1. Hintergrund
Ein wichtiges Glied bei der Gewährleistung der Stabilität ist der Aufbau des Fehlermanagementsystems. Die vier Kernfunktionen des Fehlermanagementsystems sind Fehlererkennung, Fehlerzugriff, Fehlerortung und Fehlerbeseitigung ist von entscheidender Bedeutung, einschließlich der Vorhersage von Indikatoren, der Erkennung von Anomalien und der Fehlervorhersage. Das Hauptziel besteht darin, Fehler rechtzeitig und genau zu erkennen. Heute stellen wir hauptsächlich die Anwendung des KI-Anomalieerkennungsalgorithmus bei der Indikatorerkennung für die Anomalieerkennung bei der Fehlererkennung vor.
Nachteile herkömmlicher schwellenwertbasierter Anomalieerkennungsmethoden:
-
Es stützt sich mehr auf persönliche Erfahrungen und muss die historischen Trends der Indikatoren verstehen.
-
Die Konfiguration ist kompliziert. Manchmal müssen für Zeitreihendaten mit periodischen Schwankungen unterschiedliche Schwellenwerte für unterschiedliche Zeiträume konfiguriert werden.
-
Wenn sich das Geschäft ändert, muss der Schwellenwert kontinuierlich angepasst werden. Im Laufe der Zeit und wenn sich das Geschäft ändert, kann sich auch der Trend der Beobachtungsindikatoren ändern, und der Schwellenwert muss entsprechend angepasst werden.
Es wird stark von großen Werbeaktionen oder Ausreißern beeinflusst. Beispielsweise sind einige Schwellenwertkonfigurationen im Jahresvergleich oder im Monatsvergleich unterschiedlich das Erkennungsurteil in diesem Moment.
Im Vergleich zur Erkennung fester Schwellenwerte können KI-Erkennungsalgorithmen die oben genannten Probleme in abnormalen Erkennungsszenarien wie plötzlichen Anstiegen und plötzlichen Abfällen effektiv lösen. Im Folgenden wird die Anwendung von KI-Erkennungsalgorithmen in Observability-Produkten vorgestellt.
2. Algorithmus zur Anomalieerkennung
Vor dem AI-Anomalieerkennungsalgorithmus ist es normalerweise erforderlich, historische Daten vorzuverarbeiten, einschließlich der Eliminierung von Ausreißern und dem Auffüllen fehlender Werte usw.
Entfernung von Ausreißern
Zu diesem Zeitpunkt fragen Sie sich möglicherweise, warum Sie bei der Anomalieerkennung Ausreißer entfernen müssen. Die Ausreißer beziehen sich hier auf die Extremwerte in den als Referenz verwendeten historischen Daten. Das Entfernen von Ausreißern kann dazu beitragen, die Genauigkeit von Anomalieerkennungsalgorithmen zu verbessern.
Boxplot
Das Boxplot muss die Verteilung des Datensatzes nicht berücksichtigen. Es misst die statistische Streuung und Datenvariabilität, indem es die Daten in Quartile unterteilt. Es handelt sich um einen einfachen und effektiven Algorithmus zur Eliminierung von Ausreißern.
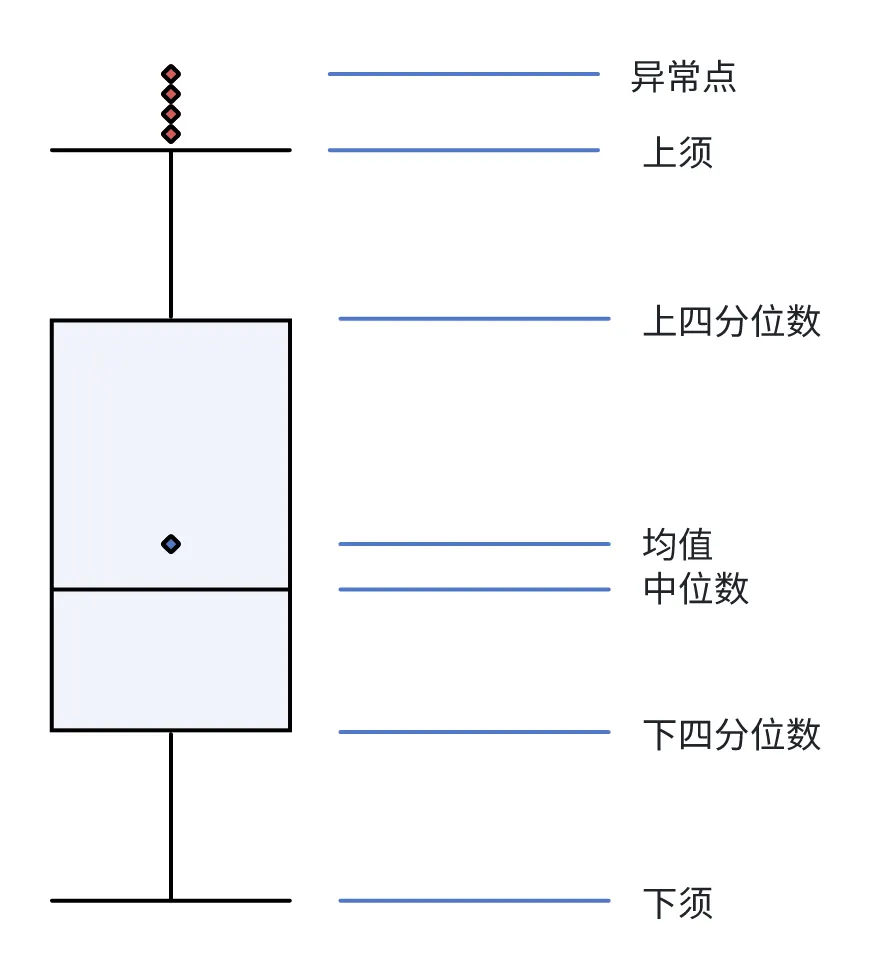
-
Unteres Quartil: der Wert, der dem 25 %-Quartil (Q1) entspricht
-
Median: der Wert, der dem 50 %-Perzentil entspricht (Q2)
-
Oberes Quartil: der Wert, der dem 75 %-Perzentil entspricht (Q3)
-
Oberer Whisker: Q3+1,5 (Q3-Q1)
-
Untere Whisker: Q1-1,5 (Q3-Q1)
Wie in der Abbildung oben gezeigt, gelten Werte, die größer als der obere Whisker oder kleiner als der untere Whisker sind, als Ausreißer.
In Anbetracht der Eigenschaften von 3Sigma- und Box-Plot-Algorithmen ist der Box-Plot möglicherweise universeller, da die Verteilung des Datensatzes nicht berücksichtigt werden muss. In praktischen Anwendungen verwenden wir auch den Box-Plot-Algorithmus, um Ausreißer zu eliminieren. Nach der Eliminierung von Ausreißern müssen fehlende Werte aufgefüllt werden, um die Kontinuität der Daten sicherzustellen und zu verhindern, dass nachfolgende Erkennungsalgorithmen während der Verarbeitung Fehler melden. Die üblichen Methoden zum Auffüllen fehlender Werte sind:
-
Verwenden Sie vor und nach der Füllmethode den vorherigen Wert zum Füllen oder den nächsten normalen Wert zum Füllen.
-
Mittlere und mittlere Füllmethoden.
-
Interpolationsmethode: Die Interpolationsmethode umfasst lineare Interpolation und Polynominterpolation. Die lineare Interpolation verwendet eine lineare Regression, um fehlende Positionswerte vorherzusagen, während die polynomielle Interpolation eine polynomielle Regression verwendet, um fehlende Positionswerte vorherzusagen.
Das Folgende ist der Effekt der Verwendung von Boxplots zur Eliminierung von Ausreißern und der Polynominterpolation:
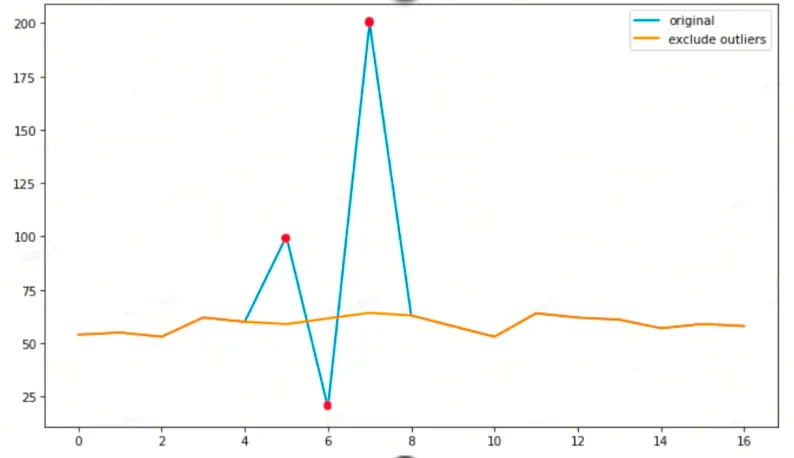
Die blaue Linie ist der ursprüngliche Beobachtungswert, der rote Punkt ist der erkannte abnormale Punkt und die gelbe Linie ist das Ergebnis nach dem Füllen durch die Interpolationsmethode. Verwenden Sie nach der Datenvorverarbeitung die vorverarbeiteten Ergebnisse, um Ausreißer zu erkennen.
Anwendung statistischer Methoden
Bei der Analyse der Beobachtungsdaten weisen die meisten Indikatoren eine Periodizität und einen Trend auf.

Zu den wichtigsten statistischen Methoden zur Anomalieerkennung in Observability-Produkten gehören 3Sigma- und Zscore-Änderungspunkterkennungsalgorithmen.
3Sigma-Algorithmus
Der 3Sigma-Algorithmus geht davon aus, dass, wenn die Verteilung des Datensatzes zur Normalverteilung gehört, die Wahrscheinlichkeit, dass der Datenpunkt innerhalb von plus oder minus 1 Standardabweichung vom Mittelwert (d. h. Sigma-Wert) liegt, 68,2 % beträgt; plus oder minus 2-fache Standardabweichung vom Mittelwert Die Wahrscheinlichkeit, dass ein Datenpunkt innerhalb des plus oder minus 3-fachen der Standardabweichung vom Mittelwert liegt, beträgt 99,6 %, was bedeutet, dass die Wahrscheinlichkeit, dass ein Datenpunkt außerhalb des Mittelwerts plus oder minus liegt minus 3 mal die Standardabweichung ist sehr klein. Diese Daten können als extrem abnormale Punkte betrachtet werden. Dieser Algorithmus lässt sich am besten verstehen, wenn man sich das folgende Wahrscheinlichkeitsdichtediagramm der Standardnormalverteilung ansieht.
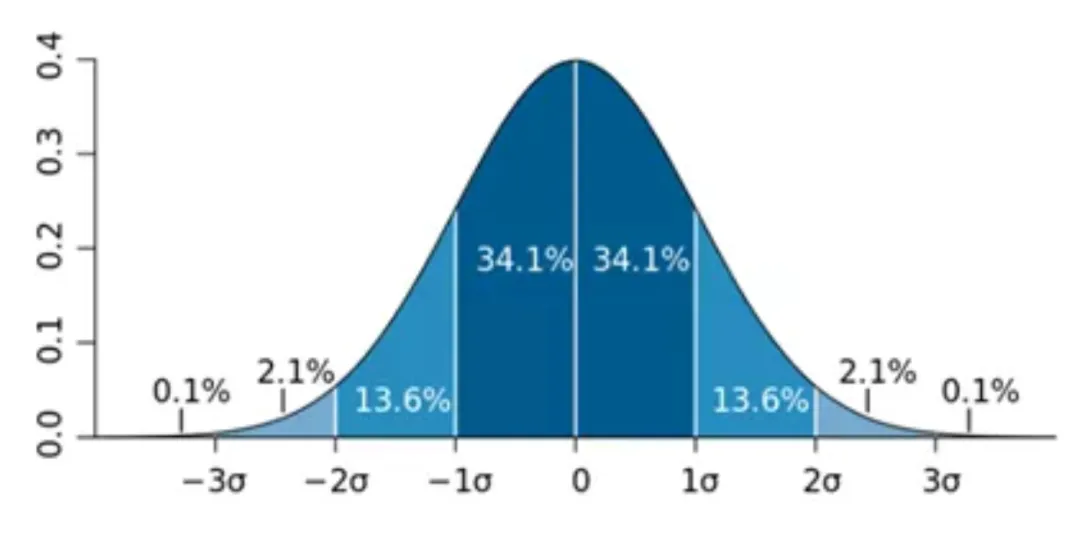
Durch Beobachtung wurde festgestellt, dass die meisten Indikatoren der Beobachtbarkeitsplattform der Normalverteilung aus der Längsschnittanalyse der Zeitbreite (dem gleichen Moment in der Geschichte) entsprechen, jedoch nicht der Normalverteilung aus horizontaler Perspektive.
Am Beispiel der Erstellung des Order-QPS-Indikators erhalten Sie die QPS-Beobachtungsdaten um 10 Uhr zur gleichen Zeit in den letzten 60 Tagen, zeichnen ein Histogramm über Python und überprüfen die Normalverteilung über den KS-Algorithmus:

Aus dem Histogramm geht hervor, dass die Daten im Wesentlichen der Normalverteilung entsprechen. Der p-Wert wird mit dem KS-Algorithmus überprüft und stimmt mit den Eigenschaften der Normalverteilung überein.

Daher können wir den 3Sigma-Algorithmus verwenden, um bei den meisten Indikatoren eine longitudinale Ausreißererkennung durchzuführen.
Als nächstes analysieren wir die Datenverteilung horizontal. Zunächst analysieren wir, ob die Daten eines vollständigen Tages der Normalverteilung entsprechen.

Zeichnen Sie ein Histogramm gemäß der obigen Methode und überprüfen Sie mithilfe des KS-Algorithmus, ob es der Normalverteilung entspricht.

Bei horizontaler Betrachtung des Histogramms entspricht der QPS-Indikator nicht der Normalverteilung. Verwenden Sie den KS-Algorithmus, um zu überprüfen, ob der p-Wert <0,05 ist, also nicht der Normalverteilung entspricht.

Analysieren Sie als Nächstes die Daten von 30 aufeinanderfolgenden Punkten, um festzustellen, ob sie der Normalverteilung entsprechen. Nehmen Sie immer noch die Erstellung von Auftrags-QPS als Beispiel, rufen Sie die Daten vom Zeitpunkt 11:31:00 bis 12:03:00 ab und zeichnen Sie ein Histogramm.

Aus der Grafik geht hervor, dass der KS-Algorithmus grundsätzlich der Normalverteilung entspricht. Es ist ersichtlich, dass der kontinuierliche 30-Punkte-Datensatz der Normalverteilung entspricht.

In Kombination mit der obigen Analyse ist unsere Erkennung von Beobachtungsindikatoren in zwei Schritte unterteilt:
-
Vertikal werden die Beobachtungswerte von 30 Punkten gleichzeitig im Verlauf ermittelt und Anomalien mithilfe des 3Sigma-Algorithmus erkannt.
-
Horizontal führt der Zscore-Algorithmus eine Änderungspunkterkennung durch und erhält horizontal die beobachteten Werte von 30 historischen Punkten zu einem bestimmten Zeitpunkt.
Schließlich werden die vertikalen und horizontalen Erkennungsergebnisse verwendet, um gemeinsam zu entscheiden, ob ein bestimmter Punkt abnormal ist.
Zscore-Algorithmus
Für die horizontale Anomalieerkennung verwenden wir den Zscore-Algorithmus. Für die horizontale Erkennung verwenden wir die Daten der letzten 30 Punkte. Die spezifische Methode ist:
-
Die Daten der letzten 30 Punkte werden entsprechend dem Fenster geglättet und die Fenstergröße beträgt 3;
-
Machen Sie einen Unterschied zwischen den geglätteten Daten vorher und nachher;
-
Berechnen Sie den Zscore für den Differenzdatensatz. Die Berechnungsformel für den Zscore lautet:
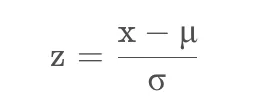
- Verwenden Sie die Überlebensfunktion der Normalverteilung, um die Wahrscheinlichkeit des rechten Endes des Zscores zu berechnen und festzustellen, ob die Wahrscheinlichkeit größer als 0,01 ist.
Am Beispiel der Erstellung von Auftrags-QPS wird die 3sigma-Erkennungslogik verwendet, um den Wert gleichzeitig in den letzten 30 Tagen um 14:00:00 Uhr am 15.01.2024 zu erhalten:
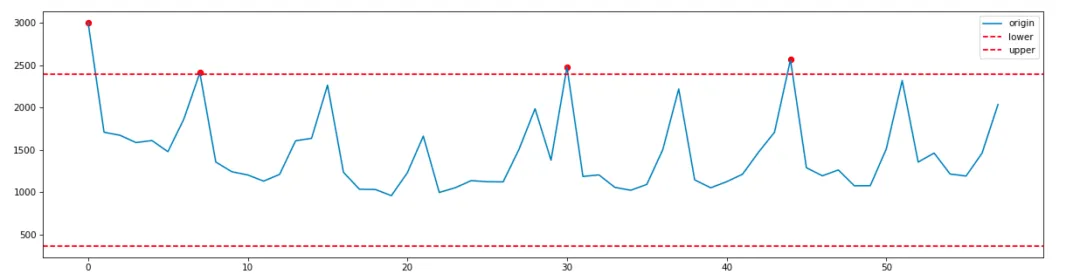
Verwenden Sie den Zscore-Algorithmus, um Anomalien an 32 historischen Punkten vom 14.01.2024 um 11:31:00 Uhr bis zum 14.01.2024 um 12:03 Uhr wie folgt zu erkennen:
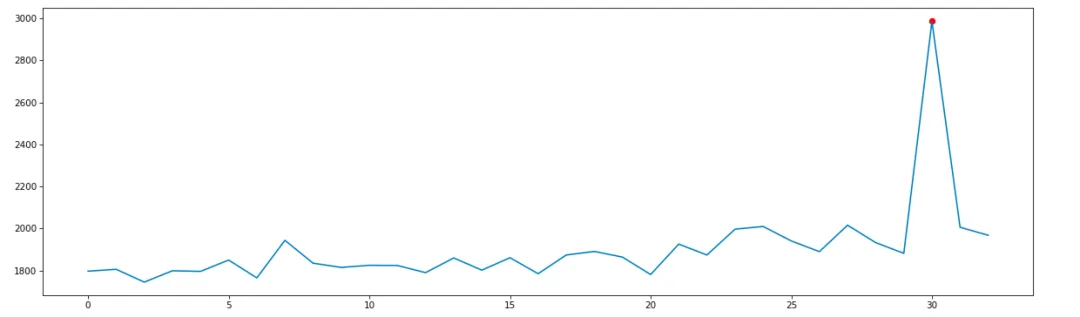
Die oben genannten horizontalen und vertikalen Algorithmen können die Anomalieprüfung der meisten Beobachtungsindikatoren lösen, aber die Schwankung einiger Indikatoren war immer sehr gering, wie beispielsweise der Speicheranzeige, wie in der folgenden Abbildung dargestellt:
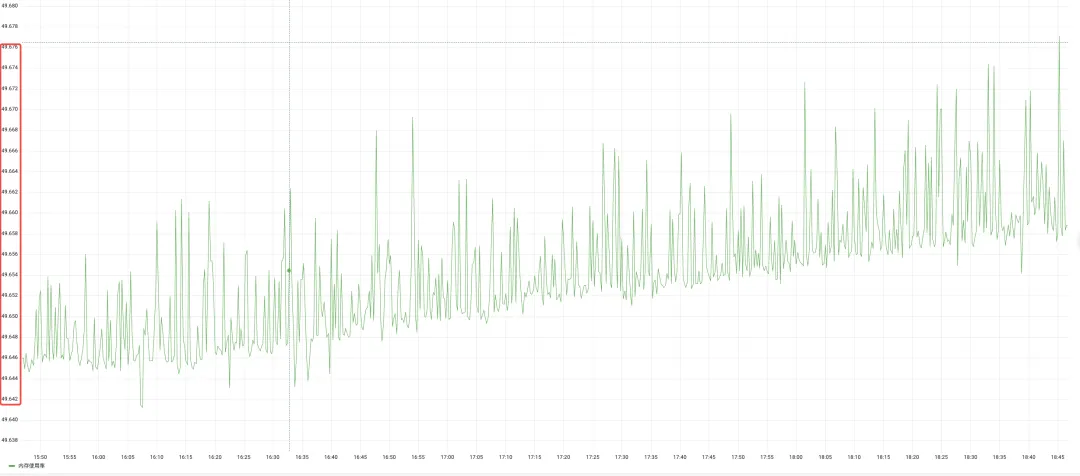
Die Verwendung der statistischen 3-Sigma-Methode zur Erkennung von Ausreißern führt zu folgenden Ergebnissen:
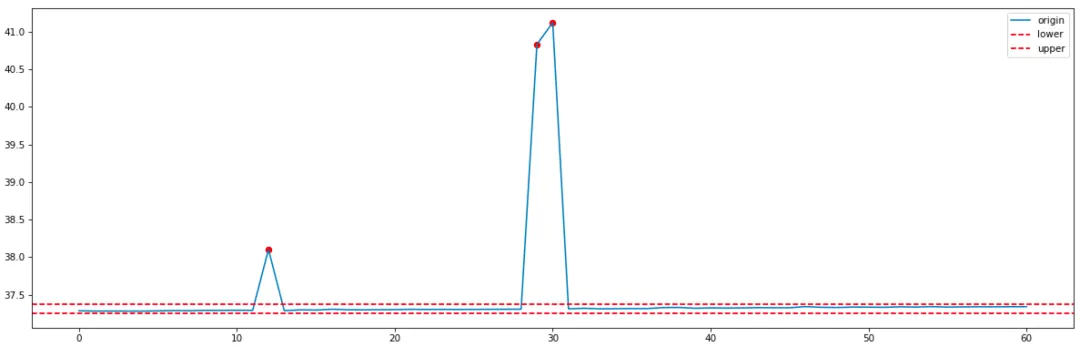
Es ist ersichtlich, dass die Ober- und Untergrenzen der 3-Sigma-Berechnung sehr klein sind und die Ober- und Untergrenzen nahe bei etwa 1 liegen, was dazu führt, dass dieser Indikator viele abnormale Punkte erkennt. Daher untersuchen wir die Verwendung anderer komplexer Algorithmen, wie beispielsweise maschineller Lernalgorithmen, um das Problem zu lösen.
Anwendung maschineller Lernmethoden
Bei statistischen Methoden zur Anomalieerkennung können in einigen speziellen Szenarien Probleme wie große Erkennungsfehler und Rauschen auftreten. Daher haben wir die Erkennungsalgorithmen für maschinelles Lernen untersucht, da die meisten Beobachtungsdaten unbeschriftet sind und die Kosten für die Beschaffung von Etiketten relativ hoch sind Unbeaufsichtigte Algorithmen, Forschung und Anwendungen wurden in isolierten Wäldern durchgeführt.
isolierter Wald
Isolation Forest-Algorithmus, eine unbeaufsichtigte Anomalieerkennungsmethode, die für kontinuierliche Daten geeignet ist . Dieser Algorithmus verwendet keine Indikatoren wie Abstand und Dichte (LOF, K-Mittel), um die Unterschiede zwischen Proben und anderen Proben zu beschreiben, sondern stellt direkt die sogenannte Isolation dar. Daher ist der Algorithmus einfach und effizient. Darüber hinaus ist der Algorithmus äußerst robust und macht keine Annahmen über die Verteilung des Datensatzes.
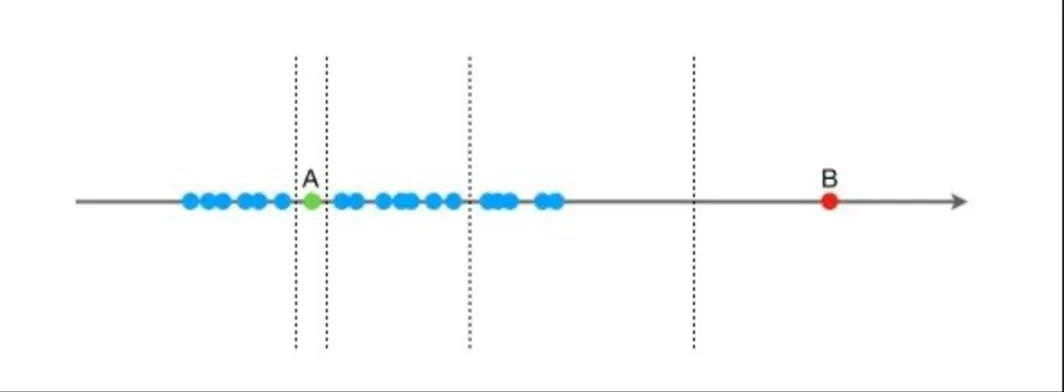
Die Idee des Isolationswaldalgorithmus: Angenommen, es gibt einen Satz eindimensionaler Daten (wie unten gezeigt). Der Zweck besteht darin, die Punkte A und B zunächst zufällig zu trennen Wählen Sie einen Wert X und teilen Sie die Daten dann in zwei Gruppen links und rechts entsprechend = auf Punkt B ist relativ weit von anderen Daten entfernt, und die Segmentierung kann einige Male dauern. Punkt A ist mit anderen Datenpunkten geclustert, und die Segmentierung kann länger dauern. Aus statistischer Sicht müssen relativ gruppierte Punkte häufiger geteilt werden, relativ isolierte Punkte benötigen weniger Teilungen. Der Isolationswald verwendet die Anzahl der Teilungen, um zu messen, ob ein Punkt gruppiert (normal) oder isoliert (abnormal) ist.
In praktischen Anwendungen unterstützt Python sklearn bereits den isolierten Waldalgorithmus. Wir müssen nur einige Anpassungen an den Parametern im Algorithmus vornehmen. Zu den Parametern des sklearn IsolationForest-Algorithmus gehören:
-
n_estimators: int, optional (Standard = 100), die Anzahl der iTree, gibt die Anzahl der zufälligen Bäume im Wald an.
-
max_samples: int oder float, optional (default="auto") Die Anzahl der Stichproben, für die der Teilbaum erstellt werden soll. Die Ganzzahl ist die Zahl und die Dezimalzahl ist der Anteil des gesamten Satzes. Sie wird verwendet, um die Anzahl der Stichproben zu trainieren Zufallszahlen.
-
Kontamination: Float in (0, 0,5), optional (Standard = 0,1) gibt den Anteil der Anomalien in einem bestimmten Datensatz an. Die Anzahl der Kontaminationen im Datensatz ist tatsächlich die Anzahl der abnormalen Daten in den Trainingsdaten Wert wird zur Entscheidungsfindung verwendet. Der Schwellenwert wird in der Funktion definiert.
-
max_features: int oder float, optional (Standard = 1,0) Die Anzahl der Features zum Erstellen jedes Teilbaums, die Anzahl der Ganzzahlen, die Dezimalzahl ist der Anteil der Gesamtfeatures, gibt die Anzahl der Attribute an, die aus der Gesamtstichprobe X extrahiert werden, um sie jeweils zu trainieren Bei Tree iTree wird standardmäßig nur ein Attribut verwendet. Wenn es auf eine Ganzzahl eingestellt ist, werden max_features-Attribute extrahiert. Wenn es sich um eine Float-Gleitkommazahl handelt, werden max_features * X.shape[1]-Attribute extrahiert.
-
Bootstrap: boolean, optional (Standard=False) Ob die Stichprobe mit oder ohne Ersetzung erfolgt. Wenn es „True“ ist, tastet jeder Baum die Trainingsdaten mit Ersetzung ab. Bei „Falsch“ wird eine Stichprobenentnahme ohne Ersatz durchgeführt.
-
n_jobs: int oder None, optional (Standard = None) Anzahl der Jobs, die beim Ausführen der Funktionen fit() und Predict() parallel ausgeführt werden sollen. „Keine“ wird als 1 ausgedrückt, außer im Fall des joblib.parallel_backend-Kontexts. Auf -1 setzen, um alle verfügbaren Prozessoren zu verwenden Random_State: int, RandomState-Instanz oder None, optional (Standard=None) Die Zufälligkeit jedes Trainings. Wenn auf eine int-Konstante festgelegt, wird der Random_State-Parameterwert für Zufallszahlen verwendet. Der Startwert des Generator; wenn auf eine RandomState-Instanz eingestellt, ist Random_State ein Zufallszahlengenerator. Wenn auf None gesetzt, ist der Zufallszahlengenerator die in np.random verwendete RandomState-Instanz.
-
verbose: int, optional (Standard=0) Der Detaillierungsgrad des während des Trainings gedruckten Protokolls. Je größer der Wert, desto detaillierter ist es.
-
warm_start: bool, optional (Standard=False) Wenn auf „True“ gesetzt, wird das Ergebnis des letzten Aufrufs erneut verwendet, um weitere Bäume zum letzten Satz von Gesamtstruktur 1 hinzuzufügen. Andernfalls wird eine gesamte neue Gesamtstruktur angepasst.
Wir passen die Kontamination hauptsächlich an, um die Schwellenwertgröße des Anomalieerkennungsalgorithmus zu steuern. In praktischen Anwendungen definieren wir den Kontaminationswert als 0,01, was eine relativ strenge Erkennungsschwelle ist. Angesichts der Speichernutzung mit relativ geringen Erkennungsschwankungen im statistischen Algorithmus lauten die Ergebnisse, die durch die Verwendung der isolierten Gesamtstruktur zur Erkennung erzielt werden, wie folgt:
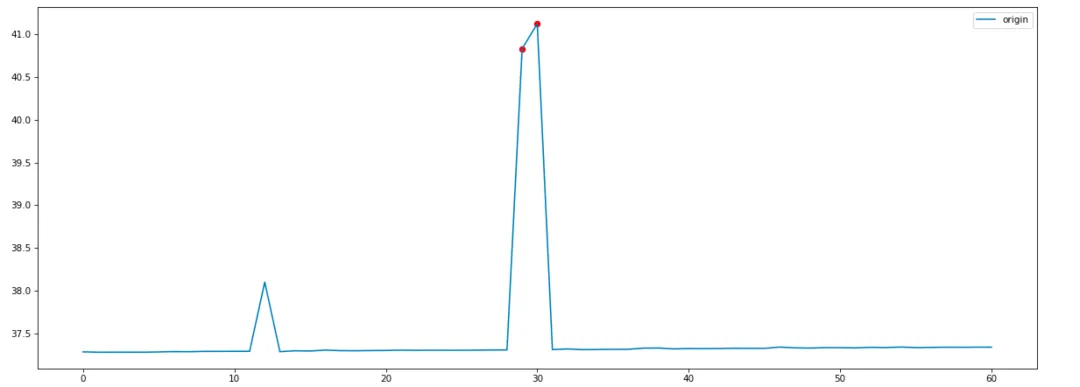
Im Vergleich zum statistischen 3Sigma-Algorithmus ist die Erkennung des isolierten Waldes strenger und der abnormale Rauschpunkt mit Index 12 wurde nicht erkannt.
Im Vergleich zu Algorithmen für maschinelles Lernen weisen statistische Algorithmen eine geringe Algorithmuskomplexität, eine schnelle Erkennungsgeschwindigkeit und eine relativ starke Interpretierbarkeit auf. Algorithmen für maschinelles Lernen sind robuster als statistische Algorithmen und stellen keine Anforderungen an die Verteilung des Datensatzes, ihre Interpretierbarkeit ist jedoch relativ gering. Kombination der Vor- und Nachteile der beiden Arten von Algorithmen In unserer allgemeinen Strategie zur Erkennung von Anomalien werden wir die beiden Erkennungsalgorithmen kombinieren, um gemeinsame Entscheidungen zu treffen und die Genauigkeit der Erkennung zu verbessern.
Anwendung von Deep-Learning-Methoden
Darüber hinaus ist für einige Kernszenarien wie Anmeldung, Produktdetails, Bestellung, Lieferkette usw. eine besonders hohe Vorhersagegenauigkeit erforderlich, und das Alarmgeräusch ist gering. Wir haben auch einige Untersuchungen in diesem Bereich durchgeführt Deep-Learning-Algorithmen wie LSTM, Transformer, die hauptsächlich die kürzlich populären Transformer-Modelle und -Varianten erforschten und damit experimentierten und schließlich Pyraformer mit relativ guten Ergebnissen durch Experimente übernahmen. Pyraformer verwendet ein Aufmerksamkeitsmodul mit Pyramidenstruktur, das langfristige Abhängigkeiten gut erfassen kann und eine geringere zeitliche und räumliche Komplexität aufweist. Für eine spezifische theoretische Einführung in Pyraformer können Interessierte auf Artikel oder Artikel zu Pyraformer verweisen, hier Wir Wir führen nur einige geringfügige Änderungen ein, die wir am Pyraformer vorgenommen haben.
Die Art und Weise, wie wir Pyraformer für die Indikatorvorhersage verwenden, besteht hauptsächlich darin, Ober- und Untergrenzen basierend auf vorhergesagten Werten zu berechnen. Der Open-Source-Pyraformer unterstützt keine Vorhersagen für Ober- und Untergrenzen. Die spezifische Methode ist:
-
Durch Vorhersage des vorhergesagten Werts zum historischen Zeitpunkt wird die Differenz zum beobachteten Wert berechnet und das Berechnungsergebnis als neuer Fehlerindikator in die Zeitreihendatenbank geschrieben.
-
Wenn Sie den Wert zu einem bestimmten Zeitpunkt in der Zukunft vorhersagen, ermitteln Sie im ersten Schritt über den Fehlerindikator die nächstgelegenen 30-Punkt-Fehlerwerte, berechnen Sie die Standardabweichung der 30 Fehlerpunkte als Sigma und berechnen Sie dann den vorhergesagten Wert Zeit plus oder minus 3-faches Sigma. Ober- und Untergrenze ermittelt.
Die folgende Abbildung zeigt den Vorhersageeffekt eines bestimmten Kernszenarios:
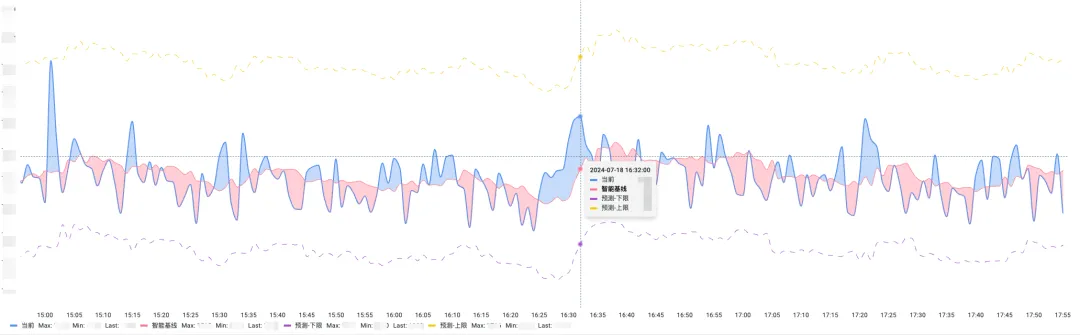
Derzeit wurde dieser Algorithmus auf tägliche Alarme in mehr als 50 Kernszenarien angewendet. Nach der Anwendung des Algorithmus konnten Fehlalarme in Kernszenarien um mehr als 50 % reduziert werden.
3. Zusammenfassung und Ausblick
Derzeit wird der Anomalie-Erkennungsalgorithmus hauptsächlich in zwei Aspekten verwendet: Zum einen in der Risikowahrnehmungsszene der Kernszene, die hauptsächlich den plötzlichen Anstieg und den plötzlichen Abfall von QPS der Anwendung, RT, Fehlerrate, Fehlercode, abnormale Anzahl und CPU erkennt Im Erkennungsszenario erreicht die Anomalieerkennungsrate mehr als 90 %. Im anderen Fall ist es das Risikowahrnehmungsszenario, dass es am Ende des Release-Batches zu einem plötzlichen Anstieg der Instanzerkennung kommt. RT, Fehlerrate, Anzahl der Ausnahmen usw. nach der Änderung Ausnahme, um zu verhindern, dass problematischer Code online veröffentlicht wird und größere Auswirkungen hat. Zukünftig werden wir weiterhin an KI-Erkennungsalgorithmen und Vorhersagealgorithmen forschen und diese in weiteren Szenarien implementieren. Darüber hinaus untersuchen wir auch den Fehlerzugriff und die Fehlerlokalisierung und haben in einigen Szenarien gute Ergebnisse erzielt, die in Zukunft separat geteilt werden.
* Text/Yunbin
Dieser Artikel stammt ursprünglich von Dewu Technology. Weitere spannende Artikel finden Sie unter: Dewu Technology
Ein Nachdruck ohne die Genehmigung von Dewu Technology ist strengstens untersagt, andernfalls wird eine rechtliche Haftung gemäß dem Gesetz verfolgt!
Google: Der Übergang zu Rust hat zu einem starken Rückgang der Android-Schwachstellen geführt , die für IT-Experten immer schwieriger werden, detaillierte tägliche und wöchentliche Berichte zu erstellen! Wie kann man die Situation durchbrechen? Tcl/Tk 9.0 veröffentlicht AMDs erstes Open-Source-Kleinsprachenmodell AMD-135M. Es ist Nationalfeiertag, aber wie kann ich auf das Netzwerk des aus Hangzhou stammenden Unternehmens zugreifen? Version startet einen begrenzten Dateilöschtest. Die Shanghai Stock Exchange testet heute 270 Millionen eingegangene Bestellungen: Die Gesamtleistung ist doppelt so hoch wie der historische Höchststand. Apple bringt möglicherweise sein erstes Smart Display auf den Markt und unterstützt das Betriebssystem homeOS FFmpeg im Jahr 2025. „Péter“ bringt Smart Spectrum AI auf den Markt und kündigt an, dass alle Modelle mit einem Rabatt von mindestens 10 % erhältlich sein werden.