
In Suchanwendungen ist die herkömmliche Schlüsselwortsuche seit jeher die Hauptsuchmethode. Sie eignet sich für exakt passende Abfrageszenarien und bietet eine geringe Latenz und eine gute Interpretierbarkeit der Ergebnisse. Allerdings berücksichtigt die Schlüsselwortsuche keine kontextbezogenen Informationen und kann zu irrelevanten Ergebnissen führen. In den letzten Jahren erfreut sich die semantische Suche, eine auf Vektorabruftechnologie basierende Suchverbesserungstechnologie, immer größerer Beliebtheit. Sie verwendet Modelle des maschinellen Lernens, um Datenobjekte (Text, Bilder, Audio und Video usw.) in Vektoren umzuwandeln Wenn das verwendete Modell für die Problemdomäne von hoher Relevanz ist, kann es häufig den Kontext und die Suchabsicht besser verstehen und so die Relevanz der Suchergebnisse verbessern In der Problemdomäne wird der Effekt stark reduziert.
Sowohl die Schlüsselwortsuche als auch die semantische Suche haben offensichtliche Vor- und Nachteile. Kann also die Gesamtrelevanz der Suche durch die Kombination ihrer Vorteile verbessert werden? Die Antwort ist, dass einfache arithmetische Kombinationen aus zwei Hauptgründen nicht die erwarteten Ergebnisse erzielen können:
-
Erstens liegen die Bewertungen verschiedener Abfragetypen nicht in derselben vergleichbaren Dimension, sodass einfache arithmetische Berechnungen nicht direkt durchgeführt werden können.
-
Zweitens liegen die Bewertungen in einem verteilten Abrufsystem normalerweise auf Shard-Ebene und die Bewertungen aller Shards müssen global normalisiert werden.
Zusammenfassend müssen wir einen idealen Abfragetyp finden, um diese Probleme zu lösen. Er kann jede Abfrageklausel einzeln ausführen, Abfrageergebnisse auf Shard-Ebene sammeln und schließlich die Bewertungen aller Abfragen normalisieren und zusammenführen, um das Endergebnis zurückzugeben ist die Hybrid Search-Lösung.
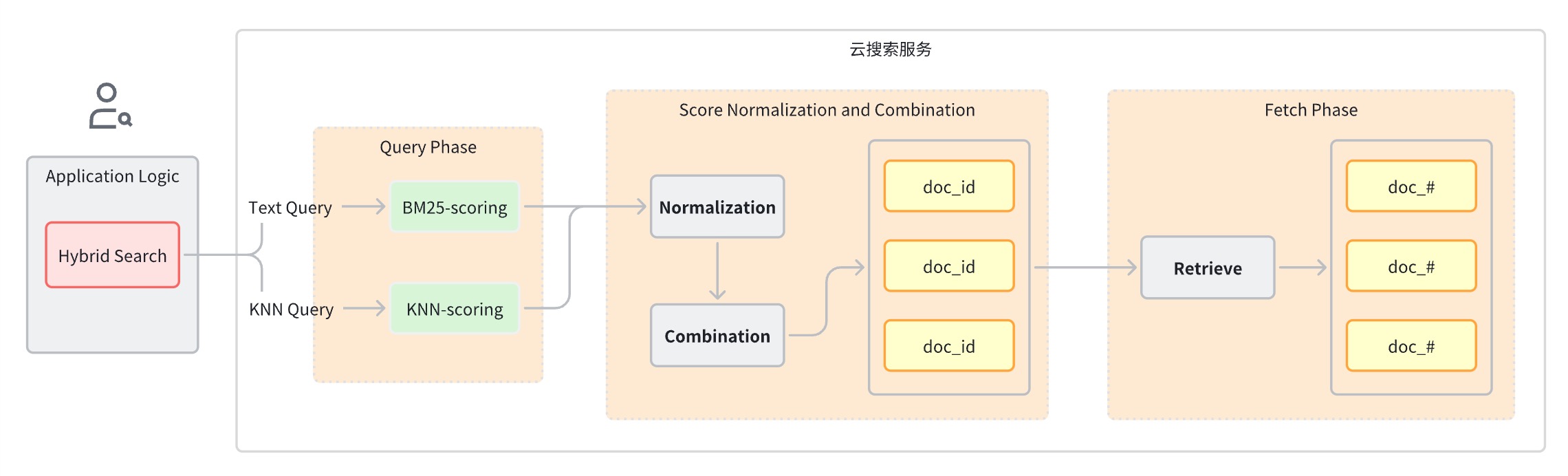
Normalerweise lässt sich eine Hybrid-Suchanfrage in die folgenden Schritte unterteilen:
-
Abfragephase: Verwenden Sie gemischte Abfrageklauseln für die Schlüsselwortsuche und die semantische Suche.
-
Score-Normalisierungs- und Zusammenführungsphase, die auf die Abfragephase folgt.
-
Da jeder Abfragetyp einen anderen Bewertungsbereich bereitstellt, führt diese Stufe eine Normalisierungsoperation für die Bewertungsergebnisse jeder Abfrageklausel durch. Die unterstützten Normalisierungsmethoden sind min_max, l2 und rrf.
-
Um die normalisierten Bewertungen zu kombinieren, umfassen die Kombinationsmethoden arithmetic_mean,symmetric_mean und harmonisch_mean.
-
-
Dokumente werden basierend auf den kombinierten Bewertungen neu geordnet und an den Benutzer zurückgegeben.
Umsetzungsideen
Aus der Einführung der vorherigen Grundsätze können wir erkennen, dass zur Implementierung einer Hybrid-Retrieval-Anwendung mindestens diese grundlegenden technischen Einrichtungen erforderlich sind.
-
Volltextsuchmaschine
-
Vektorsuchmaschine
-
Modell für maschinelles Lernen für die Vektoreinbettung
-
Datenpipeline, die Text, Audio, Video und andere Daten in Vektoren umwandelt
-
Fusionssortierung
Die Cloud-Suche von Volcano Engine basiert auf den Open-Source-Projekten Elasticsearch und OpenSearch. Sie unterstützt seit dem ersten Tag vollständige und ausgereifte Funktionen zum Abrufen von Texten und Vektoren. Gleichzeitig wurden auch eine Reihe funktionaler Iterationen durchgeführt und Weiterentwicklungen für Hybrid-Suchszenarien, die eine sofort einsatzbereite Hybrid-Suchlösung bieten. In diesem Artikel wird am Beispiel einer Bildsuchanwendung erläutert, wie mithilfe der Cloud-Suchdienstlösung Volcano Engine schnell eine hybride Suchanwendung entwickelt werden kann.

Der End-to-End-Prozess lässt sich wie folgt zusammenfassen:
-
Konfigurieren und erstellen Sie verwandte Objekte
-
Aufnahmepipeline: Unterstützt den automatischen Aufruf des Modells, um Bildkonvertierungsvektoren im Index zu speichern
-
Suchpipeline: Unterstützt die automatische Konvertierung von Textabfrageanweisungen in Vektoren zur Ähnlichkeitsberechnung
-
k-NN-Index: der Index, in dem der Vektor gespeichert ist
-
-
Schreiben Sie die Bilddatensatzdaten in die OpenSearch-Instanz, und OpenSearch ruft automatisch das Modell für maschinelles Lernen auf, um den Text in einen Einbettungsvektor umzuwandeln.
-
Wenn der Client eine hybride Suchabfrage initiiert, ruft OpenSearch das maschinelle Lernmodell auf, um die eingehende Abfrage in einen Einbettungsvektor umzuwandeln.
-
OpenSearch führt eine hybride Suchanfragenverarbeitung durch, kombiniert Keyword Search- und Semantic Search-Scores und gibt Suchergebnisse zurück.
Planen Sie einen tatsächlichen Kampf
Umweltvorbereitung
-
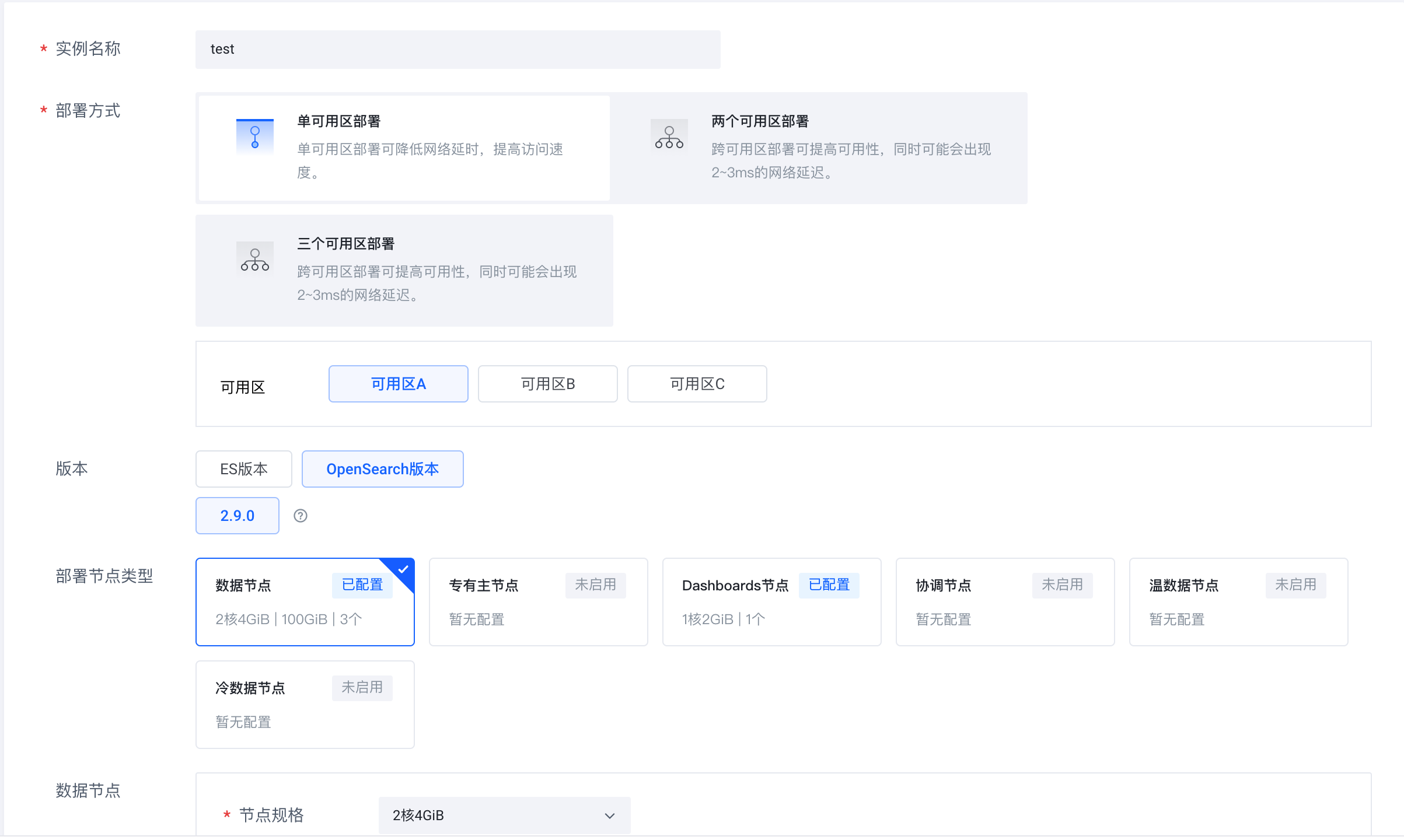
Melden Sie sich beim Cloud-Suchdienst Volcano Engine (https://console.volcengine.com/es) an, erstellen Sie einen Instanzcluster und wählen Sie OpenSearch 2.9.0 als Version aus.
-
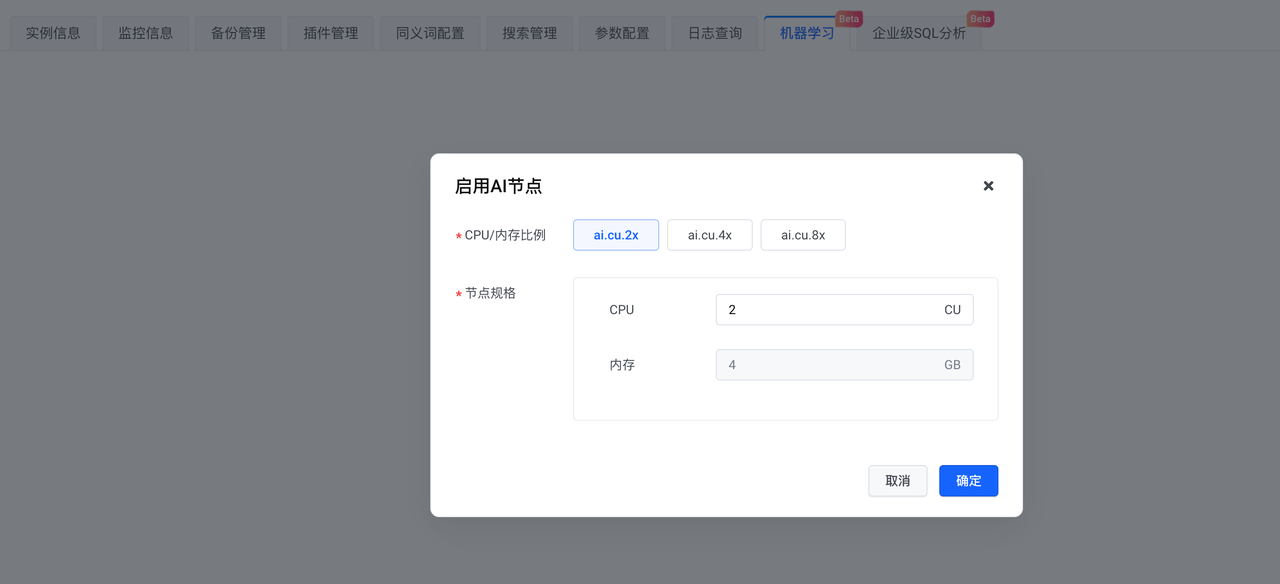
Nachdem die Instanz erstellt wurde, aktivieren Sie den AI-Knoten.
-
Bei der Modellauswahl können Sie Ihr eigenes Modell erstellen oder ein öffentliches Modell auswählen. Hier wählen wir das öffentliche Modell aus . Klicken Sie nach Abschluss der Konfiguration auf Jetzt starten .
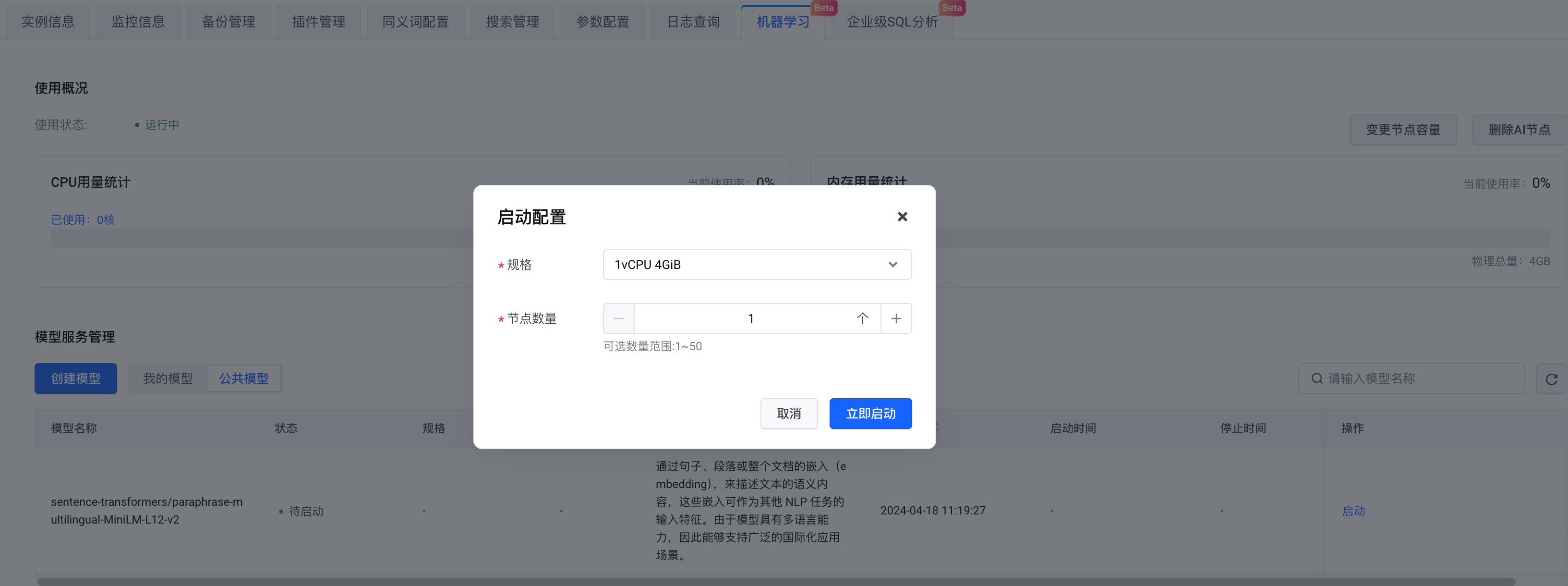
Zu diesem Zeitpunkt sind die OpenSearch-Instanz und der maschinelle Lerndienst, auf dem die Hybridsuche basiert, bereit.
Datensatzvorbereitung
Verwenden Sie den Amazon Berkeley Objects-Datensatz (https://registry.opendata.aws/amazon-berkeley-objects/). Der Datensatz muss nicht lokal heruntergeladen werden und wird über die Codelogik direkt auf OpenSearch hochgeladen Weitere Informationen finden Sie unten im Codeinhalt.
Schritte
Installieren Sie Python-Abhängigkeiten
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonStellen Sie eine Verbindung zu OpenSearch her
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
Geben Sie die OpenSearch-Linkadresse sowie die Informationen zu Benutzername und Passwort ein. model_remote_config ist die Verbindungskonfiguration des Remote-Machine-Learning-Modells, die in den Modellaufrufinformationen angezeigt werden kann . Kopieren Sie alle remote_config- Konfigurationen in den Aufrufinformationen nach model_remote_config .
-
Laden Sie im Abschnitt „Instanzinformationen“ > „Dienstzugriff“ das Zertifikat in das aktuelle Verzeichnis herunter.
-
Es werden ein Indexname, eine Pipeline-ID und eine Suchpipeline-ID angegeben.
Erstellen Sie eine Aufnahmepipeline
Erstellen Sie eine Ingest-Pipeline, geben Sie das zu verwendende maschinelle Lernmodell an, konvertieren Sie die angegebenen Felder in Vektoren und betten Sie sie wieder ein. Konvertieren Sie
das Beschriftungsfeld
wie folgt in einen Vektor und speichern Sie ihn in
caption_embedding
.
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)Erstellen Sie eine Suchpipeline
Erstellen Sie die für die Abfrage erforderliche Pipeline und konfigurieren Sie das Remote-Modell.
Unterstützte Normalisierungsmethoden und gewichtete Summenmethoden:
-
Normalisierungsmethode:
min_max,l2,rrf -
Methode der gewichteten Summierung:
arithmetic_mean,geometric_mean,harmonic_mean
Hier wird die rrf-Normalisierungsmethode ausgewählt.
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)Erstellen Sie einen k-NN-Index
-
Konfigurieren Sie die vorab erstellte Ingest-Pipeline im Feld index.default_pipeline .
-
Konfigurieren Sie gleichzeitig die Eigenschaften und setzen Sie caption_embedding auf knn_vector. Hier verwenden wir hnsw in faiss.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)Datensatz laden
Lesen Sie den Datensatz in den Speicher und filtern Sie einige der Daten heraus, die verwendet werden müssen.
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()Datensatz hochladen
Laden Sie den Datensatz auf Opensearch hoch und übergeben Sie image_url und caption für jedes Datenelement. Es ist nicht erforderlich,
caption_embedding
zu übergeben , es wird automatisch durch das Remote-Machine-Learning-Modell generiert.
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))Hybride Suchanfrage
Nehmen Sie als Beispiel die Abfrage von
Schuhen
. Die Abfrage enthält zwei Abfrageklauseln, eine
match
Abfrage und eine
remote_neural
Abfrage. Geben Sie bei der Abfrage die zuvor erstellte Suchpipeline als Abfrageparameter an. Die Suchpipeline wandelt den eingehenden Text in einen Vektor um und speichert ihn im Feld
caption_embedding für nachfolgende Abfragen.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])Hybride Suchanzeige

Oben wird die Bildsuchanwendung als Beispiel verwendet, um den praktischen Prozess zur schnellen Entwicklung einer hybriden Suchanwendung mithilfe der Cloud-Suchdienstlösung Volcano Engine vorzustellen. Melden Sie sich bei der Volcano Engine-Konsole an, um sie zu bedienen.
Der Volcano Engine-Cloud-Suchdienst ist mit Elasticsearch, Kibana und anderen häufig verwendeten Open-Source-Plug-Ins kompatibel. Er bietet den Abruf mehrerer Bedingungen, Statistiken und Berichte für strukturierten und unstrukturierten Text und ermöglicht eine elastische Bereitstellung mit einem Klick Skalierung, vereinfachter Betrieb und Wartung sowie schnelle Erstellung von Protokollanalysen, Informationsabrufanalysen und anderen Geschäftsfunktionen.
{{o.name}}
{{m.name}}