


Zu den aktuellen Mainstream-Beschleunigungsideen gehören Operatoroptimierung, Modellkompilierung, Modell-Caching, Modelldestillation usw. Im Folgenden werden einige repräsentative Open-Source-Lösungen kurz vorgestellt, die beim Testen verwendet werden.
▐Betreiberoptimierung : FlashAttention2
▐Modellkompilierung : oneflow/stable-fast
oneflow beschleunigt die Modellinferenz, indem das Modell in einem statischen Diagramm kompiliert und mit der integrierten Operatorfusion von oneflow.nn.Graph und anderen Beschleunigungsstrategien kombiniert wird. Der Vorteil besteht darin, dass das Basis-SD-Modell nur eine Zeile kompilierten Codes benötigt, um die Beschleunigung abzuschließen. Der Beschleunigungseffekt ist offensichtlich, der Unterschied im Generierungseffekt ist gering und kann in Kombination mit anderen Beschleunigungslösungen (z. B. Deepcache) verwendet werden. , und die offizielle Aktualisierungshäufigkeit ist hoch. Die Mängel werden später besprochen.
Stable-Fast ist ebenfalls eine Beschleunigungsbibliothek, die auf der Modellkompilierung basiert und eine Reihe von Beschleunigungsmethoden für die Operatorfusion kombiniert. Die Leistungsoptimierung basiert jedoch auf Tools wie Xformer, Triton und Torch.jit.
▐Modell- Caching: Deepcache
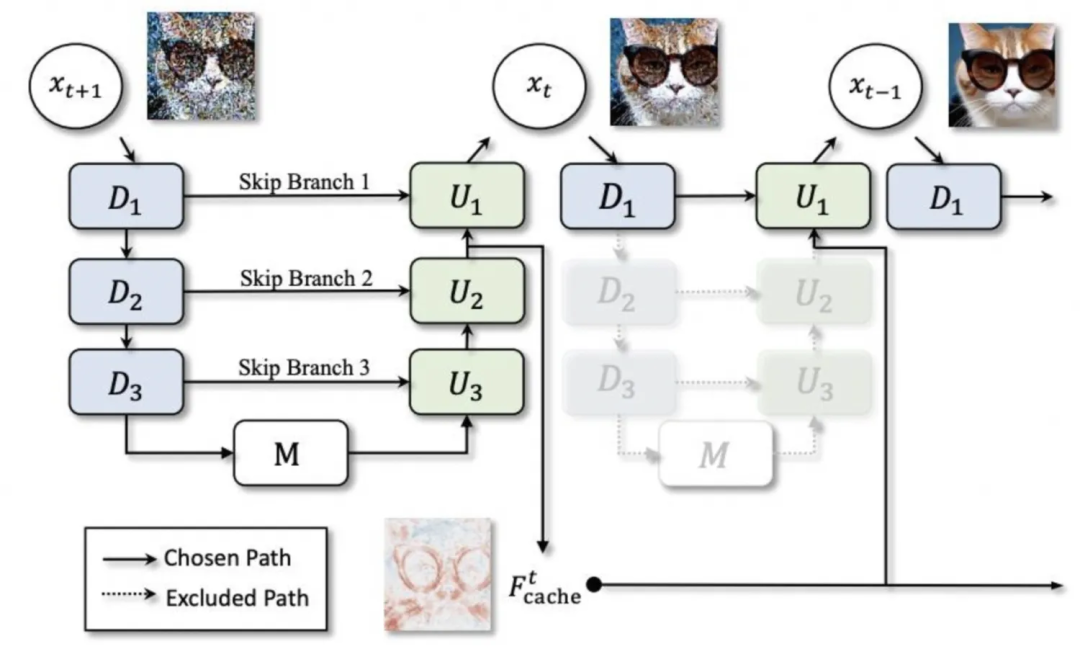
▐Modelldestillation : lcm-lora
Durch die Kombination von lcm (Latent Consistency Model) und lora destilliert lcm das gesamte SD-Modell, um eine Argumentation in wenigen Schritten zu erreichen, während lcm-lora nur die Form von lora verwendet, um den Lora-Teil zu optimieren, der auch direkt kombiniert werden kann bei regelmäßiger Lora-Nutzung.

SD1.5-Beschleunigungstest
▐Testumgebung
▐Testergebnisse
-
Durch den Vergleich der generierten Bilder mit einem festen Startwert können wir feststellen, dass die Oneflow-Kompilierung die RT um mehr als 40 % reduzieren kann, ohne dass die Genauigkeit verloren geht Sekunden Kompilierungszeit zum Aufwärmen. -
Auf dieser Basis kann Deepcache die RT um weitere 15 bis 25 % reduzieren, aber gleichzeitig wird mit zunehmendem Cache-Intervall der Unterschied in den Generierungseffekten immer deutlicher. -
oneflow ist auch für das SD1.5-Modell mit Controlnet wirksam -
Stable-Fast ist stark von externen Paketen abhängig und anfällig für verschiedene Versionsprobleme und externe Toolfehler. Ähnlich wie bei Oneflow dauert die erstmalige Generierung von Bildern eine gewisse Kompilierungszeit, und der endgültige Beschleunigungseffekt ist etwas geringer oneflow.
▐Detaillierte Vergleichsdaten
Optimierung |
Durchschnittliche Generierungszeit (Sekunden) 512 * 512, 50 Schritt |
Beschleunigungseffekt |
Effekt erzeugen 1 |
Effekt erzeugen 2 |
Effekt erzeugen 3 |
Diffusoren |
3.3701 |
0 |
|
|
|
Diffusoren+bf16 |
3,3669 |
≈0 |
|
|
|
Diffusoren + Kontrollnetz |
4.7452 |
|
|||
Diffusoren + Oneflow-Zusammenstellung |
1,9857 |
41,08 % |
|
|
|
Diffusoren+Oneflow-Kompilierung+Controlnet |
2.8017 |
|
|||
Diffusoren + Oneflow-Zusammenstellung + Deepcache |
Intervall = 2: 1,4581 |
56,73 % (15,65 %) |
|
|
|
Intervall = 3: 1,3027 |
61,35 % (20,27 %) |
|
|
||
Intervall = 5: 1,1583 |
65,63 % (24,55 %) |
|
|
||
Diffusoren+schnell |
2,3799 |
29,38 % |















▐Testumgebung
▐Testergebnisse
Grundlegendes SDXL-Modell:
Unter der Bedingung eines festen Startwerts scheint es wahrscheinlicher zu sein, dass das SDXL-Modell den Effekt der Bilderzeugung durch die Verwendung verschiedener Beschleunigungsschemata beeinflusst.
Oneflow kann die RT nur um 24 % reduzieren, aber dennoch die Genauigkeit der generierten Bilder gewährleisten.
Wenn das Intervall 2 beträgt (d. h. der Cache wird nur einmal verwendet), wird die RT um 42 % reduziert. Bei einem Intervall von 5 wird die Differenz jedoch um 69 % reduziert Bilder ist auch offensichtlich.
lcm-lora reduziert die Anzahl der zum Generieren von Diagrammen erforderlichen Schritte erheblich und kann eine erhebliche Inferenzbeschleunigung erzielen. Bei Verwendung vorab trainierter Gewichte ist die Stabilität jedoch äußerst schlecht und reagiert sehr empfindlich auf die Anzahl der Schritte Garantiert eine stabile Ausgabe im Einklang mit dem angeforderten Bild
oneflow und deepcache/lcm-lora können gut zusammen verwendet werden
Lora:
Nach dem Laden von Lora wird die Inferenzgeschwindigkeit der Diffusoren erheblich reduziert, und der Grad der Reduzierung hängt von der Art und Menge der verwendeten Lora ab.
Deepcache funktioniert immer noch und es gibt immer noch Genauigkeitsprobleme, aber bei kürzeren Cache-Intervallen ist der Unterschied nicht groß
Bei Verwendung von Lora kann die Oneflow-Kompilierung den Seed nicht so reparieren, dass er mit der Originalversion konsistent bleibt.
Die Oneflow-Kompilierung optimiert die Inferenzgeschwindigkeit nach dem Laden von Lora. Wenn mehrere Loras geladen werden, ist die Inferenzgeschwindigkeit fast dieselbe wie beim Laden ohne Lora, und der Beschleunigungseffekt ist äußerst signifikant. Wenn Sie beispielsweise zwei Garne + Aquarellfarben gleichzeitig verwenden, kann der RT um etwa 65 % reduziert werden.
Oneflow hat die Ladezeit von Lora leicht optimiert, aber die Einstellungsvorgangszeit nach dem Laden von Lora hat sich erhöht.
▐Detaillierte Vergleichsdaten
Optimierung |
Lora |
Durchschnittliche Generierungszeit (Sekunden) 512*512, 50 Schritte |
Lora-Ladezeit (Sekunden) |
Lora-Änderungszeit (Sekunden) |
Wirkung 1 |
Effekt 2 |
Effekt 3 |
Diffusoren |
keiner |
4.5713 |
|
||||
Garn |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。