Der Aufbau und die Pflege einer Suchmaschine auf Milliardenebene ist nicht einfach, und es gibt keine ein für alle Mal optimale Verwaltungsmethode. Dieser Artikel ist das Ergebnis kontinuierlichen Lernens und einer Zusammenfassung in der Praxis. Er stellt vor, wie man ein Suchsystem aufbaut, das Produkte im Bereich von mehreren zehn Millionen bis zu Hunderten von Millionen unterstützt und die Steigerung der gesamten Abfrage-QPS von Hunderten auf Tausende realisiert der Gesamt-QPS Der Prozess der Erhöhung von Level 100 auf Level 10.000. Unter diesen ist die Erweiterung der ES-Ressourcen von wesentlicher Bedeutung. Darüber hinaus konzentriert sich dieser Artikel jedoch auch auf einige ES-Leistungsprobleme, die durch Erweiterung nicht gelöst werden können. Ich hoffe, dass Sie durch diesen Artikel mehr Daten und Nutzungsreferenzen für ES-Nutzungsszenarien erhalten. Aus Platzgründen wird der Teil zur Stabilitätsgovernance im nächsten Artikel vorgestellt.
Geschäftseinführung
Das Plattform-Investitionsmanagementsystem dient dem Multi-Entity-Investitionsszenario der Douyin-E-Commerce-Plattformaktivitäten. Es sammelt und wählt Produkte über die Investmentplattform aus und verteilt die Produkte dann an verschiedene C-seitige Systeme. Auch die Unternehmen, die Investitionen anziehen, sind sehr vielfältig, darunter Live-Übertragungsräume, Produktinvestitionen, Couponinvestitionen usw. Unter ihnen ist Produktinvestition unsere größte Investitionseinheit.
Servicestruktur der Investmentplattform
Rechenzentrum
Das Rechenzentrum ist ein ES-basierter Suchdienst, der konfigurierbare, skalierbare und universelle Datenerfassungs- und Orchestrierungsdienste bereitstellt. Es handelt sich um einen universellen Dienst, der die Datenabfrage auf der Investitionsplattform unterstützt.
Wichtige Konzepte zum Verständnis:
-
Indikatoren
: Indikatoren sind Metadaten, die wir verwenden, um ein Attribut einer Entität oder eines Objekts zu beschreiben, z. B. Produktname, Store Experience Score, Expertenebene, Registrierungsdatensatz-ID. Gleichzeitig kann es sich auch um die Mindestaktualisierung und den Erwerb eines handeln Objekt. Einheit, z. B. Produktpreisvergleichsinformationen. Wir können alle Felder mit klarer Semantik als Indikatoren definieren
.
-
Satz
: Stellt einen Satz dar, der durch eine gewisse Gemeinsamkeit konvergiert werden kann, z. B. einen Produktattributsatz und einen Filialattributsatz, die über die Produkt-ID bzw. die Filial-ID abgerufen werden können. Es kann sich auch um eine Sammlung von Produktregistrierungsdatensätzen handeln, die über abgerufen werden können Registrierungsdatensatz-ID. In geschäftlicher Hinsicht drückt es eine Reihe verwandter Indikatoren aus, und die Indikatoren stehen in einer Eins-zu-Viele-Beziehung.
-
Lösung
: Datenerfassungslösung Wir abstrahieren die beiden Konzepte von Indikatoren und Sammlungen, sodass Daten in der kleinsten Einheit erfasst und kontinuierlich horizontal erweitert werden können. Lösung hilft uns zu abstrahieren, wie Indikatoren unter verschiedenen Sammlungen erhalten werden.
-
Benutzerdefinierter Header
: Der benutzerdefinierte Header bezieht sich auf den Titel, der in jeder zweidimensionalen Zeilendatenliste angezeigt werden soll. Er steht in einer Eins-zu-viele-Beziehung mit dem Indikator.
-
Filterelement
: Das Filterelement bezieht sich auf das Filterelement, das in jeder zweidimensionalen Zeilendatenliste verwendet werden muss. Es kann eine 1-zu-1-Beziehung angeben.
-
Audit-Ansicht
: Die Audit-Ansicht bezieht sich auf eine Audit-Seite, die dynamisch aus einer Reihe benutzerdefinierter Header und einer Reihe von Filterelementen in einem Audit-Geschäftsszenario gerendert werden kann.
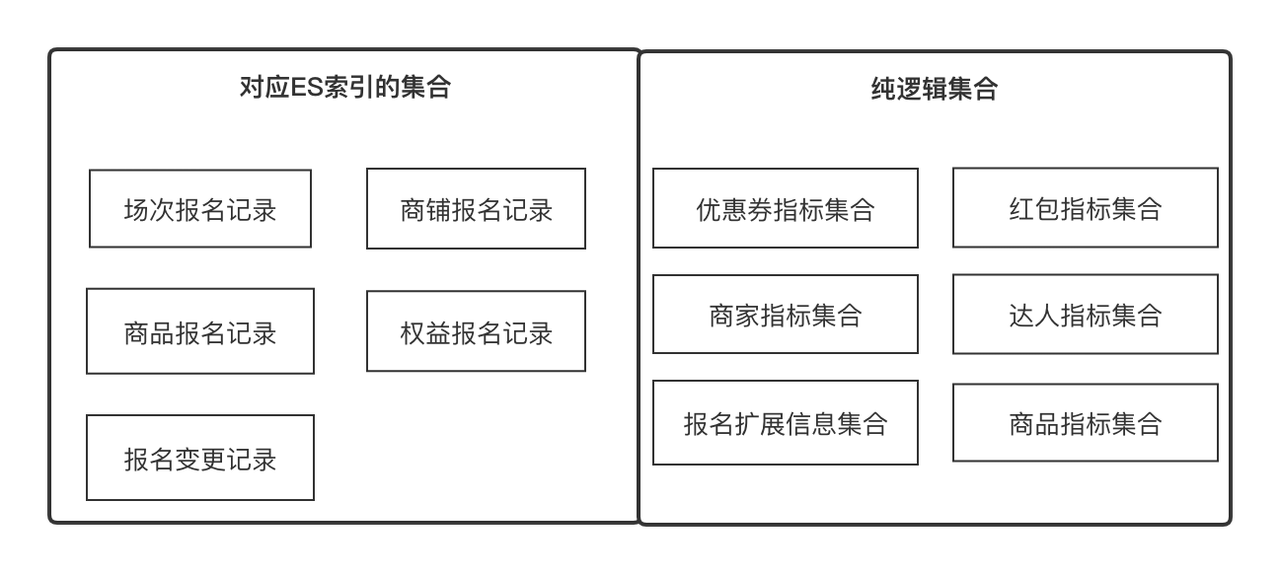
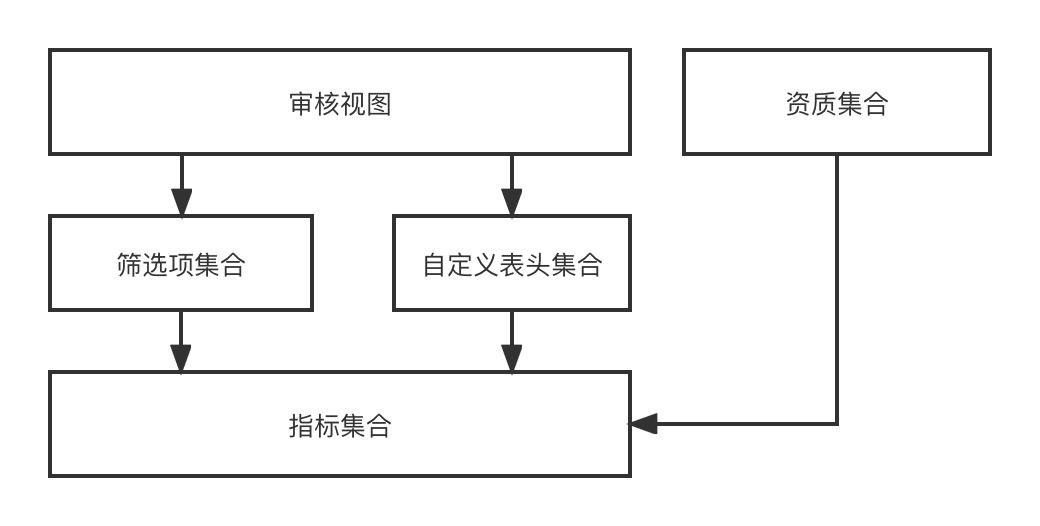
Im funktionalen Design über den Indikator -> [Elemente filtern, benutzerdefinierter Header] -> Audit-Ansicht -> der Prozess des endgültigen dynamischen Renderns einer Audit-Seite Da wir Investitionen mit mehreren Entitäten und mehreren Szenarien rekrutieren, verschiedene Entitäten Es sind unterschiedliche Szenarien erforderlich, sodass diese Reihe von Funktionen, die wir entwickelt haben, alle erforderlichen Audit-Ansichtseffekte dynamisch kombinieren kann.
Das Rechenzentrum bietet allgemeine Datenerfassungsfunktionen für übergeordnete Unternehmen, einschließlich Datensynchronisierung und Datenabfrage. Derzeit gibt es zwei Datenquellen, die externe RPC-Schnittstelle und den Registrierungsdatensatz ES. Das Rechenzentrum integriert zwei Sätze von Datenerfassungslösungen, die die Außenwelt überhaupt nicht kennen, das heißt, es muss nur welche Datenindikatoren unter welchen abrufen Sammlung.
Der Zweck der Erstellung von ES besteht darin, die Überprüfungs- und Statistikfunktionen von Investitionsregistrierungsdatensätzen zu unterstützen und den gewünschten Dateninhalt für das übergeordnete Unternehmen auszugeben.
Erstellen Sie einen ES-Cluster von 0 bis 1
Um ein System von 0 auf 1 aufzubauen, das auf der Erfüllung grundlegender Geschäftsanforderungen basiert, muss die Stabilität die folgenden zwei Punkte unterstützen;
-
Der grundlegende Disaster-Recovery-Mechanismus bedeutet, dass sich das Unternehmen rechtzeitig anpassen kann, wenn die Leistung des Systems aufgrund von Änderungen an Basiskomponenten und Lese- und Schreibverkehr beeinträchtigt wird.
-
Die endgültige Datenkonsistenz bedeutet, dass der Registrierungsdatensatz DB -> ES-Mehrmaschinenraumdaten vollständig ist.
Programmforschung
Bewertung der ES-Clusterkapazität
Die ES-Clusterkapazitätsbewertung soll sicherstellen, dass der Cluster für einen bestimmten Zeitraum nach seiner Erstellung stabile Dienste bereitstellen kann. Dabei müssen vor allem die folgenden Probleme gelöst werden:
-
Wie viele Shards sollten für jeden Index festgelegt werden, wie viel nachfolgendes Datenwachstum wird erwartet und Schätzungen zum Lese- und Schreibverkehr;
-
Wie viele Dateninstanzen sollten in einem einzelnen Cluster eingerichtet werden und welche Spezifikationen sollten für eine einzelne Dateninstanz verwendet werden;
-
Verstehen Sie den Unterschied zwischen vertikaler und horizontaler Expansion, wie lautet unsere Reaktionsstrategie, wenn das Datenvolumen oder der Datenverkehr unerwartet ansteigt, und wie sollte die ES-Cluster-Notfallwiederherstellung gestaltet werden?
Schlüssellösungen:
-
Sobald die Anzahl der ES-Index-Shards festgelegt ist, kann sie nicht mehr geändert werden. Daher ist es wichtig, die Anzahl der Shards zu bestimmen. Normalerweise ist die Anzahl der Shards ein ganzzahliges Vielfaches der ES-Instanz, um den Lastausgleich sicherzustellen.
-
Die Größe eines einzelnen Shards liegt zwischen 10 und 30 GB. Eine übermäßige Indizierung beeinträchtigt die Abfrageleistung.
-
Der Anstieg des Datenverkehrs kann durch Kapazitätserweiterung behoben werden, und der Anstieg der Daten kann durch Löschen alter Daten oder Erhöhen der Anzahl der Shards behoben werden. Außerdem muss ein Disaster-Recovery-Bereitstellungsplan für mehrere Maschinenräume verwendet werden, damit sich jeder gegenseitig unterstützt ist ein katastrophentoleranter Maschinenraum.
Auswahl der Datensynchronisierungsverbindung
Es wird hauptsächlich gelöst, wie DB-Registrierungsdatensätze mit ES synchronisiert werden, wie andere verwandte Indikatoren in ES geschrieben werden und wie die Datenkonsistenz aktualisiert und sichergestellt wird.
-
DB -> ES muss ein Quasi-Echtzeit-Datenstrom sein, und Änderungen in Registrierungsdatensätzen und anderen Informationen müssen in Quasi-Echtzeit durchsuchbar sein;
-
Zusätzlich zu seinen eigenen Feldern muss der Registrierungsdatensatz auch seine Attributfelder wie registrierte Produkte, Geschäfte und Experten ergänzen. Er wird auch in ES geschrieben und
kann Teilaktualisierungen unterstützen
, sodass die ES-Schreibmethode nur die Upsert-Methode sein kann ;
-
Aktualisierungen einzelner Registrierungsdatensätze müssen in Ordnung sein und dürfen nicht in Konflikt geraten.
Umfrage zur Grundkonfiguration des ES-Index
Verstehen Sie die wesentlichen ES-Grundlagen und -Konfigurationen.
-
{"dynamic": false} vermeidet die automatische Erweiterung von ES-Zuordnungen oder das Hinzufügen unerwarteter Indextypen;
-
index.translog.durability=async, die asynchrone Aktualisierung des Translogs trägt zur Verbesserung der Schreibleistung bei, es besteht jedoch die Gefahr eines Datenverlusts;
-
Das Standard-Aktualisierungsintervall von ES beträgt 1 Sekunde, was bedeutet, dass die Daten bereits eine Sekunde nach erfolgreichem Schreiben gefunden werden können.
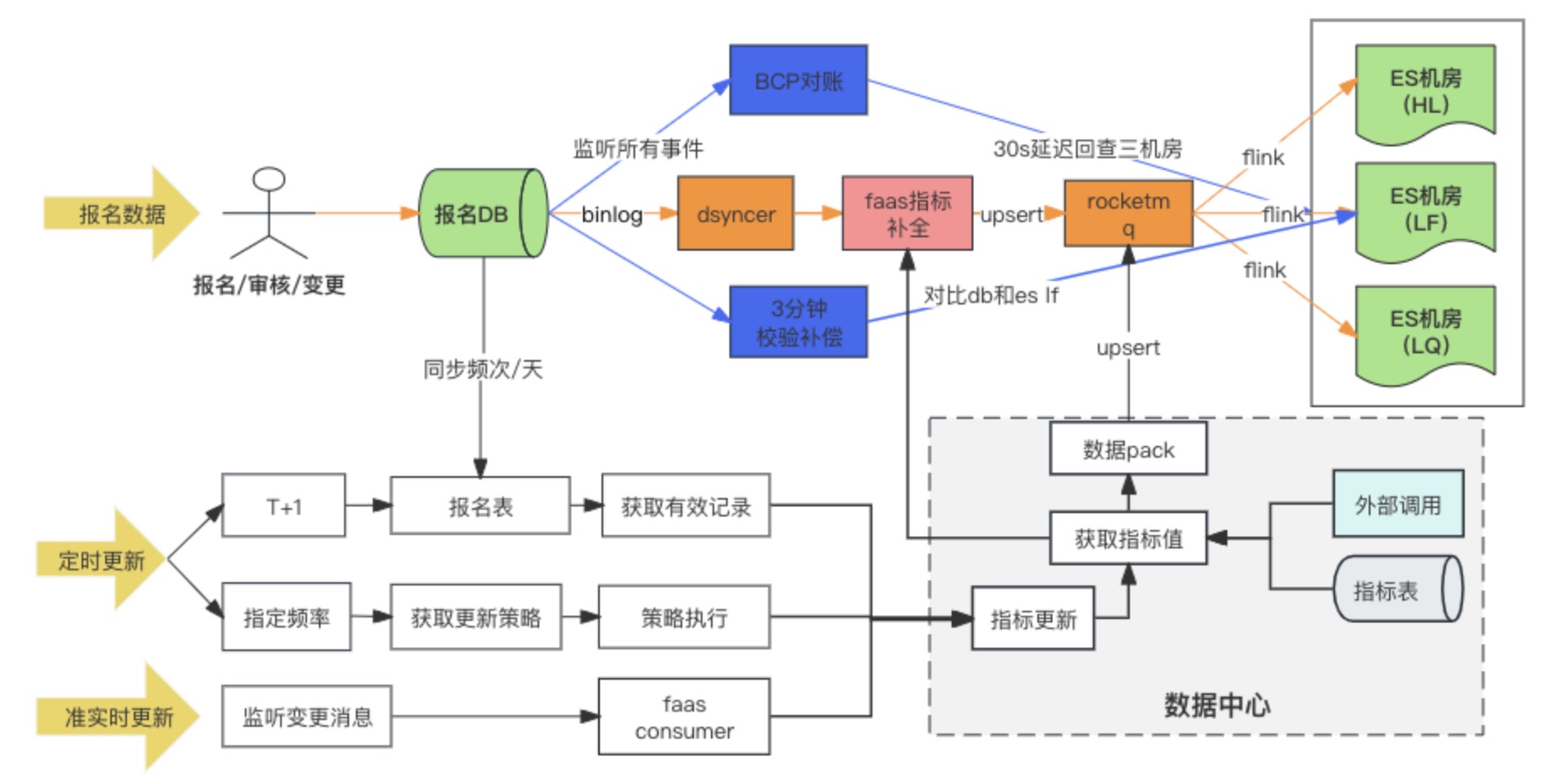
Datensynchronisierungslösung
Diagramm der Datensynchronisationsverbindung
Die Datensynchronisierungslösung DB -> ES übernimmt letztendlich die Methode des synchronen Schreibens heterogener Daten in RocketMQ + Flink für den Mehrmaschinenraumverbrauch. Gleichzeitig werden die erweiterten Indikatoren gefüllt, wenn der Registrierungsdatensatz zum ersten Mal geschrieben wird in durch das benutzerdefinierte Konvertierungsskript von Faas, und die Aktualisierungsabhängigkeiten der erweiterten Indikatoren sind Ändern Sie die beiden Methoden des Abhörens von Nachrichten und geplanter Aufgaben. Bei der Recherche gab es tatsächlich drei Optionen für DB -> ES-Multicomputerraum. Am Ende haben wir uns für die dritte Option entschieden. Hier vergleichen wir die Unterschiede zwischen den drei Optionen.
Lösung 1: Durch heterogene Datensynchronisation (Dsyncer) direkt in den ES-Raum mit mehreren Maschinen schreiben
Mangel:
-
Direktes Schreiben ist bei der Erfüllung der ES-Anforderungen zur gleichzeitigen Bereitstellung mehrerer Computerräume von Nachteil, da es kein erfolgreiches Schreiben in mehreren Computerräumen gleichzeitig garantieren kann. Ist es in Ordnung, mehrere heterogene Daten bereitzustellen und diese separat zu schreiben? Ja, das heißt, der Arbeitsaufwand verdreifacht sich auf etwa ein Dutzend Indizes.
-
Die Schreibfähigkeit von Direct Write Bulk ist relativ schwach, und die Schreibspitzen werden deutlicher, wenn der Datenverkehr schwankt, was sich nicht positiv auf die Schreibleistung von ES auswirkt.
-
Direktes Schreiben kann die ordnungsgemäße Aktualisierung eines einzelnen Registrierungsdatensatzes nicht garantieren, wenn ES über mehrere Aktualisierungseinträge verfügt. Kann ich die globale Version erhöhen? Ja, aber zu schwer.
Vorteile:
Kürzester Abhängigkeitspfad, geringe Schreiblatenz und minimales Systemrisiko. Für Unternehmen mit geringem Datenverkehr und Unternehmen mit einfachen Synchronisierungsszenarien ist dies absolut kein Problem.
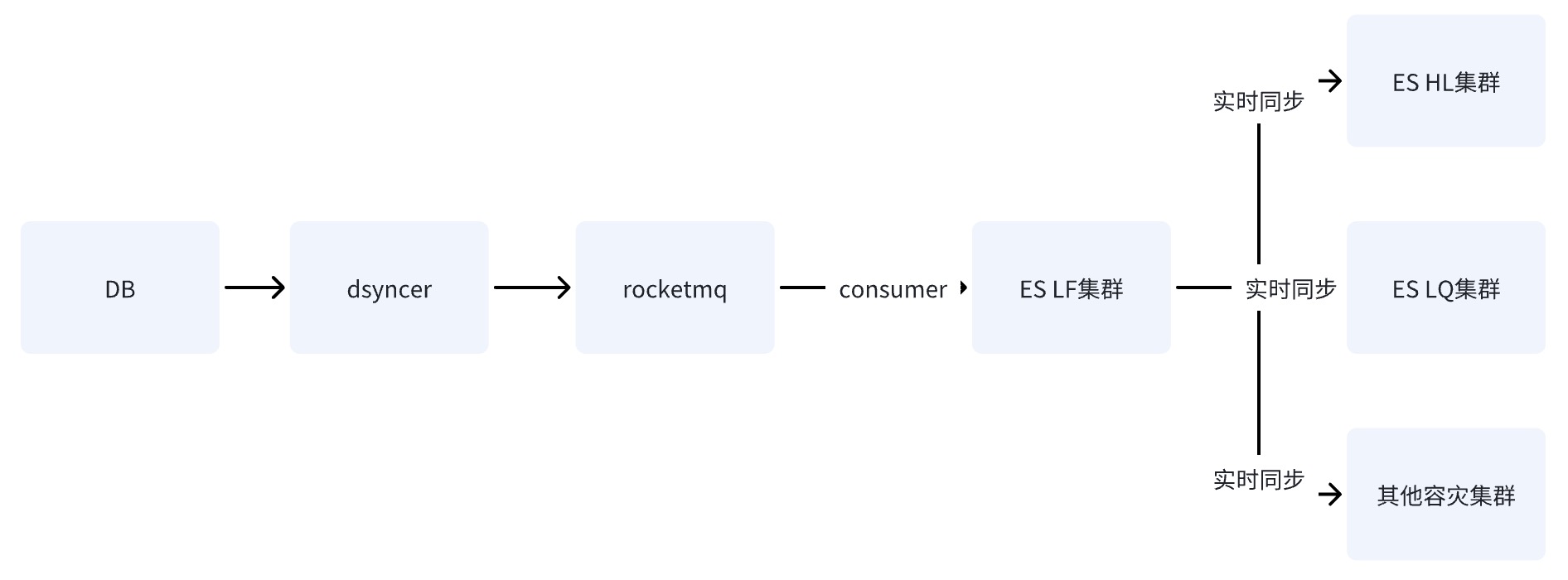
Option 2: Schreiben Sie einen einzelnen ES-Computerraum über RocketMQ
Nachdem DB über RocketMQ in den ES-Einzelcomputerraum geschrieben hat, werden die Daten über die von ES bereitgestellte Cluster-übergreifende Datenreplikationsfunktion mit anderen Computerräumen synchronisiert.
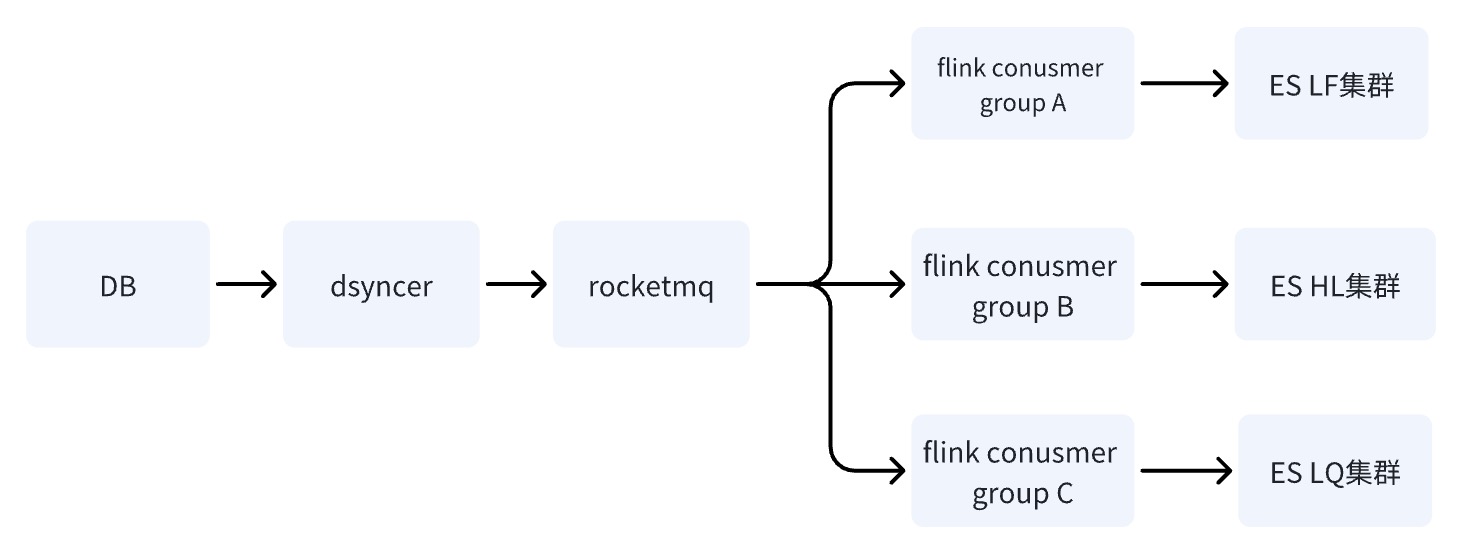
Option 3: Schreiben Sie den ES -Raum mit mehreren Maschinen über RocketMQ + Flink ✅
Wenn DB über RocketMQ in den ES-Cluster schreibt, werden mehrere unabhängige Verbrauchergruppenaufgaben gestartet. Das System kann das verteilte Flink-System verwenden, um Daten in mehrere Computerräume zu schreiben.
Es gibt nur einen Unterschied zwischen Schema zwei und Schema drei: Die Art und Weise, in mehrere Computerräume zu schreiben, besteht darin, in einen Computerraum zu schreiben und die Daten dann in Quasi-Echtzeit mit anderen Computerräumen zu synchronisieren Drei besteht darin, mehrere unabhängige Verbraucher in den Maschinenraum zu schreiben.
Die Nachteile der Optionen zwei und drei sind die gleichen: Der Abhängigkeitspfad ist am längsten und die Schreibverzögerung wird leicht durch den Jitter der Basiskomponenten beeinflusst. Der fatale Nachteil von Option zwei besteht jedoch darin, dass es einen
einzigen Risikopunkt
gibt Unter der Annahme, dass die Daten über LF mit HL und LQ synchronisiert werden, wird das System nach dem Auflegen von LF unbrauchbar .
Der Vorteil von Option drei besteht darin, dass die Schreibverbindungen mehrerer Computerräume unabhängig voneinander sind. Wenn bei einer Verbindung Probleme auftreten, kann RocketMQ das Problem der sequentiellen Aktualisierung einzelner Schlüssel nicht leicht lösen ,
was aus Option eins ebenfalls unerwünscht ist
.
Warum kann das Schreiben über RocketMQ das Problem von Unordnung und Konflikten lösen?
-
Erstens wird das ES-Schreiben durch optimistisches Sperren basierend auf der Versionsnummer gesteuert. Wenn derselbe Datensatz gleichzeitig zur gleichen Zeit aktualisiert wird, ist die Version, die wir gleichzeitig erhalten, dieselbe, vorausgesetzt, sie ist 1, dann wird dies für alle der Fall sein Aktualisieren Sie die Version auf 2, um zu schreiben. Es treten Konflikte auf, und Konflikte verursachen immer das Problem verlorener Updates.
-
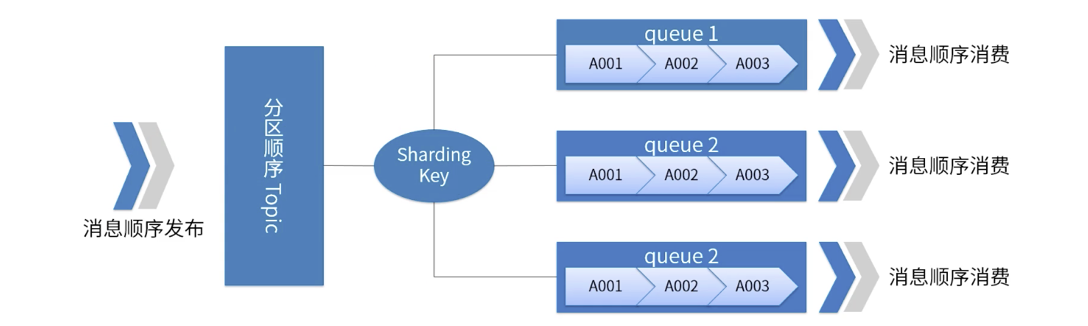
Allgemeine Geschäftsszenarien erfordern einen geordneten Verbrauch basierend auf der Reihenfolge von Schlüsseln und Partitionen. Der geordnete Verbrauch erfordert zwei notwendige Bedingungen: Wenn Nachrichten gespeichert werden, müssen sie mit der Reihenfolge übereinstimmen, in der sie gesendet werden in dem sie gespeichert sind.
Wenn das Unternehmen Nachrichten ordnungsgemäß konsumieren möchte, muss es daher sicherstellen, dass die mit demselben Schlüssel gesendeten Nachrichten an dieselbe Partition gesendet werden, und die konsumierten Nachrichten stellen sicher, dass die Nachrichten mit demselben Schlüssel immer von konsumiert werden gleicher Verbraucher. Tatsächlich sind die beiden oben genannten notwendigen Bedingungen jedoch nicht vollständig garantiert, z. B. wenn das Schreiben einer bestimmten Broker-Instanz immer wieder fehlschlägt.
Ein Bild veranschaulicht die Partitionsreihenfolge von RocketMQ
-
Für ein bestimmtes Thema werden alle Nachrichten entsprechend dem Sharding-Schlüssel in mehrere (Warteschlangen) unterteilt.
-
Nachrichten in derselben Warteschlange werden in strenger FIFO-Reihenfolge veröffentlicht und verarbeitet.
-
Der Sharding-Schlüssel ist ein Schlüsselfeld, das zur Unterscheidung verschiedener Partitionen in aufeinanderfolgenden Nachrichten verwendet wird. Es handelt sich um ein völlig anderes Konzept als der Schlüssel gewöhnlicher Nachrichten.
-
Anwendbare Szenarien: Hohe Leistungsanforderungen. Bestimmen Sie anhand des Sharding-Schlüssels in der Nachricht, an welche Warteschlange die Nachricht gesendet wird. Im Allgemeinen kann eine ordnungsgemäße Partitionierung unsere Geschäftsanforderungen erfüllen.
Hier ist zu beachten,
dass
RocketMQ dem Unternehmen möglicherweise bei der Lösung von 99 % der Out-of-Order-Probleme geholfen hat, dies jedoch nicht bei 100 % der Fall ist B. das ABA-Phänomen, beispielsweise wenn Partiton ausfällt, wird die Nachricht wiederholt an andere Partitionswarteschlangen usw. gesendet, sodass ein Konsistenzabgleich unerlässlich ist.
Mehrschichtiger Abstimmungsmechanismus
Der Abstimmungsmechanismus löst das Datenkonsistenzproblem von DB->ES. Wie bereits erwähnt, handelt es sich bei DB->ES um einen Quasi-Echtzeit-Datenfluss, und die Abhängigkeitsverbindung ist relativ lang. Abstimmungs- und Vergütungsstrategien, um letztendlich die Datenkonsistenz sicherzustellen.
Hier haben wir eine dreistufige Abstimmung durchgeführt. Wir nutzen die Abstimmungsplattform, um eine Abstimmung auf Minutenebene und eine Offline-Abstimmung zu erreichen. Die Gründe für die Notwendigkeit einer mehrstufigen Abstimmung werden im Folgenden einzeln erläutert.
Diagramm zur DB-Synchronisierung von ES-Verbindungsfehlern
Abgleich der zweiten Ebene der Business Verification Platform ( BCP ).
Anhand der obigen Abbildung werden Sie feststellen, dass die DB->ES-Synchronisierung von vielen abhängigen Komponenten abhängt. In diesem Fall benötigen wir eine
Abstimmung aus globaler Sicht,
um Synchronisationsverbindungsprobleme zu erkennen, d. h. eine BCP-Echtzeitabstimmung.
Bei der BCP-Abstimmung handelt es sich um eine Single-Stream-Abstimmung, die den ES-Abgleich mit mehreren Maschinen direkt überprüft. Verzögerungen oder Blockaden bei der Datensynchronisierung in den Zwischenverbindungen können durch sorgfältige BCP-Abstimmung schnell erkannt werden Wenn Binlog abgeschnitten ist und die BCP-Abstimmung nicht korrigiert werden kann, wird später besprochen, wie diese Situation gelöst werden kann. Es ist jedoch zumindest ersichtlich, dass die BCP-Abstimmung mit Ausnahme von DB->DBus ausreicht, um die meisten Synchronisationsverzögerungen zu finden Probleme. Warum ein einzelner Stream anstelle mehrerer Streams?
-
Vermeiden Sie unkontrollierbare Verzögerungsprobleme, die durch lange Datenflussverbindungen für den Multi-Stream-Abgleich verursacht werden und zu einer geringen Überprüfungsgenauigkeit führen.
-
Die Wartungskosten der BCP-Abstimmung werden erheblich reduziert, da wir bei Verwendung von Multi-Stream mehrere BCP-Abstimmungen für die Abstimmung mehrerer Computerräume verwalten müssen, für deren Wartung grundlegendere Komponenten erforderlich sind.
Das Schreiben der BCP-Abstimmungs-DB löst immer ES-Get-Anfragen aus, die bestimmte Abfrageressourcen auf ES verbrauchen, aber Get-Anfragen sind Abfragemethoden mit sehr guter Leistung. Beispielsweise haben wir kein Problem damit, innerhalb von 1000 QPS zu schreiben.
Bei der Get-Anforderung muss ein Parameter „Echtzeit“ beachtet werden, der bei der Anforderung auf „Falsch“ gesetzt werden muss. Andernfalls wird bei jeder Anforderung ein Aktualisierungsvorgang ausgelöst, der sich auf die Schreibleistung des Systems auswirkt.
mgetReq := EsClient.MultiGet().
Echtzeit (falsch)
Abstimmung auf Minutenebene
Wie im vorherigen Abschnitt erwähnt, ist der Pfad, der durch den Abgleich der Business Verification Platform (BCP) nicht abgedeckt werden kann, DB->DBus. Dies ist die Situation, in der Binlog abgeschnitten wird. Normalerweise hätte eine Binlog-Unterbrechung einen schwereren Unfall bedeuten können, aber was wir tun müssen, ist, alles Mögliche zu tun.
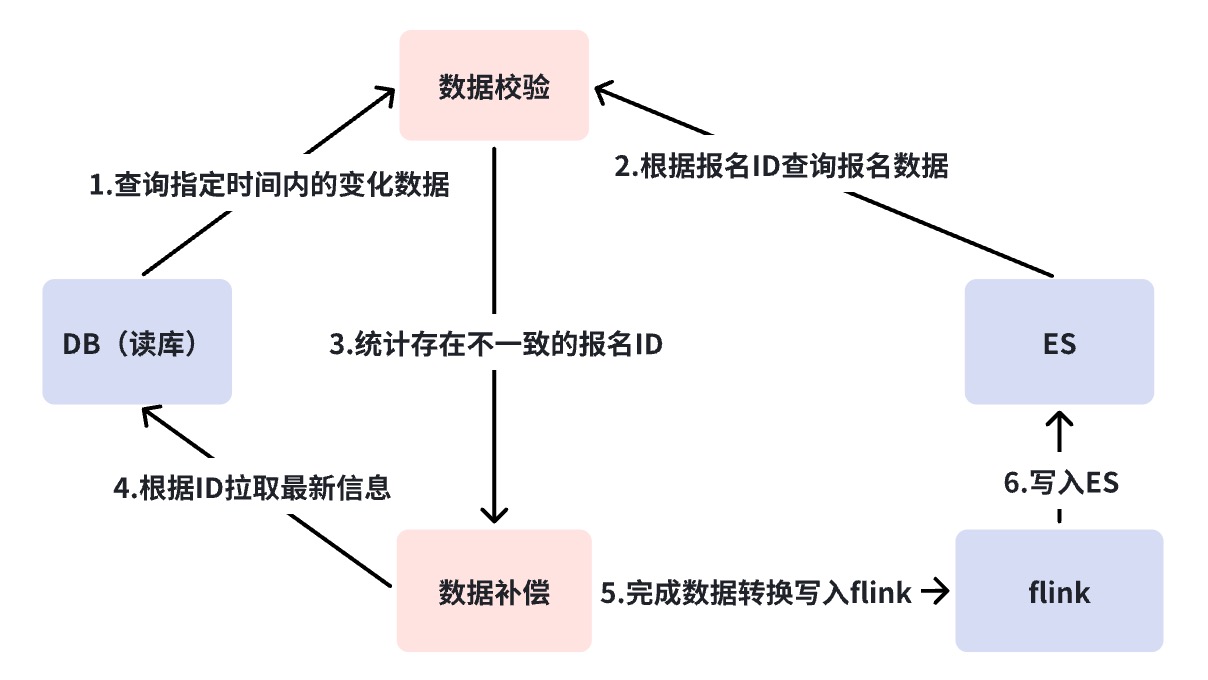
Der Abgleich auf Minutenebene fragt DB und ES direkt ab, ohne auf irgendwelche Komponenten angewiesen zu sein. Wenn Inkonsistenzen auftreten, wird ein automatischer Ausgleich durchgeführt. Einerseits gleicht der Abgleich auf Minutenebene die Mängel des BCP-Abgleichs aus, und der zweite Punkt besteht darin, einen Kompensationsmechanismus hinzuzufügen. Der Grund, warum BCP keine Kompensation durchführt, liegt darin, dass BCP hauptsächlich zur Erkennung von Problemen dient und daher leichtgewichtig und schnell bleiben muss. Außerdem ist es immer noch auf Basiskomponenten wie RocketMQ und DBus angewiesen. Diese Art der Kompensation kann immer noch nicht alle abnormalen Szenarien abdecken.
Standardmäßig gehen wir davon aus, dass die Komponentenfunktion für den Abgleich alle drei Minuten intakt ist, aber eine kurze Verzögerung in einem Knoten führt zu einer Kompensation. Wenn Kompensationsalarme häufig auftreten, müssen wir das Problem mit der Verbindung weiter analysieren. Zu diesem Zeitpunkt werde ich in unserem Szenario den Link in zwei Teile aufteilen und prüfen, ob ein Problem mit dem vorherigen Link von RocketMQ oder ein Problem mit RocketMQ und den nachfolgenden Verbrauchslinks vorliegt. Wenn vor RocketMQ ein Problem mit der Verbindung auftritt, z. B. eine Binlog-Unterbrechung, ein Aufhängen heterogener Datensynchronisierungsplattformkomponenten usw., werden die Kompensationsdaten direkt in RocketMQ geschrieben und in mehreren Computerräumen verbraucht Zeitlich muss der Leseverkehr nicht unterbrochen werden und kann die Konsistenz der Daten in mehreren Computerräumen gewährleisten. Wenn RocketMQ jedoch aufhängt, wird direkt in ES geschrieben. Da wir derzeit nicht garantieren können, dass mehrere Computerräume gleichzeitig erfolgreich geschrieben werden können, haben wir uns entschieden, nur in einen einzelnen Computerraum zu schreiben und den gesamten Datenverkehr dorthin umzuleiten der einzelne Computerraum.
Das Aufhängen von RocketMQ ist ein sehr schlechtes Signal, und die Situation ist hier komplizierter. Aufgrund des direkten Schreibens auf ES verliert das System zu diesem Zeitpunkt bei hohem Schreibverkehr den Strombegrenzungsschutz, und ES kann diesem möglicherweise nicht standhalten. Ein einzelner Computerraum kann möglicherweise nicht dem gesamten Leseverkehr standhalten Wenn gleichzeitig Schreibkonflikte auftreten, muss der Business-Schreibport herabgestuft werden. Wenn RocketMQ aufhängt, ist es daher verständlich, dass das zentrale System der Schreibverbindung lahmgelegt ist.
Dies ist das Letzte, was Sie sehen möchten, daher ist das SLA von RocketMQ die Grundlage des Geschäfts.
T+1 Offline-Abgleich
Bei der Offline-Abstimmung werden die Daten von DB und ES täglich mit Hive synchronisiert. Bei Inkonsistenz wird automatisch eine Kompensation für die Datenkonsistenz eingeleitet Daten müssen spätestens T +1 Kompensation erfolgreich sein.
Zusammenfassen
Oben haben wir die erste Phase des Aufbaus, der Bereitstellung der Notfallwiederherstellung, des Konsistenzabgleichs und der grundlegenden Strategien zur Reaktion auf Systemausnahmen abgeschlossen. Derzeit kann ES Lese- und Schreibanforderungen für Dutzende Millionen Produktindizes unterstützen. Der Datenverkehr in einem einzelnen Computerraum schwankt zwischen 500 und 100 QPS, und der Schreibverkehr wird grundsätzlich bei etwa 500 QPS gehalten.
Mit der Geschäftsentwicklung kam es im ES-Cluster jedoch mehrfach zu CPU-Anstiegen, ein oder mehrere Computerräume waren gleichzeitig voll und die Abfrageverzögerungen nahmen plötzlich zu. Der Lese- und Schreibverkehr schwankte jedoch nicht stark Dieses Risiko liegt weit unter dem Systemspitzenwert und wird auf die im ES-Cluster auftretenden Leistungsprobleme und die Nutzungssituation des Unternehmens zurückgeführt. Wir werden Ihnen diesen Teil im nächsten Artikel Stabilitätsmanagement der ES Search Engine weiter vorstellen.
Artikelquelle |. ByteDance Business Platform Wang Dan