
Was ist hohe Kardinalität?
Kardinalität wird in der Mathematik als Skalar definiert, der zur Darstellung der Anzahl der Elemente in einer Menge verwendet wird. Beispielsweise beträgt die Kardinalität einer endlichen Menge A = {a, b, c} 3. Es gibt auch ein Kardinalitätskonzept für unendliche Mengen . Heute sprechen wir hauptsächlich über den Bereich Computer, wir werden hier nicht näher darauf eingehen.
Im Kontext einer Datenbank gibt es keine strenge Definition der Kardinalität, aber alle sind sich einig, dass die Kardinalität der Definition in der Mathematik ähnelt: Sie wird verwendet, um die Anzahl der verschiedenen Werte zu messen, die in einer Datenspalte enthalten sind. Beispielsweise verfügt eine Datentabelle, in der Benutzer aufgezeichnet werden, normalerweise über mehrere Spalten UID. Offensichtlich ist die Kardinalität von so hoch wie von und Nameeine Spalte von kann relativ wenige Werte enthalten. Im Beispiel der Benutzertabelle kann man also sagen, dass die Spalte zur hohen Basis und die Spalte zur niedrigen Basis gehört.GenderUIDIDNameUIDGenderUIDGender
Wenn es weiter in den Bereich der Zeitreihendatenbank unterteilt wird, bezieht sich die Kardinalität häufig auf die Anzahl der Zeitreihen. Nehmen wir als Beispiel die Anwendung einer Zeitreihendatenbank im beobachtbaren Bereich API-Dienste. Um das einfachste Beispiel zu geben: Es gibt zwei Bezeichnungen für die Antwortzeit jeder Schnittstelle des API-Dienstes verschiedener Instanzen: API Routesund InstanceWenn es 20 Schnittstellen und 5 Instanzen gibt, ist die Basis der Zeitachse (20+1)x(5 +1)-1 = 125 ( +1unter Berücksichtigung der Tatsache, dass die Antwortzeit aller Schnittstellen einer Instanz oder die Antwortzeit einer Schnittstelle in allen Instanzen separat betrachtet werden kann), scheint der Wert nicht groß zu sein, aber es sollte beachtet werden Der Bediener ist ein Produkt. Solange also eine bestimmte Kardinalität eines Etiketts hoch ist oder ein neues Etikett hinzugefügt wird, erhöht sich die Kardinalität der Zeitachse dramatisch.
Warum es wichtig ist
Wie wir alle wissen, verfügen relationale Datenbanken wie MySQL, mit denen jeder am besten vertraut ist, im Allgemeinen über ID-Spalten sowie über allgemeine Spalten wie E-Mail, Bestellnummer usw. Dies sind Spalten mit hoher Kardinalität, von denen man selten hört. Aufgrund einer solchen Datenmodellierung treten jedoch gewisse Probleme auf. Tatsache ist, dass im OLTP-Bereich, mit dem wir vertraut sind, eine hohe Kardinalität oft kein Problem darstellt, im Timing-Bereich jedoch aufgrund des Datenmodells häufig Probleme auftreten Schauen wir uns an, was ein High-Base-Datensatz eigentlich bedeutet.
Meiner Meinung nach bedeutet ein hochbasierter Datensatz eine große Datenmenge. Für eine Datenbank hat die Zunahme der Datenmenge zwangsläufig Auswirkungen auf das Schreiben, Abfragen und Speichern Auswirkungen beim Schreiben ist der Index.
Hohe Kardinalität traditioneller Datenbanken
Nehmen Sie als Beispiel B-Tree, die am häufigsten zum Erstellen von Indizes in relationalen Datenbanken verwendete Datenstruktur. Normalerweise beträgt die Komplexität des Einfügens und der Abfrage O (logN) und die Raumkomplexität beträgt im Allgemeinen O (N). N ist die Anzahl der Elemente, also die Kardinalität, von der wir sprechen. Natürlich hat ein größeres N eine gewisse Auswirkung, aber da die Komplexität des Einfügens und Abfragens dem natürlichen Logarithmus entspricht, ist die Auswirkung nicht so groß, wenn die Datengröße nicht besonders groß ist.
Es scheint also, dass High-Base-Daten keine Auswirkungen haben, die nicht ignoriert werden können. Im Gegenteil, der Index von High-Base-Daten ist selektiver als der Index von Low-Base-Daten Durch eine Abfragebedingung können große Datenmengen herausgefiltert werden, wodurch der Festplatten-E/A-Overhead reduziert wird. In Datenbankanwendungen ist es notwendig, übermäßigen Festplatten- und Netzwerk-E/A-Overhead zu vermeiden. Beispielsweise select * from users where gender = "male";ist der resultierende Datensatz sehr groß und die Festplatten-E/A und die Netzwerk-E/A sind sehr groß. In der Praxis ist die Verwendung dieses Index mit niedriger Kardinalität allein nicht sinnvoll.
Hohe Kardinalität von Zeitreihendatenbanken
Was ist also an Zeitreihendatenbanken anders, was dazu führt, dass Datenspalten mit hohem Basiswert Probleme verursachen? Im Bereich der Zeitreihendaten, sei es Datenmodellierung oder Engine-Design, wird sich der Kern um die Zeitachse drehen. Wie bereits erwähnt, bezieht sich das Problem der hohen Kardinalität in Zeitreihendatenbanken auf die Anzahl und Größe der Zeitleisten. Diese Größe ist nicht nur die Kardinalität einer Spalte, sondern das Produkt der Kardinalität aller Beschriftungsspalten. Es ist verständlich, dass in herkömmlichen relationalen Datenbanken die hohe Basis in einer bestimmten Spalte isoliert ist, dh die Datenskala linear wächst, während die hohe Basis in Zeitreihendatenbanken das Produkt mehrerer Spalten ist, was nichtlinear ist Wachstum. Schauen wir uns genauer an, wie die High-Base-Zeitleiste in der Zeitreihendatenbank generiert wird. Schauen wir uns zunächst das erste Szenario an:
Zeitreihengröße
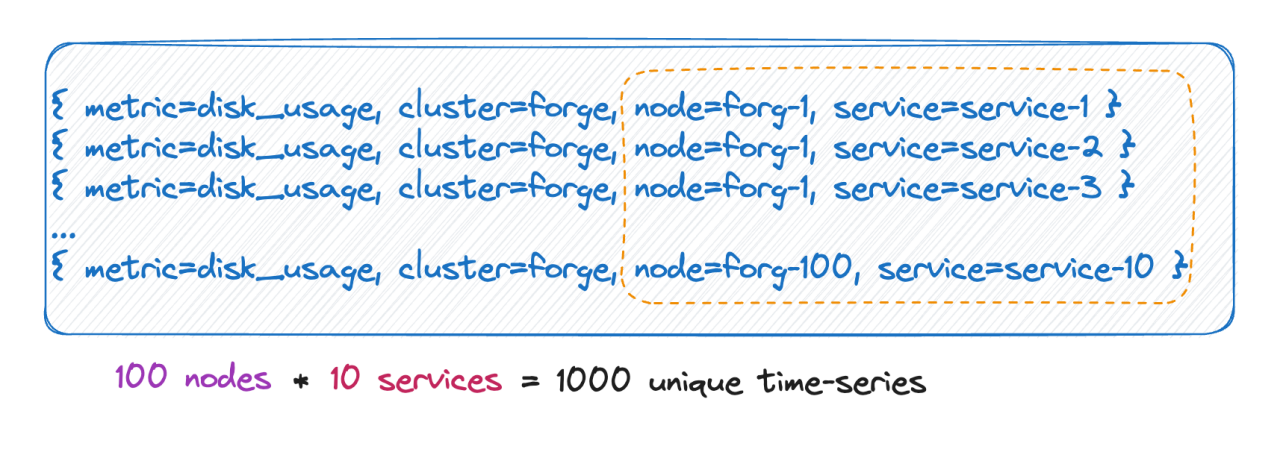
Wir wissen, dass die Anzahl der Zeitlinien tatsächlich dem kartesischen Produkt aller Etikettenbasen entspricht. Wie im Bild oben gezeigt, beträgt die Anzahl der Zeitleisten 100 * 10 = 1000 Zeitleisten. Wenn dieser Metrik 6 Tags hinzugefügt werden, hat jeder Tag-Wert 10 Werte und die Anzahl der Zeitleisten beträgt 10^9, was 100 Millionen entspricht. Eine Zeitleiste, Sie können sich diese Größenordnung vorstellen.
Tag hat unendlich viele Werte
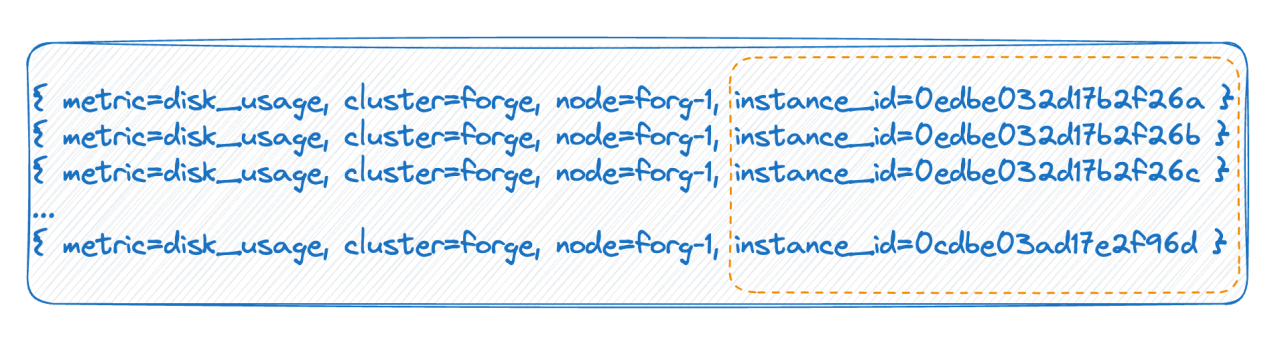
Im zweiten Fall hat beispielsweise in einer Cloud-nativen Umgebung jeder Pod eine ID. Bei jedem Neustart wird der Pod tatsächlich gelöscht und neu erstellt und eine neue ID generiert, was dazu führt, dass der Tag-Wert sehr hoch ist Es gibt viele, und jeder vollständige Neustart führt dazu, dass sich die Anzahl der Zeitleisten verdoppelt. Die beiden oben genannten Situationen sind die Hauptgründe für die in der Zeitreihendatenbank erwähnte hohe Kardinalität.
Wie eine Zeitreihendatenbank Daten organisiert
Wir wissen, wie hohe Kardinalität auftritt. Wir müssen verstehen, welche Probleme sie verursachen wird, und wir müssen auch verstehen, wie gängige Zeitreihendatenbanken Daten organisieren.
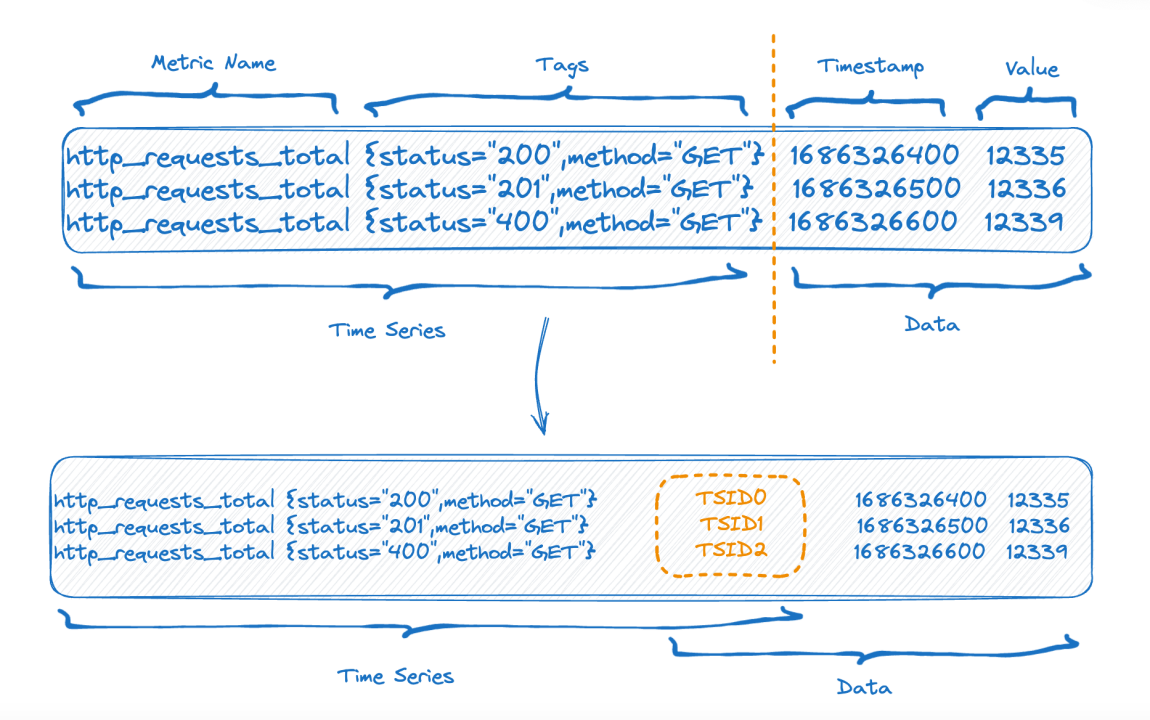
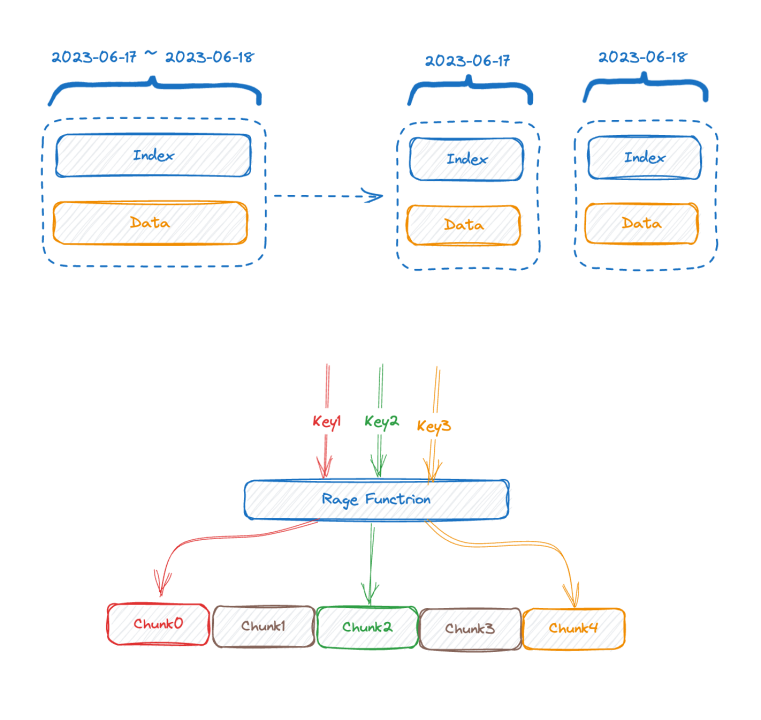
Die obere Hälfte der Abbildung zeigt die Darstellung vor dem Schreiben der Daten und die untere Hälfte der Abbildung zeigt die logische Darstellung nach der Datenspeicherung. Auf der linken Seite sind die Indexdaten des Zeitreihenteils und auf der rechten Seite die Daten dargestellt Teil.
Jede Zeitreihe kann eine eindeutige TSID generieren, und der Index und die Daten sind über die TSID verknüpft. Bekannte Freunde haben diesen Index möglicherweise gesehen, es ist ein invertierter Index.
Schauen wir uns das Bild unten an, das den invertierten Index im Speicher darstellt:
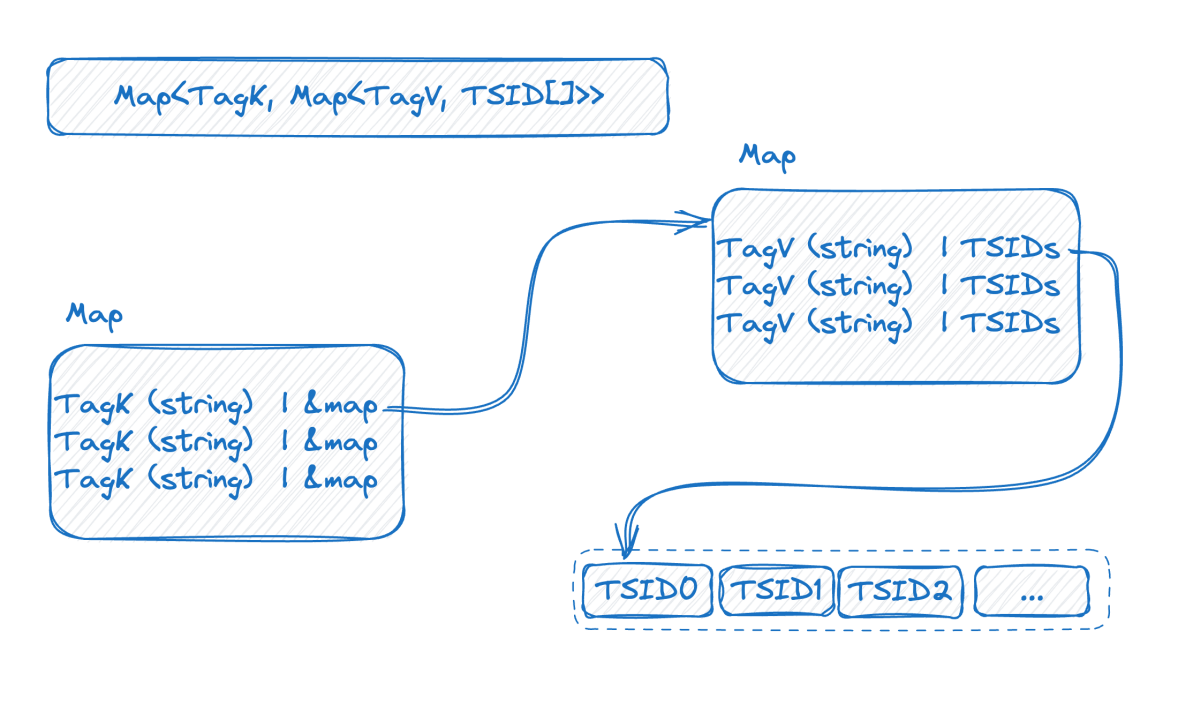
Dies ist eine zweischichtige Karte. Die äußere Schicht findet zunächst die innere Karte über den Tag-Namen. K in der inneren Karte ist der Tag-Wert und V ist der Satz von TSIDs, die den entsprechenden Tag-Wert enthalten.
An diesem Punkt können wir in Kombination mit der vorherigen Einführung sehen, dass die Doppelschichtkarte umso größer sein wird, je höher die Basis der Zeitreihendaten ist. Nachdem wir die Indexstruktur verstanden haben, können wir versuchen zu verstehen, wie das Problem der hohen Basis entsteht:
Um einen hohen Schreibdurchsatz zu erreichen, ist es am besten, diesen Index im Speicher zu belassen. Eine hohe Kardinalität führt dazu, dass der Index erweitert wird und Sie nicht mehr in den Speicher passen. Wenn der Speicher nicht gespeichert werden kann, muss er auf die Festplatte ausgelagert werden. Nach dem Auslagern auf die Festplatte wird die Schreibgeschwindigkeit aufgrund einer großen Menge an zufälligen Festplatten-E/A beeinträchtigt. Schauen wir uns die Abfrage noch einmal an. Anhand der Indexstruktur können wir den Abfrageprozess erraten, z. B. die Abfragebedingungen where status = 200 and method="get". Der Prozess besteht darin, zuerst die Karte mit dem Schlüssel zu finden status, die innere Karte abzurufen und dann "200"alle TSID-Sätze abzurufen erneut auf die gleiche Weise, und dann wird der neue TSID-Satz, der nach dem Schnittpunkt der beiden TSID-Sätze erhalten wird, verwendet, um Daten nacheinander entsprechend der TSID abzurufen.
Es ist ersichtlich, dass der Kern des Problems darin besteht, dass die Daten gemäß der Zeitleiste organisiert sind. Sie müssen also zuerst die Zeitleiste abrufen und dann die Daten gemäß der Zeitleiste finden. Je mehr Zeitachsen an einer Abfrage beteiligt sind, desto langsamer wird die Abfrage.
Wie man es löst
Wenn unsere Analyse korrekt ist und wir die Ursache des Problems mit hoher Basis im Bereich der Zeitreihendaten kennen, wird es einfach sein, die Ursache des Problems zu lösen:
- Datenebene: Indexwartungs- und Abfrageherausforderungen, verursacht durch C(L1) * C(L2) * C(L3) * ... * C(Ln).
- Technische Ebene: Die Daten sind nach Zeitleisten organisiert. Sie müssen also zuerst die Zeitleiste abrufen und dann die Daten entsprechend der Zeitleiste finden. Wenn mehr Zeitleisten vorhanden sind, ist die Abfrage langsamer.
Der Herausgeber wird die Lösungen unter zwei Aspekten diskutieren:
Optimierung der Datenmodellierung
1 Entfernen Sie unnötige Etiketten
Wir legen häufig versehentlich einige unnötige Felder als Beschriftungen fest, wodurch die Zeitleiste aufgebläht wird. Wenn wir beispielsweise den Status des Servers überwachen, instance_nameist ipes tatsächlich nicht erforderlich, dass diese beiden Felder zu Beschriftungen werden, und das andere kann als Attribut festgelegt werden.
2. Datenmodellierung basierend auf tatsächlichen Abfragen
Nehmen Sie als Beispiel Sensorüberwachung im Internet der Dinge:
- 10-W-Geräte
- 100 Regionen
- 10 Geräte
Wenn es in Prometheus in eine Metrik modelliert wird, ergibt sich eine Zeitleiste von 10 W * 100 * 10 = 100 Millionen. (Nicht strenge Berechnung) Denken Sie darüber nach, wird die Abfrage auf diese Weise durchgeführt? Wie kann man beispielsweise die Zeitleiste eines bestimmten Gerätetyps in einer bestimmten Region abfragen? Dies scheint unangemessen, da nach der Angabe des Geräts auch der Typ bestimmt wird, sodass die beiden Beschriftungen nicht unbedingt zusammen sein müssen. Dann kann es zu Folgendem kommen:
- metric_one: 10-W-Geräte
- metric_two:
- 100 Regionen
- 10 Geräte
- metric_ three: (unter der Annahme, dass ein Gerät möglicherweise in eine andere Region verschoben wird, um Daten zu sammeln)
- 10-W-Geräte
- 100 Regionen
Insgesamt ergibt sich eine Zeitleiste von 10 W + 100 10 + 10 W 100 ~ 1010 W, was zehnmal weniger als oben ist.
3. Verwalten Sie wertvolle High-Base-Timeline-Daten separat
Wenn Sie natürlich feststellen, dass Ihre Datenmodellierung sehr gut mit der Abfrage übereinstimmt, die Zeitachse jedoch immer noch nicht reduziert werden kann, weil der Datenumfang zu groß ist, sollten Sie alle mit diesem Kernindikator verbundenen Dienste auf einen besseren Computer übertragen.
Optimierung der Zeitreihen-Datenbanktechnologie
- Die erste wirksame Lösung ist die vertikale Segmentierung. Die meisten gängigen Zeitreihendatenbanken in der Branche haben mehr oder weniger eine ähnliche Methode zur Segmentierung des Index nach Zeit übernommen, denn wenn diese Segmentierung nicht durchgeführt wird, wird der Index im Laufe der Zeit erweitert Immer mehr, und schließlich kann der Speicher ihn nicht mehr speichern. Wenn er nach Zeit aufgeteilt wird, kann der alte Indexblock auf die Festplatte oder sogar auf den Remotespeicher ausgelagert werden.
- Das Gegenteil der vertikalen Segmentierung ist die Verwendung eines Sharding-Schlüssels, bei dem es sich im Allgemeinen um ein oder mehrere Tags mit der höchsten Häufigkeit der Verwendung von Abfrageprädikaten handeln kann äquivalent zur Verwendung Die verteilte Divide-and-Conquer-Idee löst den Engpass auf einem einzelnen Computer. Der Preis besteht darin, dass der Operator nicht nach unten gedrückt werden kann und die Daten nur auf den verschoben werden können, wenn die Abfragebedingung keinen Sharding-Schlüssel enthält oberste Ebene zur Berechnung.
Bei den oben genannten beiden Methoden handelt es sich um traditionelle Lösungen, die das Problem nur bis zu einem gewissen Grad lindern können, das Problem jedoch nicht grundsätzlich lösen können. Die nächsten beiden Lösungen sind keine herkömmlichen Lösungen, sondern die Richtungen, die GreptimeDB zu erkunden versucht. Sie werden hier nur zu Ihrer Information kurz erwähnt, ohne dass eine eingehende Analyse erfolgt:
-
Wir möchten vielleicht darüber nachdenken, ob Zeitreihendatenbanken wirklich invertierte Indizes benötigen und InfluxDB_IOx keine invertierten Indizes hat. Für Abfragen mit hoher Kardinalität verwenden wir Partitionsscans, die üblicherweise in OLAP-Datenbanken verwendet werden, in Kombination mit Min-Max Wäre der Effekt besser, wenn wir eine Bereinigungsoptimierung durchführen würden?
-
Asynchrone intelligente Indizierung Um intelligent zu sein, müssen Sie zunächst das Verhalten analysieren und asynchron erstellen, um die Abfragen des Benutzers zu beschleunigen. Dafür wird keine Inversion erzeugt. Durch die Kombination der beiden oben genannten Lösungen hat die Inversion beim Schreiben keinen Einfluss auf die Schreibgeschwindigkeit, da sie asynchron erstellt wird.
Wenn wir uns die Abfrage noch einmal ansehen, können die Daten anhand des Zeitstempels in Buckets eingeteilt werden. Die Lösung besteht darin, einen harten Scan durchzuführen und einige Min-Max-Indizes zur Bereinigungsoptimierung zu kombinieren. Es ist immer noch möglich, Dutzende Millionen oder Hunderte Millionen Zeilen in Sekunden zu scannen.
Wenn eine Anfrage eintrifft, schätzen Sie zunächst ab, wie viele Zeitleisten sie umfassen wird. Wenn es sich um eine kleine Menge handelt, verwenden Sie die Inversion, und wenn es sich um eine große Menge handelt, gehen Sie direkt zu „Scannen + Filtern“ ohne Invertierung.
Wir erforschen die oben genannten Ideen noch und sind noch nicht perfekt.
Abschluss
Eine hohe Basis ist nicht immer ein Problem. Manchmal müssen wir ein eigenes Datenmodell aufbauen, das auf unseren eigenen Geschäftsbedingungen und der Art der von uns verwendeten Tools basiert. Natürlich weisen Tools manchmal bestimmte Szenariobeschränkungen auf. Prometheus indiziert beispielsweise standardmäßig Etiketten unter jedem einzelnen Computer. Dies ist jedoch auch für Benutzer praktisch beim Umgang mit großen Datenmengen überfordert. GreptimeDB ist bestrebt, eine einheitliche Lösung sowohl für Einzelplatz- als auch für Großszenarien zu schaffen. Wir untersuchen auch technische Ansätze für komplexe Probleme, und jeder ist willkommen, darüber zu diskutieren.
Referenz
- https://en.wikipedia.org/wiki/Cardinality
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
Über Greptime:
Greptime Greptime Technology hat es sich zur Aufgabe gemacht, effiziente Datenspeicherungs- und Analysedienste in Echtzeit für Bereiche bereitzustellen, die große Mengen an Zeitreihendaten erzeugen, wie etwa intelligente Autos, das Internet der Dinge und Beobachtbarkeit, und Kunden dabei zu helfen, den großen Wert von Daten auszuschöpfen. Derzeit gibt es drei Hauptprodukte:
-
GreptimeDB ist eine in der Rust-Sprache geschriebene Zeitreihendatenbank. Sie ist Open Source, cloudnativ und hochkompatibel. Sie hilft Unternehmen, Zeitreihendaten in Echtzeit zu lesen, zu schreiben, zu verarbeiten und zu analysieren und gleichzeitig die langfristigen Speicherkosten zu senken.
-
GreptimeCloud kann Benutzern vollständig verwaltete DBaaS-Dienste bereitstellen, die hochgradig in Observability, Internet of Things und andere Bereiche integriert werden können.
-
GreptimeAI ist eine auf LLM-Anwendungen zugeschnittene Observability-Lösung.
-
Die integrierte Fahrzeug-Cloud-Lösung ist eine Zeitreihen-Datenbanklösung, die tief in die tatsächlichen Geschäftsszenarien von Automobilunternehmen eindringt und die tatsächlichen Geschäftsprobleme löst, nachdem die Fahrzeugdaten des Unternehmens exponentiell gewachsen sind.
GreptimeCloud und GreptimeAI wurden offiziell getestet. Folgen Sie dem offiziellen Account oder der offiziellen Website für die neuesten Entwicklungen! Wenn Sie an der Enterprise-Version von GreptimDB interessiert sind, können Sie sich gerne an den Assistenten wenden (suchen Sie auf WeChat nach greptime, um den Assistenten hinzuzufügen).
Offizielle Website: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Dokumentation: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Slack: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele für Windows-Plattformen zu produzieren