
Autor: Lu Yufeng Quelle: Zhihu
Zusammenfassung
Die Entwicklung von MindNLP hat insgesamt etwa ein Jahr gedauert und ist mit vielen Problemen konfrontiert, die auch mit einer Reihe von Auswirkungen und Herausforderungen einhergehen, die LLM mit sich bringt. Als Nachzügler des NLP-Frameworks, das für sein Wachstum auf MindSpore angewiesen ist, muss es tatsächlich darüber nachdenken, wie es seine Ökologie erweitern kann.
Wie das Sprichwort sagt: Wenn Sie es nicht schlagen können, machen Sie mit. Aber für die Open-Source-Welt besteht kein Grund, über einen Beitritt zu sprechen. Es ist normal, dass Sie ein Teil von mir sind. Außerdem wurde Pytorch2.1+Ascend vor zwei Tagen offiziell angekündigt. Die ökologische Veredelung ist zweifellos die beste Lösung. Genug des Klatsches und kommen wir zum Punkt.
01
MindNLP-Datensätze
Wir hoffen, von Beginn des MindNLP-Designs an alle Vorteile und Funktionen von MindSpore voll nutzen zu können, einschließlich funktionaler Fusionsprogrammierung, dynamischer Diagrammfunktionen, Datenverarbeitungs-Engines usw. Hier wird die Datenverarbeitungs-Engine separat herausgenommen und ausführlich besprochen.
1.1MindSpore-Datenverarbeitungs-Engine
Abbildung 1: Schematisches Diagramm der MindSpore-Daten-Engine-Pipeline
Wie in der Abbildung gezeigt, ist das Design der Daten-Engine eine Pipeline [1], die dem Datensatz von Tensorflow und den Datensätzen im Kartenstil von Pytorch sehr ähnlich ist und hauptsächlich auf eine Hochleistungsdatenverarbeitung abzielt.
In einer Zeit, in der jeder immer noch kleine Modelländerungen und kleine Datensätze vornimmt, um die Rangliste aufzufrischen, erfolgt die Datenvorverarbeitung normalerweise offline, sodass Python für die Verarbeitung so flexibel wie möglich verwendet werden kann und normalerweise der große Speicher des Servers dies kann Jeder wird alle Daten auf einmal hineinstopfen und dann mehrere Prozesse öffnen, um sie zu verarbeiten. Laden Sie es anschließend in Tensor und senden Sie es zum Training an das Netzwerk. Aber selbst wenn der Datensatz etwas größer ist, kann die Vorverarbeitung des Datensatzes Stunden oder sogar Tage dauern.
Die Pipeline-Methode konzentriert sich auf mehrere Funktionen:
1. Bei Bedarf laden
2. Asynchrone Verarbeitung
3. Parallel
Unter diesen können 1 und 2 im Detail besprochen werden. Am Beispiel von Textdaten sieht der gesamte Ausführungsablauf bei Verwendung der einfachsten Python-Ladevorverarbeitungslogik (d. h. Pytorch Dataloader) wie folgt aus:
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
Die Lademethode von Pipeline ist
Eine anschaulichere Beschreibung lautet: Es gibt jetzt einen Zeiger, der auf den Anfang der Datensatzdatei zeigt. Wir rufen jedes Mal eine Stapelgröße von Daten ab, und der Zeiger rückt um die Stapelgröße vor, bis er abgerufen wird.
Offensichtlich kann das Abrufen jeweils nur einer angemessenen Datenmenge den Speicherverbrauch erheblich reduzieren, und die während des Vorverarbeitungsprozesses generierten Zwischenvariablen können auch auf eine kleine Größe komprimiert werden. Darüber hinaus kann diese Methode die Offline-Datenvorverarbeitung in eine Online-Vorverarbeitung umwandeln:
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Abbildung 2: Datenverarbeitungs- und Netzwerk-Computing-Pipeline
Die Datenverarbeitungspipeline verarbeitet kontinuierlich Daten und sendet die verarbeiteten Daten an den Cache auf der Geräteseite. Nach der Ausführung eines Schritts werden die Daten des nächsten Schritts direkt aus dem Cache des Geräts gelesen. Während das Netzwerk trainiert, werden auch Daten verarbeitet, wobei jeder seine eigenen Aufgaben erfüllt.
Natürlich ist diese Methode auch ein zweischneidiges Schwert. Während sie die Speicherauslastung und Leistung verbessert, führt sie auch zu Problemen bei der Benutzerfreundlichkeit. Bei der Karte in Abbildung 1 handelt es sich um eine asynchrone Verarbeitung. Nach der Konfiguration jedes Datenvorverarbeitungsvorgangs werden die Ergebnisse nicht direkt ausgeführt. Dies ist nicht benutzerfreundlich für Daten, die eine genaue Kontrolle erfordern und viele besondere Bedingungen aufweisen, und es ist sehr wahrscheinlich, dass eine Pipeline-Ausführung erfolgt . Eine Anomalie wird plötzlich ausgelöst.
LLM hat diese Situation jedoch geändert, und die gesamte Datenverarbeitung ist auch zu einer riesigen Datenmenge geworden, und in Geschäftsszenarien wird das Streamen von Daten natürlich zur optimalen Lösung wahrscheinlich der Hauptgrund, warum Pytorch begonnen hat, Pipelines zu erstellen, und HuggingFace-Datensätze sind ebenfalls Pipelines).
1.2 Probleme bei der Unterstützung von MindNLP-Datensätzen
Wie bereits erwähnt, nutzt die Datenverarbeitung von MindNLP vollständig die MindSpore-Datenverarbeitungs-Engine und hat innerhalb eines Jahres mehr als 20 Datensätze unterstützt (Benchmark von Torchtext). Im tatsächlichen Einsatz ist jedoch offensichtlich, dass verschiedene NLP-Aufgaben mehr als diese Datensätze erfordern und es schwierig ist, sich kontinuierlich an eine offene Domäne anzupassen.
Darüber hinaus hat der Datensatz von Shengsi MindSpore auch einige Probleme verursacht. Das Hauptproblem besteht darin, dass MindSpore Dataset drei Arten von Ladern entwickelt hat, nämlich:
1. Spezifischer Datensatzlader: wie IMDBDataset, EnWik9Dataset usw.
2. Text-Abstract-Loader: TextFileDataset
3. Benutzerdefinierter Loader: GeneratorDataset
Wenn Sie 1 verwenden, bedeutet dies, dass Sie kontinuierlich Anpassungen hinzufügen müssen. Wenn Sie 2 verwenden, müssen Sie vor dem Laden Formate wie XML, JSON usw. vorverarbeiten. Dies widerspricht dem hocheffizienten Designkonzept von Pipeline und Ihnen Der Umfang der Entwicklung mit 3 bedeutet immer noch, dass der erste Schritt in Abbildung 1 zur Volllast zurückkehrt, was offensichtlich nicht das ist, was wir wollen. Aufgrund der Notwendigkeit, den Datensatz schnell zu unterstützen, haben wir uns dennoch für die 1+3-Methode zur Unterstützung entschieden.
Dies ist nicht effizient und erfordert jedes Mal eine separate Anpassung. Gibt es also eine dauerhafte Lösung?
02
HuggingFace ökologische Veredelung
Das Laden von Datensätzen durch MindNLP will lediglich zwei Dinge erreichen:
1. Unterstützen Sie große Datensätze ohne Anpassung
2. Verwenden Sie eine effiziente Pipeline
Da Sie es nicht selbst schaffen können, verlassen wir uns auf die Kraft der Ökologie. Zusätzlich zum Transformers-Warehouse hat HuggingFace seit mehreren Jahren Bibliotheken für verschiedene Prozesse des KI-Trainings entwickelt und unterstützt eine große Anzahl von Datensätzen. Und da HuggingFace Hosting-Dienste bereitstellt, sind auch viele neue Datensätze direkt im Datensatz-Hub. Direkt veröffentlichen auf. Wenn wir Datensätze verwenden, um Problem 1 zu lösen, schauen wir uns das zweite Problem an.
Tatsächlich wählen die meisten Leute, die MindSpore Dataset verwenden, grundsätzlich zwei Verarbeitungsmethoden:
1. Offline-Vorverarbeitung in MindRecord und anschließendes Laden mit MindDataset
2. Laden Sie den Datensatz in den Speicher und laden Sie ihn dann mit einem bestimmten Datensatzlader/GeneratorDataset
Um eine Online-Vorverarbeitung durchführen zu können, ist Methode 1 offensichtlich nicht ratsam, daher ist die Idee, HuggingFace-Datensätze zu übertragen, auch sehr einfach. Ich habe über zwei Ideen nachgedacht und werde sie im Folgenden diskutieren.
2. 1 Download des Pfropfdatensatzes
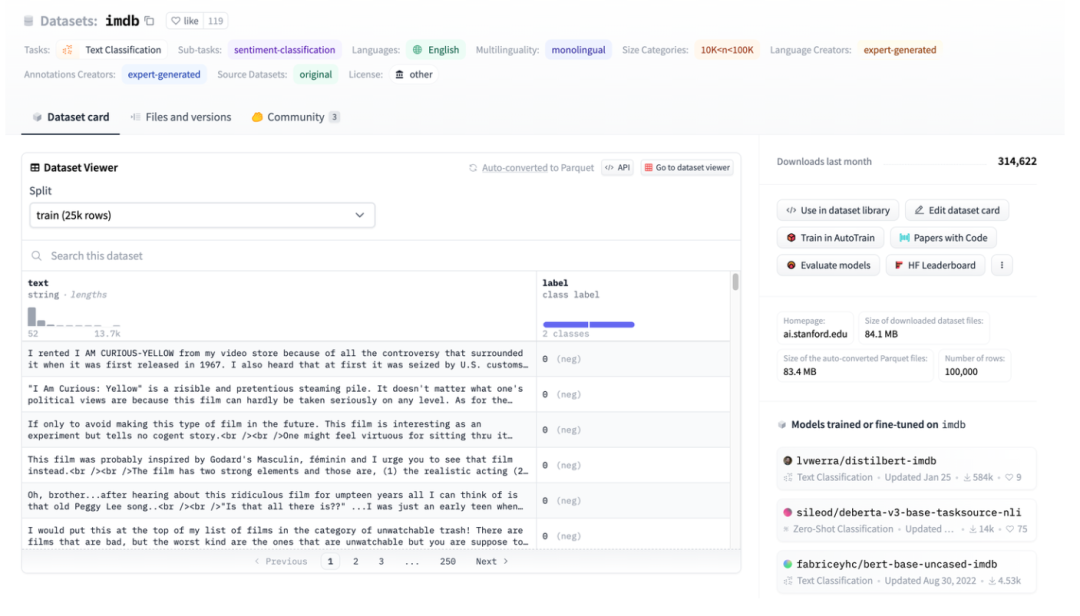 Abbildung 3: Darstellung des HuggingFace-Datensatzes am Beispiel von IMDB
Abbildung 3: Darstellung des HuggingFace-Datensatzes am Beispiel von IMDB
Abbildung 3 ist ein Screenshot der imdb-Seite. Sie können sehen, dass die Daten gut strukturiert sind. Verwenden Sie dann HuggingFace Datasets, um sie direkt herunterzuladen, und verwenden Sie dann direkt den abstrakten Datenlader TextFileDataset, um die verarbeiteten Dateien direkt zu lesen.
Abbildung 4: TextFileDataset-Schnittstelle
Sie können sehen, dass TextFileDataset zum Laden nur den Dateipfad oder die Pfadliste übergeben muss. Im praktischen Betrieb bin ich jedoch auf ein Problem gestoßen: HuggingFace Datasets verwendet Apache Arrow-Dateien.
Abbildung 5: Einführung in das Pfeilformat von HuggingFace-Datensätzen
Apache Arrow[2] ist ein sprachunabhängiger, systemübergreifender Hochleistungs-Datenaustauschformatstandard, der nicht kopiert werden kann. Dies bedeutet, dass der Datensatz von MindSpore nicht direkt und einfach gelesen werden kann. Er kann zwar auch mit der Pyarrow-Bibliothek betrieben werden, dies erhöht jedoch die Komplexität und führt zu einem Zustand, der vor dem Laden eine Vorverarbeitung erfordert. Es stellt sich jedoch heraus, dass die Eigenschaften von Arrow-Dateien besser für den Datensatz von MindSpore geeignet sind.
2. 2 Vorteile des Pfeilformats
In der Multiwalker-Umgebung versuchen zweibeinige Roboter, ihre Last zu tragen und nach rechts zu gehen. Mehrere Roboter transportieren eine große Ladung und müssen zusammenarbeiten, wie im Bild unten gezeigt.
HuggingFace verwendet das Apache Arrow-Format, das mehrere offensichtliche Vorteile bietet:
1. Das Standardformat von Arrow ermöglicht Lesevorgänge ohne Kopie, wodurch praktisch der gesamte Serialisierungsaufwand entfällt.
2. Arrow ist spaltenorientiert, sodass die Abfrage und Verarbeitung von Datenausschnitten oder Datenspalten schneller erfolgt.
3. Arrow behandelt jeden Datensatz als speicherzugeordnete Datei. Beim Zugriff auf Teildaten in einer großen Datei ist es nicht erforderlich, die gesamte Datei zu laden, und mehrere Prozesse können sich den Speicher teilen. Die Speicherzuordnung ermöglicht die Verwendung großer Datensätze auf Computern mit relativ kleinem Gerätespeicher; das Laden des gesamten englischen Wikipedia-Datensatzes erfordert nur wenige MB RAM.
4. Beim Laden von Daten können Sie die Streaming-Parameter für das Streaming-Laden festlegen.
Schauen wir uns an dieser Stelle noch einmal das Design der MindSpore-Daten-Engine an: On-Demand-Laden, Online-Verarbeitung und HuggingFace-Datensätze passen perfekt zusammen.
2.3 MindNLP-Anpassung
Da es sich bei der von HuggingFace Datasets selbst geladenen Pfeildatei um eine speicherzugeordnete Datei handelt, muss sie nicht in den Speicher kopiert werden. Durch die Verwendung des Indexindex wird sie nicht vollständig geladen, sodass sie direkt als Quelle zum Laden und Senden von Daten verwendet werden kann direkt zum GeneratorDataset zur Verwendung.
Abbildung 6: GeneratorDataset-Schnittstelle
Die Erstellung von GeneratorDataset erfordert hauptsächlich Quelldaten und den Spaltennamen, der jeder Datenspalte entspricht. Wenn Sie sich Abbildung 3 ansehen, können Sie sehen, dass HuggingFace Datasets alle Spalten benannt hat. Das Folgende ist der abgefangene Kerncode:
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
Auch die Verarbeitungsschritte sind denkbar einfach:
1. Laden Sie mit „load_dataset“ der HuggingFace-Datensätze
2. Verwenden Sie zur Kapselung gekapselte Transitklassen
3. Übergeben Sie GeneratorDataset
Aus Gründen der Benutzerfreundlichkeit behalten wir die Parametereinstellungen der Schnittstelle „load_dataset“ genau wie bei HuggingFace Datasets bei, aber was zurückgegeben wird, ist eine Klasse oder ein Dict, die von der MindSpore-Daten-Engine verarbeitet werden können, sodass die nahtlose Verbindung der Die Datenverarbeitungsfunktionen von Shengsi MindSpore können abgeschlossen werden.
Lassen Sie uns kurz über die Struktur der Transitklasse sprechen.
Zu den Datentypen von HuggingFace Datasets gehören Dataset und IterableDataset:
Es gibt zwei Arten von Datensatzobjekten: ein Dataset und ein IterableDataset. Welche Art von Datensatz Sie verwenden oder erstellen, hängt von der Größe des Datensatzes ab. Im Allgemeinen ist ein IterableDataset aufgrund seines verzögerten Verhaltens und seiner Geschwindigkeitsvorteile ideal für große Datenmengen (denken Sie an Hunderte von GB!), während Dataset für alles andere großartig ist. Auf dieser Seite werden die Unterschiede zwischen einem Datensatz und einem iterierbaren Datensatz verglichen, um Ihnen bei der Auswahl des richtigen Datensatzobjekts für Sie zu helfen.[3]
Beim Durchlaufen dieser beiden Arten von Datensätzen wird ein Diktat zurückgegeben, das von der Datenverarbeitungs-Engine von MindSpore nicht unterstützt wird. Daher werden zwei Übertragungsklassen erstellt, um die Daten im Diktat zu lesen, ohne weitere zusätzliche Operationen hinzuzufügen. Erstellen Sie für Dataset eine TransferDataset-Klasse und lesen Sie sie in der Methode __getitem__ ein.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
Für Streaming-Daten IterableDataset müssen Sie diese in der Methode __iter__ lesen und TransferIterableDataset als iterierbares Objekt erstellen.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
Zu diesem Zeitpunkt wurde ein Plan fertiggestellt, der wenig Aufwand erfordert und HuggingFace-Datensätze vollständig aufpfropfen kann. Im Vergleich zu Paddle NLP ist die Pfropfstrategie einfach und elegant.
03
abschließend
Als Open-Source-Framework gibt es tatsächlich eine große Anzahl nutzbarer Open-Source-Ressourcen. Die sogenannte kontinuierliche Erweiterung des Nord-Süd-Ökosystems bedeutet nicht unbedingt, dass ich es verwende, du nutzt es, du nutzt mich , und Sie sind glücklich und sorgenfrei. Dieses Mal werden HuggingFace-Datensätze in den praktischen Austausch von Shengsi MindSpore integriert, was ein tieferes Verständnis von Shengsi MindNLP ermöglicht und auch zur Erweiterung des Shengsi MindSpore-Ökosystems beiträgt.
Verweise
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! Google bestätigte Entlassungen, die den „35-jährigen Fluch“ chinesischer Programmierer in den Flutter-, Dart- und Teams- Python mit sich brachten stark und wird von GPT-4.5 vermutet; Tongyi Qianwen Open Source 8 Modelle Arc Browser für Windows 1.0 in 3 Monaten offiziell GA Windows 10 Marktanteil erreicht 70 %, Windows 11 GitHub veröffentlicht weiterhin KI-natives Entwicklungstool GitHub Copilot Workspace JAVA ist die einzige starke Abfrage, die OLTP+OLAP verarbeiten kann. Dies ist das beste ORM. Wir treffen uns zu spät.