Autor: Von Elastic Craig Taverner
Elasticsearch verfügt seit Jahren über leistungsstarke Geodaten-Such- und Analysefunktionen , aber seine API unterscheidet sich stark von dem, was typische GIS-Benutzer gewohnt sind. Im vergangenen Jahr haben wir die Abfragesprache ES|QL hinzugefügt , eine Pipeline-Abfragesprache, die so einfach wie SQL, wenn nicht sogar einfacher, ist. Es eignet sich besonders gut für die Such-, Sicherheits- und Observability-Anwendungsfälle, in denen sich Elastic auszeichnet. Wir haben außerdem Unterstützung für die Geodatensuche und -analyse in ES|QL hinzugefügt, was die Verwendung noch einfacher macht, insbesondere für Benutzer aus der SQL- oder GIS- Community.
Elasticsearch 8.12 und 8.13 bieten grundlegende Unterstützung für Geodatentypen in ES|QL. Diese Funktionalität wird durch die Hinzufügung von Geodatensuchfunktionen in 8.14 erheblich erweitert. Noch wichtiger ist, dass diese Unterstützung eng an den Simple Feature Access (OGC)-Standard des Open Geospatial Consortium ( OGC) angelehnt ist , der von anderen räumlichen Datenbanken wie PostGIS verwendet wird, was die Verwendung für GIS-Experten, die mit diesen Standards vertraut sind, erleichtert.
In diesem Blogbeitrag zeigen wir Ihnen, wie Sie Geodatensuchen mit ES|QL durchführen und wie es im Vergleich zu seinen SQL- und Query-DSL-Äquivalenten abschneidet. Außerdem zeigen wir Ihnen, wie Sie mit ES|QL räumliche Verknüpfungen durchführen und die Ergebnisse in Kibana Maps visualisieren. Bitte beachten Sie, dass sich alle hier beschriebenen Funktionen im Status „Technische Vorschau“ befinden und wir uns über Ihr Feedback zur Verbesserung dieser Funktionen freuen würden.
Daten vorbereiten
Wir können die in diesem Tutorial verwendeten Daten von folgendem Ort herunterladen:
git clone https://github.com/liu-xiao-guo/esqlDas von uns verwendete Dokument ist esql/airport_city_boundaries.csv unter main · liu-xiao-guo/esql · GitHub
Anschließend öffnen wir Kibana:
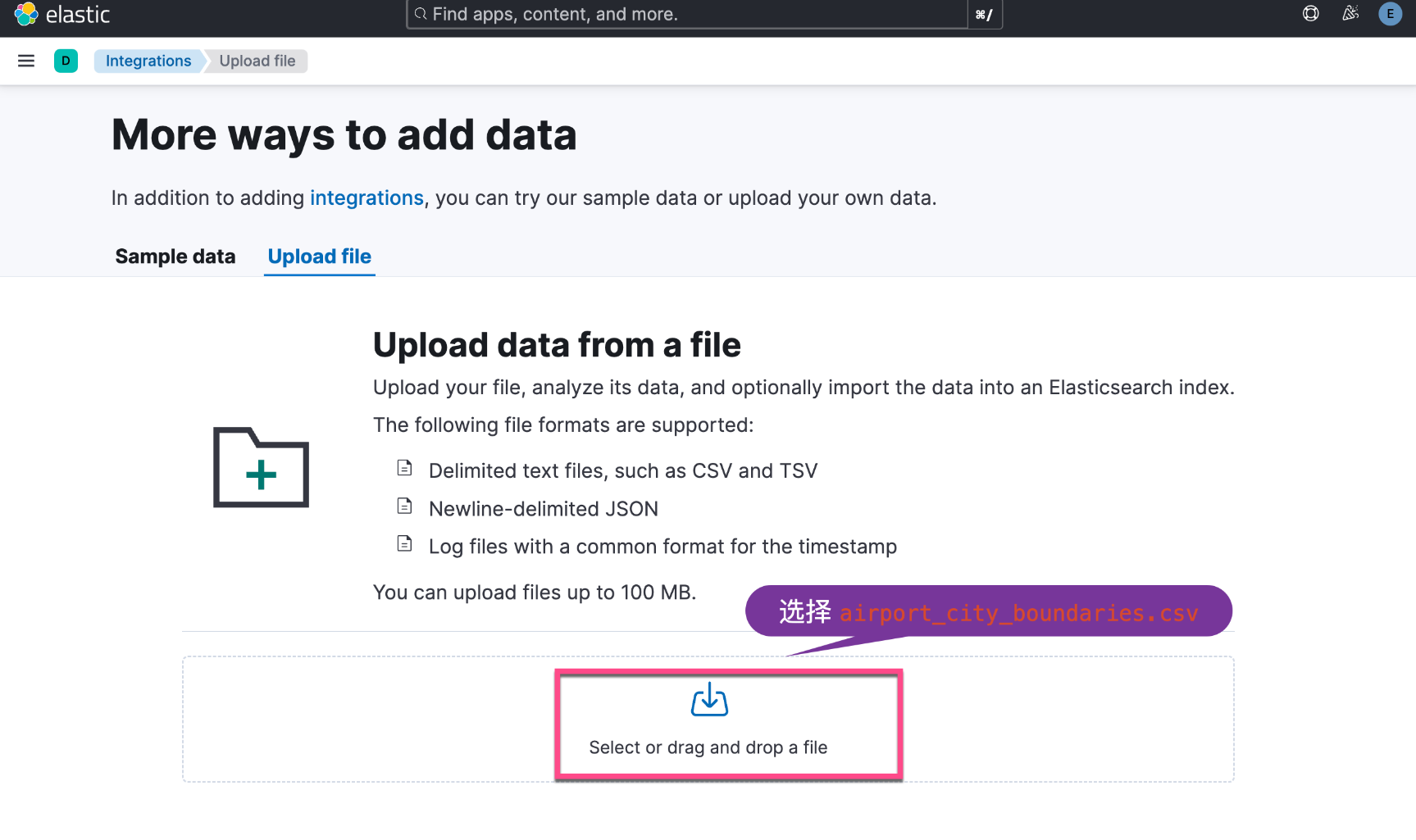
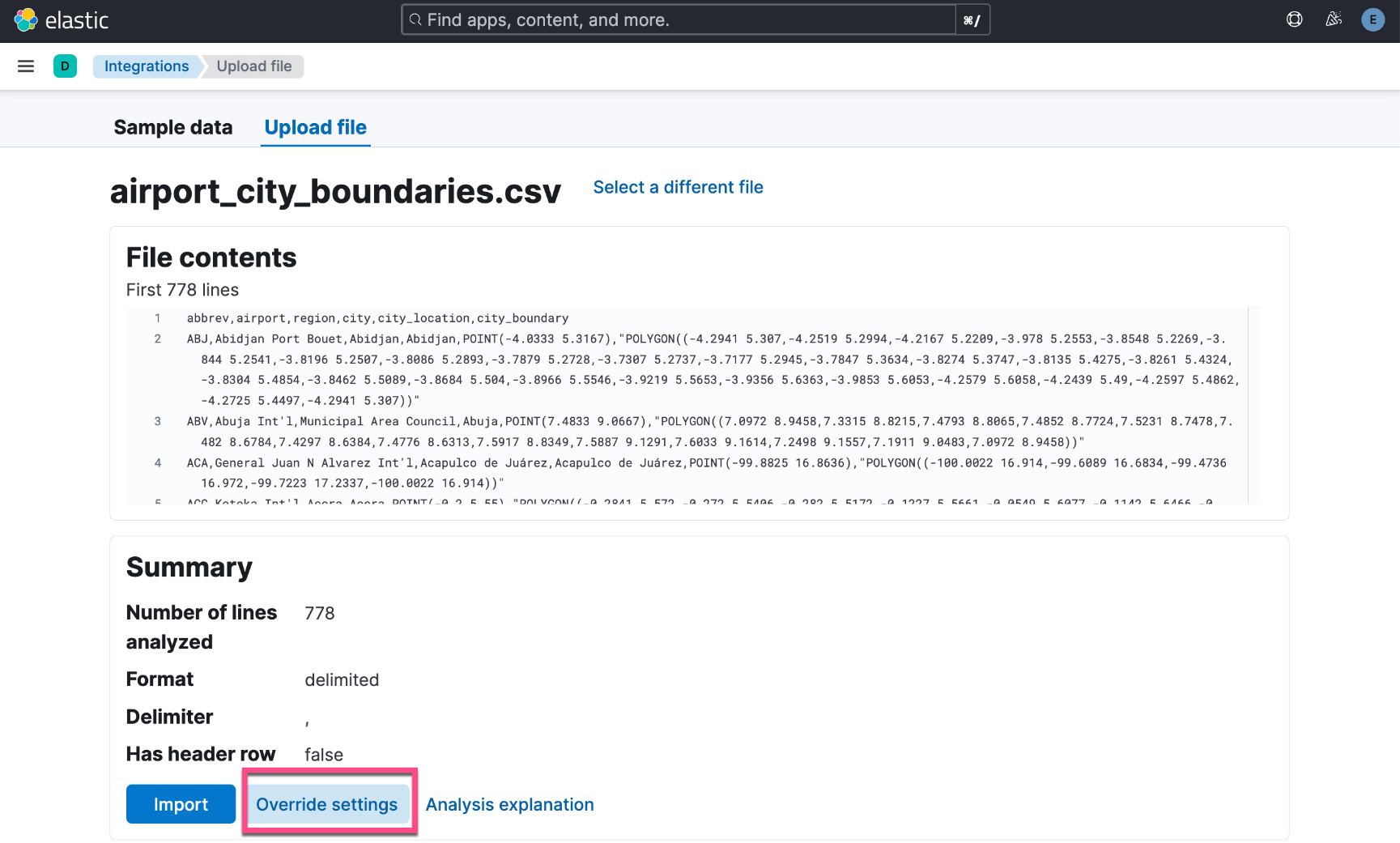
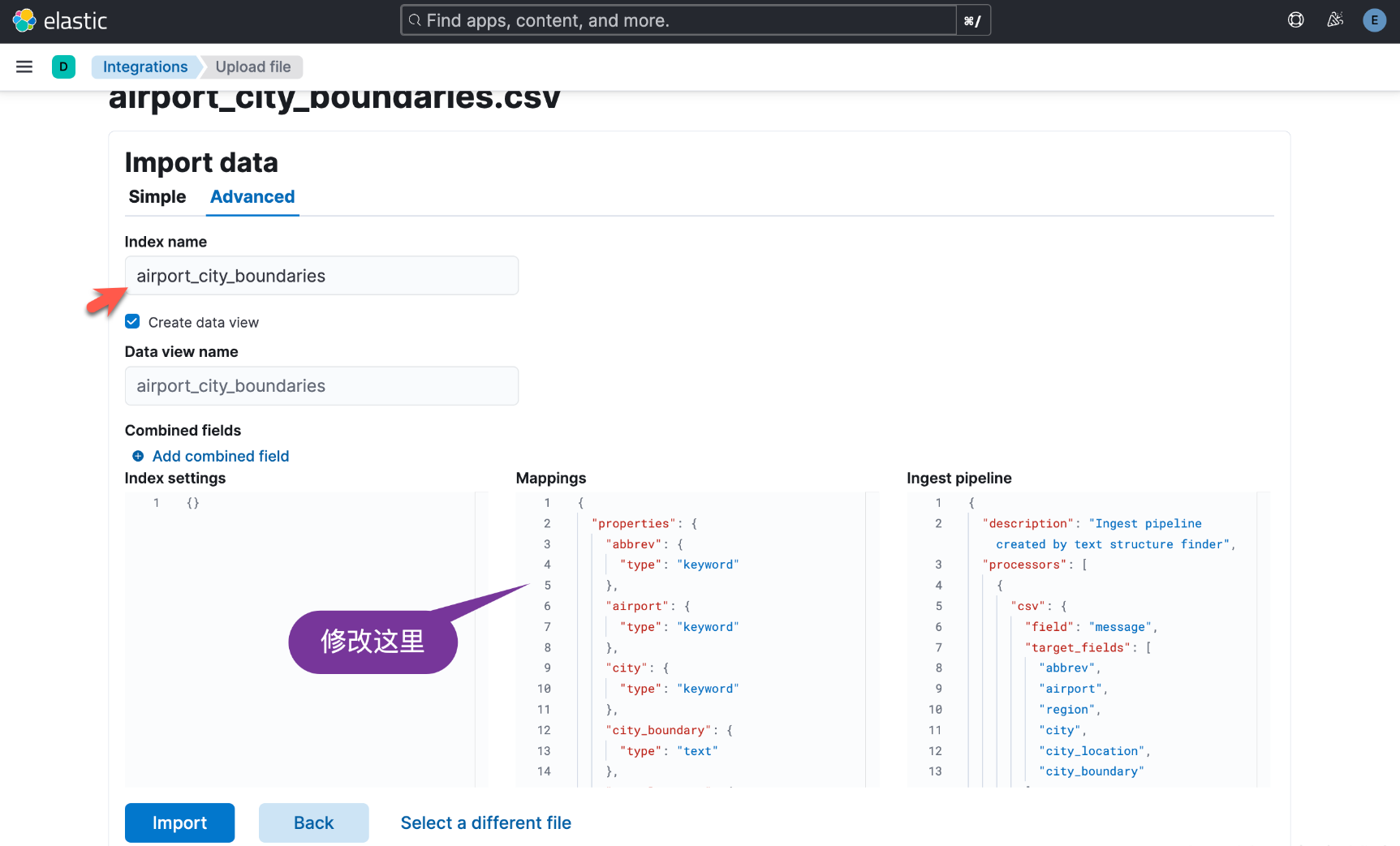
Oben haben wir den Indexnamen auf „airport_city_boundaries“ festgelegt.
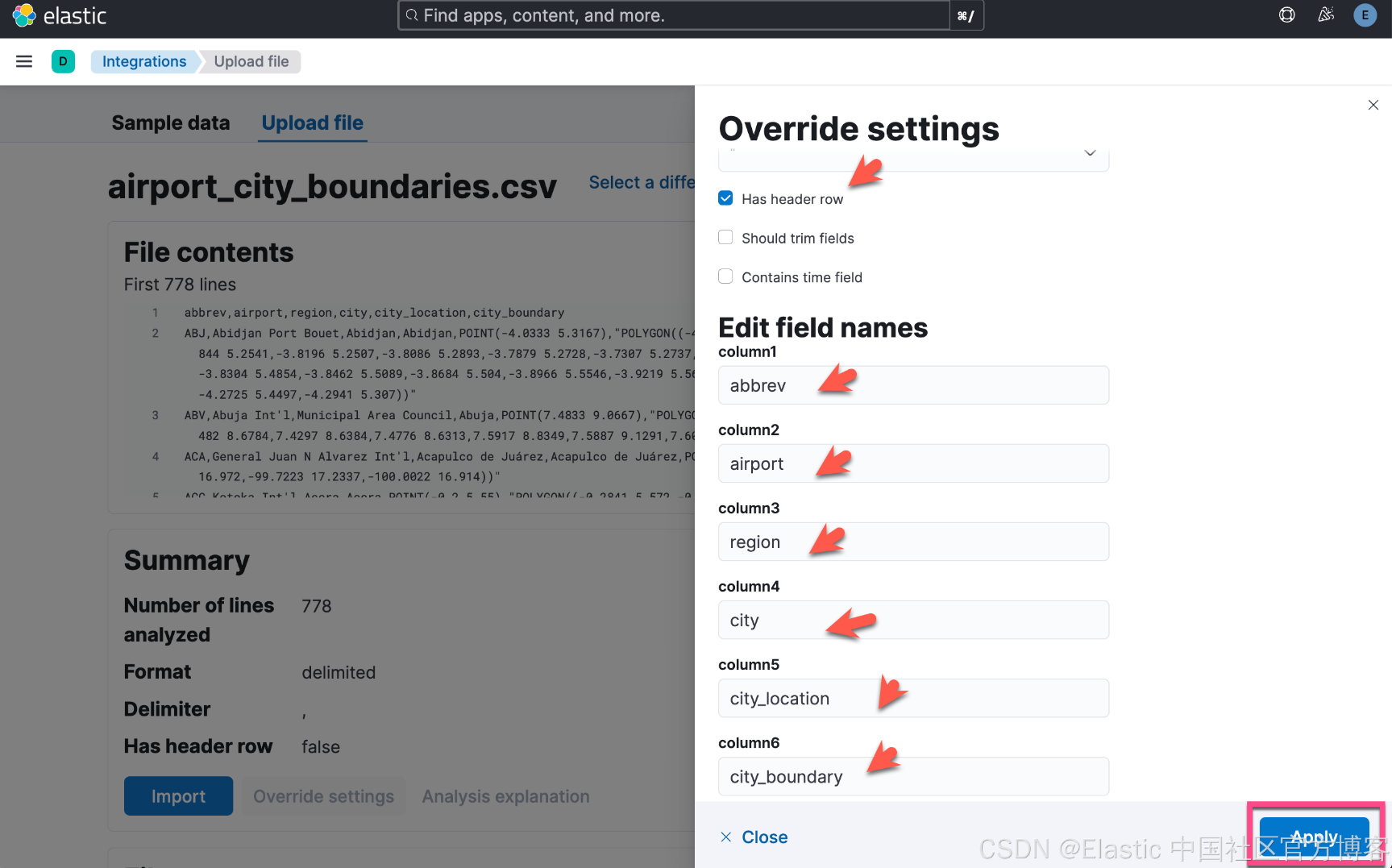
Wir ändern die obigen Zuordnungen wie folgt:
"properties": {
"abbrev": {
"type": "keyword"
},
"airport": {
"type": "text"
},
"city": {
"type": "keyword"
},
"city_boundary": {
"type": "geo_shape"
},
"city_location": {
"type": "geo_point"
},
"region": {
"type": "text"
}
}
}
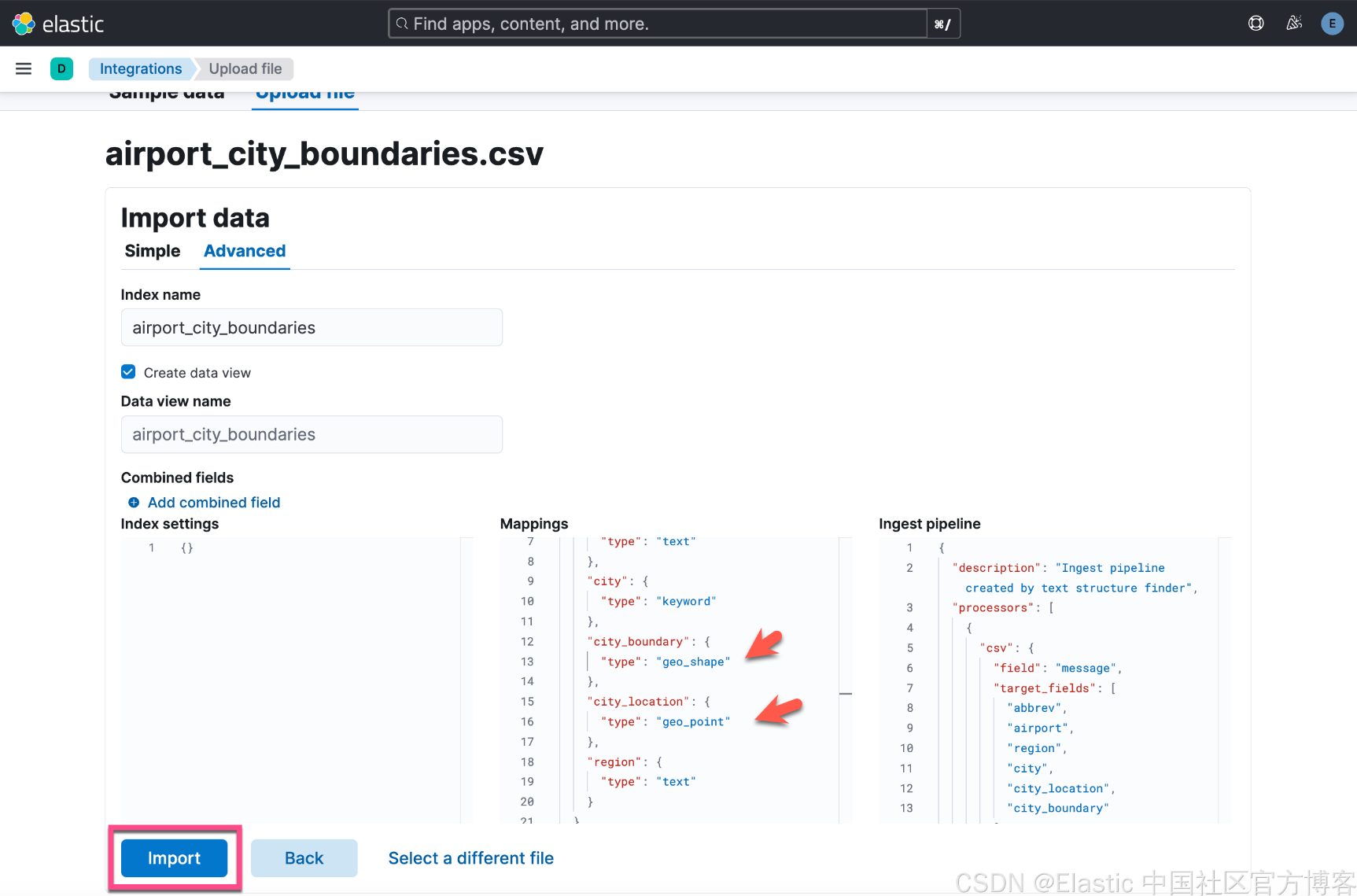
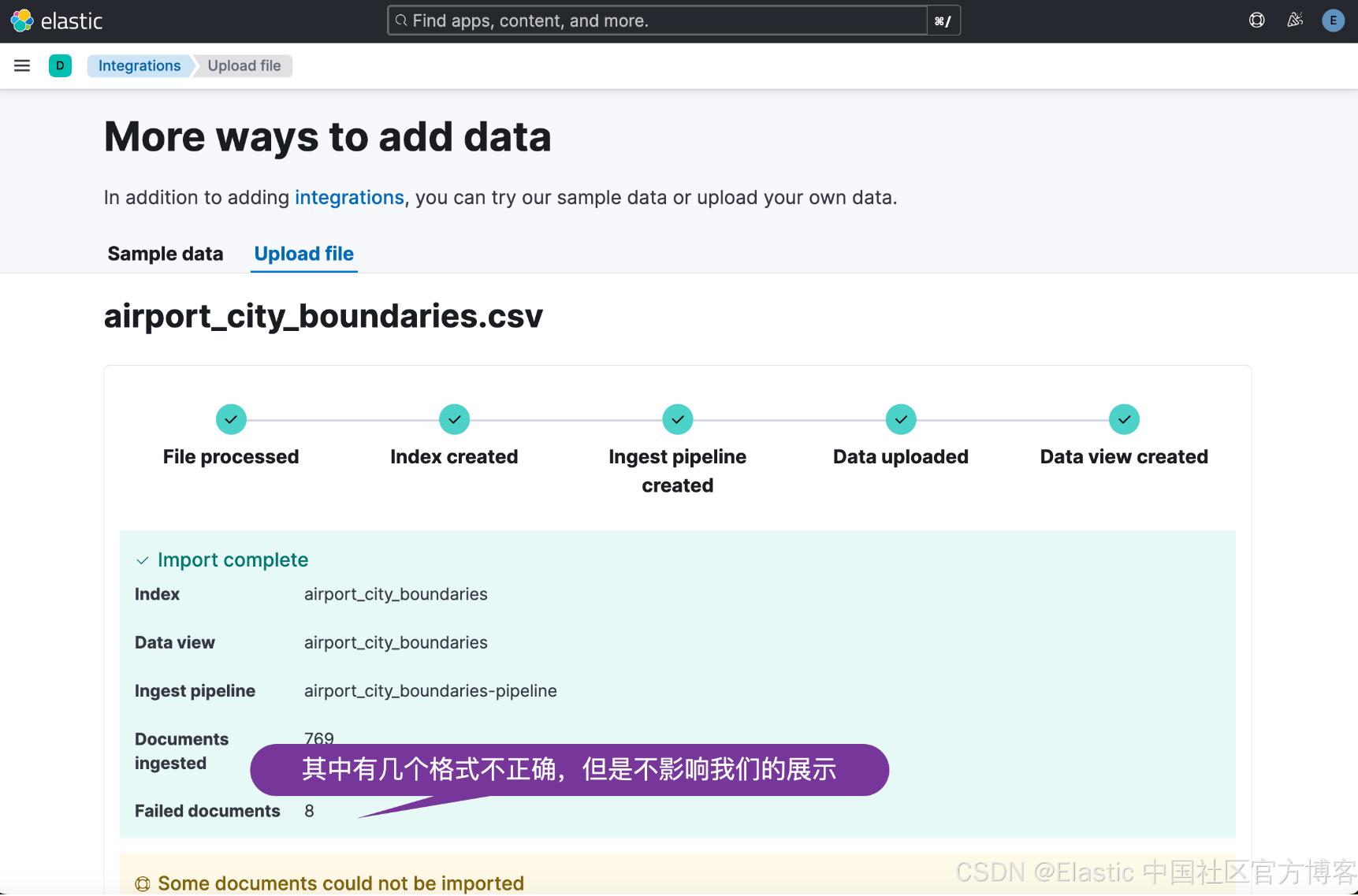
Wie oben gezeigt, haben wir 769 Dokumente erfolgreich geschrieben.
Suchen Sie nach Geodaten
Beginnen wir mit einer Beispielabfrage:
FROM airport_city_boundaries
| WHERE ST_INTERSECTS(
city_boundary,
"POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))"::geo_shape
)
| KEEP abbrev, airport, region, city, city_location
Dadurch wird nach jedem Stadtgrenzenpolygon gesucht, das das rechteckige Suchpolygon rund um den Sanya Phoenix International Airport (SYX) schneidet.
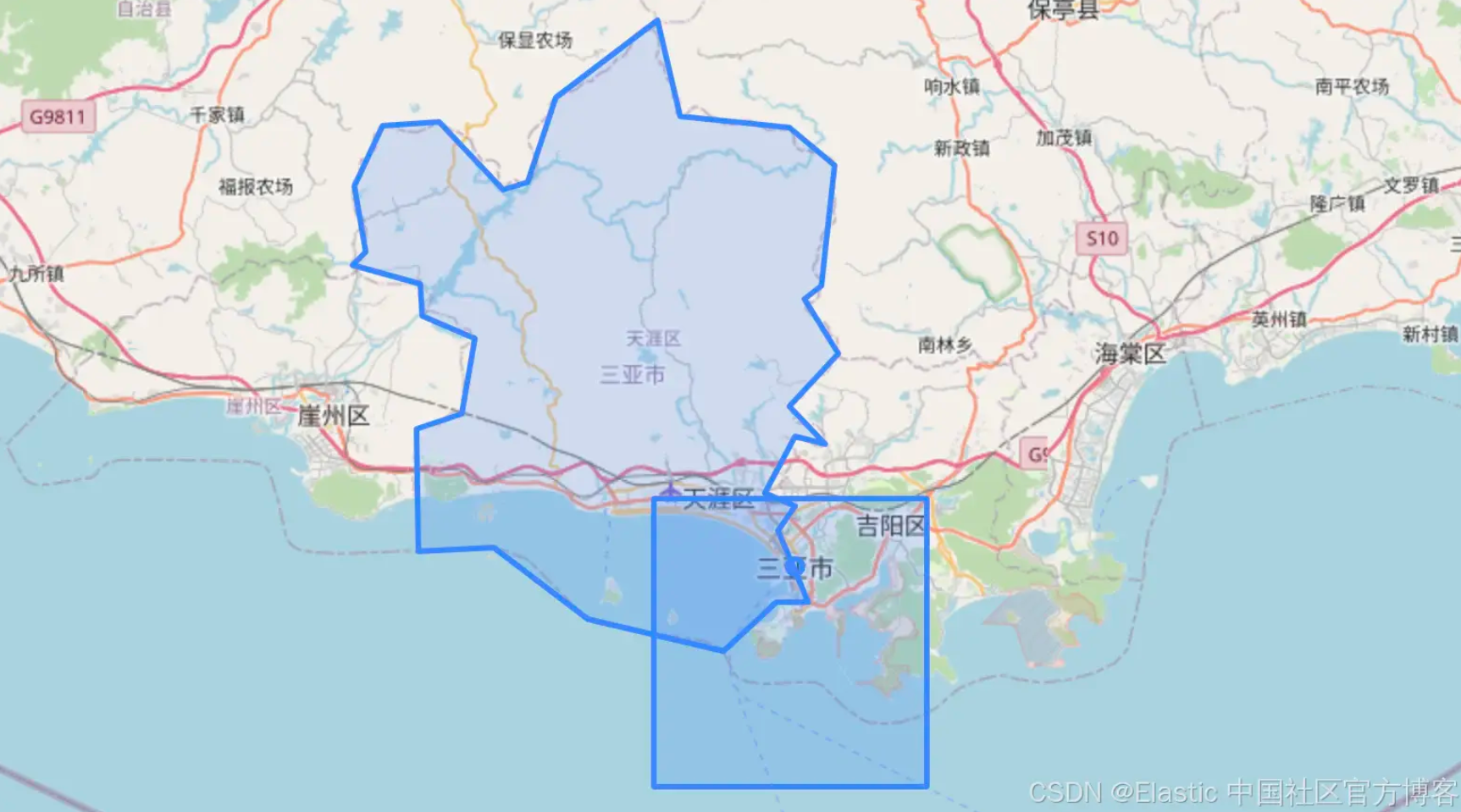
Im Beispieldatensatz von Flughäfen, Städten und Stadtgrenzen findet diese Suche sich überschneidende Polygone und gibt die erforderlichen Felder aus den übereinstimmenden Dokumenten zurück:
| Abkürzung | Flughafen | Region | Stadt | Ort |
|---|---|---|---|---|
| SYX | Sanya Phoenix International | Bezirk Tianya | Platzieren Sie es | PUNKT(109.5036 18.2533) |
Es ist ganz einfach! Vergleichen Sie dies nun mit der klassischen Elasticsearch-Abfrage DSL für dieselbe Abfrage:
GET /airport_city_boundaries/_search
{
"_source": ["abbrev", "airport", "region", "city", "city_location"],
"query": {
"geo_shape": {
"city_boundary": {
"shape": {
"type": "polygon",
"coordinates" : [[
[109.4, 18.1],
[109.6, 18.1],
[109.6, 18.3],
[109.4, 18.3],
[109.4, 18.1]
]]
}
}
}
}
}
Der Zweck beider Abfragen ist ziemlich klar, aber ES|QL-Abfragen sind SQL sehr ähnlich. Die gleiche Abfrage in PostGIS sieht so aus:
SELECT abbrev, airport, region, city, city_location
FROM airport_city_boundaries
WHERE ST_INTERSECTS(
city_boundary,
'SRID=4326;POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))'::geometry
);
Sehen wir uns das ES|QL-Beispiel an. Ziemlich ähnlich, oder?
FROM airport_city_boundaries
| WHERE ST_INTERSECTS(
city_boundary,
"POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))"::geo_shape
)
| KEEP abbrev, airport, region, city, city_location
Wir haben festgestellt, dass bestehende Benutzer der Elasticsearch-API die Verwendung von ES|QL als einfacher empfinden. Wir gehen nun davon aus, dass bestehende SQL-Benutzer (insbesondere Spatial SQL-Benutzer) ES|QL als sehr ähnlich empfinden werden, wie sie es gewohnt sind.
Warum nicht SQL verwenden?
Was ist mit Elasticsearch SQL? Es gibt es schon seit einiger Zeit und es verfügt über einige Geodatenfunktionen. Allerdings ist Elasticsearch SQL als Wrapper über der Rohabfrage-API geschrieben, was bedeutet, dass nur Abfragen unterstützt werden, die in die Roh-API konvertiert werden können. Für ES|QL gilt diese Einschränkung nicht. Als völlig neuer Stack ermöglicht er viele Optimierungen, die in SQL nicht möglich sind. Unsere Benchmarks zeigen, dass ES|QL oft schneller ist als die Abfrage-API , insbesondere bei Aggregationen!
Unterschiede zu SQL
Offensichtlich ähnelt ES|QL im vorherigen Beispiel etwas SQL, es gibt jedoch einige wichtige Unterschiede. Beispielsweise ist ES|QL eine Pipeline-Abfragesprache, die mit einem Quellbefehl wie FROM beginnt und dann alle nachfolgenden Befehle mit dem Pipe-Zeichen | verknüpft. Dies macht es leicht zu verstehen, wie jeder Befehl eine Datentabelle empfängt und einen Vorgang für diese Tabelle ausführt, z. B. das Filtern mit WHERE, das Hinzufügen einer Spalte mit EVAL oder das Durchführen einer Aggregation mit STATS. Anstatt mit SELECT zu beginnen und die endgültigen Ausgabespalten zu definieren , kann es einen oder mehrere KEEP-Befehle geben, von denen der letzte die endgültige Ausgabe angibt. Diese Struktur vereinfacht die Argumentation bei Abfragen.
Wenn wir uns auf den WHERE-Befehl im obigen Beispiel konzentrieren, können wir sehen, dass er dem PostGIS-Beispiel sehr ähnlich ist:
EN|QL
WHERE ST_INTERSECTS(
city_boundary,
"POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))"::geo_shape
)
PostGIS
WHERE ST_INTERSECTS(
city_boundary,
'SRID=4326;POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))'::geometry
)
Neben dem Unterschied bei den Anführungszeichen für Zeichenfolgen besteht der größte Unterschied darin, wie wir die Zeichenfolge in einen Leerzeichentyp umwandeln. In PostGIS verwenden wir das Suffix ::geometry und in ES|QL das Suffix ::geo_shape. Dies liegt daran, dass ES|QL in Elasticsearch ausgeführt wird und der Typkonvertierungsoperator:: verwendet werden kann, um eine Zeichenfolge in einen beliebigen unterstützten ES|QL-Typ, in diesem Fall geo_shape, zu konvertieren. Darüber hinaus implizieren die Typen geo_shape und geo_point in Elasticsearch ein räumliches Koordinatensystem namens WGS84, das üblicherweise durch die SRID-Nummer 4326 dargestellt wird. In PostGIS muss dies explizit angegeben werden, daher wird der WKT-Zeichenfolge SRID=4326; vorangestellt. Wenn Sie das Präfix entfernen, wird die SRID auf 0 gesetzt, was eher den Elasticsearch-Typen „cartesian_point“ und „cartesian_shape“ ähnelt, die nicht an ein bestimmtes Koordinatensystem gebunden sind.
Sowohl ES|QL als auch PostGIS bieten die Syntax der Typkonvertierungsfunktion:
EN|QL
WHERE ST_INTERSECTS(
city_boundary,
TO_GEOSHAPE("POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))")
)
PostGIS
WHERE ST_INTERSECTS(
city_boundary,
ST_SetSRID(
ST_GeomFromText('POLYGON((109.4 18.1, 109.6 18.1, 109.6 18.3, 109.4 18.3, 109.4 18.1))'),
4326
)
)
OGC-Funktionen
Elasticsearch 8.14 führt die folgenden vier räumlichen OGC-Suchfunktionen ein:
| EN|QL | PostGIS | Beschreibung |
|---|---|---|
| ST_INTERSECTS | ST_Intersects | Gibt true zurück, wenn sich zwei Geometrien schneiden, andernfalls false. |
| ST_DISJOINT | ST_Disjoint | Gibt true zurück, wenn sich die beiden Geometrien nicht schneiden, andernfalls false. Das Gegenteil von ST_INTERSECTS. |
| ST_CONTAINS | ST_Contains | Gibt true zurück, wenn eine Geometrie eine andere Geometrie enthält, andernfalls false. |
| ST_INNERHALB | ST_Within | Gibt true zurück, wenn eine Geometrie innerhalb einer anderen Geometrie liegt, andernfalls false. Inverse Operation von ST_CONTAINS. |
Diese Funktionen verhalten sich ähnlich wie ihre PostGIS-Gegenstücke und können auf die gleiche Weise verwendet werden. ST_INTERSECTS gibt beispielsweise true zurück, wenn sich zwei Geometrien schneiden, andernfalls false. Wenn Sie auf die Dokumentationslinks in der Tabelle oben klicken, werden Sie möglicherweise feststellen, dass alle ES|QL-Beispiele in der WHERE-Klausel nach der FROM-Klausel stehen, während alle PostGIS-Beispiele literale Geometrien verwenden. Tatsächlich unterstützen beide Plattformen die Verwendung dieser Funktionen in jedem Teil einer Abfrage.
Das erste Beispiel für ST_INTERSECTS in der PostGIS-Dokumentation ist:
SELECT ST_Intersects(
'POINT(0 0)'::geometry,
'LINESTRING ( 2 0, 0 2 )'::geometry
);
Die entsprechende Version in ES|QL ist:
ROW ST_INTERSECTS(
"POINT(0 0)"::geo_point,
"LINESTRING ( 2 0, 0 2 )"::geo_shape
)
Beachten Sie, dass wir im PostGIS-Beispiel keine SRID angegeben haben. Dies liegt daran, dass bei der Verwendung von Geometrietypen in PostGIS alle Berechnungen auf einem planaren Koordinatensystem durchgeführt werden. Wenn also zwei Geometrien dieselbe SRID haben, spielt es keine Rolle, welche SRID ist. In Elasticsearch gilt dies auch für die meisten Funktionen, allerdings gibt es Ausnahmen, bei denen geo_shape und geo_point sphärische Berechnungen verwenden, wie wir im nächsten Blog über räumliche Distanzsuchen sehen werden.
ES|QL Vielseitigkeit
Wir haben also das obige Beispiel der Verwendung räumlicher Funktionen in der WHERE-Klausel und dem ROW-Befehl gesehen. Wo sonst können sie nützlich sein? Eine sehr nützliche Stelle ist der EVAL-Befehl. Mit diesem Befehl können Sie einen Ausdruck auswerten und das Ergebnis zurückgeben. Lassen Sie uns beispielsweise feststellen, ob die Schwerpunkte aller nach Ländernamen gruppierten Flughäfen innerhalb der Grenzen des Landes liegen:
FROM airports
| EVAL in_uk = ST_INTERSECTS(location, TO_GEOSHAPE("POLYGON((1.2305 60.8449, -1.582 61.6899, -10.7227 58.4017, -7.1191 55.3291, -7.9102 54.2139, -5.4492 54.0078, -5.2734 52.3756, -7.8223 49.6676, -5.0977 49.2678, 0.9668 50.5134, 2.5488 52.1065, 2.6367 54.0078, -0.9668 56.4625, 1.2305 60.8449))"))
| EVAL in_iceland = ST_INTERSECTS(location, TO_GEOSHAPE("POLYGON ((-25.4883 65.5312, -23.4668 66.7746, -18.4131 67.4749, -13.0957 66.2669, -12.3926 64.4159, -20.1270 62.7346, -24.7852 63.3718, -25.4883 65.5312))"))
| EVAL within_uk = ST_WITHIN(location, TO_GEOSHAPE("POLYGON((1.2305 60.8449, -1.582 61.6899, -10.7227 58.4017, -7.1191 55.3291, -7.9102 54.2139, -5.4492 54.0078, -5.2734 52.3756, -7.8223 49.6676, -5.0977 49.2678, 0.9668 50.5134, 2.5488 52.1065, 2.6367 54.0078, -0.9668 56.4625, 1.2305 60.8449))"))
| EVAL within_iceland = ST_WITHIN(location, TO_GEOSHAPE("POLYGON ((-25.4883 65.5312, -23.4668 66.7746, -18.4131 67.4749, -13.0957 66.2669, -12.3926 64.4159, -20.1270 62.7346, -24.7852 63.3718, -25.4883 65.5312))"))
| STATS centroid = ST_CENTROID_AGG(location), count=COUNT() BY in_uk, in_iceland, within_uk, within_iceland
| SORT count ASC
Die Ergebnisse sind wie erwartet, wobei die Schwerpunkte der britischen Flughäfen innerhalb der britischen Grenzen und nicht innerhalb der isländischen Grenzen liegen und umgekehrt:
| Schwerpunkt | zählen | in_uk | in_iceland | innerhalb_uk | innerhalb_Islands |
|---|---|---|---|---|---|
| PUNKT (-21.946634463965893 64.13187285885215) | 1 | FALSCH | WAHR | FALSCH | WAHR |
| PUNKT (-2.597342072712148 54.33551226578214) | 17 | WAHR | FALSCH | WAHR | FALSCH |
| PUNKT (0,04453958108176276 23,74658354606057) | 873 | FALSCH | FALSCH | FALSCH | FALSCH |
Tatsächlich können diese Funktionen in jedem Teil der Abfrage verwendet werden, solange ihre Signatur sinnvoll ist. Beide akzeptieren zwei Argumente, entweder ein literales räumliches Objekt oder ein Feld vom Typ „räumlich“, und beide geben einen booleschen Wert zurück. Eine wichtige Überlegung ist, dass das Koordinatenreferenzsystem (CRS) der Geometrie übereinstimmen muss, andernfalls wird ein Fehler zurückgegeben. Das bedeutet, dass Sie die Typen „geo_shape“ und „cartesian_shape“ nicht im selben Funktionsaufruf mischen können. Sie können jedoch die Typen geo_point und geo_shape mischen, da der Typ geo_point ein Sonderfall des Typs geo_shape ist und beide dasselbe Koordinatenreferenzsystem verwenden. Die Dokumentation für jede oben definierte Funktion listet die unterstützten Typkombinationen auf.
Darüber hinaus kann jeder Parameter in beliebiger Reihenfolge ein Leerzeichenliteral oder ein Feld sein. Sie können sogar zwei Felder, zwei Texte, ein Feld und einen Text oder einen Text und ein Feld angeben. Die einzige Voraussetzung ist die Typkompatibilität. Diese Abfrage vergleicht beispielsweise zwei Felder im selben Index:
FROM airport_city_boundaries
| EVAL in_city = ST_INTERSECTS(city_location, city_boundary)
| STATS count=COUNT(*) BY in_city
| SORT count ASC
| EVAL cardinality = CASE(count < 10, "very few", count < 100, "few", "many")
| KEEP cardinality, count, in_city
Bei der Abfrage wird grundsätzlich gefragt, ob der Standort der Stadt innerhalb der Stadtgrenzen liegt, was im Allgemeinen korrekt sein sollte, es gibt jedoch immer Ausnahmen:
| Kardinalität | zählen | in_stadt |
|---|---|---|
| wenige | 29 | FALSCH |
| viele | 740 | WAHR |
Eine interessantere Frage ist, ob der Flughafenstandort innerhalb der Grenzen der vom Flughafen bedienten Stadt liegt. Der Standort des Flughafens befindet sich jedoch in einem anderen Index als der, der die Stadtgrenzen enthält. Dies erfordert eine Möglichkeit, Daten in diesen beiden unabhängigen Indizes effizient abzufragen und zu korrelieren.
räumliche Verbindungen
ES|QL unterstützt den JOIN-Befehl nicht, aber Sie können den ENRICH-Befehl verwenden , um einen Sonderfall von Joins zu implementieren, der sich in SQL wie ein „Links-Join“ verhält. Dieser Befehl funktioniert wie ein „Links-Join“ in SQL und ermöglicht Ihnen die Anreicherung von Ergebnissen aus einem Index mit Daten aus einem anderen Index basierend auf der räumlichen Beziehung zwischen den beiden Datensätzen.
Lassen Sie uns beispielsweise die Ergebnisse der Flughafentabelle anreichern, indem wir Stadtgrenzen finden, die Flughafenstandorte enthalten, mit zusätzlichen Informationen über die vom Flughafen bedienten Städte und dann einige Statistiken zu den Ergebnissen erstellen:
FROM airports
| ENRICH city_boundaries ON city_location WITH airport, region, city_boundary
| MV_EXPAND city_boundary
| EVAL boundary_wkt_length = LENGTH(TO_STRING(city_boundary))
| STATS centroid = ST_CENTROID_AGG(location), count = COUNT(city_location), min_wkt = MIN(boundary_wkt_length), max_wkt = MAX(boundary_wkt_length) BY region
| SORT count DESC
| LIMIT 5
Dadurch werden die Top-5-Regionen mit den meisten Flughäfen zusammen mit den Schwerpunkten aller Flughäfen mit passenden Regionen und dem Längenbereich der WKT-Darstellungen der Stadtgrenzen innerhalb dieser Regionen zurückgegeben:
| Schwerpunkt | zählen | my_wkt | max_wkt | Region |
|---|---|---|---|---|
| PUNKT (-32.56093470960719 32.598117914802714) | 90 | 207 | 207 | Null |
| PUNKT (-73.94515332765877 40.70366442203522) | 9 | 438 | 438 | Stadt New York |
| PUNKT (-83.10398317873478 42.300230911932886) | 9 | 473 | 473 | Detroit |
| PUNKT (-156.3020245861262 20.176383580081165) | 5 | 307 | 803 | Hawaii |
| PUNKT (-73.88902732171118 45.57078813901171) | 4 | 837 | 837 | Montreal |
Also, was genau ist hier los? Wo findet der sogenannte JOIN statt? Der Schlüssel zur Abfrage liegt im ENRICH-Befehl:
FROM airports
| ENRICH city_boundaries ON city_location WITH airport, region, city_boundary
Dieser Befehl weist Elasticsearch an, die aus dem Flughafenindex abgerufenen Ergebnisse anzureichern und einen Schnittpunkt-Join zwischen dem Feld „city_location“ des ursprünglichen Index und dem Feld „city_boundary“ des Index „airport_city_boundaries“ durchzuführen, den wir in mehreren vorherigen Beispielen verwendet haben. Einige dieser Informationen sind in dieser Abfrage jedoch nicht klar erkennbar. Was wir sehen, ist der Name der angereicherten Richtlinie „city_boundaries“, und die fehlenden Informationen sind in der Richtliniendefinition gekapselt.
{
"geo_match": {
"indices": "airport_city_boundaries",
"match_field": "city_boundary",
"enrich_fields": ["city", "airport", "region", "city_boundary"]
}
}
Hier können wir sehen, dass eine geo_match-Abfrage durchgeführt wird (standardmäßig überschneidet), die abzugleichenden Felder sind „city_boundary“ und „rich_fields“ sind die Felder, die wir dem Originaldokument hinzufügen möchten. Eines der Felder, die Region, wird tatsächlich als Gruppierungsschlüssel für den STATS-Befehl verwendet, was ohne diese „Linksverknüpfungs“-Funktion nicht möglich wäre. Weitere Informationen zu Anreicherungsstrategien finden Sie in der Anreicherungsdokumentation . Wenn Sie diese Dokumente durchlesen, werden Sie feststellen, dass sie die Verwendung umfangreicher Indizes zum Anreichern von Daten zum Zeitpunkt des Indexierens durch Konfigurieren der Aufnahmepipeline beschreiben. Dies ist für ES|QL nicht erforderlich, da der ENRICH-Befehl zur Abfragezeit funktioniert. Es reicht aus, den Rich-Index mit den erforderlichen Daten und der Anreicherungsstrategie vorzubereiten und dann den ENRICH-Befehl in der ES|QL-Abfrage zu verwenden.
Möglicherweise stellen Sie auch fest, dass das häufigste Feld null ist. was bedeutet das? Erinnern Sie sich daran, dass ich diesen Befehl mit einem „Links-Join“ in SQL verglichen habe, was bedeutet, dass, wenn für einen Flughafen keine passenden Stadtgrenzen gefunden werden, der Flughafen immer noch zurückgegeben wird, der Feldwert im Index „airport_city_boundaries“ jedoch null ist. Es wurde festgestellt, dass 89 Flughäfen keine passenden Stadtgrenzen hatten und ein Flughafen ein Null-Match-Regionsfeld aufwies. Dies führte zu 90 Flughäfen ohne Regionen in den Ergebnissen. Ein weiteres interessantes Detail ist die Notwendigkeit des Befehls MV_EXPAND. Dies ist notwendig, da der ENRICH-Befehl möglicherweise mehrere Ergebnisse für jede Eingabezeile zurückgibt und MV_EXPAND dabei hilft, diese Ergebnisse in mehrere Zeilen aufzuteilen, eine für jedes Ergebnis. Dies erklärt auch, warum „Hawaii“ unterschiedliche min_wkt- und max_wkt-Ergebnisse anzeigt: Es gibt mehrere Regionen mit demselben Namen, aber unterschiedlichen Grenzen.
Kibana-Karte
Kibana fügt der Kartenanwendung Unterstützung für Spatial ES|QL hinzu. Das bedeutet, dass Sie ES|QL jetzt verwenden können, um Geodaten in Elasticsearch zu durchsuchen und die Ergebnisse auf einer Karte zu visualisieren.
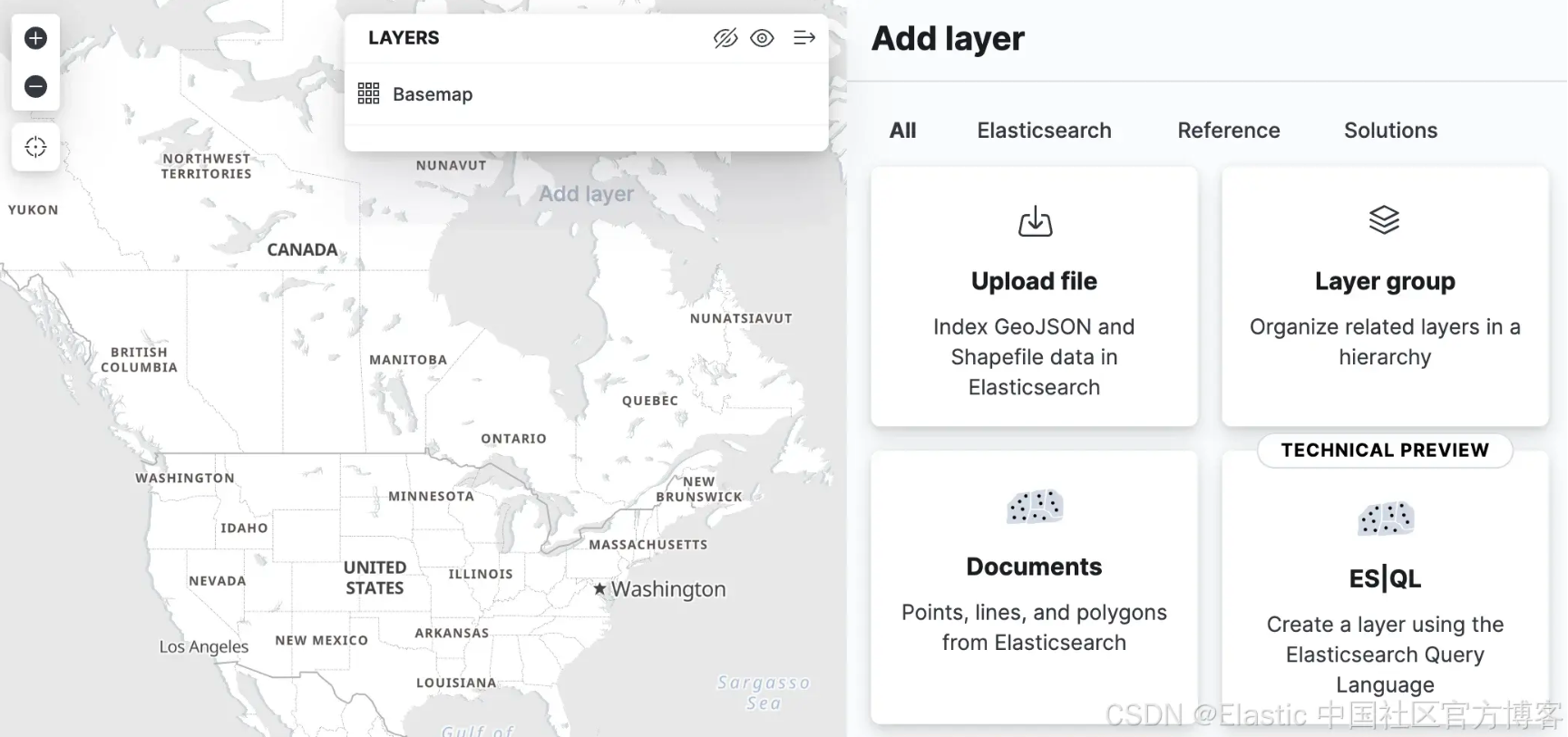
Im Menü „Ebene hinzufügen“ gibt es eine neue Ebenenoption namens „ES|QL“. Wie alle bisher beschriebenen Geodatenfunktionen befindet sich diese Option im Status „Technische Vorschau“. Wenn Sie diese Option auswählen, können Sie der Karte basierend auf den Ergebnissen einer ES|QL-Abfrage einen Layer hinzufügen. Beispielsweise könnten Sie Ihrer Karte eine Ebene hinzufügen, die alle Flughäfen der Welt anzeigt.
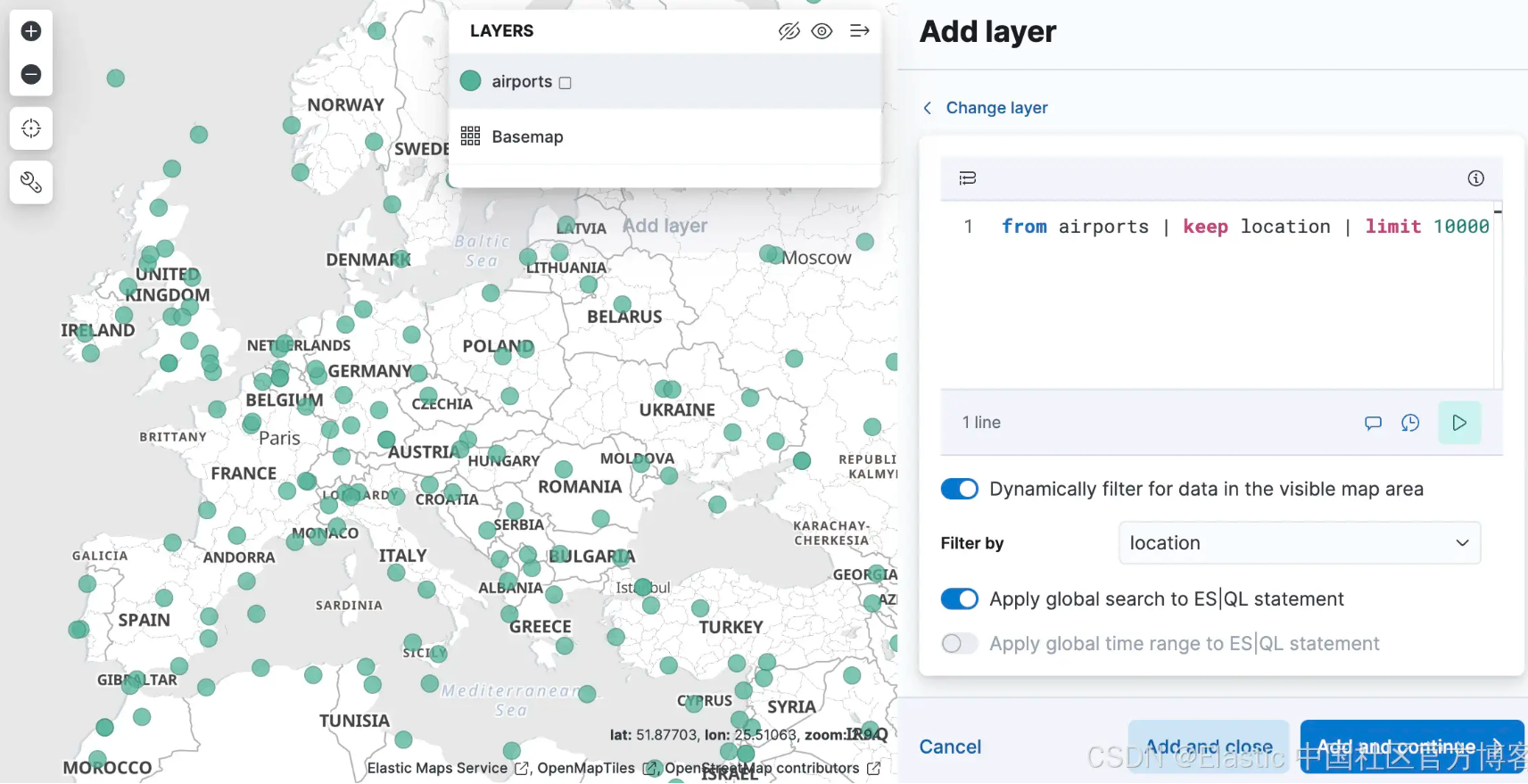
Oder Sie könnten einen Layer hinzufügen, der die Polygone im Index „airport_city_boundaries“ anzeigt, oder noch besser: Wie generiert die obige komplexe ENRICH-Abfrage Statistiken darüber, wie viele Flughäfen es in jeder Region gibt?
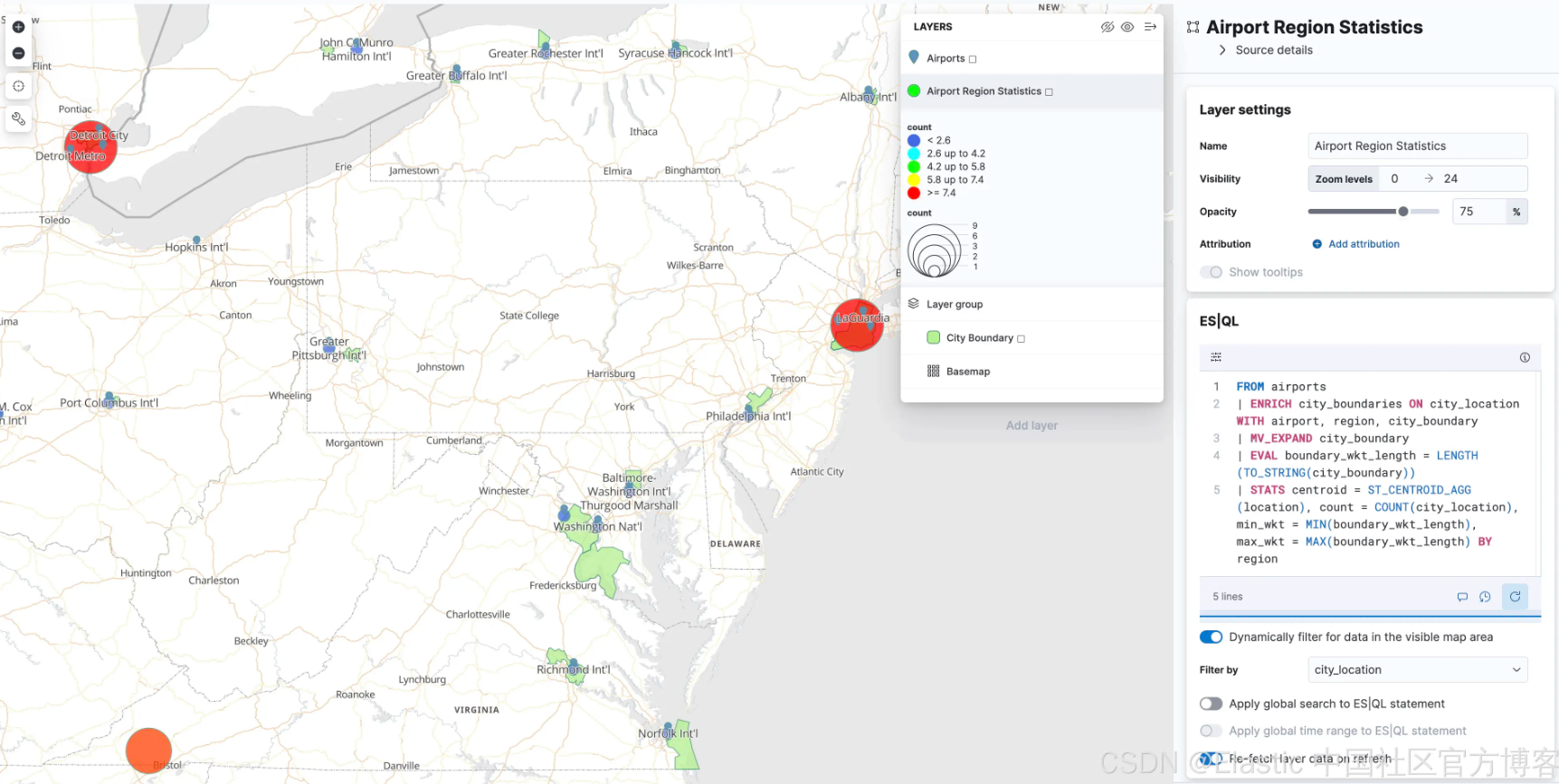
Was kommt als nächstes?
Möglicherweise ist Ihnen aufgefallen, dass wir in den beiden obigen Beispielen eine weitere räumliche Funktion ST_CENTROID_AGG eingefügt haben. Dies ist die im STATS-Befehl verwendete Aggregatfunktion und die erste von vielen räumlichen Analysefunktionen, die wir zu ES|QL hinzufügen möchten. Wenn wir mehr zu zeigen haben, werden wir darüber bloggen!
Bevor wir dazu kommen, möchten wir Ihnen etwas mehr über eine besonders spannende Funktion erzählen, die wir entwickelt haben: die Möglichkeit, räumliche Distanzsuchen durchzuführen, eine der am häufigsten verwendeten räumlichen Suchfunktionen in Elasticsearch. Können Sie sich vorstellen, wie die Syntax für eine Distanzsuche aussehen könnte? Vielleicht so etwas wie die OGC-Funktion? Seien Sie gespannt auf den nächsten Blog dieser Reihe, um mehr zu erfahren!
Spoiler-Alarm: Elasticsearch 8.15 wurde gerade veröffentlicht und beinhaltet räumliche Distanzsuchen mit ES|QL!
Bereit, es selbst auszuprobieren? Starten Sie Ihre kostenlose Testversion .
Möchten Sie sich von Elastic zertifizieren lassen? Finden Sie heraus, wann die nächste Elasticsearch-Ingenieurschulung beginnt!
Artikel: Georäumliche Suche mit Elasticsearch ES|QL — Search Labs
Google: Der Übergang zu Rust hat die Schwachstellen von Android erheblich reduziert. Huawei kündigt an, dass Open UBMC, der alte klassische Musikplayer Winamp, am 2024.2.3 veröffentlicht wird es ist ein Markenzeichen von Oracle geworden? Open Source Daily |. Wie chinesische KI-Unternehmen das US-Chip-Verbot umgehen; Wer kann den Durst der KI-Entwickler stillen? Das Startup-Unternehmen „Zhihuijun“ veröffentlichte Open-Source-AimRT, ein Laufzeit-Entwicklungsframework für den modernen Robotikbereich, Tcl/Tk 9.0, veröffentlichte das multimodale KI-Modell Meta und Llama 3.2