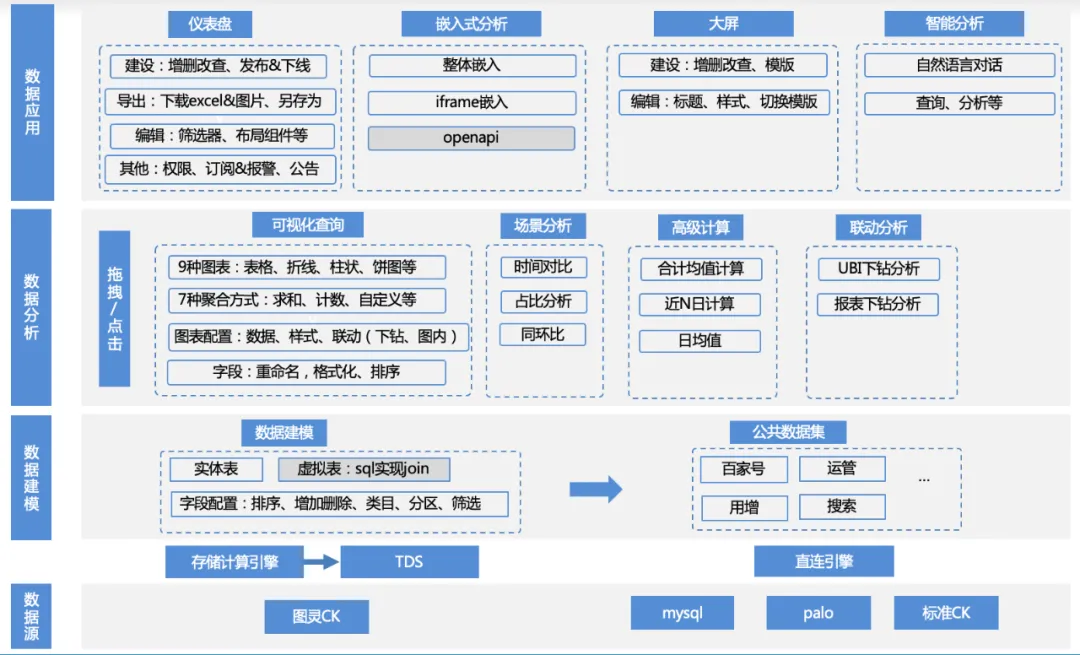
1. Datenquellenzugriff : Das Unternehmen verwendet TDS, um die Upstream-Turing-Tabellendaten über die Berechnungs-Engine zu berechnen, schreibt die Daten dann in Engines wie Clickhouse/MySQL/Palo und greift über eine direkte Verbindung darauf zu, oder das Unternehmen stellt sein eigenes Palo bereit / MySQL-Datenquellenzugriff.
a. Datenquellenverwaltung: Hinzufügen, Löschen, Ändern und Abfragen von Datenquellen, Anpassung von Clickhouse/MySQL/Palo und anderen Engine-Treibern
2. Datenmodellierung : Nach der Verbindung mit der Datenquelle können die Daten durch Schreiben von SQL und direkt aus der Originaltabelle in das Produkt geladen werden. Diese Tabellen erfordern jedoch normalerweise eine einfache sekundäre Verarbeitung, um sie in Datensätze umzuwandeln, die analysiert werden können.
a. Datensatzverwaltung: Funktionen wie Hinzufügen, Löschen, Ändern, Datenvorschau, Schemaanzeige, visuelle Analyse mit einem Klick usw.
b. Datensatzfeldverwaltung: Hinzufügen, Löschen, Ändern, Feldsortierung, benutzerdefinierte Felder usw.
c. Verwaltung von Datensatzkategorien: Hinzufügen, Löschen, Ändern und benutzerdefiniertes Sortieren der Kategorien, zu denen Felder gehören usw.
d. Verwaltung des Datensatzverzeichnisses: Hinzufügen, Löschen, Ändern und benutzerdefiniertes Sortieren des Datensatzverzeichnisses usw.
3. Datenanalyse : Basierend auf dem Datensatz können Benutzer Indikatoren, Dimensionen und Filter frei per Drag-and-Drop verschieben, geeignete Diagrammtypen und Szenarioanalysemethoden auswählen sowie Analysen und Berechnungen durchführen.
a. Datenkonfiguration: Datensätze wechseln, benutzerdefinierte Felder hinzufügen
b. Diagrammkonfiguration: Tabellen-, Liniendiagramm-, Balkendiagramm-, Kreisdiagramm- und andere Diagrammtypkonfigurationen, Legendenfarbeinstellungen, Datenformateinstellungen usw.
c. Szenarioanalyse: Unterstützung für mehrere Szenarioanalysefunktionen wie Tagesdurchschnittswert, Jahresvergleich, Anteil, Gesamtwert usw.
d. Attributionsanalyse: Funktionen zur Self-Service-Attributionsanalyse
e. Interaktive Analyse: Drill-Down-Analyse usw.
4. Datenanwendung : Benutzer können die Analyseergebnisse im Dashboard speichern, in eine Plattform eines Drittanbieters einbetten, auf dem großen Bildschirm speichern oder direkt für intelligente Analysen usw. verwenden.
a. Dashboard-Verwaltung: Hinzufügen, Löschen, Ändern, benutzerdefiniertes Sortieren, Veröffentlichen und Offline, Datenexport, Abonnementwarnungen usw.
b. Eingebettete Analyse: ifame eingebettet, sdk eingebettet und andere eingebettete Modi
c. Großer Bildschirm: Echtzeit-Großbildschirm
d. Intelligente Analyse: LUI-Konversationsanalyse
2.1 Gesamtdesign
Die Gesamtarchitektur von TDA ist in der folgenden Abbildung dargestellt:
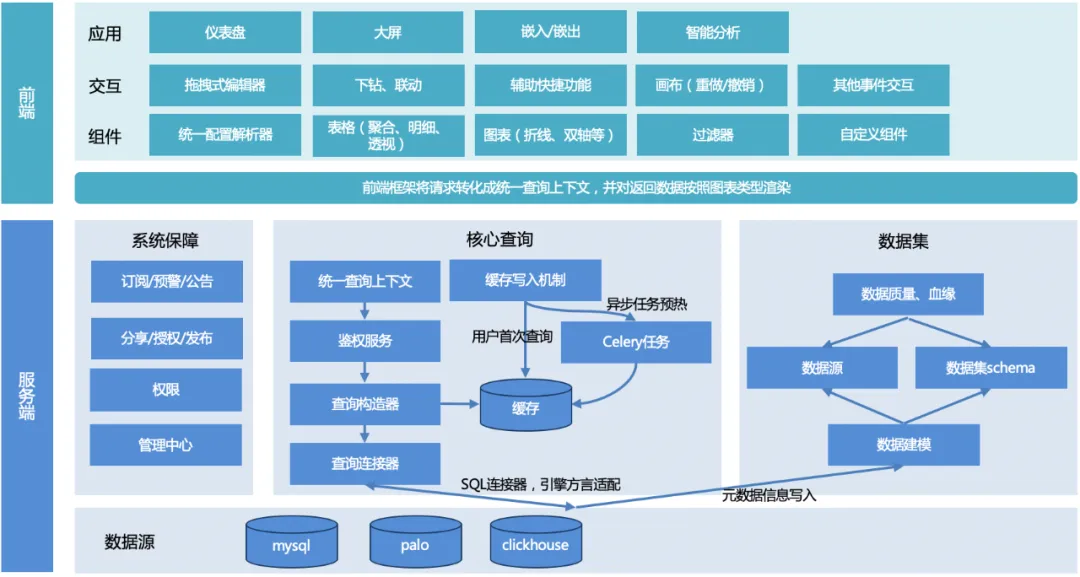
Der Gesamtprozess: Der Benutzer initiiert eine Abfrage, der Server vereinheitlicht den Abfragekontext, erstellt das Abfrageobjekt, passt den zugrunde liegenden Engine-Dialekt an, gibt ein einheitliches Datenformat zurück und dann passt sich das Front-End-Rendering-Framework an und rendert entsprechend dem Diagrammtyp .
Server:
1. Einheitlicher Abfragekontext : Um die Wiederverwendung gemeinsamer Funktionen bei der späteren Erweiterung anderer Diagrammfunktionen zu erleichtern, wurde ein einheitlicher Abfragekontext entworfen.
2. Abfragekonstruktor : Erstellen Sie ein Abfrageobjekt (es kann mehrere sein, z. B. um eine Tabelle zu paginieren, müssen Sie zwei Abfrageobjekte erstellen, eines ist ein Paging-Abfrageobjekt und das andere ist ein Zählabfrageobjekt), entsprechend der Anforderung Parameter, die vom Frontend übergeben werden.
3. Abfrage-Connector :
a. Derzeit gibt es nur einen SQL-Connector, der zur Erfüllung der SQL-Abfrage-Engine (MySQL, Palo, Clickhouse usw.) verwendet wird. Verschiedene Engines, Syntax oder einige Funktionen können unterschiedlich sein und müssen über unterschiedliche Engines angepasst werden Regelkonfigurationen;
b. Andere Konnektoren können in Zukunft erweitert werden, um Nicht-SQL-Abfragen zu erfüllen.
4. Cache-Schreiben : Um die Abfrageleistung sicherzustellen, gibt es zwei Schreibmethoden: Schreiben, wenn der Benutzer zum ersten Mal zugreift, oder Vorwärmen des Caches durch geplante Sellerie-Aufgaben.
5. Datensatzmodul : Bereitstellung von Datenunterstützung, Herstellung von Verknüpfungen mit zugrunde liegenden Datenquellen und Sicherstellung der Datenqualität.
6. Systemgarantiemodul : Abonnement-, Frühwarn- und Ankündigungsfunktionen ermöglichen die Datenfreigabe, -veröffentlichung und -autorisierung und verbessern die Effizienz der Datenzirkulation. Das Verwaltungszentrum und die Berechtigungen bieten zugrunde liegende Verwaltungs- und Berechtigungsunterstützung.
Frontend:
1. Komponentenbibliothek : Bietet Konfigurationsanalysen, verschiedene Diagramm-Rendering-Komponenten, Filterkomponenten und benutzerdefinierte Komponentenfunktionen.
2. Interaktion : Umfasst Seiteninteraktionsfunktionen, einschließlich Drag-and-Drop-Editor, Drilldown-Verknüpfung, Hilfsverknüpfungsfunktionen, Canvas-Funktionen und andere Ereignisinteraktionen.
3. Anwendung : Implementieren Sie verschiedene visuelle Anwendungen für verschiedene Benutzer und Nutzungsszenarien, z. B. Dashboards, große Bildschirme usw.
2.2 Detailliertes Design
2.2.1 Kernabfrage
One-Stop-Self-Service-BI verwirklicht durch Modellierungsideen für öffentliche Datensätze die Drei-Punkte-Analyseidee von „Trends, Dimensionen und Details“, die vor vielen Herausforderungen steht, darunter:
-
Multi-Source-Daten, Multi-Chart-Präsentation und mehrere Szenarioanalysen und -berechnungen : Im BI-System gibt es mehr als eine zugrunde liegende Datenquellen-Engine. Um Datenquellen flexibel zu erweitern, erfordert der Präsentationsstil auch eine umfassende Diagrammunterstützung Gleichzeitig muss die Berechnung gemeinsame Analysefunktionen wie Monats- und Tagesdurchschnittswerte unterstützen, um die Analyse in verschiedenen Szenarien zu erfüllen.
-
Abfragen von zig Millionen Daten in Sekundenschnelle : Die Idee, öffentliche Datensätze zu erstellen, erleichtert die Analyse, bringt aber auch neue Herausforderungen mit sich. Die Menge von mehreren zehn Millionen Daten an einem einzigen Tag stellt eine große Herausforderung für die Abfrageleistung dar.
Als Reaktion auf die oben genannten Probleme wurden entsprechende Lösungen formuliert:
-
Einheitliche Abfrage : Vereinheitlichen Sie den Abfragekontext, erstellen Sie das Abfrageobjekt, passen Sie den zugrunde liegenden Engine-Dialekt an, geben Sie ein einheitliches Datenformat zurück und das Front-End-Rendering-Framework passt das Rendering entsprechend dem Diagrammtyp an.
-
Abfrageoptimierung : Ⅰ> Caching + automatisches Rolling, das 70 % der öffentlichen Dashboard-Anfragen abdeckt; Ⅱ> Optimierung der Erstellung von SQL-Abfragen und vollständige Nutzung der Engine-seitigen Aggregationsfunktionen III> Gleichzeitige Verarbeitung mehrerer Domänennamen und Multi-Coroutine-Antwortverarbeitung; .
Einheitliche Abfrage:
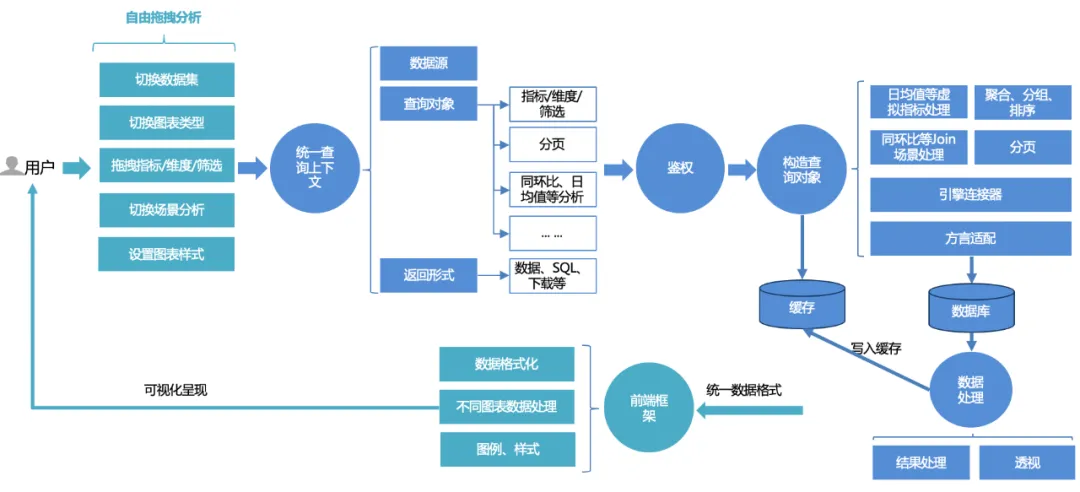
Der einheitliche Abfrageprozess für Plattformbenutzer ist wie folgt:
1. Benutzer können Analysen frei per Drag-and-Drop auf der Seite durchführen: Datensätze wechseln, zwischen verschiedenen Diagrammtypen wechseln, Indikatoren, Dimensionen, Filter und Abfragen per Drag-and-Drop verschieben oder, wenn sie erweiterte Szenenanalysefunktionen nutzen möchten, wechseln Konfigurationen mit einem Klick.
2. Die Front-End-Anfrage wird in einem einheitlichen Abfragekontext verarbeitet : einschließlich Datenquelle, Abfrageobjekt und Rückgabeformular. Das Abfrageobjekt kapselt grundlegende Indikatoren, Dimensionen, Filterinformationen und erweiterte Analysekonfigurationen, z. B. im Jahresvergleich Vergleich und Tagesdurchschnittswert.
3. Einheitlicher Authentifizierungsdienst : Basierend auf dem Kern der doppelten Authentifizierung von Dashboard und Datensatz unterstützt er auch eine detailliertere Berechtigungssteuerung für Zeilen und Zeilenberechtigungen.
4. Erstellen Sie das Abfrageobjekt : Vervollständigen Sie zunächst die grundlegende SQL-Konstruktion (Aggregation, Gruppierung, Filterung) basierend auf Indikatoren, Dimensionen und Filtertripeln, stellen Sie dann die Sortierlogik gemäß den Sortierregeln zusammen und fügen Sie einige erweiterte Analyseoptionen hinzu (z. B (Monat, Tagesdurchschnitt usw.) Zusätzliche Assemblerlogik und anschließende Paging-Verarbeitung müssen mit Dialektanpassung kombiniert werden. Fragen Sie beim Abfragen von Daten verschiedene Datenbanken (z. B. MySQL, Palo, Clickhouse usw.) entsprechend unterschiedlicher Engine ab Linker.
5. Daten abfragen und verarbeiten : Nachdem Sie die Daten über den Linker abgefragt haben, verarbeiten Sie die Daten (Verarbeitung des Datumsformats, Perspektive des Liniendiagramms usw.).
6. Cache : Die verarbeiteten Daten werden in den Cache geschrieben. Wenn der Cache während der Abfrage direkt aufgerufen wird, werden die zwischengespeicherten Daten direkt gelesen und zurückgegeben.
7. Einheitliches Rendering des Front-End-Rendering-Frameworks : Gibt ein einheitliches Datenformat zurück und das Front-End vervollständigt das adaptive Rendering von Diagrammen, Stilen usw.
Abfrageoptimierung: Ⅰ>Cache + automatisches Rollup, deckt 70 % der öffentlichen Dashboard-Anfragen ab.
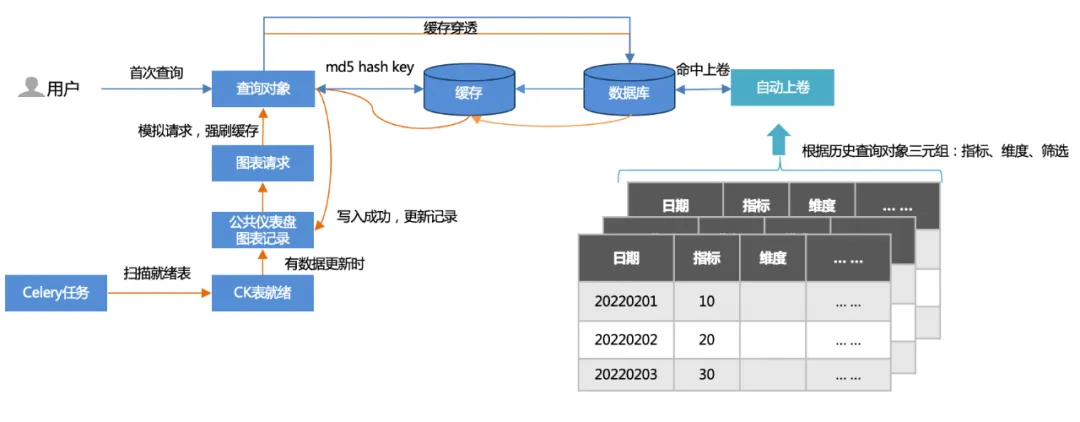
1. Zwei Caching-Methoden :
Erste Abfrage: Der Benutzer greift zuerst zu (Cache-Penetration), fragt die Datenbank ab und schreibt dann in den Cache.
Aufwärmen der Offline-Aufgabe: Scannen Sie öffentliche Dashboard-Diagrammdatensätze und simulieren Sie Diagrammanfragen (mehr als 500 pro Aktualisierung), um das Leeren des Caches zu erzwingen.
2. Automatisches Aufziehen :
Basierend auf den Tripeln (Indikatoren, Dimensionen, Filterung) historischer Abfragen wird eine Rollup-Tabelle erstellt und die Abfrage trifft auf die Rollup-Tabelle. Die abgefragte Datenmenge wird erheblich reduziert und die Leistung erhöht.
Abfrageoptimierung: Ⅱ> Optimieren Sie die Konstruktion von SQL-Abfragen und nutzen Sie die Aggregationsfunktionen von MPP-Architektur-Engines (wie Clickhouse/Palo usw.) vollständig aus.

Im Szenario der Analyse öffentlicher Datensätze ist es nach der Abfrage der Daten nahezu unmöglich, sie im Speicher zu aggregieren und zu berechnen (z. B. muss (a + b) / c basierend auf den detaillierten Daten a, b aggregiert und berechnet werden). , c) und Sie müssen das MPP auf der Engine-Seite verwenden. Die Abfragefähigkeit der Architektur verfeinert die Aggregationsberechnung auf der Engine-Seite zur Ausführung, genau wie bei der monatlichen Aggregation umfasst das Datenvolumen Dutzende Milliarden Daten Das Volumen nach der motorseitigen Aggregationsberechnung wird um das Dutzende Mal reduziert und die Leistung wird ebenfalls um ein Vielfaches verbessert.
Abfrageoptimierung: III>Mehrere Domänennamen gleichzeitige Anforderungen, Multi-Coroutine-Antwortverarbeitung.
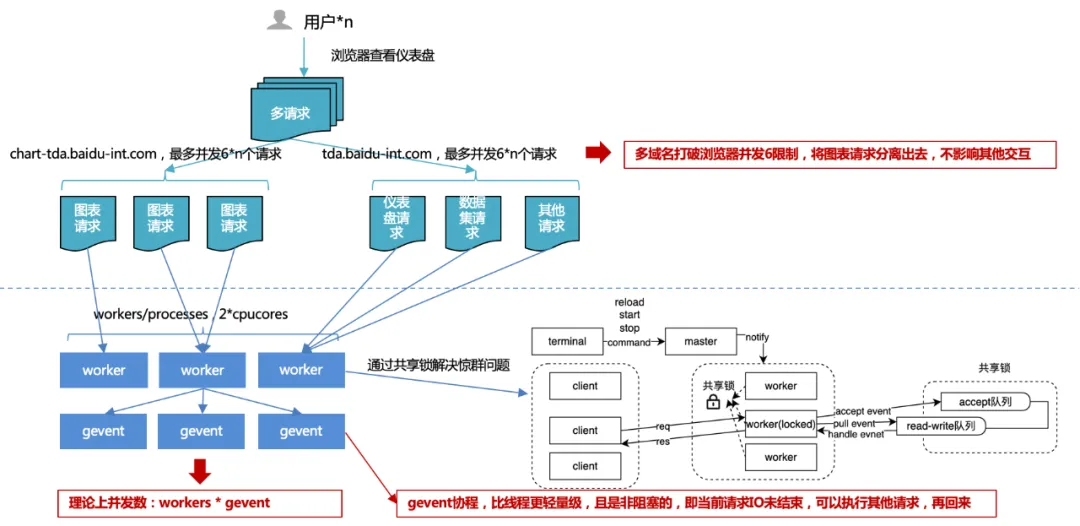
1. Browser-Parallelitätslimit von 6 : Durch die Verwendung mehrerer Domänennamen werden Diagrammanfragen von anderen Anfragen entlastet, um eine reibungslose Plattforminteraktion und eine erhöhte Parallelität von Diagrammanfragen zu gewährleisten und dadurch die Gesamtleistung zu verbessern.
Berücksichtigen Sie die Portressourcen des Betriebssystems: Die Gesamtzahl der PC-Ports beträgt 65536, sodass eine TCP-Verbindung (http ist auch TCP) einen Port belegt. Das Betriebssystem öffnet in der Regel die Hälfte aller Ports für externe Anfragen, um eine schnelle Erschöpfung der Portanzahl zu verhindern.
Übermäßige Parallelität führt zu häufigem Wechsel und Leistungsproblemen: Ein Thread verarbeitet eine HTTP-Anfrage. Wenn also die Anzahl der Parallelitäten sehr groß ist, kommt es zu häufigem Thread-Wechsel. Und das Wechseln des Thread-Kontexts ist manchmal keine leichte Ressource. Dies führt zu mehr Verlusten als Gewinnen, sodass im Anforderungscontroller ein Verbindungspool generiert wird, um frühere Verbindungen wiederzuverwenden. Daher können wir davon ausgehen, dass die maximale Anzahl von Verbindungspools unter demselben Domänennamen 4 bis 8 beträgt. Wenn alle Verbindungspools verwendet werden, werden nachfolgende Anforderungsaufgaben blockiert und nachfolgende Aufgaben werden ausgeführt, wenn freie Links vorhanden sind.
Verhindern Sie, dass eine große Anzahl gleichzeitiger Anforderungen desselben Clients den Parallelitätsschwellenwert des Servers überschreitet: Der Server legt normalerweise einen Parallelitätsschwellenwert für dieselbe Clientquelle fest, um böswillige Angriffe zu vermeiden kann dazu führen, dass der Parallelitätsschwellenwert des Servers überschritten wird.
Client-Gewissensmechanismus: Um zu verhindern, dass zwei Anwendungen Ressourcen beanspruchen, erhält die stärkere Partei uneingeschränkt Ressourcen, wodurch die schwächere Partei dauerhaft blockiert wird.
2. Serverseitige Multiprozess- und Multi-Coroutine-Parallelität :
Wenn Sie mit mehreren Prozessen entwickeln, kann es zu dem „Donnerherdenproblem“ kommen, bei dem mehrere Prozesse auf dasselbe Ereignis warten. Wenn ein Ereignis auftritt, werden alle Prozesse vom Kernel geweckt, aber nach dem Aufwachen erhält nur ein Prozess das Ereignis und verarbeitet es. Die anderen Prozesse treten weiterhin in den Wartezustand ein, nachdem festgestellt wurde, dass die Zeiterfassung fehlgeschlagen ist Je mehr Prozesse es gibt, desto schwerwiegender ist der Konflikt um die CPU, was zu erheblichen Kontextkosten führt.
Als Reaktion auf diese Situation hat der uwsgi-Dienst daher einen gemeinsamen Sperrmechanismus entworfen und implementiert, um sicherzustellen, dass nur ein Prozess gleichzeitig Ereignisse überwacht, und so das Donnerherdenproblem zu lösen.
Allerdings kann die Anzahl der Prozesse nicht unbegrenzt erweitert werden. Generell wird empfohlen, die Anzahl der CPU-Kerne zu verdoppeln.
Wie lässt sich der Durchsatz verbessern, da die Anzahl der Prozesse begrenzt ist? Unter normalen Umständen ist IO blockiert. Wenn Sie eine Datenbank oder eine Datei lesen, wartet der aktuelle Prozess oder Thread, bis der IO-Vorgang das Ergebnis zurückgibt, bevor er mit der Ausführung von nachfolgendem Code fortfährt. Wenn wir den Durchsatz durch Multithreading erhöhen und auf E/A-Blockierungen stoßen, bleibt der Thread hängen und andere gleichzeitige Anforderungen werden vom Thread nicht verarbeitet. Asynchrone E/A wird über Coroutinen implementiert, d. h. für jeden Thread, wenn es sich um E/A handelt Beim Warten auf das E/A-Ergebnis verarbeiten wir zunächst die neue Anforderung, warten, bis die E/A abgeschlossen ist, und springen dann zurück zu dem Code, der auf die E/A warten muss. Auf diese Weise nutzen wir jeden Thread im Programm voll aus und haben immer etwas zu tun. Diese Methode verbessert den Gesamtdurchsatz und reduziert den Gesamtzeitaufwand, ohne den individuellen Zeitaufwand zu beeinträchtigen.
2.2.2 Systemgarantie
Benachrichtigungen abonnieren:
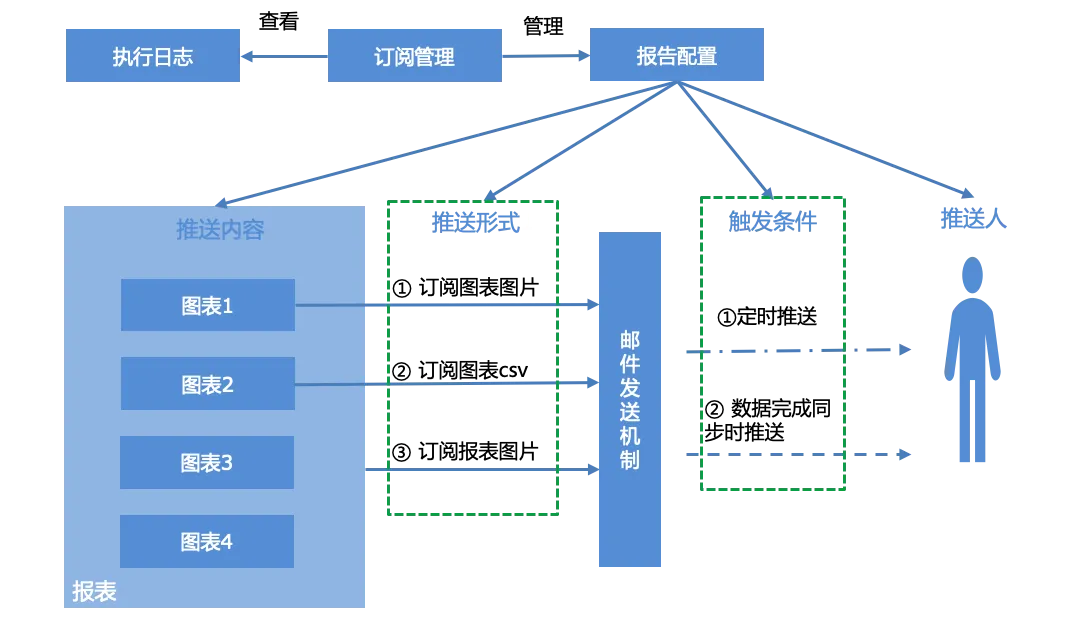
Benutzer können Berichte für Berichte konfigurieren, generierte Abonnementberichte gemäß der Abonnementverwaltungsoberfläche verwalten und das Ausführungsprotokoll des Systems, also den Push-Status von Berichten, anzeigen.
Die Berichtskonfiguration umfasst hauptsächlich vier Teile: Push-Inhalt, Push-Formular, Triggerbedingungen und Pusher:
Push-Inhalt : einzelnes Diagramm, gesamter Bericht
Push-Form : drei Push-Formen
Diagramm-Screenshot
Diagramm-CSV-Daten-E-Mail-Anhang
Screenshot melden
Auslösende Bedingungen :
Geplanter Push, geplanter Push basierend auf Cron-Ausdruck.
Wird gepusht, wenn die Datensynchronisierung abgeschlossen ist. Wenn die mit allen Diagrammen des Berichts verknüpften Datensätze die Datensynchronisierung abschließen, werden Push-Bedingungen ausgelöst und E-Mail-Benachrichtigungen abgeschlossen.
Pusher : E-Mail-Konto, bei mehreren mit „“ trennen.
Berechtigungen:

Hierarchische Verwaltung und Kontrolle von Datenberechtigungen: Basierend auf dem zweischichtigen Authentifizierungskern für Datensätze und Dashboards werden Zeilen- und Spaltenberechtigungen für die Beantragung einer Autorisierung entsprechend der Regelgranularität unterstützt und Benutzerberechtigungen flexibel gesteuert.
Effiziente Zusammenarbeit: Öffnen Sie den einheitlichen Behördendienst MPS (Unified Authority Management System), realisieren Sie die Genehmigung von Behörden, die Wiederherstellung nach Ablauf, das Einfrieren von Kündigungen und andere Funktionen, eröffnen Sie ein reibungsloses Büro und beschleunigen Sie die Hochgeschwindigkeitszirkulation von Genehmigungen von Behörden.
03 Zusammenfassung und Planung
3.1 Zusammenfassung
Nach kontinuierlicher Iteration hat TDA grundsätzlich Self-Service-Analysefunktionen aus einer Hand entwickelt und die folgenden Indikatoren erreicht:
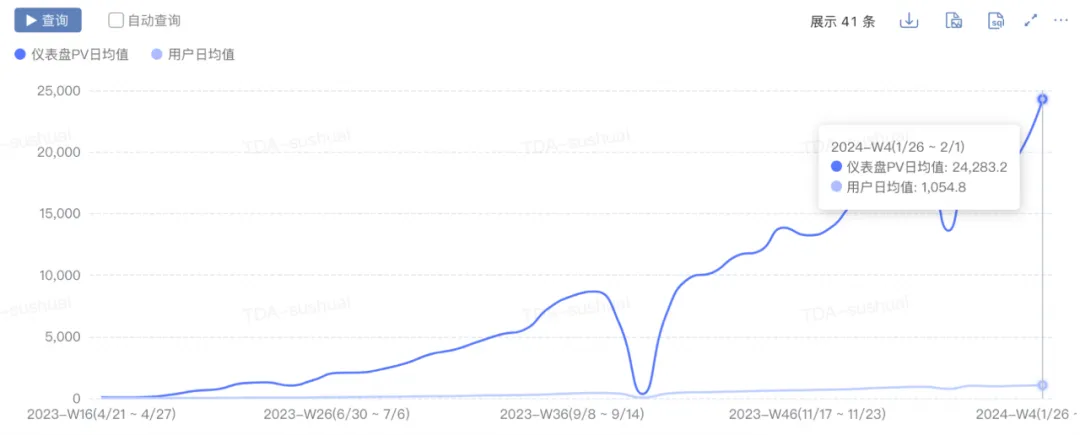
- Skalenwachstum: pv stieg von 0 auf 2w+, uv stieg von 0 auf 1000+ und täglich neue Charts stiegen von 0 auf 300+.
-
Leistungsverbesserung: Die Zeit, die benötigt wurde, um das 90. Perzentil des ersten Bildschirms des Dashboards zu erreichen, sank von 10 Sekunden+ auf 5 Sekunden.
-
Verbesserung der Geschäftseffizienz: Förderung einer Self-Service-Rate von über 80 % des Kerngeschäfts, Steigerung der Effizienz der Fluktuationsanalyse um das 20-fache und End-to-End-Attributionsanalyse einzelner Indikatorschwankungen von 2 Stunden auf 5 Minuten.
3.2 Planung
Mit der Durchdringung nativer KI-Technologie in verschiedenen Bereichen wird TDA in Zukunft auch KI-Technologie kombinieren, um das intelligente Analyseerlebnis der Plattform zu verbessern. Die wichtigsten Punkte sind wie folgt:
-
Self-Service-Datenzugriff: Der Datenzugriff wird liberalisiert, Datenquellentypen werden erweitert usw.
-
KI+BI: BI-Funktionen wie Attributionsanalyse, eingebettete Analyse und Analyseberichte werden mit KI für große Modelle kombiniert, um intelligente Analyseprodukte zu verbessern.
-
Management Cockpit (Erkunden): OKR Goals Dashboard.
------ENDE------
Literatur-Empfehlungen
Eine kurze Analyse, wie kommerzielle Echtzeitdienste beschleunigt werden können
Weiterentwicklung des Login-Systems, komfortables Login-Design und Implementierung
Dieser Artikel vermittelt Ihnen ein umfassendes Verständnis der IO-Basisbibliothek der Go-Sprache
Systemabstimmung des Baidu Trading Center
Enthüllung des Geheimnisses der Baidu Data Warehouse Fusion Computing Engine
Das erste große Versionsupdate von JetBrains 2024 (2024.1) ist Open Source. Sogar Microsoft plant, dafür zu bezahlen. Warum steht es immer noch in der Kritik? [Wiederhergestellt] Tencent Cloud-Backend stürzte ab: Viele Servicefehler und keine Daten nach der Anmeldung an der Konsole. Deutschland muss auch 30.000 PCs von Windows auf Linux Deepin-IDE migriert haben Bootstrapping! Visual Studio Code 1.88 wurde veröffentlicht. Tencent hat Switch wirklich in eine „denkende Lernmaschine“ verwandelt. Der auf SQLite basierende Web-Client WCDB hat ein umfangreiches Upgrade erhalten.