
Autor: vivo Internet Big Data Team-Wu Yonggang, Li Xiong
Dieser Artikel ist der vierte Artikel in der Artikelreihe „Practice of User Behavior Analysis Model“ des vivo Internet Big Data-Teams – Retention Analysis Model.
In diesem Artikel werden das Konzept und die Grundprinzipien des Retention-Analysemodells ausführlich vorgestellt und seine spezifische Implementierung im Produkt erläutert. Angesichts der Probleme im tatsächlichen Nutzungsprozess wurde eine praktische Lösung basierend auf dem ClickHouse-Retention-Analysemodell untersucht.
1. Hintergrundanforderungen
Laut Statistiken von CNNIC hat Chinas Internetnutzerzahl 1,079 Milliarden erreicht, und die Internetdurchdringungsrate hat 79,4 % erreicht. Obwohl das Internet immer noch schnell wächst, ist die Zahl der Nutzer allmählich gesättigt. Das Internet ist tatsächlich in die Ära der bestehenden Nutzer eingetreten. Der allgemeine Verkehrswettbewerb wird immer härter und die Bindung von Nutzern wird immer wichtiger als die Gewinnung neuer Nutzer Benutzer. Wie kann man also treue Benutzer identifizieren und die Bindungsleistung der Zielbenutzergruppe verstehen? Wie kann man die Abwanderung von Nutzern analysieren und Produkte optimieren? Die Analyse, ob die Zielbenutzer das gewünschte Verhalten erreicht haben usw., sind wichtige Themen in unserer Datenanalyse, und das Retention-Analysemodell ist für uns ein wichtiges Werkzeug zur Lösung dieser Probleme.
2. Übersicht
2.1 Konzepteinführung
Das Retention-Analysemodell wird hauptsächlich verwendet, um das Verhältnis von Benutzern, die das erste Ereignis ausgelöst haben, zu analysieren, um nachfolgende Ereignisse (z. B. Wiederbesuchsereignisse) in späteren Zeiträumen auszulösen. Dieses Modell kann die Loyalität oder Benutzerbindung des Benutzers besser widerspiegeln. Es gibt mehrere wichtige Konzepte, die es beim Aufbewahrungsanalysemodell zu verstehen gilt:

Für die Aufbewahrungsanalyse ist im Allgemeinen die Angabe des Startereignisses und des Rückbesuchsereignisses erforderlich. Das Startereignis und das Rückbesuchsereignis können jedoch gleich oder unterschiedlich sein:
1. Sie können das gleiche Ereignis für das Erstereignis und das Rückbesuchsereignis auswählen . Dadurch können Sie intuitiv die Anzahl der treuen Benutzer erkennen, die das Ereignis ausgelöst haben.
Beispiel: Während des Anmeldevorgangs ist das erste Ereignis die erfolgreiche Anmeldung und das erneute Besuchsereignis die erfolgreiche Anmeldung. Innerhalb eines Zeitraums kann die Anzahl der Benutzer, die dieses Ereignis kontinuierlich auslösen, die Anzahl der sein treue Benutzer.
2. Sie können unterschiedliche Ereignisse für das Erstereignis und das Rückbesuchsereignis auswählen. Dies sind die Benutzerbindungsdaten im Rahmen eines relativ normalen Prozesses.
Beispiel: Bei einer bestimmten Aktivität, von der Auftragserteilung bis zur erfolgreichen Zahlung, ist das Startereignis die Auftragserteilung und das Gegenbesuchsereignis der Zahlungserfolg. Innerhalb eines Zeitraums ist derselbe Benutzer, der diese beiden Ereignisse auslöst, der vorgesehene Prozess Benutzeraufbewahrungsdaten.
2.2 Analyseideen
Die Bindungsrate ist einer der Kernindikatoren eines Produkts. Wir verbessern die Produktfunktionen, verbessern die Benutzererfahrung und analysieren die Zielbenutzer weitgehend, um diesen Indikator zu verbessern. Beispielsweise können wir bewerten, ob eine bestimmte Iteration positiv ist, indem wir die Aufbewahrungsrate an N Tagen berechnen. Wie in Abbildung 1 dargestellt, kann eine Anwendung, wenn sie das Homepage-Layout optimiert und die neue Version A startet, mit der alten Version B kombiniert werden, um die tägliche Benutzerbindungsrate zu berechnen. Es entsteht im Allgemeinen eine abnehmende Bindungskurve. Je langsamer die Kurve abklingt, desto höher ist unsere Retention Rate, was auch zeigt, dass sich die Änderung unserer Homepage positiv auswirkt. Natürlich kann die Verbesserung der Bindung manchmal nur ein paar Zehntel Prozent betragen, aber unter der Voraussetzung einer großen Benutzerbasis kann es auch zu einigen qualitativen Veränderungen kommen. Wir können auch bestimmte Personengruppen als Benutzergruppen definieren, Bindungsanalysen für verschiedene Benutzergruppen durchführen und loyalere Benutzergruppen ermitteln.
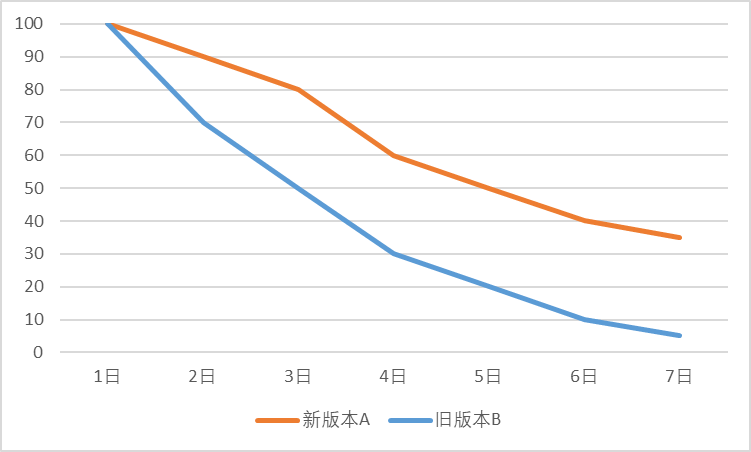
Abbildung 1 Vergleich der Aufbewahrung zwischen neuer Version A und alter Version B
3. Datenanalyse mittels Aufbewahrung
Nachdem wir nun die Grundkonzepte des oben genannten Aufbewahrungsmodells verstanden haben, werfen wir einen Blick darauf, wie man eines erstellt.
3.1 Wählen Sie eine Startveranstaltung und eine Gegenbesuchsveranstaltung aus
Startereignis: Öffnen Sie den Browser.
Gegenbesuchsereignis: Beenden Sie den Browser.
3.2 Aufbewahrungstage festlegen
Legen Sie eine Aufbewahrungsfrist von 3 Tagen fest.
3.3 Bestimmen Sie das Aufbewahrungszeitintervall
Das Konzept des Zeitintervalls bezieht sich hier auf das Datumsintervall, das Sie anzeigen müssen. Wenn Sie beispielsweise das Zeitintervall 2023-01-06~2023-01-08 auswählen, dann nur die drei Tage vom 2023-01-06 bis Der 08.01.2023 wird berechnet, jeder Tag wird am selben Tag gespeichert, am 1. Tag gespeichert, am 2. Tag gespeichert und am 3. Tag gespeichert.
3.4 Anzeige- und Berechnungslogik der gespeicherten Daten
Anzahl der Startbenutzer = Anzahl der Benutzer, die am berechneten Datum das Startereignis auslösen.
Die Anzahl der behaltenen Benutzer am Tag = die Schnittmenge der Benutzer, die das Ereignis des erneuten Besuchs am Tag ausgelöst haben, und der Benutzer, die das erste Ereignis am Tag ausgelöst haben.
Die Anzahl der behaltenen Benutzer am ersten Tag = die Schnittmenge der Benutzer, die am nächsten Tag das Wiederbesuchsereignis ausgelöst haben, und der Benutzer, die am berechneten Datum das Startereignis ausgelöst haben.
Die Anzahl der behaltenen Benutzer am 2. Tag = die Schnittmenge der Benutzer, die nach 2 Tagen das erneute Besuchsereignis ausgelöst haben, und der Benutzer, die am berechneten Datum das Startereignis ausgelöst haben.
Die Anzahl der behaltenen Benutzer am 3. Tag = die Schnittmenge der Benutzer, die nach 3 Tagen das erneute Besuchsereignis ausgelöst haben, und der Benutzer, die am berechneten Datum das Startereignis ausgelöst haben.
Die Bindungsrate des Tages = die Anzahl der behaltenen Benutzer am Tag / die anfängliche Anzahl der Benutzer * 100 %.
Die Bindungsrate am ersten Tag = die Anzahl der behaltenen Benutzer am ersten Tag / die Anzahl der Erstbenutzer * 100 %.
Die Bindungsrate am zweiten Tag = die Anzahl der behaltenen Benutzer am zweiten Tag/die anfängliche Anzahl der Benutzer*100 %.
Bindungsrate am 3. Tag = Anzahl der behaltenen Benutzer am 3. Tag/anfängliche Anzahl der Benutzer * 100 %.
Die Tabelle mit der Anzahl der Benutzerbindungszahlen (d. h. Tabelle 1) gibt an, dass, wenn das Startereignis „Browser öffnen“ und das Ereignis des erneuten Besuchs „Browser verlassen“ ist, dies den beibehaltenen Benutzern in den letzten drei Tagen vom 06.01.2023 bis entspricht Daten vom 09.01.2023.
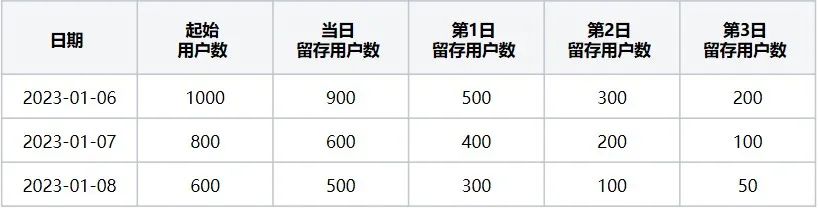
Tabelle 1 Tabelle mit Benutzeraufbewahrungsnummern
Die Tabelle mit der Benutzerbindungsrate (d. h. Tabelle 2) gibt an, dass, wenn das Startereignis „Browser öffnen“ und das Ereignis für den erneuten Besuch „Browser verlassen“ ist, dies den beibehaltenen Benutzern in den letzten drei Tagen vom 06.01.2023 bis entspricht 08.01.2023. Anteilsdaten.
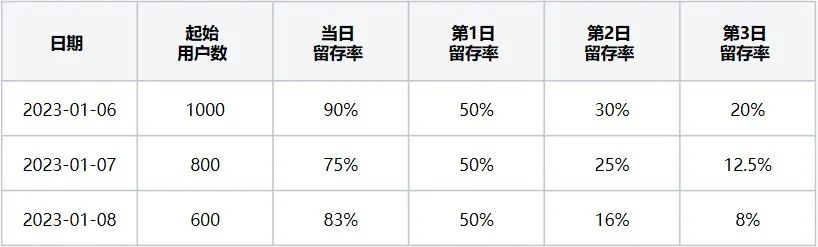
Tabelle 2 Tabelle zur Benutzerbindungsrate
Nimmt man die Daten vom 06.01.2023 in Tabelle 1, beträgt die Anzahl der Startbenutzer am 6. Januar 1.000: bezieht sich auf die Anzahl der Benutzer, die das Startereignis „Browser öffnen“ ausgelöst haben; die Anzahl der beibehaltenen Benutzer Tag: 900: Bezieht sich auf die Anzahl der Benutzer, die das anfängliche Ereignis „Browser öffnen“ ausgelöst haben. Die Anzahl der Benutzer, die unter den anfänglichen Ereignisbenutzern am selben Tag das erneute Besuchsereignis „Browser verlassen“ ausgelöst haben.
Anzahl der behaltenen Benutzer am ersten Tag: 500: bezieht sich auf die Anzahl der Benutzer, die das Rückbesuchsereignis am 7. Januar ausgelöst haben und sich mit dem ersten Ereignis am 6. Januar überschnitten haben. Anzahl der behaltenen Benutzer am zweiten Tag: 300: bezieht sich auf die Die Anzahl der Benutzer, die das Rückbesuchsereignis am 8. Januar ausgelöst haben. Und die Anzahl der Kreuzungsbenutzer, die das Startereignis am 6. Januar ausgelöst haben, beträgt 300, und so weiter bis zum dritten Tag. Zu diesem Zeitpunkt sind die drei Tage der gespeicherten Daten für den Tag 06.01.2023 sind berechnet!
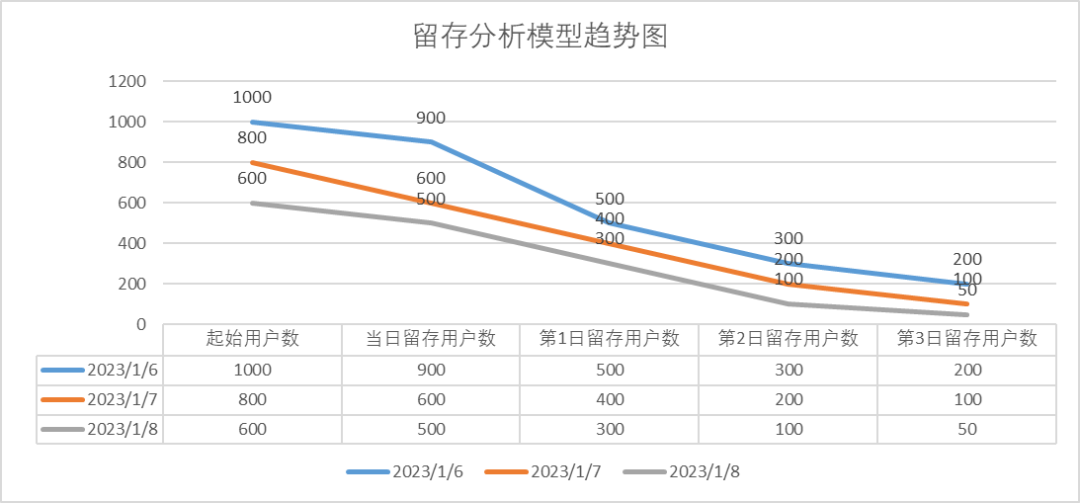
Abbildung 2: Trenddiagramm der behaltenen Benutzer innerhalb von 3 Tagen, entsprechend dem auslösenden Erstereignis und dem erneuten Besuchsereignis
4. Gesamtfunktionales Design und Implementierung des Retention-Analysemodells
4.1 (Offline) Funktion Gesamtarchitekturdesign
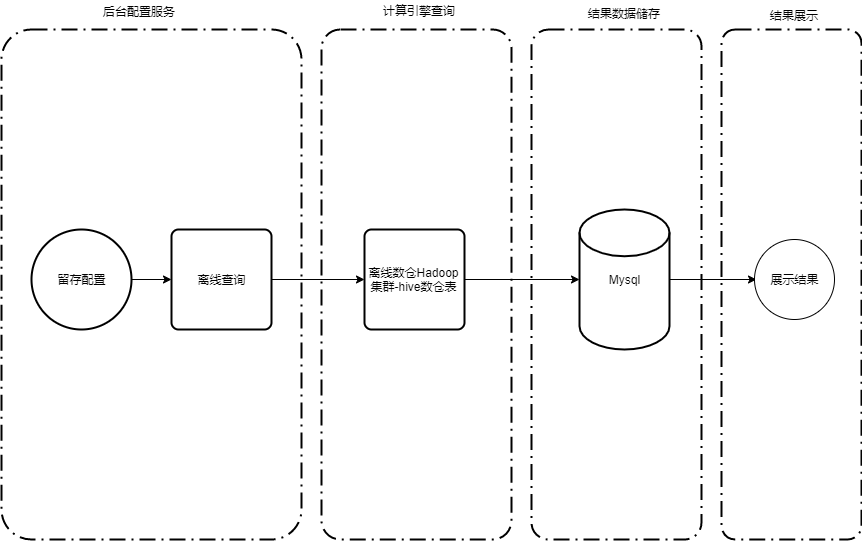
Abbildung 3 Hive-Architekturdiagramm des Aufbewahrungsanalysemodells
Die Gesamtarchitektur ist hauptsächlich in vier Phasen unterteilt: Konfiguration, Berechnung, Speicherung und Anzeige.
1. Konfiguration
In dieser Phase geht es hauptsächlich um die Implementierung von Hintergrunddiensten auf der Engineering-Seite. Benutzer können Startereignisse und Wiederbesuchsereignisse, Filterbedingungen, Benutzergruppenfilterung, Dimensionsfilterung und andere Konfigurationen entsprechend ihren eigenen Anforderungen auf der Plattform festlegen. Nach Erhalt der Konfigurationsanforderung wählt der Hintergrunddienst je nach Aufbewahrungsanalysetyp verschiedene Aufgabenassembler aus, um die SQL-Aufgaben zusammenzustellen.
2. Berechnung
Basierend auf der empfangenen Abfragemethode wählt die Plattform die Offline-Abfrage-Spark-Engine zur Analyse und Berechnung aus. Offline-Berechnungsergebnisse werden mit MySQL synchronisiert.
3. Lagerung
Der Offline-Ergebnissatz wird in der MySQL-Datenbank gespeichert und kann dem Benutzer über den Hintergrunddienst angezeigt werden.
4. Anzeige
Die Offline-Ergebnisse werden entsprechend der Diagrammkonfigurations-ID angezeigt, indem die MySQL-Ergebnistabellendaten abgefragt werden. Die sofortige Abfrage wird direkt nach der Konfiguration abgefragt und angezeigt.
4.2 (Offline) Implementieren Sie SQL unter verschiedenen Aufbewahrungsbedingungen
Universelle Offline-Ausführung von Hive-Task-SQL
SQL zur Offline-Aufbewahrungsstrukturausführung
Die Bedeutung der Felder in SQL ist:
[origin_day]: Startdatum der Aufbewahrungsberechnung
[Tag]: Datum der endgültigen Berechnung des Selbstbehalts
[diff]: An welchem Tag gespeichert werden soll
[Benutzer]: Anzahl der Startbenutzer
【Aufbewahrung】: Aufbewahrungsnummer
Die obige SQL-Bedeutung: Fragen Sie die detaillierten Aufbewahrungsdaten jedes Tages im Intervall vom Startdatum der Aufbewahrungsberechnung bis zur Startzeit und Endzeit ab. Die vollständigen Aufbewahrungsdaten im Zeitintervall können nicht auf einmal berechnet werden mehrere Tage, und das Ergebnis dieser SQL-Ausführung wird als umgedrehtes Dreieck in der Tabelle der beibehaltenen Ergebnisse angezeigt.
Beispiel: Nachdem wir das Startereignis und das Gegenbesuchsereignis festgelegt haben, berechnen wir die 3-tägige Aufbewahrung für jeden Tag vom 01.05.2022 bis zum 05.05.2022. Zu diesem Zeitpunkt ist die Startzeit der 01.05.2022 und die Endzeit ist der 05.05.2022, die Aufbewahrungsfrist beträgt 3 Tage.
In diesem Fall sollte das Startdatum der Aufbewahrungsberechnung der Zeitraum 2022-05-01 bis 2022-05-08 sein, sodass die dreitägige Aufbewahrung für jeden Tag vom 2022-05-01 bis 2022-05-05 berechnet werden kann.
Schritt 1 : Berechnen Sie das Startdatum der Aufbewahrung = 01.05.2022, und der endgültige Datumsbereich für die Aufbewahrungsberechnung sind die täglichen Aufbewahrungsdaten vom 01.05.2022 bis zum 05.05.2022. Aus zeitlicher Sicht das Startdatum der Aufbewahrungsberechnung Es kann nur die Retention am 01.05.2022 berechnet werden. Die Ergebnisse nach der Ausführung sind wie folgt (Tabelle 3):

Tisch 3
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表4):
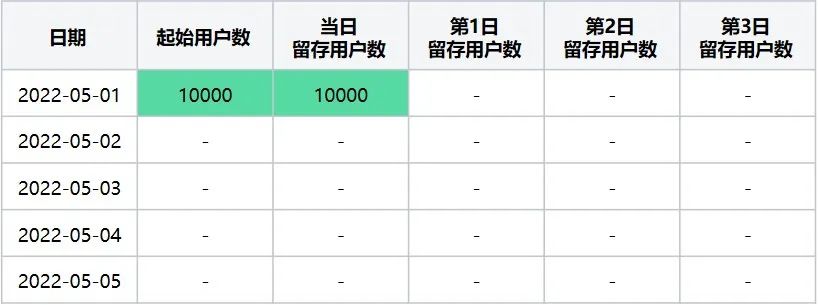
表4
起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内转换后留存数据表
第二步:计算起始留存日期 = 2022-05-02时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第1日留存用户数及2022-05-02日当日留存用户数据,执行后结果如下(表5):

表5
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表6):
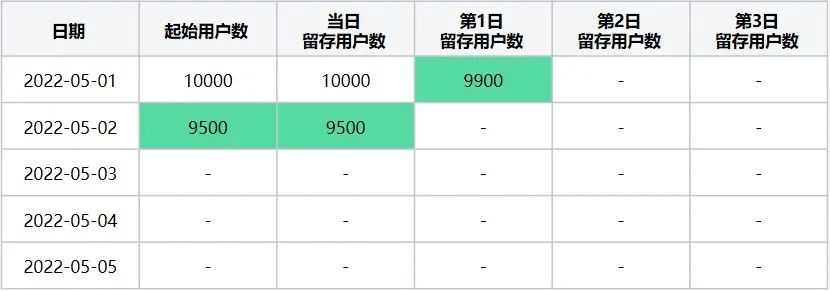
表6
起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内转换后留存数据表
第三步:计算起始留存日期 = 2022-05-03时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第2日留存用户数、2022-05-02日第1日留存用户数据、2022-05-03日当日留存用户数据,执行后结果如下(表7):
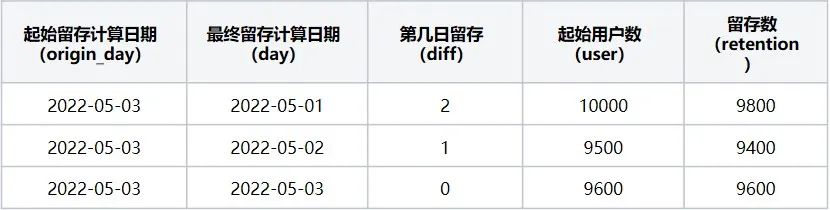
表7
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表8):
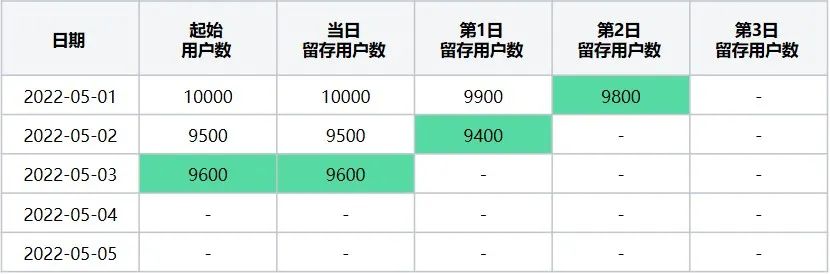
表8
起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内转换后留存数据表
第四步:以此类推,计算起始留存日期 = 2022-05-08时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-05日的第3日留存用户数,执行后结果如下(表9):

表9
起始留存计算日期2022-05-08在2022-05-01~2022-05-05区间内留存详情数据
最终数据展示完全后会是一个完整的表格(可得如下结果表10):
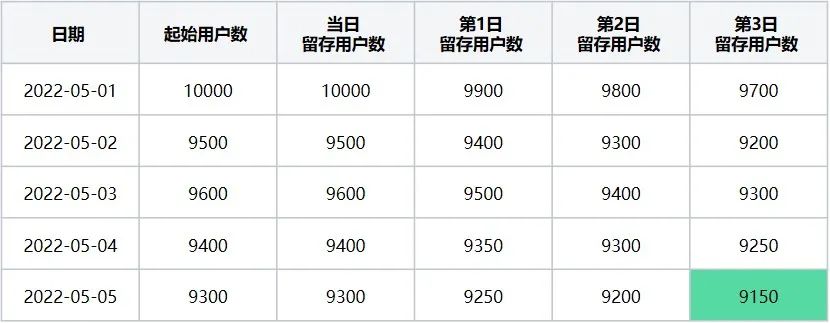
表10
2022-05-01~2022-05-05的每一天的3日留存数据表
4.3 存在的问题与下一步优化的方向
存在的问题:
用户在平台上进行报表创建后,在产出报表结果上耗时较长;当配置报表查询周期长,数据量大的情况下,存在计算资源消耗过大的情况。
优化方向:
为了优化报表生成过程,可以考虑使用ClickHouse来处理数据。ClickHouse是一个高性能、分布式、列式存储的数据库系统,特别适合处理大规模数据和复杂查询。
具体而言,可以采用以下ClickHouse特性:
将数据导入ClickHouse中,以便更快地查询和计算。ClickHouse支持高效的数据导入和压缩方式,可以大大减少数据的存储空间和查询时间。
利用ClickHouse的列式存储和分布式计算能力,实现增量计算和数据预处理。通过使用ClickHouse的分布式计算能力,可以将计算任务分配给多个节点并行处理,从而加快计算速度。同时,通过使用ClickHouse的列式存储能力,可以避免不必要的数据读取和计算,提高计算效率。
利用ClickHouse的缓存机制,提高查询效率。ClickHouse支持高效的缓存机制,可以将查询结果缓存在内存中,以便更快地响应查询请求。
利用ClickHouse的SQL查询语言,实现灵活的数据分析和报表生成。ClickHouse支持SQL查询语言,可以方便地进行数据分析和报表生成,同时也支持复杂查询和聚合操作,可以满足各种数据分析需求。
通过利用ClickHouse上述特性,进一步提高整个数据分析过程的效率和准确性。
五、基于ClickHouse的留存分析模型
5.1 利用ClickHouse查询速度快的特性改造离线留存图表产出方式
利用ClickHouse进行实时留存查询
传统的离线留存计算通常需要借助Hadoop、Spark等大数据处理框架,需要消耗大量计算资源和时间。而利用ClickHouse进行离线留存计算,可以大大提高计算速度和效率,可以实现秒级响应和高并发查询。
具体步骤如下:
将用户行为数据导入ClickHouse;
根据查询配置数据组装留存SQL用于查询;
利用ClickHouse的高速查询功能,实时查询留存率数据。
利用ClickHouse进行留存图表的产出
利用ClickHouse进行留存计算和查询后,可以通过数据可视化工具对留存数据进行图表化展示,从而更加直观地了解用户留存情况。例如:
利用数据可视化工具连接ClickHouse数据库,查看留存率数据或者通过http请求查询结果表数据;
通过数据可视化工具绘制留存图表,并进行定制化设计和样式调整。
结合hive、ClickHouse两者优点,可将架构做如下优化,对于历史较长时间日期的结果回溯进行hive查询处理,可在ClickHouse中存储的数据作为每天例行查询存储结果。
例行:是指创建一次图表每日例行执行报表任务,产出数据(例行可回溯ClickHouse中存储日期的留存数据)。
手动:是指在指定时间范围内执行,执行完成产出任务停止。
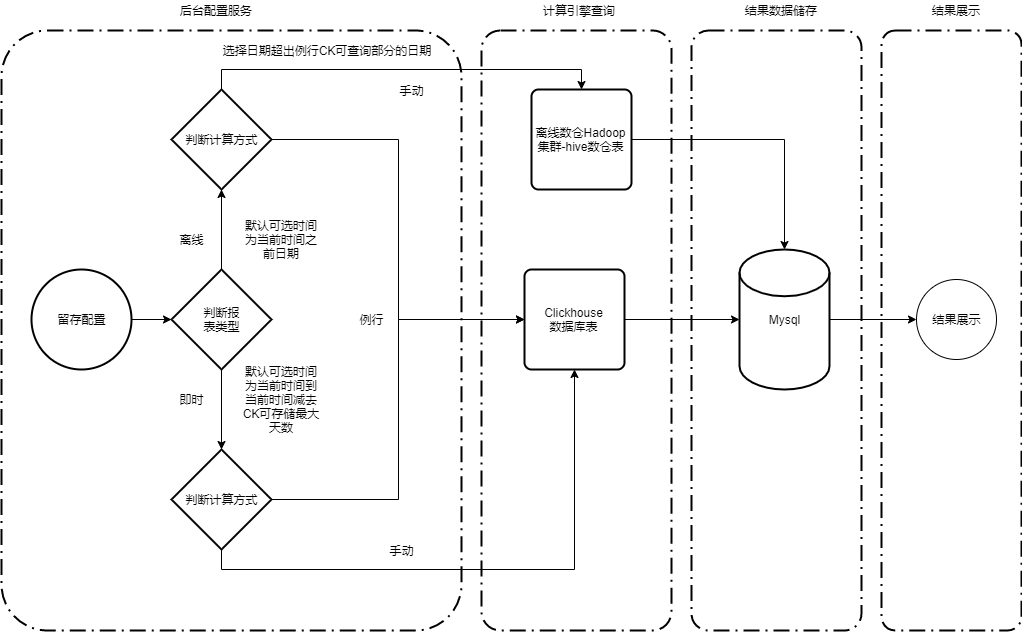
图4 结合ClickHouse、hive后留存分析模型架构图
5.2 主要函数介绍
Retention
该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如 WHERE)。
除了第一个以外,条件成对适用:如果第一个和第二个是真的,第二个结果将是真的,如果第一个和第三个是真的,第三个结果将是真的,等等。
① 语法
retention(cond1, cond2, ..., cond32);
② 参数
cond — 返回 UInt8 结果(1或0)的表达式。
③ 返回值
数组为1或0。
1 — 条件满足。
0 — 条件不满足。
④ 类型
UInt8
ClickHouse查询SQL
ClickHouse即时查询留存SQL
SQL 当中返回结果含义分别为:
retention_date:留存日期
user:起始用户数
retain0:当日留存用户数
retain1:第1日留存用户数
retain2:第2日留存用户数
retain3:第3日留存用户数
ratio0:当日留存率
ratio1:第1日留存率
ratio2:第2日留存率
ratio3:第3日留存率
以上SQL含义:计算出指定时间区间内3日留存信息,可一次性查询出指定区间内的所有3日留存数据,一个sql即可查询完全。
例如:我们定了起始事件和回访事件后,去计算2022-06-01~2022-06-04的每一天的3日留存,此时,起始时间是2022-06-01,结束2022-06-04,留存天数3天。
针对此案例,在不同的日期查询数据完整性不一致,我们拿2022-06-04日和2022-06-07日两日查询举例。
第一步:针对2022-06-04日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表11)。

表11
2022-06-04日计算2022-06-01~2022-06-04的每一天的3日留存数据表
第二步:针对2022-06-07日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表12)。

表12
2022-06-08日计算2022-06-01~2022-06-04的每一天的3日留存数据表
趋势结果展示(图5):
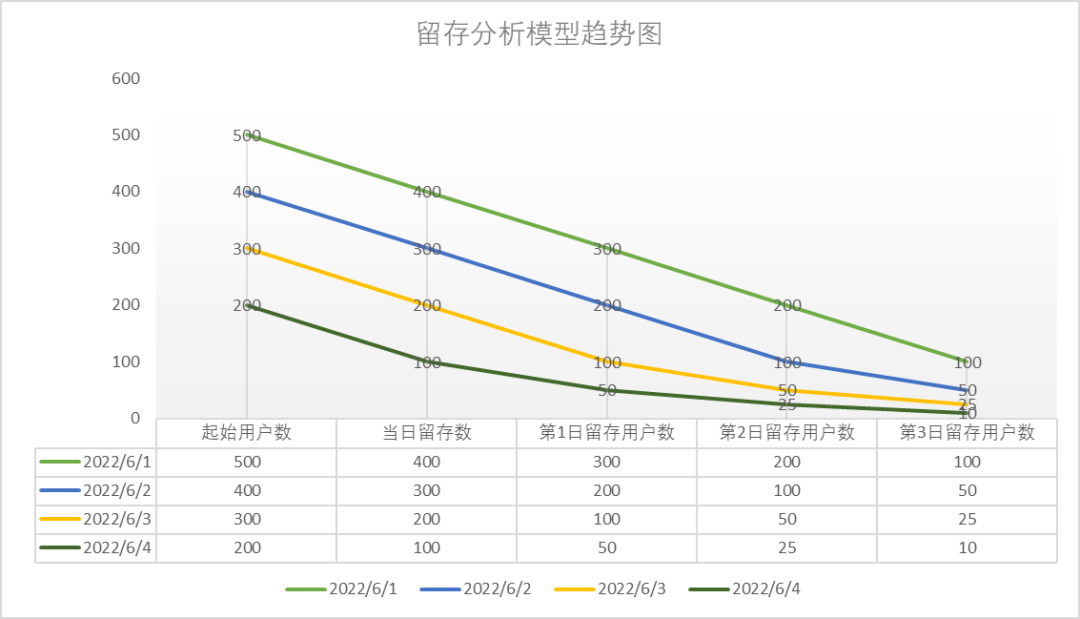
图5 留存分析模型趋势图
六、写在最后
本文介绍的留存模型就是数据分析工具箱的核心分析模型,使用的范围十分广泛。它通过计算用户在一段时间内的留存率,可以评估产品、服务或应用程序的用户体验和吸引力,提高用户留存率和活跃度。在实际的生产中,业务可根据自身具体需求和用户特征进行定制化设计,同时也可将通过留存分析得到的人群信息结合其他的数据分析方法进一步的深入分析。例如,从留存中得到的用户人群信息,我们可以进一步的使用路径分析的分析方法,分析用户的访问行为对于产品的影响。
数据分析的工具方法有很多,除了上面提到过得用于分析用户在应用上的访问行为的用户路径分析;也有衡量业务中关键事件之间转化效果的漏斗分析;还有事件分析、归因分析等等,他们共同组成的强大的数据分析工具箱,可以较为全面的分析用户行为的潜在特征与规律,帮助产品或者决策者作为更加可靠的决策。
END
猜你喜欢
本文分享自微信公众号 - vivo互联网技术(vivoVMIC)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。