Hintergrundeinführen
GPUs werden derzeit häufig in der Deep-Learning-Plattform iQiyi verwendet. Die GPU verfügt über Hunderte oder Tausende von Verarbeitungskernen und kann eine große Anzahl von Anweisungen parallel ausführen, wodurch sie sich sehr gut für Deep-Learning-bezogene Berechnungen eignet. GPUs werden häufig in CV- (Computer Vision) und NLP-Modellen (Natural Language Processing) verwendet. Im Vergleich zu CPUs können sie das Modelltraining und die Inferenz normalerweise schneller und wirtschaftlicher durchführen.
Das CTR-Modell (Click Trough Rate) wird häufig in Empfehlungs-, Werbe-, Such- und anderen Szenarien verwendet, um die Wahrscheinlichkeit abzuschätzen, mit der ein Benutzer auf eine Anzeige oder ein Video klickt. Im Trainingsszenario des CTR-Modells wurden in großem Umfang GPUs eingesetzt, was die Trainingsgeschwindigkeit verbessert und die erforderlichen Serverkosten senkt.
Wenn wir jedoch im Inferenzszenario das trainierte Modell über Tensorflow-Serving direkt auf der GPU bereitstellen, stellen wir fest, dass der Inferenzeffekt nicht ideal ist. erscheint in:
-
Die Inferenzlatenz ist hoch. CTR-Modelle sind in der Regel endbenutzerorientiert und reagieren sehr empfindlich auf die Inferenzlatenz.
-
Die GPU-Auslastung ist gering und die Rechenleistung wird nicht vollständig ausgenutzt.
Ursachenanalyse
Analysetool
-
Tensorflow Board, ein offiziell von Tensorflow bereitgestelltes Tool, kann den Zeitaufwand in jeder Phase des Berechnungsflussdiagramms visuell anzeigen und den Gesamtzeitaufwand der Bediener zusammenfassen.
-
Nsight ist eine von NVIDIA für CUDA-Entwickler bereitgestellte Entwicklungstool-Suite, die eine relativ einfache Verfolgung, Fehlerbehebung und Leistungsanalyse von CUDA-Programmen durchführen kann.
Fazit der Analyse
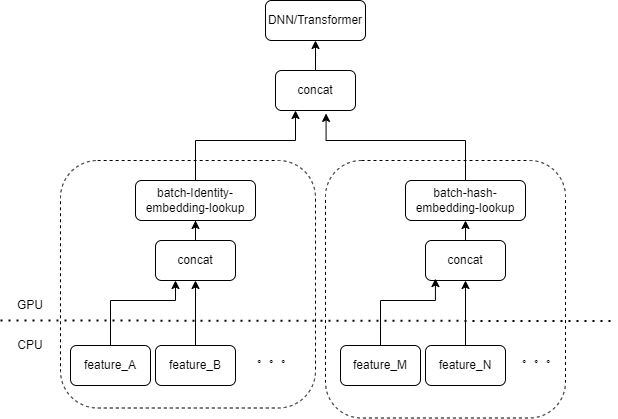
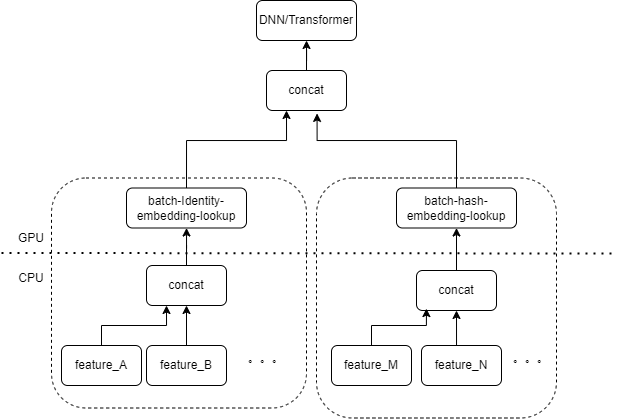
Typische CTR-Modelleingaben enthalten eine große Anzahl spärlicher Funktionen (z. B. Geräte-ID, ID des zuletzt angesehenen Videos usw.). Die FeatureColumn von Tensorflow verarbeitet diese Features. Zunächst werden Identitäts-/Hash-Operationen durchgeführt, um den Index der Einbettungstabelle zu erhalten. Nach der Einbettungssuch- und Mittelungsoperation wird der entsprechende Einbettungstensor erhalten. Nach dem Spleißen der Einbettungstensoren, die mehreren Merkmalen entsprechen, wird ein neuer Tensor erhalten, der dann in den nachfolgenden DNN/Transformer und andere Strukturen eingeht.
Daher aktiviert jedes spärliche Feature mehrere Operatoren in der Eingabeebene des Modells. Jeder Operator entspricht einer oder mehreren GPU-Berechnungen, also dem Cuda-Kernel. Jeder Cuda-Kernel umfasst zwei Phasen: Starten des Cuda-Kernels (der zum Starten des Kernels erforderliche Overhead) und Kernel-Ausführung (eigentliche Durchführung von Matrixberechnungen auf dem Cuda-Kernel). Der Operator, der der spärlichen Feature-Identitäts-/Hash-/Einbettungssuche entspricht, hat einen geringen Rechenaufwand, und der Startkernel benötigt oft mehr Zeit als die Kernel-Ausführungszeit. Im Allgemeinen enthält das CTR-Modell Dutzende bis Hunderte spärlicher Funktionen, und theoretisch wird es Hunderte von Startkerneln geben, was derzeit den größten Leistungsengpass darstellt.
Dieses Problem trat nicht auf, wenn die GPU zum Trainieren des CTR-Modells verwendet wurde. Da das Training selbst eine Offline-Aufgabe ist und Verzögerungen nicht berücksichtigt werden, kann die Stapelgröße während des Trainings sehr groß sein. Obwohl der Startkernel immer noch mehrmals ausgeführt wird, ist die durchschnittliche Zeit, die für jede Probe des Startkernels aufgewendet wird, sehr gering, solange die Anzahl der beim Ausführen des Kernels berechneten Proben groß genug ist. Wenn bei Online-Inferenzszenarien Tensorflow Serving erforderlich ist, um vor der Durchführung von Berechnungen genügend Inferenzanforderungen zu empfangen und Batches zusammenzuführen, ist die Inferenzlatenz sehr hoch.
Optimierung
Unser Ziel ist es, die Leistung zu optimieren, ohne den Trainingscode oder das Service-Framework grundsätzlich zu ändern. Wir denken natürlich an zwei Methoden: Reduzieren Sie die Anzahl der gestarteten Kernel und verbessern Sie die Geschwindigkeit des Kernel-Starts.
Operatorfusion
Die grundlegende Operation besteht darin, mehrere aufeinanderfolgende Operationen oder Operatoren zu einem einzigen Operator zusammenzuführen. Dadurch kann einerseits die Anzahl der Cuda-Kernel-Starts reduziert werden. Andererseits können einige Zwischenergebnisse während des Berechnungsprozesses in Registern gespeichert oder gemeinsam genutzt werden Speicher und nur in der Berechnung Am Ende des Unterabschnitts werden die Berechnungsergebnisse in den globalen Cuda-Speicher geschrieben.
Es gibt zwei Hauptmethoden
-
Automatische Fusion basierend auf Deep-Learning-Compiler
-
Manuelle Operator-Fusion für Unternehmen
automatische Fusion
Wir haben verschiedene Deep-Learning-Compiler ausprobiert, wie zum Beispiel TVM/TensorRT/XLA, und tatsächliche Tests können die Fusion einer kleinen Anzahl von Operatoren in DNN erreichen, wie zum Beispiel kontinuierliches MatrixMat/ADD/Relu. Da TVM/TensorRT Zwischenformate wie ONNX exportieren muss, muss der Online-Prozess des Originalmodells geändert werden. Daher verwenden wir tf.ConfigProto(), um Tensorflows integriertes XLA für die Fusion zu aktivieren.
Die automatische Fusion hat jedoch keinen guten Fusionseffekt für Operatoren im Zusammenhang mit spärlichen Features.
Manuelle Operatorfusion
Wir gehen natürlich davon aus, dass wir einen Operator implementieren können, um die Eingabe mehrerer Features in einem Array als Eingabe des Operators zusammenzufassen, wenn mehrere Features von derselben Art von FeatureColumn-Kombination in der Eingabeebene verarbeitet werden. Die Ausgabe des Operators ist ein Tensor, und die Form dieses Tensors stimmt mit der Form des Tensors überein, der durch separate Berechnung der ursprünglichen Merkmale und deren anschließende Verkettung erhalten wird.
Am Beispiel der ursprünglichen Kombination IdentityCategoricalColumn + EmbeddingColumn haben wir den Operator BatchIdentiyEmbeddingLookup implementiert, um dieselbe Berechnungslogik zu erreichen.
Um den Algorithmusstudenten die Verwendung zu erleichtern, haben wir einen neuen FusedFeatureLayer gekapselt, der den nativen FeatureLayer ersetzt. Zusätzlich zum Einschließen des Fusionsoperators ist auch die folgende Logik implementiert:
-
Die Fusionslogik wird während der Inferenz wirksam und die ursprüngliche Logik wird während des Trainings verwendet.
-
Features müssen sortiert werden, um sicherzustellen, dass Features desselben Typs zusammen angeordnet werden können.
-
Da die Eingabe jedes Features eine variable Länge hat, generieren wir hier ein zusätzliches Indexarray, um zu markieren, zu welchem Feature jedes Element des Eingabearrays gehört.
Für Unternehmen muss nur der ursprüngliche FeatureLayer ersetzt werden, um den Integrationseffekt zu erzielen.
Der ursprünglich hunderte Male getestete Startkernel wurde nach der manuellen Fusion auf weniger als das Zehnfache reduziert. Der Aufwand beim Starten des Kernels wird erheblich reduziert.
MultiStream verbessert die Starteffizienz
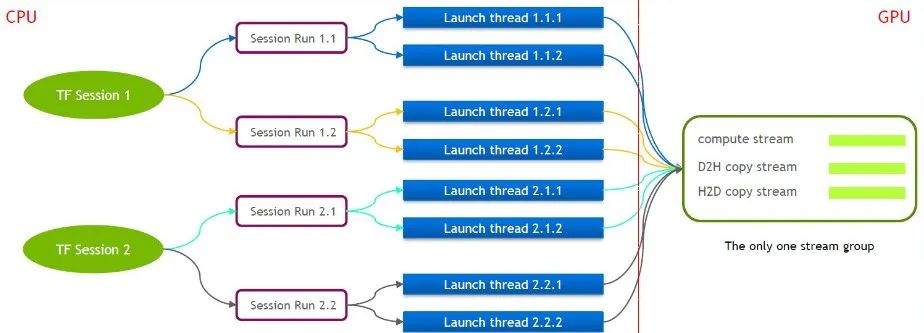
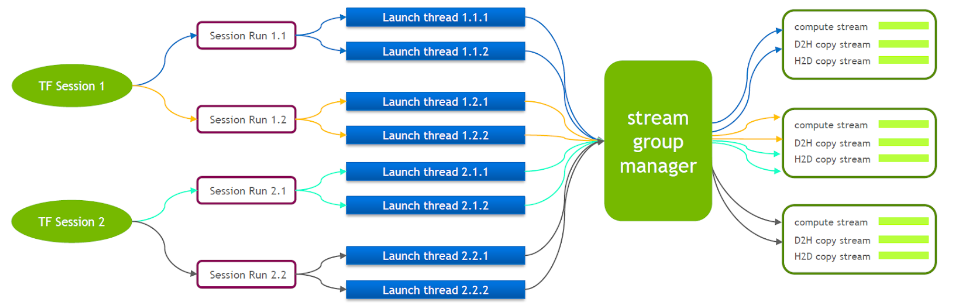
TensorFlow selbst ist ein Single-Stream-Modell, das nur eine Cuda-Stream-Gruppe enthält (bestehend aus Compute Stream, H2D Stream, D2H Stream und D2D Stream). Mehrere Kernel können nur seriell auf demselben Compute Stream ausgeführt werden, was ineffizient ist. Selbst wenn der Cuda-Kernel über mehrere Tensorflow-Sitzungen gestartet wird, ist auf der GPU-Seite weiterhin eine Warteschlange erforderlich.
Aus diesem Grund unterhält das technische Team von NVIDIA einen eigenen Zweig von Tensorflow, um die gleichzeitige Ausführung mehrerer Stream-Gruppen zu unterstützen. Dies wird verwendet, um die Effizienz des Starts des Cuda-Kernels zu verbessern. Wir haben diese Funktion in unser Tensorflow Serving portiert.
Wenn Tensorflow Serving ausgeführt wird, muss Nvidia MPS aktiviert sein, um gegenseitige Störungen zwischen mehreren CUDA-Kontexten zu reduzieren.
Optimierung kleiner Datenkopien
Basierend auf der vorherigen Optimierung haben wir die kleine Datenkopie weiter optimiert. Nachdem Tensorflow Serving die Werte jeder Funktion aus der Anfrage deserialisiert hat, ruft es cudamemcpy mehrmals auf, um die Daten vom Host auf das Gerät zu kopieren. Die Anzahl der Anrufe hängt von der Anzahl der Funktionen ab.
Bei den meisten CTR-Diensten wird tatsächlich gemessen, dass es bei kleiner Batchgröße effizienter ist, die Daten zuerst auf der Hostseite zu verbinden und dann cudamemcpy auf einmal aufzurufen.
Chargen zusammenführen
Im GPU-Szenario muss die Stapelzusammenführung aktiviert werden. Standardmäßig führt Tensorflow Serving keine Anfragen zusammen. Um die parallelen Rechenfähigkeiten der GPU besser zu nutzen, können mehr Samples in eine Vorwärtsberechnung einbezogen werden. Wir haben die Option „enable_batching“ von Tensorflow Serving zur Laufzeit aktiviert, um mehrere Anfragen stapelweise zusammenzuführen. Gleichzeitig müssen Sie eine Batch-Konfigurationsdatei bereitstellen, die sich auf die Konfiguration der folgenden Parameter konzentriert. Im Folgenden sind einige unserer Erfahrungen aufgeführt.
-
max_batch_size: Die maximal zulässige Anzahl von Anfragen in einem Stapel, die etwas größer sein kann.
-
batch_timeout_micros: Die maximale Wartezeit für das Zusammenführen eines Stapels. Auch wenn die Anzahl des Stapels nicht max_batch_size erreicht, wird sie sofort berechnet (theoretisch gilt: Je höher die Verzögerungsanforderung, desto kleiner ist die Einstellung hier). Am besten stellen Sie den Wert auf unter 5 Millisekunden ein.
-
num_batch_threads: Maximale Anzahl gleichzeitiger Inferenzthreads. Nach dem Einschalten von MPS kann der Wert auf 1 bis 4 eingestellt werden. Bei weiteren Threads erhöht sich die Verzögerung.
Hierbei ist zu beachten, dass die meisten spärlichen Features, die in das CTR-Klassenmodell eingegeben werden, Features variabler Länge sind. Wenn der Kunde keine besondere Vereinbarung trifft, kann es bei mehreren Anfragen zu inkonsistenten Längen eines bestimmten Features kommen. Tensorflow Serving verfügt über eine Standard-Auffülllogik, die die entsprechenden Features für kürzere Anfragen mit Nullen auffüllt. Bei Features mit variabler Länge wird -1 zur Darstellung von Null verwendet. Die Standardauffüllung von 0 ändert tatsächlich die Bedeutung der ursprünglichen Anforderung.
Beispielsweise ist die ID des zuletzt von Benutzer A angesehenen Videos [3,5] und die ID des zuletzt von Benutzer B angesehenen Videos ist [7,9,10]. Wenn die Anforderung standardmäßig abgeschlossen ist, wird sie zu [[3,5,0], [7,9,10]]. Bei der anschließenden Verarbeitung geht das Modell davon aus, dass A kürzlich 3 Videos mit den IDs 3, 5, 0 angesehen hat.
Daher haben wir die Abschlusslogik der Tensorflow-Serving-Antwort geändert. In diesem Fall lautet die Abschlusslogik [[3,5,-1], [7,9,10]]. Die Bedeutung der ersten Zeile ist immer noch, dass die Videos 3 und 5 angesehen wurden.
endgültige Wirkung
Nach verschiedenen oben genannten Optimierungen haben Latenz und Durchsatz unseren Anforderungen entsprochen und wurden in empfohlenen personalisierten Push- und Wasserfall-Streaming-Diensten implementiert. Die Geschäftsergebnisse stellen sich wie folgt dar:
-
Der Durchsatz wird im Vergleich zum nativen Tensorflow-GPU-Container um mehr als das Sechsfache erhöht.
-
Die Latenz entspricht im Grunde der CPU und erfüllt die Geschäftsanforderungen
-
Bei der Unterstützung der gleichen QPS werden die Kosten um mehr als 40 % reduziert
Vielleicht möchten Sie es auch sehen
Dieser Artikel wurde vom öffentlichen WeChat-Konto geteilt – iQIYI Technology Product Team (iQIYI-TP).
Bei Verstößen wenden Sie sich bitte zur Löschung an [email protected].
Dieser Artikel ist Teil des „ OSC Source Creation Plan “. Alle, die ihn lesen, sind herzlich eingeladen, mitzumachen und ihn gemeinsam zu teilen.