

Gäste teilen:
Yang Linsan-Huixi-Geheimdienst
Über Huixi Intelligence:
Huixi Intelligence ist ein 2022 gegründetes Start-up-Unternehmen, das Chips für autonomes Fahren herstellt. Das Unternehmen hat sich dem Aufbau einer innovativen Plattform für intelligente fahrzeuginterne Datenverarbeitung verschrieben und bietet hochwertige intelligente Fahrchips, benutzerfreundliche offene Werkzeugketten und Full-Stack-Lösungen für autonomes Fahren, um Automobilherstellern dabei zu helfen, eine qualitativ hochwertige und effiziente Massenproduktion autonomen Fahrens zu erreichen und Bereitstellung sowie den Aufbau kostengünstiger, groß angelegter und automatisierter Iterationsfunktionen, die im datengesteuerten Zeitalter führend im High-End-Smart-Travel sind.
Teilen Sie die Gliederung:
- Wie verwende ich Alluxio in einem Startup?
- Der Prozess der Nutzung von Alluxio von 0 bis 1 (Forschung, Bereitstellung und Produktion).
- Praktischer Erfahrungsaustausch.
Im Folgenden finden Sie die Volltextversion des geteilten Inhalts
Thema teilen:
„Anwendung und Einsatz von Alluxio im Modelltraining für autonomes Fahren“
Geschlossener Datenkreislauf für autonomes Fahren
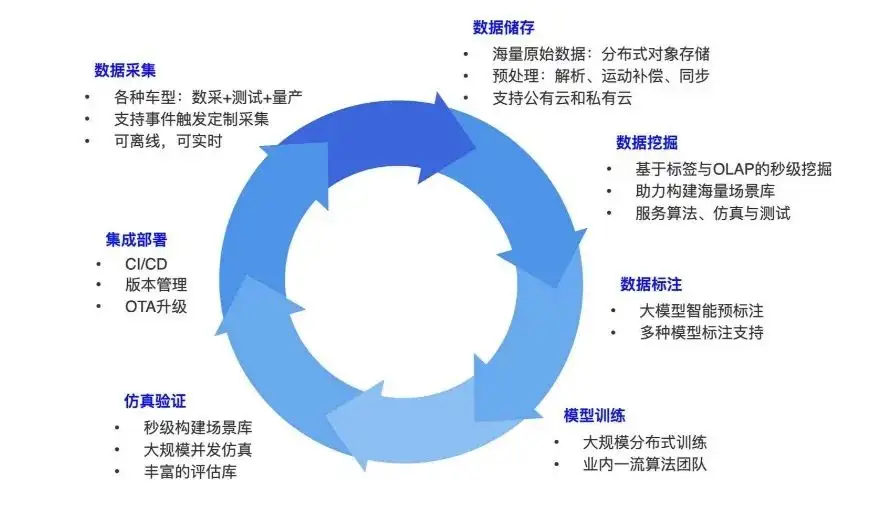
Lassen Sie mich zunächst erläutern, wie man beim autonomen Fahren einen geschlossenen Datenkreislauf aufbaut. Jeder kennt diesen Geschäftsprozess. Autonomes Fahren wird eine Vielzahl von Fahrzeugtypen umfassen, beispielsweise Data-Mining-Fahrzeuge und Autos, die mit Algorithmen auf der Straße fahren. Bei der Datenerfassung werden während des Fahrvorgangs verschiedene Daten vom selbstfahrenden Auto erfasst: Bei den Kameradaten handelt es sich beispielsweise um Bilder und bei den Lidar-Daten um Punktwolken.
Wenn die Sensordaten erfasst werden, kann ein Auto täglich mehrere Terabyte an Daten erzeugen. Diese Art von Daten wird als Ganzes über die Basisfestplatte oder andere Upload-Methoden gespeichert und in den Objektspeicher übertragen. Nachdem die Originaldaten gespeichert wurden, gibt es eine Pipeline für die Datenanalyse und Vorverarbeitung, z. B. das Schneiden in Datenrahmen, jeweils einen Rahmen, und Synchronisierungs- und Ausrichtungsvorgänge können zwischen verschiedenen Sensordaten in jedem Rahmen durchgeführt werden.
Nach Abschluss der Datenanalyse ist es an der Zeit, sich weiter damit zu befassen. Erstellen Sie Datensätze einzeln. Denn ob es sich um einen Algorithmus, eine Simulation oder einen Test handelt, es muss ein Datensatz erstellt werden. Wenn wir beispielsweise Daten für eine bestimmte Nacht an einem regnerischen Tag, an einer bestimmten Kreuzung oder in einigen dicht besiedelten Gebieten benötigen, müssen wir im gesamten System eine große Anzahl solcher Datenanforderungen haben und diese kennzeichnen Daten und fügen Sie einige Beschriftungen hinzu. Am Osttor der Tsinghua-Universität müssen Sie beispielsweise den Längen- und Breitengrad dieses Standorts ermitteln und die umliegenden POIs analysieren. Beschriften Sie dann die ermittelten Daten. Zu den gängigen Anmerkungen gehören: Objekte, Fußgänger, Objekttypen usw.
Diese gekennzeichneten Daten werden für das Training verwendet. Zu den typischen Aufgaben gehören die Zielerkennung, die Spurlinienerkennung oder größere End-to-End-Modelle. Nachdem das Modell trainiert wurde, muss eine Simulationsüberprüfung durchgeführt werden. Stellen Sie es nach der Überprüfung im Auto bereit, führen Sie die Daten aus und sammeln Sie auf dieser Grundlage weitere Daten. Es handelt sich um einen solchen Zyklus, bei dem Daten ständig angereichert und ständig Modelle mit besserer Leistung erstellt werden. Dies ist es, was der gesamte geschlossene Trainings- und Datenkreislauf leisten muss, und es ist auch das Kernstück der aktuellen Forschung und Entwicklung zum autonomen Fahren.
Algorithmentraining: NAS
Wir konzentrieren uns auf das Modelltraining: Beim Modelltraining werden Daten hauptsächlich durch Data Mining erfasst, um einen Datensatz zu generieren. Der Datensatz ist intern eine PKL-Datei, einschließlich Daten, Kanal und Speicherort. Schließlich schreiben Studenten, die Datenalgorithmen trainieren, ihre eigenen Download-Skripte, um die Daten aus dem Objektspeicher in den lokalen Speicher abzurufen.
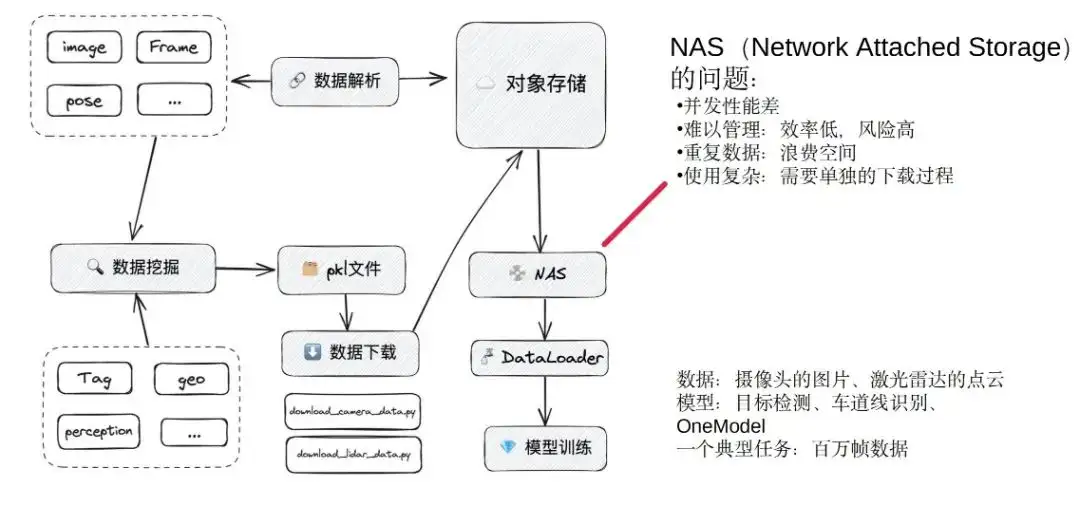
Bevor wir uns für Alluxio entschieden haben, nutzten wir das NAS-System als Cache, zogen Objektspeicherdaten auf das NAS und verwendeten schließlich verschiedene Modelle, um die Daten für das Training zu laden. Dies ist der ungefähre Trainingsprozess vor der Verwendung von Alluxio.
Eines der größten Probleme bei NAS:
- Die Parallelitätsleistung ist relativ schlecht – wir können NAS als große Festplatte verstehen, was völlig ausreicht, wenn nur wenige Aufgaben gleichzeitig ausgeführt werden. Wenn jedoch Dutzende von Trainingsaufgaben gleichzeitig ausgeführt werden und viele Modelle trainiert werden, kommt es häufig zu Problemen. Es gab eine Zeit, in der wir sehr feststeckten und das Forschungs- und Entwicklungsteam sich jeden Tag beschwerte. Es steckt so fest, dass die Verfügbarkeit und die Parallelitätsleistung sehr schlecht sind.
- Schwierigkeiten bei der Verwaltung – jeder verwendet sein eigenes heruntergeladenes Skript und lädt dann die gewünschten Daten in sein eigenes Verzeichnis herunter. Eine andere Person lädt möglicherweise selbst einen weiteren Datenstapel herunter und legt ihn in einem anderen Verzeichnis des NAS ab. Dies erschwert die Bereinigung, wenn der NAS-Speicherplatz voll ist. Damals kommunizierten wir grundsätzlich persönlich oder in WeChat-Gruppen. Einerseits ist die Effizienz äußerst gering und die Verwendung der Gruppennachrichtenverwaltung wird hinterherhinken. Andererseits kann die manuelle Entfernung auch einige Risiken mit sich bringen. Es kam schon vor, dass beim Entfernen von Daten die Datensätze anderer Personen gelöscht wurden. Dies führt auch zu Fehlern im Online-Aufgabenbereich, was ein weiteres Problem darstellt.
- Platzverschwendung – Von verschiedenen Personen heruntergeladene Daten werden in unterschiedlichen Verzeichnissen abgelegt. Es ist möglich, dass derselbe Datenrahmen in mehreren Datensätzen erscheint, was zu einer erheblichen Platzverschwendung führt.
- Die Verwendung ist sehr kompliziert – da die Dateiformate in pkl unterschiedlich sind, ist auch die Download-Logik unterschiedlich und jeder muss das Download-Programm separat schreiben.
Dies sind einige der Schwierigkeiten und Probleme, mit denen wir zuvor bei der Verwendung von NAS konfrontiert waren. Um diese Probleme zu lösen, haben wir Nachforschungen angestellt. Nach der Recherche haben wir uns auf Alluxio konzentriert. Ich habe festgestellt, dass Alluxio einen relativ einheitlichen Cache bereitstellen kann. Der Cache kann unsere Trainingsgeschwindigkeit verbessern und die Verwaltungskosten senken. Wir werden das Alluxio-System auch verwenden, um das Problem der Doppelcomputerräume zu lösen. Durch einheitliche Namespace- und Zugriffsmethoden kann einerseits unser Systemdesign vereinfacht werden, andererseits wird auch die Code-Implementierung sehr einfach.
Algorithmentraining in Alluxio eingeführt
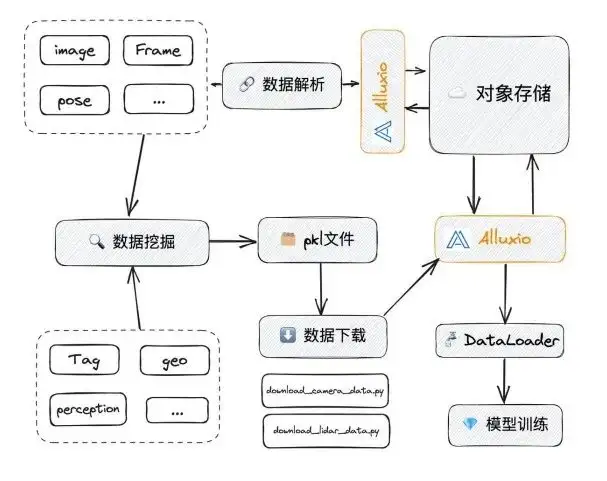
Wenn wir NAS durch Alluxio ersetzen, kann Alluxio einige der gerade genannten Probleme gezielt lösen:
- Was die Parallelität betrifft: NAS selbst ist kein vollständig verteiltes System, Alluxio jedoch schon. Wenn das IO, auf das das NAS zugreift, eine bestimmte Geschwindigkeit erreicht, friert es möglicherweise ein, wenn es mehrere G/s erreicht. Die Obergrenze von Alluxio ist sehr hoch. Nachfolgend finden Sie spezielle Tests, um diesen Punkt zu veranschaulichen.
- Die manuelle Bereinigung oder Verwaltung wird sehr mühsam sein: Alluixo konfiguriert die Cache-Räumungsrichtlinie. Normalerweise wird der Cache über LRU automatisch gelöscht und bereinigt, wenn ein Schwellenwert (z. B. 90 %) erreicht wird. Der Effekt davon:
- Die Effizienz wird erheblich verbessert;
- Dadurch können Sicherheitsprobleme vermieden werden, die durch versehentliches Löschen verursacht werden.
- Das Problem doppelter Daten wurde gelöst.
In Alluxio entspricht eine Datei in UFS einem Pfad in Alluxio. Wenn jeder auf diesen Pfad zugreift, kann er die entsprechenden Daten abrufen, sodass kein Problem mit doppelten Daten auftritt. Darüber hinaus ist die Verwendung der oben genannten Funktionen relativ einfach. Wir müssen nur über die FUSE-Schnittstelle darauf zugreifen und müssen keine Dateien mehr herunterladen.
Das Obige löst die verschiedenen Probleme, über die wir gerade gesprochen haben, auf logischer Ebene. Lassen Sie uns über unseren gesamten Implementierungsprozess sprechen, wie wir Alluxio von 0 auf 1 realisieren können, vom ersten POC-Test über die Überprüfung verschiedener Leistungen bis hin zur endgültigen Bereitstellung, dem Betrieb und der Wartung. Einige unserer praktischen Erfahrungen.
Alluxio-Einsatz: einzelner Computerraum
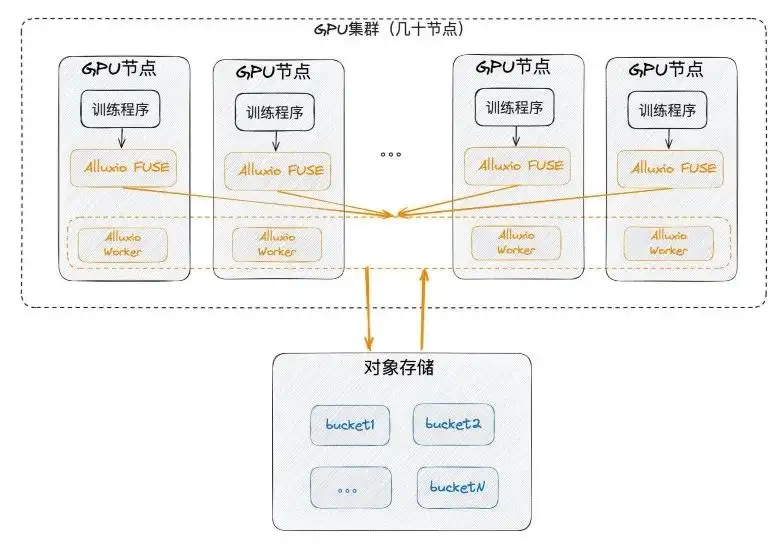
Zunächst können wir es in einem einzelnen Computerraum bereitstellen, was bedeutet, dass es sich in der Nähe der GPU befinden und auf dem GPU-Knoten bereitgestellt werden muss. Gleichzeitig wurde zur Nutzung jedes Knotens SSD verwendet, das zuvor selten auf der GPU verwendet wurde, und dann wurden FUSE und Worker gemeinsam bereitgestellt. FUSE entspricht dem Client und der Worker entspricht einem kleinen Cache-Cluster mit Intranetkommunikation zur Bereitstellung von FUSE-Diensten. Schließlich kommuniziert der Worker mit dem zugrunde liegenden Objektspeicher selbst.
Alluxio-Einsatz: in allen Computerräumen
Aber aus verschiedenen Gründen werden wir weiterhin maschinenübergreifende Räume haben. Es gibt jetzt zwei Computerräume, und jeder Computerraum wird über entsprechende S3-Dienste und entsprechende GPU-Rechenknoten verfügen. Grundsätzlich werden wir in jedem Computerraum einen Alluxio einsetzen. Gleichzeitig sollten wir auch auf diesen Prozess achten. Wenn in einem Computerraum auch zwei Alluxio-Objektspeicher vorhanden sein müssen, versuchen Sie, einen einheitlichen Plan für die Bucket-Namen zu erstellen Überlastung der beiden. Wenn zum Beispiel Bucket 1 hier und Bucket 1 dort vorhanden ist, führt dies zu einigen Problemen, wenn Alluxio gemountet wird.
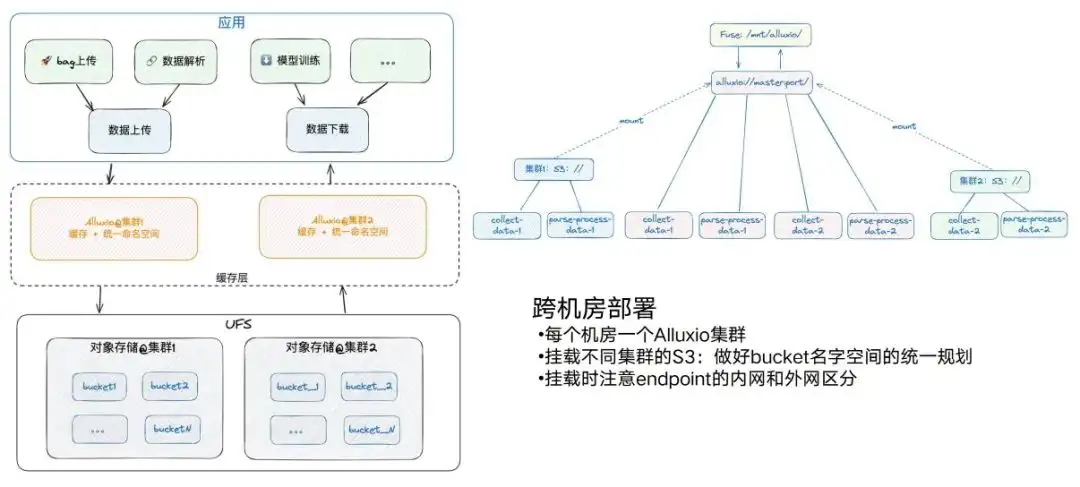
Beachten Sie auch, dass Sie bei verschiedenen Endpunkten auf die Unterscheidung zwischen dem internen Netzwerk und dem externen Netzwerk achten müssen. Beispielsweise stellt Alluxio von Cluster 1 das interne Netzwerk des Endpunkts von Cluster 1 bereit, und das externe Netzwerk befindet sich auf der anderen Seite , wird die Leistung stark reduziert. Nach der Bereitstellung können wir über denselben Pfad auf die Daten verschiedener Buckets in verschiedenen Clustern zugreifen, sodass die gesamte Architektur im Hinblick auf die maschinenraumübergreifende Bereitstellung sehr einfach wird.
Alluxio-Test: Funktionalität
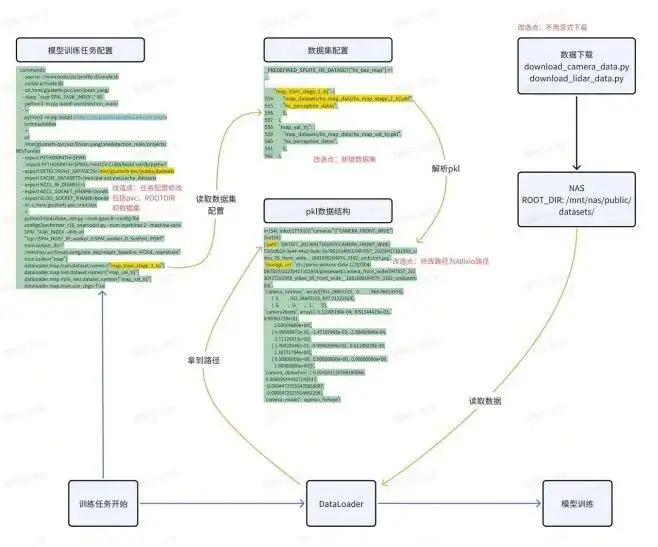
Wenn Sie Ihr NAS wirklich durch Alluxio ersetzen möchten, müssen Sie vor der Bereitstellung zahlreiche Funktionstests durchführen. Der Zweck dieser Art von Funktionstests besteht darin, den vorhandenen Algorithmusprozess minimal zu modifizieren, damit Algorithmenstudenten ihn auch verwenden können. Dies kann von Ihrer tatsächlichen Situation abhängen. Wir haben mit Alluxio fast zwei bis drei Wochen lang eine POC-Überprüfung durchgeführt, die zum Beispiel Folgendes umfasste:
- Konfiguration des Zugriffs auf PVC auf K8S;
- Wie der Datensatz organisiert ist;
- Konfiguration der Auftragsübermittlung;
- Ersatz von Zugangswegen;
- Letztendlich wurde auf die Skriptschnittstelle zugegriffen.
Viele der oben aufgetretenen Probleme müssen möglicherweise überprüft werden. Zumindest müssen wir eine typische Aufgabe auswählen, dann einige Änderungen vornehmen und schließlich das NAS relativ reibungslos durch Alluxio ersetzen.
Alluxio-Test: Leistung
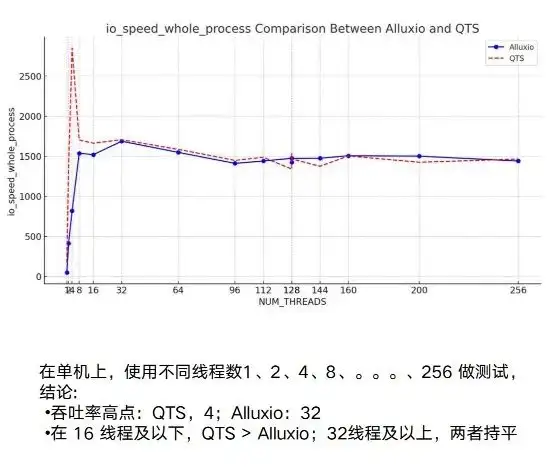
Als nächstes werden auf dieser Grundlage einige Leistungstests durchgeführt. In diesem Prozess haben wir relativ ausreichend Tests durchgeführt, unabhängig davon, ob es sich um eine einzelne Maschine oder mehrere Maschinen handelt. Auf einer einzelnen Maschine ist die Leistung von Alluxio und dem Original-NAS grundsätzlich gleich.
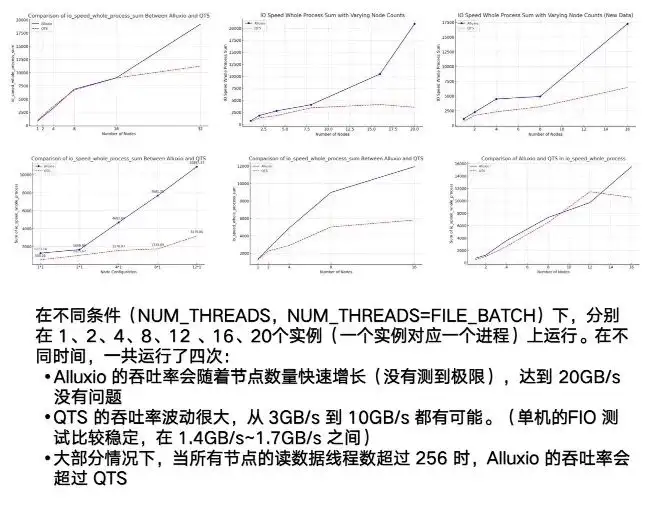
Was die Vorteile von Alluxio tatsächlich ausmacht, sind seine Multi-Host- und verteilten Fähigkeiten. Sie können sich NAS oder unser Beispiel von QTS ansehen, das einen ganz offensichtlichen Punkt hat: Instabilität. Die Schwankung zwischen dem Testen von 3G und 10G wird relativ groß sein. Gleichzeitig gibt es einen offensichtlichen Engpass, wenn es etwa 7/8G erreicht.
Was die Vorteile von Alluxio tatsächlich ausmacht, sind seine Multi-Host- und verteilten Fähigkeiten. Sie können sich NAS oder unser Beispiel von QTS ansehen, das einen ganz offensichtlichen Punkt hat: Instabilität. Die Schwankung zwischen dem Testen von 3G und 10G wird relativ groß sein. Gleichzeitig gibt es einen offensichtlichen Engpass, wenn es etwa 7/8G erreicht.
Was Alluxio betrifft, so kann der Knoten während des gesamten Testprozesses mit zunehmender Anzahl laufender Instanzen eine sehr hohe Obergrenze erreichen. Als wir ihn auf 20 GB/s eingestellt haben, zeigte er immer noch einen Aufwärtstrend. Dies zeigt, dass die Gesamtleistung von Alluxio bei gleichzeitigem und verteiltem Betrieb sehr gut ist.
Alluxio-Landung: Parameter anpassen und Umgebung anpassen
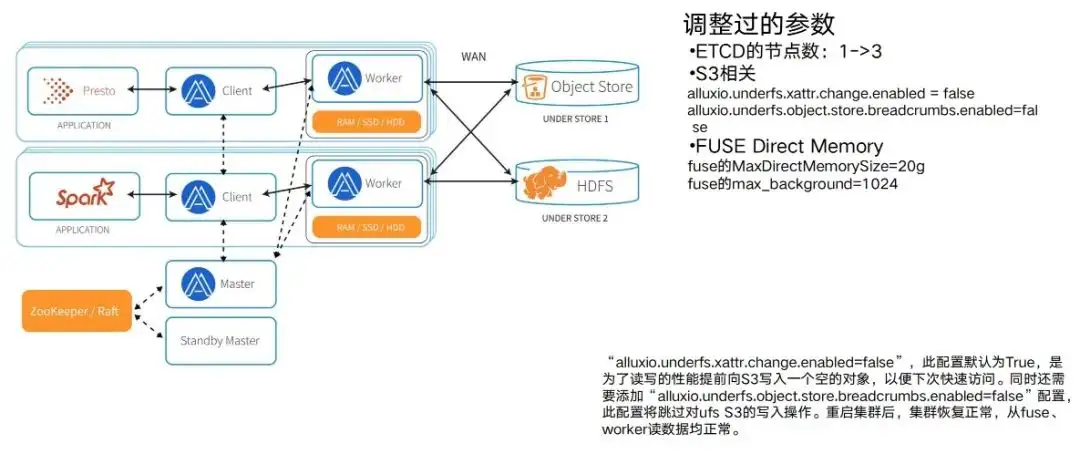
Nach Abschluss der Funktionsüberprüfung und Leistungstests ist es an der Zeit, den Alluxio-Cluster tatsächlich bereitzustellen. Nach der Bereitstellung ist ein Prozess der Parameteranpassung und -anpassung erforderlich. Denn während des Tests wurden nur einige typische Aufgaben verwendet. Nach der tatsächlichen Verwendung der Alluxio-Umgebung werden Sie feststellen, dass mit zunehmenden Aufgaben ein Prozess der Parameteranpassung und -anpassung erfolgt. Es ist notwendig, die entsprechenden Parameter von Alluxio mit der tatsächlichen Betriebsumgebung abzugleichen, bevor die Leistung vollständig genutzt werden kann. Daher wird es einen Prozess geben, bei dem Parameter ausgeführt, betrieben, gewartet und angepasst werden.
Wir haben einige typische Parameteranpassungsprozesse durchlaufen, wie zum Beispiel:
- Die Knoten von ETCD sind hier aufgelistet. Am Anfang ist es 1 und ändert sich dann auf 3. Dadurch wird sichergestellt, dass nur eine ETCD aufgehängt wird und nicht der gesamte Cluster aufgehängt wird.
- Es gibt auch S3-bezogene. Wenn beispielsweise Alluxio implementiert wird, generiert S3 einen relativ langen Zugriffspfad und schreibt standardmäßig einige Leerzeichen in die mittleren Pfadknoten, um eine bessere Leistung zu erzielen. Aber in diesem Fall verfügt der S3 unter unserer Trainingsaufgabe über eine Berechtigungskontrolle und ist nicht berechtigt, diese Art von Daten zu schreiben. Angesichts dieser Art von Konflikt ist auch eine Parameteranpassung erforderlich.
- Es gibt auch Funktionen wie die Parallelitätsintensität, die der FUSE-Knoten selbst tolerieren kann. Einschließlich der Größe des verwendeten Direktspeichers hat dies tatsächlich viel mit der tatsächlichen Parallelitätsintensität des gesamten Unternehmens zu tun. Es hat tatsächlich viel mit der Datenmenge zu tun, auf die gleichzeitig zugegriffen werden kann. Es gibt auch einen Parameteranpassungsprozess und so weiter. In verschiedenen Umgebungen können unterschiedliche Probleme auftreten. Dies ist auch der Grund, sich für die Alluxio Enterprise Edition zu entscheiden. Da Alluxio während der Enterprise-Version über einen sehr starken Support verfügt, kann es sich bei Problemen rund um die Uhr anpassen und kooperieren. Nur mit aufeinander abgestimmten Zyklen kann der gesamte Cluster reibungsloser laufen.
Alluxio-Implementierung: Betrieb und Wartung
Der erste Klassenkamerad unseres Teams für Betrieb und Wartung hatte nur eine Person, die für einen Großteil der zugrunde liegenden Infra-Wartung und damit verbundenen Arbeiten verantwortlich war. Als ich Alluxio einsetzen wollte, reichten die Ressourcen auf der Betriebs- und Wartungsseite tatsächlich nicht aus, also war es gleichwertig Für mich ist es auch eine Teilzeitbeschäftigung mit Betrieb und Wartung. Aus der Perspektive, etwas selbst zu bedienen und zu warten, ist es wichtig, viele Aufzeichnungen und Kenntnisse über Betrieb und Wartung zu führen, insbesondere für einen Anfänger. Zum Beispiel, wie man das Problem beim nächsten Mal besser lösen kann und ob man solche Erfahrungen schon einmal gemacht hat.
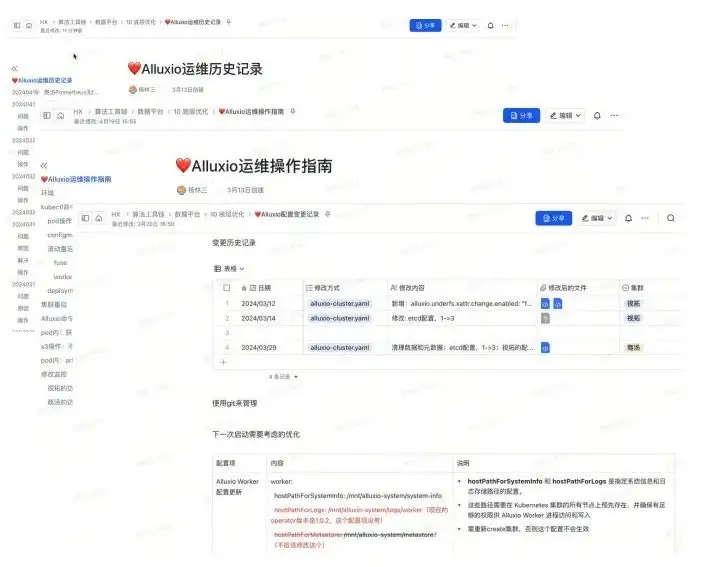
Basierend auf unserer damaligen Umgebung werden drei Dokumente verwaltet.
- Dokumente zur Betriebs- und Wartungshistorie : Welche Probleme sind beispielsweise an welchem Tag aufgetreten? Was ist die Ursache dieser Probleme und was ist ihre Lösung? Was sind die spezifischen Operationen?
- Betriebsdokumentation : Wenn wir beispielsweise K8S betreiben und warten, welche Schritte sind erforderlich, um es neu zu starten, welche Vorgänge werden ausgeführt, wie werden die Protokolle gelesen, wenn Probleme auftreten, wie werden Fehler behoben und welche Aufgaben und Arbeiten sollten ausgeführt werden, um sie anzuzeigen die Daten, die FUSE, Überwachung usw. entsprechen. Dies sind einige häufig verwendete Operationen.
- Konfigurationsänderungen: Weil Alluxio gerade Parameter anpasst. Zu unterschiedlichen Zeiten stoßen Sie möglicherweise auf unterschiedliche Konfigurationsdateien und Yaml-Dateien und müssen möglicherweise einige Sicherungen erstellen. Sie können es mit Git verwalten oder einfach die Dokumentenverwaltung nutzen. Dadurch ist eine Rückverfolgung auf die aktuelle Konfiguration und historische Konfigurationsversionen möglich.
Auf dieser Grundlage werden wir auch einige entsprechende unterstützende Konstruktionen erstellen, um Alluxio besser nutzen zu können. Forschungs- und Entwicklungsstudenten sind der Meinung, dass Alluxio nach der Verwendung recht einfach zu verwenden ist. Beim Multitasking werden jedoch einige unterstützende Konstruktionsanforderungen offengelegt. Beispielsweise müssen wir die Bildgröße ändern und das Bild von hochauflösendem 4K auf 720P reduzieren, um mehr Aufgaben-Caching zu unterstützen.
Der Trainingsdatensatz wird für ein besseres Vorladen der Daten über Cluster hinweg synchronisiert. Im Mittelpunkt steht dabei die systematische Konstruktion, die Alluxio durchführen muss.
Alluxio-Landung: Gemeinsam vorankommen
Da wir Alluxio weiterhin verwenden, werden wir auch feststellen, dass einige Bereiche verbesserungswürdig sind. Durch die Rückmeldung an Alluxio haben wir insbesondere die Iteration des gesamten Produkts vorangetrieben.
Was den Studierenden, die Algorithmen entwickeln, am Herzen liegt:
- Stabilität: Es muss während des Betriebs stabil sein. Es darf das Training des gesamten Systems nicht durch einen Absturz in Alluxio behindern. Möglicherweise gibt es hier einige Betriebs- und Wartungstipps, z. B. den Versuch, FUSE so oft wie möglich nicht neu zu starten. Wie gerade erwähnt, führt ein Neustart von FUSE dazu, dass der Zugriffspfad fehlschlägt und beim Lesen von Datendateien ein E/A-Fehler auftritt.
- Determinismus: Alluxio hat beispielsweise zuvor vorgeschlagen, dass Daten nicht vorab geladen werden müssen, das heißt, sie müssen vor dem Vortraining nicht einmal gelesen werden, sondern nur einmal während der ersten Epoche. Da es in der Forschung und Entwicklung jedoch einen Release-Zyklus gibt, muss er genau wissen, wie lange das Vorladen dauern wird. Wenn er die erste Epoche durchliest, ist es schwierig, die gesamte Trainingszeit abzuschätzen. Dies erstreckt sich tatsächlich auch auf die Art und Weise, wie eine Dateiliste zwischengespeichert wird. Dies stellt auch einige Anforderungen an Alluxio.
- Kontrollierbarkeit: Obwohl Alluxio eine automatisierte LRU-basierte Cache-Räumung und Cache-Bereinigung bieten kann. Tatsächlich hofft die Forschung und Entwicklung jedoch immer noch, dass einige zwischengespeicherte Daten proaktiv bereinigt werden können. Können Sie Alluxio diese Daten also auch freigeben, indem Sie eine Dateiliste bereitstellen? Dies ist auch unser Bedürfnis, Alluxio zusätzlich zur indirekten Nutzung direkt und auf sehr kontrollierbare Weise zu nutzen.
Auch auf der Betriebs- und Wartungsseite werden einige Anforderungen gestellt:
- Konfigurationscenter: Alluxio selbst kann ein Konfigurationscenter zum Speichern des Konfigurationsverlaufs bereitstellen. Wenn Sie eine Funktion zum Implementieren von Änderungen an Konfigurationselementen hinzufügen, planen Sie im Voraus, welche Auswirkungen diese Änderung haben wird.
- Trace verfolgt den laufenden Prozess eines Befehls: Eine weitere realistischere Anforderung stellen wir nun fest: Die Verzögerung beim Zugriff auf eine UFS-Datei ist relativ hoch. Möglicherweise können wir den Grund nicht anhand der FUSE-Protokolle erkennen, daher müssen wir uns die Worker-Protokolle ansehen, die dem Standort entsprechen. Dies ist tatsächlich ein sehr zeitaufwändiger und mühsamer Prozess, und das Problem kann oft nicht gelöst werden, sodass die Online-Kundendienstunterstützung von Alluxio erforderlich ist. Kann Alluxio einen Trace-Befehl hinzufügen, um die zeitaufwändigen Probleme von FUSE, Arbeit und Lesen von UFS beim Zugriff auf den gesamten Link zu verfolgen? Dies wird tatsächlich eine große Hilfe für den gesamten Betriebs- und Wartungsprozess oder den Fehlerbehebungsprozess sein.
- Intelligente Überwachung: Manchmal sind die Dinge, die wir überwachen, Dinge, die wir bereits kennen. Wenn beispielsweise ein Problem mit dem Direktspeicher vorliegt, konfigurieren wir ein Überwachungselement. Aber wenn das nächste Mal ein neues Problem in meinem Protokoll auftaucht, handelt es sich möglicherweise um ein verstecktes Problem, das still und leise auftritt, ohne dass es jemand merkt. Wir hoffen, diese Situation automatisch überwachen zu können.
Wir haben Alluxio durch Rückmeldungen zu Arbeitsaufträgen verschiedene Vorschläge unterbreitet. Es besteht die Hoffnung, dass Alluxio während des Produktiterationsprozesses leistungsfähigere Funktionen bereitstellen kann. Machen Sie die gesamten F&E-, Betriebs- und Wartungsangelegenheiten zufriedenstellender.
Zusammenfassung
Erstens bietet Alluxio im Vergleich zu NAS eine sehr gute Benutzerfreundlichkeit in Bezug auf die Caching-Beschleunigung für das gesamte Training des autonomen Fahrmodells. Für uns wird es auch um eine 10-fache Verbesserung gehen. Die Kostensenkung ergibt sich aus zwei Teilen:
- Die Produktbeschaffungskosten sind niedrig;
- NAS verfügen möglicherweise über 20–30 % redundanten Speicher, was Alluxio lösen kann.
Unter dem Gesichtspunkt der Wartbarkeit können Daten automatisch bereinigt werden, was zeitnaher und sicherer ist. Im Hinblick auf die Benutzerfreundlichkeit kann über FUSE bequemer auf Daten zugegriffen werden.
Zweitens habe ich auch erzählt, wie Huixi Alluxio von 0 auf 1 einsetzt und ein System betreibt und wartet.
Das Obige ist mein Beitrag, vielen Dank an alle.
