Inhaltsverzeichnis
2. Testen Sie die Statistiken von Millionen von Daten
1. HyperLogLog
Zuerst verstehen wir zwei Konzepte:
UV: Der vollständige Name lautet Unique Visitor, auch Unique Visitors genannt, und bezieht sich auf natürliche Personen, die über das Internet auf diese Webseite zugreifen und diese durchsuchen.
Besucht derselbe Nutzer die Website mehrmals am Tag, wird dies nur einmal erfasst.
PV: Der vollständige Name lautet Page View, auch Seitenaufrufe oder Klicks genannt. Jedes Mal, wenn ein Benutzer eine Seite auf der Website besucht, wird ein PV aufgezeichnet und der Benutzer öffnet die Seite mehrmals.
Oberfläche werden mehrere PVs aufgezeichnet.
Wird häufig zur Messung des Website-Verkehrs verwendet.
Im Allgemeinen ist UV viel größer als PV. Wenn wir also die Anzahl der Besuche auf derselben Website messen, müssen wir viele Faktoren berücksichtigen.
Daher verwenden wir diese beiden Werte einfach als Referenzwert
Es wird schwieriger sein, UV-Statistiken auf der Serverseite zu erstellen, da die gezählten Benutzerinformationen gespeichert werden müssen, um festzustellen, ob der Benutzer gezählt wurde.
Wenn jedoch jeder besuchende Benutzer in Redis gespeichert wird, ist die Datenmenge sehr beängstigend. Wie geht man also damit um?
Hyperloglog (HLL) ist ein probabilistischer Algorithmus, der vom Loglog-Algorithmus abgeleitet ist und zur Bestimmung der Kardinalität sehr großer Mengen verwendet wird, ohne dass diese alle gespeichert werden müssen
Wert.
Sie können sich auf die relevanten Algorithmusprinzipien beziehen: https://juejin.cn/post/6844903785744056333#heading-0
Die HLL in Redis wird basierend auf der String-Struktur implementiert. Der Speicher einer einzelnen HLL beträgt immer weniger als 16 KB und die Speichernutzung ist erschreckend gering!
Als Kompromiss sind die Messungen probabilistisch und weisen einen Fehler von weniger als 0,81 % auf.
Für die UV-Statistik ist dies jedoch völlig vernachlässigbar.

2. Testen Sie die Statistiken von Millionen von Daten
Testidee: Wir verwenden Unit-Tests direkt, um 1 Million Daten zu HyperLogLog hinzuzufügen, um zu sehen, wie die Speichernutzung und die statistischen Auswirkungen sind.
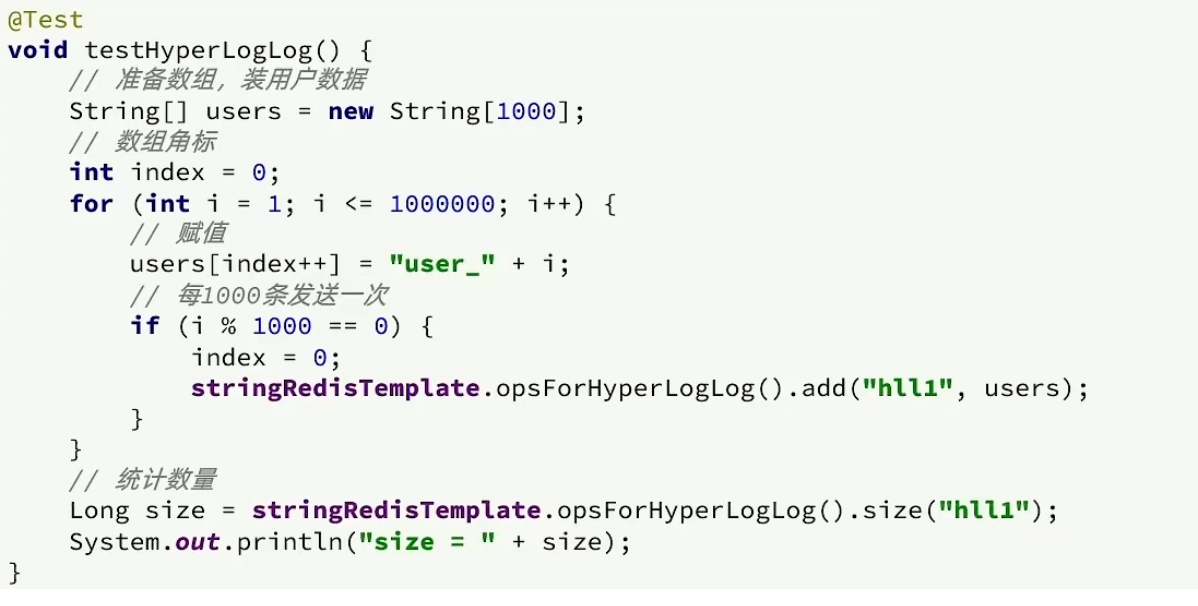
Nach dem Test: Unser Fehler liegt im zulässigen Bereich und die Speichernutzung ist minimal