Idempotence and Sequence of Distributed System and Distributed Lock
How to Design the Idempotence of Distributed Service Interface
What is idempotence
How to ensure idempotence for a certain interface in a distributed system? This matter is actually a technical issue of the production environment that you must consider when doing distributed systems. What do you mean?
You see, if you have a service that provides an interface, the service is deployed on 5 machines, and the next interface is the payment interface. Then when other users are operating on the front-end, they don’t know why. In short, an order accidentally initiates two payment requests, and then these two requests are scattered on different machines deployed by the service. Okay, the result is one order. Two deductions? Embarrassed. . .
Or the order system calls the payment system to make the payment, and the result is accidental because the network timed out, and then the order system went through the retry mechanism we saw earlier, and clicked to give you a retry. Okay, the payment system received a payment. Requested twice, and because the load balancing algorithm fell on different machines, it was embarrassing. . .
So you must know this, otherwise the distributed system you build may be easy to bury pits
Network problems are very common. 100 requests are all ok; 10,000 times, maybe 1 time will be retried after timeout; 100,000, 10 times; 1 million, 100 times; if there are 100 requests repeated, you did not handle it, resulting in Orders were deducted twice, 100 orders were deducted wrongly; 100 users complained every day; 3000 users complained a month
We have encountered this in production before. It is to write data to the database. Repeated requests cause our data to be often wrong. If some duplicate data occurs, it will cause some problems.
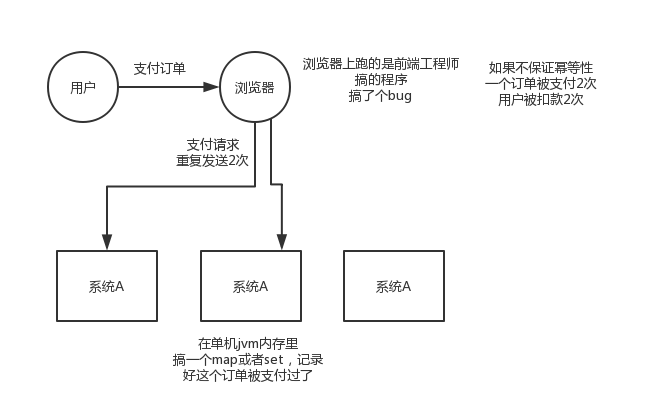
If it is a stand-alone environment, only one map or set needs to be maintained, and each time it is judged whether the order ID has been paid.
This is not a technical problem. There is no universal method. This is based on your experience in how to ensure idempotence in combination with your business.
The so-called idempotence means that an interface initiates the same request multiple times. Your interface must ensure that the result is accurate. For example, no more deductions, no more data can be inserted, and no more statistical values can be added by 1. This is idempotence, and I won't give you academic terms.
Guarantee idempotence
In fact, there are three main points to ensure idempotence:
- For each request, there must be a unique identifier. For example: an order payment request must include the order id. An order id can be paid at most once, right?
- After each request is processed, there must be a record indicating that the request has been processed. For example, a common solution is to record a status in mysql, such as recording a payment flow for this order before payment, and the payment flow is collected.
- Every time a request is received, it needs to perform logical processing to determine whether it has been processed before. For example, if an order has been paid, there is already a payment flow. If this request is sent repeatedly, the payment flow is inserted first, orderId Already exists, the unique key constraint takes effect, and an error message cannot be inserted. Then you don’t have to deduct any more.
- The above is just an example for everyone. In the actual operation process, you have to combine your own business, such as using redis and orderId as the unique key. Only by successfully inserting this payment stream can the actual payment deduction be executed.
The requirement is to pay for an order, you must insert a payment stream, order_id to create a unique key, unique key
So before you pay for an order, insert a payment stream first, and the order_id is already in.
You can write a logo into redis, set order_id payed, the next time you repeat the request, first check the value corresponding to the order_id of redis, if it is paid, it means you have already paid, so don’t pay again.
Then, when you repeat the payment for this order, you write and try to insert a payment stream, and the database reports an error to you, saying that the unique key conflicts, and the entire transaction can be rolled back.
It is also possible to save a processed identity, and different instances of the service can operate redis together.
How to ensure the order of distributed service interface requests?
In fact, the calling sequence of the distributed system interface is also a problem. Generally speaking, the sequence is not guaranteed. But sometimes it may indeed require strict order guarantees. To give you an example, you service A calls service B, insert and then delete. Well, the two requests passed and landed on different machines. Perhaps the insert request was executed slower for some reasons, causing the delete request to be executed first. At this time, because there was no data, there was no effect; as a result, the insert request came over at this time. Now, well, the data is inserted, then it will be embarrassing.
It was supposed to be inserted first -> then deleted. This data should be gone, but now it is deleted first -> then inserted. The data still exists. In the end, you can't figure out what happened. So these are some very common problems in distributed systems
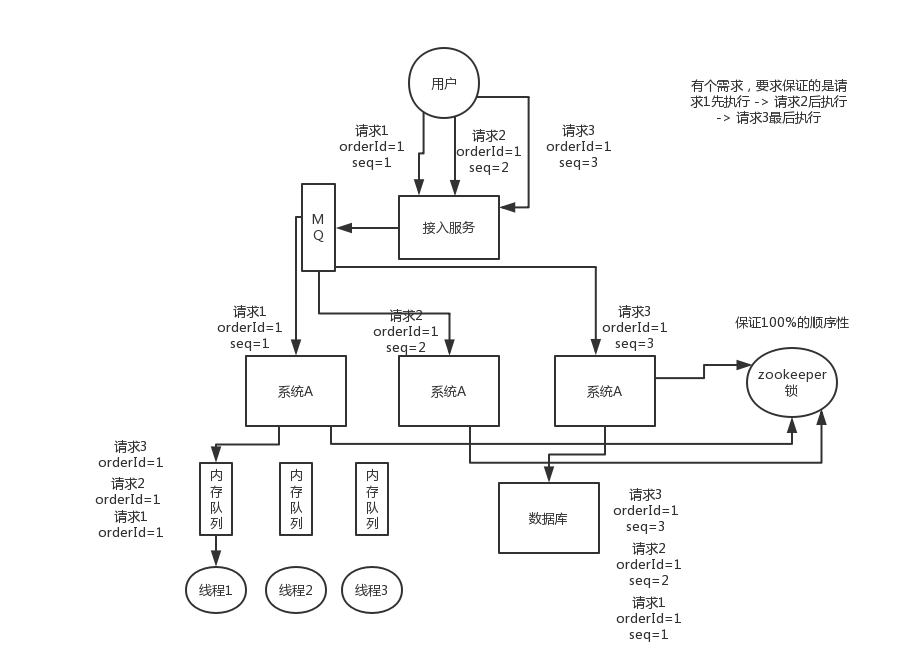
First of all, generally speaking, my personal advice to you is that the system you design best from business logic does not require this order guarantee, because once the order guarantee is introduced, the complexity of the system will increase, and it will This brings about problems such as low efficiency, excessive pressure on hot data, and so on.
Let me give you a solution we have used. To put it simply, first you have to use dubbo's consistent hash load balancing strategy to distribute, for example, requests corresponding to a certain order id to a certain machine, and then on that Because the machine may be executed concurrently by multiple threads, you may have to immediately put the request corresponding to a certain order id into a memory queue and force the queue to ensure their order.
However, there are many follow-up problems caused by this. For example, what if a certain order corresponds to a lot of requests, which causes a certain machine to become a hot spot? To solve these problems, a series of complex technical solutions must be opened up. . . This type of problem has caused us a lot of headaches, so what should I suggest?
It is better to avoid this kind of problem, for example, just now, whether the insert and delete operations of an order can be combined into one operation, that is, a delete, or what.
Use MQ and memory queue to solve
Method 1, and the most friendly way is to use message queues and memory queues to solve the problem. The first thing we need to do is to distribute the requests that need to be sequenced to the same specific machine through the Hash algorithm, and then the machine is putting the requests inside In the memory queue, the thread obtains consumption from the memory queue to ensure the order of threads
However, this method can solve 99% of the order, but there may still be problems with access services, such as changing the request 123 to 231, resulting in inconsistent order in the MQ queue.
Use distributed locks to solve
Distributed locks can guarantee strong consistency, but because of the introduction of this heavyweight synchronization mechanism, the amount of concurrency will be drastically reduced, because it requires frequent lock acquisition and lock release operations.
How to design an RPC framework similar to Dubbo
When encountering such problems, at least start with the principles of similar frameworks that you know, and talk about it by referring to the principles of dubbo. You can design it. For example, don't dubbo have so many layers? And what each layer does, do you probably know? Let's talk about it roughly according to this idea.
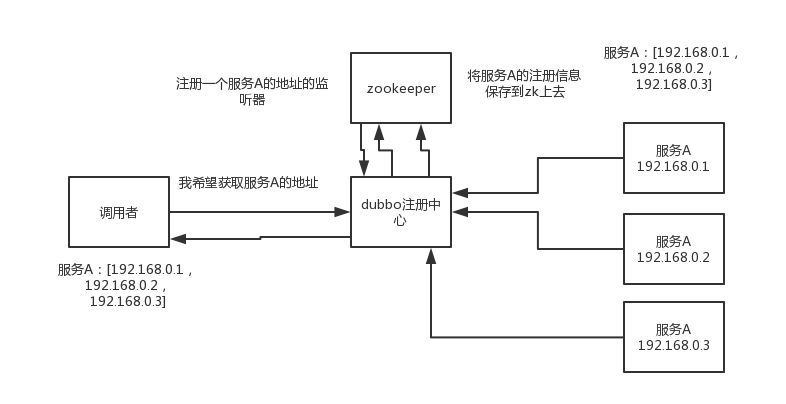
- You have to go to the registration center to register your service. Do you have to have a registration center that keeps information about each service? You can use zookeeper to do it, right?
- Then your consumers need to go to the registration center to get the corresponding service information, right, and each service may exist on multiple machines
- Then it's time for you to initiate a request, how do you initiate it? I'm trapped, right? Of course it is based on a dynamic proxy. You get a dynamic proxy for the interface. This dynamic proxy is a local proxy for the interface, and then the proxy will find the machine address corresponding to the service.
- Then which machine to send the request? Then there must be a load balancing algorithm. For example, the simplest one can be randomly polled, right?
- Then you find a machine and you can send a request to him. How do I send the first question? You can say that you have used netty, nio; the second question is what format data should be sent? You can say hessian serialization protocol is used, or something else, right. Then the request passed. .
- The server side is the same, you need to generate a dynamic proxy for your own service, listen to a certain network port, and then proxy your local service code. When a request is received, the corresponding service code is called, right.
What are the usage scenarios of Zookeeper?
Distributed locks are very commonly used. If you are doing java system development, distributed systems, there may be some scenarios that will be used. The most commonly used distributed lock is zookeeper to make distributed locks.
In fact, to be honest, to ask this question is to see if you understand zk, because zk is a very common basic system in distributed systems. And when you ask, what is the usage scenario of zk? See if you know some basic usage scenarios. But in fact, if zk digs deep, it is natural to ask very deeply.
Distributed coordination
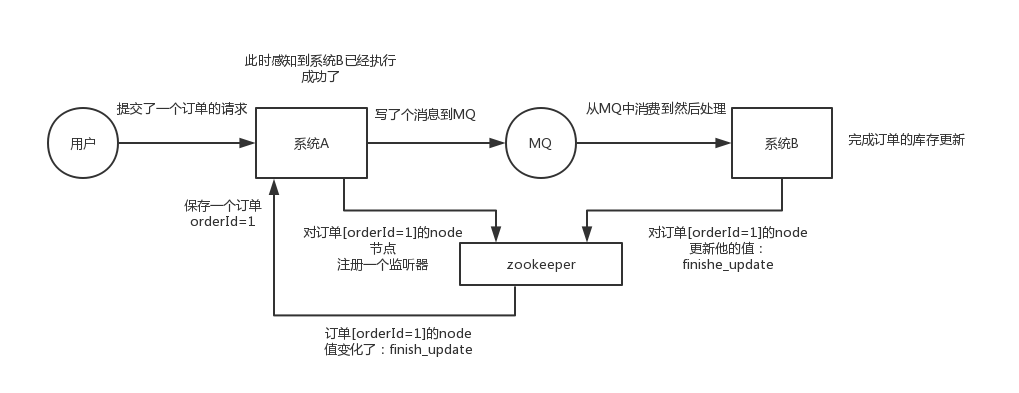
This is actually a very classic usage of zk. Simply put, it's like, your system A sends a request to mq, and the message is processed by B after it is consumed. How does A system know the processing result of B system? With zk, the coordination work between distributed systems can be realized. After system A sends the request, it can register a listener on the value of a certain node on zk. Once system B has processed it, modify the value of that node zk, and A can immediately receive the notification, which is a perfect solution.
Distributed lock
Two consecutive modification operations are issued to a certain data, and the two machines receive the request at the same time, but only one machine can execute the other machine first and then execute it. Then you can use the zk distributed lock at this time. After a machine receives the request, first acquires a distributed lock on zk, that is, you can create a znode and then perform the operation; then another machine also tries to create the znode, It turned out that I couldn't create it because it was created by someone else. . . . You can only wait, wait until the first machine has finished executing it and then execute it yourself.

Metadata/configuration information management
Zk can be used to manage the configuration information of many systems. For example, many distributed systems such as kafka, storm, etc. will use zk to manage some metadata and configuration information. The dubbo registry does not also support zk.
HA high availability
This should be very common. For example, many big data systems such as hadoop, hdfs, yarn, etc., choose to develop HA high availability mechanism based on zk, that is, an important process will usually be the main and backup two, and the main process will immediately be sensed by zk when it hangs. Switch to standby process
Distributed lock
Interview questions
- What are the general ways to implement distributed locks?
- How to design distributed locks using redis?
- Is it okay to use zk to design distributed locks?
- Which of the two implementations of distributed locks is more efficient?
Redis implements distributed locks
Officially called the RedLock algorithm, it is a distributed lock algorithm officially supported by redis.
This distributed lock has 3 important considerations, mutual exclusion (only one client can acquire the lock), no deadlock, fault tolerance (most redis nodes or this lock can be added and released)
The first and most common implementation is to create a key in redis to be locked
SET my:lock random value NX PX 30000, this command is ok, this NX means that the setting will be successful only when the key does not exist, PX 30000 means that the lock will be automatically released after 30 seconds. When someone else creates it, if they find it already exists, they can't lock it.
To release the lock is to delete the key, but generally you can delete it with a lua script, and delete it only if the value is the same:
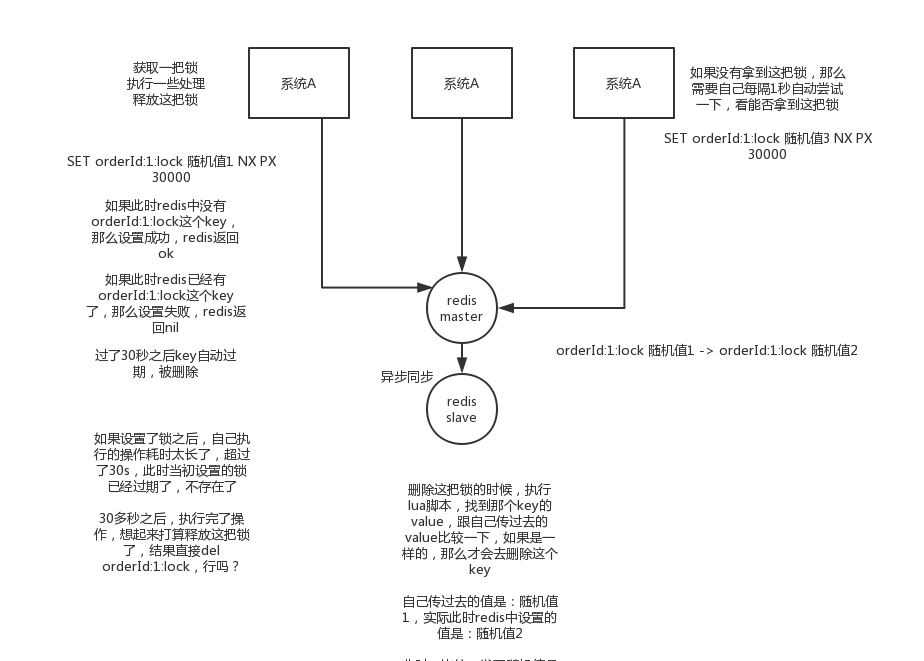
Regarding how redis executes lua scripts, Baidu by yourself
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Why use random values? Because if a client acquires the lock, but it is blocked for a long time before the execution is completed, the lock may have been automatically released at this time. At this time, other clients may have acquired the lock. If you delete the key directly at this time There will be problems, so you have to use a random value plus the above lua script to release the lock.
But this will definitely not work. Because if it is an ordinary redis single instance, it is a single point of failure. Or redis ordinary master-slave, then redis master-slave asynchronous replication, if the master node hangs, the key has not been synchronized to the slave node, at this time the slave node switches to the master node, others will get the lock.
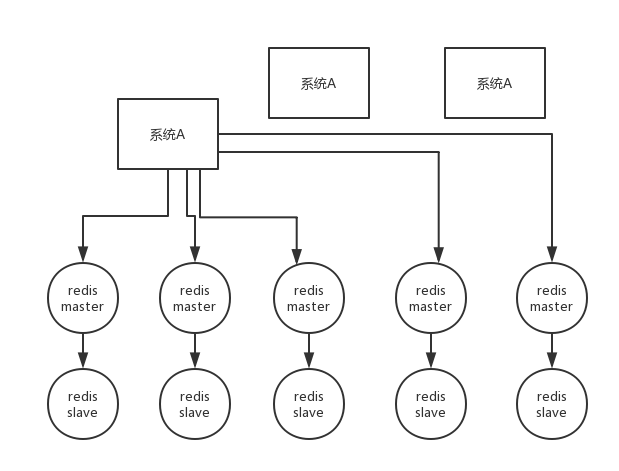
The second question, RedLock algorithm
- This scenario assumes that there is a redis cluster with 5 redis master instances. Then perform the following steps to obtain a lock:
- Get the current timestamp in milliseconds
- Similar to the above, try to create a lock on each master node in turn, the expiration time is relatively short, usually tens of milliseconds
- Try to establish a lock on most nodes, for example, 5 nodes require 3 nodes (n / 2 +1)
- The client calculates the time to establish the lock, if the time to establish the lock is less than the timeout time, even if the establishment is successful
- If the lock establishment fails, then delete the lock in turn
- As long as someone else establishes a distributed lock, you have to keep polling to try to acquire the lock
ZK implements distributed locks
The zk distributed lock, in fact, can be done relatively simple, that is, a node tries to create a temporary znode, and the lock is acquired when the creation is successful; at this time, other clients will fail to create the lock and can only register a listener Listen to this lock. To release the lock is to delete the znode. Once it is released, the client will be notified, and then a waiting client can re-lock it again.
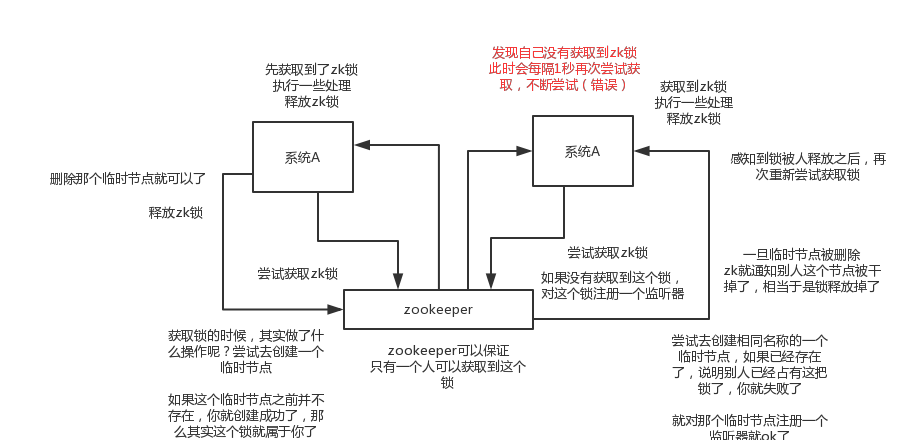
ZK implements distributed locks, that is, it does not need to perform a polling algorithm, but registers a listener, but when someone releases the lock, it will notify the process that needs to acquire the lock.
At the same time, when ZK acquires a lock, it actually creates a temporary node. If the temporary node does not exist before, it is created successfully, which means that the lock belongs to the thread.
At the same time, other threads will try to create a temporary node with the same name. If it already exists, it means that someone else already has the lock, then the creation will fail.
Once the temporary node is deleted, zk informs others that the lock has been released, which is equivalent to the lock being released.
Assuming that the server holding the lock is down at this time, Zookeeper will automatically release the lock.
ZK implements distributed lock code
/**
* ZooKeeperSession
* @author Administrator
*
*/
public class ZooKeeperSession {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private ZooKeeper zookeeper;
private CountDownLatch latch;
public ZooKeeperSession() {
try {
this.zookeeper = new ZooKeeper(
"192.168.31.187:2181,192.168.31.19:2181,192.168.31.227:2181",
50000,
new ZooKeeperWatcher());
try {
connectedSemaphore.await();
} catch(InterruptedException e) {
e.printStackTrace();
}
System.out.println("ZooKeeper session established......");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取分布式锁
* @param productId
*/
public Boolean acquireDistributedLock(Long productId) {
String path = "/product-lock-" + productId;
try {
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
return true;
} catch (Exception e) {
while(true) {
try {
Stat stat = zk.exists(path, true); // 相当于是给node注册一个监听器,去看看这个监听器是否存在
if(stat != null) {
this.latch = new CountDownLatch(1);
this.latch.await(waitTime, TimeUnit.MILLISECONDS);
this.latch = null;
}
zookeeper.create(path, "".getBytes(),
Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
return true;
} catch(Exception e) {
continue;
}
}
// 很不优雅,我呢就是给大家来演示这么一个思路
// 比较通用的,我们公司里我们自己封装的基于zookeeper的分布式锁,我们基于zookeeper的临时顺序节点去实现的,比较优雅的
}
return true;
}
/**
* 释放掉一个分布式锁
* @param productId
*/
public void releaseDistributedLock(Long productId) {
String path = "/product-lock-" + productId;
try {
zookeeper.delete(path, -1);
System.out.println("release the lock for product[id=" + productId + "]......");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 建立zk session的watcher
* @author Administrator
*
*/
private class ZooKeeperWatcher implements Watcher {
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event.getState());
if(KeeperState.SyncConnected == event.getState()) {
connectedSemaphore.countDown();
}
if(this.latch != null) {
this.latch.countDown();
}
}
}
/**
* 封装单例的静态内部类
* @author Administrator
*
*/
private static class Singleton {
private static ZooKeeperSession instance;
static {
instance = new ZooKeeperSession();
}
public static ZooKeeperSession getInstance() {
return instance;
}
}
/**
* 获取单例
* @return
*/
public static ZooKeeperSession getInstance() {
return Singleton.getInstance();
}
/**
* 初始化单例的便捷方法
*/
public static void init() {
getInstance();
}
}
Redis distributed lock and ZK distributed lock
Redis distributed locks, in fact, you need to keep trying to acquire locks by yourself, which consumes performance
Zk distributed lock, can not get the lock, just register a listener, there is no need to actively try to acquire the lock, and the performance overhead is small
Another point is that if the client that redis acquired the lock has a bug or hangs, then the lock can only be released after the timeout period; in the case of zk, because the temporary znode is created, as long as the client hangs, the znode will not be released. , The lock is automatically released at this time
Is redis distributed lock troublesome every time you find it? Traverse the lock, calculate the time and so on. . . Zk's distributed lock semantics are clear and easy to implement
So without analyzing too many things, I will talk about these two points. I personally think that the distributed lock of zk is more reliable than the distributed lock of redis, and the model is simple and easy to use.