
Hallo zusammen, ich bin Wang Chunxiao vom Shandong Provincial Computing Center (National Supercomputing Jinan Center). Ich nehme seit 2022 an Supercomputing-Internetprojekten teil. Ich bin hauptsächlich für die Forschung und Entwicklung einer einheitlichen Speicherplattform für Computernetzwerke verantwortlich Ich habe auch einige Arbeiten an Speicherbasen durchgeführt. Nach mehr als einem Jahr harter Arbeit bin ich Alluxio für die Unterstützung und Hilfe sehr dankbar.
Als nächstes werden wir uns auf das Thema Supercomputing Internet konzentrieren und drei Aspekte mit Ihnen teilen:
(1) Probleme und Herausforderungen beim Aufbau des Supercomputing-Internets;
(2) Forschung zu Schlüsseltechnologien der Supercomputing-Internet-Unified-Storage-Plattform;
(3) Anwendung und zukünftige Entwicklung des Supercomputing-Internets
1. Probleme und Herausforderungen beim Aufbau des Supercomputing-Internets

Lassen Sie mich zunächst kurz das National Supercomputing Jinan Center vorstellen. Es wurde 2011 gegründet und ist der Geburtsort des inländischen Servers „Sunway Blu-ray“. Natürlich ist der Umfang von Sunway Blu-ray inzwischen um Petaflops gewachsen zur Exa-Skala. Ab 2019 haben wir begonnen, eine universelle Plattform auf Basis der inländischen Plattform zu entwickeln und aufzubauen. Das heißt, die Sunward Supercomputing-Plattform, deren CPU-, GPU- und Speicherbandbreite ein beträchtliches Ausmaß erreicht hat, spielt in vielen Branchen in der Provinz Shandong eine wichtige unterstützende Rolle.
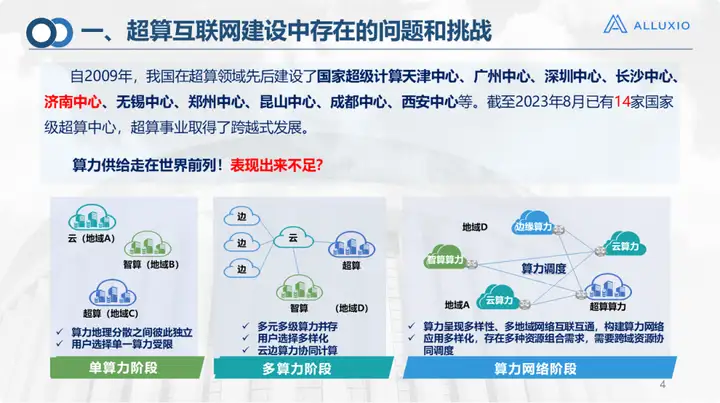
Seit 2009 hat unser Land sukzessive viele Supercomputing-Zentren eingerichtet. Bis August 2023 wird unser Land über 14 Supercomputing-Zentren auf nationaler Ebene, mehr als 30 intelligente Rechenzentren und mehr als 500 große Cloud-Rechenzentren verfügen. Mit dieser Größe steht es auch an der Spitze der weltweiten Rechenleistungsversorgung.
Heutzutage, mit der steigenden Nachfrage nach großen Modellen und vielen anderen Dingen, wurden auch einige Defizite bei der Rechenleistung aufgedeckt. Dies ist untrennbar mit der Komplexität unserer Anwendungsentwicklung verbunden: Heutige Anwendungen können nicht mehr allein durch Rechenleistung gelöst werden. In der Vergangenheit konnte man einfach einige Daten und ein Modell nehmen und diese auf einer bestimmten Ressource ausführen. Jetzt ist das Stadium der Multi-Rechenleistung erreicht. In einigen relativ großen Anwendungsszenarien gibt es Anforderungen an den Umfang und die Art der Rechenleistung und des Speichers. Beispielsweise ist es beim konvergenten Computing wie Cloud Computing, High Performance Computing und AI Computing sowie bei dem von unserem Land vorgeschlagenen Szenario des Computing im Osten und im Westen tatsächlich schwierig, das Problem einfach zu lösen Erhöhen Sie die Rechenleistung oder den Speicherplatz in einem bestimmten Bereich. Natürlich gibt es regionale Unterschiede in der Nachfrage nach Rechenleistung und der Ressourcenverteilung in meinem Land. Dies ist auch die ursprüngliche Absicht meines Landes, ein Supercomputing-Internet aufzubauen.

Im April 2023 begann das Ministerium für Wissenschaft und Technologie mit der Arbeit zum Aufbau eines nationalen Supercomputing-Internets, um ein integriertes Supercomputing-Stromnetz und eine Serviceplattform aufzubauen. Das National Supercomputing Jinan Center ist ebenfalls eine der Supercomputing-Interneteinheiten. Seine Aufgabe besteht derzeit darin, eine einheitliche Ressourcenverwaltung, Steuerung und Koordination von großflächigen Rechenleistungsspeichern und Netzwerken durchzuführen, um eine optimale Ressourcenverteilung zu erreichen.
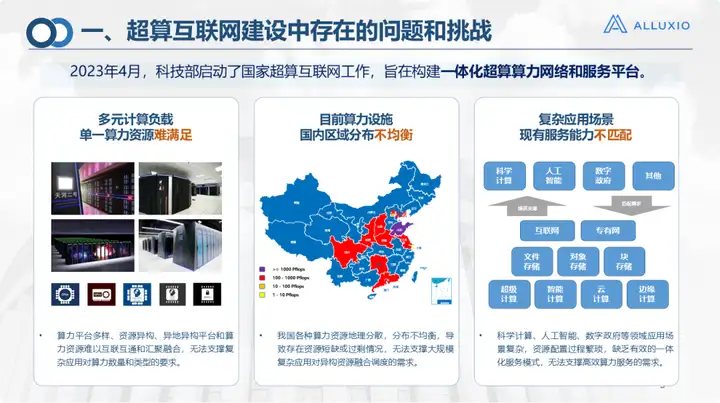
Das National Supercomputing Center in Jinan plant und baut seit 2016 ein Supercomputing-Internet und hat auf allen Ebenen daran gearbeitet. Natürlich gibt es auch viele Probleme beim Aufbau und der Anwendung von Rechenleistungsnetzwerken.
1. Das erste ist das Problem diversifizierter Rechenleistungsplattformen, einschließlich der endlosen Entstehung verschiedener Cloud-Plattformen, KI-Plattformen und Speicherplattformen;
2. Das zweite ist das Problem heterogener Ressourcen, einschließlich der inländischen Gruppenchipstandards, die sehr unterschiedlich sind, und Speichersysteme verfügen auch über verschiedene Schnittstellen, die sehr verstreut sind, komplexe Strukturen und viele Protokolle aufweisen, was die Umsetzung erschwert Vernetzung und Interoperabilität: Es muss eine einheitliche Plattform geschaffen werden.
3. Der dritte Grund ist die ungleiche Verteilung der Rechenleistung, die in unserem Land ein häufiges Problem darstellt. Am Beispiel der Provinz Shandong befindet sich die Datenverarbeitung in Jinan und die Speicherung in Zibo. Wenn es einen Engpass im Zwischennetzwerk gibt, ist es grundsätzlich schwierig, eine Fernmontage, einen Anruf oder sogar eine Übertragung zu erreichen.
Es gibt auch einige komplexe Anwendungsszenarien, wie zum Beispiel die Bereiche der marinen meteorologischen Fernerkundung, deren Betriebsabläufe relativ komplex sind. Die Daten können an einem Ort gespeichert werden und müssen zur Datenvorverarbeitung, Simulation, Modellschulung usw. an einen anderen Ort übertragen werden Andere Vorgänge müssen jedoch möglicherweise auf verschiedenen Plattformen oder sogar in verschiedenen Regionen durchgeführt werden. Ohne eine integrierte Serviceplattform ist es schwierig, alle Plattformen zu beherrschen Probleme und Herausforderungen Dies ist auch das, was wir lösen müssen, wenn wir den Kern des Supercomputing-Internets aufbauen.
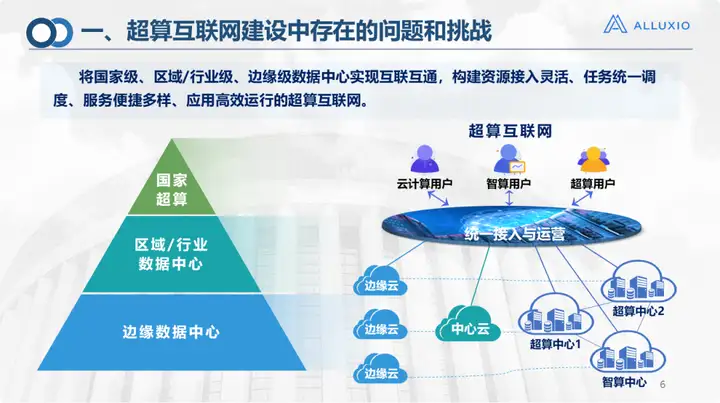
Dies ist der Rahmen des Supercomputing-Internets, der es Rechenzentren auf nationaler, Unternehmens-/regionaler und Edge-Ebene ermöglicht, Verbindungen und eine hierarchische Klassifizierung zu erreichen. Interoperabilität soll einen relativ einfachen und einheitlichen Zugriff und Betrieb von Rechenleistung, Speicher und Netzwerken ermöglichen. Es kann wie Wasser und Strom fließen und den oberen Ebenen zur Nutzung durch verschiedene Benutzer zur Verfügung gestellt werden. Einige sind sogar gemischte Benutzer: Beispielsweise muss ein Algorithmus sowohl hohe Leistung als auch KI verwenden. Dies ist auch unser Konstruktionsziel.
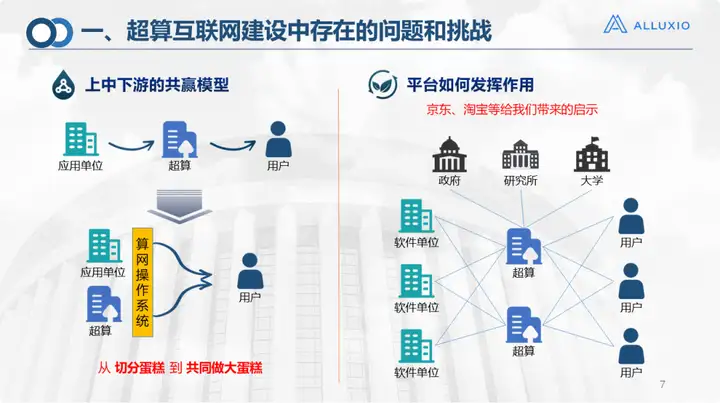
Dies war zu dieser Zeit die Industriekette für die Entwicklung des Supercomputing-Internets. In der Vergangenheit nutzten Benutzer Rechenleistung, Speicher und Software über Supercomputing oder Rechenzentren, und es gab eine Anwendungseinheit eines Drittanbieters. Jetzt haben wir eine mittlere Schicht mit drei Schichten oberer, mittlerer und nachgelagerter Definitionen hinzugefügt: Die Anwendungseinheiten und Supercomputer auf der ersten Schicht dienen als Anbieter paralleler Ressourcen, und das Betriebssystem des Supercomputing-Netzwerks dient als mittlere Schicht zur Bereitstellung entsprechende Rechenleistung und Speichernetzwerk. Das Betriebsmodell kann sich auf Plattformen wie JD.com und Taobao beziehen, die als Zwischenplattform genutzt werden können. Wie JD.com und Taobao verkaufen sie Waren, aber was wir betreiben, ist eine Ressource, ein Modell, das vom Anschneiden des Kuchens zum gemeinsamen Backen des Kuchens wechselt.
2. Forschung zu Schlüsseltechnologien der Supercomputing-Internet-Unified-Storage-Plattform
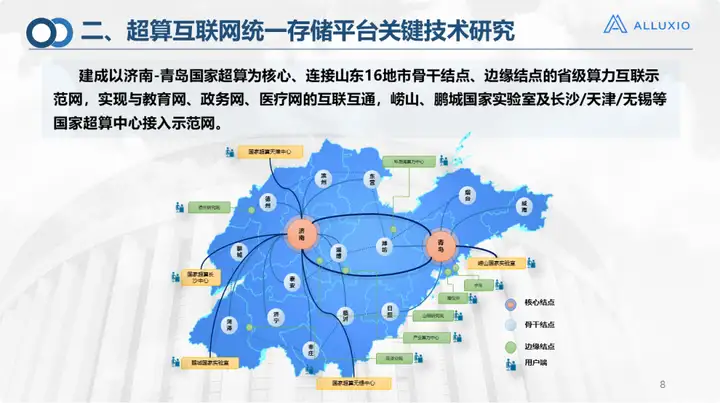
Dies ist die aktuelle Bausituation des Supercomputing-Internets. Es wurde erstmals in Shandong getestet und deckte 16 Städte in der Provinz Shandong ab, darunter die beiden Kernknoten Jinan und Qingdao sind Standleitungen zu verwenden. Darüber hinaus gibt es 30 Edge-Knoten, die über Sdone oder das Internet verbunden werden können. Gleichzeitig haben wir auch 28 Rechencluster und 45 Speichersysteme von 7 Typen angeschlossen. Die einheitliche Plattform des Speichersystems ist mit Alluxio aufgebaut. Dies ist die Größe unserer ersten Version des Supercomputing-Netzwerkbetriebssystems. Derzeit unterstützt die obere Schicht drei Arten von Diensten: Cloud Computing, HPC und KI. Es stellt hauptsächlich Ressourcen in drei Aspekten bereit:
1. Computerressourcen;
2. Speicherressourcen;
3. Netzwerkressourcen.
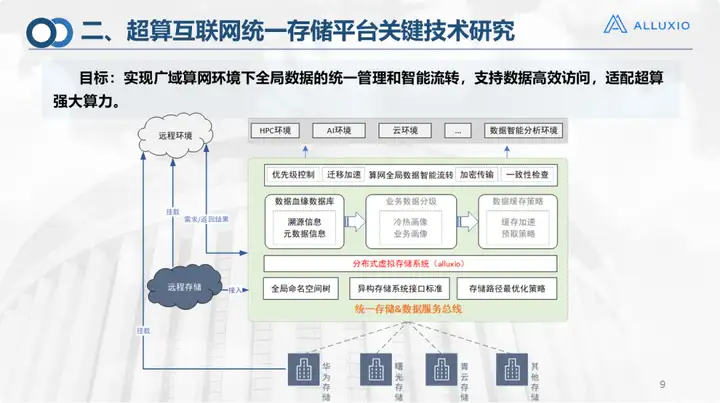
Da ich hauptsächlich für die Unified Storage-Plattform verantwortlich bin, werde ich mich auf die Einführung der Unified Storage-Plattform konzentrieren. Dies ist das Design-Framework-Diagramm. Tatsächlich spielt es keine Rolle Es handelt sich um jede Art von Speicher unten oder in der Cloud. Wir alle müssen den Speicher verwalten. Die Ebene, die sich mit dem Speichersystem befasst, verwendet Alluxio als Speicherbasis. Auf dieser Grundlage haben wir auch einige Optimierungsarbeiten durchgeführt, darunter Pfadoptimierung, Datenmigrationsstrategie, verschlüsselte Übertragung, Konsistenzprüfung usw. Einige davon befinden sich noch im Überprüfungsprozess und wurden nicht zur ersten Version hinzugefügt. Dies ist unsere Gesamtplan.
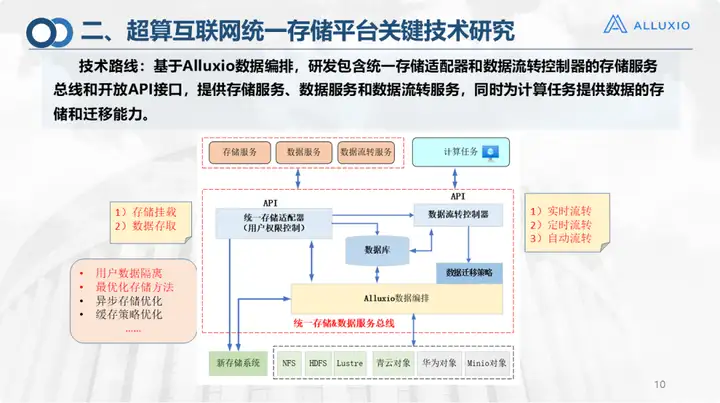
Dieses Bild zeigt, dass die Kerntechnologie der einheitlichen Speicherplattform das Design des Servicebusses ist. Ich habe es separat herausgenommen, weil wir auf der oberen Ebene einen einheitlichen Speicheradapter und Datenflusscontroller entwickelt und drei Zirkulationsstrategien eingebettet haben: Echtzeitausleihe, geplante Ausleihe und automatische Ausleihe. Es stellt außerdem Speicher-, Daten- und Datenübertragungsdienste für dieses Codeberechnungsportal (das Hauptportal oben) bereit und kann Schnittstellen- und Montagefunktionen bereitstellen. Wie beim Unified Storage Adapter können wir derzeit Folgendes tun:
1. Automatische Speichermontage;
2. Es werden mehrere Möglichkeiten des Datenzugriffs unterstützt, einschließlich Schnittstelle, Client und Befehlszeile.
Natürlich haben wir auch Untersuchungen zur Isolierung von Benutzerdaten und zu optimalen Speichermethoden durchgeführt, die bereits eingebettet sind. Der Datenflusscontroller erledigt viel Arbeit und verfügt über drei Flussstrategien:
1. Die Echtzeitübertragung ist hauptsächlich für Benutzer gedacht, da Benutzer auf unserer Plattform einen Speicherplatz in Jinan und einen Speicherplatz in Qingdao beantragen. Wenn sie die Daten in Echtzeit migrieren möchten, gibt der Benutzer die ursprüngliche Adresse an und Ziel der Migration, wählen Sie die Übertragungsgeschwindigkeit aus und passen Sie die Migrationsstrategie automatisch an. Wir haben auch einige Untersuchungen zu intelligenten Modellen durchgeführt, um die Laufzeit von Aufgaben in verschiedenen Zuständen zu berechnen und die optimale Strategie auszuwählen.
2. Geplante Übertragung. Die geplante Übertragung ist derzeit auf Ozean- und Campus-Szenarien ausgerichtet. Beispielsweise sind Vor-Ort-Daten in Schulen oder auf dem Meer am Rande, da es sich bei einigen davon um Videodaten handelt und der Datenumfang besonders groß ist. Wenn Sie recherchieren möchten und sparen müssen, gibt es tatsächlich kein solches Speichergerät am Rand. Ohne eine so große Menge an Speichergeräten müssen Sie möglicherweise jede Woche eine geplante Datenmigration durchführen. Konfigurieren Sie die angegebene Quelladresse und Zieladresse der Migration innerhalb einer definierten Zeit. Wir verwenden das intelligente Modell auch, um die optimale Strategie basierend auf Aufgabenzeit und Termin auszuwählen. Sie können dies nachts oder bei relativ geringem Netzwerkverkehr tun.
3. Die automatische Übertragung ist ebenfalls eine Funktion, bei der die zu migrierenden Daten und Speicherorte basierend auf der Regel-Engine intelligent ausgewählt werden. Es kann viele solcher Szenarien geben. Wir haben mehrere solcher Szenarien angepasst, und später gibt es eine Einführung in automatische Flussszenarien. Die Beurteilung basiert darauf, ob die Daten separat gespeichert und berechnet werden. Wenn sie beispielsweise in Zibo gespeichert sind und ich sie in Jinan berechnen möchte, können wir sie automatisch nach Jinan migrieren, wenn die Netzwerkbedingungen keine Zustimmung des Benutzers zulassen ihn. Natürlich können Sie feststellen, ob die Daten vorab abgerufen werden, indem Sie den Zugriffsmodus der Metadatendatenbank und die Zugriffshäufigkeit der Hotspot-Daten kombinieren.
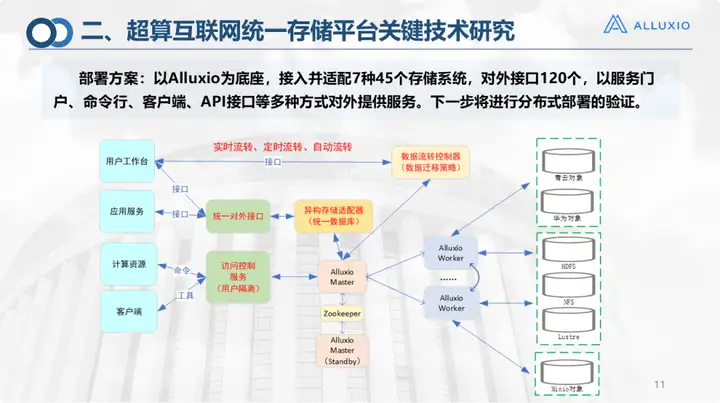
Dies ist unser Bereitstellungsplan, der derzeit mit den in der Abbildung aufgeführten Speichersystemen verbunden ist, einschließlich Alibaba Cloud. Es gibt etwa 130 externe Schnittstellen, die externe Dienste über die Befehlszeile, den Client, die API usw. des Serviceportals bereitstellen können. Für die aktuelle Bereitstellung folgen wir weiterhin der klassischen Bereitstellung von Alluxio. In der späteren Phase hoffen wir auf einen verteilten Einsatz: Aufgrund von Netzwerkbeschränkungen konzentrieren sich derzeit alle Exporte auf Jinan. Obwohl bereits 16 Städte China Unicom gegründet haben, sind die Exporte noch nicht liberalisiert. Beispielsweise wurde die Verbindung zwischen Qingdao und Zibo noch nicht vollständig getestet. Unter solchen Umständen gibt es bei diesem Layout kein Problem, wenn der gesamte Speicher von der allgemeinen Plattform Alluxio Master Jinan bereitgestellt und aufgerufen wird. Wenn andere Netzwerke liberalisiert werden, wird dies hoffentlich auch der Fall sein in Qingdao können wir die lokale Montage realisieren, ohne den Master in Jinan benachrichtigen zu müssen, damit er die Zuteilung vornehmen kann. Dies fügt tatsächlich einen weiteren Schritt hinzu, sodass wir jetzt auch Tests und Überprüfungen der verteilten Bereitstellung durchführen.
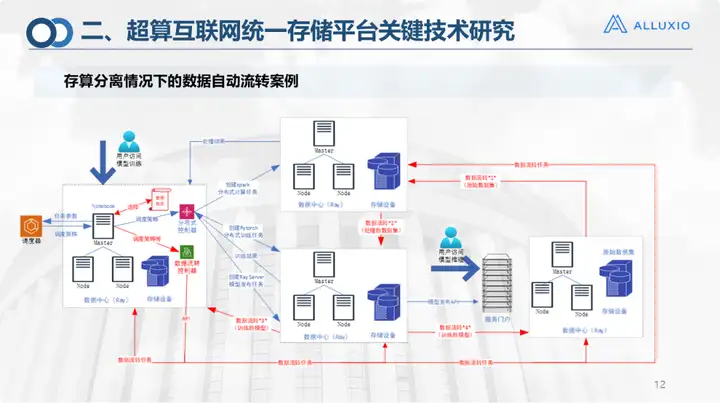
Dies ist ein Fall der automatischen Speicherübertragung und Berechnungstrennung. Dies ist natürlich auch das tatsächliche Szenario des aktuellen Smart Campus.
Unsere Speichergeräte und Rechenressourcen wurden alle auf einer einheitlichen Speicherplattform und Cloud-Plattform, einer sogenannten Multi-Cloud-Management-Plattform, verwaltet. In diesem Fall verfügt unser Computernetzwerk-Betriebssystem über einen Gesamtplan. In dieser Umgebung sind alle Daten derzeit im Rechenzentrum ganz rechts vorhanden und der Benutzer befindet sich in Jinan oder übermittelt Schulungsaufgaben Auf der Hauptplattform wird nach der Übermittlung ein allgemeiner Zeitplan erstellt, um zu bestimmen, wo die Rechenressourcen, die Vorschulungsumgebung und die Schulungsumgebung die Standorte abgrenzen und Ressourcen generieren sollen, da dieser Container je nach Bedarf automatisch generiert werden muss wird basierend auf der Datenansicht generiert (unsere in Alluxio Eine Ebene der Datenansicht wird oben erstellt). Gemäß der Datenansicht und dem Datenflusscontroller werden die Daten für das Training von der ursprünglichen Adresse zur Zieladresse migriert. Für dieses Szenario sind tatsächlich vier Flüsse erforderlich:
√ Fluss vom Originaldatensatz zum Training in der Vorverarbeitungsumgebung vor dem Training;
√ Nach der Verarbeitung müssen Sie zum Training in die Trainingsumgebung gehen.
√ Schließlich muss das Modell an den Benutzer zurückgegeben werden.
√ Wenn der Benutzer es konfiguriert, muss es vor der Durchführung von Inferenzoperationen an die endgültige Szene (z. B. einen Campus) zurückgegeben werden.
Daher haben wir den Zirkulationsprozess in mehreren spezifischen Branchenszenarien spezifiziert.
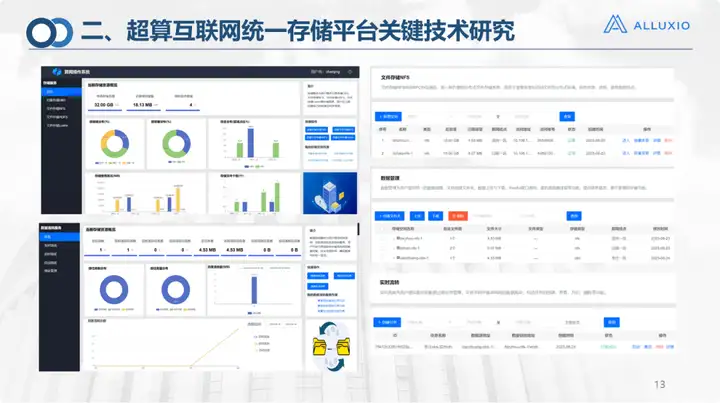
Dies ist die aktuelle Schnittstelle unserer Unified Storage Plattform V1.0. Es wurde auf dem Hauptportal veröffentlicht, einschließlich des Serviceportals und des Verwaltungsportals. Das Serviceportal verfügt über insgesamt 6 Module und mehr als 20 Untermodule.
Für die Unified-Storage-Plattform müssen wir noch Folgearbeiten durchführen: einschließlich der verteilten Bereitstellung von Alluxio-Master-Knoten und einer einheitlichen Planungsverwaltung auf der oberen Ebene. Dann gibt es noch das Vorabrufen von Daten, bei dem es sich um die Optimierung des Daten-Caching-Mechanismus handelt, einschließlich des Designs des Vorabrufs und der Zuordnungsregeln. Und was noch wichtiger ist: Wir möchten eine abgestufte Speicherung durchführen, was wir später tun müssen.
3. Anwendung und zukünftige Entwicklung des Supercomputing-Internets

Im Folgenden werden die aktuellen Anwendungen des Supercomputing-Internets in verschiedenen Branchen vorgestellt:
Wir werden uns in der zweiten Hälfte des Jahres 2022 auf die Entwicklung des Supercomputing-Internets konzentrieren, aber tatsächlich entwerfen wir das Layout bereits seit 2016, sodass wir bereits einige Anwendungen in vielen Branchen haben: darunter Ozeane, Materialien, Meteorologie und Umweltschutz. Ökologie, Industriesimulation, Bildung und andere Aspekte.
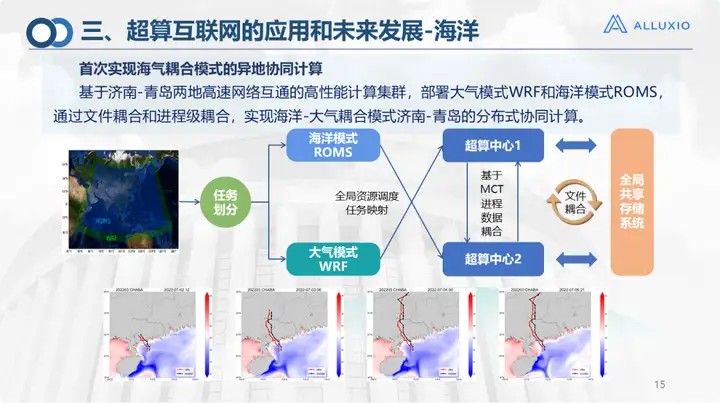
Dabei handelt es sich um das Ozeankopplungsmodell, ein miteinander verbundenes Netzwerk, das wir gemeinsam mit dem Laoshan-Labor aufgebaut haben. Wie Sie sehen, können Berechnungen im Ozean relativ kompliziert sein. Es sind Ozeanmodellrechnungen und Atmosphärenmodellrechnungen erforderlich. Das aktuelle Atmosphärenmodell wird auf dem Supercomputer von Qingdao durchgeführt, das Ozeanmodell wird auf dem Supercomputer von Jinan durchgeführt, und dann wird eine Dateikopplung durchgeführt. Dies ist das erste Mal, dass wir im Jahr 2023 kollaboratives Remote-Computing implementiert haben und gute Ergebnisse erzielt haben.

Im Bereich der Fernerkundung haben wir auch ein relativ vollständiges Datenflussszenario. Dies sind die Daten des National Earth Observation Scientific Data Center: Zuerst werden sie über eine dedizierte Leitung an den Jinan Supercomputer übertragen und dann in Blockdateien gespeichert Durch einige Sortier- und Speichervorgänge werden Datenprodukte wie Objekte erzeugt und nach der Verarbeitung gemeinsam genutzt. Dies ist auch unser erstes System zur Datenerfassung und -verarbeitung, das domänenübergreifende Speicherung und Berechnung trennt. Wir haben auch die Einrichtung des National Earth Observation Depository and Computing Center beantragt.
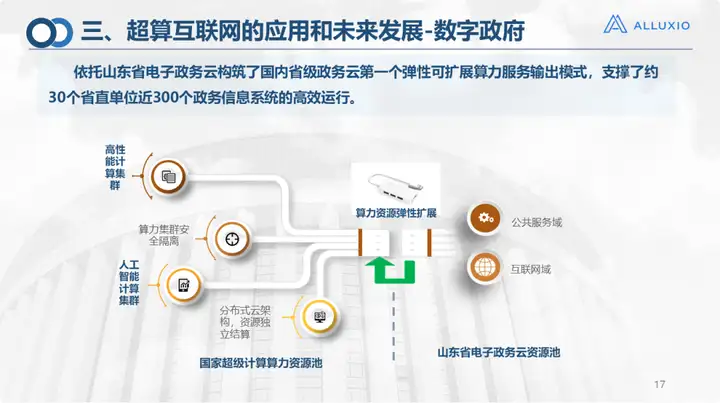
Im Bereich der digitalen Verwaltung unterstützen wir derzeit den effizienten Betrieb von 30 Provinzeinheiten und 300 Regierungssystemen in der Provinz Shandong, da E-Government selbst in unserer Einheit liegt. Dabei handelt es sich natürlich hauptsächlich um Operationen in der Cloud Ressourcen elastische Erweiterung.
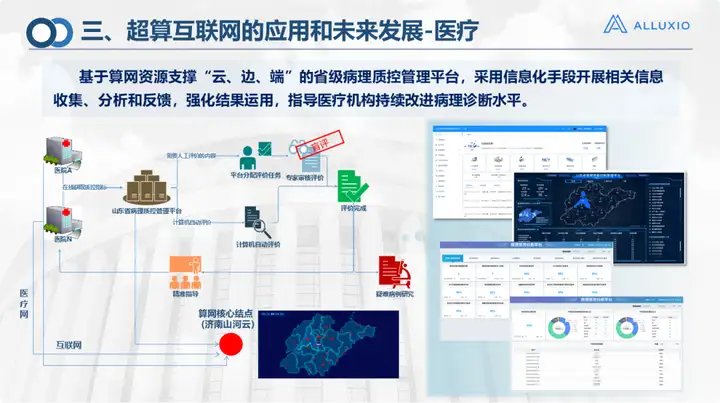
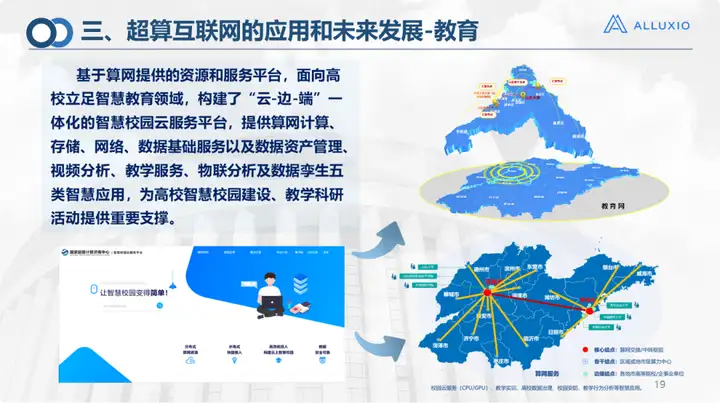
In Bereichen wie der medizinischen Versorgung und dem Bildungswesen wird hauptsächlich Cloud- und Edge-Arbeit geleistet. Es handelt sich um das von Suanwang bereitgestellte Computer- und Speichernetzwerk, einschließlich der oben erwähnten geplanten Übertragung. Im Smart-Campus-Szenario haben wir das Projekt der Qilu University of Technology durchgeführt, und wir haben mehr in Campus-Anwendungsszenarien durchgeführt.
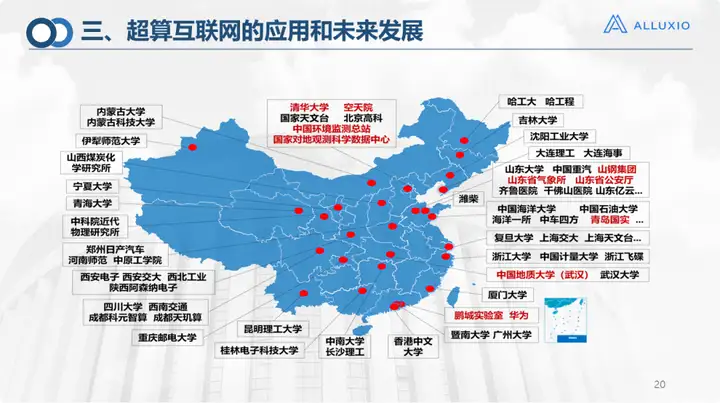
Lassen Sie mich abschließend das Unternehmen vorstellen. Unsere Bewerbungen decken mehr als 2.000 Unternehmen/Universitäten/Institutionen im ganzen Land ab und haben auch im In- und Ausland große Anerkennung gefunden. Ich denke, es ist tatsächlich notwendig, ein Rechenleistungsnetzwerk aufzubauen, das dazu beitragen wird, unseren aktuellen Bestand an Rechenleistungsressourcen wiederzubeleben. Wenn wir über ein Supercomputing-Internet verfügen, sollten wir die Nutzung von Rechenressourcen verbessern, die Monetarisierung von Rechenleistung ermöglichen und Rechenzentren, Supercomputing-Zentren und anderen Datenzentren einen nachhaltigen und gesunden Betrieb ermöglichen, und in einigen Supercomputing-Ökosystemen ist es besser Anwendungen in den Bereichen Umweltschutz, Ozeane und Fernerkundung, und ich glaube, dass es in Zukunft noch breitere Anwendungsszenarien geben wird.
