
Autor: Ye Jidong vom vivo Internet Big Data Team
In diesem Artikel wird hauptsächlich der gesamte Prozess der Analyse und Lösung des Problems des Speicherüberlaufs vorgestellt, der durch einen durch die FileSystem-Klasse verursachten Online-Speicherverlust verursacht wird.
Definition eines Speicherverlusts : Ein Objekt oder eine Variable, die vom Programm nicht mehr verwendet wird, belegt weiterhin Speicherplatz im Speicher, und die JVM kann das geänderte Objekt oder die geänderte Variable nicht ordnungsgemäß zurückfordern. Ein einzelner Speicherverlust scheint keine große Auswirkung zu haben, aber die Anhäufung von Speicherverlusten führt zu einem Speicherüberlauf.
Speicherüberlauf (nicht genügend Speicher) : Bezieht sich auf einen Fehler, bei dem das Programm aufgrund unzureichenden zugewiesenen Speicherplatzes oder unsachgemäßer Verwendung während der Ausführung des Programms nicht weiter ausgeführt werden kann. Zu diesem Zeitpunkt wird ein OOM-Fehler gemeldet sogenannter Speicherüberlauf.
1. Hintergrund
Xiaoye tötete am Wochenende Menschen im Canyon of Kings und sein Telefon erhielt plötzlich eine große Anzahl von Maschinen-CPU-Alarmen. Wenn die CPU-Auslastung 80 % übersteigt, wird gleichzeitig auch ein Alarm „Vollständiger GC“ ausgelöst für den Dienst. Dieser Dienst ist ein sehr wichtiger Dienst für das Xiaoye-Projektteam. Xiaoye legte die Ehre der Könige schnell ab und schaltete den Computer ein, um das Problem zu überprüfen.


Abbildung 1.1 CPU-Alarm Voll-GC-Alarm
2. Problemerkennung
2.1 Überwachung und Anzeige
Da die Service-CPU und der vollständige GC einen Alarm auslösen, können Sie sehen, dass beide Monitore gleichzeitig eine abnormale Ausbuchtung aufweisen, wenn die CPU einen Alarm auslöst. Vollständige GC kommt besonders häufig vor. Es wird vermutet, dass der Alarm zur Erhöhung der CPU-Auslastung durch vollständige GC verursacht werden könnte .
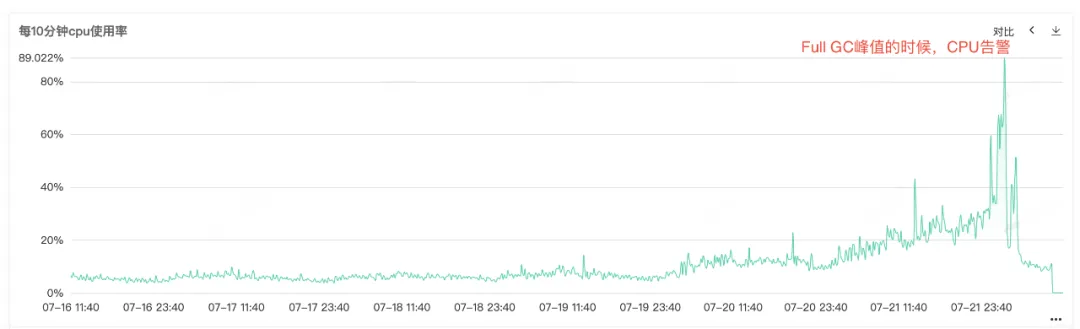
Abbildung 2.1 CPU-Auslastung
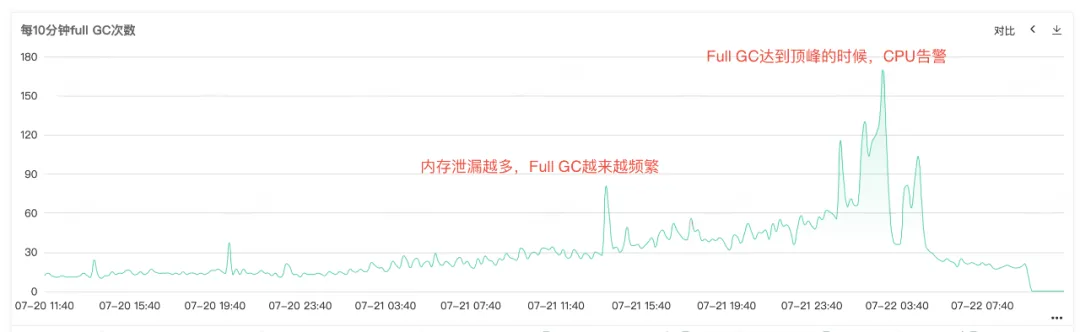
Abbildung 2.2 Vollständige GC-Zeiten
2.2 Speicherverlust
Aus dem häufigen Full Gc können wir erkennen, dass es Probleme mit dem Speicherrecycling des Dienstes geben muss. Überprüfen Sie daher die Überwachung des Heapspeichers, des Speichers der alten Generation und des Speichers der jungen Generation des Dienstes Bei der alten Generation können wir sehen, dass der residente Speicher der alten Generation immer größer wird und immer mehr Objekte in der alten Generation nicht recycelt werden können. Schließlich ist der gesamte residente Speicher belegt, und es ist ein offensichtlicher Speicherverlust zu erkennen .
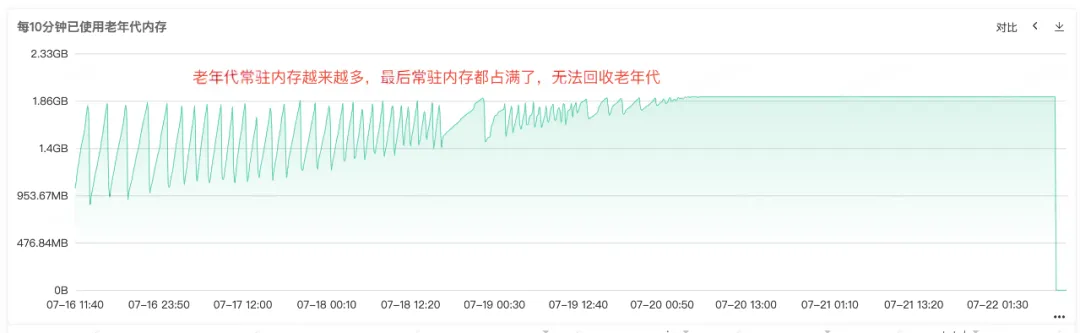
Abbildung 2.3 Speicher der alten Generation
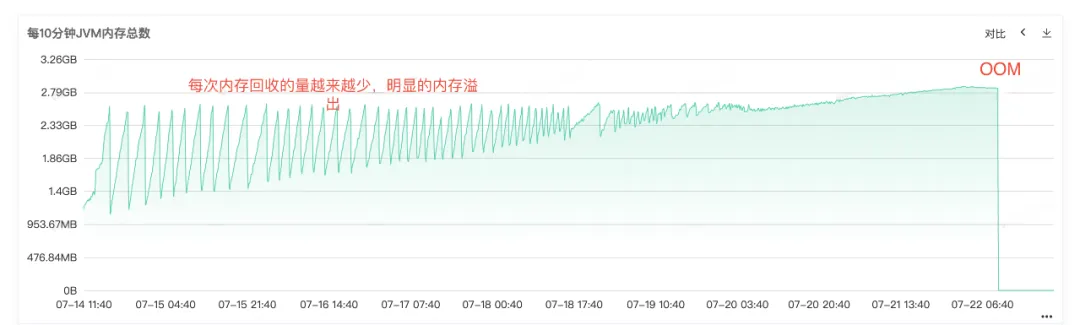
Abbildung 2.4 JVM-Speicher
2.3 Speicherüberlauf
Aus dem Online-Fehlerprotokoll können wir auch eindeutig erkennen, dass der Dienst OOM beendet hat. Die Hauptursache des Problems liegt also darin, dass der Speicherverlust dazu geführt hat , dass der Speicher OOM überläuft und der Dienst schließlich nicht mehr verfügbar ist .

Abbildung 2.5 OOM-Protokoll
3. Fehlerbehebung
3.1 Heap-Speicheranalyse
Nachdem klar war, dass die Ursache des Problems ein Speicherverlust war, haben wir sofort den Service-Speicher-Snapshot gesichert und die Dump-Datei zur Analyse in MAT (Eclipse Memory Analyzer) importiert. Verdächtige Lecks Rufen Sie die Ansicht der vermuteten Leckstelle auf.
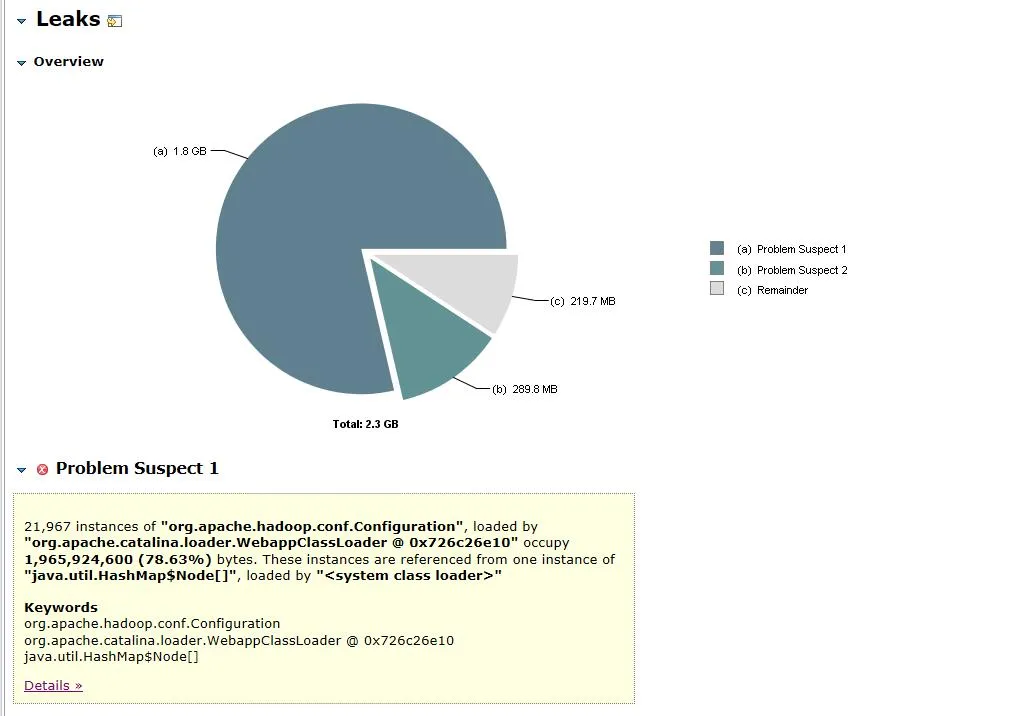
Abbildung 3.1 Speicherobjektanalyse
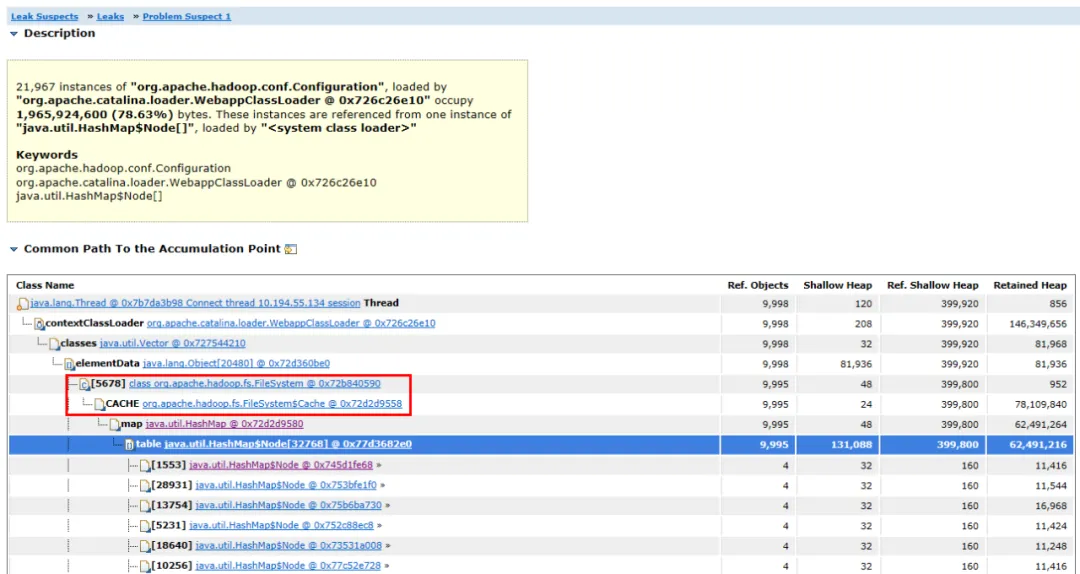
Abbildung 3.2 Objektverbindungsdiagramm
Die geöffnete Dump-Datei ist in Abbildung 3.1 dargestellt. Das Objekt org.apache.hadoop.conf.Configuration macht 1,8 GB des 2,3 GB großen Heap-Speichers aus, was 78,63 % des gesamten Heap-Speichers entspricht .
Erweitern Sie die zugehörigen Objekte und Pfade des Objekts. Sie können sehen, dass das Hauptobjekt HashMap ist . Die HashMap wird vom FileSystem.Cache- Objekt gehalten und die obere Ebene ist FileSystem . Es kann vermutet werden, dass der Speicherverlust höchstwahrscheinlich mit FileSystem zusammenhängt.
3.2 Quellcode-Analyse
Nachdem Sie das Speicherverlustobjekt gefunden haben, besteht der nächste Schritt darin, den Speicherverlustcode zu finden.
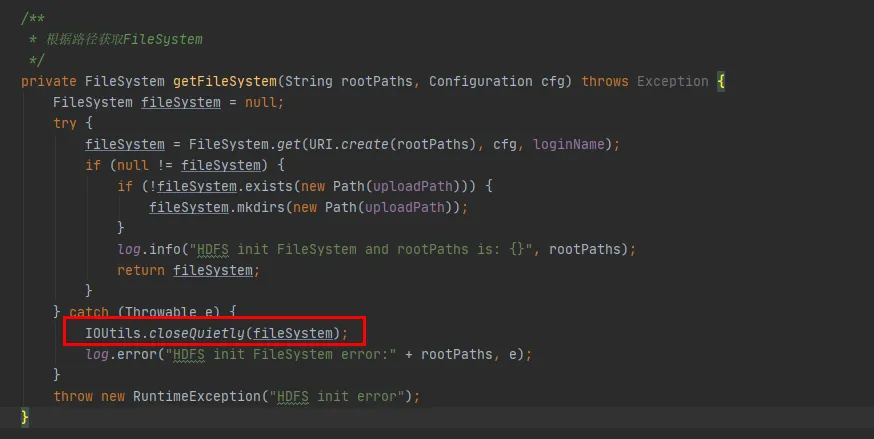
In Abbildung 3.3 finden wir einen solchen Code in unserem Code. Jedes Mal, wenn er mit HDFS interagiert, stellt er eine Verbindung mit HDFS her und erstellt ein FileSystem-Objekt. Nach der Verwendung des FileSystem-Objekts wurde die Methode close() jedoch nicht aufgerufen, um die Verbindung freizugeben.
Allerdings handelt es sich hier sowohl bei der Konfigurationsinstanz als auch bei der Dateisysteminstanz um lokale Variablen. Nach der Ausführung der Methode sollten diese beiden Objekte von der JVM wiederverwendet werden können.
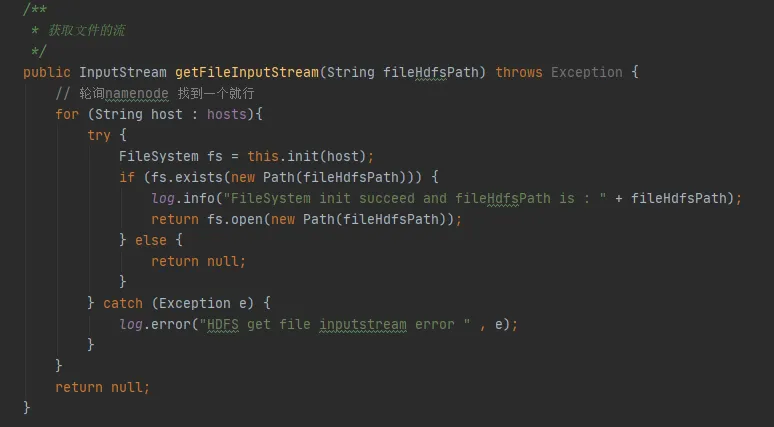
Abbildung 3.3
(1) Vermutung 1: Hat FileSystem konstante Objekte?
Als nächstes schauen wir uns den Quellcode der FileSystem-Klasse an. Die init- und get- Methoden von FileSystem lauten wie folgt:
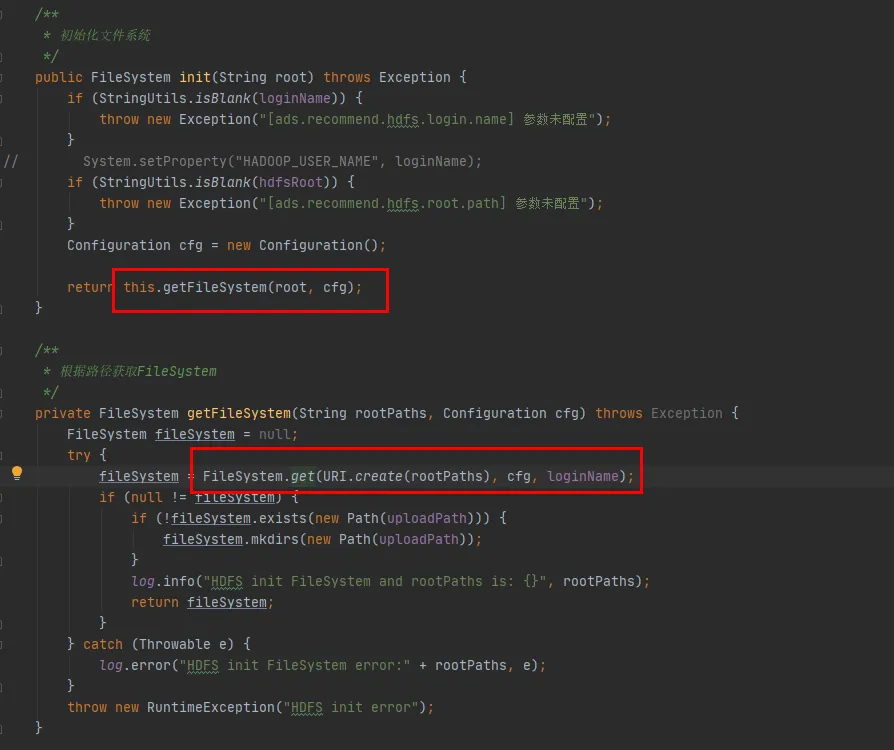

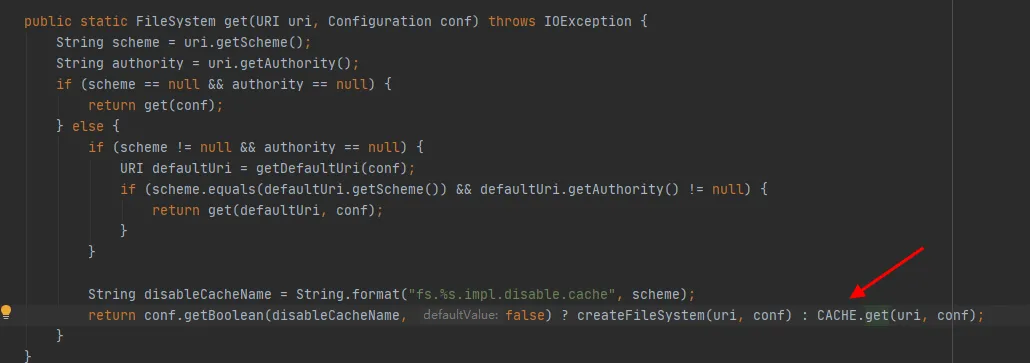
Abbildung 3.4
Wie aus der letzten Codezeile in Abbildung 3.4 ersichtlich ist, gibt es einen CACHE in der FileSystem-Klasse, und „disableCacheName“ wird verwendet, um zu steuern, ob Objekte aus dem Cache abgerufen werden . Der Standardwert dieses Parameters ist false. Das heißt, FileSystem wird standardmäßig über das CACHE-Objekt zurückgegeben .

Abbildung 3.5
Aus Abbildung 3.5 können wir ersehen, dass CACHE ein statisches Objekt der FileSystem-Klasse ist. Mit anderen Worten, das CACHE-Objekt wird immer existieren und nicht recycelt. Das konstante Objekt CACHE existiert und die Vermutung wurde bestätigt.
Dann werfen Sie einen Blick auf die CACHE.get-Methode:
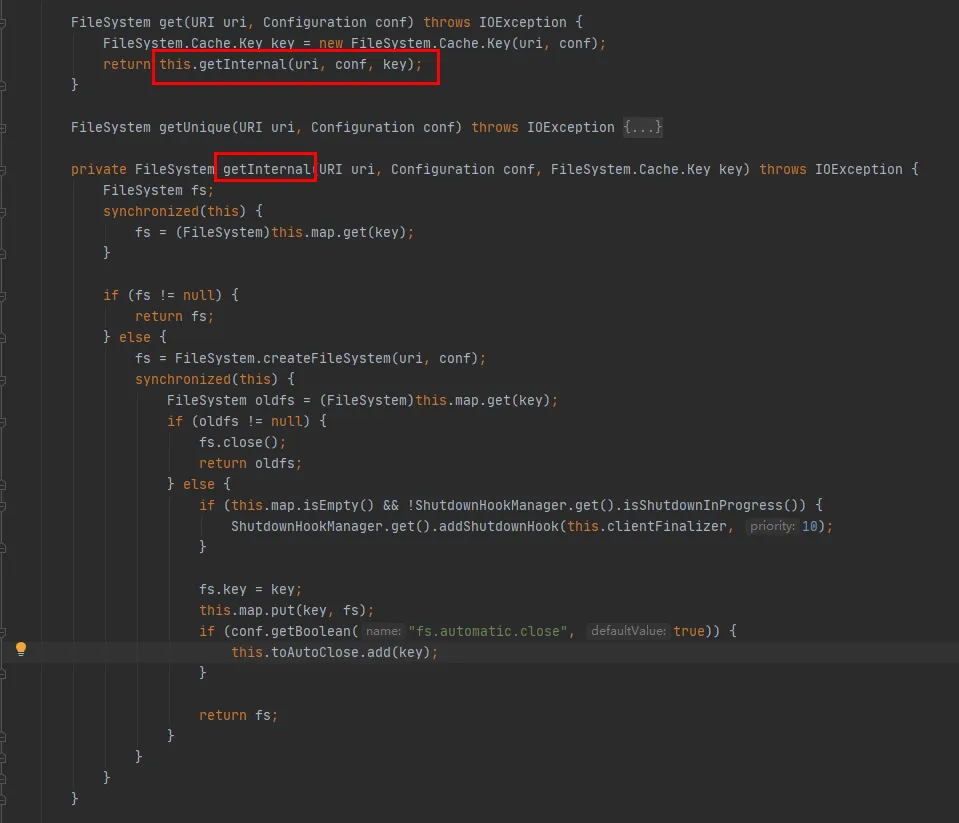
Wie aus diesem Code ersichtlich ist:
-
Innerhalb der Cache-Klasse wird eine Map verwaltet, die zum Zwischenspeichern verbundener FileSystem-Objekte verwendet wird. Der Schlüssel der Map ist das Cache.Key-Objekt. FileSystem wird jedes Mal über Cache.Key abgerufen. Wenn es nicht abgerufen wird, wird der Erstellungsprozess fortgesetzt.
-
Innerhalb der Cache-Klasse wird ein Set (toAutoClose) verwaltet, das zum Speichern von Verbindungen verwendet wird, die automatisch geschlossen werden müssen. Verbindungen in dieser Sammlung werden automatisch geschlossen, wenn der Client geschlossen wird.
-
Jedes erstellte FileSystem wird in der Map in der Cache-Klasse mit Cache.Key als Schlüssel und FileSystem als Wert gespeichert. Um festzustellen, ob beim Caching mehrere Caches für denselben HDFS-URI vorhanden sind, müssen Sie die hashCode-Methode von Cache.Key überprüfen.
Die hashCode-Methode von Cache.Key lautet wie folgt:

Die Schema- und Berechtigungsvariablen sind vom Typ String. Wenn sie sich im selben URI befinden, ist ihr HashCode konsistent. Der Wert des eindeutigen Parameters ist jedes Mal 0. Dann wird der HashCode von Cache.Key durch ugi.hashCode() bestimmt .
Aus der obigen Codeanalyse können wir Folgendes herausfinden:
-
Während der Interaktion zwischen dem Geschäftscode und HDFS wird für jede Interaktion eine FileSystem- Verbindung erstellt und die FileSystem-Verbindung wird am Ende nicht geschlossen.
-
FileSystem verfügt über einen integrierten statischen Cache und es gibt eine Map im Cache, um das FileSystem zwischenzuspeichern, das eine Verbindung hergestellt hat.
-
Der Parameter fs.hdfs.impl.disable.cache wird verwendet, um zu steuern, ob das Dateisystem zwischengespeichert werden muss. Standardmäßig ist es falsch, was bedeutet, dass es zwischengespeichert wird.
-
Map im Cache, Key ist die Cache.Key-Klasse, die einen Schlüssel anhand von vier Parametern bestimmt: Schema, Authority, Ugi und Unique , wie oben in der hashCode-Methode von Cache.Key gezeigt.
(2) Vermutung 2: Cachet FileSystem denselben HDFS-URI mehrmals zwischen?
Der FileSystem.Cache.Key-Konstruktor lautet wie folgt: ugi wird durch getCurrentUser() von UserGroupInformation bestimmt.

Schauen Sie sich weiterhin die getCurrentUser()-Methode von UserGroupInformation wie folgt an:

Der Schlüssel ist, ob das Subject-Objekt über AccessControlContext abgerufen werden kann. In diesem Beispiel wird beim Abrufen über get (final URI uri, final Configuration conf, final String user) während des Debuggens festgestellt, dass hier jedes Mal ein neues Subject-Objekt abgerufen werden kann. Mit anderen Worten: Derselbe HDFS-Pfad speichert jedes Mal ein FileSystem-Objekt zwischen .
Vermutung 2 wurde bestätigt: Derselbe HDFS-URI wird mehrmals zwischengespeichert, was zu einer schnellen Erweiterung des Caches führt und der Cache keine Ablaufzeit und Eliminierungsrichtlinie festlegt, was schließlich zu einem Speicherüberlauf führt.
(3) Warum wird FileSystem wiederholt zwischengespeichert?
Warum erhalten wir also jedes Mal ein neues Subject-Objekt? Schauen wir uns den Code an, um den AccessControlContext wie folgt zu erhalten:
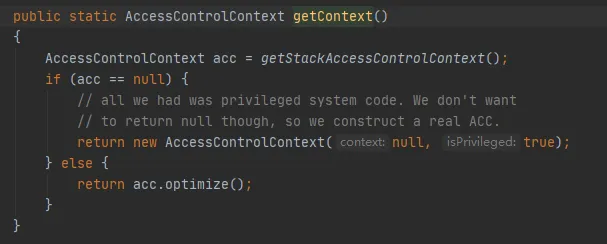
Die wichtigste Methode ist die getStackAccessControlContext-Methode, die die Native-Methode wie folgt aufruft:

Diese Methode gibt das AccessControlContext-Objekt der Schutzdomänenberechtigungen des aktuellen Stapels zurück.
Wir können es durch die Methode get(final URI uri, final Configuration conf, final String user) in Abbildung 3.6 wie folgt sehen:
-
Zunächst wird ein UserGroupInformation- Objekt über die Methode UserGroupInformation.getBestUGI abgerufen .
-
Anschließend wird die Methode get(URI uri, Configuration conf) über die doAs-Methode von UserGroupInformation aufgerufen .
-
Abbildung 3.7 Implementierung der UserGroupInformation.getBestUGI -Methode Konzentrieren Sie sich hier auf die beiden übergebenen Parameter „ ticketCachePath“ und „user“ . TicketCachePath ist der Wert, der durch die Konfiguration von hadoop.security.kerberos.ticket.cache.path erhalten wird. In diesem Beispiel ist dieser Parameter nicht konfiguriert, daher ist TicketCachePath leer. Der Benutzerparameter ist der in diesem Beispiel übergebene Benutzername.
-
„ticketCachePath“ ist leer und „user“ ist nicht leer, sodass die Methode „createRemoteUser“ in Abbildung 3.7 schließlich ausgeführt wird.

Abbildung 3.6

Abbildung 3.7
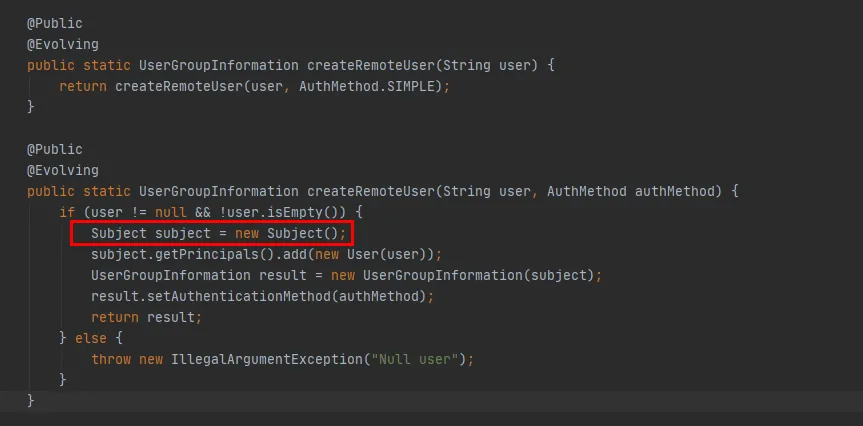
Abbildung 3.8
Aus dem roten Code in Abbildung 3.8 können Sie ersehen, dass in der Methode createRemoteUser ein neues Subject-Objekt erstellt wird und über dieses Objekt das UserGroupInformation- Objekt erstellt wird . An diesem Punkt ist die Ausführung der UserGroupInformation.getBestUGI-Methode abgeschlossen.
Schauen Sie sich als Nächstes die Methode UserGroupInformation.doAs (die letzte von FileSystem.get(final URI uri, final Configuration conf, final String user)) ausgeführte Methode wie folgt an:
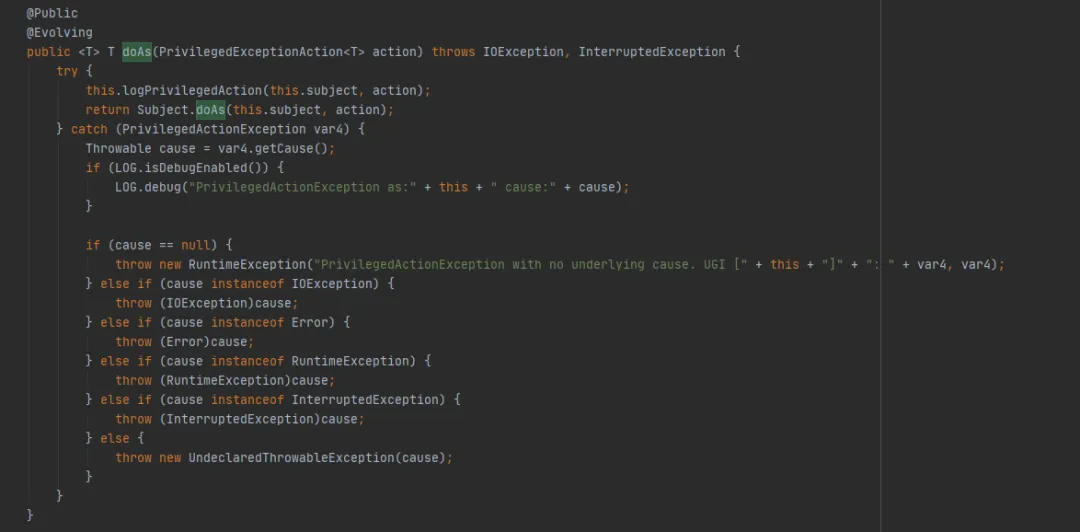
Rufen Sie dann die Methode Subject.doAs wie folgt auf:
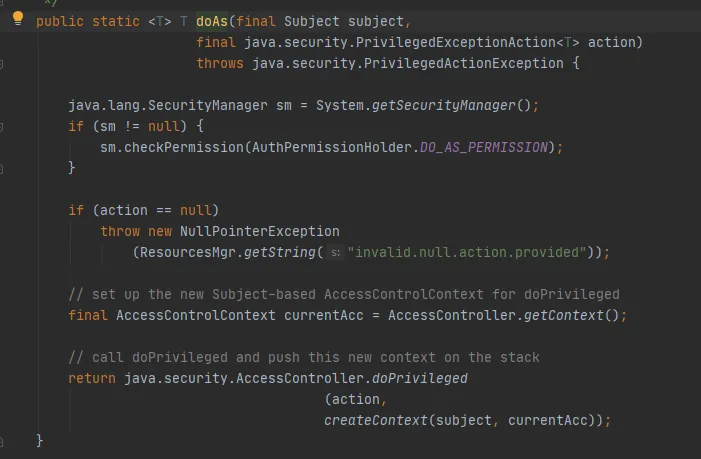
Rufen Sie abschließend die AccessController.doPrivileged-Methode wie folgt auf:
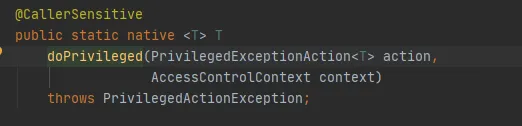
Diese Methode ist eine native Methode, die den angegebenen AccessControlContext verwendet, um PrivilegedExceptionAction auszuführen, dh die Ausführungsmethode der Implementierung aufzurufen. Das ist die Methode FileSystem.get(uri, conf).
An dieser Stelle kann erklärt werden, dass in diesem Beispiel beim Erstellen eines Dateisystems über die Methode get (final URI uri, final Configuration conf, final String user) der im Cache von FileSystem gespeicherte HashCode von Cache.key jedes Mal inkonsistent ist .
Zusammenfassen:
-
Beim Erstellen eines Dateisystems über die Methode get(final URI uri, final Configuration conf, final String user) werden jedes Mal neue UserGroupInformation- und Subject- Objekte erstellt.
-
Wenn das Cache.Key-Objekt hashCode berechnet , wirkt sich der Aufruf der UserGroupInformation.hashCode- Methode auf das Berechnungsergebnis aus .
-
UserGroupInformation.hashCode-Methode, berechnet als: System.identityHashCode(subject) . Das heißt, wenn das Subjekt dasselbe Objekt ist, wird derselbe HashCode zurückgegeben. Da er in diesem Beispiel jedes Mal anders ist, ist der berechnete HashCode inkonsistent.
-
Zusammenfassend lässt sich sagen, dass der jedes Mal berechnete HashCode von Cache.key inkonsistent ist und der Cache von FileSystem wiederholt geschrieben wird.
(4) Korrekte Verwendung von FileSystem
Warum sollte dieser Cache aus der obigen Analyse entworfen werden, da FileSystem.Cache keine Rolle spielt? Tatsächlich ist es einfach so, dass unsere Verwendung nicht korrekt ist.
In FileSystem gibt es zwei überladene Get-Methoden:
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)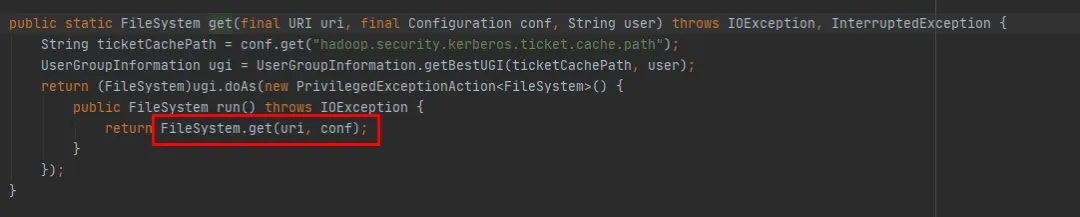
Wir können sehen, dass die Methode FileSystem get(final URI uri, final Configuration conf, final String user) schließlich die Methode FileSystem get(URI uri, Configuration conf) aufruft Es fehlt lediglich die Möglichkeit, jedes Mal ein neues Subjekt zu erstellen.

Abbildung 3.9
Wenn es keinen Vorgang zum Erstellen eines neuen Subjekts gibt, ist das Subjekt in Abbildung 3.9 null und die letzte getLoginUser-Methode wird verwendet, um den loginUser abzurufen. LoginUser ist eine statische Variable. Sobald das loginUser-Objekt erfolgreich initialisiert wurde, wird das Objekt in Zukunft verwendet. Die Methode UserGroupInformation.hashCode gibt denselben hashCode-Wert zurück. Das heißt, der im Dateisystem zwischengespeicherte Cache kann erfolgreich verwendet werden.

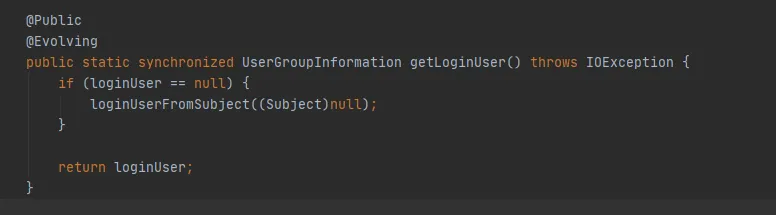
Abbildung 3.10
4. Lösung
Wenn wir nach der vorherigen Einführung das Speicherverlustproblem von FileSystem lösen möchten, haben wir die folgenden zwei Methoden:
(1) Öffentliches statisches Dateisystem get(URI uri, Configuration conf):
-
Diese Methode kann den FileSystem-Cache verwenden, was bedeutet, dass es nur ein FileSystem-Verbindungsobjekt für denselben HDFS-URI gibt.
-
Legen Sie den Zugriffsbenutzer über System.setProperty("HADOOP_USER_NAME", "hive") fest.
-
Standardmäßig ist fs.automatic.close = true, dh alle Verbindungen werden über ShutdownHook geschlossen.
(2) Public static FileSystem get(final URI uri, final Configuration conf, final String user):
-
Wie oben analysiert, führt diese Methode dazu, dass der Cache des Dateisystems ungültig wird und jedes Mal zur Karte des Caches hinzugefügt wird, was dazu führt, dass er nicht recycelt wird.
-
Bei der Verwendung besteht eine Lösung darin, sicherzustellen, dass es nur ein FileSystem-Verbindungsobjekt für denselben HDFS-URI gibt.
-
Eine andere Lösung besteht darin, nach jeder Verwendung von FileSystem die Methode close aufzurufen, wodurch das FileSystem im Cache gelöscht wird.
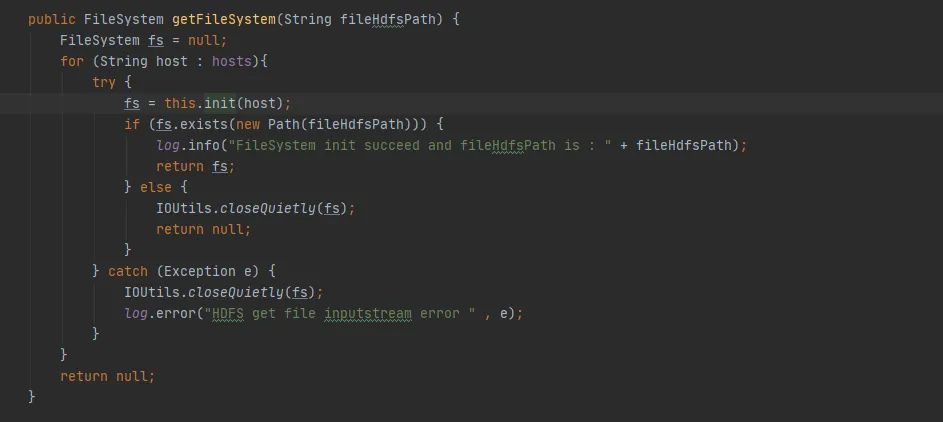
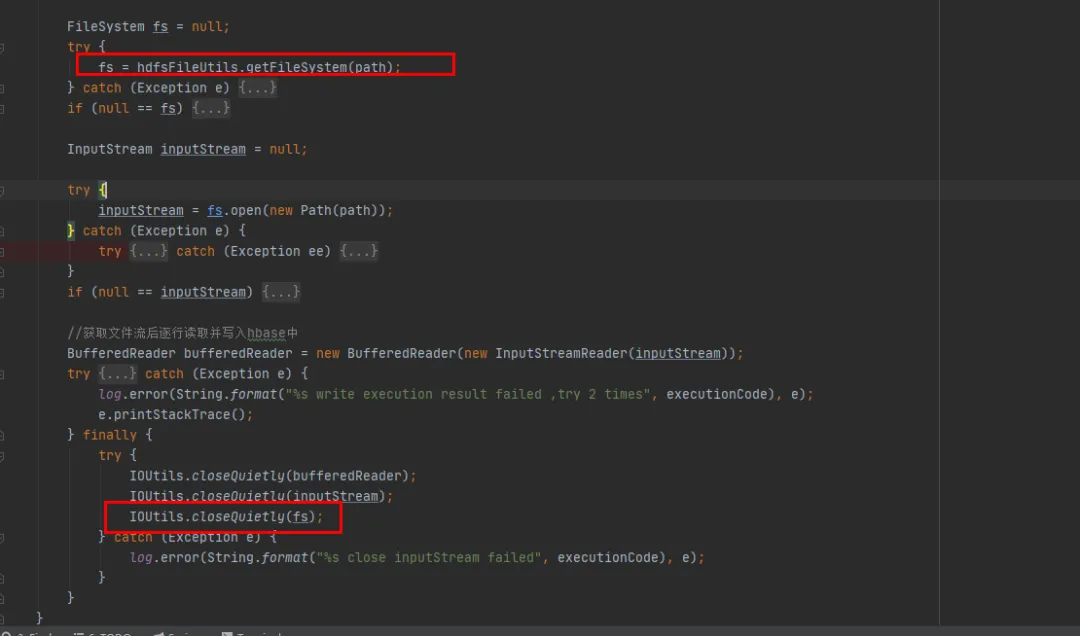
Basierend auf der Prämisse minimaler Änderungen an unserem vorhandenen historischen Code haben wir uns für die zweite Änderungsmethode entschieden. Schließen Sie das FileSystem-Objekt nach jeder Verwendung von FileSystem.
5. Optimierungsergebnisse
Nachdem der Code repariert und online freigegeben wurde (siehe Abbildung 1 unten), können Sie sehen, dass der Speicher der alten Generation nach der Reparatur normal recycelt werden kann. An diesem Punkt ist das Problem endgültig gelöst.
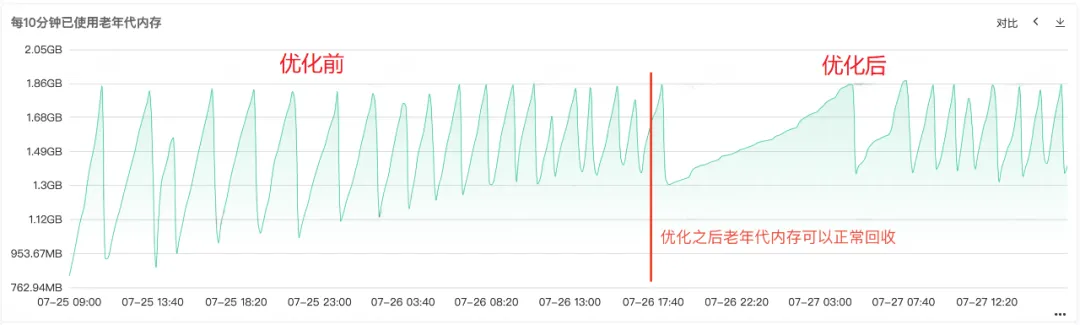
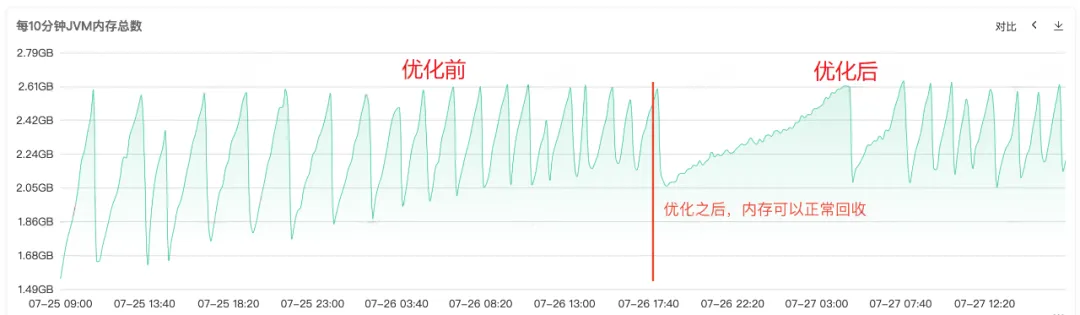
6. Zusammenfassung
Speicherüberlauf ist eines der häufigsten Probleme bei der Java-Entwicklung. Der Grund dafür sind in der Regel Speicherlecks , die eine normale Wiederverwendung des Speichers verhindern. In unserem Artikel werden wir einen vollständigen Online-Speicherüberlaufverarbeitungsprozess im Detail vorstellen.
Fassen Sie unsere gängigen Lösungen bei Speicherüberlauf zusammen:
(1) Heap-Speicherdatei generieren :
Fügen Sie den Dienststartbefehl hinzu
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseLassen Sie den Dienst automatisch Speicherdateien sichern, wenn OOM auftritt, oder verwenden Sie den Befehl jam, um Speicherdateien zu sichern.
(2) Heap-Speicheranalyse : Verwenden Sie Speicheranalysetools, um das Problem des Speicherüberlaufs genauer zu analysieren und die Ursache des Speicherüberlaufs zu finden. Im Folgenden sind einige häufig verwendete Tools zur Speicheranalyse aufgeführt:
-
Eclipse Memory Analyzer : Ein Open-Source-Java-Speicheranalysetool, das uns dabei helfen kann, Speicherlecks schnell zu lokalisieren.
-
VisualVM Memory Analyzer : Ein Tool, das auf einer grafischen Oberfläche basiert und uns bei der Analyse der Speichernutzung von Java-Anwendungen helfen kann.
(3) Suchen Sie den spezifischen Speicherleckcode basierend auf der Heap-Speicheranalyse.
(4) Ändern Sie den Speicherleckcode und geben Sie ihn zur Überprüfung erneut frei.
Speicherlecks sind eine häufige Ursache für einen Speicherüberlauf, sie sind jedoch nicht die einzige Ursache. Zu den häufigsten Ursachen für Speicherüberlaufprobleme gehören: übergroße Objekte, zu kleine Heap-Speicherzuweisung, Endlosschleifenaufrufe usw., die alle zu Speicherüberlaufproblemen führen können.
Wenn wir auf Speicherüberlaufprobleme stoßen, müssen wir in vielen Aspekten denken und das Problem aus verschiedenen Blickwinkeln analysieren. Durch die oben genannten Methoden und Tools sowie verschiedene Überwachungen können wir uns dabei helfen, Probleme schnell zu lokalisieren und zu lösen sowie die Stabilität und Verfügbarkeit unseres Systems zu verbessern.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele auf der Windows-Plattform zu produzieren