
Quellteam|Bytedance Live Operation PlatformBeim kontinuierlichen Aufbau domänenübergreifender Datenaggregationsdienste auf Basis von ES haben wir festgestellt, dass sich viele Funktionen von ES stark von häufig verwendeten Datenbanken wie MySQL unterscheiden. In diesem Artikel werden die Implementierungsprinzipien von ES und Vorschläge zur Geschäftsauswahl auf Live-Übertragungsplattformen erläutert und Probleme, die in der Praxis und im Denken auftreten.
ES-Einführung und Anwendungsszenarien
Elasticsearch ist eine verteilte, nahezu in Echtzeit arbeitende Engine zum Speichern, Abrufen und Analysieren umfangreicher Daten. Was wir oft „ELK“ nennen, bezieht sich auf ein Datensystem, das aus Elasticsearch, Logstash/Beats und Kibana besteht und in der Lage ist, Daten zu sammeln, zu speichern, abzurufen und zu visualisieren. ES spielt eine Rolle bei der Datenspeicherung und -indizierung, dem Datenabruf und der Datenanalyse in ähnlichen Datensystemen.
ES-Funktionen
Jede Technologieauswahl hat ihre eigenen Merkmale, und die Gesamtmerkmale von ES werden auch von der zugrunde liegenden Implementierung beeinflusst. Im zweiten Teil dieses Artikels werden die Grundursachen der folgenden Merkmale detailliert beschrieben.
Vorteile:
-
Verteilt: Durch Sharding können Daten bis zur PB-Ebene unterstützt und Sharding-Details von außen abgeschirmt werden. Benutzer müssen sich des Lese- und Schreibroutings nicht bewusst sein.
-
Skalierbar: Einfache horizontale Erweiterung, keine Notwendigkeit, Datenbanken und Tabellen wie MySQL manuell aufzuteilen oder Komponenten von Drittanbietern zu verwenden;
-
Schnelle Geschwindigkeit: Parallele Berechnung jedes Shards, schnelle Abrufgeschwindigkeit;
-
Volltextabfrage: mehrere gezielte Optimierungen, wie z. B. die Unterstützung der mehrsprachigen Volltextabfrage durch verschiedene Wortsegmentierungs-Plug-ins und die Verbesserung der Genauigkeit durch semantische Verarbeitung;
-
Umfangreiche Datenanalysefunktionen.
Nachteile:
-
Transaktionen werden nicht unterstützt: Der Berechnungsprozess jedes Shards ist parallel und unabhängig;
-
Nahezu in Echtzeit: Vom Schreiben der Daten bis zur Datenabfrage vergeht eine Verzögerung von mehreren Sekunden.
-
Die native DSL-Sprache ist relativ komplex und erfordert einen gewissen Lernaufwand.
Häufige Verwendungen
Die Funktionen wirken sich auf die Anwendungsszenarien der Komponenten aus. Die Live-Broadcast-Betriebsplattform verwendet ES, um verschiedene Informationen von Hunderten Millionen Ankern zu aggregieren, und verwendet sie, um verschiedene Listen auf der entsprechenden Plattform anzuzeigen wird zur Erkennung von Argos-Fehlern verwendet.
ES-Implementierung und -Architektur
Als nächstes müssen wir verstehen, wie die oben genannten Vorteile von ES realisiert werden und wie die Mängel verursacht werden. Wenn wir über Lucene sprechen, ist es eine Java-Bibliothek für die Volltextsuche, die Lucene als zugrunde liegende Komponente verwendet Funktionen Im Folgenden werden hauptsächlich die Funktionen von Lucene vorgestellt. Welche Funktionen und welche neuen Fähigkeiten bietet ES im Vergleich zu Lucene?
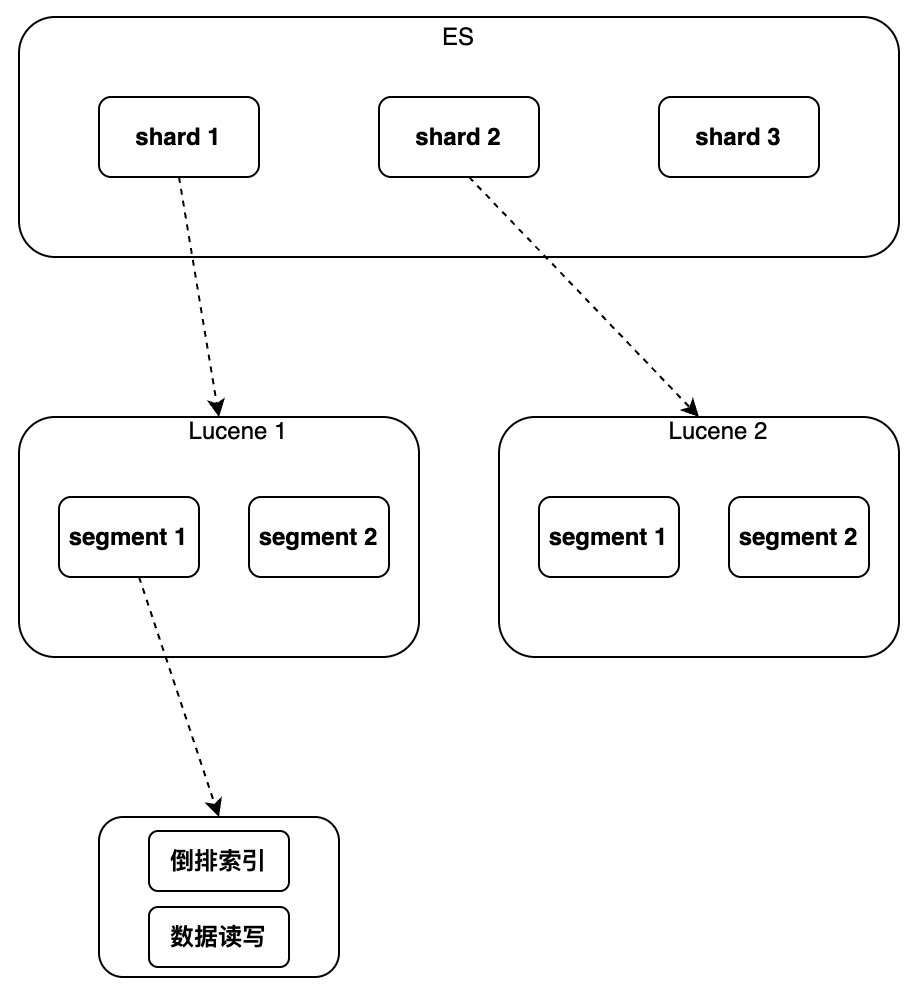
Lucene implementiert die Indizierung und den Abruf von Daten in einer einzelnen Instanz. Es unterstützt jedoch keine Änderung und Löschung von Dokumenten. Es kann keine einheitliche Methode zur Identifizierung von Dokumenten verwenden Der Vertrieb kann nicht unterstützt werden.
Daher hat ES im Vergleich zu Lucene einige neue Funktionen hinzugefügt
,
darunter hauptsächlich das neue globale Primärschlüsselfeld „_id“, das das Ändern/Löschen von Daten und das Shard-Routing ermöglicht, sowie die Verwendung einer separaten Datei zum Markieren des gelöschten Dokuments zum „Schreiben eines neuen“. Der Aktualisierungsvorgang wird durch „Dokument, Markieren des alten Dokuments als gelöscht“ implementiert. Durch Hinzufügen einer neuen Versionsnummer zum Dokument wird die Parallelität in Form einer optimistischen Sperre unterstützt Es wurde auch eine Aggregationsanalyse hinzugefügt, mit der Sortier-, Statistik- und Analyseergebnisse der Abfrageergebnisse implementiert werden können. Die spezifischen Implementierungsdetails werden im Folgenden in der Reihenfolge von Einzelinstanz bis Cluster vorgestellt.
einzelne Instanz
Index
Der Zweck der Indizierung besteht darin, den Abrufprozess zu beschleunigen. Das ursprüngliche Zielszenario des ES-Designs ist der Volltextabruf. Daher wurden zahlreiche Optimierungen vorgenommen. Darüber hinaus unterstützt es auch andere Indizes wie Block Kd Tree ES, die automatisch den entsprechenden Indextyp entsprechend dem Feldtyp abgleichen und Indizes für die Felder erstellen, die indiziert werden müssen.
Invertierter Index und Block-Kd-Baum sind ebenfalls häufig verwendete Indextypen für die Analyse. Bei Zeichenfolgen gibt es zwei häufige Situationen: Text verwendet Wortsegmentierung + invertierten Index, während Schlüsselwörter Nicht-Wortsegmentierung + invertierten Index verwenden. Für numerische Typen wie Long/Float wird normalerweise Block Kd Tree verwendet.
Invertierter Index
Beim Erstellen des Index indiziert ES standardmäßig jedes Feld. Dieser Prozess umfasst Wortsegmentierung, semantische Verarbeitung und die Erstellung von Zuordnungstabellen. Zunächst wird der Text in Wörter segmentiert. Die Wortsegmentierungsmethode hängt mit der Sprache zusammen, beispielsweise das Schneiden nach Leerzeichen im Englischen. Anschließend werden bedeutungslose Wörter gelöscht und eine semantische Normalisierung durchgeführt. Erstellen Sie abschließend die Zuordnungstabelle. Das folgende Beispiel zeigt kurz den Verarbeitungsprozess des Namensfelds von Anker 15: Es wird in Kleinbuchstaben und andere Operationen umgewandelt und die Zuordnungen von allen->15 und sara->15 werden erstellt.
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
Abfrageprozess
Nehmen Sie als Beispiel die Abfrage nach dem Anker namens „allen sara“. Gemäß den Ergebnissen der Wortsegmentierung werden jeweils zwei Listen [12, 15] und [1, 15] gefunden (in tatsächlichen Anwendungen basiert die Abfrage auch auf Synonymen). ); um die Listen und Bewertungen zusammenzuführen, drücken Sie Die Priorität besteht darin, die Ergebnisse zu erhalten [15, 12, 1] (dies ist der Rückrufschritt in der Suche und wird auch entsprechend dem Algorithmus verfeinert).
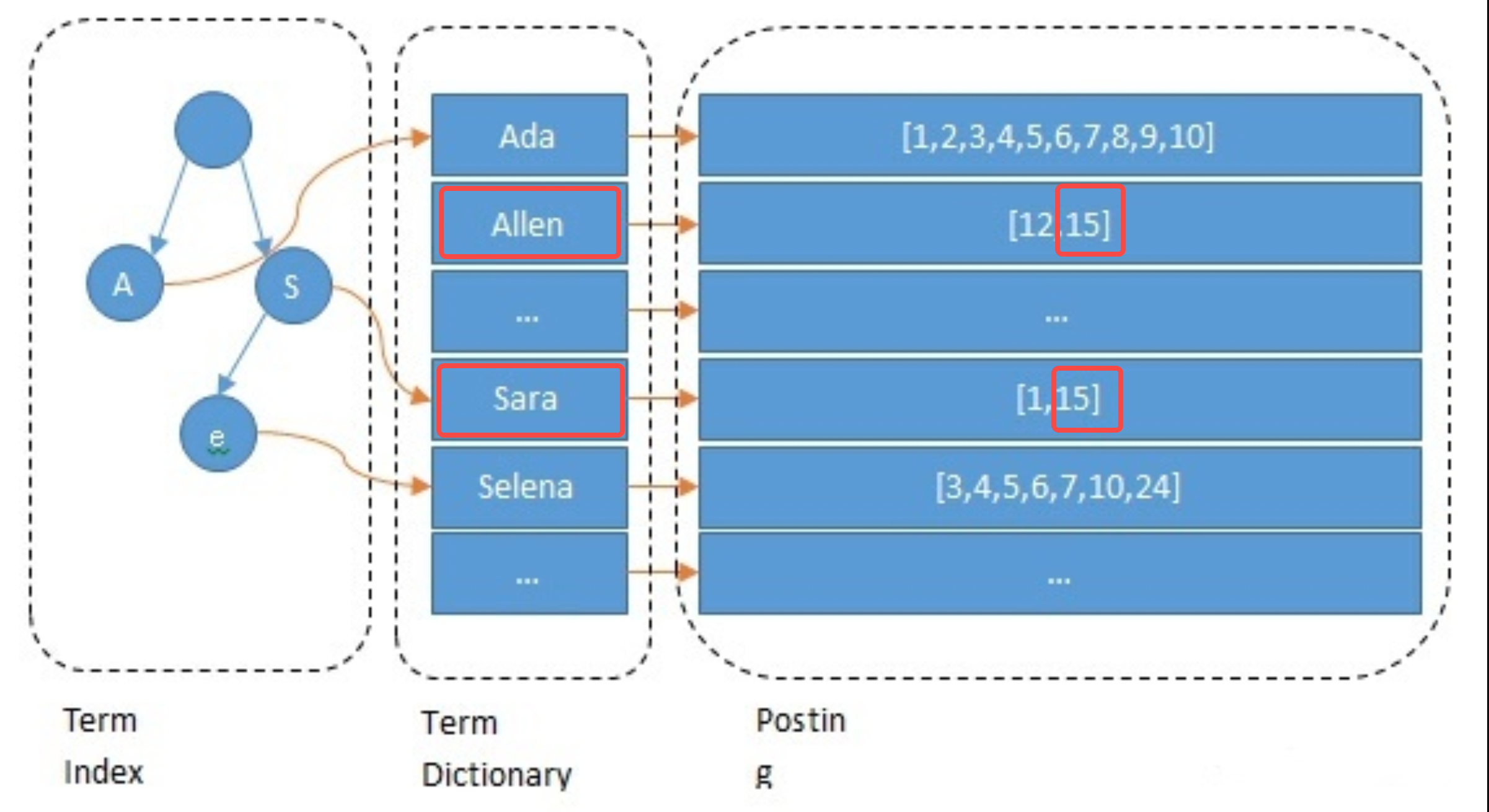
Optimierungselemente
Um den Abruf zu beschleunigen und den Speicher-/Festplattendruck zu reduzieren, führt ES die folgenden Optimierungen am invertierten Index durch, was auch der Vorteil von ES gegenüber anderen Komponenten ist. Hierbei ist zu beachten, dass die ultimative Ausnutzung des Speicherplatzes ein gemeinsames Merkmal aller Datenbanken sein kann und auf die gleiche Weise auch Speicherplatz spart: Daten werden in so wenigen Bits wie möglich gespeichert, und zwar in kleinen Mengen und in großen Mengen auf unterschiedliche Weise gespeichert.
-
Begriffsindex: Verwenden Sie Präfixbäume, um die Positionierung von „Begriffswörtern“ zu beschleunigen und das Problem der langsamen Abrufgeschwindigkeit zu lösen, die durch zu viele Wörter verursacht wird.
-
Begriffswörterbuch: Fügen Sie Wörter mit demselben Präfix in einen Datenblock ein und behalten Sie nur das Suffix bei, z. B. [hello, head] -> [lo, ad];
-
Posting: Bestellt + inkrementelle Codierung + Blockspeicher, z. B. [9, 10, 15, 32, 37] -> [9, 1, 5, 17, 5], jedes Element kann 5-Bit-Speicher verwenden;
-
Optimierung der Postzusammenführung: Verwenden Sie Roaring Bitmap, um Platz zu sparen. Wenn Sie Abfragen mit mehreren Bedingungen verwenden, müssen Sie mehrere Postings zusammenführen.
-
Semantische Verarbeitung: Inhalte mit ähnlicher Semantik können abgefragt werden.
Merkmale des invertierten Index:
-
Unterstützung der Volltextsuche: Unterstützung mehrerer Sprachen mit verschiedenen Wortsegmentierungs-Plug-Ins, z. B. dem IK-Wortsegmentierungs-Plug-In zur Implementierung der chinesischen Volltextsuche;
-
Kleine Indexgröße: Der Präfixbaum komprimiert den Speicherplatz erheblich und der Index kann im Speicher abgelegt werden, um den Abruf zu beschleunigen.
-
Schlechte Unterstützung für die Bereichssuche: eingeschränkt durch die Auswahl des Präfixbaums;
-
Anwendbare Szenarien: Suche nach Wörtern, Suche außerhalb des Bereichs. Nicht numerische ES-Felder verwenden diesen Indextyp.
B
lock
K d Baumindex
Der Block-Kd-Tree-Index eignet sich sehr gut für Bereichssuchen. Feldtypen wie ES-Werte, Geo und Bereich verwenden alle diesen Indextyp. Bei der Geschäftsauswahl sollten numerische Felder, die eine Bereichssuche erfordern, numerische Typen wie „Lang“ verwenden. Für invertierte Indizes sollten Felder, die keine Volltextsuche erfordern, den Typ „Schlüsselwort“ verwenden.
Aufgrund des begrenzten Platzes wird dieser Artikel hier nicht zu viel vorstellen. Freunde, die sich für BKd Tree interessieren, können auf den folgenden Inhalt verweisen:
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
Datenspeicher
In diesem Teil wird hauptsächlich erläutert, wie die Daten einer einzelnen Instanz im Speicher und auf der Festplatte gespeichert werden.
Segmentiertes Speichersegment
Die Daten einer einzelnen Instanz umfassen bis zu Hunderte GB und die Speicherung in einer Datei ist offensichtlich unangemessen. Wie Kafka, Pulsar und andere Komponenten, die nur Append-Daten speichern müssen, entscheidet sich ES dafür, die Daten zur Speicherung in Segmente aufzuteilen.
-
Segment: Jedes Segment verfügt über eine eigene Indexdatei und die Ergebnisse werden nach parallelen Abfragen zusammengeführt.
-
Timing der Segmentgenerierung: Geplante Generierung oder basierend auf der Dateigröße, die Dauer ist konfigurierbar, normalerweise einige Sekunden;
-
Segmentzusammenführung: Da Segmente regelmäßig generiert werden und im Allgemeinen relativ klein sind, müssen sie zu großen Segmenten zusammengeführt werden.
Latenz- und Datenverlustrisiko
-
Abrufverzögerung: Der bedingte Abruf hängt vom Index ab und der Index ist nur verfügbar, wenn das Segment generiert wird. Daher gibt es im Allgemeinen eine Verzögerung von mehreren Sekunden vom Schreiben bis zum Abruf.
-
Risiko eines Datenverlusts: Das Leeren neu generierter Segmente dauert standardmäßig mehrere zehn Minuten und es besteht das Risiko eines Datenverlusts.
-
Reduzieren Sie das Risiko eines Datenverlusts: Translog wird zusätzlich zum Aufzeichnen von Schreibereignissen verwendet. Standardmäßig wird die Festplatte alle 5 Sekunden geleert, es besteht jedoch weiterhin die Gefahr, dass mehrere Sekunden Daten verloren gehen.
So implementieren Sie Löschen/Aktualisieren
-
Löschen: Jedes Segment entspricht einer Del-Datei, in der die gelöschte ID aufgezeichnet wird. Die Suchergebnisse müssen herausgefiltert werden.
-
Update: Neue Dokumente schreiben und alte Dokumente löschen.
Cluster
Einzelmaschinendatenbanken weisen Probleme wie begrenzte Kapazität und Durchsatz sowie schwache Disaster-Recovery-Funktionen auf. Diese Probleme werden im Allgemeinen durch Sharding und Datenredundanz gelöst. Schauen wir uns zunächst an, wie ES Daten shardt und sichert, und dann, wie die folgenden drei Fragen gelöst werden können: Wie werden Lese- und Schreibanforderungen an die einzelnen Shards weitergeleitet? Wie füge ich die Suchergebnisse jedes Shards zusammen? Wie wählt man den Master zwischen aktiven und Standby-Instanzen aus?
Verteilter Splitter
Die Anzahl der Shards für jeden Index kann unabhängig konfiguriert werden. Die folgende Abbildung zeigt als Beispiel einen Index mit drei Shards. Die Gesamtspeicherkapazität wird durch die horizontale Erweiterung erhöht und die Abrufgeschwindigkeit wird durch die parallele Berechnung jedes Shards verbessert.
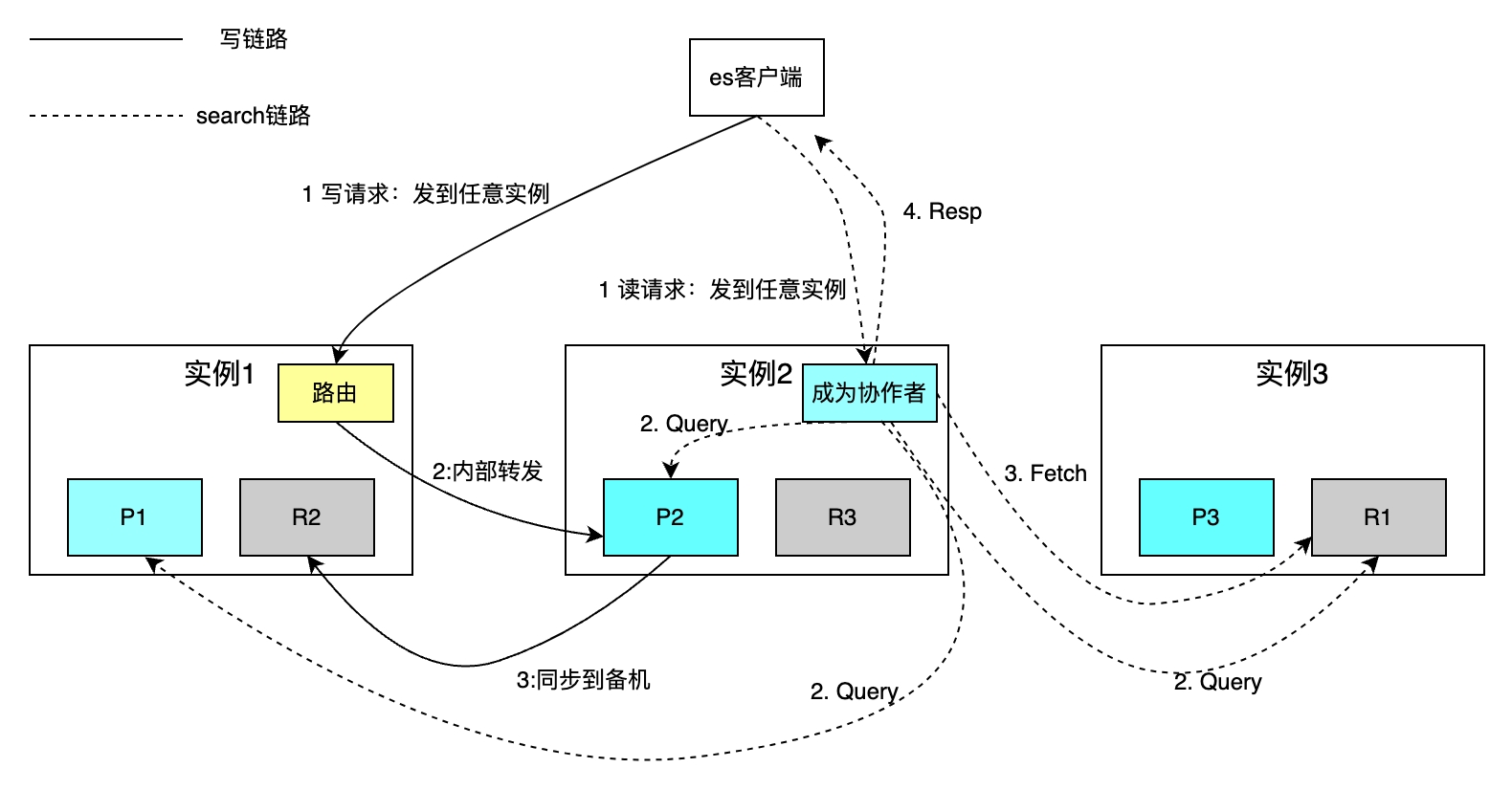
Die Routing-Richtlinie liest und schreibt ein einzelnes Dokument basierend auf dem Primärschlüssel. Beim Hash-Routing wird standardmäßig die ID als Primärschlüssel verwendet. Wenn die Geschäftspartei die Primärschlüssel-ID nicht angibt, verwendet ES den Guid-Algorithmus, um diese automatisch zu generieren. Aufgrund von Routing-Richtlinienbeschränkungen erfordert die Erhöhung oder Verringerung der Anzahl der Shards die Migration aller Daten. Auf bedingtem Abruf basierende Suchanfragen werden in zwei Schritten implementiert: den Abfragephasen der Koordinierungs- und Abfragephase des Mitarbeiters und der Erfassungsphase der Abrufphase. Der Mitarbeiter sendet eine Leseanforderung an eine beliebige Instanz, und die Instanz sendet die Anforderung parallel an jeden Shard. Jeder Shard führt lokales SQL aus und gibt 2000 + 100 Daten an den Mitarbeiter zurück, wobei alle Daten ID und UID enthalten. Der Mitarbeiter sortiert alle Shard-Daten, ruft die IDs von 100 Dokumenten ab, ruft die Daten dann nach ID ab und gibt sie an den Client zurück.
Der Nachteil besteht darin, dass die obige Abrufmethode das Sharding-Konzept vom Client abschirmt, was Lese- und Schreibvorgänge erheblich erleichtert. Es ist jedoch nicht erforderlich, sich über Unterdatenbanken und Tabellen im Klaren zu sein. Allerdings muss jede Instanz auch geöffnet werden ein Speicherplatz mit der Größe „ab+limit“ Beim Umblättern von Seiten ist viel Speicherplatz erforderlich, um Shard*-Dokumente (ab+limit) und andere Probleme zu sortieren.
Als Reaktion auf die oben genannten Probleme fügen wir in der Praxis Parameter wie uid>2200 hinzu, die sich mit jeder Anfrage zu den bedingten Elementen von „Suchen nach“ ändern, wodurch die Anzahl der Sortierungen von „von+limit“ auf „Limit“ für eine andere Form des Scrollens reduziert werden kann Suchen Sie nach, pflegen Sie die Bedingungselemente jeder Anfrage intern in ES und unterstützen Sie die Parallelität.
Einnahmen aus der Master-Slave-Synchronisation
Zu den Vorteilen zählen vor allem die hohe Verfügbarkeit durch Datenredundanz und ein erhöhter Systemdurchsatz. Die Datensynchronisierungsmethode umfasst die Master-Slave-Synchronisierung innerhalb des Clusters, die im Allgemeinen in verschiedenen Computerräumen in derselben Region bereitgestellt wird, um Schreibvorgänge zu beschleunigen. Die Konsistenz kann „Eins“, „Alle“ oder „Quorum“ sein. Darüber hinaus gibt es eine Cross-Cluster-Synchronisation (CCR), die für die Multi-Cluster-Notfallwiederherstellung und den Nahzugriff in verschiedenen Regionen verwendet wird. Sie verwendet eine asynchrone Methode und die Indexebene kann eine unidirektionale oder bidirektionale Replikation von Daten sein .
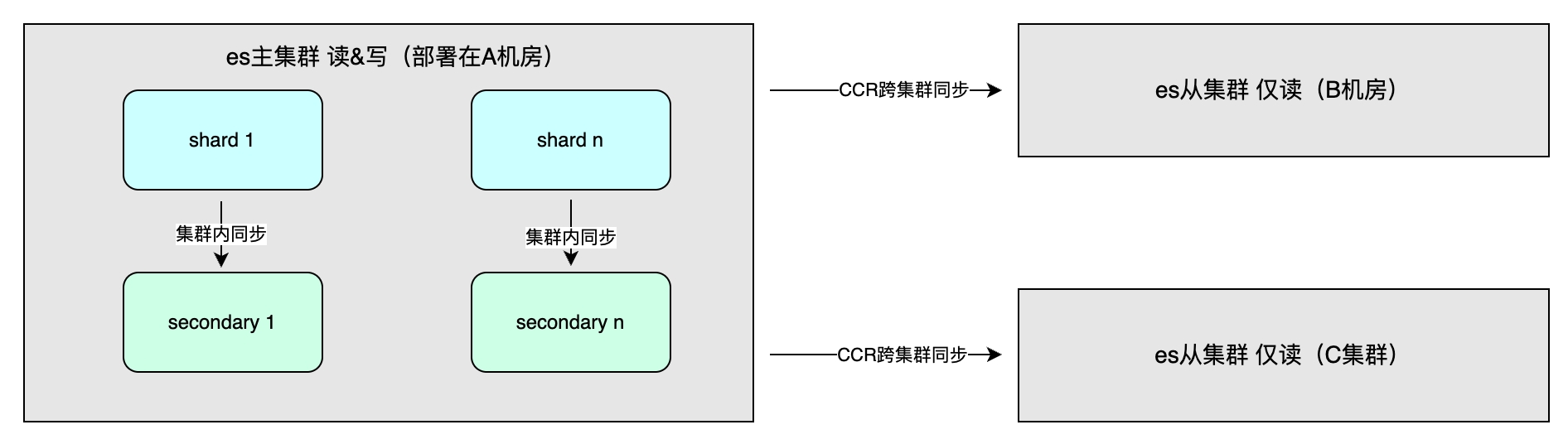
Anwendbare Szene
Die Implementierungsdetails von ES bestimmen seine Gesamteigenschaften, die sich wiederum auf anwendbare Szenarien auswirken. Zu den anwendbaren Szenarien gehören: großes Datenvolumen unterhalb der PB-Ebene, flexible Indizierung und Sortierung mehrerer Felder erforderlich; keine Anforderungen an die Abfragelatenz nach dem Schreiben; Es wird jedoch nicht empfohlen, ES als einzigen Speicher für wichtige Daten zu verwenden, da es zu einer Verzögerung von mehreren Sekunden und dem Risiko eines Datenverlusts kommt und die Hochverfügbarkeit im Gegensatz zu MySQL sorgfältig bis ins Detail optimiert ist.
Praxis eines domänenübergreifenden Datenaggregationssystems für eine Live-Übertragungsplattform
Anwendungsszenarien
Auf der Betriebsplattform für Live-Broadcast-Gilden und -Anker gibt es viele Szenarien für die Datenanzeige und -analyse, z. B. Ankerlisten, Anker- und Gildenaufgaben usw. Diese Art von Daten weist im Allgemeinen die folgenden Merkmale auf: großes Datenvolumen, viele Felder usw Aus vielen Quellen stammen beispielsweise fast 200 Indexfelder, es gibt mehr als 10 Datenquellen (z. B. Datenplattformen, Sicherheitsplattformen, Wallets usw.) und Vorgänge wie das Abrufen und Sortieren durch mehrere Felder werden unterstützt.
Wenn Benutzer Daten anzeigen, dauert es viel Zeit, Daten von jeder Geschäftspartei in Echtzeit abzurufen, und es ist schwierig, bedingte Abfragen und Sortierungen basierend auf mehreren Feldern durchzuführen, sodass die Daten vorab in einer einzigen Datenbank aggregiert werden müssen . Für Datenbanken wie MySQL und Redis ist es schwierig, die oben genannten Merkmale zu erfüllen, und ES kann sie besser unterstützen. Daher haben wir ein domänenübergreifendes Datenaggregationsdienstsystem basierend auf ES aufgebaut: Änderungen in Upstream-Datenquellen konsumieren und in die schreiben ES großer Index zur Erfüllung der Abfrageanforderungen. Nehmen Sie als Beispiel „Anchor Index“, um den Datenaggregationsmodus zu veranschaulichen:
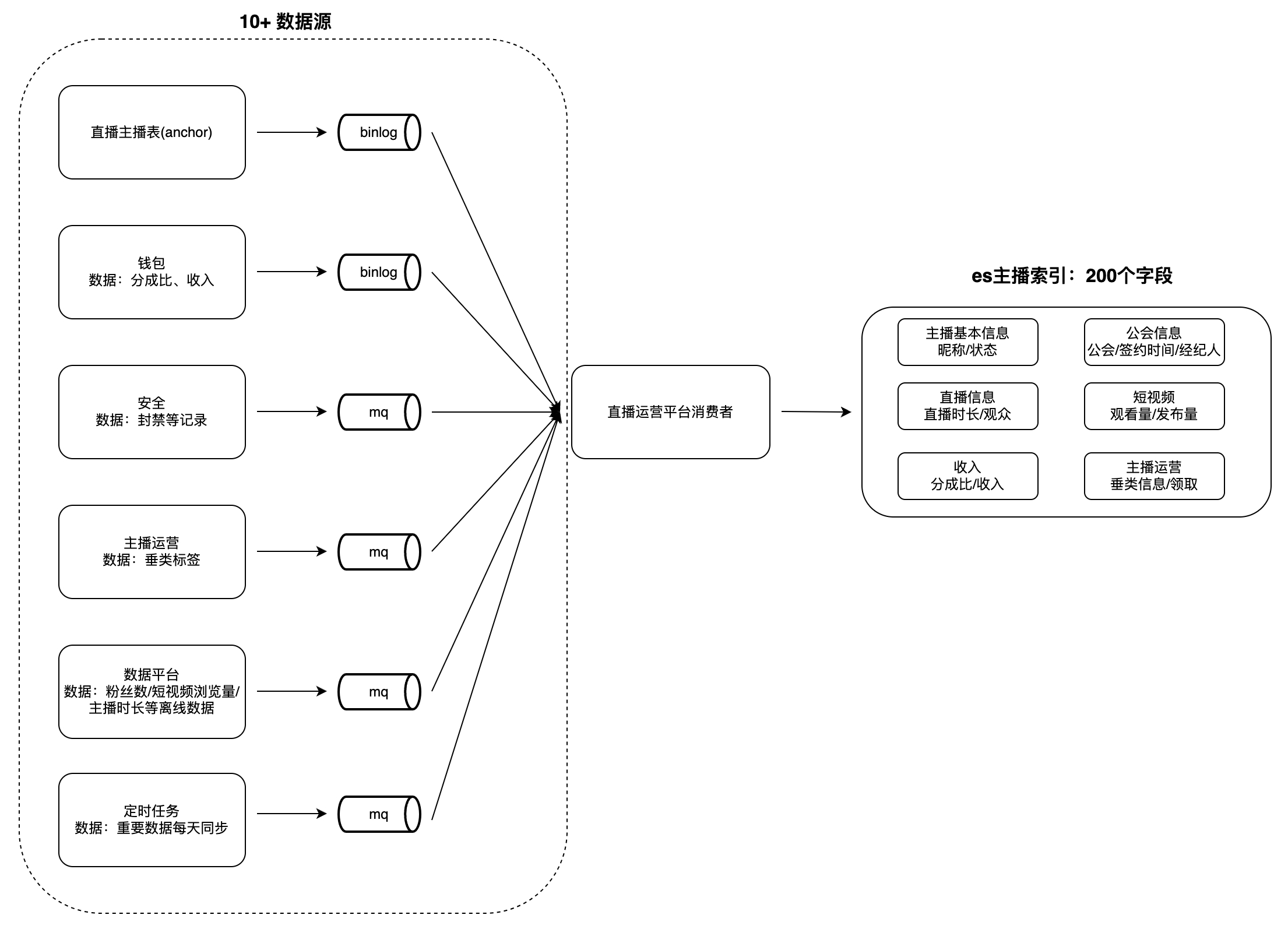
Herausforderung
Die erste Version der Implementierung verwendete einen einzelnen PSM als Verbraucher, um Upstream-Daten zu lesen und in ES zu schreiben. Da die Schreibvorgänge nicht isoliert waren, gab es viele Probleme. Erstens schreiben alle Zugriffsparteien die Datenverbrauchslogik im selben PSM, was zu einer starken Kopplung der Datenverarbeitungslogik und Schwierigkeiten bei der Wartung führt. Zweitens besteht das Risiko, dass mehrere Geschäftsparteien in dasselbe Feld schreiben, was zu geschäftlichen Ausnahmen führen kann. Darüber hinaus führt der ES-Datenschreibmodus mit vollständiger Abdeckung zu einer langsamen Datenverarbeitungsgeschwindigkeit und einer geringen MQ-Verbrauchsgeschwindigkeit. Gleichzeitig gibt es immer noch Probleme wie Ressourcenkonkurrenz und langsame Abfragen, die nicht bestimmten Upstreams zugeordnet werden können. Da alle zwei Monate etwa fünf neue Felder hinzugefügt werden und die Datenmenge weiter wächst, wird es in Zukunft größere Herausforderungen geben, wenn diese Probleme nicht angegangen werden.
Die Analyse der oben genannten Probleme kann in drei Kategorien unterteilt werden: Die Verarbeitungslogik jeder Datenquelle ist stark gekoppelt, und das Ganze wird leicht von einer einzelnen Geschäftspartei beeinflusst, was den Ressourcenwettbewerb verschärft und Schreib-Governance-Funktionen: Schreibisolation, langsame Abfragestatistiken.
Lösung
Die folgende Abbildung stellt die Gesamtstruktur nach der Governance vor. Auf dieser Grundlage analysieren wir nacheinander die Probleme und Überlegungen, die im Governance-Prozess auftreten.
Dieser Inhalt kann derzeit nicht außerhalb von Feishu-Dokumenten angezeigt werden.
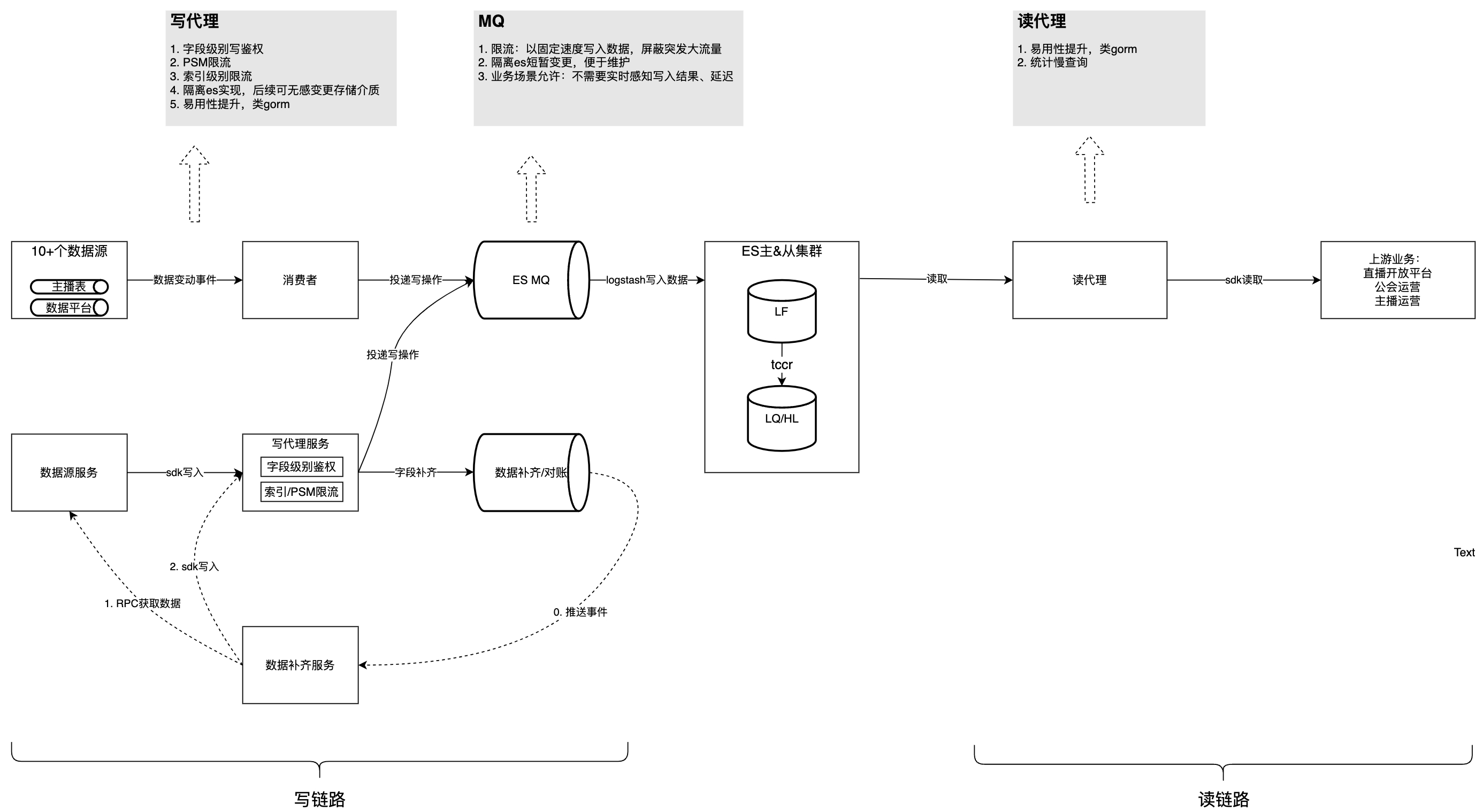
Problem 1: Die Verbrauchslogik jeder Datenquelle ist stark gekoppelt, schwer zu warten, beeinflusst sich gegenseitig und beansprucht Ressourcen.
Die spezifische Manifestation dieses Problems besteht darin, dass mehr als 10 MQ-Datenverbrauchslogiken im selben PSM implementiert sind. Die gemeinsame Datenverarbeitungslogik und geringfügige Änderungen können sich auf andere MQ-Verarbeitungen auswirken, was die Überwachung mehrerer MQ-Ereignisse durch den Dienst erschwert Ressourcenkonkurrenz und ungleichmäßige Verteilung der Partitionen eines einzelnen MQ-Ereignisses führen zu einer ungleichmäßigen Ressourcennutzung auf einer einzelnen Maschine, die nicht durch horizontale Erweiterung der Maschine gelöst werden kann. Daher wirkt sich die Codeinstabilität eines einzelnen MQ auf den Verbrauch aller MQ-Themen aus. Die ungleichmäßige Verteilung der Partitionen einzelner MQ-Themen führt zu einem sprunghaften Anstieg der CPU einzelner Verbraucherinstanzen und wirkt sich somit auf den Verbrauch anderer Themen aus.
Optimierungsstrategie:
-
Verbessern Sie die Verbrauchsgeschwindigkeit eines einzelnen Ereignisses: Überprüfen Sie die aktuelle Grenzkonfiguration aller Themen.
-
Erstellen Sie mehr Methoden zum Schreiben von Daten und verteilen Sie das Schreiben von Nicht-Kernfeldern auf verschiedene Geschäftsseiten. Es stellt beispielsweise das Schreiben eines SDK bereit und führt Dsyncer ein.
Problem 2:
Der MQ-
Datenverbrauch ist langsam und die Aktualisierung von Geschäftsdaten verzögert sich
Die Verarbeitung einer einzelnen MQ-Nachricht ist zeitaufwändig. Wenn Sie beispielsweise den ES-Datenschreibmodus mit vollständiger Abdeckung verwenden, müssen zum Aktualisieren eines Felds die verbleibenden Felder, die nicht aktualisiert werden müssen, zusammen geschrieben werden, da fast 200 Felddaten abgerufen werden müssen in Echtzeit über RPC. Insgesamt dauert es lange und die MQ-Verbrauchsgeschwindigkeit ist langsam; Die Hauptauswirkung besteht darin, dass die Datenaktualisierungsverzögerung hoch ist und es eine Weile dauert, bis Benutzerinformationen nach Änderungen auf nachgelagerten Plattformen angezeigt werden. Und für jede Aktualisierung müssen fast 200 Felder von mehreren Geschäftsparteien abgerufen werden. Anomalien in einer einzelnen Datenquelle führen dazu, dass der gesamte MQ-Ereignisverbrauch fehlschlägt und erneut versucht wird.
Optimierungsstrategie:
-
Ändern Sie den Datenschreibmodus des ES-Clusters von vollständiger Abdeckung auf teilweise Aktualisierung: Ein einzelnes Feld kann bei Bedarf aktualisiert werden, und der Verbraucher muss nicht mehr fast 200 Felder von mehreren Geschäftsparteien erhalten, was nicht nur die Datenverarbeitungszeit verkürzt, sondern auch reduziert auch die Wartungsschwierigkeiten des Codes;
-
Konfigurieren Sie alle MQ-Themen so, dass sie mehrere Worker haben, und diejenigen, die eine sequentielle Nutzung erfordern, werden so konfiguriert, dass sie basierend auf der Primärschlüssel-ID an denselben Worker weitergeleitet werden.
Problem 3: Das Schreiben ist nicht isoliert/authentifiziert/begrenzt
Beim Feldschreiben mangelt es an Isolierung und Authentifizierung, und es besteht die Gefahr, dass mehrere Geschäftsparteien in dasselbe Feld schreiben, was zu Geschäftsanomalien führen kann. Der Hauptgrund besteht darin, dass die Schreibparteien Ressourcen gemeinsam nutzen. Wenn eine Partei zu schnell schreibt, werden die Ressourcen der anderen Parteien beansprucht, was zu einer Erhöhung der Schreibverzögerung führt. Daher ist es notwendig, die Kernfeldaktualisierungen des ES-Speichers streng zu kontrollieren, um zu vermeiden, dass es zu einer großen Menge an Rückmeldungen von Benutzern kommt.
Optimierungsstrategie:
-
Schreibauthentifizierung auf Feldebene hinzugefügt, sodass nur autorisierte PSMs bestimmte Felddaten schreiben können;
-
Um Verkehrsbegrenzungsstrategien in den beiden Dimensionen PSM und Index durchzuführen, werden dynamisch konfigurierbare Komponenten auf der allgemeinen Verkehrsmanagementplattform verwendet.
Problem 4: Mangel an langsamen Abfragestatistiken und Optimierungsmethoden
Wie MySQL und andere Datenbanken führt nicht standardmäßiges SQL zu unnötigen Scans und großen Abfrageverzögerungen. ES bietet die Möglichkeit, zeitaufwändiges SQL abzufragen, kann jedoch Upstream-PSM, Logid und andere Informationen nicht korrelieren, was die Fehlerbehebung erschwert.
Optimierungsstrategie: Der Leseagent zeichnet SQL-, Upstream-PSM-, Logid- und andere Nachrichten auf, die den Schwellenwert überschreiten, in Form einer Zwischenschicht an den ES und meldet täglich langsame Abfragebedingungen.
Frage 5: Benutzerfreundlichkeit
Optimierungsstrategie:
-
Aktivieren Sie das ES SQL-Plugin im ES-Cluster. Da sich die ES SQL-Syntax geringfügig von MySQL SQL unterscheidet, wird zusätzliche Unterstützung durch den Leseagentendienst bereitgestellt: Die Benutzerseite verwendet die MySQL-Syntax und der Leseagent verwendet reguläre Ausdrücke zum Umschreiben SQL zu ES SQL-Standards; ScrollID in ES SQL einfügen, der Benutzer muss sich nicht darum kümmern, wie die Scroll-Abfrage in SQL ausgedrückt wird;
-
Helfen Sie Benutzern, Abfragedaten in Strukturen zu deserialisieren.
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
Governance-Ergebnisse
Durch die oben genannte Governance wurde die Anhäufung von Schreibverbindungen vollständig eliminiert und die Verbrauchskapazität um 150 % erhöht, was sich insbesondere in der Erhöhung der QPS des Unternehmens von 4.000 auf 10.000 widerspiegelt, ohne die Obergrenze der Systemleistung zu erreichen. Der Spitzenwert von QPS liegt bei 1500 und der SLA liegt langfristig stabil bei 99,99 %. Derzeit verwenden mehrere Geschäftsparteien das SDK und die Geschäftsparteien berichteten, dass die Zugriffszeit von ursprünglich 2 Tagen auf 0,5 Tage verkürzt wurde.
Folgeplanung
Die Folgeplanung umfasst hauptsächlich die Erweiterung der MVP-Abstimmungsfunktionen von einzelnen Szenarien auf alle Szenarien; die Förderung der vorgelagerten Geschäftsoptimierung von SQL basierend auf langsamen Abfragestatistiken und die Bereitstellung weiterer Methoden zum Schreiben von Daten;
Basierend auf der internen, groß angelegten Best-Practice-Erfahrung von ByteDance bietet Volcano Engine extern konsistente
ES-
Produkte
–
Cloud-Suchdienst
-Cloud-Produkte auf Unternehmensebene. Der Cloud-Suchdienst ist mit Elasticsearch, Kibana und anderen häufig verwendeten Open-Source-Plug-Ins kompatibel. Er bietet den Abruf mehrerer Bedingungen, Statistiken und Berichte für strukturierten und unstrukturierten Text. Er ermöglicht die Bereitstellung mit einem Klick und eine elastische Skalierung. Vereinfachter Betrieb und Wartung sowie schnelle Erstellung von Protokollanalysen, Informationsabruf und -analyse sowie anderen Geschäftsfunktionen.
{{o.name}}
{{m.name}}