A brief introduction to Redis cluster mode
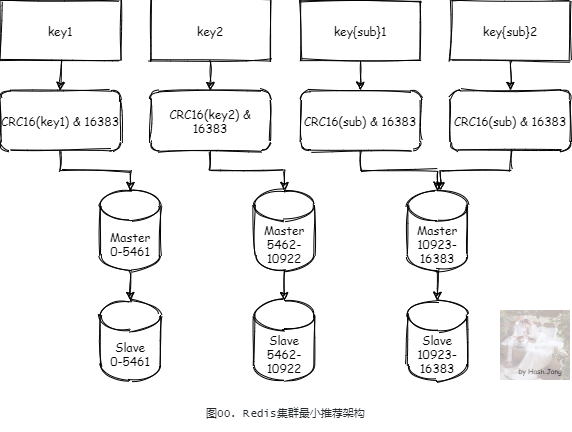
The official recommended minimum best practice solution for a cluster mode is a mode of 6 nodes, 3 masters and 3 slaves, as shown in Figure 00.
Key slot and forwarding mechanism
Redis divides the key space into 16,384 slots, and determines the slot of each key through the following algorithm:
CRC16(key) mod 16384Since 16384 = 2 to the 14th power, taking the remainder of a 2 to the nth power is equivalent to subtracting one from its 2 to the nth power. So the optimization is:
CRC16(key) & 16383When the key contains hash tags (for example key{sub}1), the slot will be calculated with the string specified in the sub tags (that is, sub), so the key{sub}1and key{sub}2will be in the same slot.
The client can send a command to read any slot to any cluster instance. When the slot belongs to the requested instance, it will process it, otherwise it will tell the client where the slot is. For example, if the following command is sent to the second Master:
GET key1
返回: MOVED slot ip:port(第一个Master的) By default, all read and write commands can only be sent to the Master . If you need to use the Slave handle the read request, the client needs to execute readonlycommands.
Master-slave automatic switching mechanism
When a Master fails, if there is a Slave, it will switch to Master.
How to judge that the Master has failed? There is a configuration in the Redis cluster configuration, the cluster-node-timeoutcluster heartbeat timeout period. When the nodes in the cluster establish a connection, the scheduled task clusterCron function (refer to the source code:https://github.com/redis/redis/blob/6.0/src/cluster.c ) will randomly select a node to send a heartbeat every second. If the cluster-node-timeoutheartbeat response is not received within the timeout period ( ), the node will be marked as pfail.
If more than half of the masters in the cluster mark the status of a node as pfail, then the status of this node will become fail.
When the node becomes fail, it will trigger automatic master-slave switch. The process of master-slave switching also involves similar elections:
- When a Master is marked as fail, when the corresponding Slave node executes the scheduled task clusterCron function, the replication offset is selected, that is, the slave with the largest master-slave synchronization progress and the latest data tries to become the master.
- This Slave sets its own currentEpoch += 1 (Under normal circumstances, all currentEpoch in the cluster are the same, and 1 is added for each election, and each currentEpoch can only vote once, to prevent multiple Slaves from being difficult to obtain most votes after they initiate elections at the same time) , And then send a failover request to all Masters, and if the majority of Masters agree, the master-slave switch will be executed.
Cluster unavailability
According to the above description, we can summarize the following unavailable situations
- When accessing a slot where both Master and Slave nodes are down, it will report that the slot cannot be obtained.
- When the number of master nodes in the cluster is less than 3, or when the number of available nodes in the cluster is an even number, the automatic master-slave switching process based on this election mechanism of fail may not work properly. One is the process of marking the failure, and the other It is the process of electing a new master, which may be abnormal.
reference
- Official document: https://redis.io/topics/cluster-spec
- Source code: [ https://github.com/redis/redis
One swipe every day, you can easily upgrade your skills and get various offers:
