
Datenbankindizes sind eine Schlüsselkomponente zur Optimierung der Leistung jedes Datenbanksystems. Ohne effektive Indizes können Ihre Datenbankabfragen langsam und ineffizient werden, was zu einer schlechten Benutzererfahrung und verringerter Produktivität führt. In diesem Artikel untersuchen wir einige bewährte Methoden zum Erstellen und Verwenden von Datenbankindizes.
Autor: Der Java Trail
Quelle dieses Artikels und des Covers: https://medium.com/, übersetzt von der Axon Open Source Community.
Dieser Artikel umfasst etwa 2.700 Wörter und die Lektüre dauert voraussichtlich 9 Minuten.
In Datenbanken werden verschiedene Indizierungsalgorithmen verwendet, um die Abfrageleistung zu verbessern. Hier sind einige der am häufigsten verwendeten Indexierungsalgorithmen:
B-Tree-Index
Ein B-Tree-Index ist eine selbstausgleichende Baumdatenstruktur, die die Datenreihenfolge beibehält und Suchen, sequentiellen Zugriff, Einfügungen und Löschungen in logarithmischer Zeit ermöglicht. Die B-Tree-Indexstruktur wird häufig in Datenbanken und Dateisystemen verwendet. B-Tree-Indizes werden häufig in relationalen Datenbanken wie MySQL und PostgreSQL verwendet.
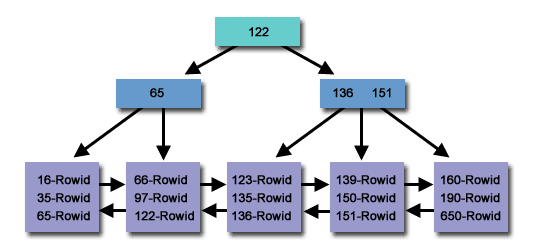
B-Tree-Indizes sind für Bereichsabfragen optimiert, da sie alle Datensätze innerhalb eines Wertebereichs effizient finden können. Dies liegt daran, dass Datensätze im Index in sortierter Reihenfolge gespeichert werden. Nutzen Sie die Vorteile von Spaltenvergleichen in Ausdrücken, die die Operatoren =, >, >=, <oder verwenden .<=BETWEEN
Angenommen, wir haben eine Produkttabelle mit der folgenden Tabellenstruktur:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
Mit der folgenden SQL-Anweisung können wir dem Feld priceeinen B-Tree-Index hinzufügen .
CREATE INDEX products_price_index ON products (price);
Hash-Index
Hash-Indizes sind ein weiterer beliebter Indexierungsalgorithmus, der zur Beschleunigung von Abfragen verwendet wird. Hash-Indizes verwenden eine Hash-Funktion, um Schlüssel Indexpositionen zuzuordnen. Dieser Indizierungsalgorithmus ist am nützlichsten für Abfragen mit exakter Übereinstimmung, z. B. die Suche nach bestimmten Datensätzen basierend auf Primärschlüsselwerten . Hash-Indizes werden häufig in In-Memory-Datenbanken wie Redis verwendet.
Hash-Indizes funktionieren, indem sie jeden Datensatz in der Tabelle basierend auf seinem Hash-Wert einem eindeutigen Bucket zuordnen. Hash-Werte werden mithilfe einer Hash-Funktion berechnet, einer mathematischen Funktion, die ein Datenelement als Eingabe verwendet und einen eindeutigen ganzzahligen Wert zurückgibt.
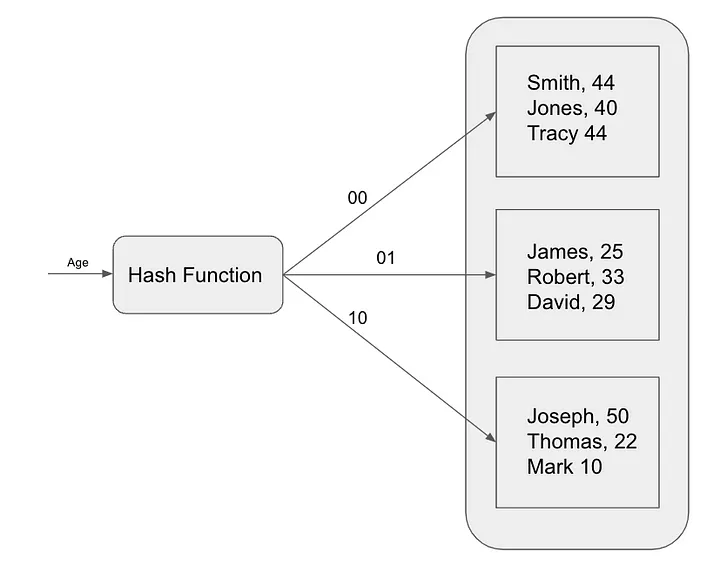
Um einen Datensatz in einem Hash-Index zu finden, berechnet die Datenbank den Hash des Suchschlüssels und sucht dann nach dem entsprechenden Bucket. Wenn sich der Datensatz im Bucket befindet, gibt die Datenbank den Datensatz zurück. Andernfalls führt die Datenbank einen vollständigen Tabellenscan durch.
Hash-Indizes sind für Suchvorgänge sehr schnell , können jedoch nicht zur effizienten Abfrage von Datenbereichen verwendet werden . Dies liegt daran, dass Hash-Funktionen keine Reihenfolge zwischen Datensätzen in der Tabelle beibehalten.
So führen Sie eine Abfrage mithilfe eines Hash-Index aus:
- Die Datenbank berechnet den Hashwert der Abfragekriterien.
- Suchen Sie den entsprechenden Hash-Bucket in der Hash-Tabelle.
- Die Datenbank ruft dann einen Zeiger auf die Zeile in der Tabelle mit dem entsprechenden Hashwert ab.
- Verwenden Sie diese Zeiger, um die tatsächlichen Zeilen aus der Tabelle abzurufen.
Angenommen, wir haben eine Produkttabelle mit der folgenden Tabellenstruktur:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
F: Sind Hash-Indizes nicht wie B-Tree optimiert?
Es gibt Situationen, in denen ein Hash-Index möglicherweise nicht die beste Wahl ist:
- Hash-Indizes sind für Suchvorgänge (für Gleichheitsvergleiche mit dem Operator
=„oder“<=>) schneller als Baumindizes, können jedoch nicht zur effizienten Abfrage von Datenbereichen verwendet werden. - Baumindizes sind bei der Suche langsamer als Hash-Indizes, können aber zur effizienten Abfrage von Datenbereichen verwendet werden.
Bereichsabfragen: Hash-Indizes sind nicht für Bereichsabfragen optimiert, bei denen Sie Datensätze innerhalb eines Wertebereichs finden müssen (mithilfe der Operatoren =, >, >=, <oder <=) BETWEEN. In diesem Fall wäre ein B-Tree-Index besser geeignet.
Sortierung: Hash-Indizes sind nicht für die Sortierung optimiert. Sie müssen die Datensätze nach einer bestimmten Spalte sortieren. In diesem Fall wäre ein B-Tree-Index oder ein Clustered-Index besser geeignet.
Große Datensätze: Hash-Indizes können speicherintensiv sein und sind daher möglicherweise nicht für große Datensätze geeignet, bei denen die Speichernutzung ein Problem darstellt.
Mit dem folgenden Befehl können wir nameeinen Hash-Index für die Spalte erstellen:
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
Wenn wir einen Hash-Index verwenden, berechnet die Datenbank den Hash-Wert des Suchbegriffs „iPhone 13 Pro“ und sucht dann nach dem entsprechenden Bucket. Da Hash-Funktionen deterministisch sind, findet die Datenbank immer Datensätze im selben Bucket, unabhängig von der Reihenfolge, in der die Datensätze in der Tabelle gespeichert sind.
Wenn wir einen Baumindex verwenden, beginnt die Datenbank im Stammverzeichnis des Baums und vergleicht den Suchschlüssel „iPhone 13 Pro“ mit dem Wert des im Stammverzeichnis gespeicherten Schlüssels . Da der Baum sortiert ist, findet die Datenbank schnell den Datensatz, der den Suchschlüssel enthält.
F: Warum ist B-Tree besser für Bereichsabfragen optimiert als der Hash-Index?
Nehmen wir nun an, wir möchten alle Produkte mit einem Preis zwischen 100 und 200 US-Dollar finden. Wir können die folgende Abfrage verwenden:
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
Arbeitsprinzip
B-Baum
B-Tree-Indizes funktionieren, indem sie Datensätze in sortierter Reihenfolge speichern. Um Datensätze in einem B-Tree-Index zu finden,
- Die Datenbank beginnt an der Wurzel des Baums und vergleicht den Suchschlüssel mit dem Wert des an der Wurzel gespeicherten Schlüssels.
- Wenn der Suchschlüssel dem Root-Schlüssel entspricht, gibt die Datenbank diesen Datensatz zurück.
- Andernfalls bestimmt die Datenbank anhand der Vergleichsergebnisse, welcher Teilbaum als nächstes durchsucht werden soll.
Hash
Hash-Indizes funktionieren, indem sie jeden Datensatz in einer Tabelle basierend auf seinem Hash-Wert einem eindeutigen Bucket zuordnen. Der Hash-Wert wird mithilfe einer Hash-Funktion berechnet. Hash-Indizes verteilen Daten zufällig über Buckets, wodurch Bereichsabfragen ineffizient werden. Das Abrufen eines Wertebereichs, beispielsweise von Preisen zwischen 100 und 200 US-Dollar, erfordert das Scannen aller Buckets in diesem Bereich, was effektiv zu einem vollständigen Tabellenscan führt. Hash-Indizes eignen sich gut für die schnelle Suche nach exakten Übereinstimmungen, ihnen fehlt jedoch die Datenreihenfolge, die für effiziente Bereichsabfragen erforderlich ist.
Frage: Warum ist der B-Tree-Index bei der Sortierung optimierter als der Hash-Index?
B-Tree-Baumindizes sortieren Daten effizienter als Hash-Indizes, da sie Datensätze in sortierter Reihenfolge speichern. Dadurch kann die Datenbank Datensätze schnell und in sortierter Reihenfolge durchlaufen.
Hash-Indizes funktionieren, indem sie jeden Datensatz in einer Tabelle basierend auf seinem Hash-Wert einem eindeutigen Bucket zuordnen. Das bedeutet, dass die Reihenfolge der Datensätze im Bucket zufällig ist. Um die Datensätze zu sortieren, muss die Datenbank alle Buckets durchlaufen und dann die Datensätze in jedem Bucket sortieren. Dies ist langsamer als die Verwendung eines B-Tree-Index, der Datensätze in sortierter Reihenfolge speichert.
Mit dem folgenden Befehl können wir priceeinen B-Tree-Index für die Spalte erstellen:
CREATE INDEX products_price_index ON products (price);
Nehmen wir nun an, wir möchten Produkte in aufsteigender Reihenfolge nach Preis sortieren. Wir können die folgende Abfrage verwenden:
SELECT * FROM products ORDER BY price ASC;
Die Datenbank verwendet einen B-Tree-Index, um Produkte schnell in sortierter Reihenfolge zu durchlaufen.
Nachteile des Hash-Index:
- Hash-Indizes unterstützen keine Bereichsabfragen oder Sortierungen
- Hash-Indizes verbrauchen viel Speicher
- Hash-Indizes sind nicht für häufig aktualisierte Datenbanken geeignet
Bitmap-Index
Bitmap-Indizes werden für Spalten mit einer kleinen Anzahl unterschiedlicher Werte verwendet, z. B. boolesche Spalten oder Geschlechtsspalten. Bitmap-Indizes sind für Spalten mit niedrigerer Kardinalität sehr kompakt und effizient.
SELECT * FROM employees WHERE gender = 'Female';
Bitmap-Indizes sind bei Spalten mit niedrigerer Kardinalität sehr effizient und ermöglichen schnelle Mengenoperationen wie Vereinigungen und Schnittmengen. Ideal für Ad-hoc-Berichte und Data Warehousing.
Volltextindex
Die Volltextindizierung wird zur Indizierung großer Textdatenmengen wie Dokumente oder Webseiten verwendet. Dieser Indexierungsalgorithmus zerlegt Text in Wörter oder Token und indiziert sie auf eine Weise, die effiziente Suchvorgänge ermöglicht. Volltextindizes sind am nützlichsten für Abfragen, bei denen nach bestimmten Wörtern oder Phrasen im Text gesucht wird. Die Volltextindizierung wird häufig in Suchmaschinen wie Elasticsearch verwendet.
Anwendungsfälle für die E-Commerce-Volltextindizierung:
Durch die Volltextindizierung können E-Commerce-Anwendungen schnell große Produktkataloge basierend auf vom Benutzer eingegebenen Suchanfragen durchsuchen. Die Volltextindizierung ermöglicht die Suche auf der Grundlage mehrerer Wörter und Phrasen, einschließlich Rechtschreibfehlern, Synonymen und sogar verwandter Konzepte. Dadurch können Nutzer leichter finden, was sie suchen, auch wenn sie den genauen Produktnamen oder die Beschreibung nicht kennen.
Stellen Sie sich zum Beispiel vor, ein Kunde sucht nach einem neuen Paar Laufschuhe. Sie geben „Laufschuhe“ in die Suchleiste ein. Mit der Volltextindizierung können E-Commerce-Anwendungen schnell alle Produktbeschreibungen, Namen und Etiketten durchsuchen, um alle Produkte rund um Laufschuhe zu finden. Suchergebnisse werden nach Relevanz sortiert, die dadurch bestimmt wird, wie oft die Suchbegriffe in Produktinformationen vorkommen.
Ohne Volltextindizierung wird bei einer Suche möglicherweise nur der Produktname berücksichtigt, ohne dass andere Faktoren berücksichtigt werden, die für Kunden relevant sein können, wie z. B. Produktbeschreibungen oder Etiketten. Darüber hinaus berücksichtigt die Suche möglicherweise keine Rechtschreibfehler oder verwandte Konzepte wie „Joggingschuhe“ oder „Turnschuhe“.
Angenommen, wir haben eine productsTabelle mit den folgenden Spalten: id, name, descriptionund tags.
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
Stellen Sie sich nun vor, ein Kunde sucht nach „Laufschuhen“. Mit der folgenden Abfrage können wir nach Produkten suchen, die zum Suchbegriff passen:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
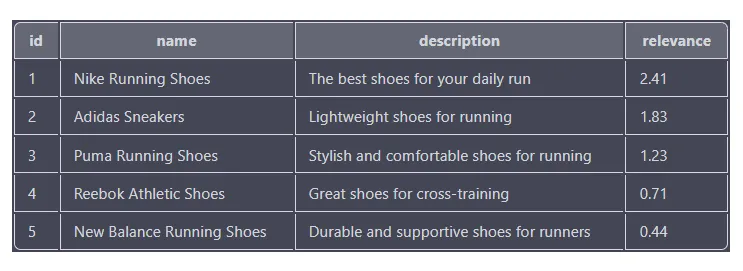
Relevanzwerte basieren darauf, wie gut jedes Produkt mit den Suchbegriffen übereinstimmt, wobei höhere Werte auf eine engere Übereinstimmung hinweisen. Die Ergebnisse werden in absteigender Reihenfolge nach Relevanzwert sortiert, sodass das Produkt mit dem höchsten Relevanzwert (Nike-Laufschuhe) ganz oben in der Liste erscheint.
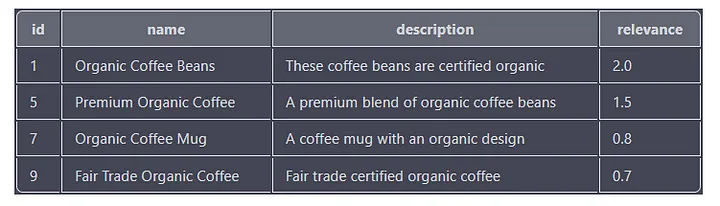
Hier ist eine weitere Beispielabfrage, die nach Produkten sucht, die die Wörter „Bio“ und „Kaffee“ enthalten:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
Diese Abfrage sucht nach allen Produkten, deren Namens-, Beschreibungs- oder Etikettenspalten sowohl die Schlüsselwörter „Bio“ als auch „Kaffee“ enthalten. Der Relevanzwert jedes Ergebnisses wird auch basierend auf der Häufigkeit und Position des Schlüsselworts in der Spalte berechnet.
Die Ausgabe enthält die Spalten „id“, „name“, „description“ und „relevance“, wobei die Ergebnisse nach der Spalte „relevance“ in absteigender Reihenfolge sortiert sind.
Vorteil
- Volltextindizes funktionieren sehr gut für textbasierte Spalten
- Ideal für Suchmaschinen und Content-Management-Systeme
- Unterstützt das Relevanzranking der Suchergebnisse
Mangel
- Die Volltextindizierung nimmt viel Speicherplatz in Anspruch
- Bei sehr großen Datenmengen kann es zu Leistungseinbußen kommen
- Die Volltextindizierung ist nicht für numerische oder kategoriale Daten geeignet
Weitere technische Artikel finden Sie unter: https://opensource.actionsky.com/
Über SQLE
SQLE ist eine umfassende SQL-Qualitätsmanagementplattform, die die SQL-Prüfung und -Verwaltung von der Entwicklung bis zur Produktionsumgebung abdeckt. Es unterstützt gängige Open-Source-, kommerzielle und inländische Datenbanken, bietet Prozessautomatisierungsfunktionen für Entwicklung, Betrieb und Wartung, verbessert die Online-Effizienz und verbessert die Datenqualität.
SQLE erhalten
| Typ | Adresse |
|---|---|
| Repository | https://github.com/actiontech/sqle |
| dokumentieren | https://actiontech.github.io/sqle-docs/ |
| Neuigkeiten veröffentlichen | https://github.com/actiontech/sqle/releases |
| Entwicklungsdokumentation für das Datenaudit-Plug-in | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |