

Obwohl sich externe Caches hervorragend zur Reduzierung der Latenz eignen, verursachen sie oft mehr Probleme als Vorteile. Hier erfahren Sie, wie Sie dieses Problem beheben können.
Übersetzt aus „Warum und wie Teams externe Datenbank-Caches ersetzen“ von Felipe Cardeneti Mendes.
Teams ziehen häufig externes Caching in Betracht, wenn eine vorhandene Datenbank das erforderliche Service Level Agreement (SLA) nicht erfüllen kann. Es handelt sich hierbei um eine ausgesprochen leistungsorientierte Entscheidung. Das Platzieren eines externen Caches vor der Datenbank erfolgt häufig, um suboptimale Latenzzeiten auszugleichen, die durch verschiedene Faktoren verursacht werden (z. B. ineffiziente Datenbankinterna, Treibernutzung, Infrastrukturauswahl, Verkehrsspitzen usw.).
Caching scheint eine schnelle und einfache Lösung zu sein, da die Bereitstellung ohne großen Aufwand implementiert werden kann und ohne dass erhebliche Kosten für die Erweiterung der Datenbank , die Neugestaltung des Datenbankschemas oder sogar tiefgreifendere Technologieumstellungen anfallen. Allerdings ist externes Caching nicht so einfach, wie oft gesagt wird. Sie können eine der problematischeren Komponenten einer verteilten Anwendungsarchitektur sein.
In einigen Fällen ist dies ein notwendiges Übel, beispielsweise wenn Sie aufgrund langwieriger und teurer Berechnungen häufig auf transformierte Daten zugreifen müssen und Sie alle anderen Möglichkeiten ausprobiert haben, um die Latenz zu reduzieren. Doch in vielen Fällen lohnt sich der Leistungsgewinn einfach nicht. Sie lösen ein Problem, schaffen aber andere.
Hier sind die oft übersehenen Risiken im Zusammenhang mit externem Caching und wie drei Teams Leistungssteigerungen und Kosteneinsparungen erzielten, indem sie ihre Kerndatenbank und externes Caching durch eine einzige Lösung ersetzten. Spoiler: Sie verwenden ScyllaDB, eine Hochleistungsdatenbank, die durch die Nutzung eines speziellen internen Caches eine verbesserte Long-Tail-Latenz erreicht .
Warum nicht zwischenspeichern?
Bei ScyllaDB arbeiten wir mit unzähligen Teams zusammen, die sich mit den Kosten, dem Aufwand und den Einschränkungen herkömmlicher Versuche zur Verbesserung der Datenbankleistung auseinandersetzen. Hier sind die Hauptschwierigkeiten, auf die Teams stoßen, wenn sie ihren Datenbanken externes Caching vorschalten.
Externes Caching erhöht die Latenz
Ein separater Cache bedeutet einen weiteren Sprung auf dem Weg. Wenn das Caching die Datenbank umgibt, erfolgt der erste Zugriff auf der Cache-Ebene. Befinden sich die Daten nicht im Cache, wird die Anfrage an die Datenbank gesendet. Dies erhöht die Latenz des ohnehin schon langsamen Pfads zu nicht zwischengespeicherten Daten. Man könnte behaupten, dass die zusätzliche Latenz keine Rolle spielt, wenn der gesamte Datensatz in den Cache passt. Sofern Ihr Datensatz jedoch nicht recht klein ist, erhöht die Speicherung des gesamten Datenbestands im Speicher die Kosten erheblich, sodass die Kosten für die meisten Unternehmen unerschwinglich sind.
Für externes Caching fallen zusätzliche Kosten an
Caching bedeutet teures DRAM, was bedeutet, dass die Kosten pro Gigabyte höher sind als bei Solid-State-Festplatten. (Weitere Einzelheiten hierzu finden Sie im Vortrag von Danny Kopping von Grafana auf P99 CONF .) Anstatt eine völlig separate Infrastruktur für das Caching bereitzustellen, ist es oft besser, vorhandenen Datenbankspeicher zu verwenden oder ihn sogar zu vergrößern, um den internen Cache aufzunehmen. Bei richtiger Größe können moderne Datenbank-Caches genauso effizient sein wie herkömmliche In-Memory-Caching-Lösungen. Datenbanken optimieren häufig den I/O-Zugriff auf Flash-Speicher gut, wenn die Größe des Arbeitssatzes zu groß ist, um in den Speicher zu passen. Daher ist eine separate Datenbank (ohne externen Cache) die bevorzugte und kostengünstigere Option.
Externes Caching verringert die Verfügbarkeit
Keine Caching-Hochverfügbarkeitslösung kann mit der Datenbank selbst mithalten. Moderne verteilte Datenbanken verfügen über mehrere Replikate; sie sind außerdem topologie- und geschwindigkeitsbewusst und können mehrere Ausfälle ohne Datenverlust überstehen.
Ein gängiges Replikationsmuster besteht beispielsweise aus drei lokalen Replikaten, wodurch Lesevorgänge häufig auf diese Replikate verteilt werden können, um den internen Caching-Mechanismus der Datenbank effektiv zu nutzen. Stellen Sie sich einen Cluster mit neun Knoten und einem Replikationsfaktor von drei vor: Im Wesentlichen enthält jeder Knoten etwa ein Drittel Ihrer gesamten Datensatzgröße. Da Anforderungen auf verschiedene Replikate verteilt werden, erhalten Sie mehr Platz zum Zwischenspeichern der Daten, sodass kein externes Zwischenspeichern erforderlich ist. Wenn umgekehrt der externe Cache kurz vor einer großen Anzahl kalter Anfragen einen Eintrag ungültig macht, kann die Verfügbarkeit für einen bestimmten Zeitraum beeinträchtigt sein, da die Datenbank diese Daten nicht in ihrem internen Cache hat (mehr dazu weiter unten).
Caches verfügen häufig nicht über Hochverfügbarkeitseigenschaften und können aufgrund ihrer Heuristik leicht ausfallen oder Datensätze ungültig machen. Teilausfälle kommen häufiger vor und sind hinsichtlich der Konsistenz noch schlimmer. Wenn der Cache unweigerlich ausfällt, wird die Datenbank mit einer Flut ungebremster Abfragen heimgesucht und kann Ihr SLA zerstören. Darüber hinaus kann der Cache selbst, selbst wenn er über einige Hochverfügbarkeitsfunktionen verfügt, die Behandlung solcher Fehler nicht mit der vorgelagerten persistenten Datenbank koordinieren. Fazit : Verlassen Sie sich auf die Datenbank, anstatt Ihr Latenz-SLA vom Cache abhängig zu machen.
Anwendungskomplexität – Ihre Anwendung muss mehr Situationen bewältigen
Externes Caching führt zu Anwendungs- und Betriebskomplexität. Sobald Sie über einen externen Cache verfügen, liegt es in Ihrer Verantwortung, den Cache mit der Datenbank auf dem neuesten Stand zu halten. Unabhängig von Ihrer Caching-Strategie (z. B. Durchschreiben, Cache-Umgehung usw.) wird es Randfälle geben, in denen Ihr Cache möglicherweise nicht mehr mit der Datenbank synchronisiert ist, und Sie müssen diese Situationen während der Anwendungsentwicklung berücksichtigen. Ihre Client-Einstellungen (z. B. Failover-, Wiederholungs- und Timeout-Richtlinien) müssen mit den Eigenschaften des Caches und der Datenbank übereinstimmen, damit sie funktionieren, wenn der Cache nicht verfügbar ist oder ausfällt. Typischerweise sind solche Szenarien schwierig zu testen und umzusetzen.
Der externe Cache beschädigt den Datenbankcache
Moderne Datenbanken verfügen über eingebettete Caches und komplexe Strategien zu deren Verwaltung. Wenn Sie einen Cache vor der Datenbank platzieren, treffen die meisten Leseanforderungen nur den externen Cache und die Datenbank speichert diese Objekte nicht in ihrem Speicher. Dadurch wird der Datenbankcache ungültig. Wenn die Anfrage schließlich die Datenbank erreicht, ist ihr Cache kalt und die Antwort kommt größtenteils von der Festplatte. Infolgedessen kann der Roundtrip vom Cache zur Datenbank und zurück zur Anwendung die Latenz erhöhen.
Externes Caching kann die Sicherheitsrisiken erhöhen
Externes Caching fügt Ihrer Infrastruktur eine völlig neue Angriffsfläche hinzu. Verschlüsselung, Isolierung und Zugriffskontrollen für im Cache abgelegte Daten können sich von denen auf der Datenbankebene selbst unterscheiden.
Beim externen Caching werden Datenbankwissen und Datenbankressourcen ignoriert
Die Datenbank ist komplex und für spezielle E/A-Workloads im System konzipiert. Viele Abfragen greifen auf dieselben Daten zu, und ein bestimmter Teil der Arbeitssatzgröße kann im Speicher zwischengespeichert werden, um Festplattenzugriff zu sparen. Eine gute Datenbank sollte über eine komplexe Logik verfügen, um zu entscheiden, welche Objekte, Indizes und Zugriffe sie zwischenspeichern soll. Die Datenbank sollte außerdem über eine Räumungsrichtlinie verfügen, um zu bestimmen, wann neue Daten vorhandene (ältere) Cache-Objekte ersetzen sollen.
Ein Beispiel ist scanresistentes Caching. Beim Scannen großer Datenmengen, wie z. B. Scans großer Bereiche oder vollständiger Tabellen, wird eine große Anzahl von Objekten von der Festplatte gelesen. Die Datenbank kann erkennen, dass es sich um einen Scan (und nicht um eine normale Abfrage) handelt, und sich dafür entscheiden, ihre Objekte aus ihrem internen Cache fernzuhalten. Beim externen Caching (das der Durchleserichtlinie folgt) wird die Ergebnismenge jedoch wie jede andere Ergebnismenge behandelt und versucht, die Ergebnisse zwischenzuspeichern. Die Datenbank synchronisiert automatisch zwischengespeicherte Inhalte mit der Festplatte basierend auf den eingehenden Anforderungsraten, sodass Benutzer und Entwickler nichts tun müssen, um Leistung und Konsistenz bei der Suche nach kürzlich geschriebenen Daten sicherzustellen. Wenn Ihre Datenbank aus irgendeinem Grund nicht schnell genug reagiert, bedeutet das:
- Cache-Konfigurationsfehler.
- Nicht genügend RAM für den Cache.
- Die Größe des Arbeitssatzes und das Anforderungsmuster sind nicht für das Caching geeignet.
- Die Implementierung des Datenbankcaches ist schlecht.
Bessere Option: Lassen Sie die Datenbank damit umgehen
Wie können Sie Ihr SLA einhalten, ohne das Risiko einer externen Datenbank-Zwischenspeicherung einzugehen? Viele Teams stellen fest, dass sie durch die Migration zu einer schnelleren Datenbank (z. B. ScyllaDB) und die Verwendung eines dedizierten internen Caches ihre Latenz-SLAs mit weniger Aufwand und geringeren Kosten einhalten können. Natürlich können die Ergebnisse je nach Arbeitsbelastungsmerkmalen und technischen Anforderungen variieren. Aber was möglich ist, bedenken Sie, was diese Teams erreichen können.
SecurityScorecard erreicht eine Latenzreduzierung von 90 % mit jährlichen Einsparungen von 1 Million US-Dollar
SecurityScorecard zielt darauf ab, die Welt sicherer zu machen, indem es die Art und Weise verändert, wie Tausende von Organisationen Cybersicherheit verstehen, abschwächen und darüber kommunizieren. Seine Bewertungsplattform ist ein objektives, datengesteuertes und quantifizierbares Maß für die gesamte Cybersicherheit und Cyber-Risiken eines Unternehmens.
Die bisherige Datenarchitektur des Teams leistete eine Zeit lang gute Dienste, konnte jedoch mit dem Wachstum nicht Schritt halten. Ihre Plattform-API fragt einen von drei Datenspeichern ab: Redis (für schnellere Suchvorgänge von 12 Millionen Scorecards), Aurora (für die Speicherung von 4 Milliarden Messstatistiken über Knoten hinweg) oder das verteilte Hadoop-Dateisystem Presto Cluster on (für komplexe SQL-Abfragen zu historischen Ergebnissen). ).
Wenn Daten und Anfragen wachsen, entstehen Herausforderungen. Bei Aurora und Presto kommt es bei hohem Durchsatz zu Latenzspitzen. Die größtmögliche Instanz von Redis reichte immer noch nicht aus und man wollte die Komplexität des Redis-Clusters nicht nutzen.
Um die Latenz im neuen Maßstab zu reduzieren, der für ein schnelles Geschäftswachstum erforderlich ist, wandte sich das Team an ScyllaDB Cloud und entwickelte eine neue Scoring-API, um weniger latenzempfindliche Anfragen an Presto- und S3-Speicher weiterzuleiten. Hier ist eine Visualisierung dieser Architektur, und sie ist ziemlich einfach:
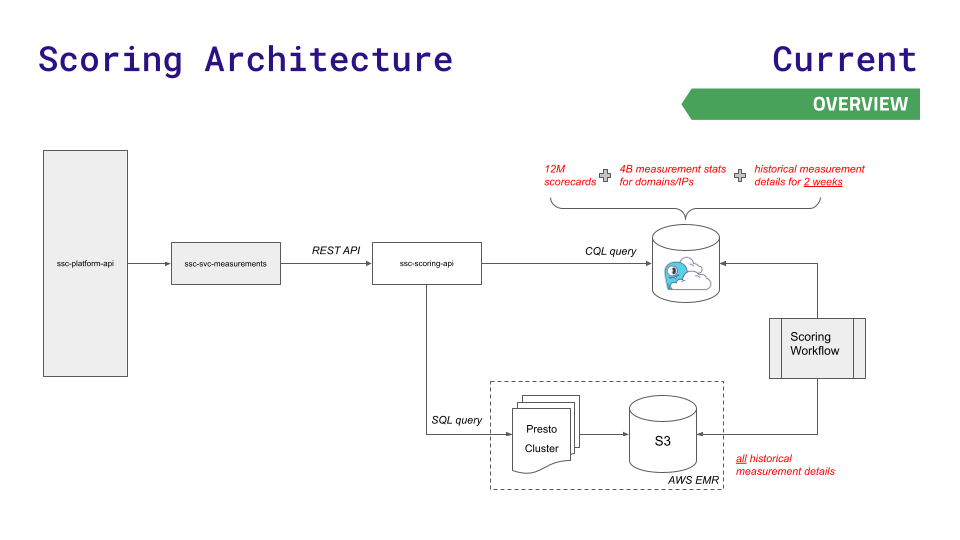
Dieser Schritt führte zu:
- 90 % geringere Latenz für die meisten Service-Endpunkte
- 80 % Reduzierung der Produktionsvorfälle im Zusammenhang mit der Leistung von Presto/Aurora
- Jährliche Einsparungen bei den Infrastrukturkosten in Höhe von 1 Million US-Dollar
- Die Verarbeitungsgeschwindigkeit der Datenpipeline wurde um 30 % erhöht.
- Verbessern Sie das Kundenerlebnis erheblich
[Lesen Sie mehr über SecurityScorecard-Anwendungsfälle]
IMVU reduziert die Redis-Kosten um das Hundertfache
IMVU ist eine beliebte soziale Community, die es Menschen auf der ganzen Welt ermöglicht, mithilfe von 3D-Avataren auf Desktops, Tablets und Mobilgeräten zu interagieren. Um den wachsenden Skalierungsanforderungen gerecht zu werden, entschied IMVU, dass es eine leistungsfähigere Lösung als seine bisherige Datenbankarchitektur (MySQL und Memcached vor Redis) benötigte. Das Team suchte nach etwas, das einfacher zu konfigurieren, einfacher zu skalieren und (bei Erfolg) einfacher zu skalieren ist.
„Redis war großartig für die Prototyping-Fähigkeiten, aber als wir es tatsächlich eingeführt hatten, waren die Kosten kaum mehr zu rechtfertigen“, sagte Ken Rudy, leitender Softwareentwickler bei IMVU. „ScyllaDB ist so optimiert, dass die erforderlichen Daten im Speicher und alles andere auf der Festplatte bleiben. Mit ScyllaDB können wir die gleiche Reaktionsfähigkeit über das Hundertfache der Skalierung beibehalten, die Redis bewältigen kann.“
Comcast nutzt jährliche Einsparungen von 2,5 Millionen US-Dollar, um die Long-Tail-Latenz um 95 % zu reduzieren
Comcast ist ein globales Medien- und Technologieunternehmen mit drei Hauptgeschäftsfeldern: Comcast Cable, einer der größten Anbieter von Video-, Hochgeschwindigkeits-Internet- und Telefongesprächen für Privatkunden in den Vereinigten Staaten; Der Xfinity-Dienst von Comcast bedient 15 Millionen Haushalte mit mehr als 2 Milliarden API-Aufrufen (Lesen/Schreiben) und mehr als 200 Millionen neuen Objekten pro Tag. In sieben Jahren hat sich das Programm von der Unterstützung von 30.000 Geräten auf über 31 Millionen Geräte ausgeweitet.
Die lange Latenzzeit von Cassandra erwies sich angesichts der schnell wachsenden Größe des Unternehmens als inakzeptabel. Um die Latenzprobleme von Cassandra vor Benutzern zu verbergen, platzierte das Team 60 Cache-Server vor seiner Datenbank. Die Konsistenz dieser Caching-Ebene mit der Datenbank zu gewährleisten, bereitet Administratoren große Probleme. Da der Cache und die zugehörige Infrastruktur zwischen Rechenzentren repliziert werden müssen, muss Comcast den Cache aktiv halten. Sie implementierten einen Cache-Wärmer, der das Schreibvolumen überprüfte und dann die Daten zwischen Rechenzentren kopierte.
Comcast wandte sich schnell an ScyllaDB, nachdem es mit dem Overhead dieses Ansatzes zu kämpfen hatte. ScyllaDB wurde entwickelt, um Latenzspitzen durch seinen internen Caching-Mechanismus zu minimieren. Dadurch kann Comcast externe Caching-Ebenen eliminieren und ein einfaches Framework bereitstellen, in dem Datendienste direkt mit Datenspeichern verbunden werden. Comcast konnte 962 Cassandra-Knoten durch nur 78 ScyllaDB-Knoten ersetzen. Sie verbesserten die allgemeine Verfügbarkeit und Leistung und eliminierten gleichzeitig 60 Cache-Server vollständig. Ergebnisse: P99, P999 und P9999 reduzierten die Latenz um 95 % und konnten doppelt so viele Anfragen verarbeiten – bei Betriebskosten von 60 %. Dadurch konnten sie letztendlich 2,5 Millionen US-Dollar pro Jahr an Infrastrukturkosten und Personalaufwand einsparen.
Abschluss
Während externe Caches großartige Begleiter zur Reduzierung der Latenz sind (z. B. zur Bereitstellung statischer Inhalte und personalisierter Daten, die keinerlei Persistenz erfordern), verursachen sie häufig mehr Probleme als Vorteile, wenn sie vor der Datenbank platziert werden.
Zu den wichtigsten Kompromissen gehören erhöhte Kosten, erhöhte Anwendungskomplexität, zusätzliche Roundtrips zur Datenbank und zusätzliche Sicherheitsoberflächen. Durch das Überdenken bestehender Caching-Strategien und den Wechsel zu einer modernen Datenbank, die in großem Maßstab vorhersehbare niedrige Latenzzeiten bietet, können Teams ihre Infrastruktur vereinfachen und Kosten minimieren. Gleichzeitig können sie ihre SLAs weiterhin einhalten, ohne den zusätzlichen Aufwand und die Komplexität externer Zwischenspeicherung.
Wie viel Umsatz kann ein unbekanntes Open-Source-Projekt bringen? Das chinesische KI-Team von Microsoft hat zusammengepackt und ist mit Hunderten von Menschen in die USA gegangen. Huawei gab offiziell bekannt, dass Yu Chengdongs Jobwechsel an der „FFmpeg-Säule der Schande“ festgenagelt wurden vor, aber heute muss er uns danken – Tencent QQ Video rächt seine vergangene Demütigung? Die Open-Source-Spiegelseite der Huazhong University of Science and Technology ist offiziell für den externen Zugriff geöffnet. Bericht: Django ist immer noch die erste Wahl für 74 % der Entwickler. Zed-Editor hat Fortschritte bei der Linux-Unterstützung gemacht brachte die Nachricht: Nachdem er von einem Untergebenen herausgefordert wurde, wurde der technische Leiter wütend und unhöflich, wurde entlassen und schwanger. Die Mitarbeiterin von Alibaba Cloud veröffentlicht offiziell Tongyi Qianwen 2.5. Microsoft spendet 1 Million US-Dollar an die Rust FoundationDieser Artikel wurde zuerst auf Yunyunzhongsheng ( https://yylives.cc/ ) veröffentlicht, jeder ist herzlich willkommen.