The spring batch framework is mainly used for batch processing of background services with a large amount of data. Using this framework can be more flexible, using various poses to perform tricky operations on the data, but after the amount of data reaches tens of millions of levels, the efficiency of processing tasks on a single machine has significantly declined Parallelism and partitioning are panacea for this problem.
By consulting the Chinese official website, I have a deeper understanding of Spring Bacth. I strongly recommend it. The documentation is really good and provides good ideas for a variety of distributed implementations.
First, let's understand parallelism and partitioning:
When to use parallel, multiple tasks do not use the same file, data table, index space can use parallel, this is very simple.
When to use partitioning, if sharing and competition do exist, then this service should be implemented using partitioned data. Another option is to use a control table to build an architectural module to maintain their interdependence. The control table should be Each shared resource is assigned a row of records. Regardless of whether these resources are used by a program, the batch architecture or program that executes the parallel job will then query this control table to determine whether the required resources can be accessed.
It is worth exploring in the work is the partition of Spring Batch, the partition is divided into local partition and remote partition. I personally understand that the differences between local and remote are:
Local partition, a complete reader, processor, writer execution step step is cut into multi-threaded simultaneous execution
Remote partition: a complete reader, processor, writer execution step step is cut and distributed to multiple nodes for execution
Start with a relatively simple local partition.
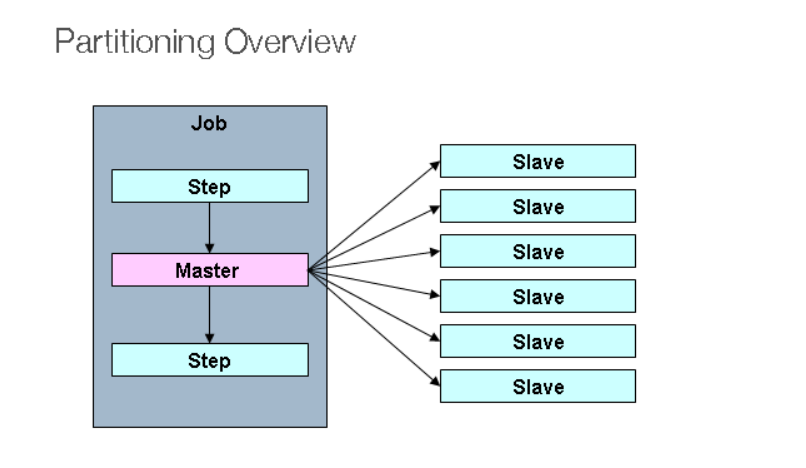
Local partition:
By checking the official documentation of spring batch, I learned that the core idea of partitioning is master-slave:
Split a step into multiple steps to execute:
The above code is analyzed, the reader, processor, writer required by the step step
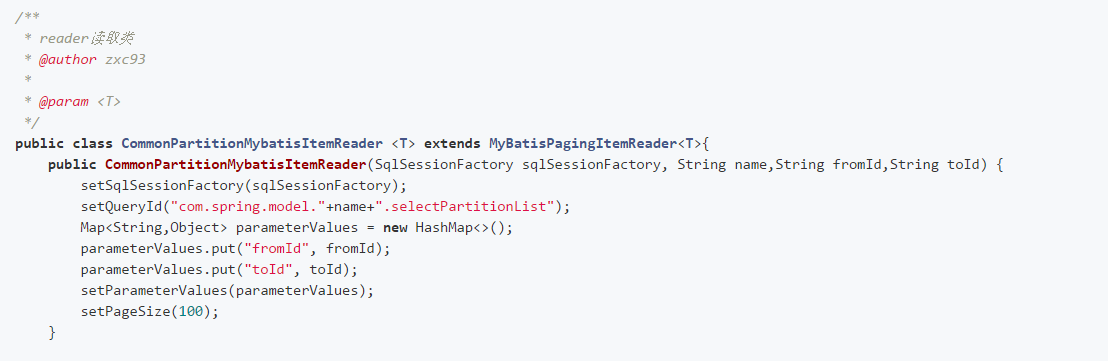
1、本文读取数据的方式,使用的是框架提供的API实现数据库分页读取MybatisPagingItemReader,工作中常用ItemReader自定义实现
2、自定义处理类实现ItemProcessor

3、文件写入,使用框架自带的API实现写入csv文件,FlatFileItemWriter,工作中常用ItemWriter自定义实现

4、启动类代码实现
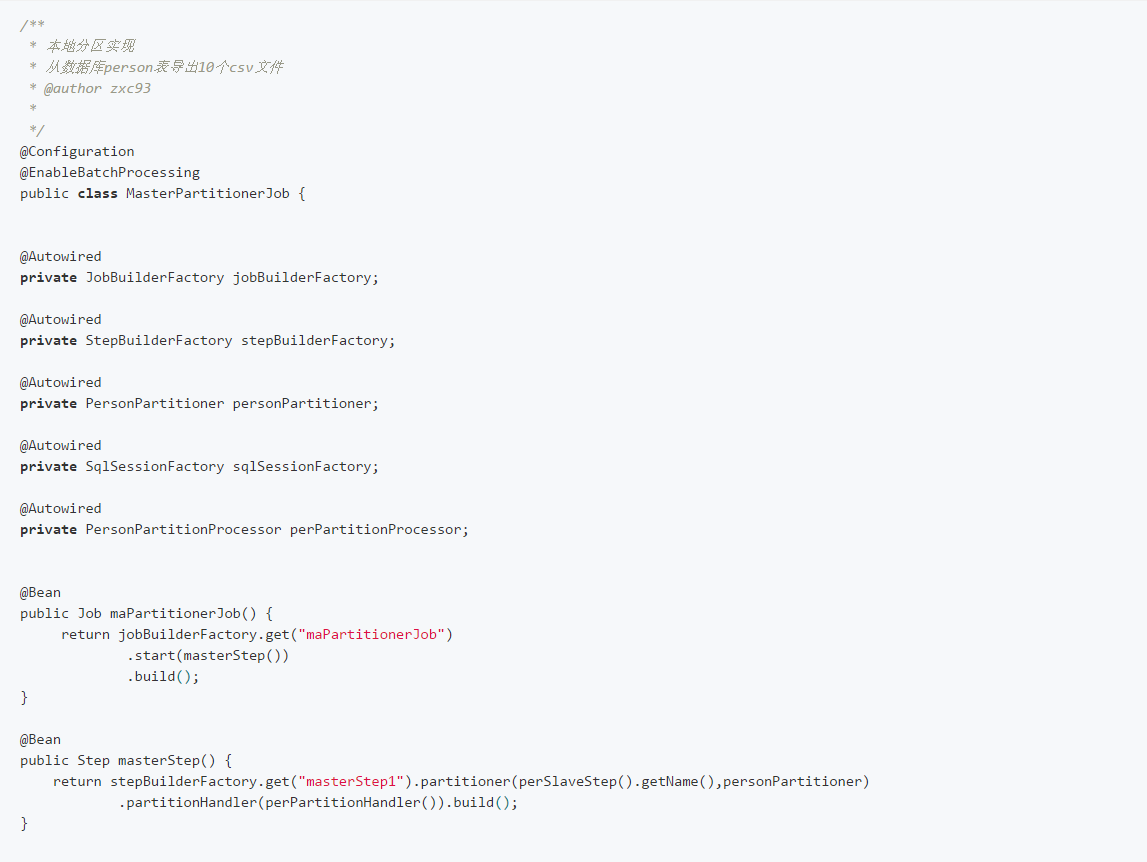

5、本地分区分割器实现
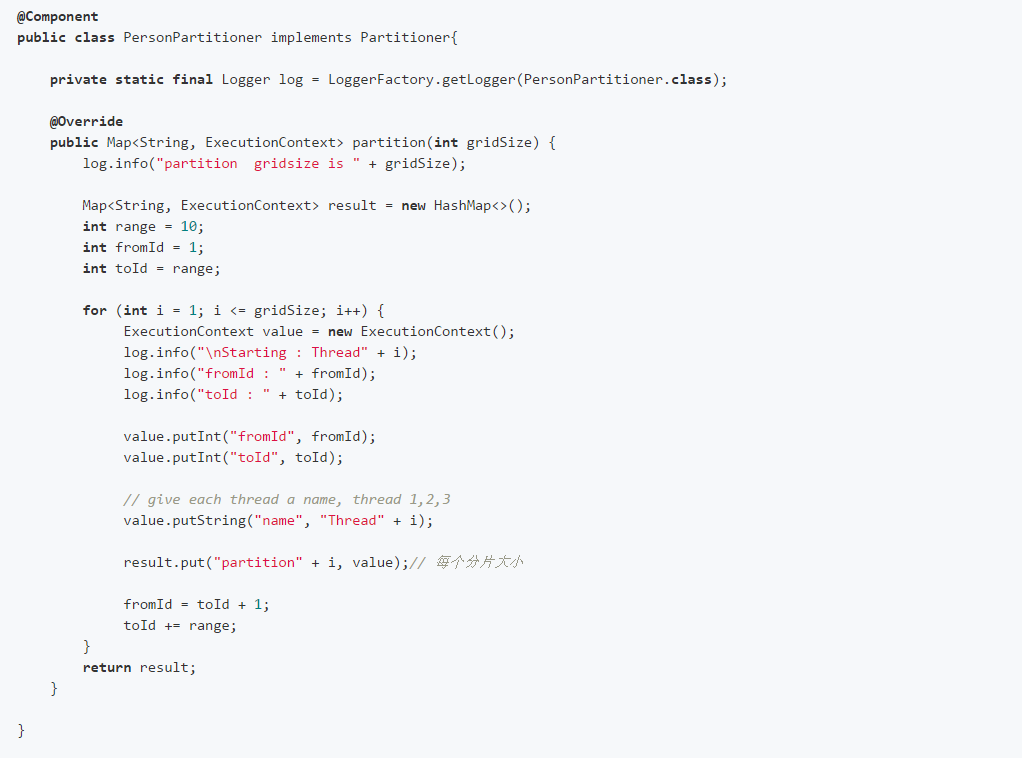
执行分区效果如下:
文件个数对应分区线程数,由参数gridSize决定,本文gridSize=10,对应生成10个文件

以上实现的是单节点多线程处理文件,但只能一定限度上提升批处理的执行效率,对于千万级的数据处理还远远不够,如过能做到多节点多线程才是真正能够更好提升效率的解决方法,这就是接下来要说的远程分区。通过看完中文官方文档,发现真正想实现远程分区的代码实现,过分复杂,并非是通过少量的伪代码就能实现功能,所以本文着重在于提供远程分区的一种实现思路,并不拓展开讲。
想明白远程分区就必须以深刻理解以下几个组件为前提,为什么呢,因为本地分区可以直接使用框架自己带实现,仅仅需要去实现Partitioner接口即可,但是远程分区涉及多节点之间的通信,往往需要自定义实现:
1、远程分区处理器(PartitionHandler),PartitionHandler组件知道远程网格环境的组织结构。 它可以发送step的上下文StepExecution请求给远端Steps,采用某种具体的数据格式,通过自定义实PartitionHandler接口,实现消息的远程分发,PartitionHandler接口可以有各种结构的实现类: 如RMI远程方法调用,EJB远程调用,自定义web服务、JMS、Java Spaces, 共享内存网格(如Terracotta或Coherence)、网格执行结构(如GridGain)。不论是哪一种选型都是为了实现网络通信。
2、分割器,Partitioner,分割器在本地分区也同样会使用,上面有相关代码贴图,它的职责就是为新的step实例生成执行环境(contexts),作为输入参数
3、各个从节点接收到分区的消息,将输入数据绑定到 Steps,并立即执行,将实现多节点处理文件