
Der Einsatz von Zeitreihendatenbanken (TSDBs) ist in verschiedenen Branchen seit Jahrzehnten üblich, insbesondere in Finanz- und Industriesteuerungssystemen. Das Aufkommen des Internets der Dinge (IoT) hat jedoch zu einem sprunghaften Anstieg der Menge an Zeitreihendaten (kurz: Zeitreihendaten) geführt, was zu höheren Anforderungen an die Datenbankleistung und Speicherkosten geführt hat und damit den Bedarf an dedizierten Daten erhöht Zeitreihendatenbanken.
Angesichts der Probleme veralteter Architektur und begrenzter Skalierbarkeit älterer Zeitreihenlösungen ist eine neue Generation von Zeitreihendatenbanken entstanden. Sie übernehmen moderne Architekturen, die eine verteilte Verarbeitung und horizontale Erweiterung sowie eine flexible Bereitstellung in der Cloud oder vor Ort ermöglichen.
Ende 2022 gesellte sich ein weiteres Blockbuster-Produkt zu den Open-Source-Zeitreihendatenbanken und wurde in nur einem Jahr von mehr als 60 Unternehmen getestet und produziert, was mehr als 70 Mitwirkende von wichtigen Universitäten und Unternehmen im In- und Ausland anzog – openGemini, Die Open-Source-Datenbank für verteilte Zeitreihen von Huawei konzentriert sich hauptsächlich auf die Speicherung und Analyse großer Zeitreihendaten. Durch technologische Innovation wird die Architektur des Geschäftssystems vereinfacht, die Speicherkosten für große Zeitreihendaten gesenkt und die Speicher- und Analyseeffizienz verbessert Zeitreihendaten.
Heute haben wir Xiang Yu, den Leiter der openGemini-Community, eingeladen, über ihre Open-Source-Geschichte zu sprechen~
01 Ausgehend von inneren Bedürfnissen und allmählicher Bewegung in Richtung Selbstforschung
Die Forschung und Entwicklung von openGemini entstand ursprünglich aus den eigenen Bedürfnissen von Huawei.
Im Jahr 2019 wurden mit der Einrichtung von Huawei Cloud Rechenzentren in Guangzhou, Shanghai, Peking, Guizhou und Hongkong gebaut und über 260 Cloud-Dienste gestartet. Täglich werden durchschnittlich mehrere TB an Überwachungsindikatordaten gesammelt . Die ursprüngliche Big-Data-Lösung ist nach und nach überfordert. Je größer die Datenmenge, desto geringer die Abfrageeffizienz und die Kosten für die Datenspeicherung steigen weiter. Es besteht ein dringender Bedarf an einer leistungsstarken, hoch skalierbaren dedizierten Zeitreihendatenbank.
Zu diesem Zeitpunkt gab es keine brauchbaren Zeitreihen-Datenbankprodukte, die mit der Nachfrageentwicklung mithalten konnten. InfluxDB ist immer noch eine eigenständige Version, und inländische Apache IoTDB und TDengine erfüllen bei weitem nicht die Produktionsanforderungen. Daher ist Huawei entschlossen, eine eigene Datenbank aufzubauen, die Datenverarbeitung zu optimieren und derzeit sehr wichtige Geschäftsprobleme zu lösen. In diesem Zusammenhang entstand openGemini.
Laut Xiang Yu führten sie im Hinblick auf die Technologieauswahl zunächst eine Clustertransformation auf Basis der Open-Source-InfluxDB durch. Mit der Zunahme der Anzahl der Indikatoren und der Erhöhung der Erfassungshäufigkeit hat der tägliche Anstieg des Datenvolumens jedoch Dutzende Terabyte erreicht. Zu diesem Zeitpunkt begannen die Mängel in der eigenen Architektur von InfluxDB offensichtlich zu werden, die sich auf die Leistung und Stabilität des Systems auswirkten. Daher entschieden sie sich für eine Rekonstruktion der Architektur und begannen mit der Eigenentwicklung des openGemini-Kernels.
02 Einzigartige Persönlichkeit, führende Leistung
Seit seiner Einführung ist openGemini eng mit den Geschäftsanforderungen von Huawei verknüpft, sodass jedes Design voller praktischer Überlegungen ist. Konkret unterscheidet sich openGemini von anderen Zeitreihendatenbanken in neun wesentlichen „Persönlichkeiten“:
Leistungsvorteil: Unter der differenzierten Wettbewerbsfähigkeit von openGemini ist hohe Leistung der wichtigste Faktor. In Szenarios mit großen Datenmengen verbessert openGemini einfache Abfrageszenarien um mehr als das Zweifache, mittlere Abfrageszenarien um mehr als das Fünffache und komplexe Abfrageszenarien um mehr als das Zehnfache im Vergleich zu Open-Source-InfluxDB. Im Vergleich zu anderen ähnlichen Open-Source-Produkten bietet openGemini auch offensichtliche Leistungsvorteile.
Die offiziell angekündigte eigenständige Schreibleistung ist wie folgt (das Testtool ist TSBS, relevante Testdetails finden Sie in der offiziellen Dokumentation der openGemini-Website):

Offiziell angekündigter Vergleich der Abfrageleistung einzelner Maschinen in DevOps-Szenarien (durchschnittliche Latenz, ms):

Offiziell angekündigter Vergleich der Abfrageleistung einzelner Maschinen in IoT-Szenarien (durchschnittliche Verzögerung, ms):
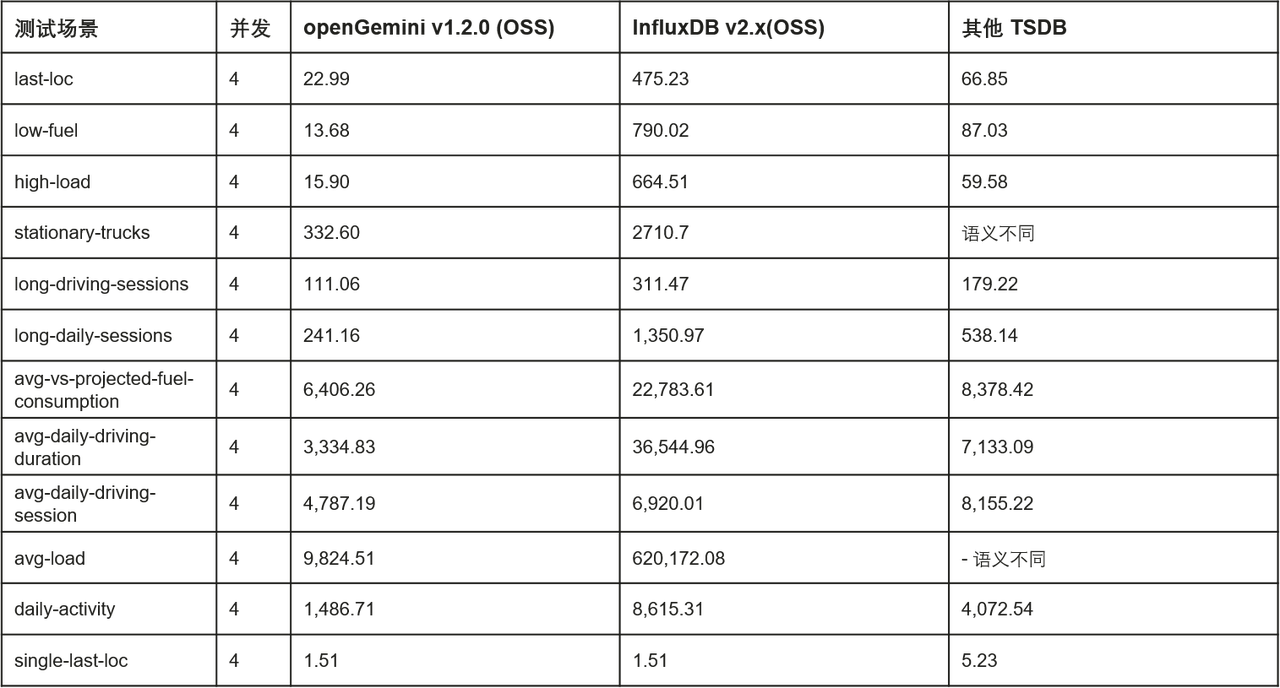
Darüber hinaus hat openGemini eine Reihe praktischer Funktionen zur Datenspeicherung und Datenanalyse eingeführt, um eine differenziertere Wettbewerbsfähigkeit aufzubauen:
Einzigartige verteilte Architektur : openGemini bietet zwei Versionen: eigenständige und verteilte Cluster. Der verteilte Cluster verwendet die MPP-Massiv-Parallelverarbeitungs-Schichtenarchitektur, die die Computer-Engine, die Speicher-Engine und die Metadatenverwaltung in unabhängige Komponenten unterteilt -store bzw. ts-meta. Verschiedene Komponenten unterstützen die unabhängige horizontale Erweiterung und ermöglichen so eine flexible Reaktion auf komplexe Anwendungsszenarien.
Engine mit hoher Kardinalität: Das Problem der hohen Kardinalität (auch als Dimensionalitätskatastrophe bekannt) führt zu einer Erweiterung des invertierten Index, was zu einem übermäßigen Speicherressourcenverbrauch und einer verringerten Lese- und Schreibleistung führt. Dies hat die Entwicklung von Zeitreihendatenbanken seit langem geplagt. Die OpenGemini-High-Radix-Engine löst dieses Problem vollständig, indem sie einen zeitreihenspezifischen Sparse-Index erstellt, der sich sehr gut für den Einsatz in der Netzwerküberwachung, der Kontrolle finanzieller Risiken, dem Internet der Dinge, dem Transport und anderen Bereichen eignet.
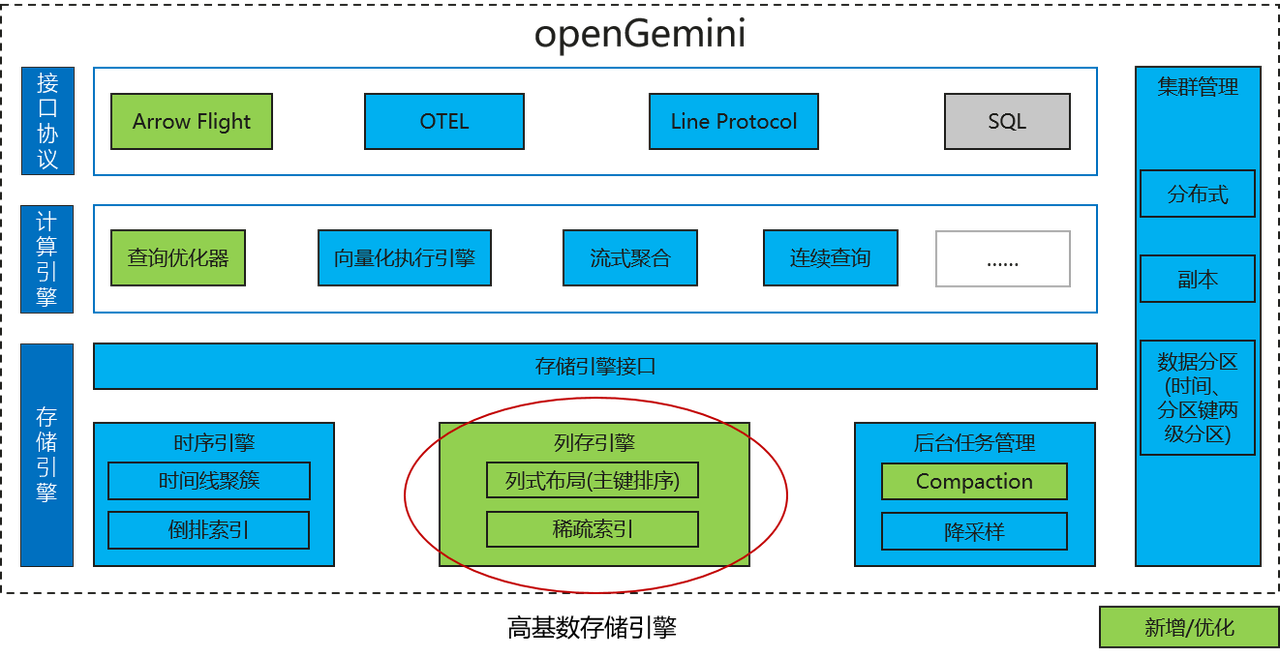
Textabfrage : Textdaten sind ein gängiger Datentyp, der die Erstellung von Indizes für Textdaten unterstützt, eine dynamische Lernwortsegmentierungsmethode verwendet, präzise Phrasen- und Fuzzy-Zuordnung unterstützt und einen geringen Speicherressourcenverbrauch und eine hohe Abrufeffizienz aufweist.
Streaming-Aggregation: Streaming-Aggregation ist eine Vorabsampling-Methode, die beim Schreiben von Daten ein Downsampling durchführt. Ihr Zweck besteht darin, das Problem herkömmlicher Downsampling-Methoden zu lösen, bei denen eine große Menge historischer Daten zur Berechnung von der Festplatte gelesen wird, was zu einer erheblichen E/A-Verstärkung führt. Das Problem.
Mehrstufiges Downsampling : Bei vorhandenen historischen Daten behalten herkömmliche Downsampling-Methoden historische Datendetails bei. In einigen Szenarien sind die historischen Datendetails nicht wichtig, und nur die Datenmerkmale müssen beibehalten werden. Die mehrstufige Downsampling-Funktion kann die Merkmale der historischen Datendetails extrahieren und die vorhandenen historischen Datendetails ersetzen, was zu einer weiteren Reduzierung führen kann die Kosten um 50 %.
Anomalieerkennung und -vorhersage: Die Anomalieerkennung und -vorhersage ist derzeit eine der ausgereiftesten Anwendungen der Zeitreihendatenanalyse und wird häufig in Szenarien wie quantitativen Transaktionen, Netzwerksicherheitserkennung und der täglichen Wartung von Rechenzentren, Industrieanlagen und IT eingesetzt Infrastruktur. openGemini bietet eine Anomalieerkennungsbibliothek – openGemini-castor, die Erkennungsalgorithmen für 13 gängige Anomalieszenarien kapselt. Sie bietet die Vorteile einer schnellen Erkennungsgeschwindigkeit, einer hohen Genauigkeit und der Integration von Stream und Batch und hilft so Anwendungen, die Effizienz der Datenanalyse zu verbessern.
Tiered Storage für heiße und kalte Daten : Unterstützt die Übertragung historischer Daten in den Objektspeicher und ermöglicht so eine kostengünstige Methode zur dauerhaften Aufbewahrung historischer Daten sowie die Offline-Analyse großer Datenmengen. [Die Veröffentlichung dieser Funktion ist für H2 geplant]
Datenzuverlässigkeit : Unterstützt mehrere Computerkopien, um die Datenzuverlässigkeit weiter zu verbessern. [Die Veröffentlichung dieser Funktion ist für H2 geplant]

03 Konzentrieren Sie sich auf die Benutzererfahrung, um den Einstieg zu erleichtern
openGemini bietet nicht nur eine starke Leistung, sondern sein einzigartiges Design kann auch in tatsächlichen Anwendungen viel Komfort bieten:
Was den Einstieg betrifft , ist openGemini vollständig kompatibel mit InfluxDB v1. Gleichzeitig verwendet openGemini dasselbe Line-Protokoll wie InfluxDB. Die Datenmodellierung ist einfach und leicht zu verstehen und auch für Entwickler relationaler Datenbanken geeignet. Schließlich verwendet openGemini eine SQL-ähnliche Abfragesprache, die kein zusätzliches Lernen erfordert und einfach zu erlernen ist. Für die Cluster-Bereitstellung stellt die Community außerdem das One-Click-Deployment-Tool Gemix zur Verfügung, das viel Konfigurationsarbeit erspart.
In Bezug auf Betriebssysteme unterstützt openGemini derzeit gängige Linux-Systeme (einschließlich openEuler), Windows und MacOS, was die Anwendungsentwicklung und das Debuggen komfortabler macht. Der Prozessor unterstützt sowohl X86- als auch ARM64-Architekturen.
Im Hinblick auf Cloud-Nativeness stellt openGemini Dockerfile- und Docker-Images bereit und unterstützt die Bereitstellung von Docker, K8s, KubeEdge und anderen Plattformen. Da sich die IP-Adresse nach dem Neustart des Containers ändert, hat openGemini eine Domänennamenfunktion hinzugefügt, um sicherzustellen, dass Clusterknoten auch nach dem Neustart des Containers weiterhin Konnektivität aufrechterhalten können. Die Community hat außerdem das openGemini-Operator-Projekt erstellt, um Benutzern die Bereitstellung von Containern mit einem Klick zu erleichtern. openGemini unterstützt das Remote-Lesen und Schreiben von Prometheus und kann als Backend-Speicher für Prometheus verwendet werden, um das Problem unzureichender Speicherkapazität zu lösen. [Übrigens: openGemini wird auch PromQL direkt unterstützen, das sich derzeit in der Entwicklung befindet]
Im Hinblick auf die Beobachtbarkeit hat die Community die ts-monitor-Komponente entwickelt, die auf das Sammeln von Knoten- und Kernelindikatoren spezialisiert ist. Sie ist in 19 Unterkategorien und mehr als 260 Elemente unterteilt. Sie kann mit Grafana verwendet werden, um eine umfassende Überwachung des Betriebsstatus zu erreichen von openGemini. Beispielsweise können Indikatoren wie CPU- und Speicherauslastung, Schreibbandbreite, Schreiblatenz, Schreibgleichzeitigkeit und QPS auf einen Blick über die visuelle Schnittstelle angezeigt werden, sodass der Betriebsstatus, die Optimierung der Datenbankleistung und die genaue Lokalisierung von Problemen leicht angezeigt werden können jederzeit.
04 Nach internen tatsächlichen Kampftests, Rückgabe an Open Source
Als Zeitreihendatenbank wird openGemini derzeit am häufigsten im Internet der Dinge und bei der Betriebs- und Wartungsüberwachung eingesetzt. In Bezug auf die Verarbeitung großer Datenmengen bietet es Vorteile, die herkömmliche Datenbanken nicht bieten können. Gleichzeitig hat openGemini als internes Projekt von Huawei den Test „seiner eigenen Leute“ bestanden:
Huawei Cloud SRE verwendet openGemini als Überwachungsdatenspeicherbasis. Insgesamt werden 25 Cluster mit einer maximalen Clustergröße von 70 Knoten eingesetzt. Es hat den tatsächlichen Test von 40 Millionen Datenschreibvorgängen pro Sekunde und 50.000 gleichzeitigen erfolgreich bestanden Abfragen. Im Vergleich zur ursprünglichen Lösung wird bei gleichem Geschäft die End-to-End-Verzögerung des ursprünglichen Systems um 50 % reduziert, CPU-Ressourcen können um 68 %, Speicherressourcen um 50 % und Festplattenressourcen eingespart werden Ressourcen können um mehr als 90 % eingespart werden.
Die industrielle IoT-Plattform von Huawei Cloud nutzte bereits zuvor die eigenständige Version von InfluxDB und muss sich keine Sorgen mehr um den Durchsatz und die Abfrageleistung machen Gerätezugriffe sind auf Millionenniveau gestiegen.
Xiang Yu stellte fest, dass openGemini aus Open Source stammt und stark vom Open Source-Projekt InfluxDB profitiert hat. Daher hofft er, dass alle openGemini-Codes Open Source sind Es hofft auch, dass die Plattform durch die offene Community zusammen mit Entwicklern gemeinsam technologische Innovationen fördert und Open-Source-Ergebnisse teilt.
Derzeit verfügt openGemini nur über eine Open-Source-Version und einen Cloud-Service. Es ist nicht geplant, sich an kommerziellen Offline-Versionen zu beteiligen, und ist bereit, an die Stiftung zu spenden. Derzeit weist die Community noch viele Unvollkommenheiten auf. Als nächstes wird die Community die ökologischen Tools von openGemini (wie Datenmigrationstools, SDK, ökologische Big-Data-Integration usw.), visuelle Verwaltungsschnittstellen, Dokumente usw. weiter bereichern.
„Derzeit wird sich die technische Planung der Community im Allgemeinen auf die drei wichtigen Anwendungsszenarien des Internets der Dinge, die Betriebs- und Wartungsüberwachung und -beobachtbarkeit konzentrieren und die ökologische Kompatibilität und den Kernel-Fähigkeitsaufbau verwandter Technologien stärken. Wir beginnen mit der Demonstration des nächsten.“ Generation der Softwarearchitektur von openGemini“, sagte Xiang Yu.
„Kurzfristig wird openGemini keine industriebezogenen Szenarien berücksichtigen, da die Geschäftsszenarien im Industriebereich sehr komplex sind, die Echtzeitanforderungen extrem hoch sind, die Gräben der Hersteller von Industriesoftware sehr tief sind und die Dinge, die.“ Die Möglichkeiten von Zeitreihendatenbanken sind begrenzt. Darüber hinaus wissen wir nicht genug über dieses Szenario. Danach werden wir nach einigen Partnern im Industriebereich suchen, z. B. nach Lösungen für die Industrie Anbieter usw., um zusammenzuarbeiten und sich gemeinsam zu verbessern“, sagte Xiang Yu.
Offizielle Homepage der openGemini-Website: https://www.openGemini.org/
Open-Source-Adresse von openGemini: https://github.com/openGemini
Fellow Chicken „Open-Source“ -Deepin-IDE und endlich Bootstrapping erreicht! Guter Kerl, Tencent hat Switch wirklich in eine „denkende Lernmaschine“ verwandelt. Tencent Clouds Fehlerüberprüfung und Situationserklärung vom 8. April RustDesk-Remote-Desktop-Startup-Rekonstruktion Web-Client WeChats Open-Source-Terminaldatenbank basierend auf SQLite WCDB leitete ein großes Upgrade ein TIOBE April-Liste: PHP fiel auf ein Allzeittief, Fabrice Bellard, der Vater von FFmpeg, veröffentlichte das Audiokomprimierungstool TSAC , Google veröffentlichte ein großes Codemodell, CodeGemma , wird es dich umbringen? Es ist so gut, dass es Open Source ist – ein Open-Source-Bild- und Poster-Editor-Tool