
Wir finden, dass die Zuordnung einer Domäne (Veröffentlichung) zu einer anderen (der domänenspezifischen Sprache von SQL) gut zu den Stärken von LLM passt.
Übersetzt aus SQL Schema Generation With Large Language Models , Autor David Eastman.
Ich habe mir die mit LLM generierte Regex- und JSON-Persistenz angesehen, aber viele glauben, dass KI gut mit der Structured Query Language (SQL) zurechtkommt . Um den 50. Geburtstag von SQL zu feiern , besprechen wir Tabellen und führen bei Bedarf technische Terminologie ein. Ich möchte die Abfrage jedoch nicht nur anhand einer vorhandenen Tabelle testen . Die Welt der relationalen Datenbanken beginnt mit Schema .
Ein Schema beschreibt eine Reihe von Tabellen, die interagieren, damit SQL-Abfragen Fragen zu einem Modell eines realen Systems beantworten können. Wir verwenden verschiedene Einschränkungen, um zu steuern, wie Tabellen zueinander in Beziehung stehen. In diesem Beispiel werde ich ein Schema für Bücher, Autoren und Verleger entwickeln. Wir werden dann sehen, ob LLM diese Arbeit replizieren kann.
Wir beginnen mit den Beziehungen zwischen unseren Dingen . Ein Buch wird von einem Autor geschrieben und von einem Verlag veröffentlicht. Tatsächlich definiert die Veröffentlichung eines Buches die Beziehung zwischen Autor und Herausgeber.
Konkret wollen wir also folgende Ergebnisse erzielen:
| Buch | Autor | Herausgeber | Veröffentlichungsdatum |
|---|---|---|---|
| Die Wespenfabrik | Iain Banks | Abakus | 16. Februar 1984 |
| Betrachten Sie Phlebas | Iain M. Banks | Orbit | 14. April 1988 |
Das ist schön zu lesen (wir kommen später darauf zurück), aber die Tabelle selbst ist keine gute Möglichkeit, weitere Informationen zu verwalten.
Wenn der Name des Herausgebers nur eine Zeichenfolge wäre, müssen Sie ihn möglicherweise mehrmals eingeben – was sowohl ineffizient als auch fehleranfällig ist. So auch der Autor. Diejenigen unter Ihnen mit einer literarischen Neigung werden wissen, dass der Autor beider Bücher (Iain Banks) dieselbe Person ist, aber er hat beim Schreiben von Science-Fiction leicht unterschiedliche Pseudonyme verwendet.
Was passiert, wenn das Buch später von einem anderen Verlag erneut veröffentlicht wird? Um sicherzustellen, dass diese beiden Veröffentlichungsereignisse unterschieden werden, müssen wir sowohl den Buchtitel als auch das Veröffentlichungsdatum angeben – unser Primärschlüssel oder unsere eindeutige Kennung muss also beides enthalten. Wir möchten, dass das System zwei Bücher mit demselben Titel und demselben Veröffentlichungsdatum ablehnt.
Anstatt eine große Tabelle zu verwenden, verwenden wir drei Tabellen und verweisen bei Bedarf auf diese. Eine für den Autor, eine für den Verlag und eine für das Buch. Wir schreiben die Details der Autoren in die Tabelle „Autoren“ und verweisen dann mithilfe von Fremdschlüsseln auf sie in der Tabelle „Bücher“ .
Das Folgende ist also eine Schematabelle, die mit der Data Definition Language ( DDL ) geschrieben wurde. Ich verwende eine MySQL-Variante – ärgerlicherweise verwenden alle Anbieter immer noch leicht unterschiedliche Dialekte.
Erstens gibt es die Autorentabelle. Wir fügen einen automatischen ID-Spaltenindex als Primärschlüssel hinzu. Wir haben das Pseudonym-Problem noch nicht wirklich gelöst (das überlasse ich dem Leser):
CREATE TABLE Authors (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Birthday date not null,
PRIMARY KEY (ID)
);
Die Publisher-Tabelle folgt demselben Muster. „NOT NULL“ ist eine weitere Einschränkung, die verhindert, dass Daten ohne Inhalt hinzugefügt werden.
CREATE TABLE Publishers (
ID int NOT NULL AUTO_INCREMENT,
Name varchar(255) not null,
Address varchar(255) not null,
PRIMARY KEY (ID)
);
Die Tabelle „books“ verweist auf einen Fremdschlüssel, was sie zwar logisch, aber etwas schwer verständlich macht. Beachten Sie, dass wir respektieren, dass der Titel des Buchs und sein Veröffentlichungsdatum zusammen den Primärschlüssel bilden.
CREATE TABLE Books (
Name varchar(255) NOT NULL,
AuthorID int, PublisherID int,
PublishedDate date NOT NULL,
PRIMARY KEY (Name, PublishedDate),
FOREIGN KEY (AuthorID) REFERENCES Authors(ID),
FOREIGN KEY (PublisherID) REFERENCES Publishers(ID)
);
Um oben eine ordentliche Tabelle zu sehen, benötigen wir eine view . Dies ist lediglich eine Möglichkeit, die Tabellen zusammenzufügen, sodass wir die Informationen auswählen können, die wir anzeigen müssen, während das Schema intakt bleibt. Nachdem wir nun das Schema aufgeschrieben haben, können wir unsere Ansicht aufbauen:
CREATE VIEW ViewableBooks AS
SELECT Books.Name 'Book', Authors.Name 'Author', Publishers.Name 'Publisher', Books.PublishedDate 'Date'
FROM Books, Publishers, Authors
WHERE Books.AuthorID = Authors.ID
AND Books.PublisherID = Publishers.ID;
Mal sehen, ob wir unser Schema in einem Online-Playground generieren können, sodass wir keine Datenbank installieren müssen.
DB Fiddle sollte den Job erledigen.
Wenn Sie DDL eingeben und dann die tatsächlichen Daten hinzufügen:
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain Banks', '1954-02-16');
INSERT INTO Authors (Name, Birthday)
VALUES ('Iain M Banks', '1954-02-16');
INSERT INTO Publishers (Name, Address)
VALUES ('Abacus', 'London');
INSERT INTO Publishers (Name, Address)
VALUES ('Orbit', 'New York');
Das Ergebnis der Ansicht wird im DB Fiddle als „Query 3“ angezeigt. Dies sind genau die Daten, die wir sehen wollten:
Kann LLM auch Muster erzeugen?
Okay, jetzt möchten wir LLM nach der Erstellung des Schemas fragen. Um zusammenzufassen, wie wir LLM unterstützen möchten:
- Wenn wir das Schema auf Englisch abfragen, möchten wir, dass es DDL für die drei Tabellen generiert, einschließlich Indizes und Einschränkungen.
- Bei Bedarf können wir auch die Notwendigkeit von Einschränkungen (Primärschlüssel, Fremdschlüssel usw.) implizieren.
- Wir können darum bitten, es zu sehen.
- Bei Bedarf können wir es anweisen, MySQL-Syntax zu verwenden.
Ich werde Llama 3 verwenden , habe mir aber auch LLM von OpenAI angesehen und ungefähr die gleichen Ergebnisse erzielt.
Unsere erste Anfrage: „Erstellen Sie ein relationales Datenbankschema, um Bücher, Verlage und Autoren zu beschreiben.“
Ergebnis:
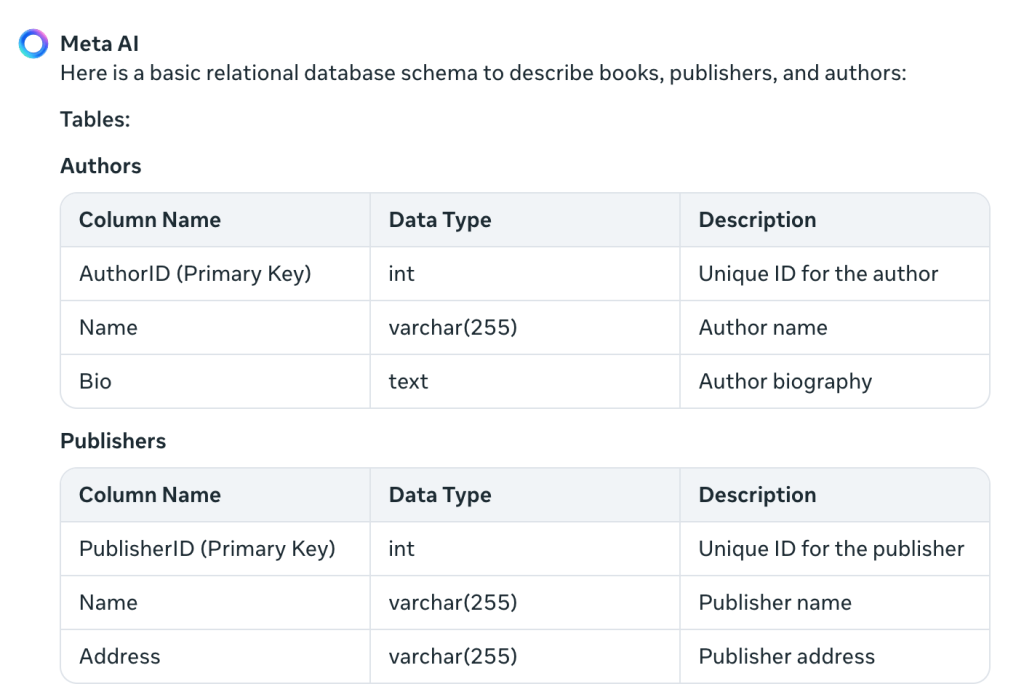
So weit, ist es gut. Die DDL wurde noch nicht erstellt, aber wir können separat nachfragen. Es eignet sich irgendwie besser, das Muster auf Englisch zu beschreiben. Schauen wir uns den Rest der Antwort an:
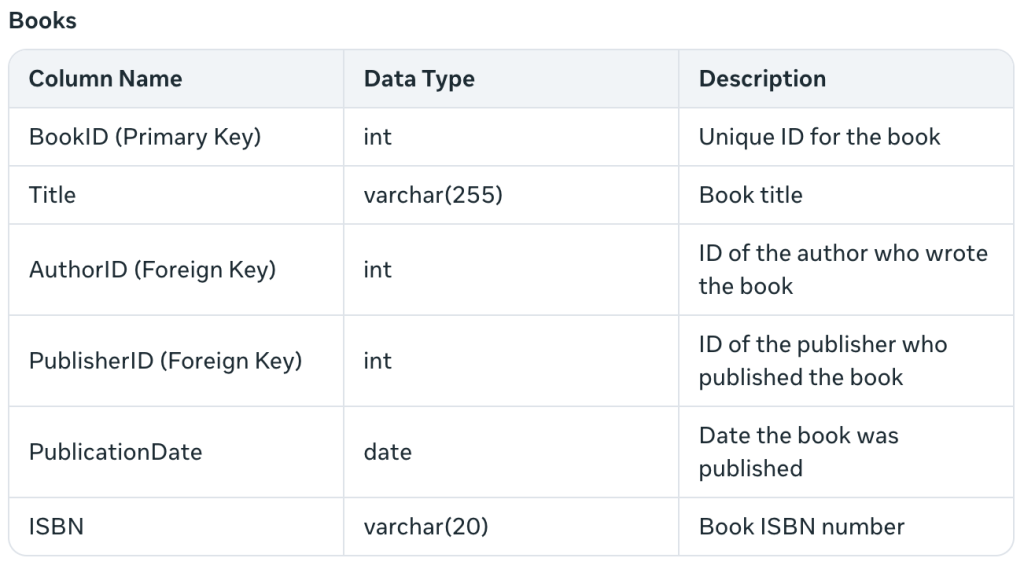
Es beschreibt die Fremdschlüsseleinschränkungen und fügt die ISBN hinzu, was ich nicht erwartet hatte. Außerdem ist „PublicationDate“ idiomatischer als mein „PublishedDate“. Außerdem wird eine Tabelle erstellt:
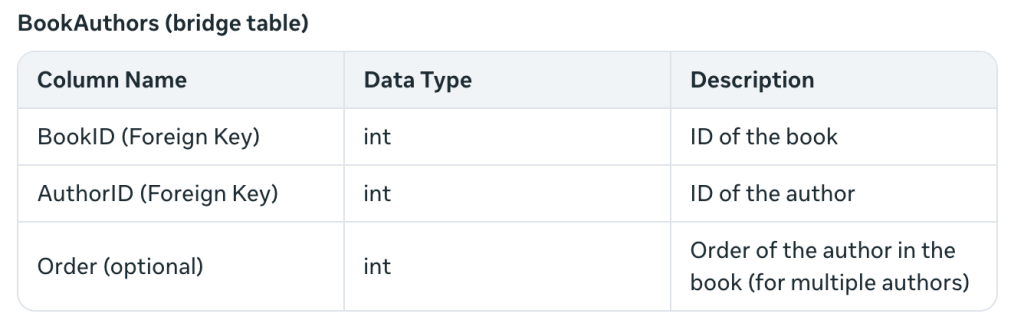
Dies löst das Problem, mehrere Autoren für ein Buch anzulegen – etwas, an das ich vorher nicht gedacht hatte. Der Begriff Brückentabelle bedeutet, dass zwei Tabellen (Bücher und Autoren) durch einen Fremdschlüssel verbunden sind.
Fragen wir DDL: „Zeigen Sie mir die Datendefinitionssprache für dieses Schema.“
Diese werden korrekt zurückgegeben, einschließlich NOT NULL-Werten, um sicherzustellen, dass keine leeren Einträge vorhanden sind. Darin heißt es außerdem, dass die DDL in mancher Hinsicht „universell“ sei, da es tatsächlich Unterschiede zwischen den SQL-Lösungen der Anbieter gebe.
Lassen Sie uns zum Schluss noch eine Meinung dazu einholen:

Dies ist komplizierter als meine Version, funktioniert jedoch in DB Fiddle einwandfrei, wenn ich mich an die Benennung meines Schemas anpasse. Die hier gezeigte Tabellenaliasbenennung ist für das Verständnis nicht hilfreich.
Fazit: LLM kann tatsächlich Muster erzeugen
Ich denke, das ist ein großer Gewinn für LLM, weil sie meine englische Beschreibung in ein gut eingeschränktes Muster und dann in eine ausführbare DDL umgewandelt haben und gleichzeitig Erklärungen bereitgestellt haben (obwohl diese Erklärungen eher für technische Beziehungsdetails gedacht waren). Ich habe nicht einmal ein dediziertes LLM oder einen speziellen Dienst genutzt, also hat es großartig geklappt.
In gewisser Weise handelt es sich hierbei um eine Zuordnung einer Domäne (der Verlagswelt) zu einer anderen (der domänenspezifischen Sprache von SQL), und das ist für LLM sehr vorteilhaft. Jeder Bereich ist klar definiert und reich an Details.
Herzlichen Glückwunsch zum Geburtstag an SQL und ich hoffe, dass LLM es noch ein paar Jahrzehnte lang relevant hält!
Ein in den 1990er Jahren geborener Programmierer hat eine Videoportierungssoftware entwickelt und in weniger als einem Jahr über 7 Millionen verdient. Das Ende war sehr bestrafend! High-School-Schüler erstellen im Rahmen einer Coming-of-Age-Zeremonie ihre eigene Open-Source-Programmiersprache – scharfe Kommentare von Internetnutzern: Der inländische Dienst Taobao (taobao.com) verließ sich aufgrund des grassierenden Betrugs auf RustDesk und stellte die inländischen Dienste ein und startete die Arbeit zur Optimierung der Webversion von Java neu 17 ist die am häufigsten verwendete Java LTS-Version. Windows 11 erreicht weiterhin einen Rückgang. Open Source Daily unterstützt die Übernahme von Open Source Rabbit R1; Electric schließt die offene Plattform Apple veröffentlicht M4-Chip Google löscht Android Universal Kernel (ACK) Unterstützung für RISC-V-Architektur Yunfeng ist von Alibaba zurückgetreten und plant, in Zukunft unabhängige Spiele für Windows-Plattformen zu produzierenDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.