
Erfahren Sie, wie Sie die Speichernutzung von MySQL-Verbindungen visualisieren.
Autor: Benjamin Dicken
Quelle dieses Artikels und des Covers: https://planetscale.com/blog/, übersetzt von der Axon Open Source Community.
Dieser Artikel umfasst etwa 3.000 Wörter und die Lektüre dauert voraussichtlich 10 Minuten.
Einführung
Bei der Betrachtung der Leistung einer Software gibt es typischerweise einen Kompromiss zwischen Zeit und Raum. Bei der Bewertung der MySQL-Abfrageleistung konzentrieren wir uns häufig auf die Ausführungszeit (oder Abfragelatenz) als Hauptindikator für die Abfrageleistung. Dies ist eine gute Metrik, da wir letztendlich so schnell wie möglich Abfrageergebnisse erhalten möchten.
Ich habe kürzlich einen Blog-Beitrag zum Thema „ How to Identify and Analyze Problematic MySQL Queries“ veröffentlicht , der sich auf die Messung schlechter Leistung in Bezug auf Ausführungszeit und Zeilenlesevorgänge konzentrierte. Der Speicherverbrauch wurde in dieser Diskussion jedoch weitgehend ignoriert.
Obwohl es möglicherweise nicht oft benötigt wird, verfügt MySQL auch über integrierte Mechanismen, die Aufschluss darüber geben, wie viel Speicher von Abfragen verwendet wird und wofür dieser Speicher verwendet wird. Schauen wir uns diese Funktion genauer an und sehen, wie Sie die Speichernutzung von MySQL-Verbindungen in Echtzeit überwachen können.
Speicherstatistiken
In MySQL gibt es viele Komponenten des Systems, die einzeln instrumentiert werden können. Die performance_schema.setup_instrumentsTabelle listet jede Komponente auf, und davon gibt es einige:
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
Diese Tabelle enthält viele Tools, die für die Speicheranalyse verwendet werden können. Um zu sehen, was verfügbar ist, versuchen Sie, aus der Tabelle auszuwählen und nach zu filtern memory/.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
Sie sollten Hunderte von Ergebnissen sehen. Jedes davon stellt eine andere Speicherkategorie dar und kann in MySQL einzeln erkannt werden. Einige dieser Kategorien enthalten einen kurzen Absatz, documentationder beschreibt, was diese Speicherkategorie darstellt oder wofür sie verwendet wird. Wenn Sie nur Speichertypen mit Werten ungleich Null sehen möchten documentation, können Sie Folgendes ausführen:
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
Jede dieser Speicherklassen kann mit verschiedenen Granularitäten abgetastet werden. Verschiedene Granularitätsebenen werden in mehreren Tabellen gespeichert:
SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- memory_summary_by_account_by_event_name: Speicherereignisse nach Konto zusammenfassen (Konto ist eine Kombination aus Benutzer und Host)
- memory_summary_by_host_by_event_name: Fasst Speicherereignisse auf Host-Granularität zusammen
- memory_summary_by_thread_by_event_name: Speicherereignisse mit MySQL-Thread-Granularität zusammenfassen
- memory_summary_by_user_by_event_name: Fasst Speicherereignisse auf Benutzerebene zusammen
- memory_summary_global_by_event_name: Globale Zusammenfassung der Speicherstatistiken
Beachten Sie, dass es keine spezifische Verfolgung der Speichernutzung auf jeder Abfrageebene gibt. Das bedeutet jedoch nicht, dass wir die Speichernutzung unserer Abfragen nicht analysieren können! Um dies zu erreichen, können wir die Speichernutzung jeder Verbindung überwachen, die die gewünschte Abfrage ausführt. Daher konzentrieren wir uns auf die Verwendung von Tabellen, memory_summary_by_thread_by_event_nameda eine praktische Zuordnung zwischen MySQL-Verbindungen und Threads besteht.
Finden Sie den Zweck der Verbindung
An dieser Stelle sollten Sie in der Befehlszeile zwei separate Verbindungen zum MySQL-Server einrichten. Die erste ist die Abfrage, die die Abfrage ausführt, für die Sie die Speichernutzung überwachen möchten. Der zweite wird zu Überwachungszwecken verwendet.
Führen Sie bei der ersten Verbindung diese Abfragen aus, um die Verbindungs-ID und Thread-ID abzurufen.
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
Dann holen Sie sich diese Werte. Natürlich kann Ihr Bild anders aussehen als das, was Sie hier sehen.
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
Führen Sie als Nächstes einige lang laufende Abfragen aus, für die Sie die Speichernutzung analysieren möchten. In diesem Beispiel werde ich eine große Operation aus einer Tabelle mit 100 Millionen Zeilen ausführen, was eine Weile dauern sollte, da aliases keinen Index für die SELECT-Spalte gibt:
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
Wechseln Sie nun während der Ausführung zu einer anderen Konsolenverbindung und führen Sie den folgenden Befehl aus, wobei Sie die Thread-ID durch die Thread-ID Ihrer Verbindung ersetzen:
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
Sie sollten ähnliche Ergebnisse sehen, wobei die Details stark von Ihrer Abfrage und Ihren Daten abhängen:
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
Dies gibt die Menge an Speicher an, die von jeder Kategorie beim Ausführen dieser Abfrage verwendet wird. Wenn Sie SELECT alias...diese Abfrage mehrmals ausführen, während Sie eine andere Abfrage ausführen, werden möglicherweise unterschiedliche Ergebnisse angezeigt, da die Speichernutzung der Abfrage während der gesamten Ausführung nicht unbedingt konstant ist. Jede Ausführung dieser Abfrage stellt zu einem bestimmten Zeitpunkt eine Stichprobe dar. Wenn wir also verstehen wollen, wie sich die Nutzung im Laufe der Zeit verändert, müssen wir viele Proben nehmen.
memory/sql/Filesort_buffer::sort_keysdocumentationfehlt in der Tabelle performance_schema.setup_instruments.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
Der Name weist jedoch darauf hin, dass es sich um den Speicher handelt, der zum Sortieren der Daten in der Datei verwendet wird. Dies ist sinnvoll, da der größte Teil der Kosten dieser Abfrage darin besteht, die Daten so zu sortieren, dass sie in absteigender Reihenfolge angezeigt werden können.
Erfassen Sie die Nutzung im Laufe der Zeit
Als nächstes müssen wir in der Lage sein, die Speichernutzung im Zeitverlauf zu messen. Dies ist für kurze Abfragen nicht besonders nützlich, da wir diese Abfrage nur einmal oder nur wenige Male während der Ausführung der Analyseabfrage ausführen können. Dies ist nützlicher für länger laufende Abfragen (Abfragen, die Sekunden oder Minuten dauern). Unabhängig davon sind dies die Arten von Abfragen, die wir analysieren möchten, da diese Abfragen wahrscheinlich den größten Teil des Speichers beanspruchen.
Dies kann vollständig in SQL implementiert und über gespeicherte Prozeduren aufgerufen werden. In diesem Fall verwenden wir jedoch ein separates Skript in Python, um die Überwachung bereitzustellen.
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
Dies ist ein einfacher erster Versuch für diese Art von Überwachungsskript. Zusammenfassend bewirkt dieser Code Folgendes:
- Rufen Sie die bereitgestellte Thread-ID zur Überwachung über die Befehlszeile ab
- Richten Sie eine Verbindung zur MySQL-Datenbank ein
- Führen Sie alle 250 ms eine Abfrage aus, um die 4 am häufigsten verwendeten Speicherkategorien abzurufen und den Messwert auszudrucken
Dies kann je nach Analysebedarf auf vielfältige Weise angepasst werden. Passen Sie beispielsweise die Häufigkeit der Pings an den Server an oder ändern Sie die Anzahl der pro Iteration aufgelisteten Speicherklassen. Das Ausführen dieses Befehls während der Ausführung einer Abfrage liefert die folgenden Ergebnisse:
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
Es ist großartig, hat aber einige Schwächen. Es ist schön, etwas zu sehen, das über die ersten vier Speichernutzungskategorien hinausgeht, aber wenn man diese Zahl erhöht, erhöht sich die Größe dieses ohnehin schon großen Ausgabe-Dumps. Es wäre schön, wenn es mit etwas Visualisierung eine einfachere Möglichkeit gäbe, die Speichernutzung auf einen Blick zu verstehen. Dies kann erreicht werden, indem das Skript die Ergebnisse in CSV oder JSON ausgibt und sie dann in den Visualizer lädt. Noch besser: Wir können Ergebnisse in Echtzeit darstellen, während die Daten einfließen. Dies bietet eine aktualisierte Ansicht und ermöglicht es uns, die Speichernutzung in Echtzeit zu beobachten, alles in einem Tool.
Speichernutzung grafisch darstellen
Um das Tool nützlicher zu machen und eine bessere Visualisierung zu ermöglichen, werden einige Änderungen vorgenommen.
- Der Benutzer gibt die Verbindungs-ID in der Befehlszeile an und das Skript ist für die Suche nach dem zugrunde liegenden Thread verantwortlich.
- Die Häufigkeit, mit der das Skript Speicherdaten anfordert, kann ebenfalls über die Befehlszeile konfiguriert werden.
- Diese
matplotlibBibliothek wird verwendet, um Visualisierungen der Speichernutzung zu generieren. Dies enthält ein Stapeldiagramm mit einer Legende, die die Kategorie mit der höchsten Speichernutzung anzeigt, und speichert die letzten 50 Proben.
Das ist ziemlich viel Code, der jedoch der Vollständigkeit halber hier aufgeführt ist.
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
Damit können wir die Ausführung von MySQL-Abfragen detailliert überwachen. Um es zu verwenden, rufen Sie zunächst die Verbindungs-ID der Verbindung ab, die Sie analysieren möchten:
SELECT CONNECTION_ID();
Anschließend wird durch Ausführen des folgenden Befehls die Überwachungssitzung gestartet:
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
Beim Ausführen von Abfragen für die Datenbank können wir den Anstieg der Speichernutzung beobachten und sehen, welche Kategorien am meisten zum Speicher beitragen.
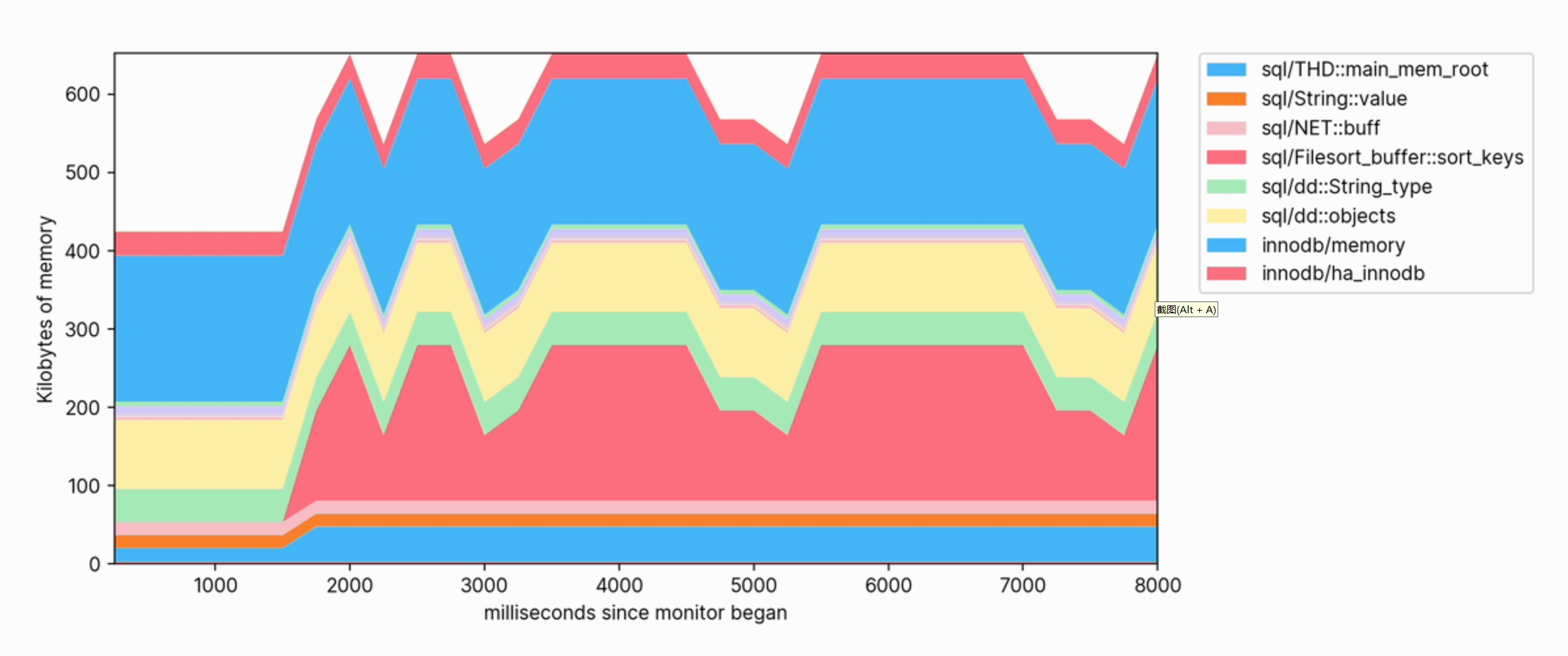
Diese Visualisierung hilft uns auch klar zu erkennen, welche Vorgänge Speicher verbrauchen. Das Folgende ist beispielsweise ein Ausschnitt des Speicherprofils, das zum Erstellen eines FULLTEXT-Index für eine große Tabelle verwendet wird:
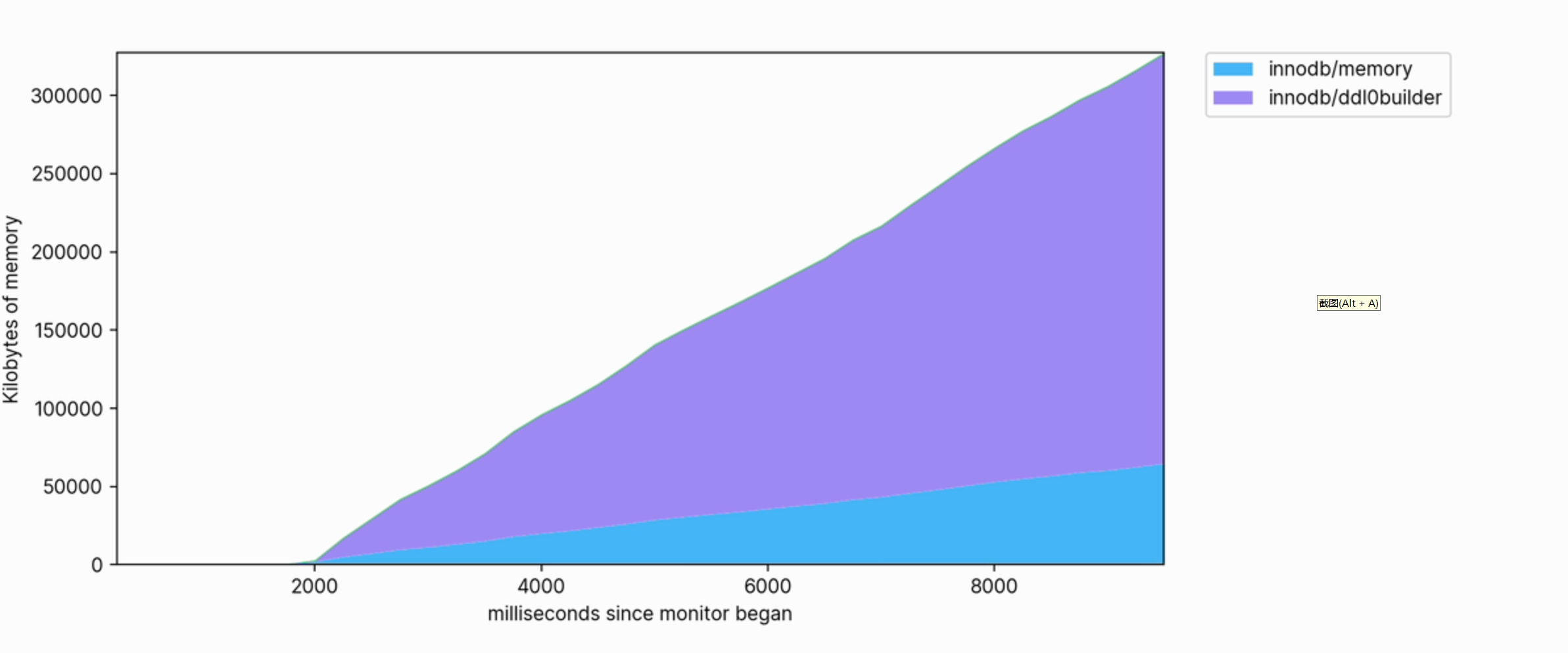
Die Speichernutzung ist groß und wächst weiter, sodass bei der Ausführung Hunderte von Megabyte verbraucht werden.
abschließend
Obwohl die Möglichkeit, detaillierte Informationen zur Speichernutzung zu erhalten, möglicherweise nicht oft benötigt wird, kann sie äußerst wertvoll sein, wenn eine detaillierte Abfrageoptimierung erforderlich ist. Dies kann aufdecken, wann und warum MySQL den Speicherdruck auf das System ausübt oder ob ein Speicherupgrade auf dem Datenbankserver erforderlich ist. MySQL bietet viele Grundelemente, auf deren Grundlage Sie Analysetools für Ihre Abfragen und Arbeitslasten entwickeln können.
Weitere technische Artikel finden Sie unter: https://opensource.actionsky.com/
Über SQLE
SQLE ist eine umfassende SQL-Qualitätsmanagementplattform, die die SQL-Prüfung und -Verwaltung von der Entwicklung bis zur Produktionsumgebung abdeckt. Es unterstützt gängige Open-Source-, kommerzielle und inländische Datenbanken, bietet Prozessautomatisierungsfunktionen für Entwicklung, Betrieb und Wartung, verbessert die Online-Effizienz und verbessert die Datenqualität.
SQLE erhalten
| Typ | Adresse |
|---|---|
| Repository | https://github.com/actiontech/sqle |
| dokumentieren | https://actiontech.github.io/sqle-docs/ |
| Neuigkeiten veröffentlichen | https://github.com/actiontech/sqle/releases |
| Entwicklungsdokumentation für das Datenaudit-Plug-in | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |