
Autor: Wu Jipeng, Big-Data-Technologiemanager der Wuxi Xishang Bank
Bearbeitung und Endbearbeitung: SelectDB- Technikteam
Einführung: Um die Werttransformation von Datenbeständen und ein umfassendes digitales und intelligentes Risikomanagement zu realisieren, hat die Big-Data-Plattform der Wuxi Xishang Bank die Entwicklung vom Hive-Offline-Data-Warehouse zum Apache-Doris -Echtzeit-Data-Warehouse durchlaufen und verfügt derzeit über Zugriff auf Hunderte von Echtzeittabellen, Hunderte von Datendienstschnittstellen und die Schnittstelle QPS erreicht Millionen von Ebenen und löst die Probleme unzureichender Aktualität, hoher Kosten und geringer Effizienz von Offline-Data-Warehouses, wodurch Abfragen um mehr als das Zehnfache beschleunigt werden und Bereitstellung zeitnaher, effektiver und sicherer Datendienste und Nutzungserfahrung für Benutzer.
Angesichts der Veränderungen, die die Finanzbranche durch neue Technologien wie Big Data, das Internet der Dinge und künstliche Intelligenz mit sich bringt, legt die Wuxi Xishang Bank einen wichtigen Schwerpunkt auf die Entwicklung technologischer Fähigkeiten und Big-Data-Fähigkeiten. Um die Werttransformation von Datenbeständen und ein umfassendes digitales und intelligentes Risikomanagement zu realisieren, hat die Wuxi Xishang Bank eine Big-Data-Plattform eingerichtet, die auf dem dreiflügeligen integrierten Technologielayout „Online-Geschäft, datenbasierte Risikokontrolle und plattformbasiert“ basiert Architektur". Um den massiven Zufluss von Transaktionsaufzeichnungen und Kreditantragsdaten jeden Tag zu verwalten und mithilfe von Benutzerporträts, Echtzeitberichten, Echtzeit-Risikokontrolle und anderen Anwendungen den Benutzern eine zeitnahere, effektivere und sicherere Bereitstellung zu bieten Datendienste und Benutzererfahrung.
Die Big-Data-Plattform der Wuxi Xishang Bank hat sich von einem Offline-Data-Warehouse auf Basis von Hive zu einem Echtzeit-Data-Warehouse auf Basis von Apache Doris entwickelt . Durch das Upgrade der Architektur wurden die Probleme unzureichender Aktualität, hoher Kosten und geringer Effizienz des Offline-Data-Warehouses gelöst und die Abfragegeschwindigkeit um das Zehnfache erhöht, sodass Banken das Kundenverhalten schneller wahrnehmen und zeitnahe Erkenntnisse gewinnen können in abnormales Transaktionsverhalten ein und identifizieren und verhindern Sie potenzielle Risiken. In diesem Artikel werden die Entwicklung der Big-Data-Plattform der Wuxi Xishang Bank und die Implementierung von Apache Doris in Echtzeitabfragen, Marketingdiensten, Risikokontrolldiensten und anderen Szenarien ausführlich vorgestellt.
Big-Data-Offline-Data-Warehouse basierend auf Hive
01 Nachfrageszenario
Die Wuxi Xishang Bank hat in der Anfangsphase ein Big-Data-Offline-Data-Warehouse aufgebaut, das hauptsächlich Szenarien wie Datenberichterstellung, Datenrisikokontrolle, Datenoperationen, Ad-hoc-Abfragen und den täglichen Datenabruf bedient, unter anderem:
-
Datenberichterstattung: Kundenrisiko, EAST-Berichterstattung, 1104, große Konzentration, Kreditberichterstattung, Zinsberichterstattung, Bekämpfung der Geldwäsche, grundlegende Finanzdatenberichterstattung usw.
-
Datenrisikokontrolle: einschließlich Risikokontrolle für Kreditrisikokontrollindikatoren, Benutzerverhaltensindikatoren, Betrugsbekämpfung, Frühwarnung nach der Kreditvergabe, Verwaltung nach der Kreditvergabe und andere Risikokontrollen.
-
Datenbetrieb: Bereitstellung regelmäßiger Batch-Daten für BI-Geschäftsberichte, Management-Cockpit, externe Kanäle und verschiedene Systeme innerhalb der Branche.
-
Ad-hoc-Abfrage und täglicher Datenabruf: Führen Sie Datenanalyse, Datenentwicklung und Datenextraktion entsprechend den Geschäftsanforderungen durch.
02 Architektur und Schmerzpunkte
In frühen Offline-Data-Warehouses stammten die Daten hauptsächlich aus Oracle, MySQL, MongoDB, Elasticsearch und Dateien. Mithilfe von Tools wie Sqoop, Spark, externen Datenquellen und Shell werden die Daten offline in das Hive-Offline-Data-Warehouse extrahiert und hierarchisch über ODS, DWD, DWS und ADS in Hive verarbeitet die Anwendungsdienstschicht.
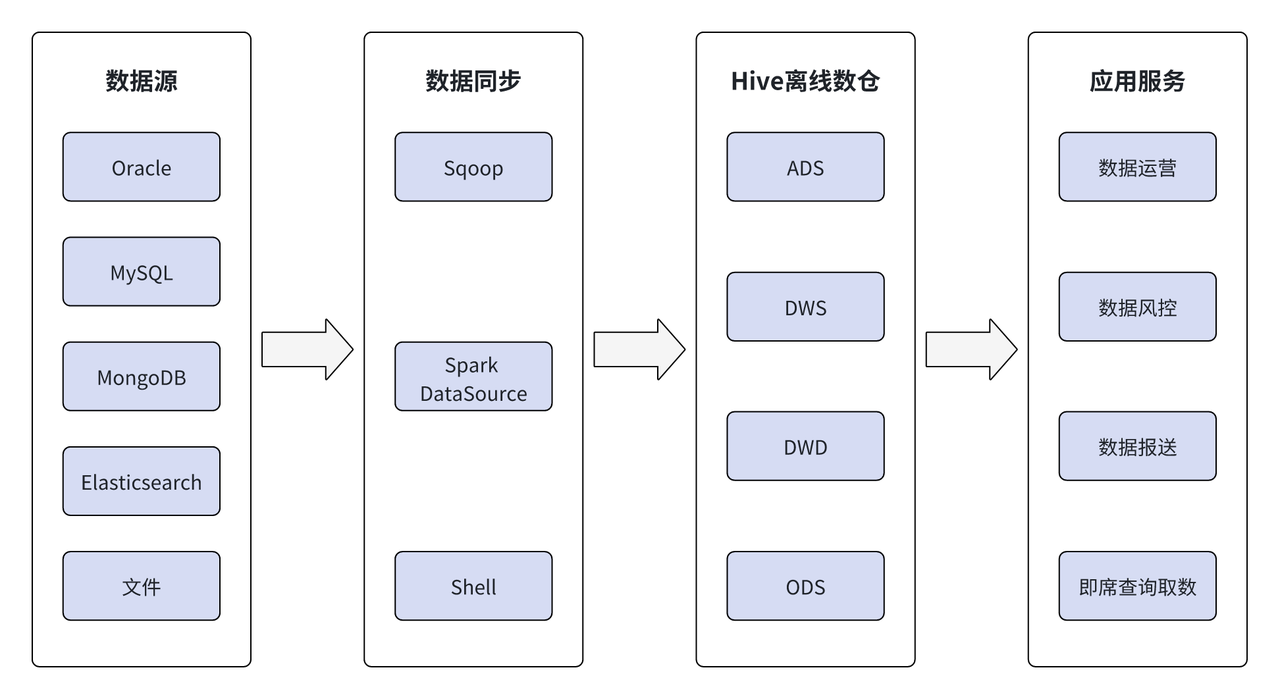
Mit der Entwicklung und Ausweitung des Geschäfts der Wuxi Xishang Bank stellen die relevanten Geschäftsabteilungen in den letzten Jahren immer höhere Anforderungen an die Datenverarbeitung. Das Offline-Data Warehouse kann den neuen Anforderungen nicht mehr gerecht werden, was sich hauptsächlich in Folgendem widerspiegelt:
-
Unzureichende Datenaktualität: Das Offline-Data-Warehouse verwendet eine Offline-Extraktionslösung und die Datenaktualität beträgt T+1. Berichte, Daten-Dashboards, Marketingindikatoren und Risikokontrollvariablen erfordern jedoch Datenaktualisierungen in Echtzeit, die die aktuelle Architektur nicht erfüllen kann .
-
Die Effizienz der Datenabfrage ist gering: Es ist eine Abfrageantwort auf der zweiten Ebene und der Millisekundenebene erforderlich. Offline-Data-Warehouse-Ausführungs-Engines sind hauptsächlich Hive und Spark. Wenn Hive ausgeführt wird, wird die Abfrage in mehrere MapReduce-Aufgaben zerlegt und die Ausführungszeit liegt im Allgemeinen bei Minuten, was die Abfrage erheblich beeinträchtigt Effizienz.
-
Hohe Wartungskosten: Die unterste Ebene des Offline-Data Warehouse umfasst viele Technologie-Stacks, darunter LDAP, Ranger, ZooKeeper, HDFS, YARN, Hive, Spark und andere Systeme, was zu hohen Systemwartungskosten führt. Obwohl es auch Echtzeitspeicher und Dienste von HBase + Phoenix online gibt, kann es das aktuelle Problem immer noch nicht vollständig lösen, da seine Komponenten relativ „schwer“ sind, die Community nicht aktiv ist und einige Funktionen die Echtzeitanforderungen nicht erfüllen können Szenarien.
Technologieauswahl
Angesichts der Schwachstellen unzureichender Aktualität von Offline-Data-Warehouses, geringer Abfrageeffizienz und hoher Wartungskosten aufgrund mehrerer Technologie-Stacks ist der Aufbau von Echtzeit-Data-Warehouses zwingend erforderlich. Nach eingehender Recherche zu mehreren MPP-Datenbanken entschied sich die Wuxi Xishang Bank für den Aufbau einer Echtzeit-Data-Warehouse-Plattform mit Apache Doris als Kern. Mit dieser Technologieauswahl soll sichergestellt werden, dass die Plattform den hohen Anforderungen der Echtzeit-Geschäftsanalyse auf Datenschreib-, Abfrage- und Serviceebene gerecht wird. Die Gründe für die Wahl von Apache Doris sind folgende:
-
Effiziente Datenaktualisierung: Apache Doris Unique Key unterstützt große Datenaktualisierungen, das Schreiben kleiner Datenstapel in Echtzeit und einfache Änderungen der Tabellenstruktur. Insbesondere bei der Verarbeitung großer Datenmengen und Partitionen kann das Problem großer Änderungsmengen und ungenauer Änderungen effektiv vermieden werden, wodurch bequemere Datenaktualisierungen in Echtzeit bereitgestellt werden.
-
Echtzeit-Schreiben mit geringer Latenz: Unterstützt das Schreiben, Aktualisieren und Löschen von Daten in Echtzeit auf der zweiten Ebene; Primärschlüsselmodell Sequenzspalteneinstellungen, um die Ordnungsmäßigkeit des Datenimports im Prozess sicherzustellen.
-
Hervorragende Abfrageleistung: Apache Doris verfügt über leistungsstarke Multi-Table-Join-Funktionen. Mithilfe der vektorisierten Ausführungs-Engine, des CBO-Abfrageoptimierers, der MPP-Architektur, intelligenter materialisierter Ansichten und anderer Funktionen kann eine Abfrageantwort auf Millisekundenebene für große Datenmengen erreicht werden Abfragen erforderlich. Gleichzeitig unterstützt Apache Doris Version 2.0 die gemischte Speicherung von Zeilen und Spalten und kann in Punktabfrageszenarien Zehntausende gleichzeitiger Antworten auf Millisekundenebene erzielen.
-
Die Plattform ist äußerst einfach zu bedienen: Sie ist mit dem MySQL-Protokoll kompatibel und bietet umfangreiche API-Schnittstellen, die die Schwierigkeit bei der Verwendung von Anwendungen der oberen Ebene verringern können. Gleichzeitig verfügt Apache Doris über eine optimierte Architektur mit nur zwei Prozessen, FE und BE. Sie vereinfacht die Knotenerweiterung und -kontraktion, unterstützt die Automatisierung des Clustermanagements und zeichnet sich durch niedrige Nutzungskosten aus niedrige Betriebs- und Wartungskosten.
Einführung von Apache Doris zum Aufbau eines Big-Data-Echtzeit-Data-Warehouse
Im April 2022 führte die Wuxi Xishang Bank Apache Doris ein, um eine Echtzeit-Data-Warehouse-Plattform aufzubauen. Da der Umfang der Bankdaten sehr groß ist, ist es schwierig, die gesamte Menge an historischen Daten aus der Geschäftsdatenbank zu synchronisieren und gleichzeitig auf Echtzeitdaten zuzugreifen. Daher basiert die anfängliche Echtzeitdatenkonstruktion hauptsächlich auf Offline-Daten.
Zunächst wird die HDFS-Broker-Methode verwendet, um historische Echtzeitdaten effizient zu initialisieren. Gleichzeitig wird das Erfassungstool DataPipeline verwendet, um die Daten in Echtzeit im Kafka-Cluster zu sammeln, und dann wird Flink in den hartcodierten Modus geschrieben Schreiben Sie die Daten in Echtzeit in Apache Doris. Schließlich wird Apache Doris mit Hilfe der Schnittstellendienstfunktionen der Feiliu-Plattform als einheitliche Speicher- und Abfrage-Engine verwendet, um Dienste für jeden Geschäftsbereich bereitzustellen.
Die Feiliu-Plattform ist eine einheitliche, umfassende Plattform, die von der Wuxi Xishang Bank zur Bewältigung zukünftiger Echtzeit-Geschäftsszenarien entwickelt wurde. Sie umfasst hauptsächlich Echtzeit-Erfassung, Echtzeit-Synchronisierungstools, Echtzeit- Data-Warehouse , Echtzeit-Berechnungen und Datendienste .
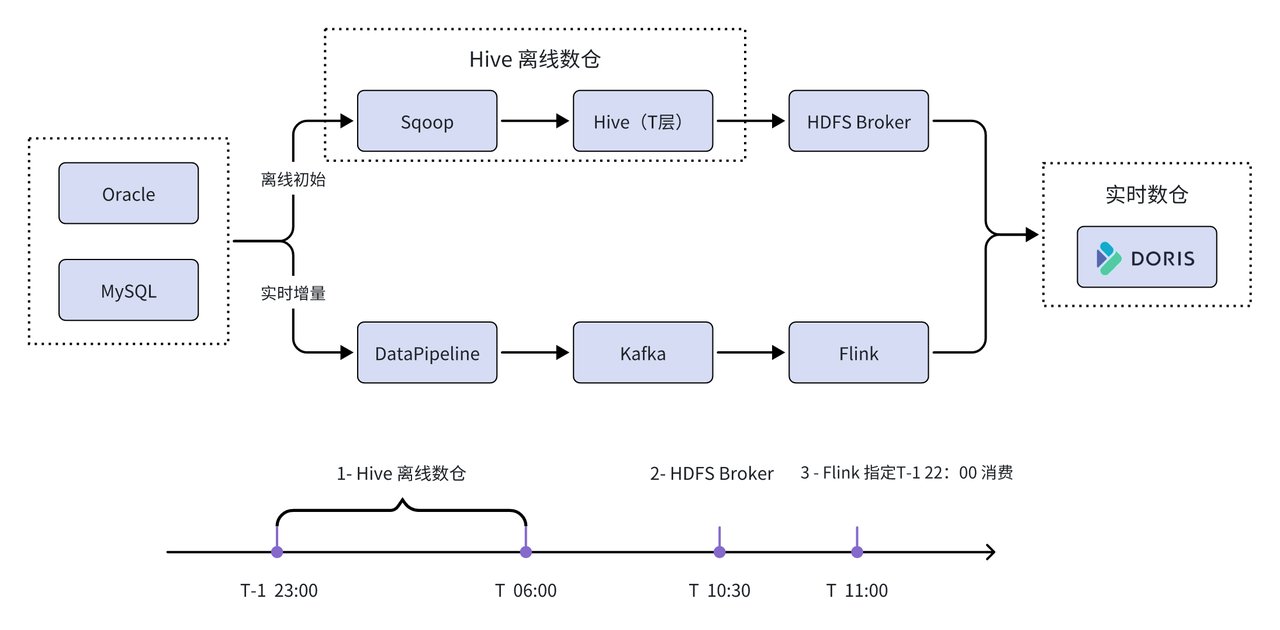
01 Verbessern Sie die Datenflussverbindungen
Ausgehend von den Eigenschaften von Bankdaten und der Kombination der funktionalen Vorteile von Apache Doris hat die Wuxi Xishang Bank die Datenflussverknüpfung neu überdacht und verbessert:
-
Durch die Synchronisierung historischer Daten aus Offline-Data-Warehouses werden Risiken minimiert: In dem Artikel wurde erwähnt, dass aufgrund der enormen Menge an Bankdaten große Datenmengen durch Firewalls und Switches fließen, wenn die gesamte Menge historischer Daten direkt von Oracle und MySQL synchronisiert wird. Dies führt dazu, dass andere Geschäftsanfragen blockiert werden und es zu Problemen wie Dienst-Timeouts kommt. Um diese potenziellen Risiken und Probleme zu vermeiden, erstellen Sie zunächst die Doris-Tabellenstruktur stapelweise auf Basis von Oracle und MySQL und synchronisieren Sie dann mithilfe des HDFS-Brokers die vollständigen T-1-Daten aus der Offline-Data-Warehouse-Hive-ODS-Schicht mit Doris, um sie zu minimieren Risiken.
-
Inkrementelle Echtzeit-Extraktion, sicherer Extraktionsmodus: Die Echtzeit-Extraktion verursacht eine sehr geringe Menge an Festplatten-IO, Speicher und CPU-Verbrauch, um eine Beeinträchtigung der Hauptgeschäftsdatenbank, standardmäßig der Geschäftsslavedatenbank oder dergleichen, zu vermeiden Die Wiederherstellung nach einem Katastrophenfall in der Stadt wird in Echtzeit durchgeführt. Für Geschäftsanforderungen mit hohen Aktualitätsanforderungen ist eine vollständige Auswertung erforderlich, bevor Daten aus der Hauptgeschäftsdatenbank extrahiert werden können.
-
Erstellen Sie die Kafka-Schicht, um die Datenkonsistenz sicherzustellen: Erstellen Sie die Kafka-Schicht als Zwischenschicht für die Datenübertragung, um die Ordnung und Konsistenz der Daten sicherzustellen. Der Schlüssel der von Datapipeline gesendeten Daten ist als Database-Table-PK konfiguriert und wird entsprechend derselben Dimension geordnet an eine Partition (Partition) des Kafka-Themas gesendet. Da die jeweiligen Partitionen von Kafka Topic in der richtigen Reihenfolge gespeichert werden, können nachgeschaltete Verbraucher Daten verarbeiten, um Auswirkungen außerhalb der Reihenfolge auf die Genauigkeit von Echtzeit-Data-Warehouse-Daten zu vermeiden. Darüber hinaus kann die Kafka-Schicht als öffentliche Datenschicht und in Marketing-, Risikokontroll- und anderen Geschäftsszenarien verwendet werden.
-
Daten werden in Echtzeit geschrieben, um sicherzustellen, dass Daten nicht verloren gehen oder dupliziert werden: In tatsächlichen Anwendungsszenarien führt die Offline-Verbindung am Tag T-1 von 23:00 bis 6:00 Uhr eine Offline-Datenstapelung durch und verwendet um 10:00 Uhr die HDFS-Broker-Methode. Uhr am Tag T. Initialisierung der historischen Daten der Tabelle. Der Echtzeit-Link verwendet Flink, um zur Echtzeit-Datensynchronisierung direkt auf das bei T-1 verbrauchte Kafka-Thema zu verweisen. Während des Echtzeit-Verbrauchsprozesses treten jedoch einige überlappende Daten auf. Um dieses Problem zu lösen, wird das Unique Key-Modell von Apache Doris ausgewählt (dieses Modell unterstützt Daten-Idempotenz), das überlappende Daten schnell abdecken kann, und der Flink-Doris-Connector wird verwendet, um die Echtzeit-Data-Warehouse-Verbindung zu gewährleisten Konsistente Echtzeit-Datensynchronisierung. Es ist nicht schwer, es wegzuwerfen.
02 Flexible Datendienste
Um genaue und effiziente Antworten auf Anfragen bereitzustellen, hat die Wuxi Xishang Bank die folgenden drei Methoden zur Implementierung von Datendiensten übernommen:
-
Offline-Datenabfrage: Für Offline-Anforderungen müssen Daten schnell abgefragt werden. Die Wuxi Xishang Bank importiert regelmäßig Daten aus dem Offline-Data-Warehouse in die Doris-Tabelle des Echtzeit-Data-Warehouse. Dies ermöglicht schnelle Abfragen im Echtzeit-Data-Warehouse, um den Anforderungen der Offline-Datenanalyse und Entscheidungsfindung gerecht zu werden.
-
Einfache Echtzeitanforderungen: Für unkomplizierte Echtzeitanforderungen nutzt die Wuxi Xishang Bank die effizienten Abfragefunktionen von Apache Doris, um die Möglichkeit zu bieten, die Datendienstschnittstelle auf der „Fei Liu“-Plattform direkt zu konfigurieren ODS-Schicht des Echtzeit-Data-Warehouse. Führen Sie eine manuelle Konfiguration durch. Auf diese Weise können die Anforderungen einfacher Echtzeit-Datenabfragen schnell erfüllt werden.
-
Komplexe Echtzeitanforderungen: Für komplexe Echtzeitanforderungen verwendet die Wuxi Xishang Bank den Echtzeit-Kafka-Datenfluss und das Flink-Light-Computing, um den Datenfluss in die DWD-Schichttabelle des Echtzeit-Data-Warehouse zu schreiben und auf Details zu basieren die „Fei Liu“-Plattform Das SQL der Tabelle wird erneut aggregiert und die Datendienstschnittstelle wird manuell konfiguriert, um den Anforderungen komplexer Echtzeit-Datenabfragen gerecht zu werden.
Angesichts vielfältigerer Serviceszenarien
01 Antwort auf BI-Berichtsanfragen innerhalb von Sekunden
Basierend auf Apache Doris erfüllt die Wuxi Xishang Bank die Anforderungen mehrerer Szenarien wie tägliche Datenanalyse, täglicher Datenabruf und BI-Echtzeitberichte. Die Abfrageantwortzeit wird erheblich verkürzt und Abfrageergebnisse können innerhalb von 1 Sekunde zurückgegeben werden Reduziert die Wartezeit von Datenanalysten erheblich. Kosten und Verbrauch von Serverressourcen.
Im Hinblick auf BI-Echtzeitberichte hat die Wuxi Xishang Bank beispielsweise Echtzeit-Kreditdatentabellen, Echtzeit-Einzahlungsdatentabellen, Kontostandstabellen und andere Berichte erstellt. **Diese Berichte umfassen durchschnittlich 253 Zeilen SQL-Code und eine durchschnittliche Antwortzeit von 1,5 Sekunden. **Darüber hinaus kann die Wuxi Xishang Bank durch die Optimierung der Abfrageleistung und des Datenmodelldesigns in kurzer Zeit genaue Echtzeitberichte erstellen, um zeitnahe Datenunterstützung für Geschäftsentscheidungen bereitzustellen.
02 Unterstützen Sie personalisierte Marketingpläne
Im Hinblick auf Marketingdatendienste basierte die Wuxi Xishang Bank auf Apache Doris, um Kunden-Tags anzureichern und genaue Kundenporträts zu verbessern, und führte verschiedene Marketingaktivitäten durch, wie Aktivitäten zur Erhöhung des Nettovermögens und Aktivitäten zur Künstler-Blindbox. Durch die Analyse von Echtzeitdaten können Banken den Konvertierungsstatus aktiver Benutzer zeitnah beobachten und die Strategie zur Betriebsauswahl umgehend anpassen, um personalisiertes Marketing von „Tausend Menschen haben ein Gesicht“ bis „Tausend Menschen haben eins“ zu erreichen Gesicht".
Beispielsweise nutzt die Wuxi Xishang Bank bei Marketingaktivitäten wie Nettovermögenserhöhungsaktivitäten und Künstler-Blindbox-Aktivitäten die Funktionen des Apache Doris Echtzeit-Data-Warehouse, um kontinuierlich Aktivitätsdaten zu sammeln, zu analysieren und Feedback zu geben. Durch die Beobachtung der Benutzerumwandlungen in Echtzeit können wir die Strategie zur Betriebsauswahl umgehend anpassen, um die Übereinstimmung zwischen Personal und Aktivitäten sicherzustellen. Diese personalisierte Marketingstrategie ermöglicht es Banken, die Kundenbedürfnisse besser zu erfüllen und das Engagement, die Antwortraten und die Bindung der Benutzer zu steigern.
03 Effiziente Risikoerkennung und -kontrolle
Die Einführung von Apache Doris ermöglicht es der Wuxi Xishang Bank, charakteristische Risikokontrollvariablen und abnormales Transaktionsverhalten schneller zu berechnen. Am Beispiel der Registrierung neuer Benutzer kann das System beim Ausfüllen von Informationen durch Benutzer schnell die Ergebnisse der Genehmigungsstrategie basierend auf charakteristischen Variablen der Risikokontrolle in Echtzeit ermitteln, das Strategiemodell zeitnah optimieren und die Qualität und Genauigkeit sicherstellen der Zustimmung.
Darüber hinaus ist die Wuxi Xishang Bank in der Lage, potenzielle Risiken rechtzeitig zu erkennen und zu verhindern. Banken können beispielsweise Transaktionsdaten wie eine große Anzahl von Transaktionen und ungewöhnliche Transaktionsbeträge in kurzer Zeit in Echtzeit erfassen und überwachen, um ungewöhnliches Transaktionsverhalten und Betrug rechtzeitig zu erkennen. Durch Echtzeit-Datenanalyse können Banken potenzielle Risiken schnell erkennen und geeignete Maßnahmen zur Vorbeugung und Reaktion ergreifen.
Darüber hinaus nutzt die Wuxi Xishang Bank auch das Echtzeit-Data-Warehouse Apache Doris, um Echtzeitanalysen der Kredithistorie und Kreditantragsinformationen der Kunden durchzuführen. Durch die schnelle Feststellung, ob der Antragsbetrag des Kunden seiner Rückzahlungsfähigkeit entspricht, können Banken zeitnahe Risikobewertungen und Entscheidungen treffen, um Kreditrisiken wirksam zu kontrollieren.
04 Die Daten des siebentägigen Handelsflussdiagramms werden automatisch aktualisiert.
In tatsächlichen Anwendungsszenarien ist die Datenmenge im Transaktionsflussblatt sehr groß und umfasst Transaktionsseriennummer, Transaktionsdatum, Transaktionstyp, Transaktionsbetrag und andere Daten. Um eine zeitnahe Aktualisierung der Daten sicherzustellen, entschied sich die Wuxi Xishang Bank für die Verwendung der Funktion der dynamischen Partitionstabelle von Apache Doris. Diese Funktion kann automatisch Partitionen erstellen und Transaktionsflussdaten, die älter als sieben Tage sind, automatisch löschen, um eine automatische Aktualisierung der Daten in der Sieben-Tage-Transaktionsflusstabelle zu erreichen. Spezifische Vorgänge umfassen die folgenden Schritte:
-
Erstellen Sie eine Pseudospalte mit dem Geschäftsdatum als gemeinsamen Primärschlüssel.
-
Wenn die ID-Daten
tran_dateüber Tage hinweg aktualisiert werden, führt der Code einen Tabellenrückgabevorgang durch; -
Suchen Sie den entsprechenden Datumswert in der Einfüge- und Partitionstabelle der Daten, fügen Sie ihn in Update Json ein und aktualisieren Sie ihn in der Datenbank.

Mit Hilfe der dynamischen Partitionierungs- und Tabellenpartitionierungsfunktion von Apache Doris kann nicht nur der stabile Betrieb des zugrunde liegenden Primärschlüssels und Servers sichergestellt werden, sondern es werden auch automatisch nur sieben Tage lang Transaktionsdaten aktualisiert und aufbewahrt, damit Analysten sie abfragen und erfüllen können 1,5-sekündige Anfrage-Antwort-Anforderung unter einer Million QPS .
05 Punktabfrage mit hoher Parallelität
Frühe Marketing- und Risikokontrollanwendungsszenarien stützten sich hauptsächlich auf zwei Sätze von HBase-Clustern zur Unterstützung von Aufzählungsdiensten. In tatsächlichen Anwendungen treten jedoch Probleme wie abnormaler Master-/Regionserver-Exit und RIT auf. Um dieses Problem zu vermeiden, können Sie die hohe Fähigkeit zur gleichzeitigen Abfrage von Apache Doris nutzen und beim Erstellen der Tabelle mit eindeutigen Schlüsseln die Merge-on-Write-Strategie aktivieren, sodass die Primärschlüsselabfrage über einen vereinfachten SQL-Ausführungspfad abgeschlossen werden kann Nur ein RPC erforderlich.
Schließlich wurden durch Stresstests auf drei Knoten, wobei jeder Knoten mit 8C und 10 GB konfiguriert war, die folgenden erheblichen Vorteile erzielt:
-
In einem Abfrageszenario, in dem eine einzelne Tabelle 50 Millionen Daten enthält, liegt der QPS bei bis zu 25.000;
-
In einem Lese- und Schreibszenario mit mehreren Tabellen und 50 Millionen Daten erreicht QPS ebenfalls 20.000;
-
Auch die Stabilität komplexer SQL-Abfragen bleibt mit QPS 25.000 auf einem hohen Niveau;
-
Im Echtzeit-Lese- und Schreibszenario mehrerer Tabellen kann QPS auch bei 25.000 stabilisiert werden.
Abschluss
Derzeit hat Apache Doris auf Hunderte von Echtzeittabellen, Hunderte von Datendienstschnittstellen und Schnittstellen-QPS zugegriffen und erreicht Millionen in der Wuxi Xishang Bank. Darüber hinaus verbessert Apache Doris als einheitliches Abfrage-Gateway die Effizienz der historischen Datenanalyse erheblich. Im Vergleich zur ursprünglichen Antwortzeit auf Minutenebene beträgt die Abfragegeschwindigkeit mehr als das Zehnfache.
Zukünftig wird die Wuxi Xishang Bank weiterhin die Vorteile von Apache Doris erforschen und seine tiefere Anwendung in Echtzeitszenarien fördern.
-
In Bezug auf die Leistung: Weitere Optimierung von Abfragen mit hoher Parallelität, automatischer Partitionierung und Bucketing, Ausführungs-Engine und anderen Funktionen, um die Effizienz der Datenabfrageantwort zu verbessern;
-
In Bezug auf den Lastausgleich: Bauen Sie zwei Cluster auf, um gleichzeitig einen architektonischen Lastausgleich zu erreichen. Die Frühwarn- und Leistungsschaltermechanismen der Architektur werden verbessert, um einen unterbrechungsfreien Geschäftsbetrieb sicherzustellen.
-
In Bezug auf die Clusterstabilität: Verwirklichen Sie die „Arbeitsteilung und Zusammenarbeit“ des Apache Doris-Clusters, sodass jeder von ihnen Aufgaben wie die Berechnung und Speicherung von Echtzeit-Data Warehouses, beschleunigte Abfragen von Datendiensten usw. übernehmen kann. um die Stabilität und Zuverlässigkeit des Systems weiter zu verbessern.