

Da die SaaS-Branche schnell wächst, werden dynamische und anpassungsfähige Architekturen benötigt, um den Zustrom von Echtzeitdaten zu bewältigen. So bauen Sie sie.
Übersetzt aus „ How To Build a Scalable Platform Architecture for Real-Time Data“ , Autorin Christina Lin.
Die Software-as-a-Service-Branche (SaaS) verzeichnet ein unaufhaltsames Wachstum, wobei die Marktgröße im Jahr 2024 voraussichtlich 317,555 Milliarden US-Dollar erreichen und sich bis 2032 auf 1,22887 Milliarden US-Dollar fast verdreifachen wird . Dieses Wachstum unterstreicht den wachsenden Bedarf an verbesserten robusten Datenstrategien. Dieser Trend wird durch die zunehmende Menge, Geschwindigkeit und Vielfalt der von Unternehmen generierten Daten sowie die Integration künstlicher Intelligenz vorangetrieben.
Diese wachsende Landschaft bringt jedoch mehrere wichtige Herausforderungen mit sich, wie z. B. die Bewältigung von Spitzendatenverkehr, den Übergang von der Online-Transaktionsverarbeitung (OLTP) zur Online-Analyseverarbeitung (OLAP) in Echtzeit, die Gewährleistung von Self-Service und Entkopplung sowie die Umstellung auf Cloud-Agnostik und Multifunktionalität. Regionsbereitstellung. Die Bewältigung dieser Herausforderungen erfordert ein ausgefeiltes Architektur-Framework, das hohe Verfügbarkeit und robuste Failover-Mechanismen gewährleistet, ohne die Systemleistung zu beeinträchtigen.
Die Referenzarchitektur in diesem Artikel beschreibt detailliert, wie eine skalierbare, automatisierte und flexible Datenplattform zur Unterstützung der wachsenden SaaS-Branche aufgebaut wird. Diese Architektur unterstützt die technischen Anforderungen der Verarbeitung großer Datenmengen und stimmt gleichzeitig mit den Geschäftsanforderungen hinsichtlich Agilität, Kosteneffizienz und Einhaltung gesetzlicher Vorschriften überein.
Technische Herausforderungen datenintensiver SaaS-Dienste
Da die Nachfrage nach Diensten und Datenmengen weiter wächst, ergeben sich in der SaaS-Branche mehrere gemeinsame Herausforderungen.
Der Umgang mit Verkehrsspitzen und -spitzen ist entscheidend für die effiziente Zuweisung von Ressourcen zur Bewältigung variabler Verkehrsmuster. Dies erfordert die Isolierung von Arbeitslasten, die Skalierung bei Spitzenlasten und die Reduzierung der Rechenressourcen außerhalb der Spitzenzeiten bei gleichzeitiger Vermeidung von Datenverlusten.
Die Aufrechterhaltung von OLTP in Echtzeit gegenüber OLAP bedeutet die nahtlose Unterstützung von OLTP, das große Mengen schneller Transaktionen mit Schwerpunkt auf Datenintegrität verwaltet, und OLAP-Systemen, die schnelle analytische Erkenntnisse unterstützen. Diese doppelte Unterstützung ist entscheidend für die Unterstützung komplexer analytischer Abfragen und die Aufrechterhaltung der Spitzenleistung. Es spielt auch eine Schlüsselrolle bei der Vorbereitung von Datensätzen für maschinelles Lernen (ML).
Um Self-Service und Entkopplung zu ermöglichen, müssen Teams mit Self-Service-Funktionen ausgestattet werden, um Themen und Cluster zu erstellen und zu verwalten, ohne sich stark auf ein zentrales IT-Team verlassen zu müssen. Dies beschleunigt die Entwicklung und ermöglicht gleichzeitig die Entkopplung von Anwendungen und Diensten sowie die Erzielung unabhängiger Skalierbarkeit.
Die Förderung von Cloud-Agnostizismus und -Stabilität ermöglicht Agilität und die Fähigkeit, in verschiedenen Cloud-Umgebungen wie AWS , Microsoft Azure oder anderen zu arbeiten
So bauen Sie eine SaaS-freundliche Architektur auf
Um diesen Herausforderungen zu begegnen, übernehmen große SaaS-Unternehmen oft ein Architektur-Framework, das den Betrieb mehrerer Cluster über mehrere Regionen hinweg umfasst und von einer individuell entwickelten Steuerungsebene verwaltet wird. Das Design der Steuerebene erhöht die Flexibilität der zugrunde liegenden Infrastruktur und vereinfacht gleichzeitig die Komplexität der damit verbundenen Anwendungen.
Während diese Strategie für eine hohe Verfügbarkeit und einen robusten Failover-Mechanismus von entscheidender Bedeutung ist, kann sie auch zu komplex werden, um eine einheitliche Leistung und Datenintegrität in einem geografisch verteilten Cluster aufrechtzuerhalten, ganz zu schweigen von der Beeinträchtigung der Leistung oder der Einführung von Latenzzeiten entstehen.
Darüber hinaus kann es in bestimmten Szenarien aus Compliance- oder Sicherheitsgründen erforderlich sein, dass Daten innerhalb eines bestimmten Clusters isoliert werden. Um Ihnen beim Aufbau einer robusten, flexiblen Architektur zu helfen, die diese Komplexität vermeidet, werde ich Sie durch einige Vorschläge führen.
1. Schaffen Sie ein stabiles Fundament
Eine große Herausforderung für SaaS-Dienste ist die Zuweisung von Ressourcen für die Bewältigung verschiedener Verkehrsmuster, einschließlich hochfrequenter und umfangreicher Online-Abfragen, Dateneinfügung und internem Datenaustausch.
Die Umwandlung des Datenverkehrs in asynchrone Prozesse ist eine gängige Lösung, die eine effizientere Skalierung und schnelle Zuweisung von Rechenressourcen ermöglicht. Daten-Streaming-Plattformen wie Apache Kafka eignen sich ideal für die effiziente Verwaltung riesiger Datenmengen. Doch die Verwaltung einer verteilten Datenplattform wie Kafka bringt eigene Herausforderungen mit sich. Das System von Kafka ist für seine technische Komplexität bekannt, da es die Verwaltung der Clusterkoordination, Synchronisierung und Skalierung sowie zusätzliche Sicherheits- und Wiederherstellungsprotokolle erfordert. Herausforderungen bei Kafka
Auch die Java Virtual Machine (JVM) in Kafka kann unvorhersehbare Latenzspitzen verursachen, vor allem aufgrund des Garbage-Collection-Prozesses der JVM. Die Verwaltung der Speicherzuweisung der JVM und die Optimierung für die hohen Durchsatzanforderungen von Kafka ist bekanntermaßen mühsam und kann sich auf die Gesamtstabilität des Kafka-Brokers auswirken.
Ein weiteres Hindernis ist Kafkas Datenrichtlinienverwaltung. Dazu gehört die Verwaltung von Datenaufbewahrungsrichtlinien, Protokollkomprimierung und Datenlöschung bei gleichzeitiger Abwägung von Speicherkosten, Leistung und Compliance bis zu einem gewissen Grad.
Kurz gesagt, die effektive Verwaltung von Kafka-basierten Systemen in einer SaaS-Umgebung ist schwierig. Aus diesem Grund greifen viele SaaS-Unternehmen auf Kafka-Alternativen zurück , die ein hochskalierbares Datenstreaming ermöglichen , ohne dass externe Abhängigkeiten wie JVM oder ZooKeeper erforderlich sind.
2. Aktivieren Sie Self-Service-Streaming-Daten
Es besteht eine wachsende Nachfrage nach Self-Service-Lösungen, die es Entwicklern ermöglichen, Themes von der Entwicklung bis zur Produktion zu erstellen. Der Infrastruktur- oder Plattformdienst sollte eine Lösung mit zentraler Steuerung bereitstellen, Anmeldedaten bereitstellen und die schnelle Erstellung und Bereitstellung von Ressourcen über verschiedene Plattformen und Phasen hinweg automatisieren.
Dies erhöht den Bedarf an einer Kontrollebene, die es in vielen Formen gibt. Einige Steuerungsebenen werden nur verwendet, um den Lebenszyklus eines Clusters oder Themas zu verwalten und Berechtigungen auf der Streaming-Plattform zuzuweisen. Andere Steuerungsebenen fügen eine Abstraktionsebene hinzu, indem sie Ziele virtualisieren und Infrastrukturdetails vor Benutzern und Clients verbergen.
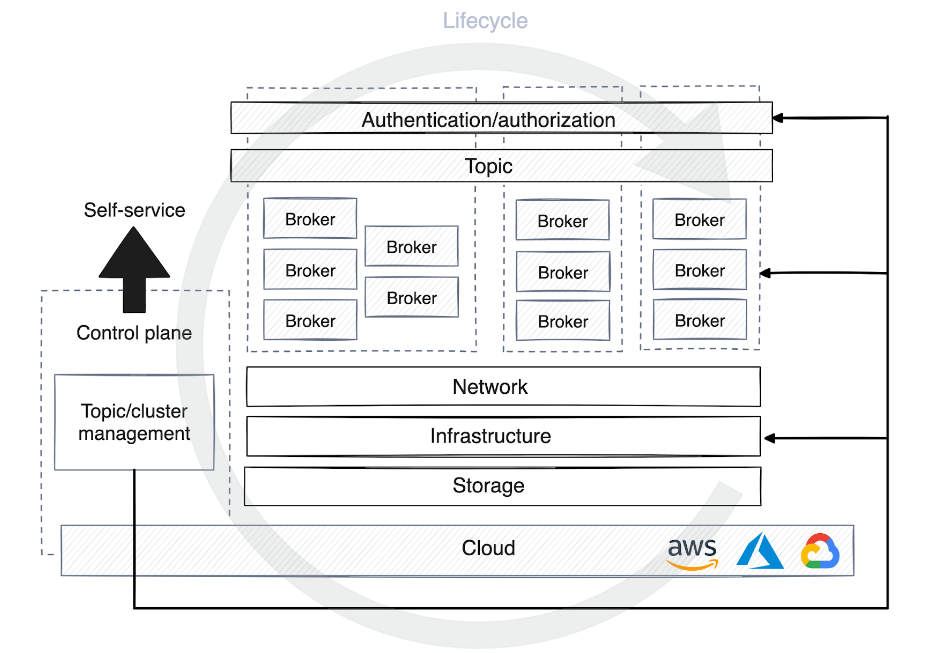
Wenn ein Thema in der Steuerungsebene der Self-Service-Datenplattform registriert wird, werden je nach Stadium der Umgebung unterschiedliche Strategien zur Optimierung der Rechenressourcen angewendet. In der Entwicklung teilen sich Themen häufig Cluster mit anderen Prozessen, die Datenaufbewahrung wird weniger groß geschrieben und die meisten Daten werden innerhalb weniger Tage verworfen.
In der Produktion muss die Ressourcenzuweisung jedoch sorgfältig auf der Grundlage des Verkehrsaufkommens geplant werden. Diese Planung umfasst die Bestimmung der Anzahl der Partitionen für Verbraucher, das Festlegen von Richtlinien zur Datenaufbewahrung, die Entscheidung über den Speicherort der Daten und die Überlegung, ob Sie für bestimmte Anwendungsfälle einen dedizierten Cluster benötigen.
Für die Steuerungsebene ist es sehr hilfreich, den Lebenszyklusverwaltungsprozess der Streaming-Plattform zu automatisieren. Dies ermöglicht es der Steuerungsebene, Agenten autonom zu debuggen, Leistungsmetriken zu überwachen und die Neuverteilung von Partitionen zu starten oder zu stoppen, um die Plattformverfügbarkeit und -stabilität im großen Maßstab aufrechtzuerhalten.
3. Echtzeitunterstützung für OLTP und OLAP
Der Übergang von der Stapelverarbeitung zur Echtzeitanalyse macht die Integration von OLAP-Systemen in die bestehende Infrastruktur von entscheidender Bedeutung. Allerdings verarbeiten diese Systeme typischerweise große Datenmengen und erfordern komplexe Datenmodelle für eine tiefgreifende mehrdimensionale Analyse.
OLAP stützt sich auf mehrere Datenquellen, und je nach Reifegrad des Unternehmens gibt es normalerweise ein Data Warehouse oder einen Data Lake zum Speichern der Daten sowie Stapelverarbeitungspipelines, die regelmäßig (normalerweise jede Nacht) ausgeführt werden, um Daten aus den Datenquellen zu verschieben . Bei diesem Prozess werden Daten aus verschiedenen OLTP-Systemen und anderen Quellen zusammengeführt – ein Prozess, der hinsichtlich der Aufrechterhaltung der Datenqualität und -konsistenz komplex werden kann.
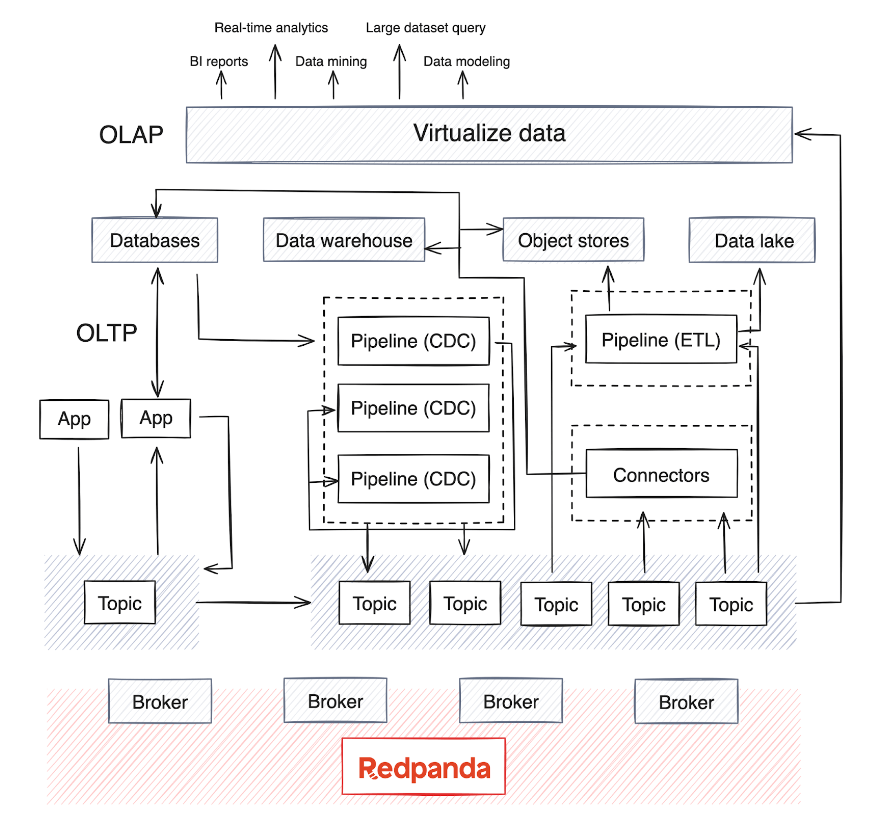
Heute integriert OLAP auch KI-Modelle mit großen Datenmengen. Die meisten verteilten Datenverarbeitungs-Engines und Streaming-Datenbanken unterstützen mittlerweile die Nutzung, Aggregation, Zusammenfassung und Analyse von Streaming-Daten aus Quellen wie Kafka oder Redpanda in Echtzeit. Dieser Trend hat zum Aufkommen von Pipelines zum Extrahieren, Transformieren, Laden (ETL) und Extrahieren, Laden, Transformieren (ELT) für Echtzeitdaten sowie zu Change Data Capture (CDC)-Pipelines geführt, die Ereignisprotokolle aus Datenbanken streamen.
Echtzeit-Pipelines, die typischerweise in Java , Python oder Golang implementiert werden, erfordern eine sorgfältige Planung. Um den Lebenszyklus dieser Pipelines zu optimieren, integrieren SaaS-Unternehmen das Pipeline-Lebenszyklusmanagement in ihre Steuerungsebenen, um die Überwachung und Ressourcenausrichtung zu optimieren.
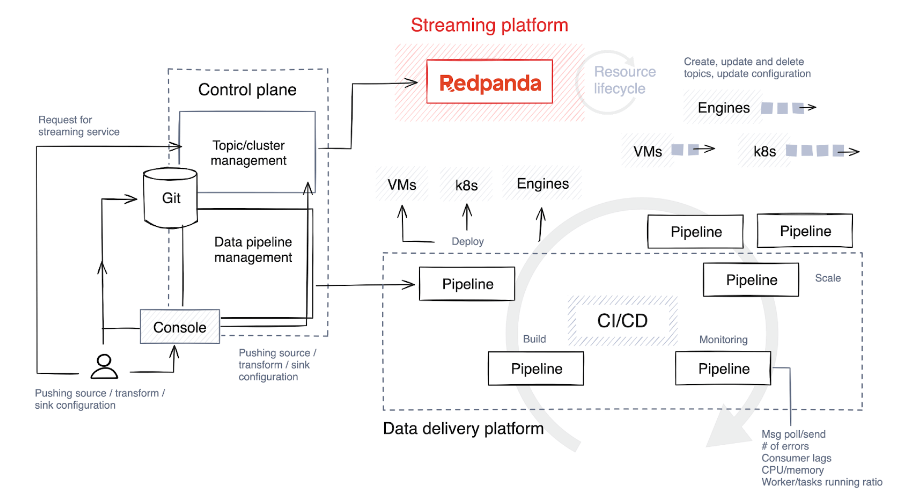
4. Verstehen (und optimieren) Sie den Lebenszyklus der Datenpipeline
Der erste Schritt besteht darin, einen Technologie-Stack auszuwählen und den Grad an Freiheit und Anpassung zu bestimmen, den Benutzer, die Pipelines erstellen, genießen werden. Ermöglichen Sie ihnen im Idealfall die Auswahl verschiedener Technologien für unterschiedliche Aufgaben und die Implementierung von Leitplanken, um den Bau und die Erweiterung von Pipelines einzuschränken.
Im Folgenden finden Sie einen kurzen Überblick über die Phasen des Pipeline-Lebenszyklus.
Bauen und testen
Der Quellcode wird entweder direkt von Pipeline-Entwicklern oder über benutzerdefinierte Tools in der Steuerungsebene in ein Git-Repository übertragen. Dieser Code wird dann mithilfe einer Sprache wie C++, Java oder C# in Binärcode oder ein ausführbares Programm kompiliert. Nach der Kompilierung wird der Code in ein Artefakt gepackt, ein Prozess, der auch die Bündelung autorisierter Abhängigkeiten und Konfigurationsdateien umfassen kann.
Anschließend führt das System automatisierte Tests durch, um den Code zu verifizieren. Während des Testens erstellt die Kontrollebene temporäre Themen speziell für diesen Zweck und diese Themen werden gelöscht, sobald der Test abgeschlossen ist.
einsetzen
Artefakte werden je nach Technologie-Stack auf virtuellen Maschinen (z. B. Kubernetes ) oder Streaming-Datenbanken bereitgestellt. Einige Plattformen bieten kreativere Ansätze für Release-Strategien, wie z. B. Blue/Green-Bereitstellungen, die ein schnelles Rollback ermöglichen und Ausfallzeiten minimieren. Eine weitere Strategie ist Canary Release, bei dem eine neue Version nur auf einen kleinen Teil der Daten angewendet wird, wodurch die Auswirkungen potenzieller Probleme verringert werden.
Die Nachteile dieser Strategien bestehen darin, dass Rollbacks eine Herausforderung darstellen können und es schwierig sein kann, die von der neuen Version betroffenen Daten zu isolieren. Manchmal ist es einfacher, eine vollständige Freigabe durchzuführen und den gesamten Datensatz zurückzusetzen.
Expandieren
Viele Plattformen unterstützen die automatische Skalierung, z. B. die Anpassung der Anzahl laufender Instanzen basierend auf der CPU-Auslastung, der Grad der Automatisierung variiert jedoch. Einige Plattformen stellen diese Funktionalität nativ bereit, während andere eine manuelle Konfiguration erfordern, z. B. das Festlegen der maximalen Anzahl paralleler Aufgaben oder Arbeitsprozesse pro Job.
Während der Bereitstellung stellt die Steuerungsebene Standardeinstellungen basierend auf der erwarteten Nachfrage bereit, überwacht die Metriken jedoch weiterhin genau. Anschließend werden dem Thema zusätzliche Ressourcen zugewiesen, indem die Anzahl der Arbeitsprozesse, Aufgaben oder Instanzen nach Bedarf skaliert wird.
Monitor
Die Überwachung der richtigen Kennzahlen in Ihrer Pipeline und die Aufrechterhaltung der Beobachtbarkeit sind die wichtigsten Möglichkeiten, Probleme frühzeitig zu erkennen. Hier sind einige wichtige Kennzahlen, die Sie proaktiv überwachen sollten, um die Effizienz und Zuverlässigkeit Ihrer Datenverarbeitungspipeline sicherzustellen.
Ressourcenindikatoren
- Die CPU- und Speicherauslastung ist entscheidend für das Verständnis des Ressourcenverbrauchs.
- Festplatten-E/A ist wichtig für die Bewertung der Effizienz von Datenspeicher- und -abrufvorgängen.
Durchsatz und Latenz
- Eingabe-/Ausgabedatensätze messen die Datenverarbeitungsrate pro Sekunde.
- Pro Sekunde verarbeitete Datensätze stellen die Verarbeitungsleistung des Systems dar.
- Die End-to-End-Latenz ist die Gesamtzeit, die von der Dateneingabe bis zur Datenausgabe benötigt wird und für die Echtzeitverarbeitungsleistung von entscheidender Bedeutung ist.
Gegendruck und Hysterese
- Diese helfen, Engpässe in der Datenverarbeitung zu erkennen und mögliche Verlangsamungen zu verhindern.
Fehlerrate
- Die Verfolgung von Fehlerraten trägt dazu bei, die Datenintegrität und Systemzuverlässigkeit aufrechtzuerhalten
5. Verbessern Sie Zuverlässigkeit, Redundanz und Ausfallsicherheit
Unternehmen legen Wert auf Hochverfügbarkeit, Notfallwiederherstellung und Ausfallsicherheit, um den kontinuierlichen Betrieb bei Störungen aufrechtzuerhalten. Die meisten Daten-Streaming-Plattformen verfügen bereits über starke Schutzmaßnahmen und Bereitstellungsstrategien, vor allem durch die Erweiterung von Clustern über mehrere Partitionen, Rechenzentren und cloudunabhängige Verfügbarkeitszonen.
Dies ist jedoch mit Kompromissen verbunden, wie z. B. einer erhöhten Latenz, potenzieller Datenduplizierung und höheren Kosten. Hier finden Sie einige Vorschläge für die Planung von Hochverfügbarkeit, Notfallwiederherstellung und Ausfallsicherheit.
Hohe Verfügbarkeit
Ein automatisierter Bereitstellungsprozess, der von der Kontrollebene verwaltet wird, spielt eine Schlüsselrolle bei der Etablierung einer robusten Hochverfügbarkeitsstrategie . Diese Strategie stellt sicher, dass Pipelines, Konnektoren und Streaming-Plattformen je nach Cloud-Anbieter oder Rechenzentrum strategisch über Verfügbarkeitszonen oder Partitionen verteilt werden .

Für Datenplattformen ist es von entscheidender Bedeutung, alle Datenpipelines auf mehrere Verfügbarkeitszonen (AZs) zu verteilen, um das Risiko zu reduzieren. Die Kontinuität wird durch die Ausführung redundanter Kopien von Pipelines in verschiedenen AZs unterstützt, um eine unterbrechungsfreie Datenverarbeitung im Falle eines Partitionsausfalls aufrechtzuerhalten.
Streaming-Plattformen, die der Datenarchitektur zugrunde liegen, sollten diesem Beispiel folgen und Daten automatisch über mehrere AZs hinweg replizieren, um die Ausfallsicherheit zu verbessern. Lösungen wie Redpanda können die Datenverteilung über Partitionen hinweg automatisieren und so die Zuverlässigkeit und Fehlertoleranz der Plattform verbessern.
Berücksichtigen Sie jedoch die potenziell damit verbundenen Kosten für die Netzwerkbandbreite und berücksichtigen Sie dabei den Standort Ihrer Anwendungen und Dienste. Wenn beispielsweise Pipelines in der Nähe von Datenspeichern gehalten werden, können die Netzwerklatenz und der Overhead reduziert und gleichzeitig die Kosten gesenkt werden.
Notfallwiederherstellung
Eine schnellere Wiederherstellung nach einem Ausfall ist mit höheren Kosten aufgrund der erhöhten Datenreplikation verbunden, was zu einem höheren Bandbreiten-Overhead führt und eine Always-on-Einstellung (Aktiv-Aktiv) erfordert, wodurch sich die Hardwarenutzung verdoppelt. Nicht alle Streaming-Technologien bieten diese Funktionalität, aber Plattformen der Unternehmensklasse wie Redpanda unterstützen die Sicherung von Daten und Cluster-Metadaten im Cloud-Objektspeicher.
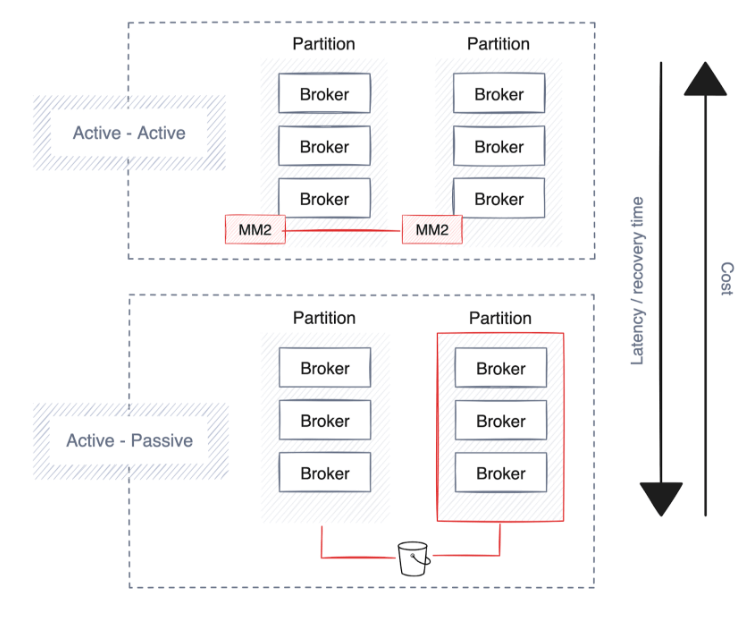
Elastizität
Zusätzlich zu Hochverfügbarkeit und Notfallwiederherstellung benötigen einige globale Unternehmen regionale Bereitstellungsstrategien, um sicherzustellen, dass ihre Datenspeicherung und -verarbeitung den spezifischen geografischen Vorschriften entspricht. Stattdessen erstellen Unternehmen, die Daten in Echtzeit über verschiedene Regionen hinweg mit minimalem Verwaltungsaufwand austauschen möchten, häufig einen gemeinsamen Cluster, der es Agenten ermöglicht, Daten über Regionen hinweg zu replizieren und zu verteilen.
Dieser Ansatz verursacht jedoch erhebliche Netzwerkkosten und Latenz, da Daten kontinuierlich an die folgenden Partitionen übertragen werden. Um den Datenverkehr zu verringern, weist Follower Fetch den Datenkonsumenten an, Daten von der geografisch nächstgelegenen Follower-Partition zu lesen.
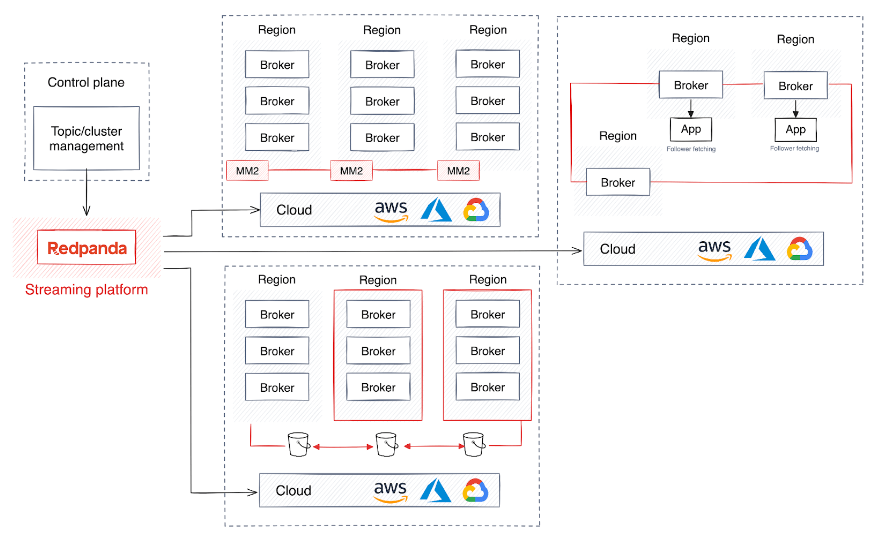
Darüber hinaus verbessert die Skalierung von Clustern für das Daten-Backfill den Lastausgleich zwischen Rechenzentren. Diese Skalierbarkeit ist für die Verwaltung wachsender Datenmengen und des Netzwerkverkehrs von entscheidender Bedeutung und hilft Unternehmen bei der Skalierung ohne Einbußen bei Leistung oder Zuverlässigkeit.
abschließend
Während sich Unternehmen durch die digitale Transformation verändern, werden Echtzeitdaten für die Entscheidungsfindung immer wichtiger. Dabei geht es darum, tiefere Erkenntnisse aus riesigen Datensätzen zu gewinnen , genauere Prognosen zu ermöglichen, automatisierte Entscheidungsprozesse zu rationalisieren und personalisiertere Dienste bereitzustellen – und das alles bei gleichzeitiger Optimierung von Kosten und Abläufen.
Eine Möglichkeit besteht darin, eine Referenzarchitektur zu übernehmen, die eine skalierbare Daten-Streaming-Plattform wie Redpanda umfasst , einen in C++ implementierten Plug-and-Play-Kafka-Ersatz. Es ermöglicht Unternehmen, Echtzeit zu vermeiden, indem es eine nahtlose Skalierung, eine Verwaltungs-API , die die Lebenszyklusautomatisierung unterstützt , mehrstufigen Speicher zur Reduzierung der Speicherkosten , Remote-Lesereplikate zur Vereinfachung der Einrichtung kostengünstiger Nur-Lese-Cluster und eine nahtlose Geoverteilung von Daten ermöglicht Verarbeitungskomplexität.
Mit der richtigen Technologie können SaaS-Anbieter ihre Dienste verbessern, das Kundenerlebnis verbessern und ihren Wettbewerbsvorteil auf dem digitalen Markt steigern. Zukünftige Strategien sollten diese Systeme weiterhin für mehr Effizienz und Anpassungsfähigkeit optimieren, damit SaaS-Plattformen in einer datengesteuerten Welt erfolgreich sein können.
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele für Windows-Plattformen zu produzierenDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.