
Autor: Bruce
Hintergrund
Der heute geteilte Fall basiert auf den Best Practices bei der Anwendung von MSE-ZooKeeper durch das technische Team von Dewu. Das ursprüngliche Dewu ZooKeeper-SLA kann auch 99,99 % betragen .
ZooKeeper (ZK) ist ein 2007 gegründeter verteilter Anwendungskoordinierungsdienst. Obwohl aus besonderen historischen Gründen viele Geschäftsszenarien immer noch darauf angewiesen sind. Zum Beispiel Kafka, Aufgabenplanung usw. Insbesondere bei der gemischten Bereitstellung von Flink und der ETCD-Entkopplung erforderte die Geschäftsseite absolute Stabilität und empfahl dringend, den selbst erstellten ZooKeeper nicht zu verwenden. Aus Stabilitätsgründen wird Alibabas MSE-ZK verwendet. Seit dem Einsatz im September 2022 hat das technische Team von Dewu keine Stabilitätsprobleme festgestellt und die SLA-Zuverlässigkeit hat tatsächlich 99,99 % erreicht.
Im Jahr 2023 nutzten einige Unternehmen selbstgebaute ZooKeeper (ZK)-Cluster, und dann kam es bei ZK zu mehreren Schwankungen während der Nutzung. Dann begann Dewu SRE, einige selbstgebaute Cluster zu übernehmen und unternahm mehrere Versuche zur Stabilitätsverstärkung. Während des Übernahmeprozesses wurde festgestellt, dass die Speichernutzung nach längerer Ausführung von ZooKeeper weiter ansteigt, was leicht zu Out-of-Memory-Problemen (OOM) führen kann. Das technische Team von Dewu war sehr neugierig auf dieses Phänomen und beteiligte sich daher am Explorationsprozess zur Lösung dieses Problems.
Erkunden und analysieren
Richtung bestimmen
Bei der Fehlerbehebung hatte ich das große Glück, in einer Testumgebung eine Fehlerstelle zu finden. Zwei Knoten im Cluster befanden sich zufällig in einem Randzustand von OOM.

Bei der Störungsstelle verbleiben meist nur noch 50 % bis zum erfolgreichen Endpunkt. Erfahrungsgemäß ist der Speicher eher hoch, oder es liegt ein Problem im Heap vor. Aus dem Flammendiagramm und jstat kann bestätigt werden, dass es sich um ein Problem im Heap handelt.

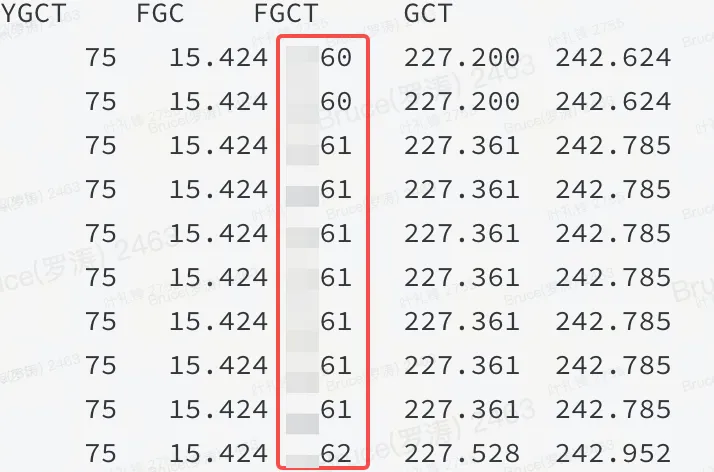
Wie in der Abbildung gezeigt: Dies bedeutet, dass eine bestimmte Ressource im JVM-Heap viel Speicher belegt und FGC sie nicht freigeben kann.
Gedächtnisanalyse
Um die Verteilung der Speichernutzung im JVM-Heap zu untersuchen, erstellte das technische Team von Dewu sofort einen JVM-Heap-Dump. Die Analyse ergab, dass der JVM-Speicher stark durch ChildWatches und DataWatches belegt ist.
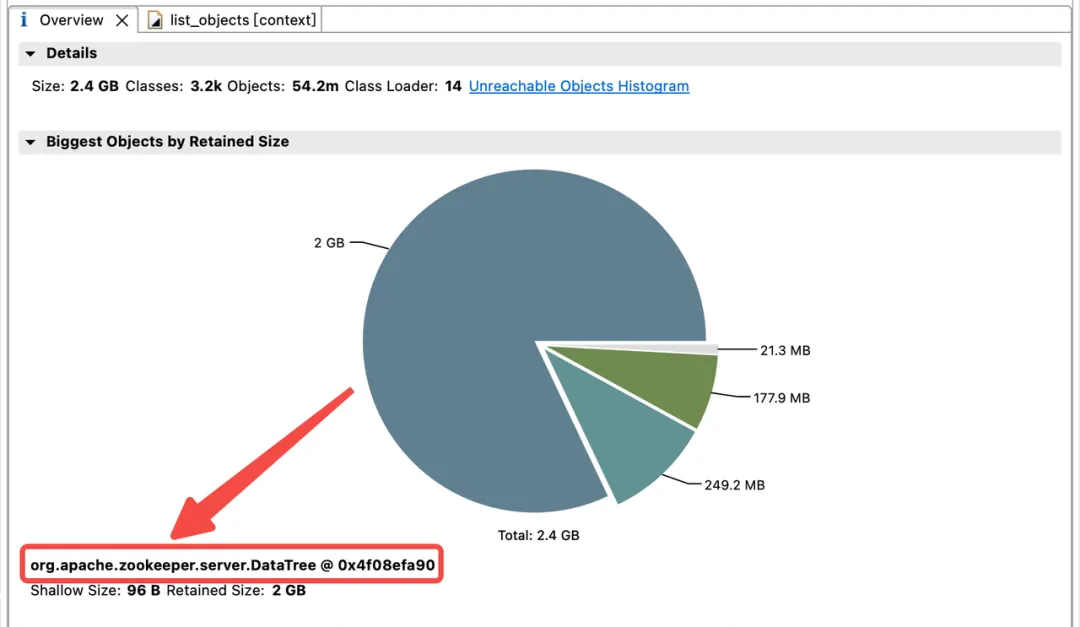
dataWatches: Verfolgen Sie Änderungen in Znode-Knotendaten.
childWatches: Verfolgen Sie Änderungen in der Znode-Knotenstruktur (Baum).
childWatches und dataWatches stammen von WatcherManager.
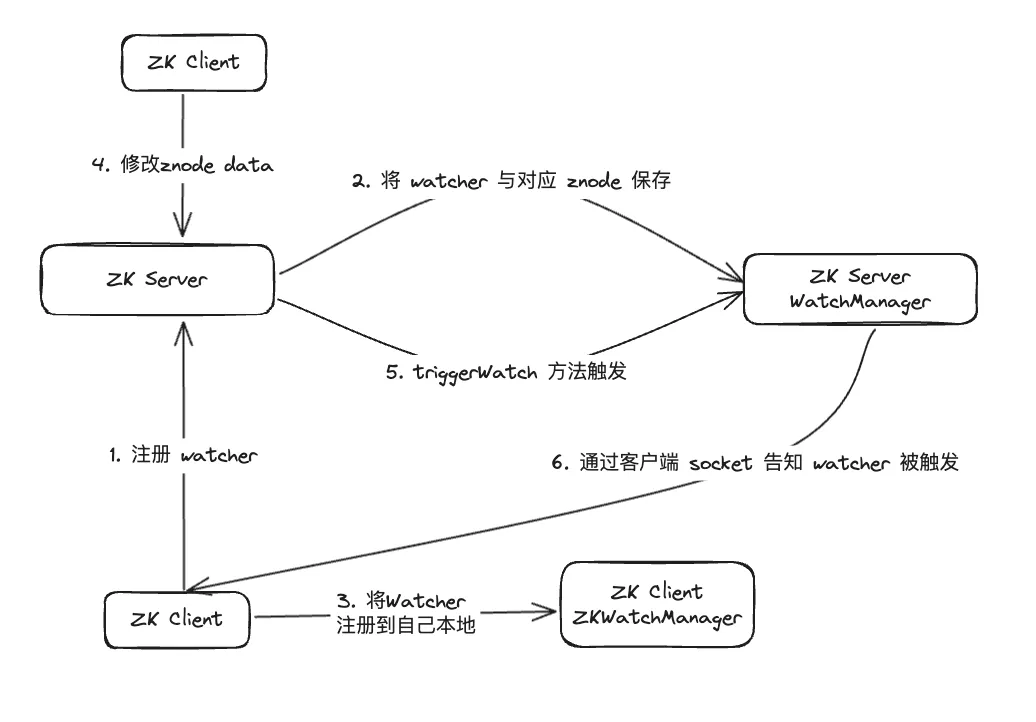
Nach einer Datenuntersuchung wurde festgestellt, dass WatcherManager hauptsächlich für die Verwaltung von Watchern verantwortlich ist. Der ZooKeeper (ZK)-Client registriert zuerst Beobachter beim ZooKeeper-Server, und dann verwendet der ZooKeeper-Server WatcherManager, um alle Beobachter zu verwalten. Wenn sich die Daten eines Znode ändern, löst WatchManager den entsprechenden Watcher aus und kommuniziert mit dem Socket des ZooKeeper-Clients, der den Znode abonniert hat. Anschließend löst der Watch-Manager des Clients den entsprechenden Watcher-Rückruf aus, um die entsprechende Verarbeitungslogik auszuführen und so den gesamten Datenveröffentlichungs-/Abonnementprozess abzuschließen.
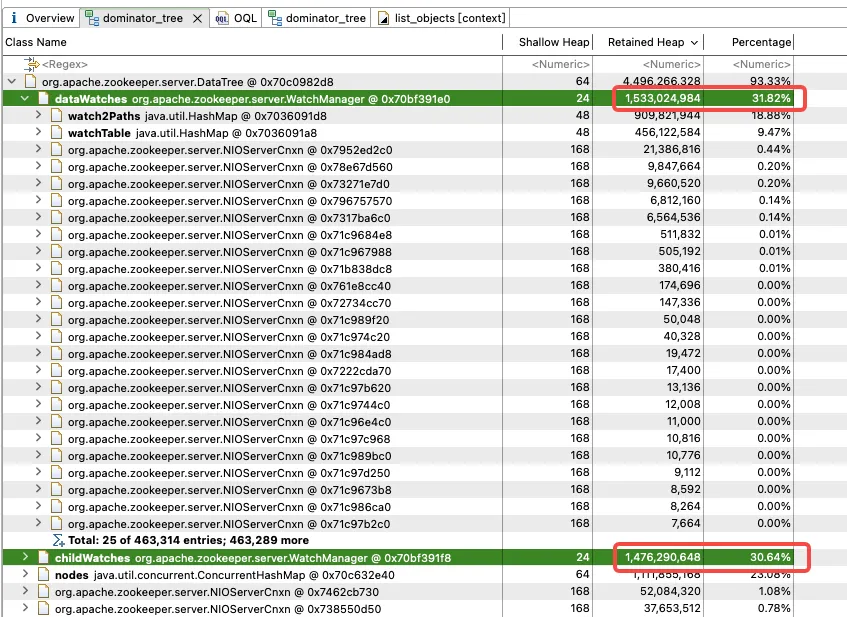
Eine weitere Analyse von WatchManager zeigt, dass das Speicherverhältnis der Mitgliedsvariablen Watch2Path und WatchTables bis zu (18,88+9,47)/31,82 = 90 % beträgt.
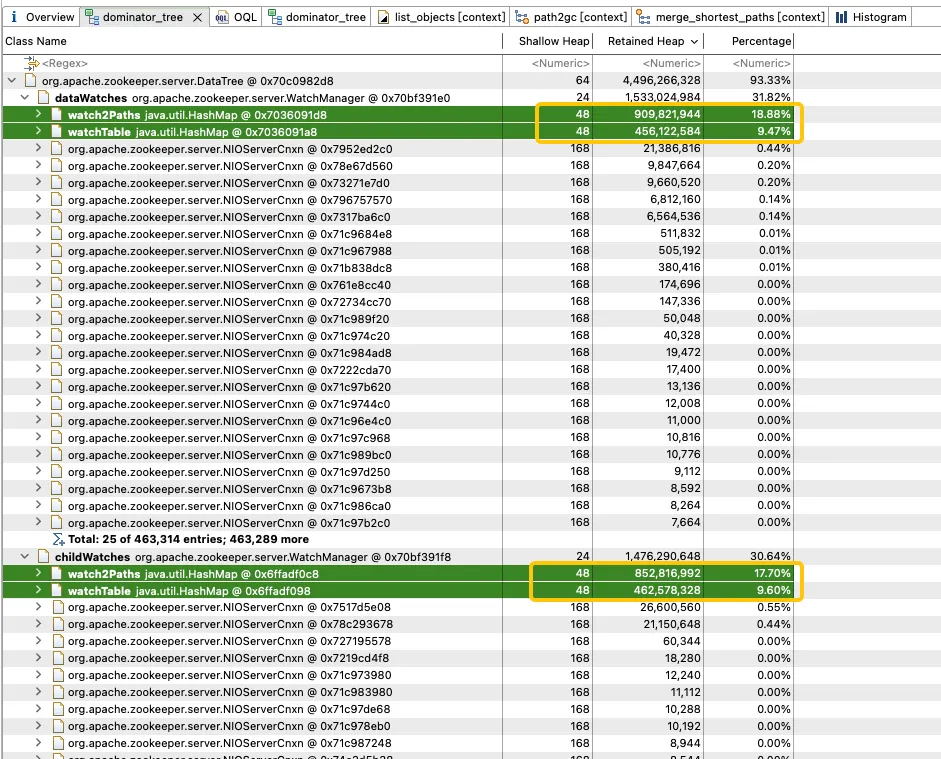
WatchTables und Watch2Path speichern die genaue Zuordnungsbeziehung zwischen ZNode und Watcher, wie im Speicherstrukturdiagramm dargestellt:
WatchTables [Forward-Lookup-Tabelle]
HashMap<ZNode, HashSet<Watcher>>
Szenario: Wenn sich ein ZNode ändert, erhält der Watcher, der den ZNode abonniert hat, eine Benachrichtigung.
Logik: Verwenden Sie diesen ZNode, um alle entsprechenden Watcher-Listen über WatchTables zu finden und dann nacheinander Benachrichtigungen zu senden.
Watch2Paths [Reverse-Lookup-Tabelle]
HashMap<Watcher, HashSet>
Szenario: Zählen Sie, welche ZNodes ein bestimmter Watcher abonniert hat.
Logik: Verwenden Sie diesen Watcher, um alle entsprechenden ZNode-Listen über Watch2Paths zu finden.
Watcher ist im Wesentlichen NIOServerCnxn, was als Verbindungssitzung verstanden werden kann.
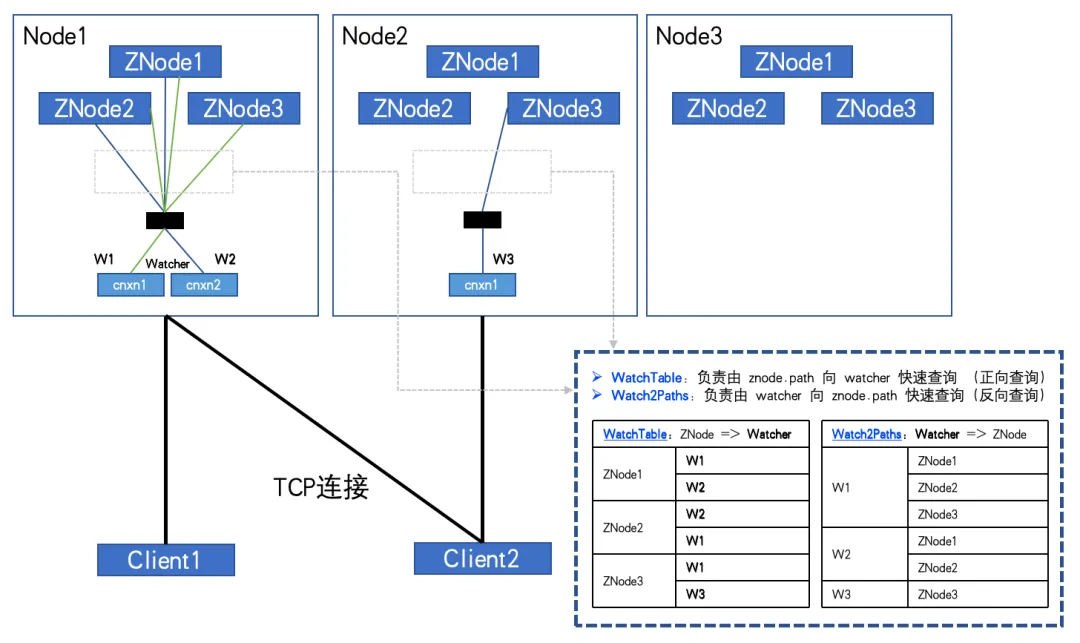
Wenn eine große Anzahl von ZNodes und Watchern vorhanden ist und der Client eine große Anzahl von ZNodes abonniert, kann er sogar vollständig abonniert werden. Die in diesen beiden Hash-Tabellen aufgezeichnete Beziehung wird exponentiell wachsen und schließlich ein himmelhohes Volumen erreichen!
Bei vollständigem Abonnement, wie in der Abbildung gezeigt:
Wenn die Anzahl der ZNodes 3 und die Anzahl der Watcher 2 beträgt, haben WatchTables und Watch2Paths jeweils 6 Beziehungen.
Wenn die Anzahl der ZNodes 4 und die Anzahl der Watcher 3 beträgt, haben WatchTables und Watch2Paths jeweils 12 Beziehungen.
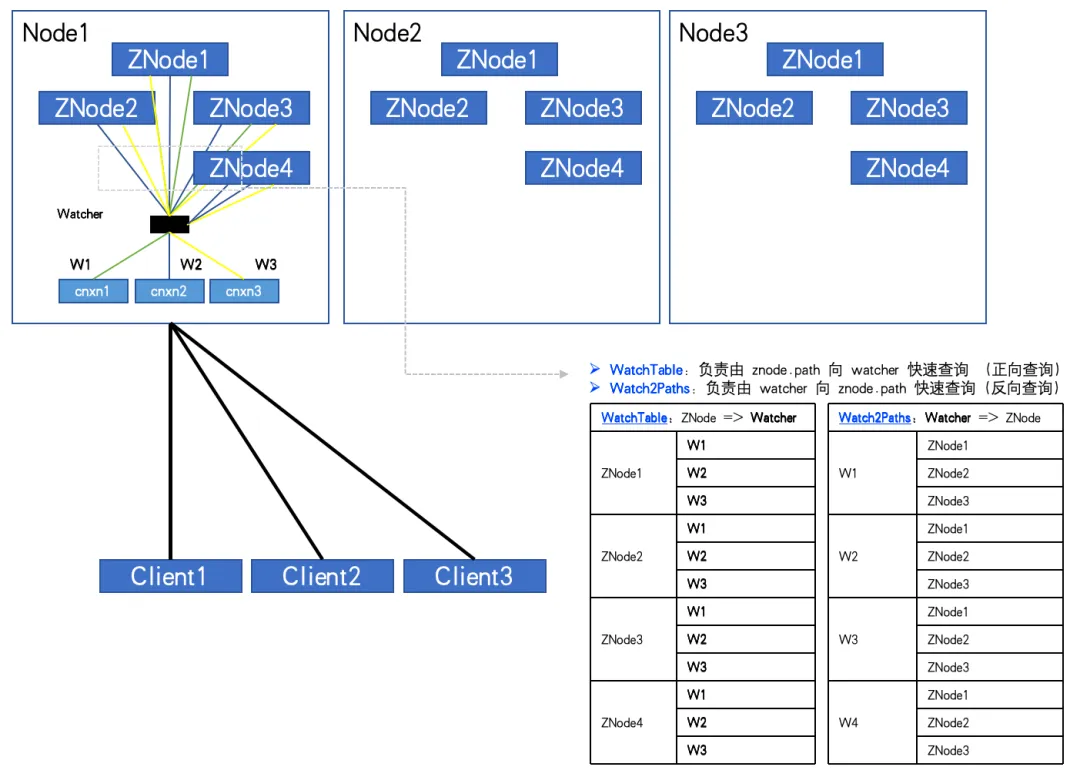
Durch die Überwachung wurde ein abnormaler ZK-Knoten entdeckt. Die Anzahl der ZNodes beträgt etwa 20 W und die Anzahl der Watcher beträgt 5.000. Die Zahl der Beziehungen zwischen Watcher und ZNode hat 100 Millionen erreicht.
Wenn zum Speichern jeder Beziehung ein HashMap&Node (32 Byte) benötigt wird, da es zwei Beziehungstabellen gibt, verdoppeln Sie ihn. Dann berechnen Sie nichts anderes. Allein diese „Shell“ erfordert 2 10000^2 32/1024^3 = 5,9 GB ungültigen Speicheraufwand.
unerwartete Entdeckung
Aus der obigen Analyse können wir erkennen, dass vermieden werden muss, dass der Client alle ZNodes vollständig abonniert. Die Realität ist jedoch, dass viele Geschäftscodes über eine solche Logik verfügen, um alle ZNodes ausgehend vom Wurzelknoten des ZTree zu durchlaufen und sie vollständig zu abonnieren.
Es mag möglich sein, einige Geschäftsparteien zu Verbesserungen zu bewegen, es kann jedoch nicht erzwungen werden, die Nutzung aller Geschäftsparteien einzuschränken. Die Lösung dieses Problems liegt daher in der Überwachung und Prävention. Leider unterstützt ZK selbst eine solche Funktion nicht, was eine Änderung des ZK-Quellcodes erfordert.
Durch die Verfolgung und Analyse des Quellcodes wurde festgestellt, dass die Ursache des Problems auf WatchManager hinweist, und die logischen Details dieser Klasse wurden sorgfältig untersucht. Nach einem gründlichen Verständnis stellte ich fest, dass die Qualität dieses Codes anscheinend von einem Absolventen geschrieben wurde und dass viele Threads und Sperren unangemessen verwendet wurden. Bei der Durchsicht der Git-Datensätze haben wir festgestellt, dass dieses Problem aus dem Jahr 2007 stammt. Spannend ist jedoch, dass in diesem Zeitraum WatchManagerOptimized (2018) durch die Suche nach Informationen der ZK-Community entdeckt wurde Uhren verursachten Probleme mit dem Speicherbedarf und lieferten 2018 endlich eine Lösung. Gerade aufgrund dieses WatchManagerOptimized scheint es, dass die ZK-Community es bereits optimiert hat.
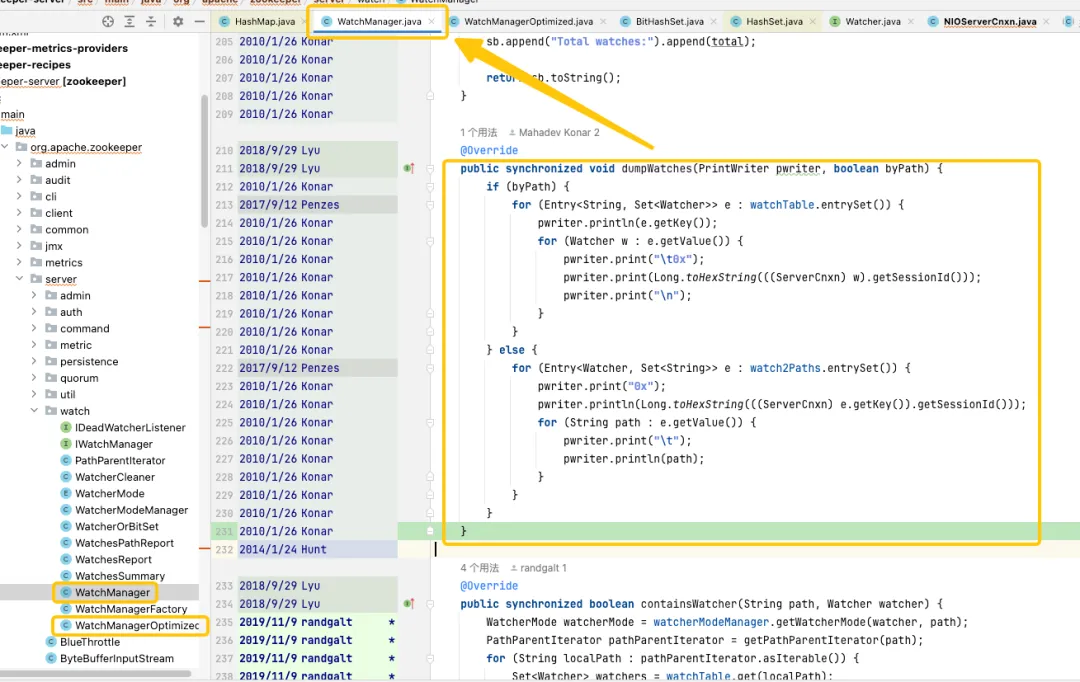
Interessanterweise aktiviert ZK diese Klasse nicht standardmäßig, selbst in der neuesten Version 3.9.X wird WatchManager immer noch standardmäßig verwendet. Vielleicht weil ZK so alt ist, schenken die Leute ihm allmählich weniger Aufmerksamkeit. Durch die Befragung von Kollegen bei Alibaba wurde bestätigt, dass MSE-ZK auch WatchManagerOptimized aktiviert, was weiter bestätigte, dass der Fokus des Dewu-Technikteams in die richtige Richtung ging.
Optimieren Sie die Erkundung
Sperroptimierung
In der Standardversion ist das verwendete HashSet threadunsicher. In dieser Version werden verwandte Betriebsmethoden wie addWatch, removeWatcher und triggerWatch alle implementiert, indem den Methoden synchronisierte schwere Sperren hinzugefügt werden. In der optimierten Version wird eine Kombination aus ConcurrentHashMap und ReadWriteLock verwendet, um den Sperrmechanismus verfeinert zu nutzen. Auf diese Weise können effizientere Vorgänge während des Prozesses des Hinzufügens von Watch und des Auslösens von Watch erreicht werden.
Speicheroptimierung
Das ist der Fokus. Aus der Analyse von WatchManager können wir erkennen, dass die Speichereffizienz der Verwendung von WatchTables und Watch2Paths nicht hoch ist. Wenn ZNode über viele Abonnementbeziehungen verfügt, wird eine große Menge zusätzlicher ungültiger Speicher verbraucht.
Überraschenderweise verwendet WatchManagerOptimized hier „schwarze Technologie“ -> Bitmap.
Der relationale Speicher wird mithilfe von Bitmaps stark komprimiert, um eine Optimierung der Dimensionsreduzierung zu erreichen.
Hauptmerkmale von Java BitSet:
- Platzsparend: BitSet verwendet Bit-Arrays zum Speichern von Daten und benötigt weniger Platz als standardmäßige boolesche Arrays.
- Die Verarbeitung ist schnell: Bitoperationen wie AND, OR, XOR, Flipping sind oft schneller als die entsprechenden booleschen Logikoperationen.
- Dynamische Erweiterung: Die Größe eines BitSets kann je nach Bedarf dynamisch wachsen, um mehr Bits aufzunehmen.
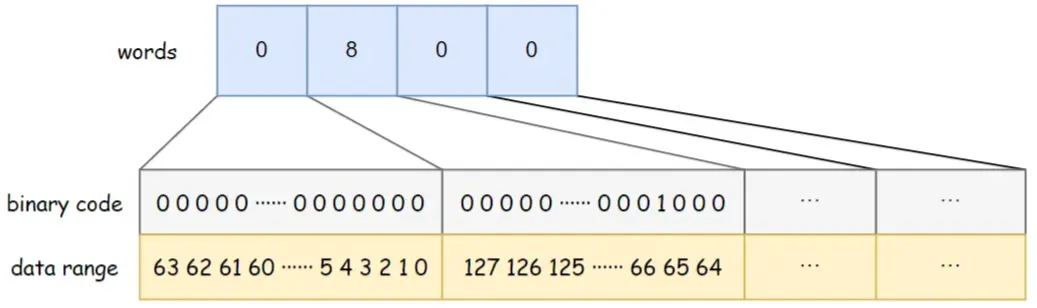
BitSet verwendet Long[]-Wörter zum Speichern von Daten. Der Long-Typ belegt 8 Bytes und ist 64 Bits . Jedes Element im Array kann 64 Daten speichern. Die Speicherreihenfolge der Daten im Array ist von links nach rechts, von niedrig nach hoch.
Beispielsweise beträgt die Wortkapazität des BitSets in der Abbildung unten 4. Wörter [0] von niedrig nach hoch geben an, ob Daten 0 bis 63 vorhanden sind, Wörter [1] von niedrig bis hoch zeigen an, ob Daten 64 bis 127 vorhanden sind, und so weiter An. Darunter sind Wörter [1] = 8 und das entsprechende Binärbit 8 ist 1, was darauf hinweist, dass zu diesem Zeitpunkt Daten {67} im BitSet gespeichert sind.
WatchManagerOptimized verwendet BitMap zum Speichern aller Watcher. Auf diese Weise, auch wenn ein 1W-Watcher vorhanden ist. Der Speicherverbrauch von Bitmap beträgt nur 8 Byte 1 W/64/1024 = 1,2 KB . Wenn es durch HashSet ersetzt wird, sind mindestens 32 Byte 10000/1024 = 305 KB erforderlich, und die Speichereffizienz ist fast 300-mal unterschiedlich.
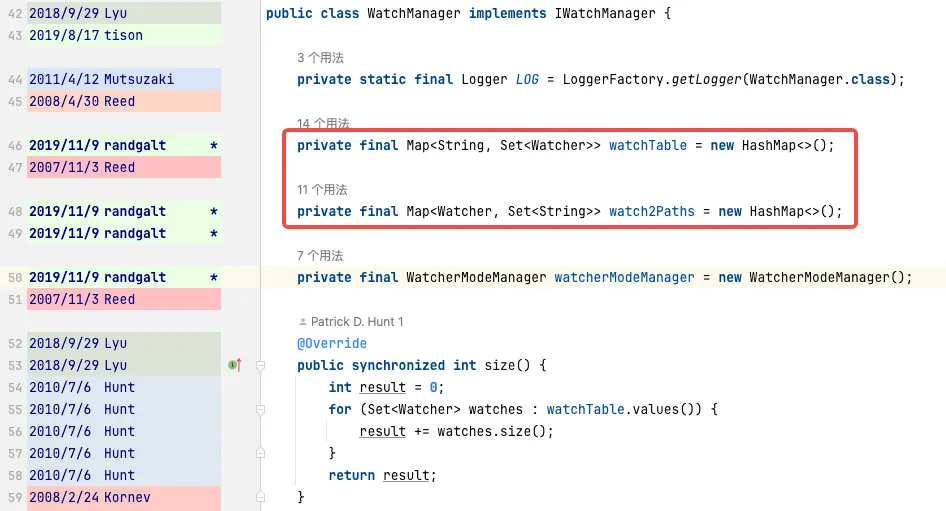
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();
Der Zuordnungsspeicher von ZNode zu Watcher wird von Map<string, set> in ConcurrentHashMap<string, BitHashSet > geändert. Das heißt, der Satz wird nicht mehr gespeichert, sondern die Bitmap wird zum Speichern des Bitmap-Indexwerts verwendet.
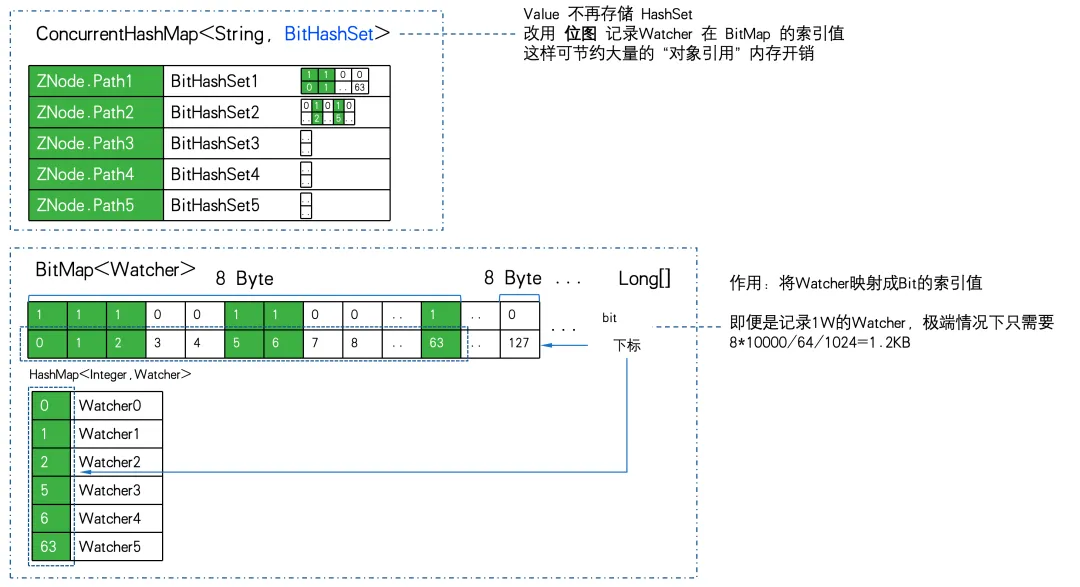
Verwenden Sie 1W ZNode und 1W Watcher und gehen Sie zum äußersten Punkt des Vollabonnements (alle Watcher abonnieren alle ZNodes), um die Speichereffizienz-PK durchzuführen:

Sie können sehen, dass 11,7 MB PK 5,9 GB betragen. Der Unterschied in der Speichereffizienz beträgt das 516-fache .
Logikoptimierung
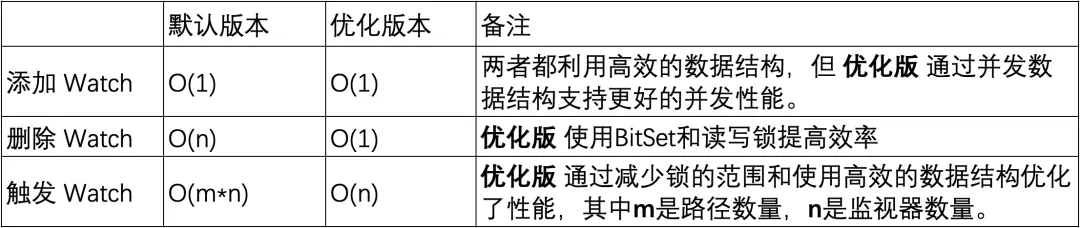
Hinzufügen eines Monitors: Beide Versionen sind in der Lage, Vorgänge in konstanter Zeit abzuschließen, aber die optimierte Version bietet durch die Verwendung von ConcurrentHashMap eine bessere Parallelitätsleistung .
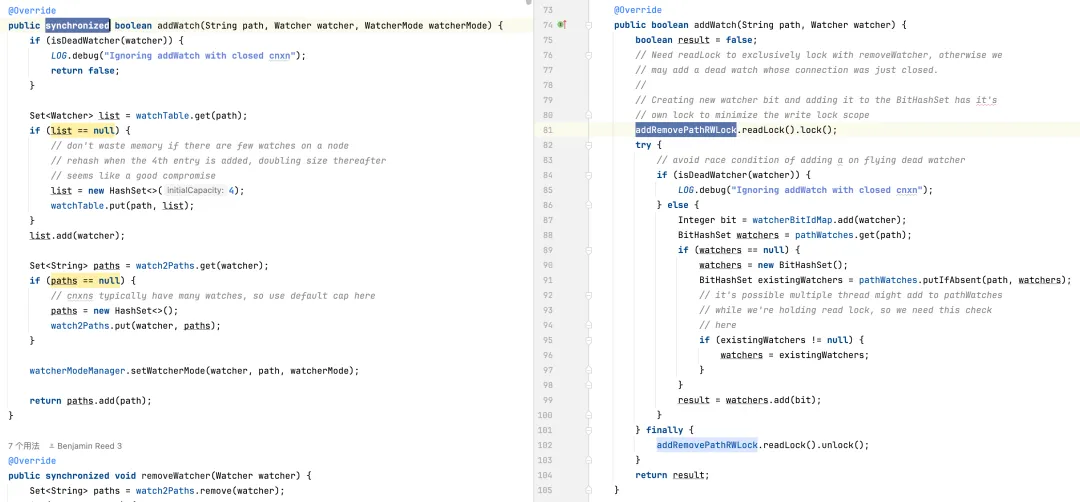
Löschen eines Monitors: Die Standardversion muss möglicherweise die gesamte Monitorsammlung durchlaufen, um den Monitor zu finden und zu löschen, was zu einer Zeitkomplexität von O(n) führt. Die optimierte Version verwendet BitSet und ConcurrentHashMap, um Monitore in O(1) in den meisten Fällen schnell zu finden und zu löschen.
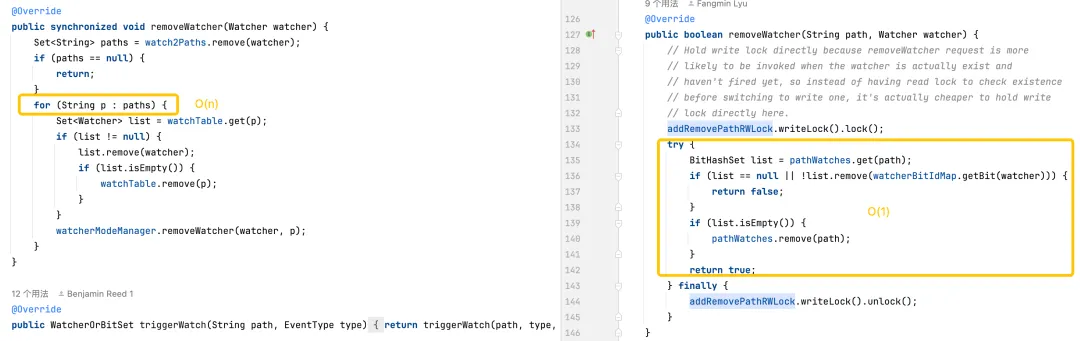
Monitore auslösen: Die Standardversion ist komplexer, da sie Vorgänge auf jedem Monitor auf jedem Pfad erfordert. Die optimierte Version optimiert die Leistung von Triggermonitoren durch effizientere Datenstrukturen und reduzierte Sperrnutzung.
Leistungsstresstest
JMH-Mikrobenchmark
Kompilierung des Quellcodes von ZooKeeper 3.6.4, JMH-Mikrofon-Stresstest WatchBench.
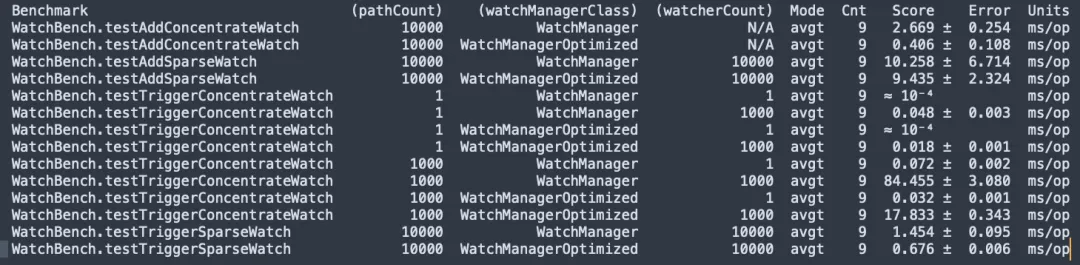
pathCount: Gibt die Anzahl der im Test verwendeten ZNode-Pfade an.
watchManagerClass: Stellt die im Test verwendete WatchManager-Implementierungsklasse dar.
watcherCount: Gibt die Anzahl der im Test verwendeten Beobachter (Watcher) an.
Modus: Zeigt den Testmodus an, hier ist avgt, der die durchschnittliche Laufzeit angibt.
Cnt: Gibt die Anzahl der Testläufe an.
Punktzahl: Gibt die Punktzahl des Tests an, also die durchschnittliche Laufzeit.
Fehler: Gibt den Fehlerbereich der Bewertung an.
Einheiten: Die Einheit, die die Punktzahl darstellt, hier Millisekunden/Operation (ms/op).
- Es gibt 1 Million Abonnements zwischen ZNode und Watcher. Die Standardversion verwendet 50 MB, und die optimierte Version benötigt nur 0,2 MB und erhöht sich nicht linear.
- Wenn man Watch hinzufügt, ist die optimierte Version (0,406 ms/op) 6,5-mal schneller als die Standardversion (2,669 ms/op).
- Es wird eine große Anzahl von Uhren ausgelöst und die optimierte Version (17,833 ms/op) ist fünfmal schneller als die Standardversion (84,455 ms/op).
Leistungsstresstest
Als nächstes wurde ein Satz ZooKeeper 3.6.4 mit 3 Knoten auf einer Maschine (32C 60G) erstellt und die optimierte Version und die Standardversion für den Vergleich der Kapazitätsstresstests verwendet.
Szenario 1: 20-W-Znode mit kurzem Pfad
Znode-Kurzpfad: /demo/znode1

Szenario 2: 20 W langer Znode-Pfad
Langer Znode-Pfad: /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- Die Speichernutzung der Uhr hängt von der Pfadlänge von ZNode ab.
- Die Anzahl der Uhren steigt in der Standardversion linear an und funktioniert in der optimierten Version sehr gut, was eine ganz offensichtliche Verbesserung für die Optimierung der Speichernutzung darstellt.
Graustufentest
Basierend auf dem vorherigen Benchmark-Test und Kapazitätstest weist die optimierte Version in einer großen Anzahl von Watch-Szenarien eine offensichtliche Speicheroptimierung auf. Als Nächstes haben wir begonnen, Graustufen-Upgrade-Testbeobachtungen für den ZK-Cluster in der Testumgebung durchzuführen.
Der erste ZooKeeper-Cluster und seine Vorteile
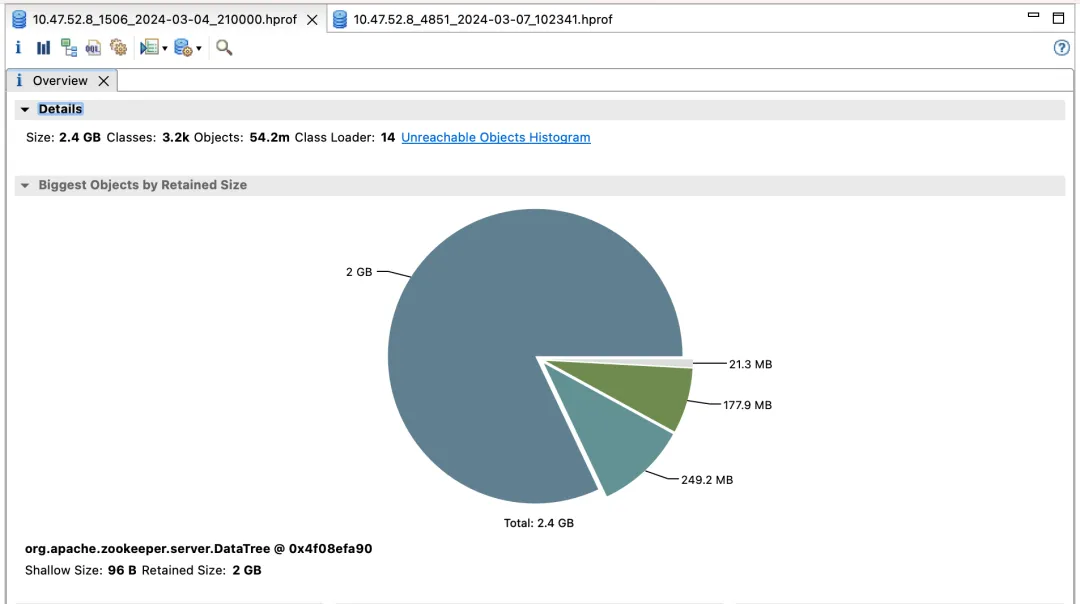
Standardversion
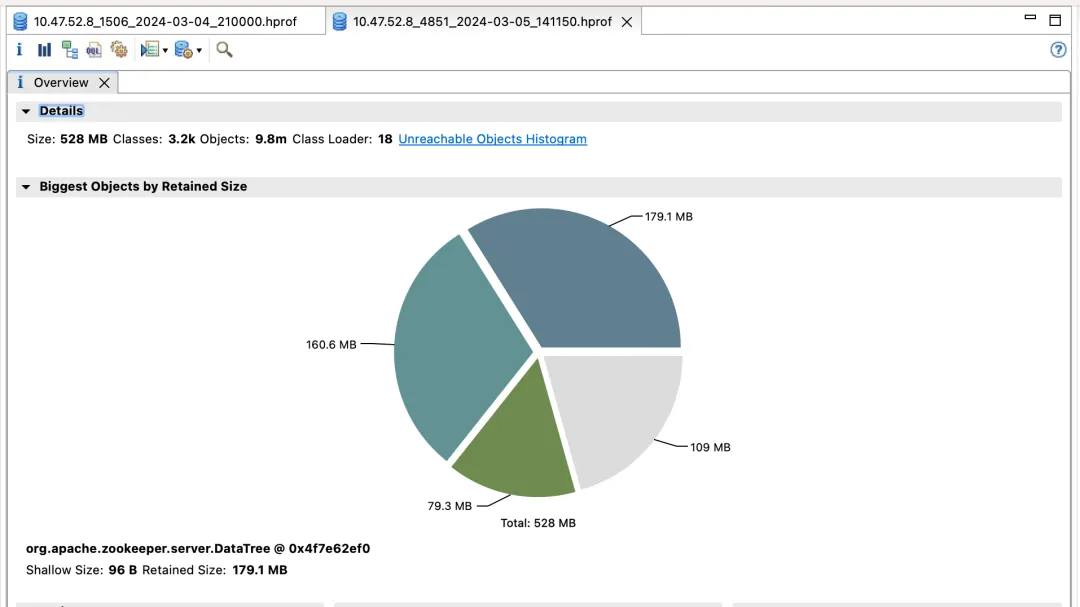
Optimierte Version


Effekteinkommen:
- Wahlzeit (Wahlzeit): um 60 % reduziert
- fsync_time (Transaktionssynchronisationszeit): um 75 % reduziert
- Speicherverbrauch: um 91 % reduziert
Zweiter ZooKeeper-Cluster und Vorteile
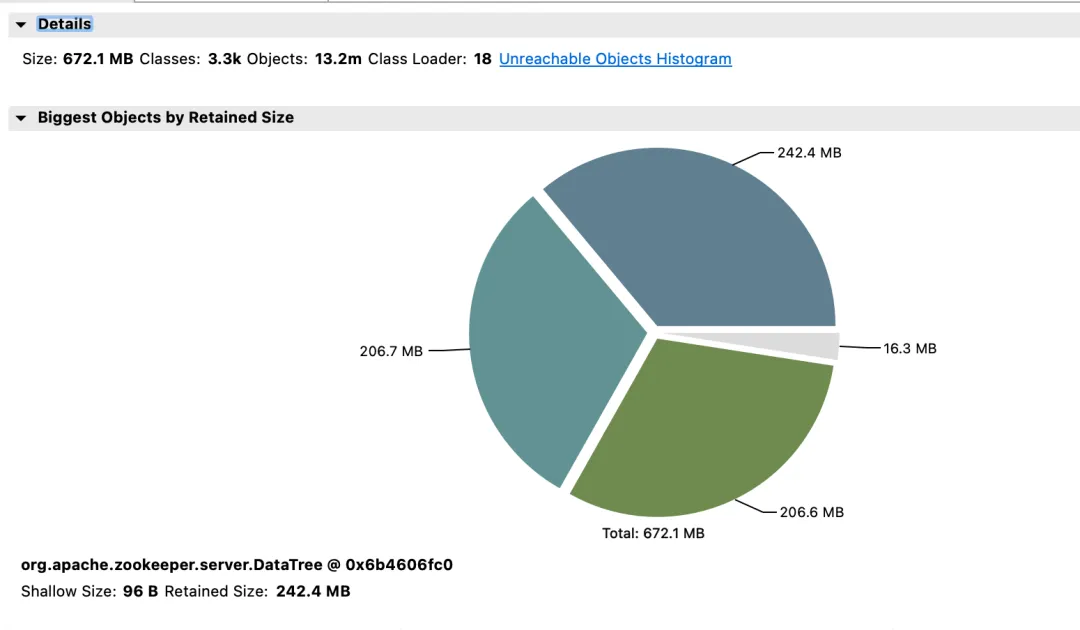



Effekteinkommen:
- Speicher: Vor der Änderung reagierte die JVM-Attach-Antwort nicht und die Datenerfassung schlug fehl.
- Wahlzeit (Wahlzeit): um 64 % reduziert.
- max_latency (Leselatenz): um 53 % reduziert.
- Proposal_Latency (Verzögerung des Wahlverarbeitungsvorschlags): 1400000 ms -> 43 ms.
- propagation_latency (Datenausbreitungsverzögerung): 1400000 ms -> 43 ms.
Der dritte Satz von ZooKeeper-Clustern und -Vorteilen
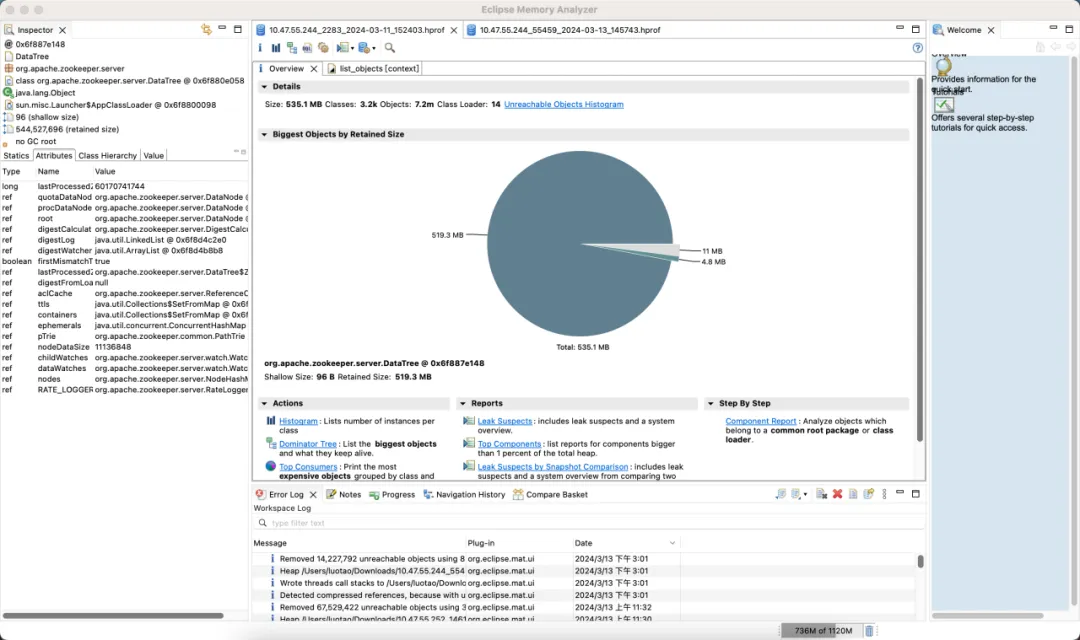
Standardversion
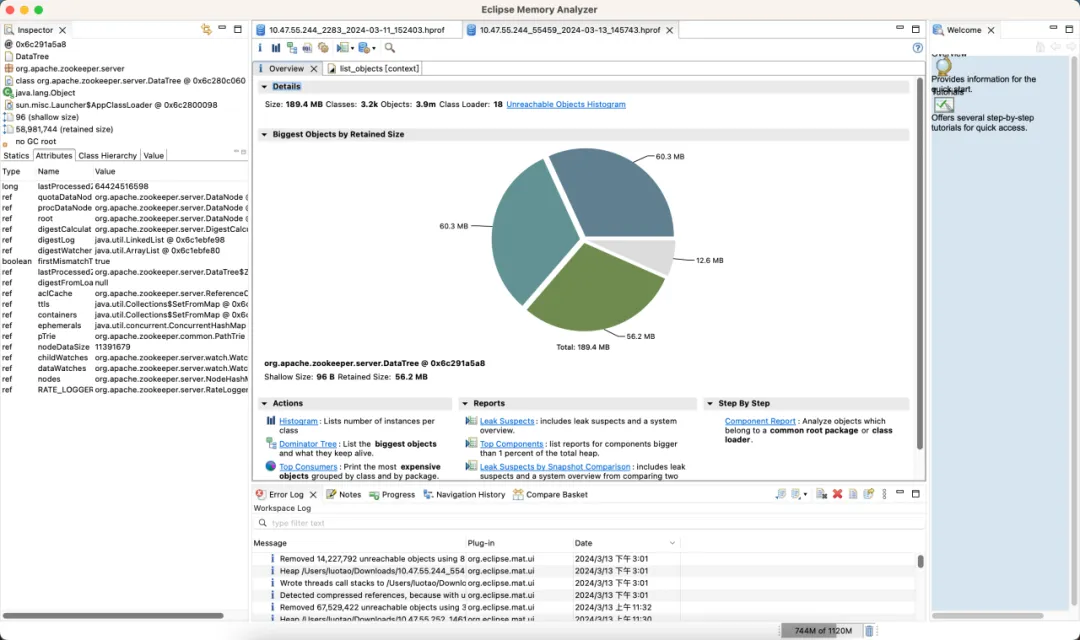
Optimierte Version
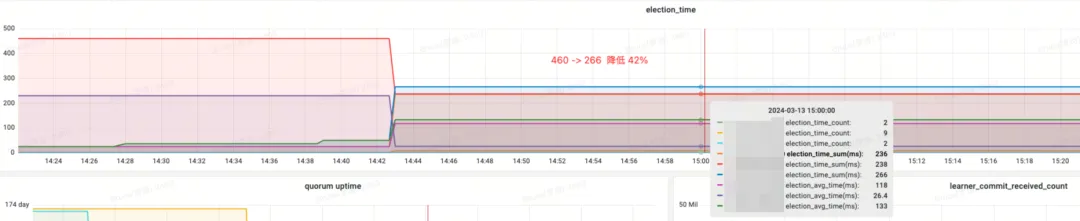

Effekteinkommen:
- Speicher: Sparen Sie 89 %
- Wahlzeit (Wahlzeit): um 42 % reduziert
- max_latency (Leselatenz): um 95 % reduziert
- Proposal_Latency (Verzögerung des Wahlverarbeitungsvorschlags): 679999 ms -> 0,3 ms
- propagation_latency (Datenausbreitungsverzögerung): 928000 ms -> 5 ms
Zusammenfassen
Durch frühere Benchmark-Tests, Leistungsstresstests und Graustufentests wurde WatchManagerOptimized von ZooKeeper entdeckt. Diese Optimierung spart nicht nur Speicher, sondern verbessert auch Indikatoren wie Wahl und Datensynchronisation zwischen Knoten durch Sperrenoptimierung erheblich und verbessert dadurch die Konsistenz von ZooKeeper. Wir haben uns auch intensiv mit Studierenden der Alibaba MSE ausgetauscht, jeweils Stresstests in Extremszenarien simuliert und sind uns einig: WatchManagerOptimized verbessert die Stabilität von ZooKeeper deutlich. Insgesamt verbessert diese Optimierung das SLA von ZooKeeper um eine Größenordnung.
ZooKeeper bietet viele Konfigurationsoptionen, in den meisten Fällen sind jedoch keine Anpassungen erforderlich. Um die Systemstabilität zu verbessern, wird empfohlen, die folgenden Konfigurationsoptimierungen durchzuführen:
- Mounten Sie dataDir (Datenverzeichnis) und dataLogDir (Transaktionsprotokollverzeichnis) jeweils auf unterschiedlichen Festplatten und verwenden Sie Hochleistungsblockspeicher.
- Für ZooKeeper Version 3.8 wird empfohlen, JDK 17 zu verwenden und den ZGC-Garbage Collector zu aktivieren. Für die Versionen 3.5 und 3.6 wird empfohlen, JDK 8 zu verwenden und den G1 Garbage Collector zu aktivieren. Für diese Versionen konfigurieren Sie einfach -Xms und -Xmx.
- Passen Sie den Standardwert des SnapshotCount-Parameters von 100.000 auf 500.000 an, wodurch der Festplattendruck erheblich reduziert werden kann, wenn sich ZNode mit hoher Frequenz ändert.
- Verwenden Sie die optimierte Version von Watch Manager WatchManagerOptimized.
Ref:
https://issues.apache.org/jira/browse/ZOOKEEPER-1177
https://github.com/apache/zookeeper/pull/590
Linus hat es sich zur Aufgabe gemacht, zu verhindern, dass Kernel-Entwickler Tabulatoren durch Leerzeichen ersetzen. Sein Vater ist einer der wenigen Führungskräfte, die Code schreiben können, sein zweiter Sohn ist Direktor der Open-Source-Technologieabteilung und sein jüngster Sohn ist ein Open-Source-Core Mitwirkender : Natürliche Sprache wird immer weiter hinter Huawei zurückfallen: Es wird 1 Jahr dauern, bis 5.000 häufig verwendete mobile Anwendungen vollständig auf Hongmeng migriert sind Der Rich - Text-Editor Quill 2.0 wurde mit einer deutlich verbesserten Erfahrung von Ma Huateng und „ Meta Llama 3 “ veröffentlicht Quelle von Laoxiangji ist nicht der Code, die Gründe dafür sind sehr herzerwärmend. Google hat eine groß angelegte Umstrukturierung angekündigt