
Mit der Entwicklung der LLM-Technologie (Large Language Model) wurde die RAG-Technologie (Retrieval Augmented Generation) ausführlich diskutiert und erforscht, und es wurden immer fortschrittlichere RAG-Abrufmethoden entdeckt. Im Vergleich zum gewöhnlichen RAG-Abruf bietet fortschrittliches RAG genauere, relevantere und umfassendere Ergebnisse beim Informationsabruf durch tiefergehende technische Details und komplexere Suchstrategien. In diesem Artikel werden zunächst diese Technologien erörtert und ein Implementierungsfall basierend auf Milvus vorgestellt.
01.Junior RAG
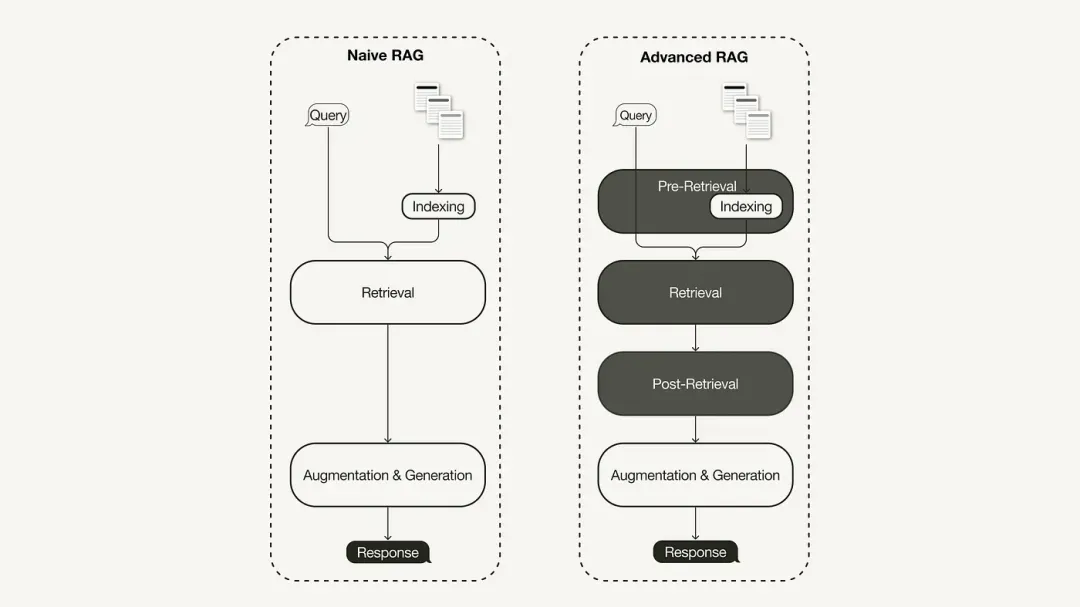
Definition der primären RAG
Das primäre RAG-Forschungsparadigma stellt die früheste Methodik dar und gewann bald nach der weit verbreiteten Einführung von ChatGPT an Bedeutung. Primäres RAG folgt dem traditionellen Prozess, einschließlich Indizierung, Abruf und Generierung. Es wird oft als „Retrieval-Reading“-Framework beschrieben und sein Arbeitsablauf umfasst drei Schlüsselschritte:
-
Der Korpus wird in diskrete Blöcke unterteilt und dann wird ein Encodermodell verwendet, um Vektorindizes zu erstellen.
-
RAG identifiziert und ruft Blöcke basierend auf der Vektorähnlichkeit zwischen Abfragen und indizierten Blöcken ab.
-
Das Modell generiert Antworten basierend auf Kontextinformationen, die im Retrieved Chunk abgerufen werden.
Einschränkungen der primären RAG
Die primäre RAG steht vor erheblichen Herausforderungen in drei Schlüsselbereichen: „Abruf“, „Generierung“ und „Verbesserung“.
Es gibt viele Probleme mit der Abrufqualität der primären RAG, wie z. B. geringe Präzision und geringer Rückruf. Eine geringe Präzision kann zu einer Fehlausrichtung der abgerufenen Blöcke sowie zu potenziellen Problemen wie Halluzinationen führen. Eine niedrige Rückrufrate führt dazu, dass nicht alle relevanten Blöcke abgerufen werden können, was zu einer unzureichend umfassenden Antwort von LLM führt. Darüber hinaus verschärft die Verwendung älterer Informationen das Problem noch weiter und kann zu ungenauen Suchergebnissen führen.
Die Qualität der generierten Antworten steht vor illusorischen Herausforderungen, das heißt, die von LLM generierten Antworten basieren nicht auf dem bereitgestellten Kontext, sind für den Kontext nicht relevant oder die generierten Antworten bergen das potenzielle Risiko, schädliche oder diskriminierende Inhalte zu enthalten.
Während des Verbesserungsprozesses steht die primäre RAG auch vor erheblichen Herausforderungen, wie sie den Kontext der abgerufenen Passagen effektiv in die aktuelle Generierungsaufgabe integrieren kann. Eine ineffiziente Integration kann zu inkohärenten oder fragmentierten Ergebnissen führen. Auch Redundanz und Duplikate sind ein heikles Thema, insbesondere wenn mehrere abgerufene Passagen ähnliche Informationen enthalten und in den generierten Antworten möglicherweise doppelter Inhalt auftauchen kann.
02. Fortgeschrittenes RAG
Um die Mängel des primären RAG zu beheben, wurde das erweiterte RAG geboren und dessen Funktionen gezielt erweitert. Wir besprechen zunächst diese Techniken, die in die Kategorien Pre-Retrieval-Optimierung, Mid-Retrieval-Optimierung und Post-Retrieval-Optimierung eingeteilt werden können.
Optimierung vor der Suche
Die Pre-Retrieval-Optimierung konzentriert sich auf die Datenindexoptimierung und die Abfrageoptimierung. Die Datenindex-Optimierungstechnologie zielt darauf ab, Daten so zu speichern, dass die Abrufeffizienz verbessert wird:
-
Schiebefenster: Verwendet Überlappungen zwischen Datenblöcken. Dies ist eine der einfachsten Techniken.
-
Verbessern Sie die Datengranularität: Wenden Sie Datenbereinigungstechniken an, z. B. das Entfernen irrelevanter Informationen, die Bestätigung der sachlichen Richtigkeit, die Aktualisierung veralteter Informationen usw.
-
Fügen Sie Metadaten hinzu: z. B. Datum, Zweck oder Kapitelinformationen zum Filtern.
-
Die Optimierung der Indexstruktur erfordert verschiedene Datenindizierungsstrategien: beispielsweise die Anpassung der Blockgröße oder die Verwendung einer Multi-Index-Strategie. Eine Technik, die wir in diesem Artikel implementieren werden, ist der Satzfensterabruf, der einzelne Sätze zum Zeitpunkt des Abrufs einbettet und sie zum Zeitpunkt der Inferenz durch größere Textfenster ersetzt.
Optimieren Sie während der Suche
Die Abrufphase konzentriert sich auf die Identifizierung des relevantesten Kontexts. Typischerweise basiert der Abruf auf einer Vektorsuche, die die semantische Ähnlichkeit zwischen Abfrage und indizierten Daten berechnet. Daher drehen sich die meisten Suchoptimierungstechniken um die Einbettung von Modellen:
-
Feinabstimmung von Einbettungsmodellen: Passen Sie Einbettungsmodelle an bestimmte Domänenkontexte an, insbesondere für Domänen mit entwicklungsbezogener oder seltener Terminologie. Beispielsweise
BAAI/bge-small-enhandelt es sich um ein leistungsstarkes Einbettungsmodell, das fein abgestimmt werden kann. -
Dynamische Einbettung: Passt sich an den Kontext an, in dem Wörter verwendet werden, im Gegensatz zur statischen Einbettung, bei der ein Vektor pro Wort verwendet wird. OpenAI ist beispielsweise
embeddings-ada-02ein komplexes dynamisches Einbettungsmodell, das kontextbezogenes Verständnis erfasst. Neben der Vektorsuche gibt es noch andere Retrieval-Techniken, beispielsweise die Hybridsuche, bei der es sich meist um das Konzept der Kombination der Vektorsuche mit der schlüsselwortbasierten Suche handelt. Diese Suchtechnik ist von Vorteil, wenn für die Suche exakte Schlüsselwortübereinstimmungen erforderlich sind.
Optimierung nach dem Abruf
Für den abgerufenen Kontextinhalt werden wir auf Rauschen stoßen, z. B. wenn der Kontext die Fenstergrenze überschreitet, oder durch den Kontext, der die Aufmerksamkeit von den Schlüsselinformationen ablenkt:
-
Eingabeaufforderungskomprimierung: Reduzieren Sie die Gesamtlänge der Eingabeaufforderung, indem Sie irrelevante Inhalte entfernen und wichtigen Kontext hervorheben.
-
Neubewertung: Verwenden Sie ein maschinelles Lernmodell, um die Relevanzbewertung des abgerufenen Kontexts neu zu berechnen.
Zu den Techniken zur Post-Search-Optimierung gehören:
03. Implementieren Sie erweitertes RAG basierend auf Milvus + LlamaIndex
Das von uns implementierte erweiterte RAG verwendet das Sprachmodell von OpenAI, das auf Hugging Face gehostete BAAI-Umordnungsmodell und die Milvus-Vektordatenbank.
Erstellen Sie einen Milvus-Index
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
Beispiel für die Indexoptimierung: Abrufen des Satzfensters
Wir verwenden SentenceWindowNodeParser in LlamaIndex, um die Technologie zum Abrufen von Satzfenstern zu implementieren.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser führt zwei Vorgänge aus:
Es unterteilt das Dokument in einzelne Sätze, die eingebettet werden.
Für jeden Satz wird ein Kontextfenster erstellt. Wenn Sie window_size = 3 angeben, enthält das resultierende Fenster drei Sätze, beginnend mit dem Satz vor dem eingebetteten Satz und bis zum Satz danach. Dieses Fenster wird als Metadaten gespeichert. Beim Abruf wird der Satz zurückgegeben, der am besten zur Abfrage passt. Nach dem Abruf müssen Sie den Satz durch das gesamte Fenster aus den Metadaten ersetzen, indem Sie a definieren MetadataReplacementPostProcessorund in der Liste verwenden .node_postprocessors
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Beispiel für Suchoptimierung: Hybridsuche
Die Implementierung der Hybridsuche in LlamaIndex erfordert nur zwei Parameteränderungen an der Abfrage-Engine, vorausgesetzt, dass die zugrunde liegende Vektordatenbank Hybridsuchabfragen unterstützt. Milvus Version 2.4 unterstützte zuvor keine Hybridsuche, aber in der kürzlich veröffentlichten Version 2.4 wird diese Funktion bereits unterstützt.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
Beispiel für eine Post-Retrieval-Optimierung: Re-Ranking
Das Hinzufügen einer Neubewertung zur erweiterten RAG erfordert nur drei einfache Schritte:
Definieren Sie zunächst ein Neubewertungsmodell mit Hugging Face BAAI/bge-reranker-base.
Fügen Sie in der Abfrage-Engine das Neuordnungsmodell zur node_postprocessorsListe hinzu.
Erhöhung der Abfrage-Engine similarity_top_k, um mehr Kontextfragmente abzurufen, die nach der Neuanordnung auf top_n reduziert werden können.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
Den detaillierten Implementierungscode finden Sie unter dem Baidu Netdisk-Link: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 Extraktionscode: r2i1
Die Raubkopien von „Qing Yu Nian 2“ wurden auf npmror hochgeladen, was dazu führte, dass npmmirror den Unpkg-Dienst einstellen musste: Es bleibt nicht mehr viel Zeit für Google. Ich schlage vor, dass alle Produkte Open Source sind . time.sleep(6) spielt hier eine Rolle. Linus ist am aktivsten beim „Hundefutter fressen“! Das neue iPad Pro verwendet 12 GB Speicherchips, behauptet jedoch, über 8 GB Speicher zu verfügen. People’s Daily Online bewertet die Aufladung im Matroschka-Stil: Nur durch aktives Lösen des „Sets“ können wir eine Zukunft haben Neues Entwicklungsparadigma für Vue3, ohne die Notwendigkeit von „ref/reactive“ und ohne die Notwendigkeit von „ref.value“. MySQL 8.4 LTS Chinesisches Handbuch veröffentlicht: Hilft Ihnen, den neuen Bereich der Datenbankverwaltung zu meistern Tongyi Qianwen GPT-4-Level-Hauptmodellpreis reduziert um 97 %, 1 Yuan und 2 Millionen Token