
Autor: Chen Xin (Shenxiu)
Hallo zusammen, ich bin Chen Xin, der technische Produktdirektor von Tongyi Lingma. In den letzten acht Jahren habe ich in der Alibaba Group an der F&E-Leistung gearbeitet, also an F&E-Werkzeugarbeiten.
Wir haben 2015 mit dem Aufbau einer One-Stop-DevOps-Plattform begonnen und dann Cloud Effect entwickelt, um die DevOps-Plattform zu cloudisieren. Wir sind davon überzeugt, dass Softwaretools bis 2023 mit umfassenden Innovationen konfrontiert sein werden. Die Kombination aus großen Modellen und Softwaretoolketten wird die Softwareforschung und -entwicklung in die nächste Ära führen.
Wo ist also die erste Station? Tatsächlich handelt es sich um eine Hilfsprogrammierung, daher haben wir mit der Entwicklung des Produkts Tongyi Lingma begonnen , einem KI-Hilfswerkzeug, das auf einem großen Codemodell basiert. Heute nutze ich diese Gelegenheit, um Ihnen einige Details zur Implementierung der Tongyi-Lingma-Technologie mitzuteilen und wie wir die Entwicklung großer Modelle im Bereich der Softwareforschung und -entwicklung sehen.
Ich werde es in drei Teile teilen. Der erste Teil stellt zunächst die grundlegenden Auswirkungen von AIGC auf die Softwareforschung und -entwicklung vor und stellt die aktuellen Trends aus einer Makroperspektive vor. Im zweiten Teil wird das Copilot-Modell vorgestellt, und im dritten Teil wird der Fortschritt zukünftiger Softwareentwicklungsagentenprodukte vorgestellt. Warum ich Copilot Agent erwähnt habe, erkläre ich Ihnen später.
Der grundlegende Einfluss von AIGC auf die Softwareentwicklung
Dieses Bild habe ich in den letzten Jahren gezeichnet. Ich denke, die wichtigsten Einflussfaktoren für die Effizienz von Forschung und Entwicklung in Unternehmen sind diese drei Punkte.
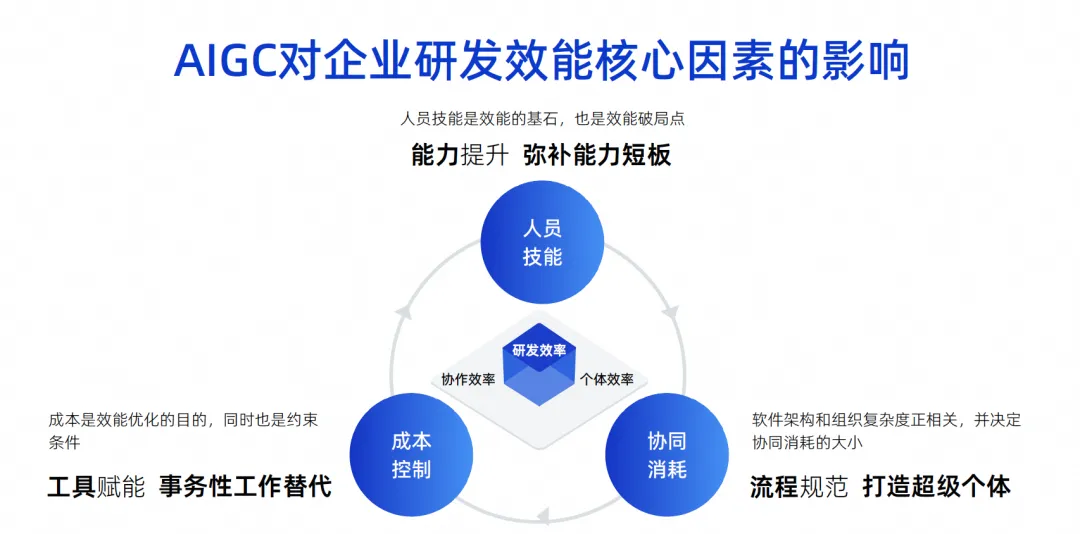
Der erste Punkt ist die soziale Kompetenz. Personalkompetenzen sind ein sehr wichtiger Faktor für die F&E-Effizienz eines Unternehmens. Beispielsweise kann Google Ingenieure rekrutieren, deren persönliche Fähigkeiten zehnmal größer sind als die anderer Fähige Ingenieure verfügen über eine Kampfeffektivität von sehr leistungsfähig und können sogar den gesamten Stapel realisieren. Ihre Rollenverteilung ist möglicherweise sehr einfach, ihre Arbeit ist sehr effizient und ihre Endeffektivität ist ebenfalls sehr groß.
Tatsächlich können jedoch nur wenige unserer Unternehmen, insbesondere chinesische Unternehmen, das Niveau von Google erreichen. Dies ist ein objektiver Einflussfaktor. Wir glauben, dass Personalkompetenzen der Grundstein für die Wirksamkeit sind und natürlich auch der Bruchpunkt der Wirksamkeit.
Der zweite Punkt ist der kollaborative Konsum. Da wir nicht von jedem Ingenieur hohe Fähigkeiten verlangen können, muss jeder über eine professionelle Arbeitsteilung verfügen. Einige sind beispielsweise für das Software-Design zuständig, andere für Entwicklung, Tests und Projektmanagement. Mit zunehmender Komplexität der Softwarearchitektur des aus diesen Personen bestehenden Teams nimmt auch die Komplexität der Organisation zu. Dies führt zu einem Anstieg des kollaborativen Verbrauchs, was letztendlich die Gesamteffizienz von Forschung und Entwicklung verlangsamt.
Der dritte Punkt ist die Kostenkontrolle. Wir haben festgestellt, dass die Leute bei der Arbeit an Projekten nicht immer reich sein können, es immer an Arbeitskräften mangelt und es unmöglich ist, über unbegrenzte Mittel zu verfügen, um die zehnfache Anzahl von Ingenieuren zu rekrutieren, was ebenfalls eine Einschränkung darstellt.
Heute, im Zeitalter der AIGC, haben diese drei Faktoren zu einigen grundlegenden Veränderungen geführt.
Was die Personalkompetenzen betrifft, kann die KI-Unterstützung die Fähigkeiten einiger Nachwuchsingenieure schnell verbessern. Tatsächlich gibt es im Ausland einige Berichte darüber, dass die Wirkung von Code-Assistenztools durch junge Ingenieure deutlich höher ist als die durch leitende Ingenieure. Da diese Werkzeuge einen sehr guten Ersatz für die Einstiegsarbeit bzw. deren Hilfswirkung darstellen, können sie die Defizite junger Ingenieure schnell ausgleichen.
Was den kollaborativen Konsum angeht: Wenn KI heute zu einem Super-Individuum werden kann, wird es tatsächlich hilfreich sein, den prozessbasierten kollaborativen Konsum zu reduzieren. Bei einigen einfachen Aufgaben ist es beispielsweise nicht erforderlich, sich mit Menschen zu befassen, die KI kann dies direkt erledigen und es ist nicht erforderlich, jedem zu erklären, wie die Anforderungen zu testen sind. Die KI kann daher nur einfache Tests durchführen, sodass die Zeiteffizienz verbessert wird . Daher kann der kollaborative Konsum durch Super-Individuen effektiv reduziert werden.
Im Hinblick auf die Kostenkontrolle soll tatsächlich eine große Anzahl von KI-Anwendungen die Transaktionsarbeit ersetzen, einschließlich der aktuellen Verwendung großer Codemodelle zur Codeunterstützung, die voraussichtlich auch 70 % der täglichen Transaktionsarbeit ersetzen wird.
Wenn wir es genauer betrachten, wird es diese vier Herausforderungen und Chancen für Intelligenz geben.

Der erste Punkt ist die individuelle Effizienz. Die sich wiederholende Arbeit und die einfache Kommunikation einer großen Anzahl von Forschungs- und Entwicklungsingenieuren können durch KI erledigt werden.
Ein weiterer Aspekt der Effizienz der Zusammenarbeit besteht darin, dass einige einfache Aufgaben direkt von der KI erledigt werden können, was den Kollaborationsverbrauch reduzieren kann. Ich habe dies gerade klar erklärt.
Der dritte Punkt ist die Erfahrung in Forschung und Entwicklung. Worauf konzentrierte sich die DevOps-Toolkette in der Vergangenheit? Nacheinander bilden sie ein großes Fließband und die gesamte Werkzeugkette. Tatsächlich kann jede Toolkette in verschiedenen Unternehmen unterschiedliche Nutzungsgewohnheiten haben und möglicherweise sogar unterschiedliche Kontosysteme, unterschiedliche Schnittstellen, unterschiedliche Interaktionen und unterschiedliche Berechtigungen haben. Diese Komplexität verursacht für Entwickler sehr hohe Kontextwechselkosten und Verständniskosten, was die Entwickler unsichtbar sehr unzufrieden macht.
Im KI-Zeitalter haben wir jedoch einige Änderungen vorgenommen. Wir können viele Tools über einen einheitlichen Dialogeingang bedienen und sogar viele Probleme im Fenster der natürlichen Sprache lösen.
Lassen Sie mich Ihnen ein Beispiel geben: Was sollten wir tun, wenn wir prüfen, ob in einer SQL-Anweisung ein Leistungsproblem vorliegt? Sie können zuerst die SQL-Anweisung im Code ausgraben, sie in eine ausführbare Anweisung umwandeln und sie dann in ein DMS-System einfügen, um sie zu diagnostizieren, um festzustellen, ob Indizes verwendet werden und ob Probleme vorliegen, und dann manuell beurteilen, ob dies der Fall ist Ändern Sie dieses SQL, um es zu optimieren, und ändern Sie es schließlich in der IDE. Dieser Prozess erfordert den Wechsel mehrerer Systeme und es müssen viele Dinge getan werden.
Wenn wir in Zukunft über Code-Intelligence-Tools verfügen, können wir einen Code einkreisen und das große Modell fragen, ob es ein Problem mit diesem SQL gibt. Dieses große Modell kann einige Tools, wie z. B. das DMS-System, unabhängig zur Analyse aufrufen Die erhaltenen Ergebnisse können mir direkt mitgeteilt werden, wie SQL durch das große Modell optimiert werden soll. Wir müssen es nur übernehmen, um das Problem zu lösen. Die gesamte Betriebsverbindung wird verkürzt, die Erfahrung verbessert und die Forschung und Entwicklung verbessert Die Effizienz wird verbessert.
Das vierte sind digitale Vermögenswerte. In der Vergangenheit hat jeder Code geschrieben und dort abgelegt, und daraus wurde ein Berg von Code oder Verbindlichkeiten. Natürlich gibt es viele offene Goldminen, die nicht ausgegraben wurden, und es gibt immer noch viele Dokumente die ich finden möchte. Die Zeit kann nicht gefunden werden.
Aber im KI-Zeitalter ist es eines der wichtigsten Dinge, die wir tun, unsere Assets und Dokumente zu sortieren und große Modelle durch SFT und RAG zu stärken, damit die großen Modelle intelligenter werden und besser zur Persönlichkeit des Unternehmens passen Daher werden die heutigen Veränderungen in den Interaktionsmethoden zwischen Mensch und Computer zu Veränderungen in der Erfahrung führen.

Künstliche Intelligenz zerlegt die Einflussfaktoren gerade jetzt. Ihr Kern besteht darin, drei Veränderungen in den Methoden der Mensch-Computer-Interaktion herbeizuführen. Das erste ist, dass die KI in Kombination mit Werkzeugen zum Copiloten wird und die Leute sie dann befehlen können, um uns bei der Fertigstellung einiger Einzelpunkt-Werkzeuge zu helfen. In der zweiten Phase sollte tatsächlich ein Konsens erzielt werden. Er wird zum Agenten, was bedeutet, dass er die Fähigkeit hat, Aufgaben unabhängig zu erledigen, einschließlich des Schreibens von Code oder der Durchführung von Tests. Tatsächlich fungiert das Tool als Multi-Domain-Experte. Wir müssen nur den Kontext angeben und die Wissensausrichtung vervollständigen. In der dritten Stufe gehen wir davon aus, dass die KI zum Entscheidungsträger werden kann, denn in der zweiten Stufe ist der Entscheidungsträger immer noch ein Mensch. In der dritten Stufe ist es möglich, dass das große Modell über einige Entscheidungsfähigkeiten verfügt. einschließlich erweiterter Funktionen zur Informationsintegration und -analyse. Zu diesem Zeitpunkt werden sich die Menschen mehr auf geschäftliche Kreativität und Korrektur konzentrieren, und viele Dinge können großen Modellen überlassen werden. Durch diese Änderung der verschiedenen Mensch-Maschine-Modi wird unsere Gesamtarbeitseffizienz höher.

Ein weiterer Punkt ist, dass sich auch die Form der Wissensvermittlung, über die wir gerade gesprochen haben, grundlegend verändert hat. In der Vergangenheit wurde das Problem der Wissensvermittlung durch Mundpropaganda, Schulungen und die Einführung des Neuen aus dem Alten gelöst. Es ist sehr wahrscheinlich, dass dies in Zukunft nicht mehr erforderlich sein wird. Wir müssen das Modell nur mit Geschäftswissen und Domänenerfahrung ausstatten und jedem Entwicklungsingenieur die Möglichkeit geben, intelligente Tools zu verwenden Tools, und das Bild oben zeigt jetzt eine One-Stop-Toolkette für DevOps. Nachdem eine große Anzahl von Code- und Dokument-Assets gesammelt wurde, werden diese Assets aussortiert und mit dem großen Modell zusammengefügt. Über RAG und SFT wird das Modell in jeden Link des DevOps-Tools eingebettet, wodurch mehr Daten generiert werden und so ein Forward entsteht In diesem Prozess können Entwickler an vorderster Front von den Vorteilen oder Fähigkeiten profitieren, die die Vermögenswerte mit sich bringen.
Das Obige ist meine Einführung aus makroökonomischer Sicht in die Kernfaktoren, die die F&E-Effizienz großer Modelle beeinflussen, sowie in die beiden wichtigsten Änderungen in der Form: Die erste ist die Änderung in der Form der Mensch-Computer-Interaktion und die zweite ist die Veränderung in der Art und Weise der Wissensvermittlung. Aufgrund verschiedener technischer Einschränkungen und Probleme in der Entwicklungsphase großer Modelle ist der Copilot-Mensch-Computer-Interaktionsmodus unser Bestes. Als Nächstes werden wir einige unserer Erfahrungen vorstellen und zeigen, wie der beste Copilot-Mensch-Computer-Interaktionsmodus erstellt wird .
Kreieren Sie Ihre beste Copilot-Pose
Wir glauben, dass das Mensch-Computer-Interaktionsmodell der Codeentwicklung derzeit nur Probleme wie kleine Aufgaben, Probleme, die eine manuelle Übernahme erfordern, und hochfrequente Probleme wie die Code-Vervollständigung lösen kann. Wir akzeptieren dies. und dann einen weiteren Absatz generieren. Dies ist ein sehr häufiges Problem, und es gibt auch das Problem einer kurzen Ausgabe. Wir werden nicht einmal eine Klasse generieren Funktion oder jedes Mal ein paar Zeilen. Warum machen wir das? Tatsächlich hat es viel mit den Einschränkungen der eigenen Fähigkeiten des Modells zu tun.
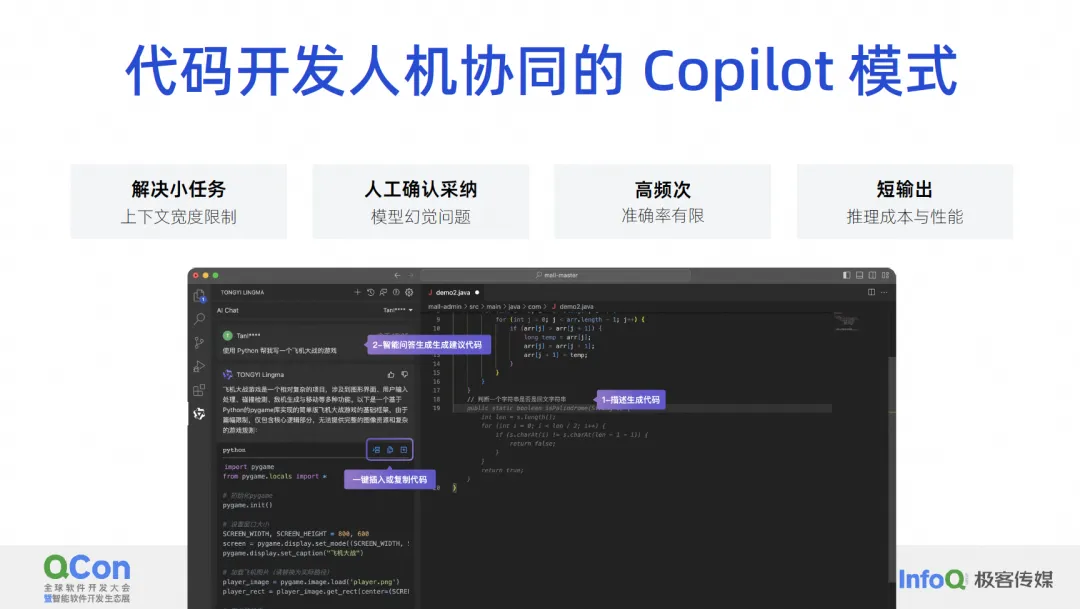
Da unsere aktuelle Kontextbreite immer noch sehr begrenzt ist, gibt es keine Möglichkeit, eine Anforderung zu erfüllen, wenn wir sie auf einmal erfüllen möchten. Daher können wir entweder den Agenten verwenden, um sie in eine Reihe kleiner Aufgaben aufzuteilen und löse sie Schritt für Schritt. Oder lassen Sie es die einfachste Aufgabe im Copilot-Modus erledigen, z. B. das Generieren eines kleinen Codeabschnitts gemäß einem Kommentar. Dies nennen wir das Lösen kleiner Aufgaben.
Im Hinblick auf die manuelle Übernahme müssen nun Menschen die von großen Codemodellen generierten Ergebnisse beurteilen. Was wir derzeit gut machen, ist eine Akzeptanzrate von 30 bis 40 %, was bedeutet, dass mehr als die Hälfte unserer generierten Codes tatsächlich ungenau sind oder nicht den Erwartungen der Entwickler entsprechen, sodass wir ständig Illusionsprobleme beseitigen müssen.
Das Wichtigste für die tatsächliche Verwendung großer Modelle auf Produktionsebene ist jedoch die manuelle Bestätigung. Generieren Sie dann nicht zu viele Hochfrequenzmodelle, sondern jedes Mal ein wenig, da die manuelle Bestätigung, ob dieser Code vorhanden ist, teuer ist OK wirkt sich auch auf die Leistung aus. In diesem Artikel werden einige unserer Überlegungen und Maßnahmen erläutert und das Problem der begrenzten Genauigkeit durch hohe Frequenz gelöst. Darüber hinaus ist die kurze Produktion hauptsächlich auf Leistungs- und Kostenprobleme zurückzuführen.
Das aktuelle Modell des Code-Assistenten trifft tatsächlich sehr genau auf einige technische Einschränkungen großer Modelle, sodass ein solches Produkt schnell auf den Markt gebracht werden kann. Unserer Meinung nach ist das Copilot-Modell, das Entwicklern am besten gefällt, die folgenden vier Schlüsselwörter: hochfrequente und starre Bedürfnisse, erreichbar, wissend, was ich will, und exklusiv für mich.

Das erste ist, dass wir hochfrequente und dringend benötigte Szenarien lösen müssen, damit Entwickler das Gefühl haben, dass dieses Ding wirklich nützlich und nicht nur ein Spielzeug ist.
Der zweite ist in Reichweite, das heißt, er kann jederzeit geweckt werden und kann uns jederzeit bei der Lösung von Problemen helfen. Ich muss nicht mehr wie früher über verschiedene Suchmaschinen nach Codes suchen. Es ist, als ob es an meiner Seite wäre und ich es jederzeit aktivieren kann, um mir bei der Lösung von Problemen zu helfen.
Die dritte besteht darin, zu wissen, was ich denke, d. h. die Genauigkeit der Beantwortung meiner Fragen und der Zeitpunkt, zu dem sie meine Fragen beantwortet, sind sehr wichtig.
Schließlich muss es mir gehören und nicht nur Dinge verstehen, die vollständig Open Source sind. Lassen Sie uns diese vier Punkte im Detail besprechen.
Es wird nur eine hohe Frequenz benötigt
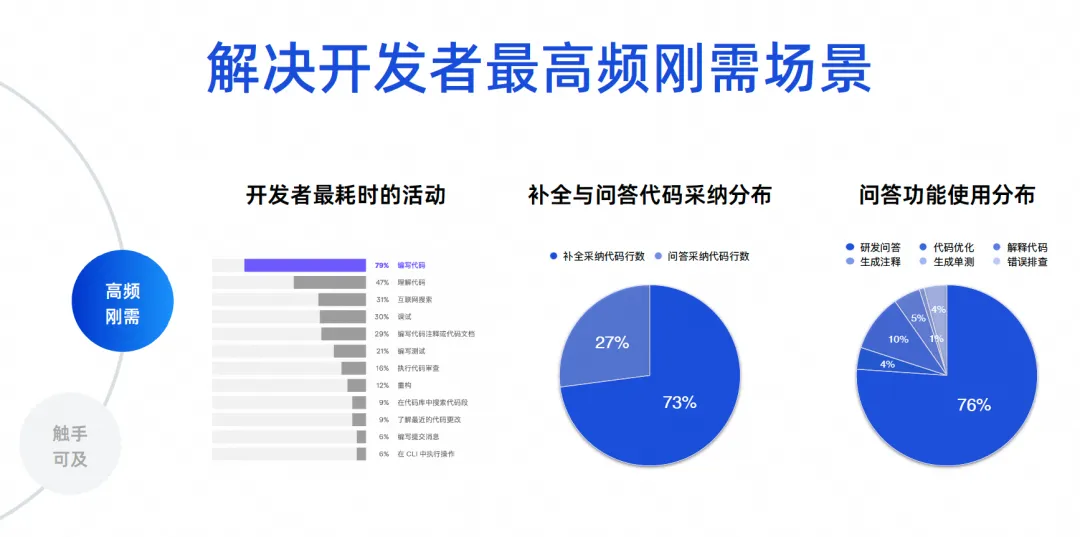
Wir müssen die häufigsten Szenarien für die Softwareentwicklung ermitteln. Ich habe hier einige echte Daten. Die ersten Daten stammen aus einem Entwicklerökologiebericht von JetBrains aus dem Jahr 2023, in dem die zeitaufwändigsten Aktivitäten von Entwicklern zusammengestellt wurden. Es ist ersichtlich, dass 70 % bis 80 % Code schreiben und durchsuchen Sie das Internet, debuggen Sie, schreiben Sie Kommentare und schreiben Sie Tests. Diese Szenarien sind eigentlich die Funktionen von Code-Intelligence-Tools. Die Kernprobleme, die Produkte wie Tongyi Lingma lösen, sind tatsächlich die häufigsten Probleme.
Bei den beiden letztgenannten Daten handelt es sich um Datenanalysen von Hunderttausenden Nutzern auf Tongyi Lingma Online. 73 % des Codes, den wir derzeit online übernehmen, stammen aus Abschlussaufgaben und 27 % stammen aus der Übernahme von Frage- und Antwortaufgaben. Heutzutage ersetzen viele KIs den Menschen beim Schreiben von Code und werden immer noch zwischen den Zeilen der IDE generiert. Dies ist ein Ergebnis, das sich aus der realen Situation ergibt. Als nächstes kommt der Anteil der Nutzung der Frage-und-Antwort-Funktion. 76 % des Anteils stammen aus F&E-Fragen und -Antworten, und die restlichen 10 % sind eine Reihe von Code-Aufgaben wie Code-Optimierung und Code-Interpretation. Daher nutzt die überwiegende Mehrheit der Entwickler immer noch unsere Tools, um allgemeine F&E-Kenntnisse anzufordern, oder nutzt natürliche Sprache, um aus großen Codemodellen einige Algorithmen zu generieren, um einige kleine Probleme zu lösen.
Die nächsten 23 % sind unsere eigentlichen detaillierten Codierungsaufgaben. Dies dient dazu, jedem einen Einblick in die Daten zu geben. Wir haben also unsere Kernziele. Zuerst müssen wir das Problem der Codegenerierung lösen, insbesondere zwischen Zeilen. Zweitens ist es notwendig, die Genauigkeits- und Professionalitätsprobleme von F&E-Problemen zu lösen.
In Reichweite

Letztendlich wollen wir über die Schaffung eines immersiven Programmiererlebnisses sprechen. Wir hoffen, dass die meisten Probleme, mit denen Entwickler heute konfrontiert sind, innerhalb der IDE gelöst werden können, anstatt darauf verzichten zu müssen.
Welche Erfahrungen haben wir in der Vergangenheit gemacht? Wenn Sie auf ein Problem stoßen, sollten Sie das Internet durchsuchen oder andere fragen und dann nach dem Herumfragen Ihr eigenes Urteil fällen. Schreiben Sie schließlich den Code, kopieren Sie ihn, fügen Sie ihn zum Debuggen und Kompilieren in die IDE ein und prüfen Sie erneut, ob dies der Fall ist schlägt fehl. Dies wird sehr zeitaufwändig sein. Wir hoffen, das große Modell in der IDE direkt fragen zu können und das große Modell Code für mich generieren zu lassen, damit die Erfahrung sehr angenehm wird. Durch eine solche technische Wahl haben wir das Problem der immersiven Programmiererfahrung gelöst.
Die Abschlussaufgabe ist eine leistungsempfindliche Aufgabe und ihre Ausgabe muss in 300 bis 500 Millisekunden erfolgen, vorzugsweise nicht länger als eine Sekunde. Daher haben wir ein kleines Parametermodell, das hauptsächlich zum Generieren von Code und zum größten Teil seines Trainings verwendet wird Der Korpus stammt ebenfalls aus Code. Obwohl die Modellparameter klein sind, ist die Genauigkeit der Codegenerierung sehr hoch.
Die zweite besteht darin, spezielle Aufgaben zu erledigen, von denen immer noch 20 bis 30 % der eigentlichen Aufgaben ausgehen, darunter sieben Aufgaben wie Annotationsgenerierung, Unit-Tests, Code-Optimierung und Fehlerbehebung bei Betriebsfehlern.
Wir verwenden derzeit ein moderates Parametermodell. Die Hauptüberlegungen hier sind erstens die Erzeugungseffizienz und zweitens das Tuning. Für ein Modell mit sehr großen Parametern sind unsere Optimierungskosten sehr hoch, aber bei diesem Modell mit mittleren Parametern sind das Codeverständnis und die Codegenerierungseffekte bereits gut, daher haben wir uns für das Modell mit mittleren Parametern entschieden.
Bei großen Modellen streben wir insbesondere bei der Beantwortung von mehr als 70 % unserer F&E-Fragen nach hoher Genauigkeit und Echtzeitwissen. Deshalb haben wir unsere RAG-Technologie durch ein Maximum-Parameter-Modell überlagert, sodass sie nahezu in Echtzeit in eine internetbasierte Wissensdatenbank eingebunden werden kann, sodass die Qualität und Wirkung ihrer Antworten sehr hoch ist und Modellillusionen erheblich beseitigt und die Antwort verbessert werden können Qualität. Wir unterstützen das gesamte immersive Programmiererlebnis durch drei solcher Modelle.

Der zweite Punkt ist, dass wir mehrere Terminals implementieren müssen, denn nur wenn wir mehr Terminals abdecken, können wir mehr Entwickler abdecken. Derzeit unterstützt Tongyi Lingma VS-Code und JetBrains. Es löst hauptsächlich Auslöseprobleme, Anzeigeprobleme und einige Interaktivitätsprobleme.
Auf der Kernebene ist unser lokaler Agentenservice ein unabhängiger Prozess. Es findet eine Kommunikation zwischen diesem Prozess und dem oben genannten Plug-in statt. Dieser Prozess befasst sich hauptsächlich mit einigen Kernfunktionen des Codes, einschließlich intelligenter Vervollständigung des Codes, Sitzungsverwaltung und Agenten.
Darüber hinaus sind Syntaxanalysedienste sehr wichtig, um dateiübergreifende Referenzprobleme zu lösen. Wenn wir den lokalen Abruf verbessern wollen, benötigen wir auch eine leichte lokale Vektor-Abruf-Engine. Daher kann der gesamte Back-End-Service auf diese Weise tatsächlich schnell erweitert werden.
Wir haben auch ein kleines lokales Offline-Modell für einige Zehntel B, um die Einzelzeilenvervollständigung in einzelnen Sprachen zu implementieren. JetBrains hat kürzlich auch ein kleines Modell eingeführt, das lokal ausgeführt wird . . Auf diese Weise werden einige unserer Datensicherheits- und Datenschutzprobleme, wie z. B. lokale Sitzungsverwaltung und lokaler Speicher, alle auf dem lokalen Computer platziert.

weiß, was ich denke
Ich weiß, was ich denke. Bezüglich des IDE-Plug-In-Tools gibt es meiner Meinung nach mehrere Punkte. Der erste ist der Auslösezeitpunkt, der auch einen großen Einfluss auf die Entwicklererfahrung hat. Soll ich es beispielsweise auslösen, wenn ich ein Leerzeichen betrete? Sollte es ausgelöst werden, wenn die IDE eine Eingabeaufforderung generiert hat? Sollte es beim Löschen dieses Codes ausgelöst werden? Wir müssen wahrscheinlich mehr als 30 bis 50 Szenarien klären. Ob der Code in diesem Szenario ausgelöst werden kann, kann durch Regeln gelöst werden. Solange wir ihn sorgfältig untersuchen und die Entwicklererfahrung untersuchen, können wir ihn nicht lösen .
Aber was die Länge der Codegenerierung angeht, denken wir, dass es schwieriger ist. Denn an verschiedenen Orten in verschiedenen Bearbeitungsbereichen wirkt sich die Länge des generierten Codes direkt auf unsere Erfahrung aus. Wenn Entwickler dazu neigen, nur eine einzige Codezeile zu generieren, besteht das Problem darin, dass der Entwickler nicht den gesamten generierten Inhalt verstehen kann. Beispielsweise weiß er beim Generieren einer Funktion nicht, was die Funktion tun wird, oder beim Generieren eines If Er weiß nicht, was in der if-Anweisung enthalten ist. Was ist die Geschäftslogik? Es gibt keine Möglichkeit, die Funktionseinheiten vollständig zu beurteilen, was sich auf seine Erfahrung auswirkt.
Wenn wir dazu einige feste Regeln verwenden, wird dies ebenfalls ein Problem verursachen, das heißt, es wird relativ starr sein. Unser Ansatz basiert also tatsächlich auf den semantischen Informationen des Codes. Durch Training und eine große Anzahl von Beispielen versteht das Modell, wie lange es heute in welchem Szenario generiert werden sollte, um die Klassenebene und Funktion automatisch zu bestimmen Ebene, Die Generierungsintensität auf logischer Blockebene und Zeilenebene wird als adaptive Entscheidungsfindung für die Generierungsintensität bezeichnet. Durch umfangreiches Vortraining ermöglichen wir dem Modell die Wahrnehmung und verbessern so die Genauigkeit der Generierung. Dies ist unserer Meinung nach auch ein wichtiger technischer Punkt.
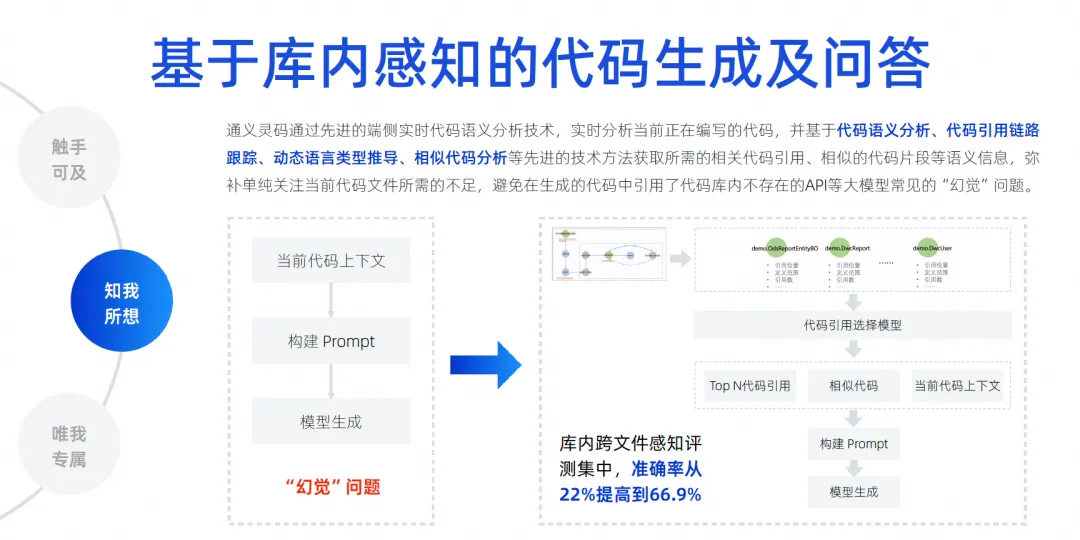
Das Wichtigste für die Zukunft ist, wie wir die Illusion des Modells beseitigen können, denn nur wenn die Illusion ausreichend beseitigt ist, kann unsere Akzeptanzrate verbessert werden. Daher müssen wir eine dateiübergreifende Kontexterkennung innerhalb der Bibliothek implementieren. Hier führen wir viele codebasierte semantische Analysen, Referenzkettenverfolgung, ähnlichen Code und dynamische Sprachtypableitung durch.
Das Wichtigste ist, mit allen Mitteln zu erraten, welche Art von Hintergrundwissen der Entwickler möglicherweise für diese Position benötigt. Diese Dinge können auch einige Sprachen, Frameworks, Benutzergewohnheiten usw. betreffen. Wir verwenden verschiedene Dinge, um es zu kombinieren Kontext, priorisieren Sie ihn, stellen Sie die kritischsten Informationen in den Kontext und geben Sie sie dann zur Ableitung an das große Modell weiter, sodass das große Modell Illusionen beseitigen kann. Durch diese Technologie können wir einen dateiübergreifenden kontextsensitiven Testsatz erreichen. Unsere Genauigkeit ist von 22 % auf 66,9 % gestiegen . Wir verbessern weiterhin den Vervollständigungseffekt.
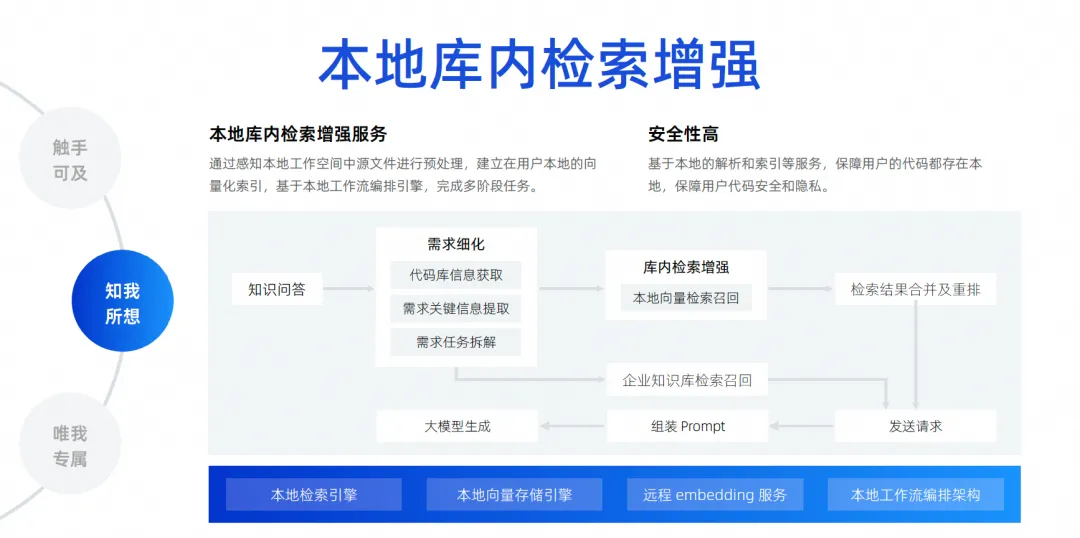
Die letzte Möglichkeit ist unsere lokale Sucherweiterung in der Bibliothek. Wie ich gerade sagte, errät die Kontexterkennung nur den Kontext des Entwicklers am Auslöserort. Ein häufigeres Szenario besteht darin, dass Entwickler heute eine Frage stellen möchten und das große Modell mir dabei helfen soll, ein Problem basierend auf allen Dateien in der lokalen Bibliothek zu lösen, z. B. mir zu helfen, einen Fehler zu beheben, mir zu helfen, eine Anforderung hinzuzufügen, mir zu helfen Füllen Sie eine Datei aus und implementieren Sie automatisch Hinzufügungen, Löschungen, Änderungen und Suchvorgänge und fügen Sie sogar eine neue Paketversion zu meiner Pompt-Datei hinzu. Um dies zu erreichen, müssen wir tatsächlich eine Suchmaschine anschließen für das große Modell. Da es uns aufgrund der Auswirkungen der Kontextbreite unmöglich ist, alle Dateien des gesamten Projekts in das große Modell zu packen, müssen wir eine Technologie namens „ Local In-Library Search Enhancement“ verwenden .
Diese Funktion dient dazu, unsere kostenlosen Fragen und Antworten auf der Grundlage der Bibliothek zu realisieren und einen lokalen Suchverbesserungsdienst in der Bibliothek einzurichten. Wir sind der Meinung, dass diese Methode für die Erfahrung der Entwickler am besten geeignet ist und die höchste Sicherheit bietet.
Der Code muss nicht in die Cloud hochgeladen werden, um den gesamten Link zu vervollständigen. Aus Sicht des gesamten Links gehen wir, nachdem ein Entwickler eine Frage gestellt hat, zur Codebasis, um die für die Zerlegung der Aufgabe erforderlichen Schlüsselinformationen zu extrahieren. Nachdem die Zerlegung abgeschlossen ist, führen wir eine lokale Vektorsuche und einen Rückruf durch Führen Sie die Suchergebnisse zusammen und ordnen Sie sie neu an. Durchsuchen Sie die interne Datenwissensdatenbank des Unternehmens, da das Unternehmen über eine einheitliche Wissensdatenbankverwaltung auf Unternehmensebene verfügt. Abschließend werden alle Informationen zusammengefasst und an das große Modell gesendet, damit das große Modell Probleme generieren und lösen kann.

Nur für mich
Ich denke, wenn Unternehmen mit großen Codemodellen eine sehr gute Wirkung erzielen wollen, kommen sie an dieser Ebene nicht vorbei. Zum Beispiel, wie man personalisierte Szenarien für Unternehmensdaten realisiert, beispielsweise in der Projektmanagementphase, wie man große Modelle gemäß einigen inhärenten Formaten und Spezifikationen von Anforderungen/Aufgaben/Fehlerinhalten generiert und uns dabei hilft, eine automatische Demontage und automatische Erneuerung zu realisieren einige Anforderungen. Schreiben, automatische Zusammenfassung usw.
Die Entwicklungsphase ist möglicherweise das, worauf alle am meisten achten. Unternehmen sagen oft, dass sie über Codespezifikationen verfügen müssen, die mit denen des Unternehmens übereinstimmen, auf die eigenen Bibliotheken von Drittanbietern verweisen und APIs aufrufen müssen, um SQL zu generieren, einschließlich der Verwendung eines Front-Ends Vom Unternehmen selbst entwickelte Frameworks, Komponentenbibliotheken usw. gehören alle zu Entwicklungsszenarien. Testszenarien müssen außerdem Testfälle generieren, die den Unternehmensspezifikationen entsprechen und sogar das Geschäft verstehen. In Betriebs- und Wartungsszenarien sollten Sie immer nach den Betriebs- und Wartungskenntnissen des Unternehmens suchen und dann Fragen beantworten, um einige der Betriebs- und Wartungs-APIs des Unternehmens zu erhalten und schnell Code zu generieren. Dies sind die Szenarien für die Personalisierung von Unternehmensdaten, die wir unserer Meinung nach umsetzen müssen. Der spezifische Ansatz besteht darin, dies durch Abrufverbesserung oder Feinabstimmungstraining zu erreichen.
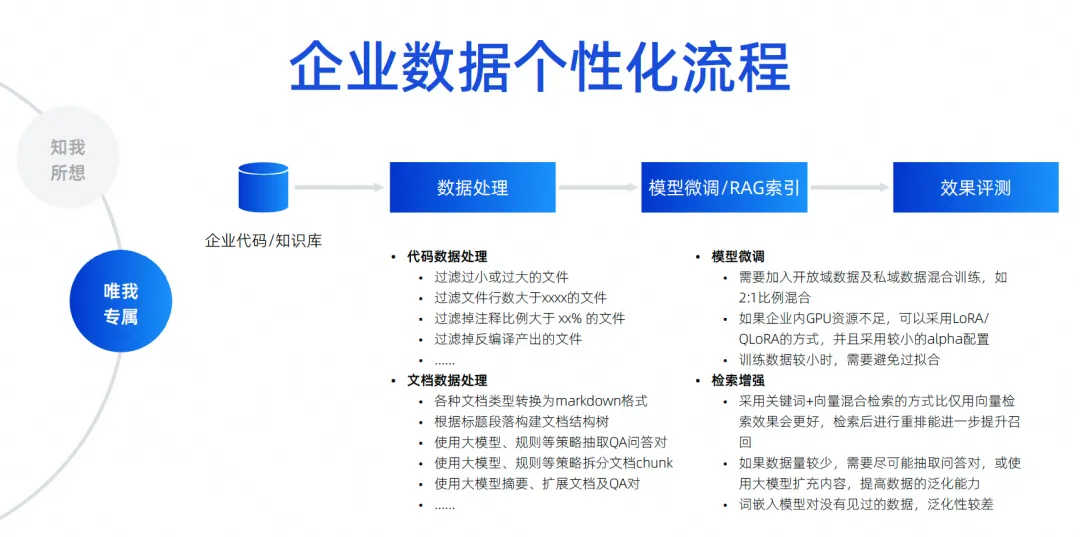
Hier habe ich einige einfache Szenarien und Dinge aufgelistet, auf die man achten sollte, darunter die Art und Weise, wie der Code verarbeitet werden soll, wie die Dokumente verarbeitet werden sollen und der Code gefiltert, bereinigt und strukturiert werden muss, bevor er verwendet werden kann.
Während unseres Trainingsprozesses müssen wir die Mischung von Open-Domain-Daten und Private-Domain-Daten berücksichtigen. Zum Beispiel müssen wir verschiedene Parameteranpassungen vornehmen. Wir müssen verschiedene Strategien zur Abrufverbesserung in Betracht ziehen. Wir untersuchen ständig, wie wir die Kontextinformationen erreichen, die wir in Codegenerierungsszenarien benötigen Die kontextbezogenen Informationen zu den Antworten, die wir im Frage-Antwort-Szenario benötigen, sind eine Verbesserung des Abrufs.
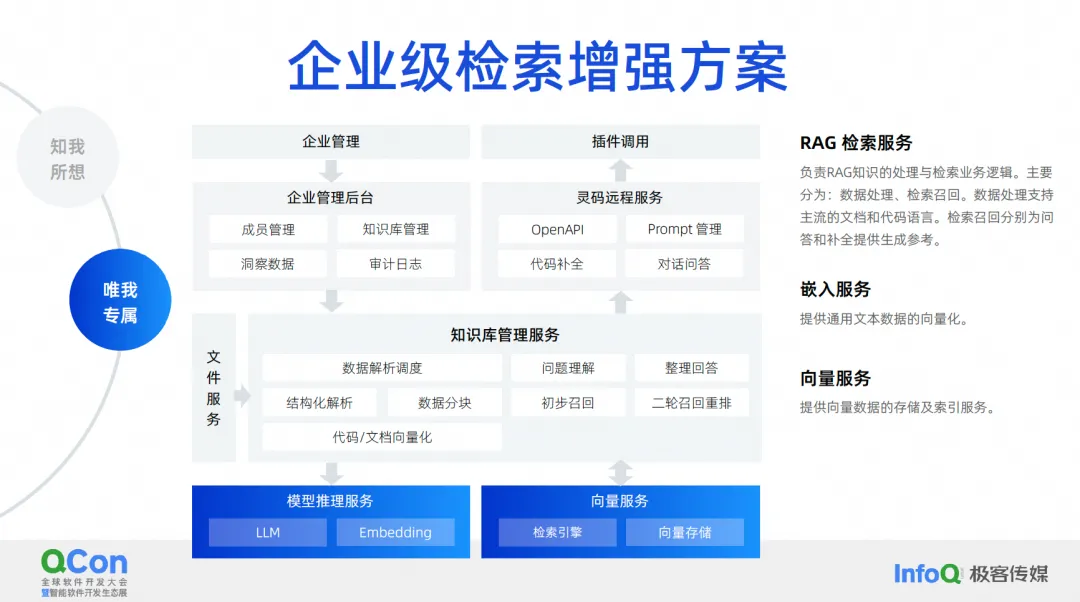
Was wir tun möchten, ist eine Abrufverbesserungslösung auf Unternehmensebene . Das aktuelle Architekturdiagramm der Abrufverbesserungslösung auf Unternehmensebene sieht ungefähr so aus. In der Mitte befindet sich der Verwaltungsdienst der Wissensdatenbank, einschließlich der Planung der Datenanalyse, des Verständnisses von Fragen, der Organisation von Antworten, der strukturierten Analyse, der Datensegmentierung usw. Die Kernfunktionen befinden sich in der Mitte und weiter unten unsere am häufigsten verwendeten Einbettungsdienste . , einschließlich Dienstleistungen für große Modelle, Speicherung und Abruf von Vektoren.
Nach oben sind einige von uns verwaltete Backends aufgeführt, die unsere Abrufverbesserung von Dokumenten und die Abrufverbesserung der Codegenerierung unterstützen. Die Codegenerierung soll den Abruf und die Verbesserung dieses Szenarios vervollständigen. Die erforderlichen Verarbeitungsmethoden und -technologien unterscheiden sich tatsächlich geringfügig von denen von Dokumenten.
Wir haben in der Vergangenheit mehrere Jahre lang mit der Fudan-Universität geforscht und sind für ihre Bemühungen sehr dankbar. Damals basierten die Ergebnisse unseres Testsatzes auch auf einem Modell von 1.1 bis 1B, gepaart mit Suchverbesserung, tatsächlich Die Genauigkeit und Wirkung können die gleiche Wirkung erzielen wie die eines 7B- oder höheren Modells.
Zukünftige Produktentwicklung des Softwareentwicklungsagenten
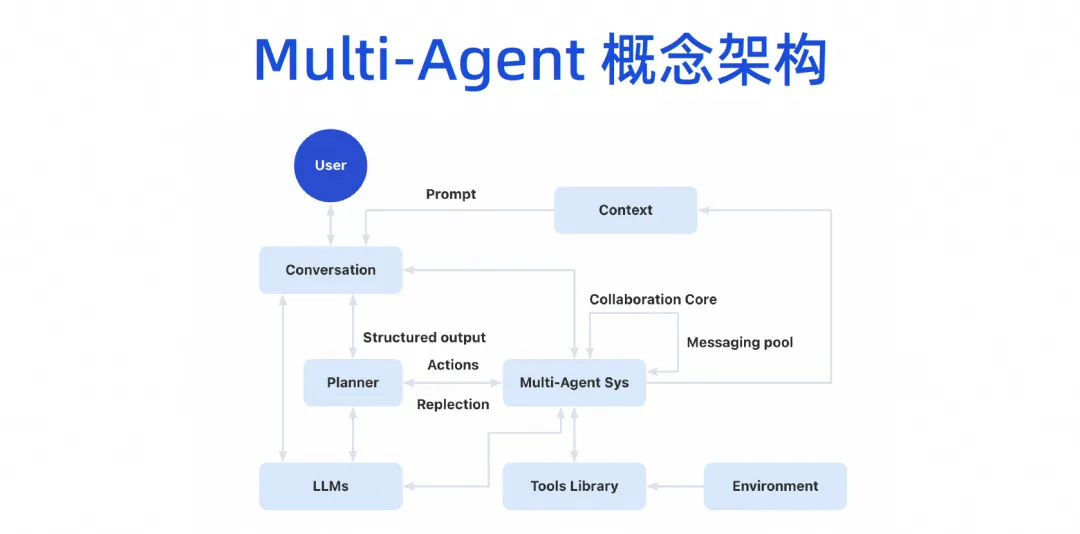
Wir glauben, dass die zukünftige Softwareentwicklung definitiv in die Agenten-Ära eintreten wird, was bedeutet, dass sie über eine gewisse Autonomie verfügt und unsere Tools sehr einfach verwenden kann, dann menschliche Absichten versteht, die Arbeit abschließt und schließlich eine Mehrzwecksoftware bildet, wie in gezeigt die Figur. Kollaboratives Modell der Agenten.

Gerade im März dieses Jahres hat uns die Geburt von Devin tatsächlich das Gefühl gegeben, dass diese Angelegenheit wirklich beschleunigt wird. Wir hätten nie gedacht, dass diese Angelegenheit ein echtes Geschäftsprojekt abschließen könnte, und wir hatten sogar das Gefühl, dass diese Angelegenheit Es mag zwar noch ein Jahr dauern, aber seine Entstehung gibt uns das Gefühl, dass wir heute wirklich Hunderte oder Tausende von Schritten durch große Modelle abbauen und Schritt für Schritt ausführen können. Wenn Probleme auftreten, können wir uns auch selbst reflektieren und iterieren Die starke Demontagefähigkeit und das Denkvermögen haben uns sehr überrascht.
Mit der Geburt von Devin begannen verschiedene Experten und Wissenschaftler zu investieren, darunter auch unser Tongyi-Labor, das sofort ein Projekt namens OpenDevin startete. Dieses Projekt hat in nur wenigen Wochen die 20.000-Sterne-Marke überschritten. Man sieht, dass alle von diesem Bereich sehr begeistert sind. Dann haben wir das Agent-Projekt von SWE sofort als Open-Source-Lösung bereitgestellt und so die SWE-Bench-Lösungsrate auf über 10 % gesteigert. Große Modelle lagen in der Vergangenheit alle im Bereich von ein paar Prozent, und eine Steigerung auf 10 % kommt der Leistung von Devin bereits nahe Wir sind der Meinung, dass die akademische Forschung in diesem Bereich sehr schnell sein kann.
Lassen Sie uns eine mutige Vermutung anstellen. Es ist sehr wahrscheinlich, dass die Lösungsrate der SWE-Bench von Juni bis September etwa 30 % überschreiten wird. Lassen Sie uns eine mutige Vermutung anstellen. Wenn es eine Auflösungsrate von 50 bis 60 Prozent erreichen kann, handelt es sich bei seinem Testsatz tatsächlich um einige echte Github-Probleme. Lassen Sie die KI die Probleme auf Github beheben und solche Testsätze lösen. Wenn dieser Testsatz dazu führen kann, dass die autonome Abschlussrate der KI 50 oder 60 % erreicht, ist er unserer Meinung nach tatsächlich auf Produktionsebene umsetzbar. Zumindest einige einfache Mängel können damit behoben werden, was zu den neuesten Entwicklungen gehört, die wir in der Branche gesehen haben.
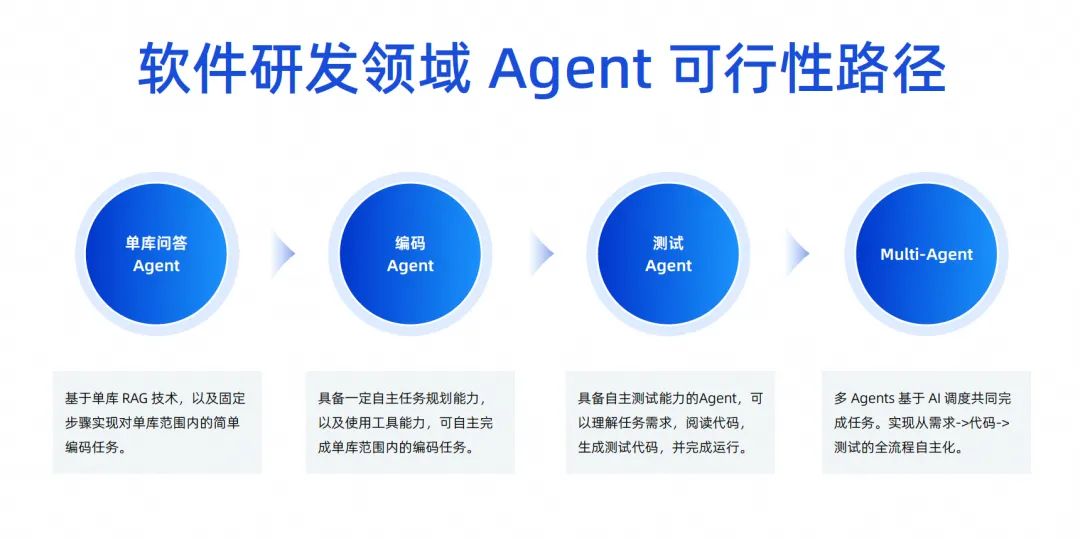
Dieses Bild lässt sich jedoch nicht sofort realisieren. Aus technischer Sicht werden wir es schrittweise in diesen vier Schritten umsetzen.
Im ersten Schritt arbeiten wir noch an einem Single-Database-Q&A-Agent. Dieser Bereich ist sehr modern. Wir arbeiten derzeit an einem Single-Database-Q&A-Agent, der in naher Zukunft online sein wird.
Im nächsten Schritt hoffen wir, einen Agenten zu starten, der Codierungsaufgaben unabhängig ausführen kann. Seine Hauptaufgabe besteht darin, über ein gewisses Maß an unabhängigen Planungsfähigkeiten zu verfügen. Er kann einige Tools verwenden, um Hintergrundwissen zu verstehen, und Codierungsaufgaben unabhängig ausführen Bibliothek, nicht bibliotheksübergreifend, Sie können sich vorstellen, dass eine Anforderung mehrere Codebasen hat, und dann wird auch das Front-End geändert, und das Back-End wird ebenfalls geändert, und schließlich wird eine Anforderung gebildet .
Daher implementieren wir zunächst den Codierungsagenten einer einzelnen Bibliothek und führen als Nächstes den Testagenten aus. Der Testagent kann einige Testaufgaben basierend auf den generierten Ergebnissen des Codierungsagenten automatisch ausführen, einschließlich des Verständnisses der Aufgabenanforderungen und des Lesens Code erstellen, Testfälle generieren und autonom ausführen.
Wenn die Erfolgsquote dieser beiden Schritte relativ hoch ist, gehen wir zum dritten Schritt über. Lassen Sie mehrere Agenten zusammenarbeiten, um Aufgaben basierend auf der KI-Planung zu erledigen, und realisieren Sie so die Autonomie des gesamten Prozesses von den Anforderungen über den Code bis hin zum Testen.
Aus technischer Sicht werden wir Schritt für Schritt vorgehen, um sicherzustellen, dass jeder Schritt zu einer besseren Umsetzung auf Produktionsebene führt und letztendlich Produkte produziert. Aber aus akademischer Sicht wird ihre Forschungsgeschwindigkeit schneller sein als unsere. Jetzt diskutieren wir aus akademischer und technischer Sicht, und wir haben einen dritten Zweig, nämlich die Modellentwicklung. Diese drei Wege sind Teil der Forschung, die wir derzeit gemeinsam mit Alibaba Cloud und Tongyi Lab durchführen.
Schließlich werden wir eine konzeptionelle Architektur mit mehreren Agenten bilden. Benutzer können mit dem großen Modell sprechen, und das große Modell kann Aufgaben aufschlüsseln, und dann wird es ein System für die Zusammenarbeit mit mehreren Agenten geben. Dieser Agent kann einige Tools anschließen und über eine eigene Betriebsumgebung verfügen. Dann können mehrere Agenten zusammenarbeiten und einige Kontextmechanismen gemeinsam nutzen.
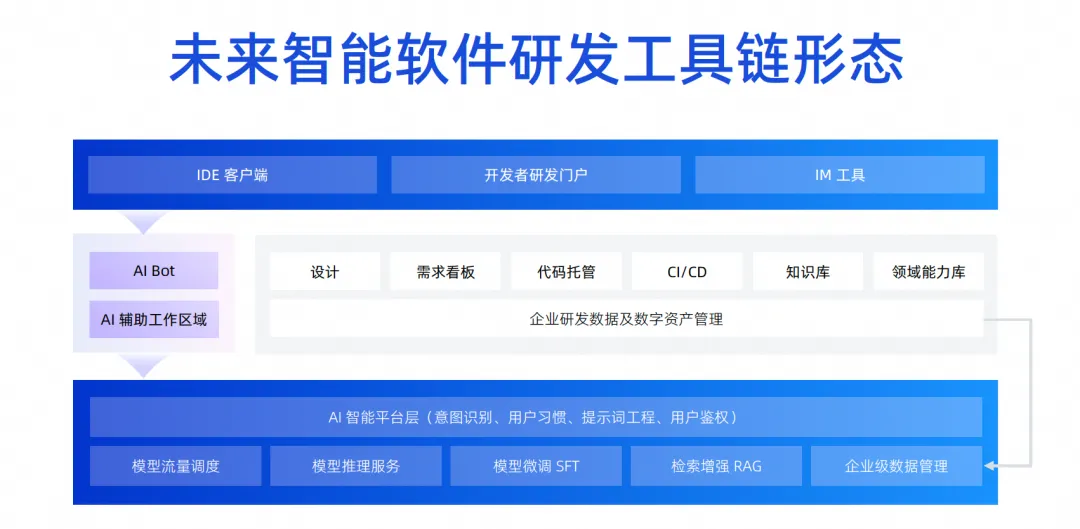
Dieses Produktbild wird in drei Ebenen unterteilt. Die untere Ebene ist die Basisebene. Für Unternehmen kann die Basisebene zuerst fertiggestellt werden. Beispielsweise kann jetzt ein großes Codemodell eingeführt werden, obwohl wir AI Bot nicht sofort implementiert haben, verfügen wir jetzt über die Funktionen des IDE-Codegenerierungs-Plug-Ins und können bereits einige Arbeiten ausführen, nämlich das Copilot-Modell.
Der Copilot-Modus entwickelt die Agentenschicht über der Infrastrukturschicht weiter. Tatsächlich kann die Infrastruktur wiederverwendet werden. Die Abrufverbesserung, die Feinabstimmung der Schulung und die Wissensbasis, die durchgeführt werden sollten, können jetzt durchgeführt werden. Die Aussortierung dieses Wissens und die Anhäufung von Vermögenswerten ergeben sich aus der Anhäufung der ursprünglichen DevOps-Plattform. Jetzt können Sie die aktuelle Basisfähigkeitsebene mit der gesamten DevOps-Toolkette durch einige Prompt-Word-Projekte kombinieren.
Wir haben in der Anforderungsphase einige Experimente durchgeführt. Wenn wir möchten, dass dieses große Modell eine Anforderung automatisch zerlegt, müssen wir möglicherweise nur einige frühere Demontagedaten und aktuelle Anforderungen in einer Eingabeaufforderung für das große Modell kombinieren und Personal besser eingesetzt. Im Experiment wurde festgestellt, dass die Genauigkeit der Ergebnisse recht hoch ist.
Tatsächlich erfordert die gesamte DevOps-Toolkette nicht für alles einen Agenten oder Copiloten. Wir verwenden jetzt einige Prompt-Word-Projekte und es gibt viele Szenarien, die sofort aktiviert werden können, darunter automatisches Debugging in unserem CICD-Prozess, intelligente Fragen und Antworten im Wissensdatenbankbereich usw.
Nach der Implementierung mehrerer Agenten kann der Agent in der IDE, im Entwicklerportal, auf der DevOps-Plattform oder sogar in unserem IM-Tool verfügbar gemacht werden. Es handelt sich tatsächlich um eine anthropomorphe Intelligenz. Der Agent selbst verfügt über einen eigenen Arbeitsbereich. In diesem Arbeitsbereich können unsere Entwickler oder Manager überwachen, wie er uns beim Schreiben von Code hilft, wie er uns beim Testen hilft und wie er im Internet verwendet wird Wenn Sie die Arbeit abschließen, verfügt es über einen eigenen Arbeitsbereich und realisiert letztendlich den vollständigen Prozess der gesamten Aufgabe.
Klicken Sie hier , um Tongyi Lingma zu erleben.
Das Team der Google Python Foundation wurde entlassen , und die an Flutter, Dart und Python beteiligten Teams stürmten auf die GitHub-Hotlist – Wie können Open-Source-Programmiersprachen und Frameworks so süß sein? Xshell 8 startet Betatest: Unterstützt das RDP-Protokoll und kann eine Fernverbindung zu Windows 10/11 herstellen. Wenn Passagiere eine Verbindung zum Hochgeschwindigkeits-WLAN der Bahn herstellen , taucht der „35 Jahre alte Fluch“ chinesischer Programmierer auf, wenn sie sich mit Hochgeschwindigkeit verbinden Rail WiFi. MySQLs erstes KI-Suchtool mit Langzeitunterstützung für Version 8.4 GA : Vollständig Open Source und kostenlos, eine Open-Source-Alternative zu Perplexity. Hongmeng: Es verfügt trotz anhaltender Unterdrückung immer noch über ein eigenes Betriebssystem Das deutsche Automobilsoftwareunternehmen Elektrobit hat eine auf Ubuntu basierende Automobil-Betriebssystemlösung als Open Source bereitgestellt .