
01 Hintergründe auf einen Blick
In dem Szenario, in dem Zeitreihendaten in die Datenbank geschrieben werden, kann es aufgrund von Problemen wie Netzwerkverzögerungen vorkommen, dass der Zeitstempel der zu schreibenden Daten kleiner ist als der maximale Zeitstempel der geschriebenen Daten Daten werden zusammenfassend als Out-of-Order-Daten bezeichnet. Die Generierung von Daten außerhalb der Reihenfolge ist fast unvermeidlich. Gleichzeitig wirkt sich das Schreiben von Daten außerhalb der Reihenfolge auf die Sortierung und Abfrage aller Daten aus. Daher müssen wir das Schreiben von Daten außerhalb der Reihenfolge unterstützen. Bestelldaten und unterstützen auch die Out-of-Order-Datenabfrage.
02 Prozessübersicht
Bei der Verarbeitung von Out-of-Order-Daten werden Out-of-Order-Daten innerhalb eines bestimmten Zeitfensters (z. B. 10 Minuten oder 1 Stunde) gemäß der Deduplizierungsstrategie verarbeitet und gespeichert, Out-of-Order-Daten außerhalb dieser Zeit Fenster wird verworfen. Die folgende Abbildung zeigt den grundlegenden Prozess zum Schreiben von Daten außerhalb der Reihenfolge:

Darunter müssen drei wichtige Punkte geklärt werden:
- Das Zeitfenster bezieht sich auf einen Zeitraum vor dem Zeitpunkt des letzten Datenzeitstempels in der Tabelle. Wenn keine neuen Daten in die Tabelle geschrieben werden, ändert sich ihr Zeitfenster nicht.
- In der Konfigurationsdatei gibt es einen Parameter: ts_st_iot_disorder_interval, der zur Unterstützung des Zeitfensters zum Schreiben von Out-of-Order-Daten verwendet wird, Einheit: Sekunden. Der Wert dieses Konfigurationselements darf den Partitionsintervallwert nicht überschreiten.
- Die Grundlage für die Beurteilung, ob die Daten nicht in Ordnung sind, besteht darin, dass der Zeitstempel der geschriebenen Daten kleiner oder gleich dem maximalen Zeitstempel aller im geschriebenen Tabellenobjekt gespeicherten Daten ist.
03 Szenariobeispiel
1. Normaler Schreibvorgang
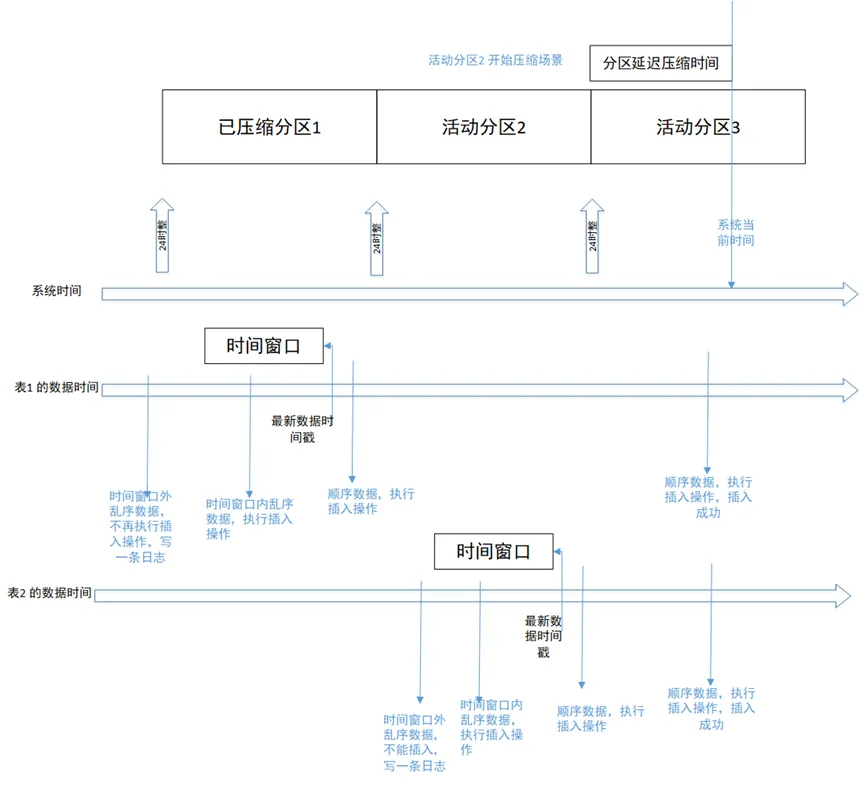
Die Zeit ist in zwei Zeilen unterteilt: Systemzeit und Datenzeit. Die Datenzeit ist für jede Tabelle unterschiedlich und daher in zwei Zeilen unterteilt: die Datenzeit von Tabelle 1 und die Datenzeit von Tabelle 2.
-
Szenario 1: Das Szenario des sequentiellen Schreibens von Daten vor zwei Tagen ist in der Abbildung oben dargestellt. Das Szenario des sequentiellen Schreibens in die historische Partition 1. Die geschriebenen sequentiellen Daten werden in der entsprechenden Partition gespeichert Die Partition schlägt fehl und löst einen Fehler aus.
-
Szenario 2: Schreiben von Daten außerhalb der Reihenfolge innerhalb des Zeitfensters Wie in der Abbildung oben dargestellt, schreibt Tabelle 2 Daten außerhalb der Reihenfolge innerhalb des Zeitfensters. Die geschriebenen Daten werden in der aktiven Partition 2 gespeichert, die verarbeitet wird In einem anderen Thread sind auch Schreibvorgänge erfolgreich.
-
Szenario 3: Schreiben von Out-of-Order-Daten, die das Zeitfenster überschreiten. Wenn die Datenbank die Komprimierungsfunktion aktiviert und das Out-of-Order-Zeitfenster auf 1 Stunde konfiguriert, werden Out-of-Order-Daten geschrieben, die eine Stunde früher liegen als der Zeitstempel des letzten Datensatzes in der Tabelle, schlägt fehl. Die geschriebenen Daten werden herausgefiltert und in das Protokoll geschrieben.
2. Prozess zum Importieren von Daten
In den importierten Daten können auch Daten außerhalb der Reihenfolge enthalten sein. In diesem Szenario entspricht die Verarbeitung nicht ordnungsgemäßer Daten dem normalen Schreibvorgang.
-
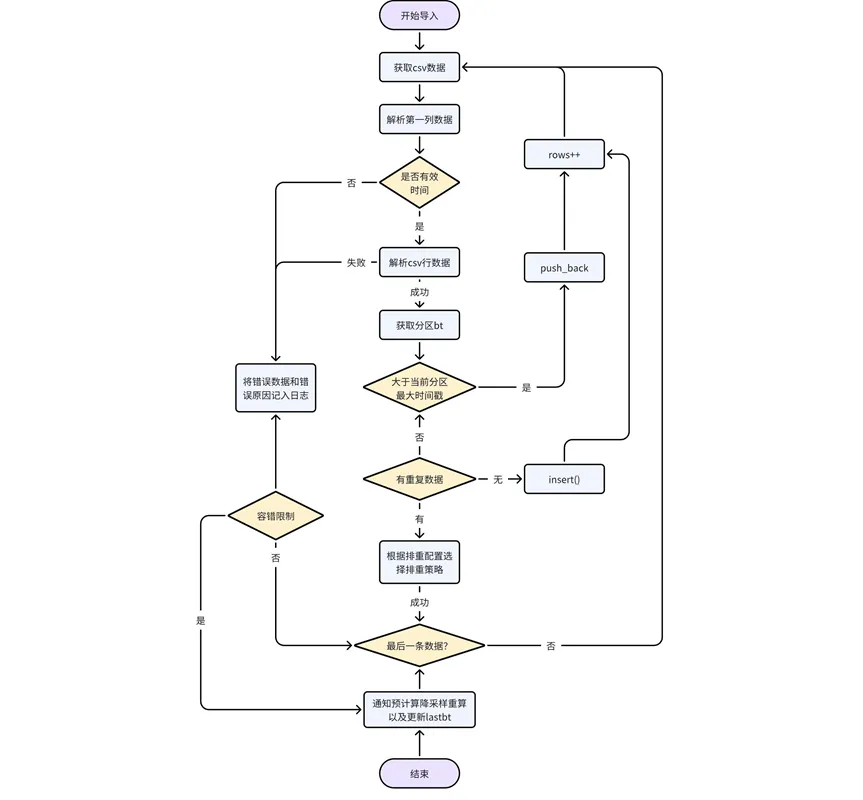
Verarbeitung der Daten selbst: Analysieren Sie die Daten in der CSV-Datei Zeile für Zeile, bestimmen Sie, ob die erste Datenspalte ein gültiger Zeit-/Zeitstempeltyp ist, und geben Sie einen Fehler zurück, wenn es sich nicht um gültige Zeitdaten handelt, bestimmen Sie die Partition; zu der die Daten gehören, und erhalten Sie die Partition bt. Wenn der Datenzeitstempel größer ist als der maximale Zeitstempel der vorhandenen Daten in der aktuellen Partition, wird ein direkter Pushback durchgeführt. Andernfalls müssen die Daten außerhalb der Reihenfolge gemäß der Deduplizierungskonfigurationslogik verarbeitet werden.
-
Passen Sie die Downsampling- und Vorberechnungslogik an: Während des Datenimportvorgangs müssen Sie den Datensatzstatus der URL in der Systemaufgabentabelle kaiwudb_jobs auf „abgelaufen“ aktualisieren, die Vorberechnung/Downsampling benachrichtigen, die betroffenen Daten neu berechnen/verarbeiten oder Warten Sie auf den nächsten Schritt. Eine Vorberechnungsaufgabe wird neu berechnet, wenn sie vom System geplant wird.
Nach Abschluss des Imports werden Vorberechnung und Downsampling benachrichtigt, um die Ergebnisse neu zu berechnen oder zu aktualisieren und lastbt zu aktualisieren.
3. Downsampling-Prozess
Nachdem die Daten außerhalb der Reihenfolge geschrieben wurden, müssen die Downsampling-Ergebnisse basierend auf den neuesten Daten aktualisiert werden.

-
Verarbeitung von in historische Partitionen importierten Daten außerhalb der Reihenfolge: Aktualisieren Sie beim Importieren von Daten außerhalb der Reihenfolge, die zu historischen Partitionen gehören, den Datensatzstatus von url=[Datenbank/Partition/Tabellenname] in der Systemaufgabentabelle kaiwudb_jobs auf abgelaufen Anschließend wird die Partitionstabelle entsprechend der Abtastregelverarbeitung erneut heruntergeladen.
-
Einfügung verarbeiten und historische Partitionsdaten schreiben: Wenn Sie die historische Partition der Einfügungsdatentabelle dekomprimieren, aktualisieren Sie den Datensatzstatus von url=[Datenbank/Partition/Tabellenname] in der Systemaufgabentabelle kaiwudb_jobs auf abgelaufen, und die Partitionstabelle wird erneut aktualisiert. entspricht in Zukunft der Verarbeitung von Downsampling-Regeln.
4. Nachdem die Daten außerhalb der Reihenfolge im Vorberechnungsprozess geschrieben wurden, müssen die Vorberechnungsergebnisse basierend auf den neuesten Daten aktualisiert werden.
-
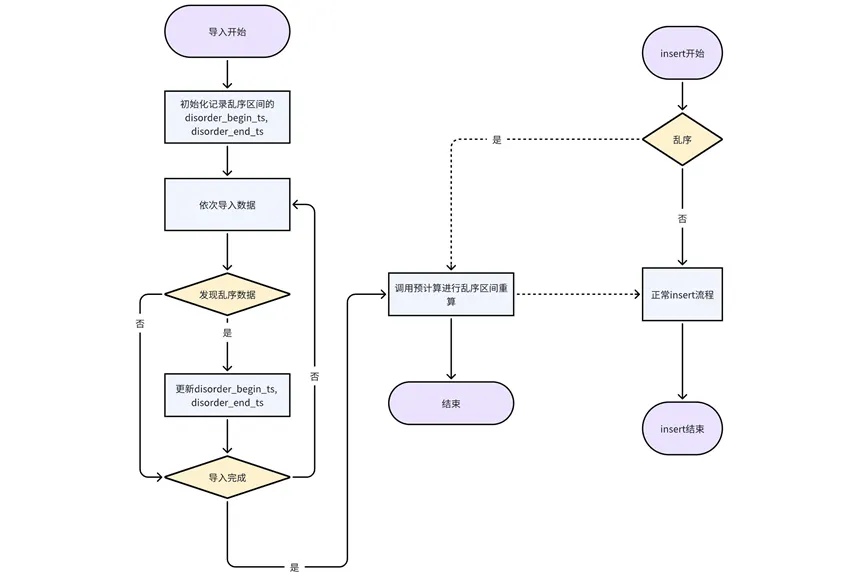
Verarbeiten Sie die Einfügung und schreiben Sie Daten außerhalb der Reihenfolge: Fügen Sie jedes Mal ein, wenn ein Teil der Daten außerhalb der Reihenfolge in der Einfügung erscheint. Dieser Ansatz kann die Genauigkeit der Vorberechnungsergebnisse in größerem Maße sicherstellen.
-
Verarbeitung importierter Daten außerhalb der Reihenfolge: Der Import wird derzeit in Einheiten von Partitionstabellen verarbeitet. Während des Importvorgangs werden der Startzeitstempel und der Endzeitstempel jeder Partitionstabelle aufgezeichnet Nachdem die Partitionstabelle vollständig ist, wird die Vorberechnungsschnittstelle zur Neuberechnung aufgerufen.
04 Zusammenfassung
Im Szenario der Out-of-Order-Datenverarbeitung sind viele Funktionen und Verknüpfungsmodule beteiligt, die synchronisiert und aktualisiert werden müssen. Wenn die Datenbank über eine vollständige Out-of-Order-Datenverarbeitung verfügt, kann sie sich besser an die Geschäftsszenarien der Benutzer anpassen und die Anwendbarkeit der Datenbank in mehreren Szenarien erheblich verbessern.
Ich beschloss , auf Open-Source -Industriesoftware zu verzichten – OGG 1.0 wurde veröffentlicht, das Team von Ubuntu 24.04 LTS wurde offiziell entlassen ". Fedora Linux 40 wurde offiziell veröffentlicht. Ein bekanntes Spieleunternehmen veröffentlichte neue Vorschriften: Hochzeitsgeschenke von Mitarbeitern dürfen 100.000 Yuan nicht überschreiten. China Unicom veröffentlicht die weltweit erste chinesische Llama3 8B-Version des Open-Source-Modells. Pinduoduo wird zur Entschädigung verurteilt 5 Millionen Yuan für unlauteren Wettbewerb. Inländische Cloud-Eingabemethode – nur Huawei hat keine Sicherheitsprobleme beim Hochladen von Cloud-Daten