

In diesem Artikel wird die Unterstützung der Databend-Engine für offene Tabellenformate vorgestellt, einschließlich Vor- und Nachteilen, Verwendungsmethoden und Vergleich mit der Kataloglösung. Darüber hinaus ist ein einfacher Workshop enthalten, der eine Einführung in die Verwendung von Databend Cloud zur Analyse der im Objektspeicher befindlichen Delta-Tabelle bietet.
Databend hat kürzlich zwei Tabellen-Engines veröffentlicht, Apache Iceberg und Delta Table, um die beiden beliebtesten offenen Tabellenformate zu unterstützen und den erweiterten Analyseanforderungen moderner Data-Lake-Lösungen basierend auf unterschiedlichen Technologie-Stacks gerecht zu werden.
Mit einer One-Stop-Lösung auf Basis von Databend/Databend Cloud können Sie Einblicke in offene Tabellendaten gewinnen und die Bereitstellungsarchitektur und den Analyseprozess vereinfachen, ohne zusätzliche Spark/Databricks-Dienste zu aktivieren. Darüber hinaus können Sie mit der auf Apache OpenDAL™ basierenden Datenzugriffslösung von Databend / Databend Cloud problemlos auf Dutzende von Speicherdiensten zugreifen, darunter Objektspeicher, HDFS und sogar IPFS, und diese problemlos in bestehende Technologie-Stacks integrieren.
Vorteil
-
Wenn Sie die offene Tabellenformat-Engine verwenden, müssen Sie nur den Typ (
DeltaoderIceberg) der Tabellen-Engine und den Speicherort der Datendatei angeben. Sie können dann direkt auf die entsprechende Tabelle zugreifen und Databend zum Abfragen verwenden. -
Mit der offenen Tabellenformat-Engine von Databend können Sie problemlos Szenarien bewältigen, in denen Sie verschiedene Datenquellen und Daten in verschiedenen Tabellenformaten mischen:
- Unter demselben Datenbankobjekt können Sie Datentabellen abfragen und analysieren, die in verschiedenen Formaten zusammengefasst sind.
- Mit der umfassenden Speicher-Backend-Integration von Databend können Sie Datenzugriffsanforderungen in verschiedenen Speicher-Backends bewältigen.
unzureichend
- Derzeit unterstützen die Apache Iceberg- und Delta Lake-Engines nur schreibgeschützte Vorgänge, das heißt, sie können nur Daten abfragen, aber keine Daten in die Tabelle schreiben.
- Das Schema der Tabelle wird beim Erstellen der Tabelle festgelegt. Wenn das Schema der Originaltabelle geändert wird, muss die Tabelle in Databend neu erstellt werden, um die Datenkonsistenz und -synchronisierung sicherzustellen.
Anweisungen
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
Tipp: Verwenden Sie Databend,
CONNECTIONum die Details zu verwalten, die für die Interaktion mit externen Speicherdiensten erforderlich sind, z. B. Zugangsdaten, Endpunkt-URLs und Speichertypen. Durch die AngabeCONNECTION_NAMEkönnen Sie es beim Erstellen von Ressourcen wiederverwendenCONNECTIONund so die Verwaltung und Nutzung von Speicherkonfigurationen vereinfachen.
Vergleich mit Kataloglösung
Databend hat zuvor Iceberg und Hive über Catalog unterstützt. Im Vergleich zu Tabellen-Engines eignet sich Catalog besser für die vollständige Docking-Ökologie und die gleichzeitige Bereitstellung mehrerer Datenbanken und Tabellen.
Die neue Open-Table-Format-Engine ist hinsichtlich der Erfahrung flexibler, unterstützt die Aggregation und Mischung von Daten aus verschiedenen Datenquellen und verschiedenen Tabellenformaten unter derselben Datenbank und führt effektive Analysen und Erkenntnisse durch.
Workshop: Verwenden Sie Databend Cloud, um Daten in Delta Table zu analysieren
Dieses Beispiel zeigt, wie Sie Databend Cloud zum Laden und Analysieren einer Delta-Tabelle im Objektspeicher verwenden.
Wir werden den klassischen Pinguin-Körpermerkmalsdatensatz (Pinguine) verwenden, ihn in eine Delta-Tabelle konvertieren und in einem S3-kompatiblen Objektspeicher ablegen. Dieser Datensatz enthält insgesamt 8 Variablen, darunter 7 Merkmalsvariablen und 1 kategoriale Variable, mit insgesamt 344 Stichproben.
- Bei den kategorialen Variablen handelt es sich um Pinguinarten (Arten), die zu drei Untergattungen der Gattung Hartschwanzpinguin gehören , nämlich Adélie, Zügelpinguin und Eselspinguin.
- Die sechs Merkmale der drei enthaltenen Pinguine sind Insel (Insel), Schnabellänge (bill_length_mm), Schnabeltiefe (bill_length_mm), Flossenlänge (flipper_length_mm), Körpergewicht (body_mass_g) und Geschlecht (sex).
Wenn Sie noch kein Databend Cloud-Konto haben, besuchen Sie bitte https://app.databend.cn/register, um sich zu registrieren und ein kostenloses Kontingent zu erhalten. Oder Sie können auf https://docs.databend.com/guides/deploy/ verweisen , um Databend lokal bereitzustellen.
In diesem Artikel wird auch die Verwendung von Objektspeicher behandelt. Sie können auch versuchen, einen Bucket mit Cloudflare R2 mit kostenlosem Kontingent zu erstellen.
Daten in den Objektspeicher schreiben
Wir müssen das entsprechende Python-Paket installieren, seaborndas für die Bereitstellung von Rohdaten, deltalakedie Konvertierung der Daten in eine Delta-Tabelle und das Schreiben in S3 verantwortlich ist:
pip install deltalake seaborn
Bearbeiten Sie dann den folgenden Code, konfigurieren Sie die entsprechenden Zugangsdaten und speichern Sie ihn als writedata.py:
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
Führen Sie das obige Python-Skript aus, um Daten in den Objektspeicher zu schreiben:
python writedata.py
Greifen Sie mit der Delta-Tabellen-Engine auf Daten zu
Erstellen Sie entsprechende Zugangsdaten in Databend:
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
Erstellen Sie eine Datentabelle mit der Delta-Tabellen-Engine:
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
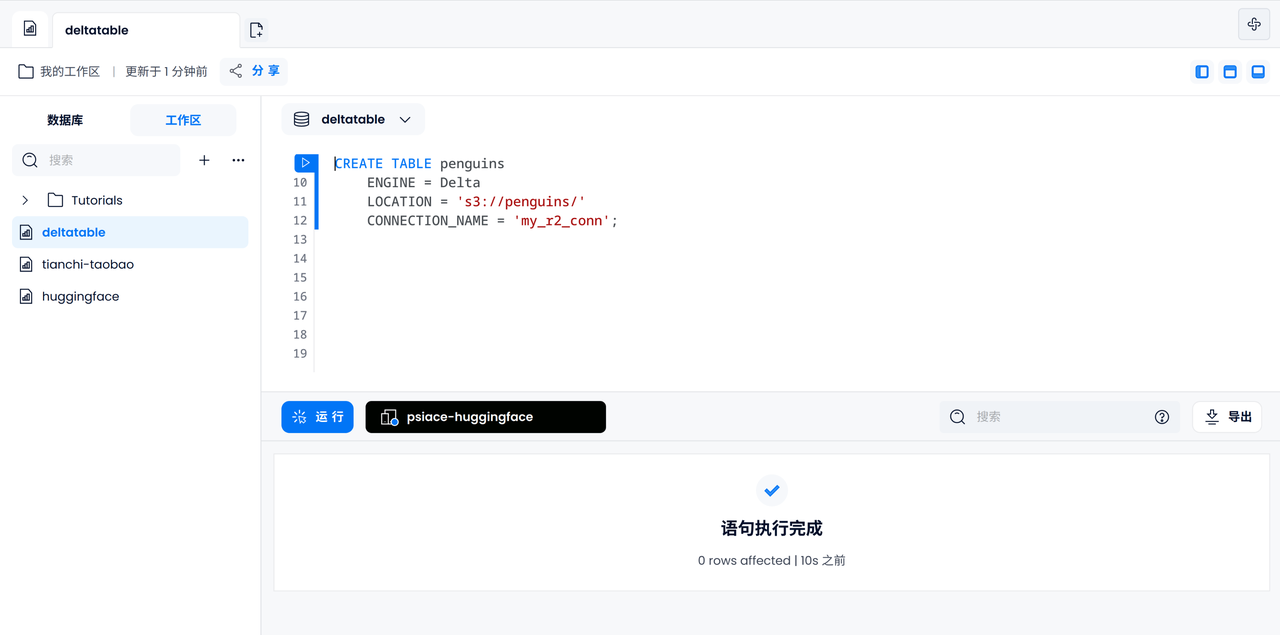
Verwenden Sie SQL, um Daten in Tabellen abzufragen und zu analysieren
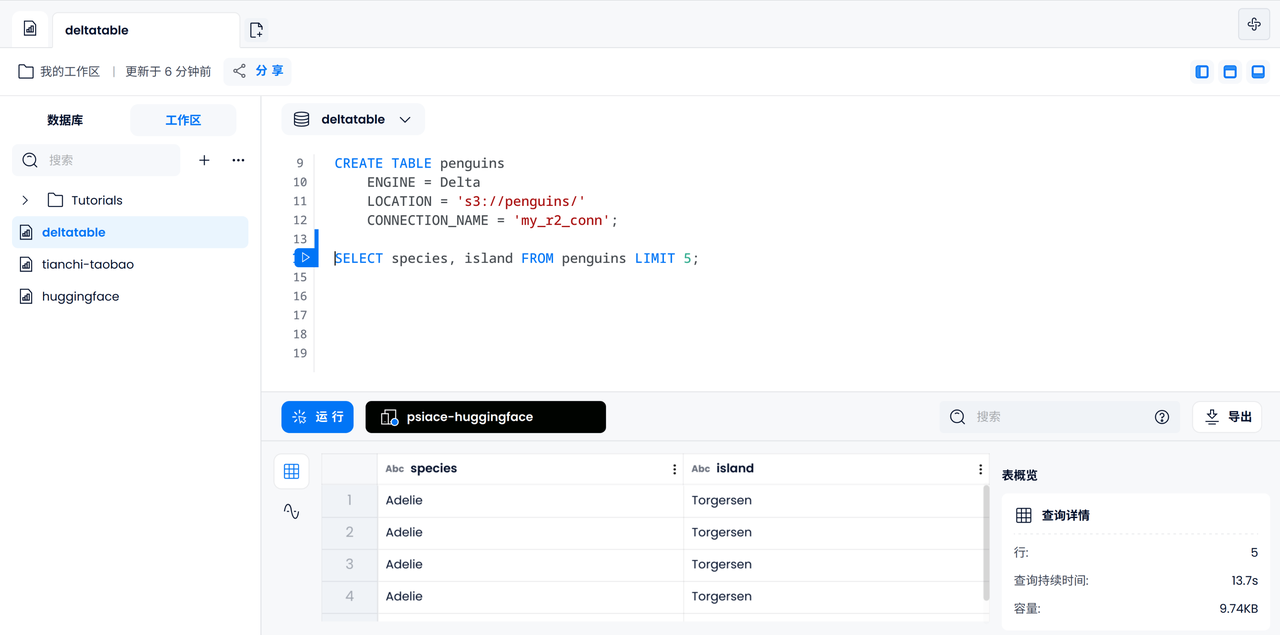
Überprüfen Sie die Datenzugänglichkeit
Lassen Sie uns zunächst die Arten und Inseln der 5 Pinguine ausgeben, um zu prüfen, ob auf die Daten in der Delta-Tabelle korrekt zugegriffen werden kann.
SELECT species, island FROM penguins LIMIT 5;
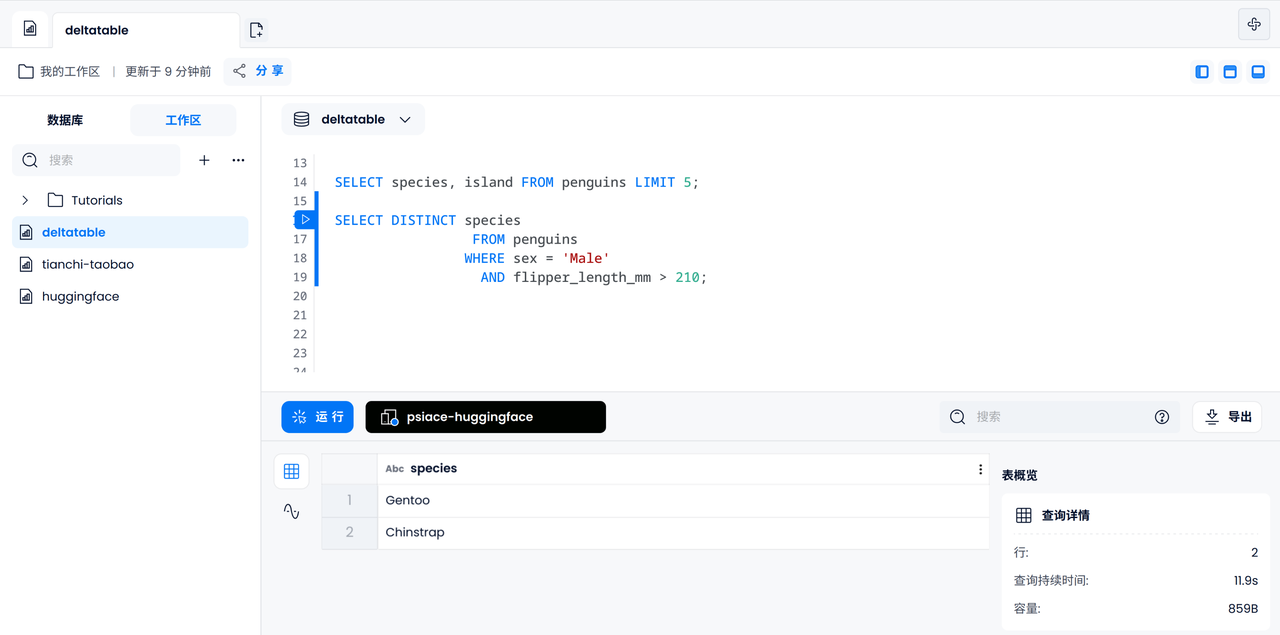
Datenfilterung
Als Nächstes können Sie einige grundlegende Datenfilterungsvorgänge durchführen, z. B. herausfinden, zu welcher Untergattung männliche Pinguine mit Flossenlängen über 210 mm gehören könnten.
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
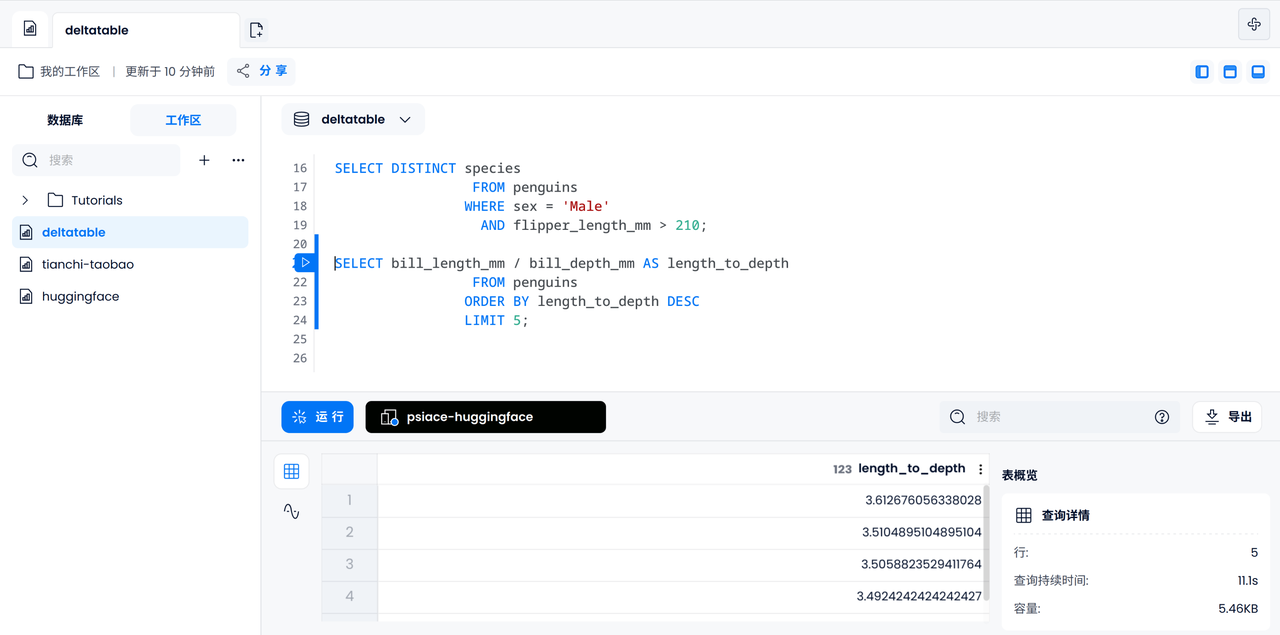
Datenanalyse
Ebenso könnten wir versuchen, das Verhältnis von Schnabellänge und -tiefe für jeden Pinguin zu berechnen und die fünf größten auszugeben.
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
Fall mit gemischter Datenquelle: Pinguin-Beobachtungsprotokoll
Jetzt kommen wir zu einem interessanten Teil: Angenommen, wir finden einen Beobachtungsdatensatz von einer wissenschaftlichen Forschungsstation, versuchen wir, diese Daten in dieselbe Datenbank einzugeben und eine einfache Datenanalyse durchzuführen: Was ist der Vogel eines bestimmten Geschlechts? Wahrscheinlichkeit, dass ein Pinguin von einem Wissenschaftler markiert wird.
Erstellen Sie eine Beobachtungsprotokolltabelle
Verwenden Sie die standardmäßige FUSE-Engine penguin_observations, um eine Tabelle mit ID, Datum, Name, Pinguinart und -geschlecht, Anmerkungen und anderen Informationen zu erstellen.
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
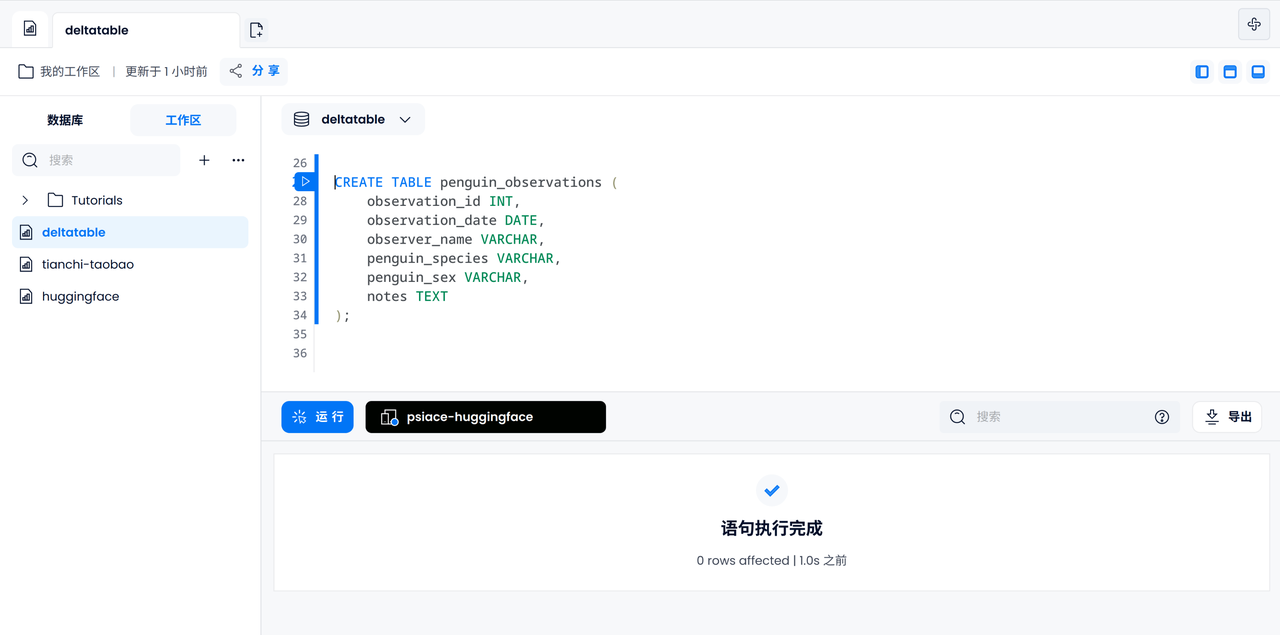
Beobachtungsprotokoll eingeben
Versuchen wir, alle 10 Protokolle manuell einzugeben. Es ist bekannt, dass sich Pinguine, die in Protokollaufzeichnungen auftauchen, voneinander unterscheiden.
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
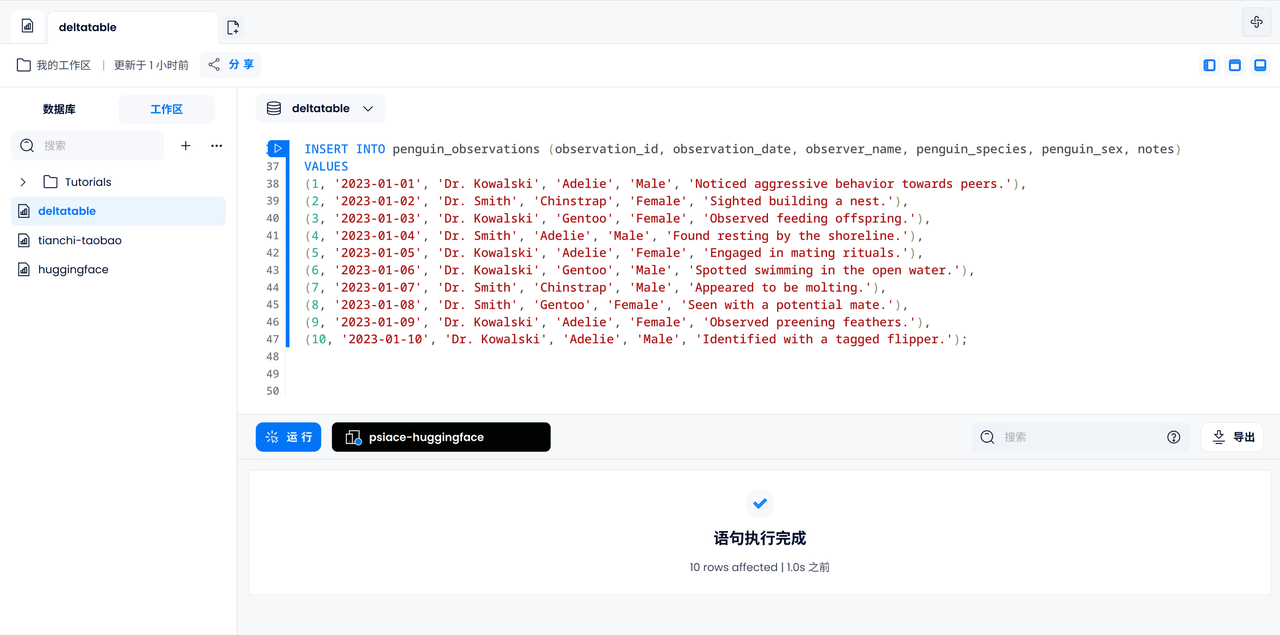
Berechnen Sie die Markierungswahrscheinlichkeit
Berechnen wir nun die Wahrscheinlichkeit, dass Dr. Kowalski unter allen Pinguinen einen bestimmten männlichen Adeliepinguin beobachtet. Zuerst müssen wir die Anzahl der von Dr. Kowalski beobachteten männlichen Adeliepinguine zählen, dann die Anzahl aller erfassten männlichen Adeliepinguine zählen und schließlich dividieren, um das Ergebnis zu erhalten.
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
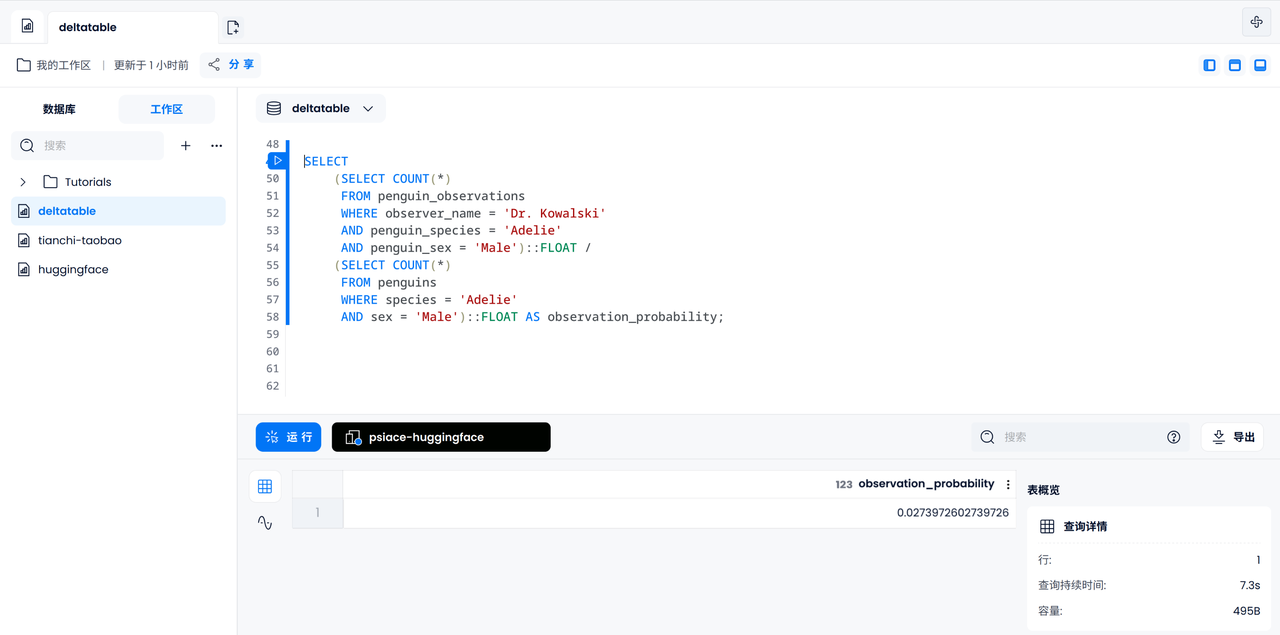
Zusammenfassen
Durch die Kombination verschiedener Tabellen-Engines für Abfragen kann Databend/Databend Cloud das Mischen von Tabellen unterschiedlicher Formate in derselben Datenbank für Analyse und Abfrage unterstützen. Dieser Artikel bietet nur einen grundlegenden Workshop, in dem jeder die Funktionen und die Verwendung kennenlernen kann. Sie können diesen Artikel gerne erweitern und weitere Szenarien für die Kombination von Iceberg und Delta Table für die Datenanalyse sowie weitere potenzielle Anwendungen in der Praxis erkunden.