This column is based on teacher Yang Xiuzhang’s crawler book "Python Web Data Crawling and Analysis "From Beginner to Proficiency"" as the main line, personal learning and understanding as the main content, written in the form of study notes.
This column is not only a study and sharing of my own, but also hopes to popularize some knowledge about crawlers and provide some trivial crawler ideas.
Column address: Python web data crawling and analysis "From entry to proficiency" For
more crawler examples, please see the column: Python crawler sledgehammer test

Previous article review:
"Python crawler series explanation" 1. Network data crawling overview
"Python crawler series explanation" 2. Python knowledge beginners
"Python crawler series explanation" 3. Regular expression crawler's powerful test
"Python crawler series explanation" 4. BeautifulSoup Technology
"Python crawler series explanation" 5. Use BeautifulSoup to crawl movie information
"Python crawler series explanation" 6. Python database knowledge
table of Contents
1 Knowledge graph and recruitment website
2 Use BeautifulSoup to crawl recruitment information
2.1 Analyze webpage hyperlinks and jump processing
2.2 DOM tree node analysis and web page crawling
4 MySQL data storage recruitment information
Immediately after the previous talk, this article mainly describes a BeautifulSoup crawler based on database storage, which is used to crawl the recruitment information of a certain website on the web, and perform various operations such as adding, deleting, modifying, and checking data. At the same time, it provides powerful technical support for data analysis. Can provide users with the required data more flexibly.
1 Knowledge graph and recruitment website
With the advent of the "big data" and "Internet +" era, a huge amount and variety of information has exploded, and this type of information has strong real-time, poorly structured, and complex relevance. Therefore, how to quickly and accurately find the information required by the user from the massive data becomes particularly difficult. In this context, it is extremely important to help people obtain the information they need from the Internet through automated and intelligent search technology. The Knowledge Graph (KG) came into being, which is a way of understanding users The query intention of the new web search engine that returns satisfactory search results to users.
Currently widely used search engines include Google, Baidu and Sogou. The core search process of such engines is as follows:
- First, the user enters the query term into the search engine;
- Secondly, the search engine retrieves web pages related to the query in the background computing system, and sorts the retrieved web pages through content similarity comparison and link analysis;
- Finally, return the sorted related results in turn.
However, in the process of information retrieval, there is no understanding of query terms and returned web pages, no in-depth analysis of web content and relationship mining of related web pages, so the search accuracy has obvious defects.
In order to improve the accuracy of search engines and understand the true intentions of user queries, the business community has proposed a new generation of search engines or knowledge computing engines, that is, knowledge graphs. The knowledge graph aims to obtain various entities, concepts, attributes, and attribute values describing the real world from websites, online encyclopedias, and knowledge bases from multiple sources, and to build relationships between entities and integrate attributes and attribute values. Store these entities and relationship information in the form of. When users query related information, the knowledge map can provide more accurate search results and truly understand the user's query needs, which is of great significance to the intelligent search for postal services.
In the process of constructing the knowledge graph, a large amount of data needs to be crawled from the Internet, including encyclopedia data, generalized search data on the World Wide Web, and subject-oriented website-oriented search data. For example, when we need to build a knowledge graph related to recruitment and employment, we need to crawl relatively common recruitment websites, such as Zhaopin, Dajie.com, 51job.com and so on.

Next, I will introduce how to crawl the job information published by Ganji.com and store it in the local MySQL database.
2 Use BeautifulSoup to crawl recruitment information
The core steps of Python calling the BeautifulSoup extension library to crawl Ganji website are as follows:
- Analyze the search rules of webpage hyperlinks, and explore the jump method of page search;
- Analyze the DOM tree structure of the webpage, locate and analyze the HTML source code of the required information;
- Use Navicat for MySQL tool to create databases and tables corresponding to Zhaolian recruitment website;
- Python calls BeautifulSoup to crawl the data and operate the MySQL database to store the data locally.
2.1 Analyze webpage hyperlinks and jump processing
The "Job Search" page of the recruitment website contains a series of options to choose from, such as "Category", "Region", "Benefits", "Monthly Salary" and so on.

Select the data on page 1: " http://bj.ganji.com/zpbiaoqian/p6o1/ ",
the data on page 2: " http://bj.ganji.com/zpbiaoqian/p6o2/ ",
...
we The data on page n can be derived : " http://bj.ganji.com/zpbiaoqian/p6on/ ".
From this we find that only the number before the last "/" has changed.
When analyzing URL links, some special symbols are often encountered. The meanings of common special symbols in URL are given below:
| Special symbol | Meaning in URL | URL encoding | ASCII code |
| Space | Space connection parameters in URL, also can be connected with "+" | %20 | 32 |
| # | Represents a bookmark | %23 | 35 |
| % | Specify special characters | %25 | 37 |
| & | Separator between parameters in URL | %26 | 38 |
| ' | Single quotes in URL | %27 | 39 |
| + | "+" in the URL identifies a space | % 2B | 43 |
| - | Minus sign in URL | % 2D | 45 |
| / | Used to separate directories and subdirectories | % 2F | 47 |
| ; | Separator for multiple parameter passing in URL | % 3B | 91 |
| = | The value of the specified parameter in the URL | % 3D | 93 |
| ? | Separate actual hyperlinks and parameters | % 3F | 95 |
The redirection of query multi-page results is a very classic and commonly used technique in website and system development. The redirection page is usually located at the bottom of the webpage.

So how does the web crawler realize the data analysis of multi-page jump? Here are 3 methods for reference:
- By analyzing the hyperlinks of the webpages, we find the rules of the URL parameters corresponding to the page turning, and then use Python to splice the dynamically changing URLs to access and crawl different pages respectively. This method is used in the text. As mentioned earlier, for page turning, only changing the "p" value in the URL can be achieved.
- Some webpages can use Selenium and other automatic positioning technologies to dynamically locate the link or button that the webpage jumps to by analyzing the DOM tree structure of the webpage. For example, call the find_element_by_xpath() function to locate the webpage jump button, and then operate the mouse control to automatically click to jump to the corresponding page.
- If the webpage is accessed using the POST method and the redirection parameters are not specified in the URL, the source code corresponding to the webpage redirection link needs to be analyzed. The result of reviewing element feedback on the jump page is shown in the following figure, and then after crawling the jump link, the corresponding URL and crawling data are accessed through the crawler.

For example, using BeautifulSoup technology to crawl Zhaolian recruitment information is achieved by analyzing the URL of webpage hyperlinks. The core code is as follows:
i = 1
while i <= n:
url = 'http://bj.ganji.com/zpbiaoqian/p6o' + str(i) + '/'
crawl(url)First visit URLs of different page numbers through string splicing, and then call the crawl(url) function to crawl. Among them, the crawl() function is used to crawl the specified content in the url.
2.2 DOM tree node analysis and web page crawling
Next, we need to analyze the specific DOM tree nodes of the Zhaopin recruitment website, and describe in detail the method of using the BeautifulSoup technology to locate and crawl the nodes.

At this time, multiple <div> tags need to be positioned. Call the find_all() function to get the node whose class attribute is "newlist", and then use the for loop to get the table table. The core code is as follows:
for tag in soup.find_all(attrs={"class": "con-list-zcon new-dl"})After locating each piece of recruitment content, crawl the specific content, such as Zhang Zhiwei's name, company name, monthly salary, work location, release date, etc., and assign these information to variables and store them in the local MySQL database.
Among them, the code to obtain job title and salary information is as follows:
zhiwei = tag.find(attrs={"class": "list-ga gj_tongji js-float"}).get_text()
xinxi = tag.find(attrs={"class": "s-butt s-bb1"}).get_text()When defining a web crawler, it is usually necessary to store the hyperlinks of some detail pages locally, such as the hyperlinks in the red box in the figure below.
 In BeautifulSoup technology, the URL corresponding to the hyperlink can be obtained through the get('href') function.
In BeautifulSoup technology, the URL corresponding to the hyperlink can be obtained through the get('href') function.
url_info = tag.find_all(attrs={"class": "list-ga gj_tongji js-float"})
for u in url_info:
chaolianjie = u.get('href')
print(chaolianjie)So far, how to use the BeautifulSoup technology to analyze the information, locate nodes and crawl the required knowledge of the Zhaopin recruitment website has been explained.
3 Navicat for MySQL tool to operate database
Navicat for MySQL is an ideal solution for managing and developing MySQL. It supports a single program and can directly connect to the MySQL database. Navicat for MySQL provides an intuitive and powerful graphical interface for database management, development and maintenance, and provides MySQL novices and professionals with powerful tools for comprehensive database management to facilitate their operation of the database.
3.1 Connect to the database
Click the "Connect" button to pop up the "Connect" dialog box, enter relevant information in the dialog box, such as host name, port, etc. If it is a local database, enter "localhost" in the "Host" text box, and enter "3306" in the "Port" text box. "Username" and "Password" are the corresponding values of the local MySQL database, "Username" The default is root, the default "password" is "123456", and the connection name here is the database "bookmanage" created in the previous article.
After filling in, the stand-alone "connection test", when the local connection is successfully created, click OK, you can see the database that has been created locally.

Specifically, we can see the two tables "books" and "students" created in the previous article. Obviously, it is more convenient than the MySQL introduced in the previous article.

3.2 Create a database
There are two ways to create a database with Navicat for MySQL:
The first is to create a database through SQL statements, and the specific code is as follows:
create database test00The second is to right-click the mouse and select "New Database" in the pop-up shortcut menu:
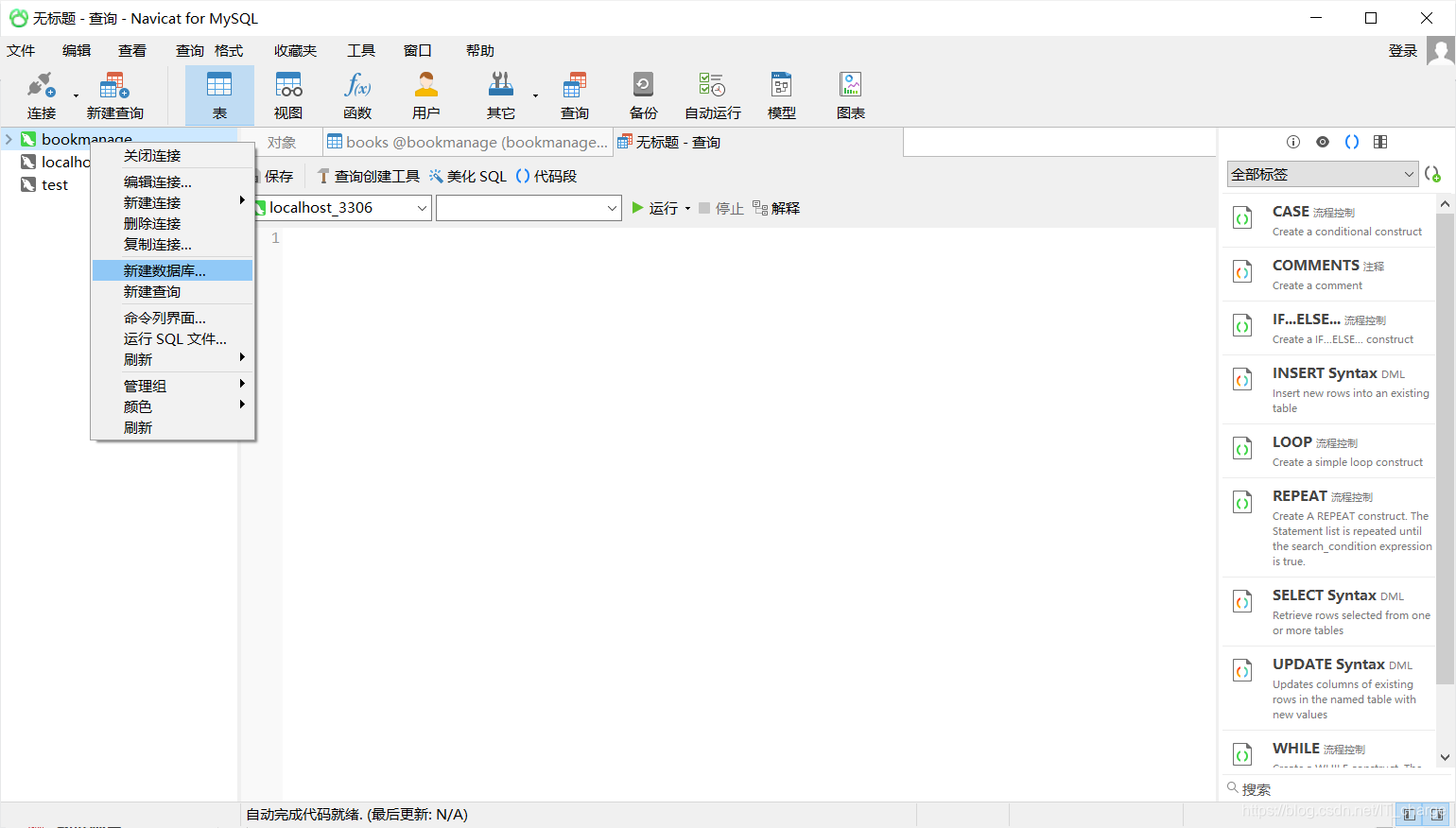
Then enter the database name, character set, and collation in the "New Database" dialog box that pops up. As mentioned in the first method, set the database name to "test00", set the character set to "utf8", and set The collation is set to "utf8_unicode_ci"

Click OK, and the local MySQL database is created successfully.
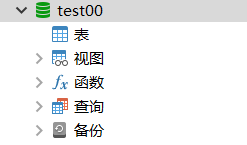
3.3 Create table
There are also two ways to create a table with Navicat for MySQL:
one is to click the New Table button in the taskbar to create, and the other is to right-click the blank space and select "New Table" in the pop-up shortcut menu to create.

Assuming that the newly created table is T_USER_INFO, click the "Add column" button to insert the response field into the table. The inserted fields include: ID (serial number), USERNAME (user name), PWD (password), DW_NAME (unit name); You can set the primary key, non-empty attributes, add comments, etc.

After setting, click the "Save" button and enter "T_USER_INFO" in the "Enter Table Name" text box. At this time, a table in the database is created successfully.

After the table is created, click the Open Table button to view the data contained in the current table. Because the table currently has no data, it is empty.

Of course, right-clicking of the mouse can perform a series of operations on the table, and interested readers can learn more, so I won’t repeat them here.

3.4 Operation
Common commands supported by SQL statements include:
- Database Definition Language (DDL): create, alter, drop
- Database manipulation language (DML): insert, delete, update, select
- Data Control Language (DCL): grant, revoke
- Transaction Control Language (TCL): commit, savepoint, rollback
3.4.1 Insert operation
Click the "Query" button, and then click the "New button" to perform SQL statement operations in the pop-up dialog box, and then click the "Run" button.
INSERT INTO T_USER_INFO
(ID,USERNAME,PWD,DW_NAME)
VALUES('1','zzr','123456','软件学院')

3.4.2 Update operation
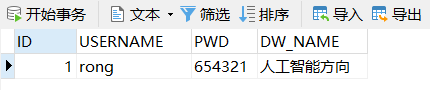
Update the data with the ID value of "1" in the table T_USER_INFO
UPDATE T_USER_INFO SET USERNAME='rong',PWD='654321',DW_NAME='人工智能方向'
WHERE ID='1'
3.4.3 Query operation
Query the information whose USERNAME is "rong" in the table T_USER_INFO, the code is as follows:
SELECT * FROM T_USER_INFO WHERE USERNAME='rong';
3.4.4 Delete operation
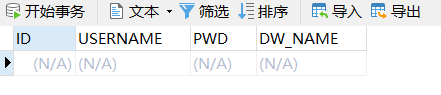
Delete the information whose ID value is "1" in the table T_USER_INFO, the code is as follows:
DELETE FROM T_USER_INFO WHERE ID='1' 
4 MySQL data storage recruitment information
4.1 MySQL operating database
First, you need to create a table. The SQL statement code is as follows:
CREATE TABLE `PAQU_ZHAOPINXINXI`(
`ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '序号',
`zwmc` varchar(100) COLLATE utf8_bin DEFAULT NULL COMMENT '职位名称',
`xzdy` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '薪资待遇',
`gzdd` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '工作地点',
`gzjy` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '工作经验',
`zdxl` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '最低学历',
`zprs` varchar(50) COLLATE utf8_bin DEFAULT NULL COMMENT '招聘人数',
PRIMARY KEY(`ID`)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;

4.2 Code implementation
import re
import requests
import MySQLdb
from bs4 import BeautifulSoup
# 存储数据库
# 参数:'职位名称', '薪资待遇', '工作地点', '工作经验', '最低学历', '招聘人数'等
def DatabaseInfo(zwmc, xzdy, gzdd, gzjy, zdxl, zprs):
try:
conn = MySQLdb.connect(host = 'localhost', user='root', passwd='123456', port=3306, db='test00')
cur = conn.cursor() # 数据库游标
# 设置编码方式
conn.set_character_set('utf8')
cur.execute('SET NAMES utf8;')
cur.execute('SET CHARACTER SET utf8;')
cur.execute('SET character_set_connection=utf8;')
# SQL 语句
sql = '''
insert into paqu_zhaopinxinxi(zwmc, xzdy, gzdd, gzjy, zdxl, zprs)values(%s, %s, %s, %s, %s, %s)
'''
cur.execute(sql, (zwmc, xzdy, gzdd, gzjy, zdxl, zprs))
print('数据库插入成功')
except MySQLdb.Error as e:
print('Mysql Error %d: %s' % (e.args[0], e.args[1]))
finally:
cur.close()
conn.commit()
conn.close()
# 爬虫函数
def crawl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
html = requests.get(url, headers=headers).text
# lxml:html解析库(把HTML代码转化成Python对象)
soup = BeautifulSoup(html, 'lxml')
print('爬取信息如下:')
i = 0
for tag in soup.find_all(attrs={"class": "con-list-zcon new-dl"}):
i = i + 1
zwmc = tag.find(attrs={"class": "list-ga gj_tongji js-float"}).get_text()
zwmc = zwmc.replace('\n', '')
print(zwmc)
# 其他信息
xinxi = tag.find(attrs={"class": "s-butt s-bb1"}).get_text()
print(xinxi)
xzdy = re.findall('薪资待遇:(.*?)元', xinxi)
gzdd = re.findall('工作地点:(.*?)\n', xinxi)
gzjy = re.findall('工作经验:(.*?)\n', xinxi)
zdxl = re.findall('最低学历:(.*?)\n', xinxi)
zprs = re.findall('招聘人数:(.*?)人', xinxi)
gzdd = gzdd[0]
gzjy = gzjy[0]
zdxl = zdxl[0]
# 写入 MySQL 数据库
print('写入数据库操作 ')
DatabaseInfo(zwmc, xzdy, gzdd, gzjy, zdxl, zprs)
else:
print('爬取职位总数:', i)
# 主函数
if __name__ == '__main__':
# 翻页执行 crawl(url) 爬虫
i = 1
while i <= 10:
print('页码:', i)
url = 'http://bj.ganji.com/zpbiaoqian/p6o{}/'.format(i)
crawl(url)
i = i + 1

At this point, a complete example of using BeautifulSoup technology to crawl recruitment website information and store it in the local MySQL database has been finished. Through the database, users can perform various operations such as adding, deleting, modifying and checking data, which is very suitable for mass data crawling and data analysis operations.
5 Summary of this article
The previous articles respectively described the BeautifulSoup technology and the Python operating database. This article runs through all the knowledge points through an example of using the BeautifulSoup technology to crawl recruitment information, and stores the crawled content in the local MySQL database. Through these articles, I hope to popularize some relevant knowledge about crawlers and provide some trivial crawler ideas.
Welcome to leave a message, learn and communicate together~
Thanks for reading