
Die Magie des eBPF-Codes besteht darin, Peer-Adressen direkt in den TCP-Stream weiterzuleiten, um die Kommunikationstopologie zu rekonstruieren
„ Erstellen einer Netzwerktopologie einer Kubernetes-Anwendung auf nicht-intrusive Weise“ von Ilya Shakhat.
einführen
Eine Kubernetes-Anwendung ist logisch in zwei Teile unterteilt: Ein Teil sind die Rechenressourcen (dargestellt durch Pods) und der andere Teil stellt den Zugriff auf die Anwendung bereit (dargestellt durch Dienste). Anwendungsclients können über den abstrakten Namen darauf zugreifen, ohne sich darum zu kümmern, welcher Pod die Anfrage tatsächlich bearbeitet. Und da ein einzelner Dienst mehrere Pods als Backends haben kann, fungiert er auch als Lastausgleicher. In einer standardmäßigen Kubernetes-Bereitstellung wird diese Lastausgleichsfunktion mithilfe sehr einfacher iptables oder Linux IPVS implementiert – beide arbeiten auf der L4-Ebene (z. B. TCP) und implementieren einen naiven, zufallsbasierten Round-Robin-Mechanismus. Natürlich können Cloud-Anbieter auch traditionellere Lastausgleichslösungen für die Bereitstellung von Anwendungen anbieten, aber fangen wir einfach an.
Wenn wir über die verschiedenen Probleme nachdenken, die bei in Kubernetes bereitgestellten Anwendungen auftreten können, gibt es eine Klasse von Problemen, die ein Verständnis der spezifischen Instanz der Verarbeitung von Clientanforderungen erfordern. Beispiel: (1) Ein Anwendungs-Pod wird auf einem Host mit einer schlechten Netzwerkverbindung bereitgestellt und es dauert länger, eine neue Verbindung herzustellen als bei anderen Pods, oder (2) die Leistung eines Pods lässt mit der Zeit nach, während die Leistung anderer Pods stabil bleibt oder (3) die Anfrage eines bestimmten Clients wirkt sich auf die Anwendungsleistung aus. Die verteilte Ablaufverfolgung ist oft eine Möglichkeit, Erkenntnisse zu solchen Problemen zu gewinnen, und wird offensichtlich verwendet, um den Pfad einer Client-Anfrage zur Backend-Anwendung zu verfolgen. Traditionell erfordert die verteilte Ablaufverfolgung eine Form der Instrumentierung, die vom manuellen Hinzufügen von Code bis hin zur vollautomatischen Injektion in die Laufzeit reichen kann. Aber kann der gleiche Effekt erzielt werden, ohne den Client-Code überhaupt zu ändern?
Um das obige Problem zu beheben, benötigen wir im Wesentlichen zwei Funktionen der verteilten Ablaufverfolgung: (1) das Sammeln von Metriken im Zusammenhang mit der Anforderungslatenz und (2) die genaue Kenntnis, wohin jede Anforderung geht. Die erste Funktion kann einfach und auf unaufdringliche Weise mit einem der zahlreichen von eBPF unterstützten Tools (einer Technologie, die das dynamische Anhängen von Sonden an Kernelfunktionen ermöglicht) implementiert werden, z. B. Protokollieren, welcher Prozess eine neue Verbindung hergestellt hat, Abrufen von Socket-/Verbindungsmetriken und prüfen Sie sogar auf erneute Übertragungen oder böswillige Verbindungszurücksetzungen. Im openEuler-Ökosystem ist Gala-Gopher ein solches Tool, das eine große Anzahl verschiedener Sonden bereitstellt, darunter Socket-, TCP- und L7/HTTP(s)-Sonden. Allerdings ist die zweite Funktion (zu wissen, wohin eine einzelne Anfrage geht) viel schwieriger zu erreichen. In einem verteilten Tracing-Framework wird dies erreicht, indem eine Span-/Trace-ID in die Anwendungsnutzlast eingefügt wird und dann Beobachtungen sowohl vom Client als auch vom Backend unter Verwendung derselben Span-ID korreliert werden. Da es nicht in den Anwendungscode eingreift, müssen dieselben Informationen auf generische Weise eingefügt werden. Dies ist jedoch einfach nicht möglich, da dies das Abfangen des ausgehenden Datenverkehrs, dessen Analyse, das Einfügen der ID usw. in das Anwendungsprotokoll erfordern würde serialisiert und weitergeleitet. Es sieht so aus, als hätten wir gerade ein Service-Mesh neu erfunden!
Bevor wir fortfahren, werfen wir einen Blick auf die in der Netzwerküberwachung verfügbaren Daten. Hier gehen wir davon aus, dass der Monitor Informationen von allen Knoten erhält, die den Anwendungs-Pod hosten, und diese Daten dann beispielsweise von Prometheus verarbeitet werden. Sammel Sie. Um dies zu erreichen, benötigen wir eine experimentelle Umgebung.
Test Umgebung
Zunächst benötigen wir einen bereitgestellten Kubernetes-Cluster mit mehreren Knoten. In der Huawei Cloud heißt der entsprechende Dienst Cloud Container Engine (CCE).
Dann benötigen wir eine Testanwendung, und dafür verwenden wir ein sehr einfaches Python-Programm, das eine HTTP-Anfrage akzeptiert und in der Lage ist, ausgehende HTTP-Anfragen an die in der ursprünglichen Anfrage angegebene Adresse zu stellen. Auf diese Weise können wir Anwendungen einfach verknüpfen.
Diese Anwendungen werden mit den lateinischen Buchstaben A, B usw. benannt. Anwendung A wird als Bereitstellung A und Dienst A usw. bereitgestellt. Die erste Anwendung wird auch der Außenwelt ausgesetzt, sodass sie von außen aufgerufen werden kann.
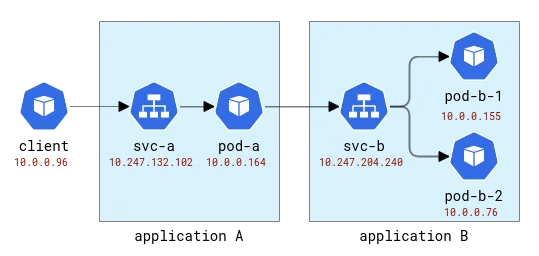
A- und B-Anwendungstopologie
In Kubernetes wird Gala-gopher als Daemon-Set bereitgestellt und auf jedem Kubernetes-Knoten ausgeführt. Es stellt Metriken bereit, die von Prometheus genutzt und letztendlich von Grafana visualisiert werden. Die Servicetopologie wird basierend auf Metriken erstellt und durch das NodeGraph-Plugin visualisiert.
Beobachtbarkeit
Senden wir einige Anfragen an Anwendung A und leiten sie wie folgt an Anwendung B weiter:
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
In der Ausgabe sehen wir, dass eine der Anfragen für Anwendung B an einen Pod und die andere Anfrage an einen anderen Pod gesendet wurde. So sieht die Topologie in Grafana aus:
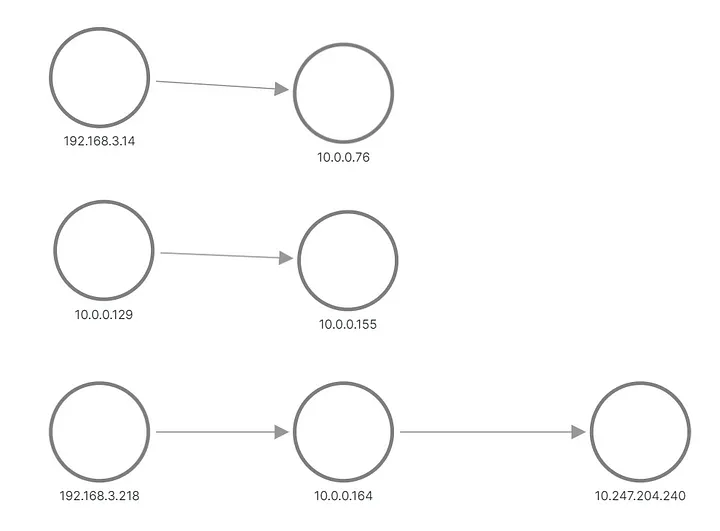
A und B wenden eine aus Metriken rekonstruierte Topologie an
Die obere und mittlere Reihe zeigen etwas, das eine Anfrage an den Pod von Anwendung B sendet, während die untere Zeile einen der Pods von A zeigt, der eine Anfrage an die virtuelle IP von Dienst B sendet. Aber das sieht überhaupt nicht nach unseren Erwartungen aus, oder? Wir sehen nur drei Knotensätze ohne Verbindungen zwischen ihnen. Die IP-Adressen aus dem Subnetz 192.168.3.0/24 sind die Knotenadressen aus dem Cluster Private Network (VPC), und 10.0.0.1/24 ist die Pod-Adresse, mit Ausnahme von 10.0.0.129, der Knotenadresse, die für intra- Knotenkommunikation.
Jetzt werden diese Metriken auf Socket-Ebene erfasst, was bedeutet, dass sie genau das sind, was der Anwendungsprozess sehen kann. Die Erfassung erfolgt über eBPF-Probes. Daher besteht die erste Idee darin, zu prüfen, ob der Betriebssystemkernel mehr über die Anwendungsverbindung weiß als die im Socket verfügbaren Informationen. Der Cluster ist mit einem Standard-CNI konfiguriert und der Kubernetes-Dienst ist als iptables-Regel implementiert. Die Ausgabe von iptables-save zeigt die Konfiguration. Am interessantesten sind diese Regeln, die den Lastausgleich tatsächlich konfigurieren:
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
Der Lastausgleich erfolgt auf demselben Knoten wie der Client. Wenn wir also Pods Knoten zuordnen, sieht das so aus:
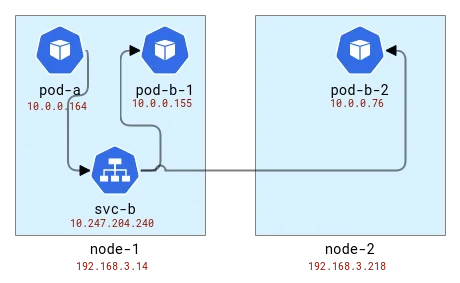
Ordnen Sie die Topologie der Anwendungen A und B den Kubernetes-Knoten zu
Intern verwendet iptables (eigentlich nftables ) das conntrack-Modul, um zu verstehen, dass Pakete zur gleichen Verbindung gehören und auf ähnliche Weise behandelt werden sollten. Conntrack ist auch für die Adressübersetzung verantwortlich, sodass Knoten mit Clientanwendungen wissen sollten, wohin sie Pakete senden sollen. Schauen wir es uns mit dem CLI-Tool conntrack an.
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
Okay, wir sehen also, dass auf dem ersten Knoten die Adresse aus dem Pod von Anwendung A übersetzt wurde und wir eine Knotenadresse mit einem zufälligen Port erhalten haben. Auf dem zweiten Knoten sind die Verbindungsinformationen umgekehrt, da das eigene Paket tatsächlich eine Antwort ist. Vor diesem Hintergrund sehen wir jedoch, dass die Anfrage vom ersten Knoten und demselben zufälligen Port kommt. Beachten Sie, dass es auf Knoten-1 zwei Anfragen gibt, da wir zwei Anfragen gesendet haben und diese von verschiedenen Pods bearbeitet wurden: Pod-b-1 auf demselben Knoten und Pod-b-2 auf einem anderen Knoten.
Die gute Nachricht hierbei ist, dass es möglich ist, den tatsächlichen Anforderungsempfänger auf dem Client-Knoten zu kennen, aber für die Serverseite muss er mit den auf dem Client-Knoten gesammelten Informationen korreliert werden . so was:
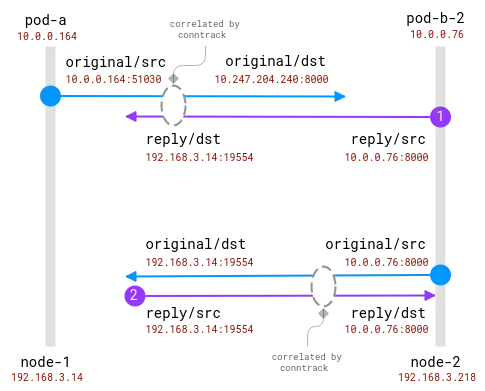
Verbindungen werden vom Conntrack-Modul verfolgt. Der blaue Kreis ist die im Socket beobachtete lokale Adresse und der violette Kreis ist die Remote-Adresse. Die Herausforderung besteht darin, Lila und Blau in Beziehung zu setzen.
Wenn sich sowohl Client- als auch Server-Pods auf demselben Knoten befinden, wird die Korrelation einfacher, es gibt jedoch immer noch einige Annahmen darüber, welche Adressen echt sind und welche ignoriert werden sollten:
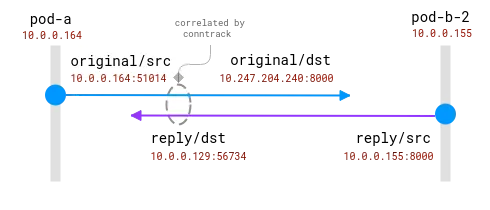
Eine Verbindung zwischen zwei Pods auf demselben Knoten. Die Quelladresse ist echt, aber die Zieladresse muss zugeordnet werden
Hier hat das Betriebssystem vollständige Einblicke in das NAT und kann eine Zuordnung zwischen der realen Quelle und dem realen Ziel bereitstellen. Es ist _möglich_, den kompletten Stream von 10.0.0.164 auf 10.0.0.155 neu zu erstellen.
Zum Abschluss dieses Abschnitts sollte es möglich sein, bestehende eBPF-Probes um Informationen zur Adressübersetzung aus dem Conntrack-Modul zu erweitern. Der Kunde kann wissen, wohin die Anfrage geht. Da der Server jedoch nicht immer wissen kann, wer der Client ist, gibt es keinen zentralen Korrelationsalgorithmus direkt. Im Gegensatz dazu liefern verteilte Tracing-Methoden Clients und Servern direkt und unmittelbar aus Kommunikationsdaten Informationen über ihre Peers . Also, hier kommt FlowTracer!
FlowTracer
Die Idee ist einfach: Daten zwischen Peers direkt innerhalb der Verbindung übertragen. Dies ist nicht das erste Mal, dass eine solche Funktion benötigt wird. Beispielsweise fügt der HTTP-Load-Balancer den HTTP-Header „X-Forwarded-For“ ein, um den Backend-Server über den Client zu informieren. Die Einschränkung besteht darin, dass wir bei L4 bleiben wollen und somit jedes Protokoll auf Anwendungsebene unterstützen möchten. Eine solche Funktionalität ist ebenfalls vorhanden, und einige L4-Load-Balancer (wie dieser hier ) können die Ursprungsadresse als TCP-Header-Option einfügen und sie dem Server verfügbar machen.
Zusammenfassung der Anforderungen:
- Transport-Peer-Adresse der L4-Schicht.
- Möglichkeit, die Adressinjektion dynamisch zu aktivieren (so einfach wie die Bereitstellung von Anwendungen in K8s).
- Nichtinvasiv und schnell.
Der einfachste Ansatz scheint die Verwendung von TCP-Header-Optionen (auch bekannt als TOA) zu sein. Die Nutzdaten sind die IP-Adresse und die Portnummer (da sie sich während der Adressübersetzung ändern). Da die Kubernetes-Bereitstellung von Huawei nur IPv4 unterstützt, können wir die Unterstützung nur auf IPv4 beschränken. IPv4-Adressen sind 32 Bits lang, während Portnummern 16 Bits erfordern, was insgesamt 6 Bytes erfordert, plus 1 Byte für den Optionstyp und 1 Byte für die Optionslänge. So sehen die TCP-Header-Spezifikationen aus:
Der Header kann mehrere Optionen mit bis zu 40 Byte enthalten. Jede Option kann eine variable Länge und einen variablen Typ/Art haben.
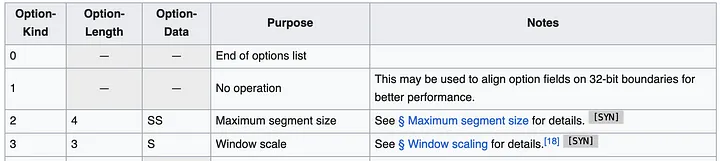
Im Allgemeinen verfügen Linux-TCP-Pakete bereits über einige Optionen, beispielsweise MSS oder Zeitstempel. Es stehen uns aber noch etwa 20 Byte Speicherplatz zur Verfügung.
Wenn wir nun wissen, wo die Daten abgelegt werden sollen, stellt sich als nächstes die Frage: Wo sollen wir den Code hinzufügen? Wir möchten, dass die Lösung möglichst allgemein ist und für alle TCP-Verbindungen verwendet werden kann. Der ideale Ort befindet sich irgendwo im Kernel im Netzwerkstapel, in einem sogenannten Socket-Puffer (einer Struktur, die Netzwerkverbindungsinformationen darstellt), von der obersten Ebene bis hinunter zu den Paketen, die für die Übertragung über das Netzwerk bereit sind. Aus Sicht der Implementierung sollte der Code (natürlich!) eBPF-Code sein und die Adressinjektionsfunktionalität kann dann dynamisch aktiviert werden.
Der offensichtlichste Ort für diese Art von Code ist TC, ein Flusskontrollmodul. Beim TC hat das eBPF-Programm Zugriff auf das erstellte Paket und kann Daten aus dem Paket lesen und schreiben. Ein Nachteil besteht darin, dass das Paket von Anfang an analysiert werden muss. Das heißt, obwohl die Funktion bpf_skb_load_bytes_relative einen Zeiger auf den Anfang des L3-Headers bereitstellt, muss die L4-Position dennoch manuell berechnet werden. Am problematischsten ist der Einfügevorgang. Es gibt zwei Funktionen mit vielversprechenden Namen, bpf_skb_adjust_room und bpf_skb_change_tail , aber sie ermöglichen eine Größenänderung von Paketen bis L3, nicht L4. Eine alternative Lösung besteht darin, zu prüfen, ob der vorhandene TCP-Header bestimmte Optionen enthält, und diese zu überschreiben. Schauen wir uns jedoch zunächst an, was ein typisches Paket enthält.
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
Dies ist das TCP-SYN-Paket, das gesendet wird, wenn der Client eine Verbindung mit der Backend-Anwendung aufbaut. Der Header enthält mehrere Optionen: MSS zur Angabe der maximalen Segmentgröße, dann optionale Bestätigung, einen bestimmten Zeitstempel, um die Reihenfolge der Pakete sicherzustellen, einen Opcode-NOP möglicherweise für die Wortausrichtung und schließlich für die Fensterskalierung für die Fenstergröße. Aus dieser Liste ist die Zeitstempeloption der beste Kandidat, der abgedeckt werden kann (laut Wikipedia liegt die Akzeptanz immer noch bei etwa 40 %), während DeepFlow – einer der Marktführer im Bereich der nicht-intrusiven eBPF-Verfolgung – diesen Vorgang durchgeführt hat.
Obwohl dieser Ansatz machbar erscheint, ist er nicht einfach umzusetzen. Das TC-Programm hat Zugriff auf übersetzte Adressen, was bedeutet, dass die Übersetzungskarte irgendwie vom Conntrack-Modul abgerufen und gespeichert werden sollte. Das TC-Programm stellt eine Verbindung zur Netzwerkkarte her. Wenn ein Knoten also über mehrere Netzwerkkarten verfügt, muss die Bereitstellung den Anschlussort korrekt identifizieren. Das Lesemodul muss alle Pakete analysieren, um den TCP zu finden, und dann die Header durchlaufen, um herauszufinden, wo sich unser Header befindet. Gibt es eine andere Möglichkeit?
Wenn Sie im August 2023 über Google nach dieser Frage suchen, wird häufig unten auf der Suchergebnisseite „Keine weiteren Ergebnisse“ angezeigt (hoffentlich ändert sich das mit diesem Blogbeitrag!). Die nützlichste Referenz ist ein Link zu einem Linux-Kernel-Patch, der 2020 von Facebook-Ingenieuren erstellt wurde. Dieser Patch zeigt, wonach wir suchen:
Frühe Arbeiten an BPF-TCP-CC ermöglichten das Schreiben von TCP-Überlastungskontrollalgorithmen in BPF. Es bietet die Möglichkeit, die Durchlaufzeit in Produktionsumgebungen zu verbessern, wenn neue Ideen zur Überlastungskontrolle getestet/veröffentlicht werden. Die gleiche Flexibilität kann auf das Schreiben von TCP-Header-Optionen ausgeweitet werden.
Es ist nicht ungewöhnlich, dass Benutzer neue TCP-Header-Optionen testen möchten, um die TCP-Leistung zu verbessern. Ein weiterer Anwendungsfall sind Rechenzentren, die über eine besser kontrollierte Umgebung verfügen und Header-Optionen in den rein internen Datenverkehr einfügen können, was mehr Flexibilität bietet.
Der heilige Gral sind diese Funktionen: bpf_store_hdr_opt und bpf_load_hdr_opt ! Beide gehören zu einer speziellen Art von Sock-Ops -Programmen, die seit dem 5.10-Kernel verfügbar sind und daher in fast jeder Version nach 2022 verwendet werden können. Das Sock-Ops-Programm ist eine einzelne Funktion, die an cgroup v2 angehängt ist und die es ermöglicht, es nur für bestimmte Sockets (z. B. Zugehörigkeit zu einem bestimmten Container) zu aktivieren. Das Programm empfängt eine einzelne Operation, die den aktuellen Status des Sockets angibt. Wenn wir eine neue Header-Option schreiben möchten, müssen wir zunächst das Schreiben für eine aktive oder passive Verbindung aktivieren und dann die neue Header-Länge mitteilen, bevor die Header-Nutzlast geschrieben werden kann. Der Lesevorgang ist einfacher, allerdings müssen wir auch zuerst das Lesen aktivieren, bevor wir die Header-Optionen lesen können. Wenn ein TCP-Paket erstellt wird, wird der TCP-Header-Callback aufgerufen. Dies geschieht vor der Adressübersetzung, sodass wir die Socket-Quelladresse in die Header-Optionen kopieren können. Der Leser kann den Wert einfach aus der Header-Option extrahieren und in einer BPF-Zuordnung speichern, sodass der Verbraucher später die beobachtete Remote-Adresse lesen und der tatsächlichen Adresse zuordnen kann. Der BPF-Teil des Erstausführungscodes umfasst weit weniger als 100 Zeilen. Ziemlich gut!
Machen Sie den Code produktionsbereit
Allerdings steckt der Teufel im Detail. Zunächst benötigen wir eine Möglichkeit, alte Datensätze aus der BPF-Karte zu löschen. Der beste Zeitpunkt hierfür ist, wenn das Conntrack-Modul die Verbindung aus seiner Tabelle löscht. Dieser Artikel von Arthur Chiao bietet eine gute Beschreibung des Conntrack-Moduls und der internen Struktur des Verbindungslebenszyklus, sodass es einfach ist, die richtige Funktion in den Kernel-Quellen zu finden – nf_conntrack_destroy . Diese Funktion empfängt den Conntrack-Eintrag, bevor sie ihn aus der internen Tabelle löscht. Da die Verbindung zu diesem Zeitpunkt offiziell endet, können wir auch eine Sonde hinzufügen, die die Verbindung ebenfalls aus unserer Zuordnungstabelle entfernt.
Im Sock-Ops-Programm geben wir nicht an, in welche Pakete die neue Header-Option eingefügt wird, vorausgesetzt, sie gilt für alle Pakete. Tatsächlich stimmt das, aber der Lesevorgang ist nur dann wirksam, wenn sich die Verbindung im etablierten/bestätigten Zustand befindet, was bedeutet, dass die Serverseite die Header-Optionen nicht aus dem eingehenden SYN-Paket lesen kann. SYN-ACK wird ebenfalls vor dem regulären TCP-Stack verarbeitet und Header-Optionen können weder injiziert noch gelesen werden. Tatsächlich funktioniert diese Funktion auf beiden Seiten nur, wenn die Verbindung vollständig mit dem ersten PSH (Paket) läuft. Für eine funktionierende Verbindung ist das vollkommen in Ordnung, aber wenn der Verbindungsversuch fehlschlägt, weiß der Client nicht, wo er versucht hat, eine Verbindung herzustellen. Dies ist ein schwerwiegender Fehler; diese Informationen sind für die Fehlerbehebung bei Netzwerkproblemen nützlich. Wie wir wissen, wird der Kubernetes-Lastausgleich auf dem Client-Knoten implementiert, sodass wir die Informationen aus Conntrack extrahieren und im gleichen Format wie die über den Stream empfangenen Daten speichern können. Hier hilft die Conntrack-Funktion ___nf_conntrack_confirm_ – sie wird aufgerufen, wenn eine neue Verbindung bestätigt werden soll, was bei aktiven (ausgehenden) TCP-Verbindungen des Clients dann erfolgt, wenn das erste SYN-Paket gesendet wird.
Mit all diesen Ergänzungen wird der Code etwas aufgebläht, umfasst aber insgesamt immer noch weit weniger als 1000 Zeilen. Der vollständige Patch ist in diesem MR verfügbar . Es ist Zeit, es in unserem Versuchsaufbau zu aktivieren und die Metriken und Topologie erneut zu überprüfen!
Sehen:
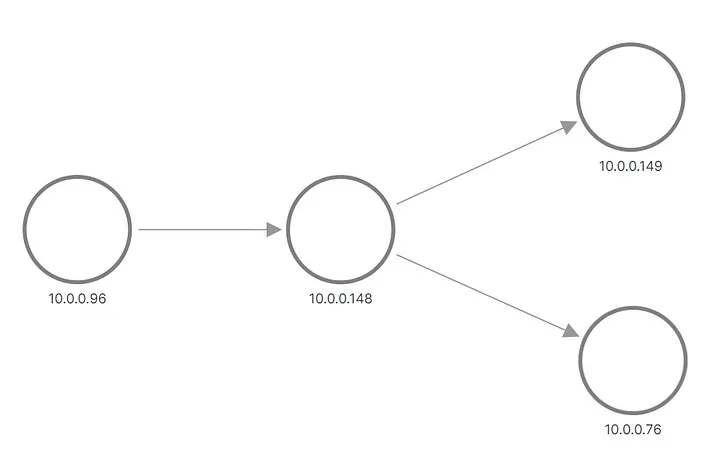
Korrekte A/B-Anwendungstopologie
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele für Windows-Plattformen zu produzierenDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.