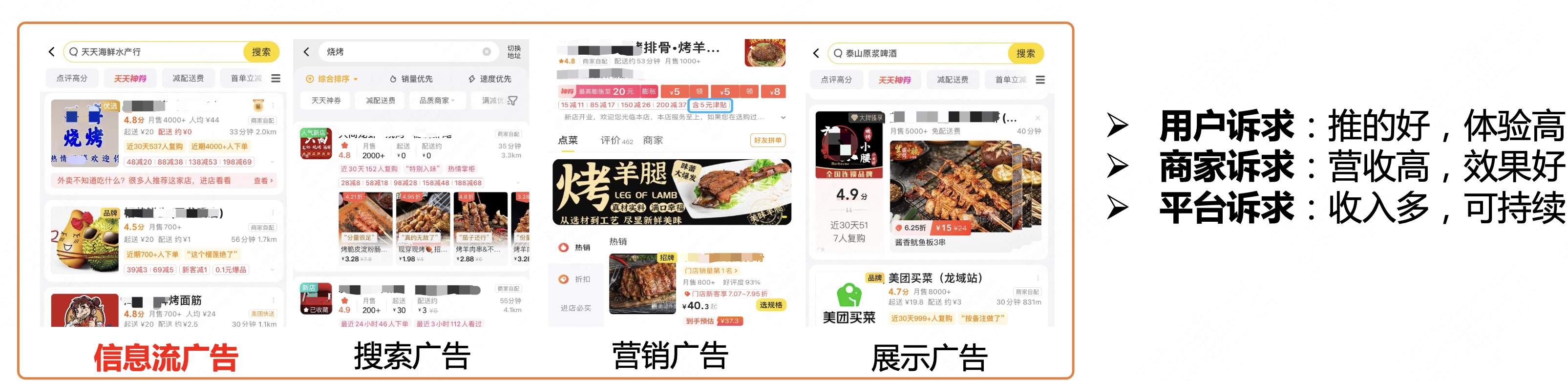
Dieser Artikel wurde aus der 81. Ausgabe des Meituan Technology Salon „Meituan's Exploration and Practice in the Field of Advertising Algorithms“ (Bilibili Video) zusammengestellt. Der Artikel stellt zunächst den aktuellen Stand des Informationsfluss-Werbegeschäfts und der Vorhersagetechnologie in Meituan vor und konzentriert sich dann auf die Weitergabe der spezifischen Praxis der Informationsfluss-Werbevorhersage in Meituan, wobei der Schwerpunkt auf Entscheidungspfaden, ultralanger und ultraweiter Modellierung usw. liegt Die vollständige Reduktionsmodellierung wurde geteilt, und schließlich gibt es einige Zusammenfassungen und Ausblicke, die für alle hilfreich oder inspirierend sein können.

1 Aktueller Stand des Informationsfluss-Werbegeschäfts und der Vorhersagetechnologie
1.1 Merkmale des Informationsfluss-Werbegeschäfts
Derzeit umfasst die Werbung von Meituan Waimai hauptsächlich Informationsflusswerbung, Suchmaschinenwerbung, Marketingwerbung, Display-Werbung usw. Das Außer-Haus-Geschäft weist typische Geschäftsmerkmale auf:
- Das Benutzerverhalten ist sehr konsistent : Benutzer haben klare Essensabsichten, beenden die Mahlzeit normalerweise innerhalb von 10 Minuten und die UV-Bestellrate ist hoch.
- Umfangreiche Anzeigeinformationen : Karteninformationen umfassen Punkte, Bewertungen, Rabatte, Lieferung und andere Informationen, die einen starken Einfluss auf die Entscheidungsfindung der Benutzer haben.
- Viele Textinformationen : In E-Commerce-Szenarien spielen Produktbilder oft eine große Rolle als Kandidatenbilder, aber in Take-Away-Szenarien sind Händler komplexere Kandidaten, die Textinformationen wie Händlernamen, Bewertungen und beliebte Gerichte beeinflussen können Entscheidungsfindung der Benutzer.
1.2 Technologieübersicht und Entwicklungsstadium
Hier stellen wir zunächst den aktuellen Stand der Vorhersagetechnologie vor. Aus technischer Sicht zeigt die folgende Abbildung den Gesamtprozess des Werbeauslieferungssystems:

Im Allgemeinen ist das Werbesystem zum Mitnehmen relativ ähnlich zu unserem Suchförderungssystem in der Branche, einschließlich Rückruf, Grobranking, Feinranking und verschiedenen Mechanismen. Der größte Unterschied zwischen Take-Away-Werbung und Branchenszenarien besteht jedoch in der Erinnerung, da sie auf Ortungsdiensten (Location Services, LBS) basiert und der Prozess selbst bestimmten Einschränkungen unterliegt. Daher werden wir mehr Rechenleistung und Ressourcen in die Feinabstimmung und Mechanismusebene investieren, um die Verbesserung der Gesamtverbindung zu maximieren.
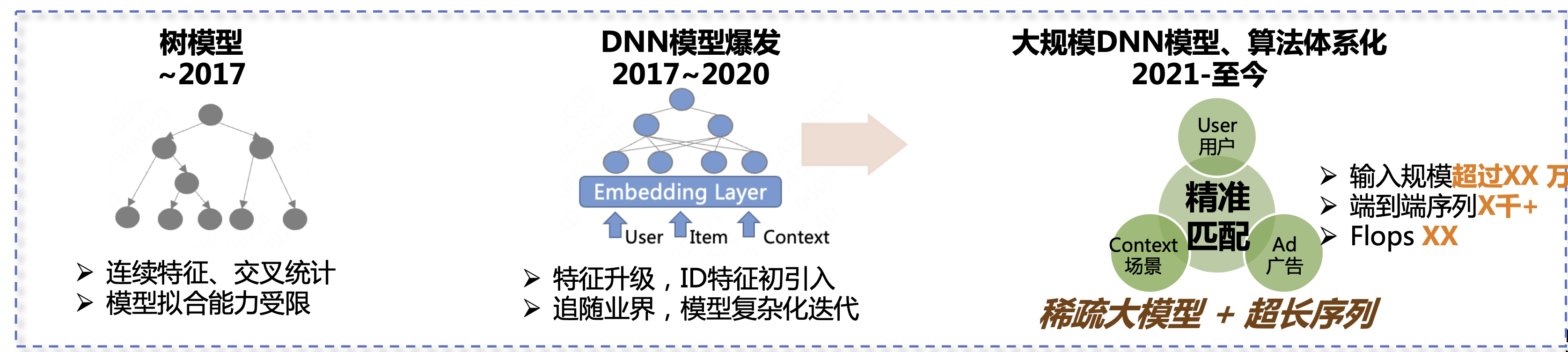
In den letzten sechs oder sieben Jahren hat der Prognosealgorithmus für Heimwerbung drei Entwicklungsstufen durchlaufen. Die erste Stufe war das Baummodell, einschließlich kontinuierlicher Merkmale, Kreuzstatistiken usw. Die Modellanpassungsmöglichkeiten waren zu diesem Zeitpunkt relativ begrenzt. Die zweite Phase dauert von 2017 bis 2020. In dieser Phase begannen die DNN-Modelle zu explodieren. Wir haben Funktionen aktualisiert und begonnen, dem Tempo der Branche zu folgen und komplexere Modelle einzuführen, um die Geschäftsergebnisse kontinuierlich zu verbessern. Die dritte Phase reicht von 2021 bis heute. Unsere Hauptrichtung sind spärliche große Modelle + ultralange Sequenzen, um die Geschäftseffekte weiter zu verbessern.
1.3 Geschätzter technischer Stand
Auf der technischen Ebene der Informationsfluss-Werbevorhersage sind die Hauptexplorationsrichtungen Benutzerrichtung, Linkrichtung und NLP-Richtung (wie in der folgenden Abbildung dargestellt). Wenn dieses Bild umfassender wäre, würde es natürlich auch Querrichtungen, mehrere Szenen und mehrere Ziele usw. enthalten. Wir haben keine anderen Richtungen gewählt, hauptsächlich weil wir in Bezug auf Querrichtungen festgestellt haben, dass das Benutzerverhalten mit der kontinuierlichen Entwicklung der Internetbranche immer komplexer wird und Querrichtungen nur Deep-Learning-Funktionen auf Kontextebene bieten können . , es kann nicht weiterhin die Ursache der Wirkung sein. Andererseits entwickelt sich zwar auch die Cross-Over-Technologie, die Entwicklungsrichtung geht jedoch auch vom ID-Matching zum Sequence-Matching, und die modellübergreifende Fähigkeit einfacher flacher Kategoriemerkmale weist nur eine begrenzte Entwicklung auf. Unter Berücksichtigung verschiedener Faktoren haben wir uns nicht für Crossover als langfristige Richtung entschieden.
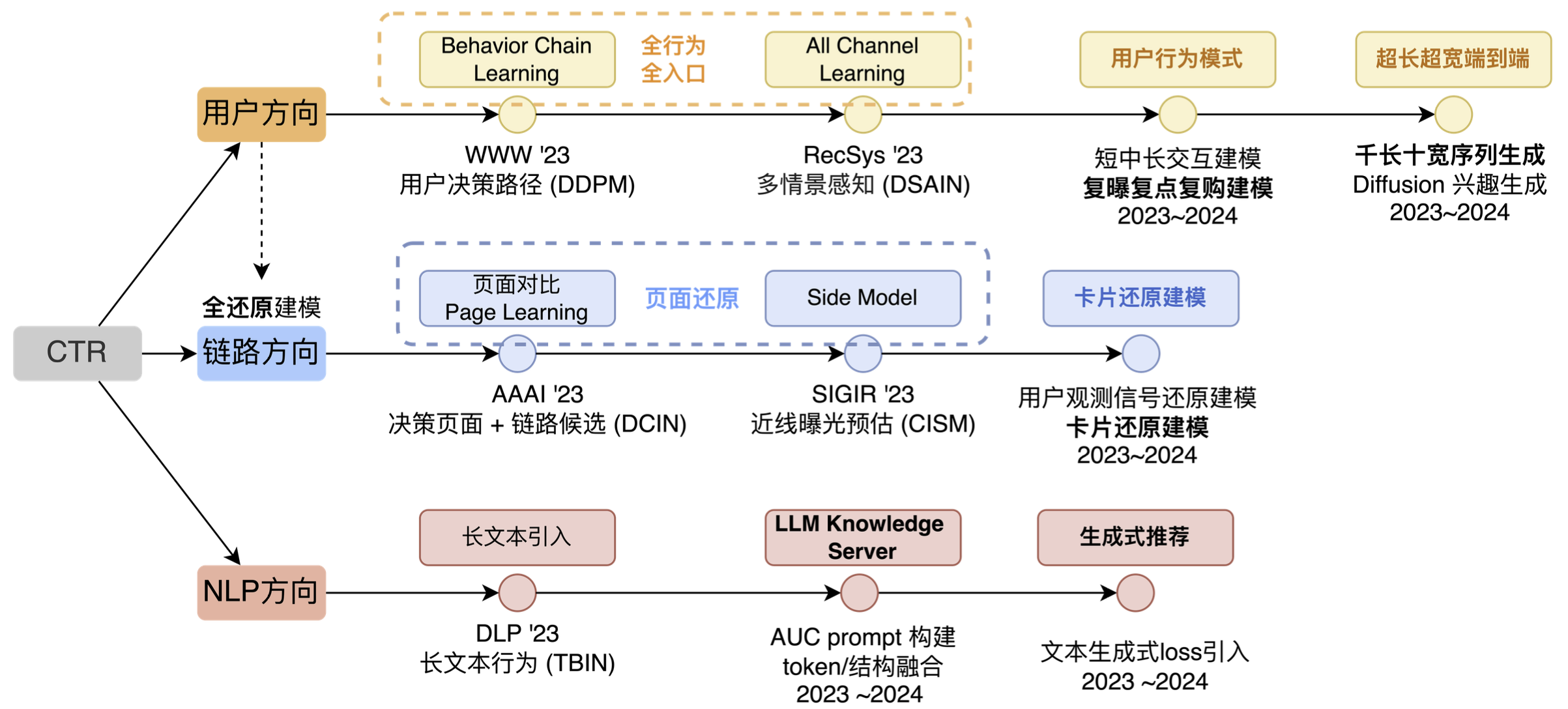
Es gibt auch eine Multiszenen-Richtung. Tatsächlich haben wir bereits einige Iterationen in dieser Richtung durchgeführt und eine Welle von Effekten hervorgerufen, aber später stellten wir fest, dass diese Technologie besser für die Verknüpfung mehrerer kleiner Szenen geeignet ist. Wenn das von Ihnen betreute Unternehmen nur über ein oder zwei relativ große Szenarien verfügt und die Unterschiede in den Benutzeranforderungen, Anzeigeformen und dem Kandidatenangebot dieser Szenarien nicht groß sind, ist es unwahrscheinlich, dass Sie Ihre technischen Fähigkeiten und Ihre Rolle in diesen Szenarien ausüben können diese Richtung.
Unsere Gesamtidee reicht vom Benutzerelement-Matching, dem Seiten-Matching, dem Pfad-Matching und schließlich dem langfristigen Interessen-Matching. Im Wesentlichen führen sie Arbeiten im Zusammenhang mit dem Benutzerabgleich auf verschiedenen Ebenen durch. Unter diesen fallen Element-Matching und Seiten-Matching in die Linkrichtung. Der Grund dafür ist, dass es bei der Linkrichtung eher darum geht, „unsichtbare Probleme“ zu lösen und diese „gesehenen“ Informationen dann für die entsprechende Modellierung zu verwenden. Daher listen wir die Linkrichtung separat auf.
- In der Benutzerrichtung haben wir ebenfalls ungefähr drei Stufen durchlaufen. Die erste Stufe besteht darin, vom ursprünglichen Einzelpunkt- und Einzeleintrittsverhalten auf vollständiges Verhalten und vollständigen Eintritt zu erweitern Wir werden weitere Verhaltensmuster untersuchen. In der dritten Phase führen wir hauptsächlich eine automatisierte Musterextraktion durch, oder mit anderen Worten: Die Fähigkeit des Netzwerks, Verhaltensweisen automatisch anzupassen, wird stärker sein.
- In der Linkrichtung konzentrieren wir uns hauptsächlich auf zwei Dinge: Zum einen auf die Seitenwiederherstellung und zum anderen auf die Kartenwiederherstellung. Dabei werden Algorithmen und technische Fähigkeiten verwendet, um das, was Benutzer „sehen“, in Modellentscheidungen wiederherzustellen.
- In Richtung NLP hatten wir früher eine andere Richtung namens Multimodalität, aber objektiv gesehen geben uns mit der Popularität von LLM auch externe Technologien mehr Input, daher führen wir LLM IN CTR separat als eine wichtige technische Richtung auf.
2 Die Praxis der Informationsflusswerbung in Meituan
2.1 Überblick über Benutzermodellierungsideen
Die allgemeine Benutzerrichtung ist in drei umgekehrte Richtungen unterteilt: Die erste ist die Zeitlinie, die zweite ist die Raumlinie und die dritte ist das Verhaltensmuster unter der gemeinsamen Wirkung von Zeit und Raum. Als wir es zerlegten, verwiesen wir auch auf die wichtigsten iterativen Methoden in der Industrie und in akademischen Kreisen, darunter Sitzungsmodellierung, Ultra-Long-Verhaltensmodellierung, Multi-Verhaltensmodellierung, Langzeit- und Kurzzeitmodellierung usw. Basierend auf Wissenschaft und Industrie, kombiniert mit geschäftlichen Problemen und Merkmalen, um Technologie und Wirtschaft besser zu integrieren, haben wir die folgende technische Aufschlüsselung.
Auf der Zeitachse glauben wir, dass eine langfristige und kurzfristige mehrstufige Integration wichtiger ist. Einerseits gibt es erhebliche Unterschiede in der Fokussierung von Benutzerinteressen auf verschiedenen Ebenen von „Segmenten“, wie z. B. Vergleich von Seitentendenzen, kontinuierlichere Interessen auf dem Pfad, Benutzer, die über einen bestimmten Zeitraum hinweg leichte Mahlzeiten zu sich nehmen usw. Wir Dies muss in verschiedene Ebenen von Segmenten unterteilt werden. Daher kombinieren wir einerseits kurzfristig und langfristig durch mehr Seiten und Pfade, erhöhen gleichzeitig das mittelfristige Interesse auf Tages- und Wochenebene, interagieren mit kurzfristigen, mittelfristigen, und kurzfristig, um die Verbindung im Zeitleistenverhalten zu verbessern. Andererseits werden dem Modell einige End-to-End-Methoden hinzugefügt, um Verhaltensmuster automatisch zu erkennen. Dies ist die zentrale Frage, die in der Zeitleiste behandelt wird.
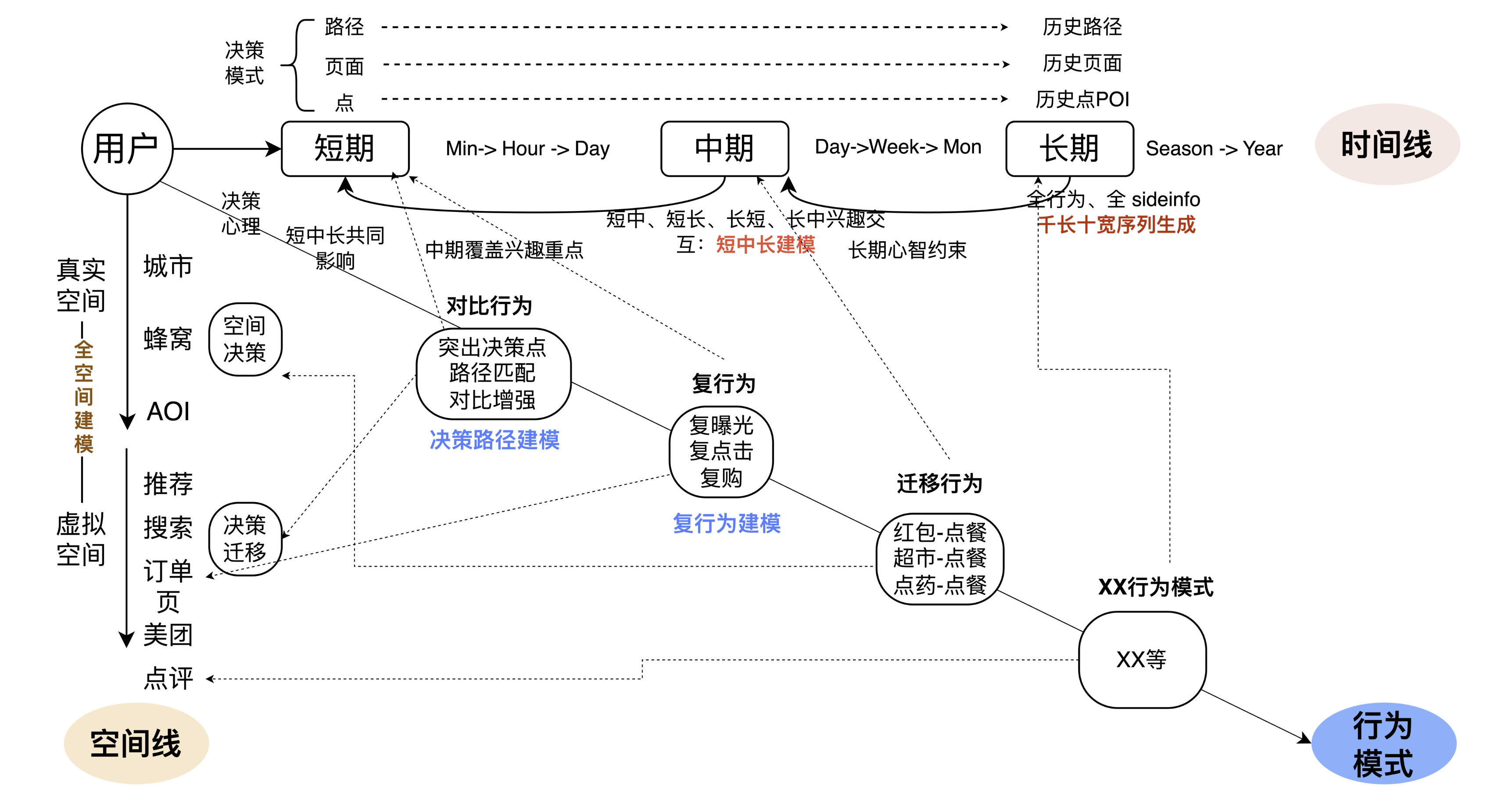
Auf der Raumlinie, in der realen physischen Raumdimension, sind die Probleme, mit denen wir konfrontiert sind, relativ klar. An verschiedenen Orten, etwa wenn man zur Arbeit geht und wenn man zu Hause ist, sind die Interessen der Menschen tatsächlich nicht genau die gleichen Platz, den wir jedem empfehlen. Wenn Benutzer beispielsweise im virtuellen Raum unterschiedliche Eingänge wie die Meituan-App und die Dianping-App nutzen, ändern sich auch die Interessen und Absichten der Menschen stark. Ein markantes Beispiel ist, dass Nutzer den Angeboten auf der Startseite und dem Mitgliederzugang eine ganz unterschiedliche Aufmerksamkeit schenken. Das durch räumliche Linien gelöste Problem besteht darin, realen Raum und virtuellen Raum zu kombinieren, um die wahre Absicht oder das wahre Verhaltensmuster des Benutzers zu bestimmen.
Die dritte Zeile besteht darin, es in das Unternehmen zu integrieren. Wenn ein Benutzer beispielsweise einige Vorgänge in der App ausführt (erhält einen roten Umschlag), welche Auswirkungen wird dieses Verhalten auf die Essensbestellung haben? Im Wesentlichen versteht das Modell, welche Auswirkungen der Benutzer auf das nächste Verhalten haben wird, nachdem einige Vorgänge ausgeführt wurden, sodass das Modell verschiedene Benutzerverhaltensmuster lernen und das Benutzerverhalten besser vorhersagen kann. Das Obige ist die Gesamtidee unserer Benutzermodellierung.
2.1.1 Entscheidungspfadmodellierung
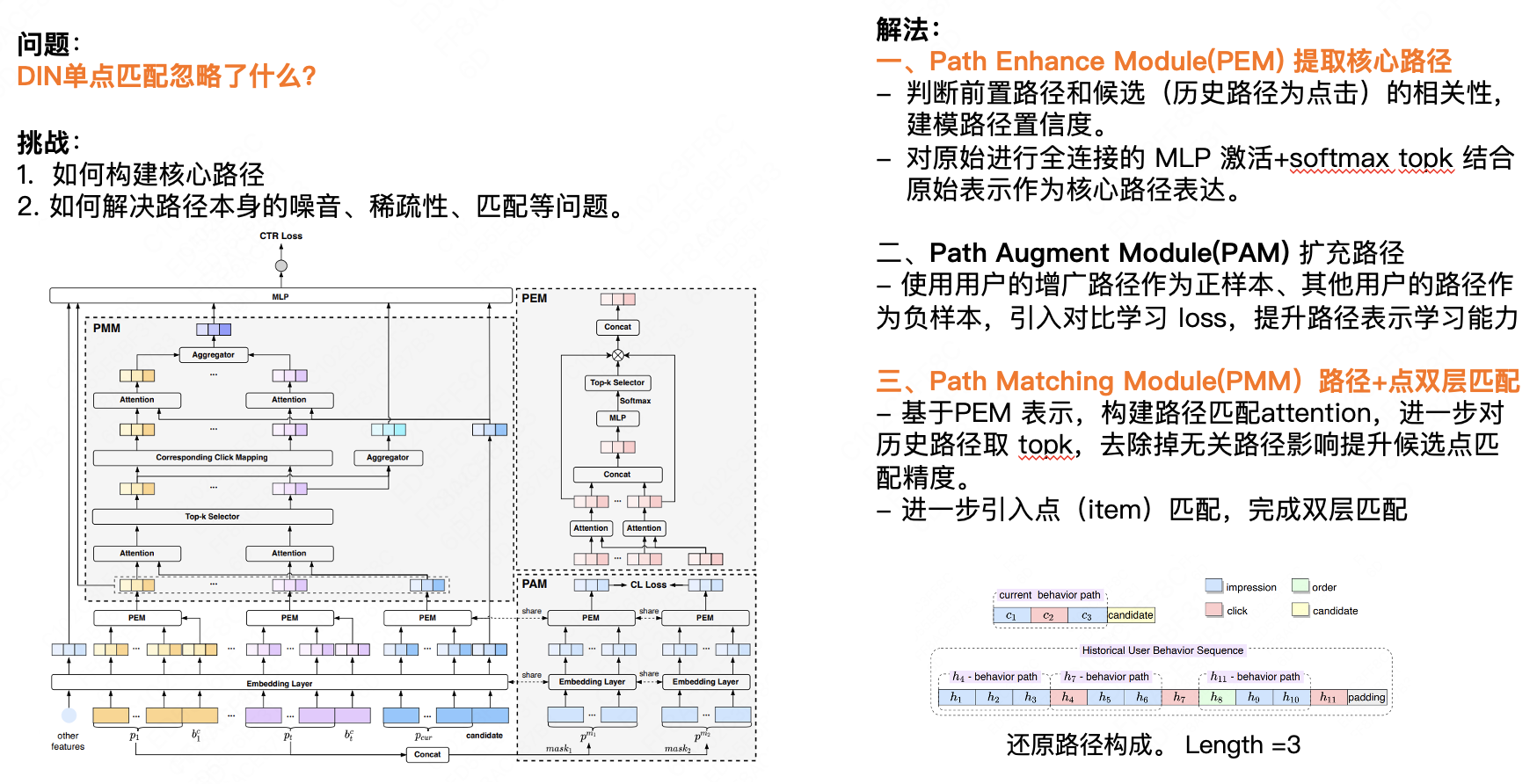
In diesem Abschnitt wird die Entscheidungspfadmodellierung vorgestellt. Die erste Kernfrage lautet: Was ignoriert das DIN-Einzelpunkt-Matching? Wir glauben, dass der Single-Point-Matching die Auswirkungen des vorherigen Verhaltens auf das nachfolgende Verhalten des Benutzers ignoriert. Bei den meisten E-Commerce-Unternehmen weist das Verhalten der Benutzer über einen bestimmten Zeitraum hinweg ein gewisses Maß an Konsistenz auf. Wir können das nächste Verhalten anhand der historischen Verhaltensdaten des Benutzers vorhersagen. Hier gibt es zwei Herausforderungen: Erstens, wie man den Kernpfad konstruiert, und zweitens, wie man das Rauschen, die Sparsamkeit, die Anpassung und andere Probleme des Pfades selbst löst. Unsere Lösung besteht hauptsächlich aus drei Punkten:
Zunächst extrahiert das Path Enhance Module (PEM) den Kernpfad.
- Bestimmen Sie die Korrelation zwischen dem vorherigen Pfad und dem Kandidaten (der historische Pfad ist ein Klick) und modellieren Sie die Pfadkonfidenz.
- Die ursprüngliche vollständig verbundene MLP-Aktivierung + Softmax Top K wird mit der ursprünglichen Darstellung als Kernpfadausdruck kombiniert.
Zweitens erweitert das Path Augment Module (PAM) den Pfad.
- Unter Verwendung des erweiterten Pfads des Benutzers als positive Stichprobe und der Pfade anderer Benutzer als negative Stichprobe wird ein vergleichender Lernverlust eingeführt, um die Lernfähigkeiten für die Pfaddarstellung zu verbessern.
Drittens: Path Matching Module (PMM) Pfad + Punkt-Doppelschicht-Matching.
- Basierend auf der PEM-Darstellung wird die Pfadanpassungsaufmerksamkeit erstellt und die Top K der historischen Pfade werden weiter ausgewählt, um den Einfluss irrelevanter Pfade zu entfernen und die Übereinstimmungsgenauigkeit der Kandidatenpunkte zu verbessern.
- Führen Sie weiter den Punkt-(Element-)Matching ein, um den Double-Layer-Matching abzuschließen.
2.1.2 Modellierung des Benutzerverhaltens für Ultra-Long und Ultra-Wide
Ich glaube, viele Studenten wissen, dass die ultralange Modellierung im Wesentlichen durch Näherungstechnologien wie Clustering und lokales Hashing implementiert wird. Die Einführung der Ultra-Wide-Modellierung ist im Wesentlichen darauf zurückzuführen, dass wir alle Eingaben zusammenfassen müssen und daher ein größeres und komplexeres Modell erforderlich ist, um die Dinge zu handhaben. In der Praxis haben wir dies jedoch nicht vollständig realisiert, da die aktuelle Rechenleistung dies nicht unterstützen kann. Wir haben einen Kompromiss eingegangen, der auf dem Niveau von 1000 (Länge) liegt, und die Breite liegt derzeit auf dem Niveau von 10+. Offline kann größere Maßstäbe unterstützt werden, und der Effekt wurde auf das Niveau von 10.000 erheblich verbessert Die Iterationseffizienz wird online stark eingeschränkt.
Auch hier stehen wir vor zwei Fragen: Die erste Frage ist, warum SIM/ETA keine Ergebnisse bringt? Diese Richtung wurde zuerst von E-Commerce-Plattformen vorgeschlagen. Wenn Benutzer beispielsweise nach Verhaltensweisen im Zusammenhang mit Schuhen auf der Website suchen, können sie auch verschiedene andere Dinge filtern zu Schuhen können herausgefiltert werden, Geräusche, die nichts mit Schuhen zu tun haben, können herausgefiltert werden und die Schuhpräferenzen des Benutzers können erlernt werden. Das Bestellen zum Mitnehmen ist für einen Kandidaten-Burger relativ anders, wenn Verhaltensweisen, die nichts mit dem Burger zu tun haben, durch die Burger-Kategorie herausgefiltert werden, gehen mehr Informationen über den Geschmack des Benutzers verloren. Dies wird durch geschäftliche Unterschiede verursacht.
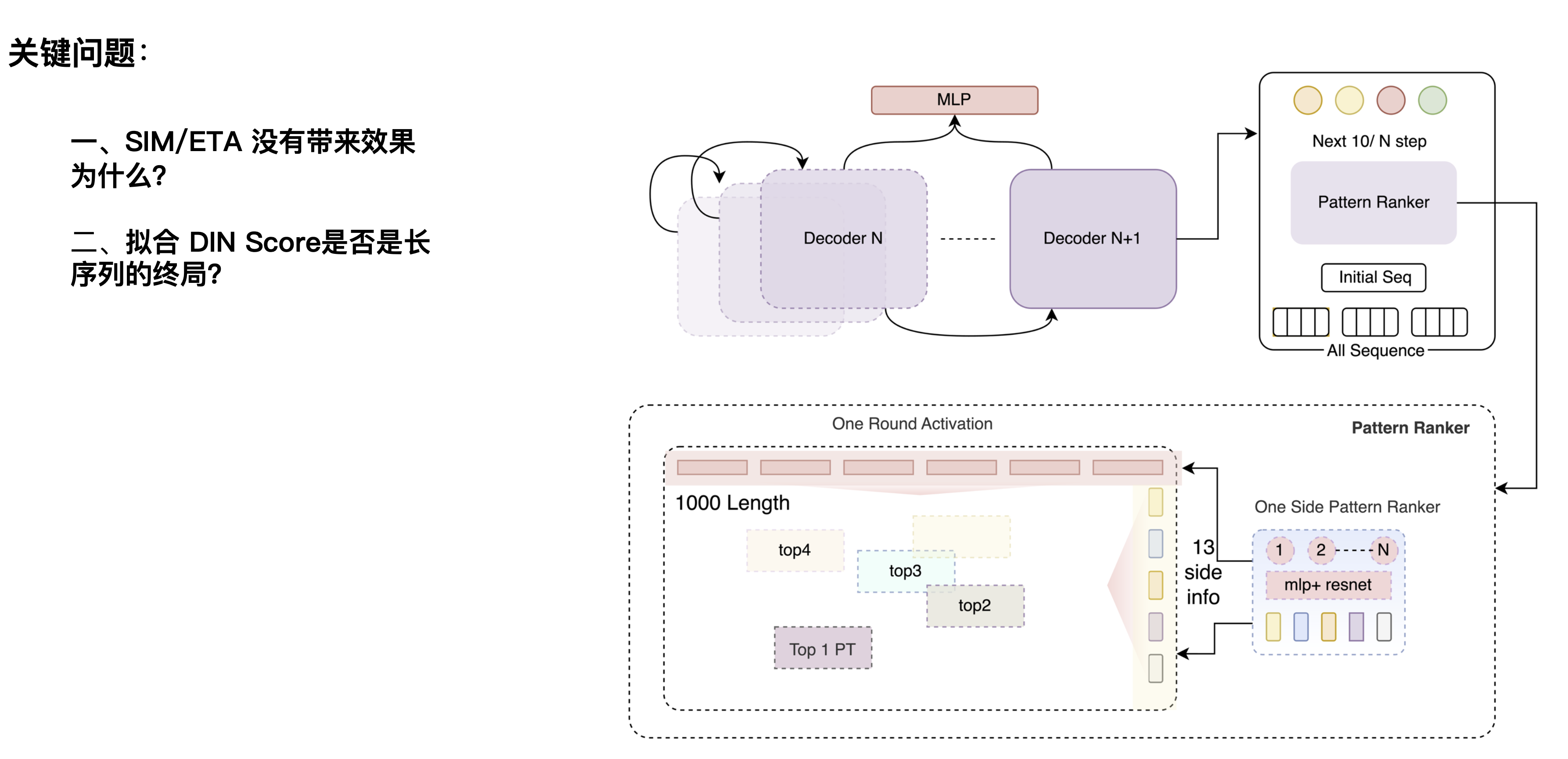
Die zweite Frage ist: Ist die Anpassung des DIN-Scores das Endspiel für lange Sequenzen? Es gab einen früheren Artikel in der Branche, der davon ausging, dass der DIN-Score der Maßstab ist, der Auswirkungen haben kann, und eine weitere Erweiterung auf die 10.000- oder 100.000-Ebene kann die Wirkung maximieren. Durch Experimente brachte die lineare Erweiterung unserer CTR-Szene auf die ultralange Ebene jedoch keine weiteren Auswirkungen, sondern nahm nach einer bestimmten Länge ab. Wir glauben, dass die Entrauschungsfähigkeit des DIN-Netzwerks selbst nicht sehr stark ist oder dass seine strukturelle Fähigkeit, Label-Ergebnisse zu extrahieren, nicht stark genug ist. Wenn es sich nicht um ein besonders starkes Netzwerk handelt, werden die Informationen, die es aufnehmen kann, bei einer Erweiterung relativ begrenzt sein.
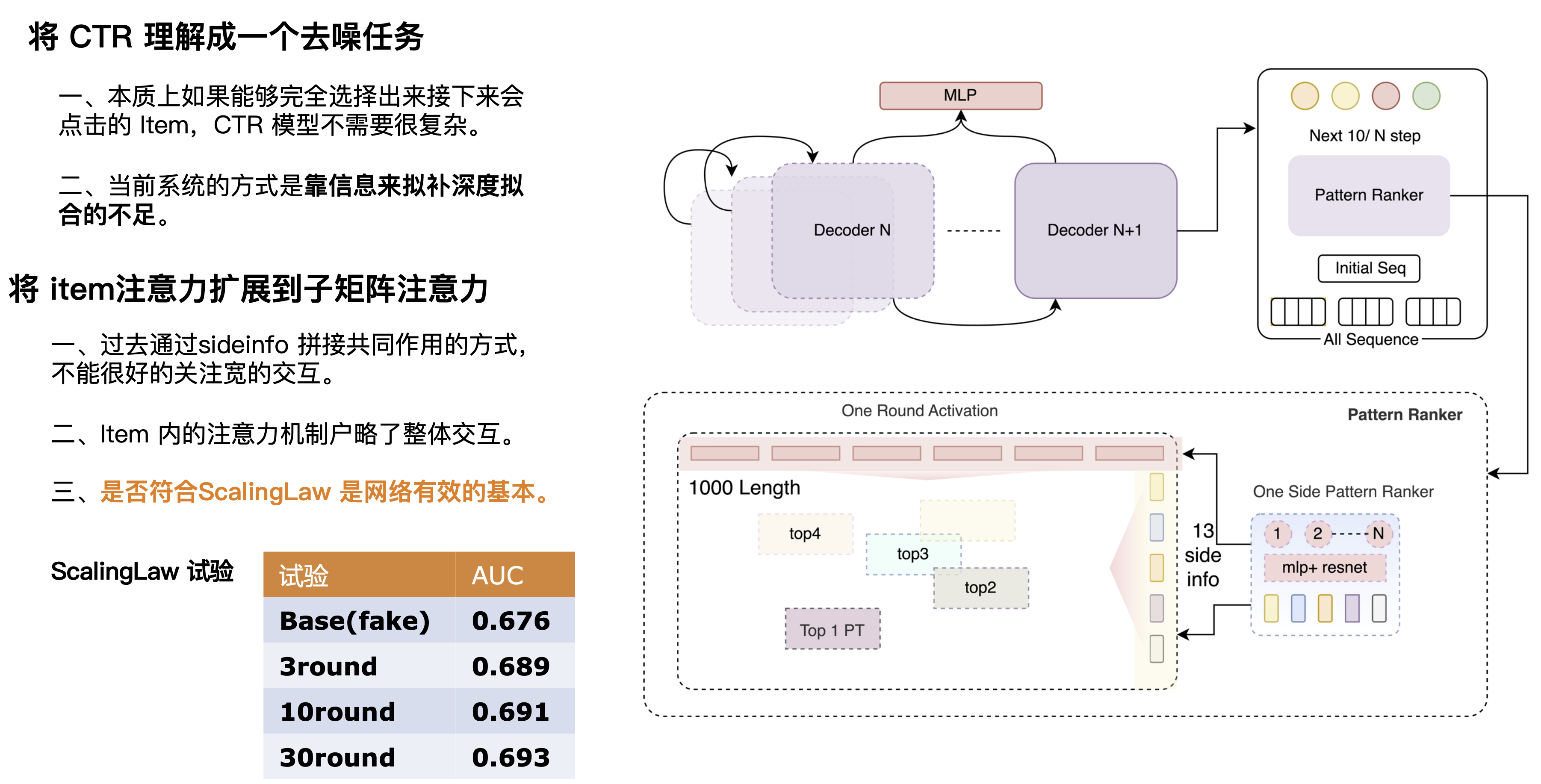
Wir können CTR als eine Entrauschungsaufgabe verstehen, bei der es sich im Wesentlichen um den Prozess der Zuordnung von Benutzern und Kandidaten auf der Grundlage der Benutzerhistorie und aktueller Szenarien handelt. Wir haben festgestellt, dass wir mit einem einfachen Netzwerk auch eine hohe AUC erzielen können, wenn wir genau vorhersagen oder sämtliches Rauschen entfernen können, z. B. indem wir die Kreuzungsinformationen „Label POI“ und „Target“ abgleichen. Daher glauben wir, dass das perfekte CTR-Netzwerk eine Kombination aus starkem Vorhersagenetzwerk und schwachem Matching-Netzwerk sein sollte. Das Vorhersagenetzwerk sollte ein sehr leistungsfähiges Netzwerk sein, das mehrere Schichten überlagern kann, um Informationen zu extrahieren und ein genaueres Vorhersageergebnis zu erhalten, das dem Ziel entspricht. Deshalb haben wir einen mehrschichtigen Decoder entwickelt, und jede Decoderschicht kann Informationen integrieren. Durch die kontinuierliche Auswahl effektiver Matrizen und die wiederholte Überlagerung effektiver Informationen können wir die Informationen genauer machen. Hier haben wir eine Reihe von Scaling-Law-Experimenten durchgeführt, um die Wirksamkeit der Ergebnisse durch Überlagerung mehrerer Netzwerkrunden zu überprüfen. Es ist ersichtlich, dass mit zunehmender Rundenzahl auch die Fähigkeit des Netzwerks, Benutzerverhalten zu lernen (AUC erhöht sich Schicht für Schicht), zunimmt.
2.2 Vollständige Restaurierungsmodellierung
Was ist eine vollständige Reduktionsmodellierung? Eine Definition, die wir geben, ist die Wiederherstellung dessen, was der Benutzer sieht. Die CTR-Aufgabe besteht darin, anhand der angezeigten Informationen zu bestimmen, ob der Benutzer klickt. Der wichtigste Punkt besteht darin, alle angezeigten Informationen in das Modell zu integrieren. In der Vergangenheit wurden bei der einfachen Modellierung durch ID-Darstellung der Kontext und die Anzeigeinformationen ignoriert führte zu einer größeren Informationslücke.
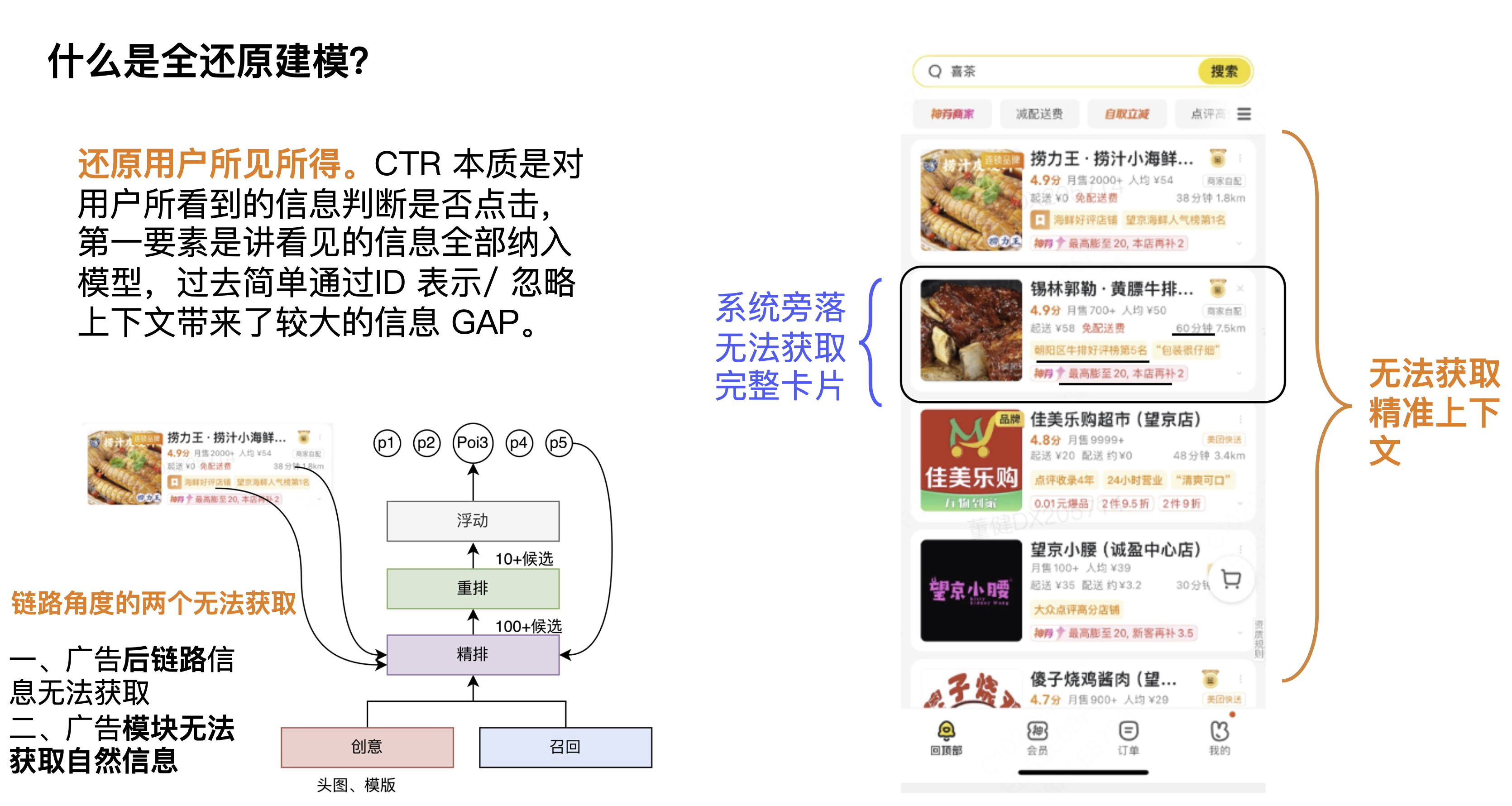
In der ersten Perspektive sind Kontextkarten nicht verfügbar. Kontextinformationen sind für die CTR des aktuellen Kandidaten und der aktuellen Karte sehr wichtig. Einige Studenten denken vielleicht, dass eine Neuanordnung dieses Problem lösen kann, aber wir glauben immer, dass Kontextinformationen zu den Linkinformationen gehören. Natürlich kann jedes Modul einen anderen Lernschwerpunkt haben und tatsächlich bringen bestimmte Effekte. Aus der zweiten Perspektive betrachten wir die Rechenleistung. Da die Rechenleistung auf der Schätzungsseite relativ hoch ist, wird der Umfang ihrer Auswirkungen größer sein und sie kann tatsächlich mehr Wirkungsraum bringen.
Betrachtet man das Bild in der unteren linken Ecke, gibt es aus Linkperspektive zwei Module, die nicht erhältlich sind, nämlich das Schätzungsmodul und das Werbemodul. Der erste besteht darin, dass die Backlink-Informationen der Werbung nicht abgerufen werden können, einschließlich der angezeigten Lieferinformationen, Liefergebühren, genauen Rabattinformationen usw., und der zweite darin, dass die natürlichen Informationen, einschließlich des natürlichen Kontexts, nicht abgerufen werden können. Daher besteht die Wiederherstellung aus einer anderen Perspektive darin, wie die Einschränkungen der Verbindung aufgehoben und Durchlaufinformationen verwendet werden können.
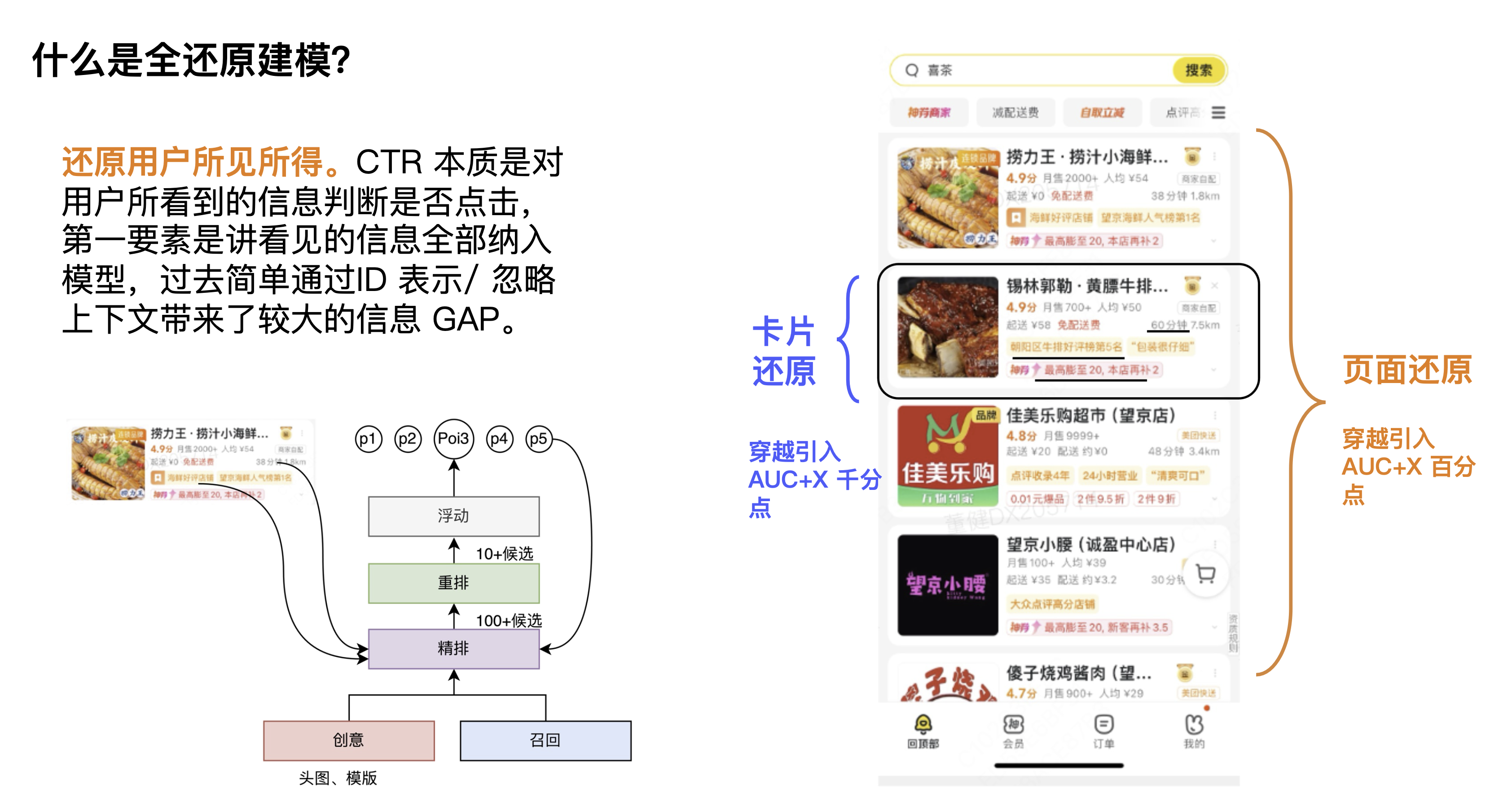
Dies sind einige der Probleme, mit denen die vollständige Wiederherstellungsmodellierung konfrontiert ist. Sie können tatsächlich in zwei Richtungen zusammengefasst werden: die Kartenwiederherstellung und die Seitenwiederherstellung. Zu Beginn haben wir die Karten- und Seiteninformationen vollständig eingegeben und den Anstieg der AUC beobachtet, um den Gesamtraum zu beurteilen. Die Ergebnisse zeigten, dass die Seiteninformationen auf der Perzentilebene lagen war mehrere tausendstel Punkte höher.
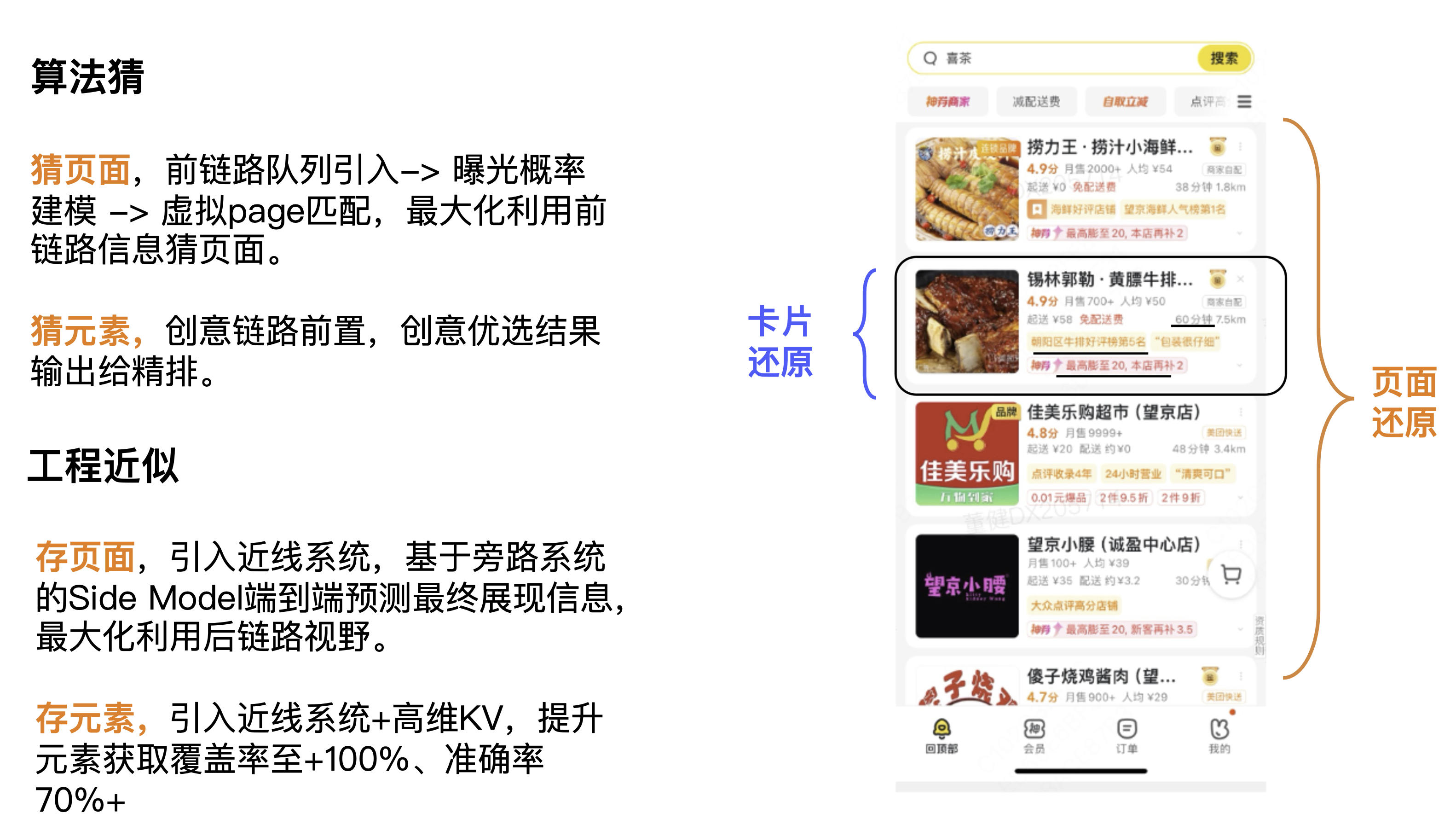
Gesamtlösungsidee
Erweitern Sie hier die Seitenwiederherstellung und die Kartenwiederherstellung. Was das Denken betrifft, lösen wir es zunächst hauptsächlich aus zwei Dimensionen: Algorithmus und Technik. Auf der Algorithmusebene besteht die erste darin, die Seite zu erraten und dabei die Informationen des vorherigen Links zu maximieren, um die Seite zu erraten. Die zweite Möglichkeit besteht darin, das Element mit dem kreativen Link davor zu erraten und die Ergebnisse der kreativen Optimierung auszugeben feines Ranking. Auf technischer Ebene besteht die erste darin, Seiten zu speichern, ein Nearline-System einzuführen und die End-to-End-Vorhersage des Seitenmodells basierend auf dem Bypass-System zu verwenden, um schließlich Informationen anzuzeigen und die Nutzung der Backlink-Ansicht zu maximieren. Die zweite Möglichkeit besteht darin, Elemente zu speichern, wodurch ein Nearline-System + hochdimensionales KV eingeführt wird, um die Elementerfassungsabdeckung auf +100 % und die Genauigkeit auf über 70 % zu erhöhen.
Wie bereits erwähnt, haben kontextbezogene Informationen einen größeren Einfluss auf den endgültigen Klick. Da das CTR-Modul den Kontext nicht ermitteln kann, bestand die bisherige Lösung darin, eine Neuanordnung einzuführen, um eine kleine Warteschlange zu modellieren, wodurch die Auswirkung kontextbezogener Linkinformationen verringert wurde. Als nächstes stehen wir vor der Herausforderung:
- Der Kontext besteht aus zwei Teilen: Satz und Sequenz. Wie erstellt man ein Kontextvorhersagemodul?
- Wie interagieren simulierte Kontexte und Kandidaten?
- Wie kann die Genauigkeit der simulierten Seite durch Destillation weiter verbessert werden?
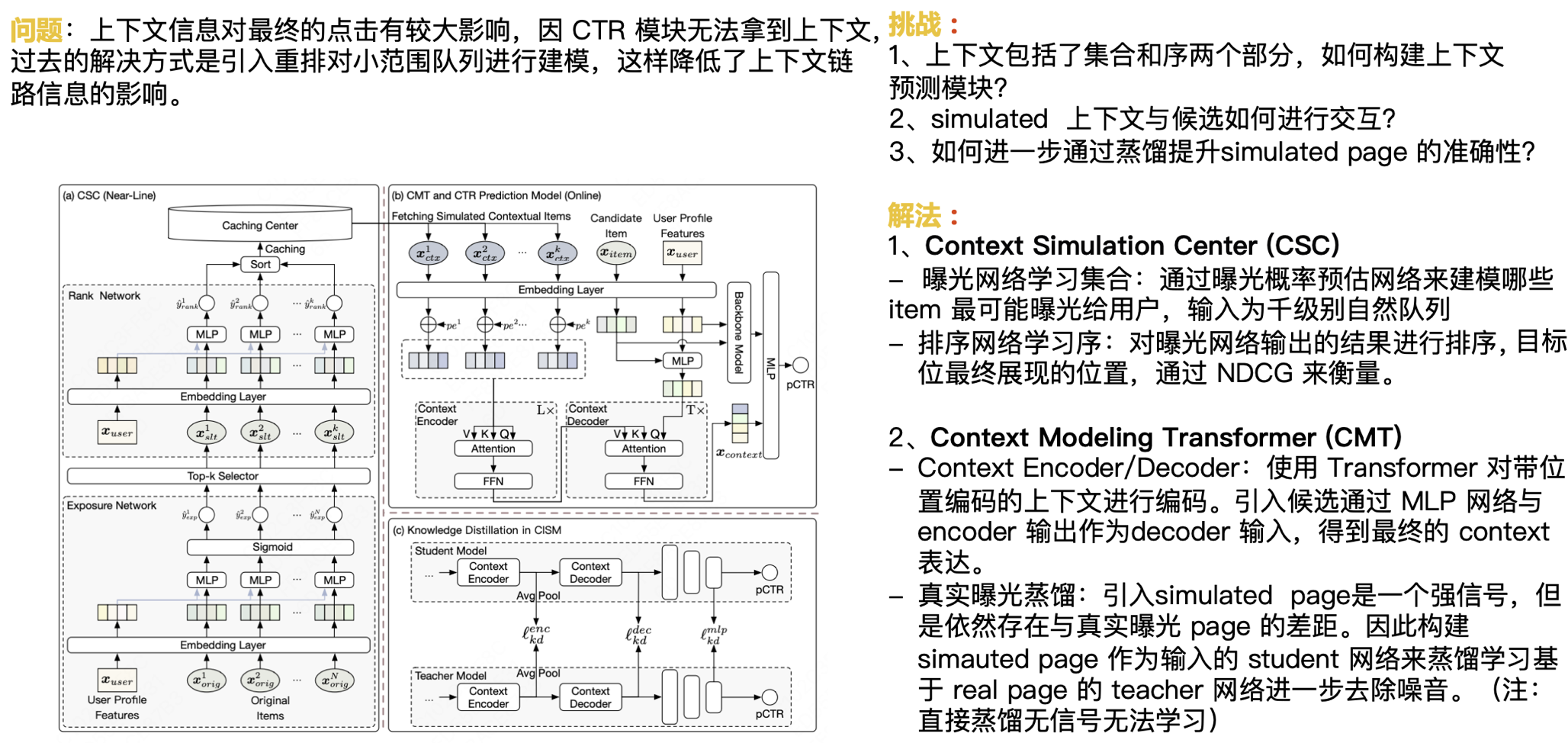
Unsere Lösung ist:
Kontextsimulationszentrum (CSC)
- Lernsatz für das Expositionsnetzwerk: Verwenden Sie das Netzwerk zur Schätzung der Expositionswahrscheinlichkeit, um zu modellieren, welche Elemente den Benutzern am wahrscheinlichsten ausgesetzt sind, und die Eingabe ist eine natürliche Warteschlange mit tausend Ebenen.
- Sortierungsnetzwerk-Lernsequenz: Sortieren Sie die vom Belichtungsnetzwerk ausgegebenen Ergebnisse und messen Sie die endgültige Zielposition mit NDCG.
Kontextmodellierungstransformator (CMT)
- Kontext-Encoder/Decoder: Verwenden Sie Transformer, um Kontext mit Positionskodierung zu kodieren. Der Kandidat wird über das MLP-Netzwerk eingeführt und die Encoder-Ausgabe wird als Decoder-Eingabe verwendet, um den endgültigen Kontextausdruck zu erhalten.
- Destillation der echten Belichtung: Die Einführung der simulierten Seite ist ein starkes Signal, aber es gibt immer noch eine Lücke zur Seite der echten Belichtung. Daher wird das Schülernetzwerk mit der simulierten Seite als Eingabe so aufgebaut, dass das Lehrernetzwerk basierend auf der realen Seite destilliert und erlernt wird, um Rauschen weiter zu entfernen. (Hinweis: Direktdestillation hat kein Signal und kann nicht erlernt werden)
Wir haben Caching- und Vorhersagekonfigurationsstrategien in Verbindung mit echter Destillation eingeführt, um den Effekt, der Teil der Seitenwiederherstellung ist, weiter zu verbessern.
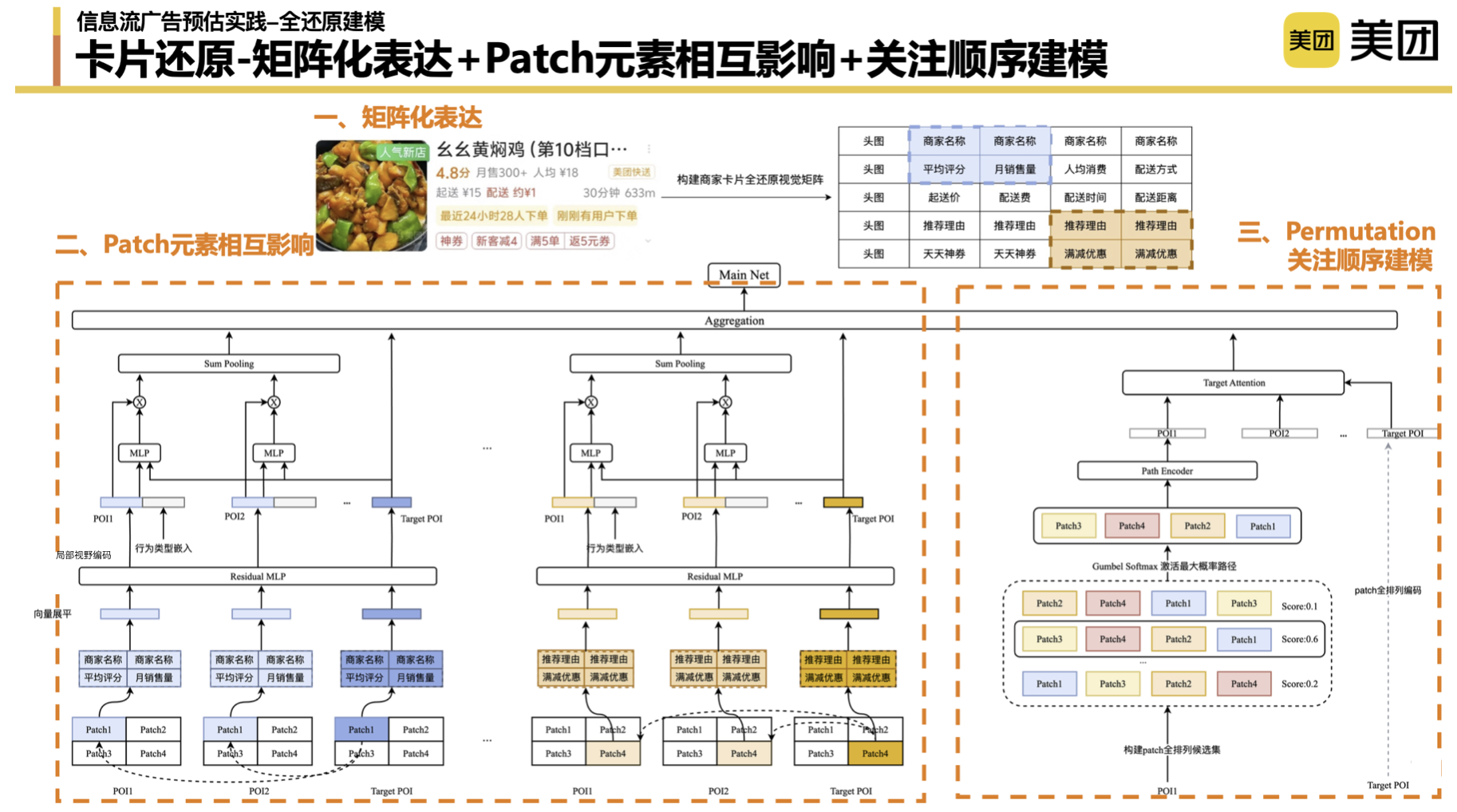
Die Gesamtidee der Kartenwiederherstellung besteht aus drei Teilen: Der erste Teil besteht darin, die Karteninformationen abzurufen. Der zweite Teil besteht darin, die Karten zu erstellen, die der Benutzer sieht.
Überlegungen zu Kartenlösungen : Aufgrund der seriellen und parallelen Module des Such- und Werbesystems können wir einige Daten nicht erhalten. In der Anfangsphase haben wir darüber nachgedacht, ob es eine „ultimative Lösung“ gibt. In den frühen Tagen haben wir reine Kachelung (reine ID) verwendet, um die von den Benutzern angezeigten Informationen wiederherzustellen, aber gibt es eine bessere Möglichkeit? Stellen Sie beispielsweise direkt die Bilder vor, die Benutzer sehen. Die aktuellen technischen Möglichkeiten unterstützen jedoch nicht die vollständige Aufzeichnung des gesamten Bildes, geschweige denn den vollständigen und genauen modellierenden Ausdruck der Bildinformationen. Letztendlich haben wir uns dafür entschieden, die Karten durch eine Matrix zu bilden, um die Informationen zu simulieren, die der Benutzer sieht.
Matrixausdruck, Modellierung auf Patch-Ebene : Zuerst haben wir den Matrixausdruck verwendet, um die Form der Karte zu formen und die Beziehung zwischen den oberen und unteren Elementen aufzubauen, die der Benutzer sieht und gewinnt. Auf der Präsentationsebene haben unterschiedliche Matrixkonstruktionsmethoden einen gewissen Einfluss auf die Ergebnisse, und die Details werden hier nicht besprochen. Im zweiten Aspekt haben wir auch einige Ideen aus dem Bildbereich übernommen und das Konzept von Patch eingeführt, um uns dabei zu helfen, Bilder in Tokens umzuwandeln und die Interaktion zwischen verschiedenen Anzeigeelementen weiter zu erlernen. Im Laufe der Übung müssen wir auch einige Parameter anpassen, z. B. ob der Patch 2 * 2 oder 3 * 3 ist. Einschließlich der Schrittlänge haben wir herausgefunden, dass der Effekt umso besser ist, je kürzer die Schrittlänge ist. Wir haben während des gesamten Patch-Level-Matching-Prozesses auch viele Experimente durchgeführt. Unsere vorläufige Schlussfolgerung ist, dass der Endeffekt des Matchings von Einzelpositions-Patches und globalen Patches besser ist.
Modellierung der Aufmerksamkeitssequenz : Die Sequenzmodellierung dient dazu, die Browsing-Sequenz des Benutzers basierend auf den Elementen, auf die der Benutzer achtet, weiter zu simulieren. Logischerweise können wir diesen Teil der Daten ohne Augenüberwachung nicht wirklich gewinnen. Hier haben wir einen kleinen Trick gemacht, um die Matrizen dieser vier Patches vollständig anzuordnen, alle Pfade auf Patch-Ebene des Benutzers aufzulisten und das Modell die impliziten Bewertungen verschiedener Permutationen und Kombinationen lernen zu lassen. Die Patch-Reihenfolge-Kombination mit der höchsten Aktivierungsbewertung wird durch den Encoder zu einem Aufmerksamkeitsreihenfolge-Ausdruck aggregiert, um die Aufmerksamkeitsreihenfolge-Kombination des POI des Ziels weiter anzupassen.
2.3 LLM in CTR
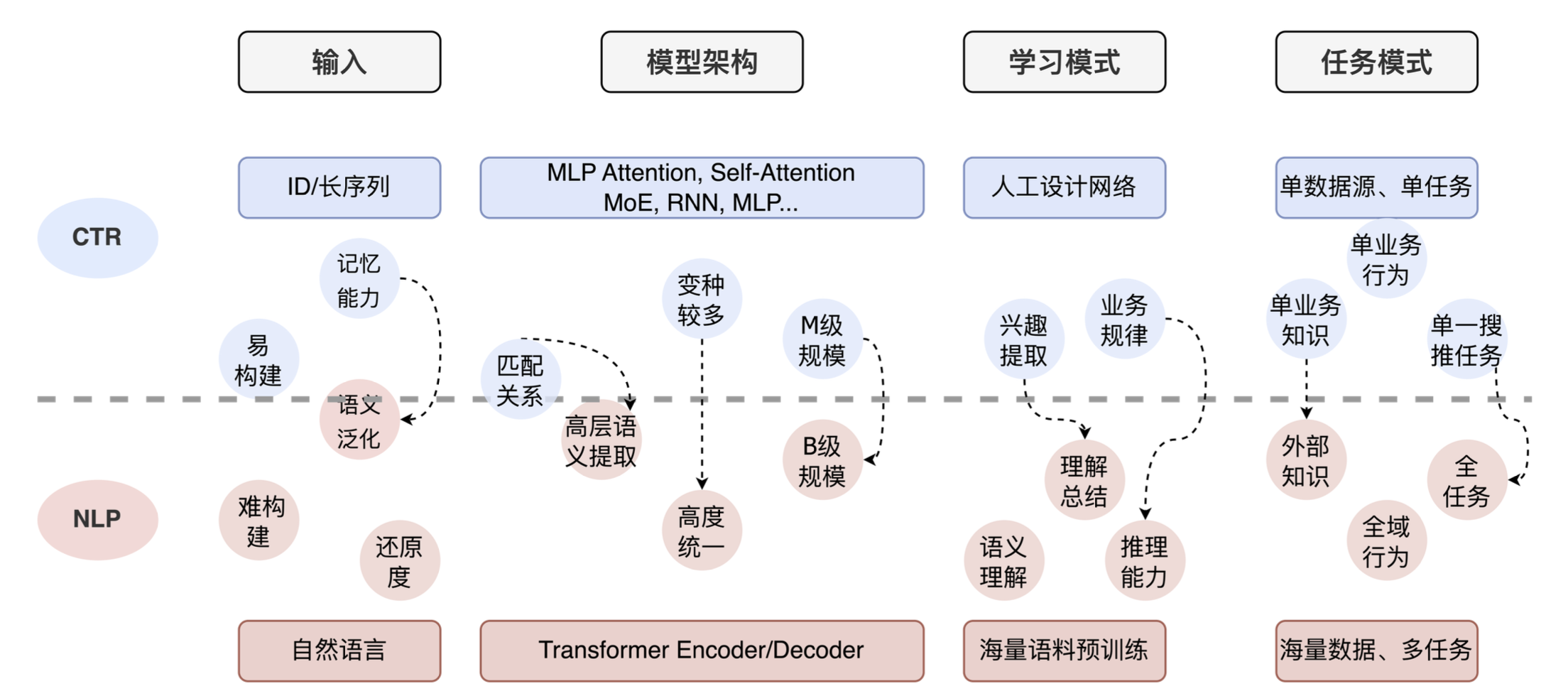
Teilen Sie abschließend die Anwendung großer Modelle in der CTR. Wir haben einige Voruntersuchungen durchgeführt und festgestellt, dass viele technische Teams derzeit ähnliche Gesamtideen haben. Die folgende Abbildung zeigt den Vergleich zwischen CTR-Aufgaben und NLP-Aufgaben. Sie können sehen, dass es große Unterschiede zwischen Eingabe, Modellarchitektur, Lernmodus und Aufgabenmodus gibt. Die NLP-Aufgabe besteht aus einem Token in natürlicher Sprache + einem großen Transformer + Verständnis- und Argumentationsfähigkeit. Die CTR-Aufgabe besteht aus einer ID-Eingabe + einem künstlich gestalteten Netzwerk + einer starken Gedächtnisfähigkeit. Gleichzeitig nutzen die meisten Unternehmen für die CTR nur ihre eigenen Geschäftsdaten, da ihnen externes Wissen und umfassendes Verständnis der Aufgaben fehlen.
Basierend auf den oben genannten Aspekten haben wir daher drei Aspekte der Arbeit durchgeführt:
- Die erste Ebene, die Wissensinjektion, besteht darin, das externe, reale Wissen, das der aktuellen CTR fehlt, in das Modell einzubringen. Viele Unternehmen übernehmen diesen Teil der Arbeit, und dafür sind vor allem die technischen Fähigkeiten von Prompt erforderlich. Da die generierten Ergebnisse nicht unbedingt den CTR-Anforderungen entsprechen, müssen wir eine gute Anpassungsarbeit leisten. Entsprechend den Merkmalen der CTR können hochfrequente Wörter und niedrigfrequente Wörter unterschieden werden. Gleichzeitig sind einige Nachbearbeitungsarbeiten im Zusammenhang mit der sofortigen Fusion erforderlich, um die Übereinstimmung mit CTR-Aufgaben zu verbessern.
- Die zweite Ebene, die Denkinjektion, besteht darin, die strukturellen Fähigkeiten des großen Modells einzuführen oder den Beurteilungsprozess des großen Modells einzuführen.
- Die dritte Ebene ist die Paradigmeniteration. Meta scheint kürzlich einen Weg für generative Empfehlungen aufzuzeigen. Als wir letztes Jahr diese Richtung untersuchten, bestand unsere Hauptidee darin, die Eingabeform zu ändern und durch einen kleineren Token zu ersetzen, der wahrscheinlich nur Zehntausende groß ist, um das groß angelegte Softmax-Problem zu lösen. Anschließend können die Daten durch Transformationsüberlagerung in Kombination mit Aggregationssemantik von der Modellfusion bis zur End-to-End-Autoregression durchlaufen werden. Wir haben festgestellt, dass Transformer damit nicht gut umgehen kann, wenn die Eingabe besonders verrauscht ist. Bei Informationen mit relativ klarer Semantik weist Transformer jedoch eine gute Leistung beim Kontextverständnis auf. Deshalb haben wir zunächst eine Ebene der semantischen Aggregation erstellt, um das Rauschen der Eingabetoken zu reduzieren . Im Allgemeinen haben wir durch kleine Token, semantische Aggregation und Transformer-Architektur eine Welle von Verbesserungen bei den Geschäftseffekten herbeigeführt.
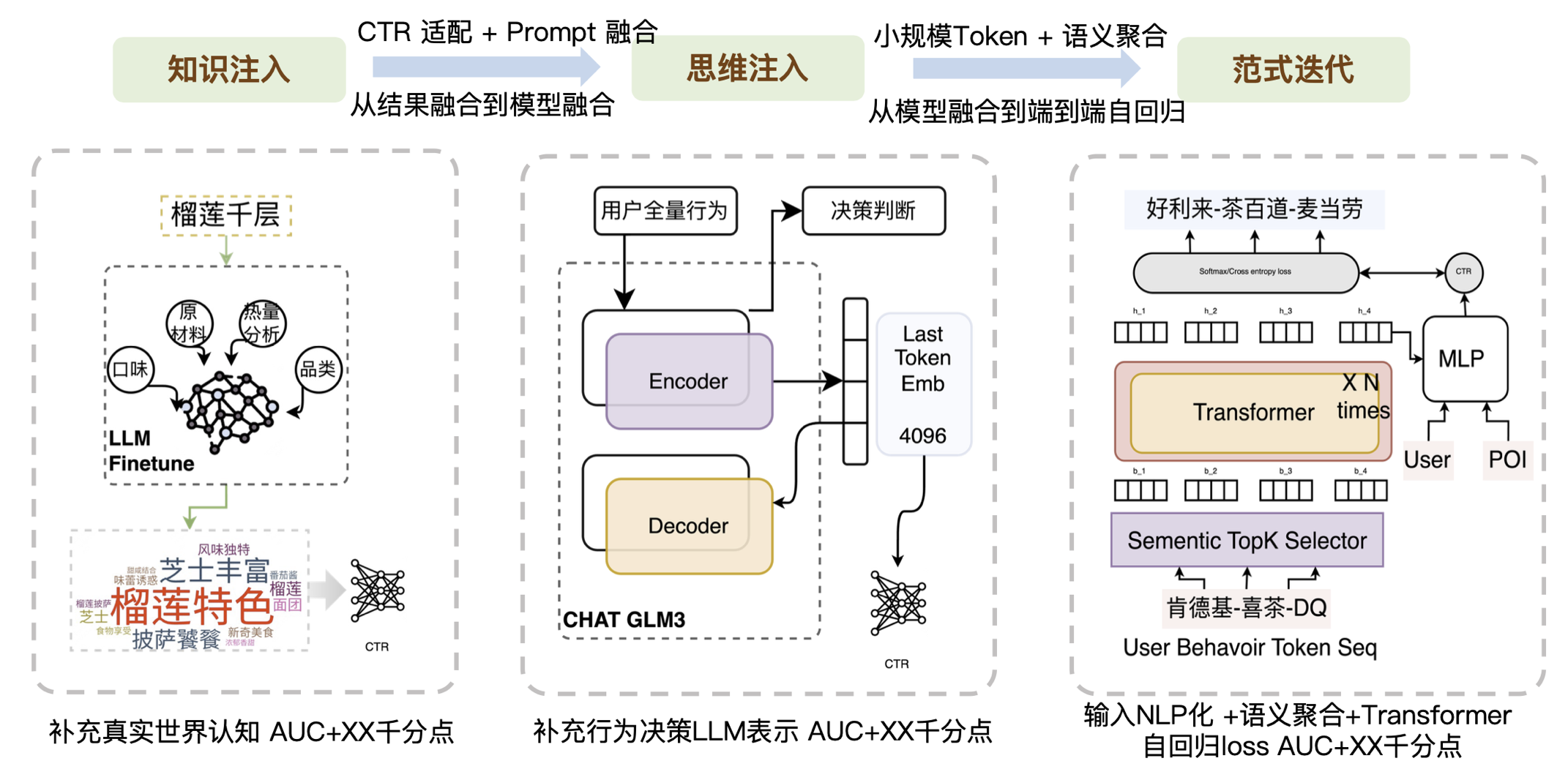
Zusammenfassend lässt sich sagen, dass das Wesentliche darin besteht, die Fähigkeiten, die CTR nicht hat, durch große Modelle auszugleichen. Wir unterteilen die Fähigkeiten, über die CTR derzeit nicht verfügt, in Wissensfähigkeiten, Generalisierungsfähigkeiten und Argumentationsfähigkeiten. Dementsprechend haben wir auch einige der Ergebnisse aufgelistet, die wir ausprobiert haben, wie in der folgenden Abbildung dargestellt:

03 Zusammenfassung und Ausblick
Im Allgemeinen besteht die Essenz der Schätzung darin, die tatsächlichen Bedürfnisse der Benutzer zu ermitteln. Einerseits beziehen wir uns auf die Branche und andererseits gehen wir tief in das Unternehmen ein, um weitere Benutzerverhaltensmuster herauszufinden Es wird untersucht, ob es eine automatisiertere Möglichkeit gibt, verschiedene Aspekte zu kombinieren. Restaurative Modellierung ist eine Verbesserung, die durch die gemeinsamen Anstrengungen von Algorithmen und Technik hervorgerufen wurde. Letztlich kann die Kombination von Algorithmus und Technik größere Veränderungen bewirken.
Die Kombination aus großen Modellen und Empfehlungen erhält von allen immer mehr Aufmerksamkeit, aber objektiv gesehen ist dies immer noch eine langfristige Arbeit. Zu diesem Zeitpunkt müssen wir noch einen praktikablen Weg finden und ihn weiter optimieren und verbessern Erwarten Sie voll und ganz, dass Sie mit einem „großen Umzug“ alle Probleme lösen werden. Eine durchgängige Empfehlung großer Modelle ist die gemeinsame Erwartung aller, aber auf dieser Grundlage glauben wir, dass die Eingabeskala die Garantie für den Effekt ist und die Rechenleistung die Garantie für die beiden oben genannten ist. Nur die leistungsstarke Kombination aus Software und Hardware kann die Zukunft gewinnen.
|. Antwortschlüsselwörter wie [Neujahrsartikel 2023], [Neujahrsartikel 2022], [Neujahrsartikel 2021], [Neujahrsartikel 2019], [Neujahrsartikel 2018], [Neujahrsartikel 2017]. Jahresartikel] und andere Schlüsselwörter im Dialogfeld der offiziellen Meituan-Kontomenüleiste Sehen Sie sich die Sammlung technischer Artikel des Meituan-Technikteams im Laufe der Jahre an.

|. Dieser Artikel wurde vom technischen Team von Meituan erstellt und das Urheberrecht liegt bei Meituan. Sie können den Inhalt dieses Artikels gerne für nichtkommerzielle Zwecke wie Weitergabe und Kommunikation nachdrucken. Bitte geben Sie an: „Der Inhalt wurde vom technischen Team von Meituan reproduziert . “ Dieser Artikel darf ohne Genehmigung nicht reproduziert oder kommerziell genutzt werden. Für kommerzielle Aktivitäten senden Sie bitte eine E-Mail an [email protected], um eine Genehmigung zu beantragen.
Es wird immer unlösbarer und die detaillierten Tages- und Wochenberichte machen es den IT-Bullen und -Pferden schwer! Wie kann man die Situation durchbrechen? AMD hat am Nationalfeiertag sein erstes kleines Sprachmodell AMD-135M veröffentlicht , aber wie kann ich auf das Netzwerk der Firma „Honor of Kings“ zugreifen? Die Shanghai Stock Exchange hat heute das Bieterhandelssystem getestet und 270 Millionen Bestellungen erhalten: Die Gesamtleistung ist normal, doppelt so hoch wie der historische Höchststand. Apple könnte sein erstes Smart Display und das unterstützende Betriebssystem homeOS FFmpeg 7.1 im Jahr 2025 auf den Markt bringen AI und kündigt den niedrigsten Rabatt von 10 % auf alle Open-Source-Modelle an. OpenAI plant, die Abonnementgebühren für ChatGPT deutlich zu erhöhen. Wer hat jetzt die Kontrolle über OpenAI? Redis 7.4.1 veröffentlicht