content
1. What is a reptile?
2. Why do web crawlers with python
3.python environment configuration
4. I need to know what pre-knowledge of python reptile
5. About Regular Expressions
6. Extract Web content and expression treated with n
7.xPath and BeautifulSoup intro
Simply put, reptiles probe is a machine, its basic operation is to simulate human behavior to various sites stroll, little buttons, look up data, information or to see the back back. Like a tireless insects crawling around in a building.
You can easily imagine: every reptile is your "avatar." Like the Monkey King pulled a handful of hairs, blow a bunch of monkeys.
You use every day Baidu, in fact, the use of this technology reptile: the release day countless reptiles to each site, their information come back again, and then the row of good makeup team waiting for you to retrieve.
Software to grab votes, equivalent to spread out numerous commitments, each avatar will help you train constantly refreshed more than 12306 tickets website. Once a ticket, immediately shot down, and then you shout: Come Tyrant payment.- from the user to know the history of almost
<- ... -!>: Defines the comment
<! DOCTYPE>: Defines the document type
<html>: total tag html document
<head>: Define the Head
<body>: define web content
<script>: Custom Scripts
<div>: Division, define partitions, container labels
<p>: paragraph, the paragraph defined
<a>: define hyperlinks
<span>: define the text container
<br>: wrap
<form>: Custom form
<table>: definition table
<th>: defined header
<tr>: table row
<td>: column of the table
<b>: define bold
<img>: Custom image
Import Re Import urllib.request Import the chardet the Response = the urllib.request.urlopen ( " http://news.hit.edu.cn/ " ) # input parameters for the page you want to crawl the URL of HTML = response.read () # html read variable chardet1 = chardet.detect (html) # acquires encoding html = html.decode (chardet1 [ ' encoding ' ]) # processed according to the acquired encoding
Here we have the official news website of a university as an example to demonstrate the operation python reptile, just a few lines of code above will be achieved crawling web content to local operations.
Next is the content of crawled to regular expression processing, get what we want to get to observe the page source code:

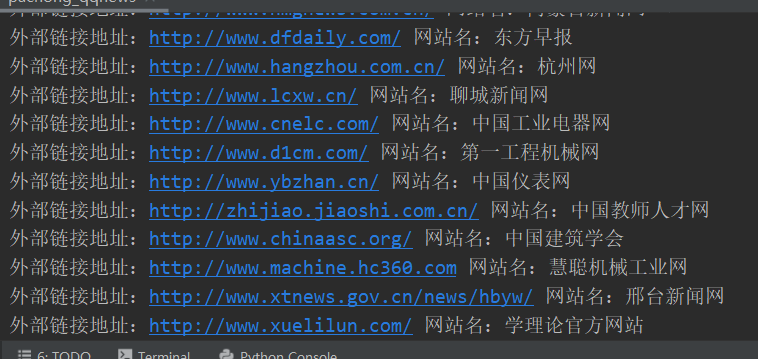
We hope for external links which are matched by the regular expression before the learned knowledge to achieve the following:
mypatten="<li class=\"link-item\"><a href=\"(.*)\"><span>(.*)</span></a></li>" mylist=re.findall(mypatten,html) for i in mylist: print("外部链接地址:%s 网站名:%s" %(i[0],i[1]))
The resulting effect is:
7.xPath and BeautifulSoup intro
In addition to the regular expression processing web documents obtained by, we can also consider their own web architecture.
XPath, full name of the XML Path Language, namely XML Path Language, it is a finding information in an XML document language. XPath was originally designed to search XML documents, but it also applies to search HTML documents.
nodename select all the child nodes of this node
/ nodes from the current selected direct child node
// Select descendant node from the current node
. Select the current node
.. select the parent node of the current node
@ selection attribute
Here a list of commonly XPath matching rules, e.g. / representatives selected direct child node representing the selected // all descendant nodes representative of selecting the current node, the current node .. Representative selected parent node @ attribute is added defining, selecting a specific node matching attributes.
from lxml import etree import urllib.request import chardet response=urllib.request.urlopen("https://www.dahe.cn") html=response.read() chardet1=chardet.detect(html) html=html.decode(chardet1['encoding']) etreehtml=etree.HTML(html) mylist=etreehtml.xpath("/html/body/div/div/div/div/div/ul/div/li")
BeautifulSoup4 reptile will learn skills. BeautifulSoup main function is to fetch data from the web, Beautiful Soup automatically converted to Unicode encoding input document, the document is converted to an output utf-8 encoded. BeautifulSoup supports the Python standard library of HTML parser also supports third-party parser, if we do not install it, then the default Python Python uses the parser, the parser lxml more powerful, faster, recommended resolve lxml device.
from BS4 Import the BeautifulSoup File = Open ( ' ./aa.html ' , ' RB ' ) HTML = File.read () BS = the BeautifulSoup (HTML, " html.parser " ) # indentation Print (bs.prettify () ) # format html structure Print (bs.title) # Get the name of the title tag Print (bs.title.name) # obtain the title tag of the text Print (bs.title.string) # all content acquisition head tag Print ( bs.head) #Get all the contents of the first tag div print (bs.div) # obtain a first div id tag value print (bs.div [ " id " ]) # Get all contents of a label to a print (bs.a) # obtain all the contents of all the tags in a Print (bs.find_all ( " a " )) # Get = ID "U1" Print (bs.find (ID = " U1 " )) # retrieve all a label, and a label print traverse href value for Item in bs.find_all ( " a " ): Print (item.get ( " href ")) # Get all of a label, and traverse print a label text value for Item in bs.find_all ( " a " ): Print (item.get_text ())
<- ... -!>: Defines the comment
<! DOCTYPE>: Defines the document type
<html>: total tag html document
<head>: Define the Head
<body>: define web content
<script>: Custom Scripts
<div>: Division, define partitions, container labels
<p>: paragraph, the paragraph defined
<a>: define hyperlinks
<span>: define the text container
<br>: wrap
<form>: Custom form
<table>: definition table
<th>: defined header
<tr>: table row
<td>: column of the table
<b>: define bold
<img>: Custom image