
Introduction / Introduction
This article is the theme sharing of this year's QCon java special "Java Coroutine Production Practice in Tencent", and the sharing team is the Tencent Big Data JVM team. This article mainly introduces the background of coroutines, the development of java coroutines, the design and implementation of the official community coroutine Project Loom, as well as the background, design and implementation, performance testing and business practices of Tencent's self-developed coroutine Kona Fiber.
1. The background of coroutine generation
1.1 Threading Model
The most classic programming model is the threading model, which is an abstraction of the CPU at the operating system level. Since the threading model is a synchronous programming model, it is intuitive and easy to understand, so the development efficiency using the threading model is high. However, for IO-intensive programs, since each IO operation needs to block the current thread, a thread switch will occur. Thread switching needs to switch between user mode and kernel mode, and thread switching needs to save the execution context of the current thread. The overhead of a thread switch is on the order of 10 microseconds. Therefore, for IO-intensive programs, a large part of the CPU is used for thread switching, resulting in low CPU utilization.
The second problem with the threading model is that for IO-intensive and high-concurrency programs, if the asynchronous programming model is not used, usually one thread corresponds to one concurrency (because if a thread does database access operations, the thread is blocked, and the thread is blocked. No other tasks can be performed, only another thread can be used). Therefore, for high-concurrency programs, a large number of threads need to be created. In order to be compatible with various programming languages and execution logic, the operating system threads reserve a large stack memory, usually 8M. Due to the large memory occupied by threads, it is difficult for a machine to create too many threads even without considering the CPU utilization (only considering the memory overhead of the thread stack, 10,000 threads require 80G memory), so it is difficult to Without using an asynchronous programming framework, only the threading model supports IO-intensive + high-concurrency programs.
1.2 Asynchronous Model
The asynchronous programming model is an abstraction of a programming language framework, which can make up for the shortcomings of the threading model for IO-intensive + high-concurrency program support. It reuses a thread. For example, before the thread is blocked by an io operation, it calls another logical unit through a callback function to complete an operation similar to thread switching; the execution efficiency of the asynchronous model is very high, because compared with thread switching, it directly A callback function is called; but its development threshold is high, and the programmer needs to understand where the io operation may occur, where the callback function needs to be called, and how to regularly check whether the io operation is completed; in addition, since the call stack of the thread consists of some logic It is composed of unrelated modules, so once a problem such as a crash occurs, the call stack is difficult to understand and the maintenance cost is also high.
1.3 Coroutines
Figure 1.1 shows a comparison of the production efficiency and execution efficiency of the threading model and the asynchronous model. It can be seen that the production efficiency of the threading model is the highest, while its execution efficiency for IO-intensive + high concurrent programs is poor. The asynchronous model is just the opposite, it is less productive, but if implemented perfectly, it is the most efficient.
The emergence of coroutines is to balance the production efficiency and execution efficiency of the threading model and the asynchronous model; first, coroutines allow programmers to write synchronous code according to the threading model, and at the same time, reduce the overhead of thread switching as much as possible.
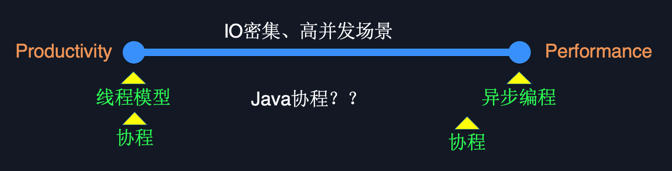
Figure 1.1
2. The development history of Java coroutines
The background of coroutine generation is analyzed above, so what is the status quo of Java coroutines?
First of all, due to the rich asynchronous framework of Java ecosystem, the urgency of coroutines is alleviated, and users can use asynchronous frameworks to solve IO-intensive + high-concurrency programs.
As shown in Figure 2.1, the development process of Java coroutines is listed.

Figure 2.1
2.1 JKU
The first Java coroutine was a paper published by JKU + a patch provided. JKU's coroutine is a stack-based coroutine, that is, each coroutine has its own independent call stack. Unlike operating system threads, since JKU's coroutines only need to consider the execution of java code, according to the characteristics of java code execution, usually only a small stack is needed to meet the needs, usually JKU's coroutines only need no more than 256K stack.
2.2 Quasar/Kotlin
Quasar and Kotlin are the solutions that appeared later. Neither of them needs to modify the java virtual machine, but only the upper-level java code. They are all stackless coroutines. The so-called stackless coroutines mean that the coroutines do not need to save the call stack when they are in the suspend state. So if the call stack is not saved after the coroutine is switched out, how to read the call relationship when the execution is resumed next time? When Quasar and Kotlin switch, they will backtrack the call stack of the current coroutine, and then generate a state machine based on this call stack. When the next execution is resumed, the execution state will be restored according to this state machine; stackless coroutines usually cannot be switched at any point. , can only be switched in the marked function, because only the marked function can generate the corresponding state machine, Quasar needs to add a @Suspendable annotation to mark the function that can be switched, and Kotlin needs to add the suspend keyword mark when the function is defined. toggle function.
2.3 Project Loom
Project Loom is the official coroutine implementation launched by the Openjdk community. It has been more than 3.5 years since the project was established. It currently contains 27 committers, more than 180 authors, and 3200+ commits.
Figure 2.1 lists some important time points for Loom. Loom was established at the end of 2017 and officially launched in early 2018. In July 2019, it released the first EA (Early Access) Build, and its implementation was still a Fiber class at this time. In October 2019, a major change occurred in its interface, the Fiber class was removed, and the VirtualThread class was added as a subclass of the Thread class, compatible with all Thread operations. At this time, its basic idea is relatively clear, that is, coroutine is a subclass of thread, which supports all operations of thread, and users can use coroutine completely in the way of thread.
As the official implementation of Openjdk, Loom's goal is to provide a system solution for Java coroutines, compatible with existing Java specifications, JVM features (such as ZGC, jvmti, jfr, etc.), and the ultimate goal is to be fully compatible with the entire Java ecosystem. Full compatibility with the Java ecosystem is both Loom's advantage and its challenge. Because Java has been developed for more than 20 years, Loom needs to add a new concept of coroutine at the bottom layer, and there are many things that need to be adapted, such as a huge and complex standard class library, and a large number of JVM features. So, as of now, Loom still has a lot of things to do, and it has not yet reached a real usable state. The rightmost part of Figure 2.1 is one of our speculations. When we guess that jdk18 or jdk19, Loom may be able to add The last Experimental flag, available to users.
3. Loom's implementation architecture
Figure 3.1 lists some of the new concepts introduced by Loom, the most important of which is the Virtual Thread, or coroutine. Loom's official statement is: "Virtual threads are just threads that are scheduled by the Java virtual machine rather than the operating system". From the user's point of view, coroutines can be understood as threads and used in the way of threads, which is also the most important design of Loom.

Figure 3.1
In addition to Virtual Thread, Loom also adds the concepts of Scope Variable and Structured Concurrency, which will be introduced later.
3.1 The basic principle of Loom
Figure 3.2 shows the life cycle of a coroutine. Initially, execute the VirtualThread.start() method to create a coroutine and wait to be scheduled; when the coroutine is scheduled for execution, it starts to execute the business code specified by the user, and may access the database/access network during the execution of the code. The IO operation will eventually call to an underlying Park operation. Park can be understood as the coroutine giving up execution permission and cannot be scheduled for execution currently. Unpark will be called after the IO ends, and the coroutine can be scheduled for execution after Unpark. During the Park operation, a freeze operation needs to be performed. This operation mainly saves the execution state of the current coroutine, that is, the call stack. When the coroutine Unpark is scheduled, it will perform a thaw operation, which is a symmetric operation of freeze, mainly to restore the call stack saved by freeze to the execution thread.
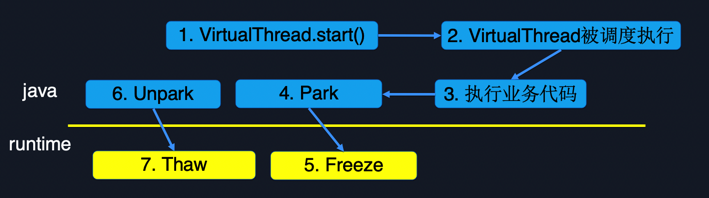
Figure 3.2
Figure 3.3 shows exactly what freeze and thaw accomplish. First look at the freeze operation. The upper part of the call stack from ForkJoinWorkerThread.run to Continuation.enterSpecial is the call in the class library. Starting from A is the user's business code. Suppose the user calls function A, function A calls function B, function B calls function C, and then function C has a database access operation, causing the coroutine to give up the execution permission ( performed a yield operation), and then call to freeze to save the execution state (call stack) of the current coroutine; at this time, a stack walk action will be generated first, and Loom will traverse up from the bottom of the current call stack, and keep traversing until Continuation.enterSpecial. Save all the oops in the traversed stack in a refStack, so as to ensure that the stack of the coroutine will not be used as the root during GC.
Usually, the thread's stack will be treated as root by GC, and stop-the-world is usually required when dealing with root. If the stack of the coroutine is the same as the stack of the thread, it is also treated as the root, then because the coroutine It can support millions or even tens of millions, which will lead to a longer stop-the-world time. Therefore, the design of stack walk and refStack (copying the contents of the coroutine stack into a refStack) can process the stack of coroutines in the concurrent phase, and will not affect the GC pause time due to the increase in the number of coroutines.
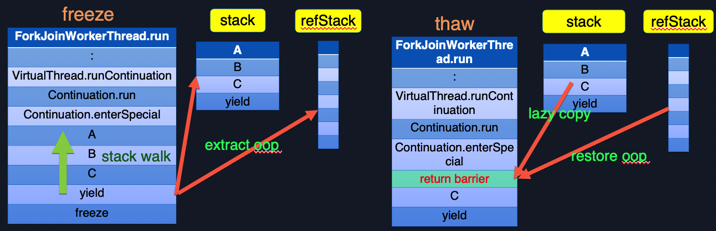
Figure 3.3
On the other hand, Loom will copy the current execution stack of the coroutine to the java heap every time it freezes, that is, A, B, C and yield in this example are copied separately, which can ensure the stack of the coroutine. Memory is really used on demand.
When the coroutine is Unparked and scheduled, the coroutine performs the thaw operation. thaw mainly restores the coroutine stack previously saved in the java heap to the execution stack. Loom introduces the optimization of lazy copy here. The so-called lazy copy means that Loom finds that most programs will generate another io after the io operation through a lot of profiling. Specific to the current example, after function C triggers an io operation, it is likely to generate an io operation instead of returning to function B after execution, and then function B also returns to function A after execution. In this case, every time thaw, there is no need to copy all the call stacks back, but only need to copy a part, and then add a return barrier at the end of the copied call stack, if the function does return to the return barrier, you can pass The return barrier triggers the action of continuing to copy the call stack; in this way, every time you freeze and thaw, only a small part of the content needs to be copied, which greatly improves the switching performance.
In the interval between freeze and thaw, it is possible that GC has been triggered and the oop is relocated. Therefore, when thawing, you need to perform a restore oop action to ensure that no memory access exception occurs.
3.2 Use of VirtualThread
-
scheduler:
A coroutine can be understood as a user-mode thread. When executing in user-mode, since it cannot directly access the CPU, only threads can be used to replace the CPU. Therefore, the coroutine needs a user-mode scheduler, the scheduler contains physical threads, and the coroutine is executed on the physical thread by the scheduler. If the user does not specify a scheduler, the default scheduler is ForkJoinPool, and Loom has done a lot of optimizations for coroutine scheduling for ForkJoinPool.
-
Create VirtualThread directly:
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Hello"));
thread.join()Compared with creating a Thread, you only need to add a function call ofVirtual(), and what is created is a coroutine.
If users want to write a more efficient scheduler for their own business model, they can specify the scheduler by calling the scheduler() function. The code is as follows:
Thread thread = Thread.ofVirtual().scheduler(CUSTOM_SCHEDULER).start(() -> System.out.println("Hello"));
thread.join()- Create a coroutine pool
In addition to using coroutines directly, you can also use coroutines by creating a coroutine pool, such as creating a coroutine pool containing 10,000 coroutines and submitting tasks to the coroutine pool for execution. The corresponding code is as follows:
ThreadFactory factory
if (UseFiber == false) {
factory = Thread.ofPlatform().factory();
} else {
factory = Thread.ofVirtual().factory();
}
ExecutorService e = Executors.newFixedThreadPool(ThreadCount, factory);When creating a ThreadPool, if the factory passed in is ofPlatform(), it corresponds to the thread pool, and if it is ofVirtual(), it corresponds to the coroutine pool.
3.3 VirtualThread Pin
The state of Pin refers to the fact that VirtualThread cannot give up the Carrier Thread (the physical thread mounted when the coroutine is executed) when it freezes. There are two main situations that lead to a Pin:
-
The call stack of VirtualThread contains the JNI frame. Because the implementation of the JNI call is C++ code, there are many things that can be done. For example, it can save the Thread ID of the current Carrier Thread. If it is switched out at this time, then the next time it is executed, if another Carrier Thread executes this coroutine, A logical error will be generated (the ID of the Carrier Thread is inconsistent);
-
VirtualThread holds synchronized locks. This is a limitation brought by the implementation of early java locks, because the owner of java's synchronized lock is the current Carrier Thread. If a coroutine holds a lock, but the owner of the lock is considered to be the current Carrier Thread, then if the This Carrier Thread goes down to execute another coroutine, possibly another coroutine is also considered to have a lock, which may lead to confusion in the semantics of synchronization and various errors.
The occasional Pin is not a serious problem, as long as there is always a physical thread in the scheduler responsible for executing the coroutine. If all physical threads in the scheduler are pinned, it may have a greater impact on throughput. Loom is optimized for the default scheduler ForkJoinPool. If all physical threads are found to be pinned, some additional physical threads will be created to ensure that the execution of the coroutine is not greatly affected. If the user wants to completely eliminate the Pin, he can locate the call stack that generates the Pin through the -Djdk.tracePinnedThreads option as shown in Figure 3.4.

Figure 3.4
3.4 Structured Concurrency
The original intention of structured concurrency is to facilitate the management of the life cycle of coroutines. The basic idea of structured concurrency is that when calling a method A, it usually does not care whether method A is executed step by step by a coroutine, or whether method A is divided into 100 subtasks and executed simultaneously by 100 coroutines. The following code is a small example of using structured concurrency:
ThreadFactory factory = Thread.ofVirtual().factory();
try (ExecutorService executor = Executors.newThreadExecutor(factory)) {
executor.submit(task1);
executor.submit(task2);
}The currently executing coroutine will wait at the end of the try code segment until the execution of the code segment corresponding to the try ends, as if the contents of the try code segment are executed step by step by the current coroutine. Structured concurrency is essentially a syntactic sugar that facilitates dividing a large task into multiple small tasks, which are executed simultaneously by multiple coroutines. With structured concurrency, structured interrupts and structured exception handling come naturally. Structured interrupt refers to the timeout management of the try code segment. For example, the user wants task1 and task2 in the try to be completed within 30 seconds. If it is not completed within 30 seconds, an interrupt is generated to end the execution. Structured exception handling means that the content in try is divided into two subtasks. If the subtask generates an exception, for exception handling, it can be done in the same way as a coroutine sequence execution.
3.5 Scope Variable
Scope Variable is a rethinking of the original ThreadLocal after the Loom community added coroutines. Scope Variable can be understood as a lightweight, structured Thread Local. Since Thread Local is globally valid, unstructured data, once it is modified, the previous value will be overwritten. Scope Variable is a structured Thread Local. Its scope is limited to one Code Blob. The following code is a test case of Scope Variable. According to the assert information, it can be seen that Scope Variable will automatically fail if it is outside the Code Blob. .
public void testRunWithBinding6() {
ScopeLocal<String> name = ScopeLocal.inheritableForType(String.class);
ScopeLocal.where(name, "fred", () -> {
assertTrue(name.isBound());
assertTrue("fred".equals(name.get()));
ScopeLocal.where(name, "joe", () -> {
assertTrue(name.isBound());
assertTrue("joe".equals(name.get()));
ensureInherited(name);
});
assertTrue(name.isBound());
assertTrue("fred".equals(name.get()));
ensureInherited(name);
});
}Another benefit of Scope Variable is that it can be neatly combined with structured concurrency. Structured concurrency usually divides a large task into multiple subtasks. If the number of subtasks is very large, for example, a large task is divided into 1000 subtasks, then if Inherit Thread Local is used to copy the Thread Local of the parent coroutine to On the sub-coroutine, since the Thread Local is mutable, the sub-coroutine can only copy the Thread Local of the parent coroutine. In the case of very many sub-coroutines, this copying is expensive. In order to deal with this situation, Scope Variable only adds a reference to the parent coroutine on the child coroutine without additional copying overhead.
4. Why do you need Kona Fiber?
From the previous analysis, it can be seen that the design of Loom is very complete, and it has fully considered various situations. Users only need to wait for Loom to mature and use Loom. So, why does Tencent need to develop its own coroutine Kona Fiber?
Through communication with a large number of businesses, we have analyzed the three main needs of the current business for coroutines:
-
Available on JDK8/JDK11: At present, a large number of businesses are still developed based on JDK8/JDK11, and Loom, as a cutting-edge feature of the Openjdk community, is developed based on the cutting-edge version of the community, making many businesses still using the old version of JDK unusable;
-
Evolvability of code: users hope that the coroutine code modified based on JDK8/JDK11 can switch to the official coroutine Loom of the community without modifying the code when upgrading to the latest version of the community in the future;
-
Switching performance requirements: The current implementation of Loom, due to stack walk and stack copy operations, leads to a certain room for improvement in switching efficiency. Users hope to have better switching efficiency.
Based on these three requirements, we designed and implemented Kona Fiber.
5. Implementation of Kona Fiber
5.1 Similarities and differences between Kona Fiber and Loom
Figure 5.1 shows the commonalities and differences between Kona Fiber and Loom. The yellow part in the middle is supported by both Kona Fiber and Loom, and the blue part on both sides is the difference between Kona Fiber and Loom.
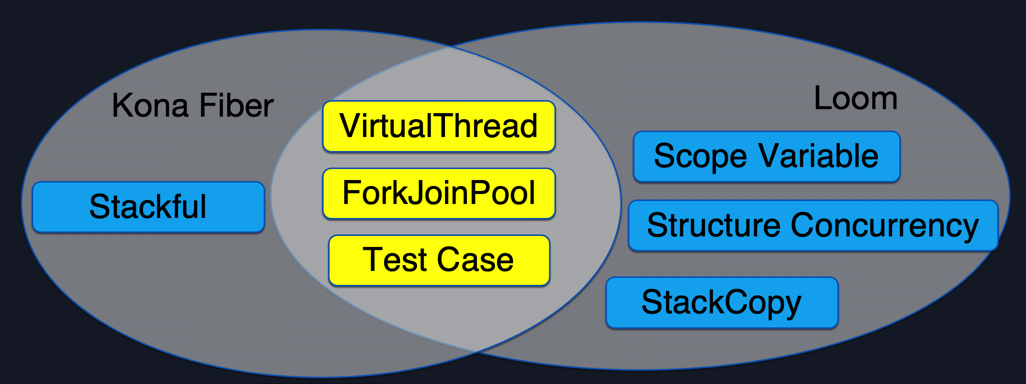
Figure 5.1
First look at the common parts:
-
The most important design of Loom is VirtualThread. KonaFiber supports all interfaces of Virtual Thread. Users can use Loom and Kona Fiber with the same set of interfaces.
-
Loom has made many optimizations for ForkJoinPool, including the aforementioned automatic expansion of Carrier Thread, and Kona Fiber has also ported and adapted this part of the optimization.
-
For Test Case, due to the consistency between Kona Fiber's interface and Loom's interface, ideally, Loom's Test Case can be run directly without any modification. Of course, when actually running Loom's Test Case, a few modifications are still required, mainly due to major version differences. Because Loom is based on the latest version (jdk18) and Kona Fiber is based on jdk8, if Loom's Test Case contains features that are not supported by jdk8, for example, jdk8 does not support variable definition of var, then a small amount of adaptation is still required. Currently, most of Loom's Test Cases have been ported to Kona Fiber, and the corresponding file directory (relative to the jdk root directory) is jdk/test/java/lang/VirtualThread/loom.
For the difference, the first is performance. Since Kona Fiber is a stackful solution, it will be better than Loom in switching performance, and it will also have more memory overhead than Loom. The detailed data of this part will be introduced in the next chapter. Secondly, since Loom introduces some new concepts, although these concepts can allow programmers to use coroutines better, it will take some time for these concepts to mature and be widely accepted by programmers. In the future, if users have common requirements for Scope Variable and Structure Concurrency, Kona Fiber will also consider introducing these concepts. At present, it is still aimed at out-of-the-box use, and these new features are not supported for the time being.
5.2 Implementation Architecture of Kona Fiber
Figure 5.2 shows the lifecycle of a Kona Fiber coroutine.
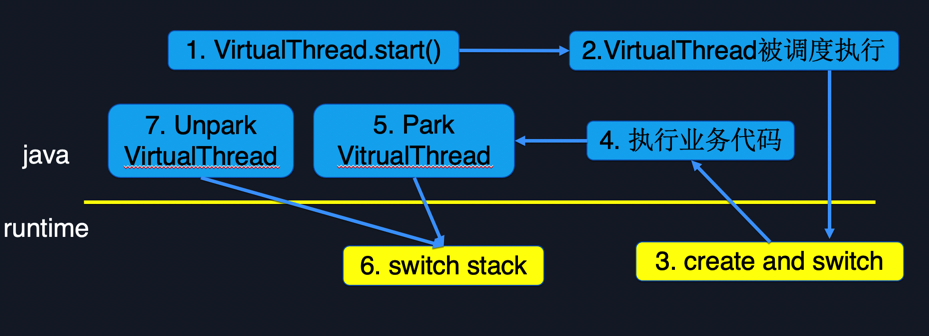
Figure 5.2
The first and second steps are the same as Loom, that is, the coroutine is created and the coroutine is scheduled to be executed. When the coroutine is actually scheduled for execution, the data structure of the coroutine and the stack of the coroutine will be created at runtime. After the creation is successful, return to the java layer to execute the user code. Next, if an IO operation (such as database access) is encountered in the user code, the coroutine will be Parked, so it will enter the runtime. At this time, a stack switch process will be executed in the runtime to switch to another coroutine execution. When the IO ends (for example, the database access is completed), the coroutine will be awakened to continue execution.
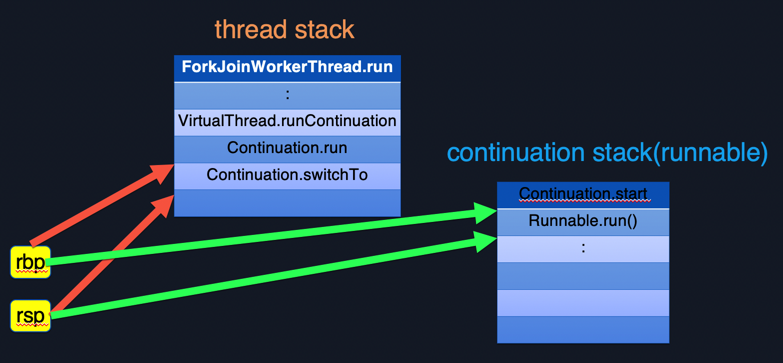
Figure 5.3
As shown in Figure 5.3, the specific implementation of Kona Fiber in stack switch is shown. Coroutines can be understood as user-mode threads, and because each coroutine of Kona Fiber has an independent stack, coroutine switching essentially only needs to switch the rsp and rbp pointers. Because the switching overhead of Kona Fiber is smaller than that of Loom's stack walk and stack copy, it will theoretically have a better performance. Detailed data will follow to compare Kona Fiber and Loom.
6. Kona Fiber Performance Data
Figure 6.1 shows the switching performance data of Kona Fiber, Loom and JKU. The horizontal axis represents the number of coroutines, and the vertical axis represents the number of switches per second.
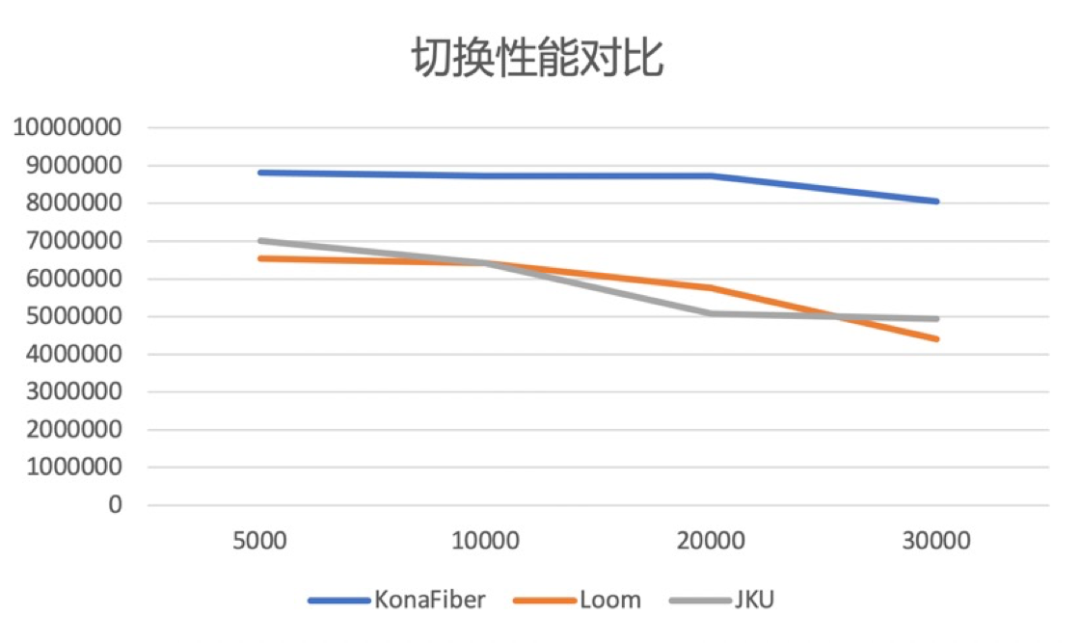
Figure 6.1
It can be seen that the performance of Kona Fiber is better than that of Loom, and when the number of coroutines is large, the performance of JKU is also better than that of Loom. As mentioned above, since Loom needs to do stack copy and stack walk when switching, the switching performance will be worse.
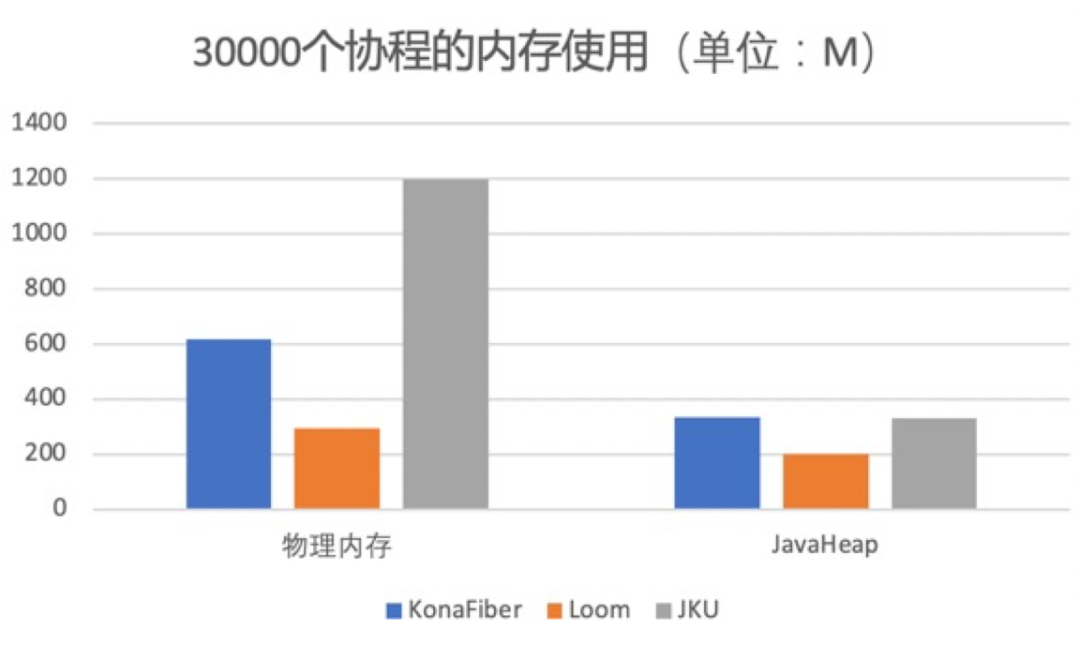
Figure 6.2
Figure 6.2 shows the memory overhead of Kona Fiber, Loom and JKU when creating 30,000 coroutines. Whether it is the physical memory directly used by the runtime or the memory usage of JavaHeap, Loom is the best (occupying the least memory). Of course, this It also benefits from the implementation of Loom's stack copy, which can achieve real on-demand use of memory. Since Kona Fiber is compatible with the concept of Loom Pin, it removes many unnecessary data structures compared to JKU, and is better than JKU in memory usage. In terms of total memory usage, although Kona Fiber occupies more memory than Loom, 30,000 coroutines occupy less than 1G of memory (the memory occupied by runtime plus the memory occupied by Java Heap), which is acceptable for most businesses .
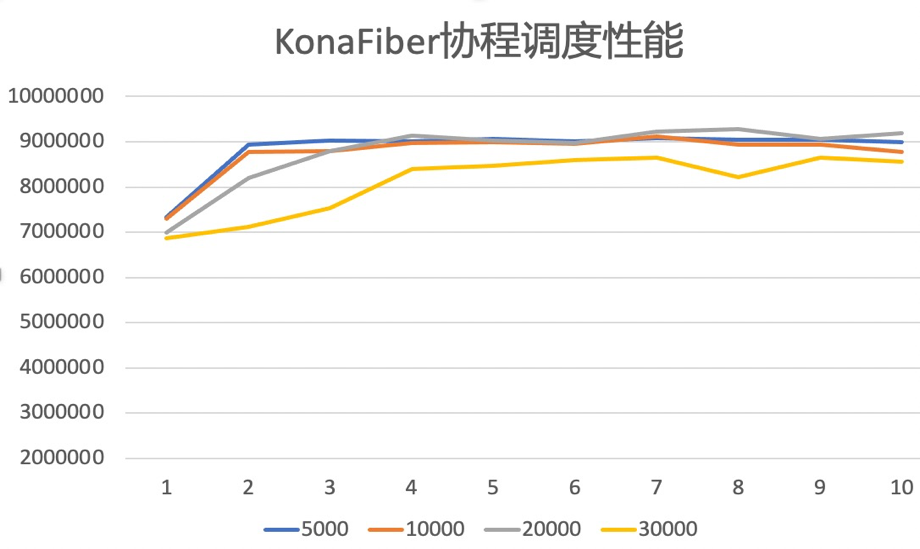
Figure 6.3
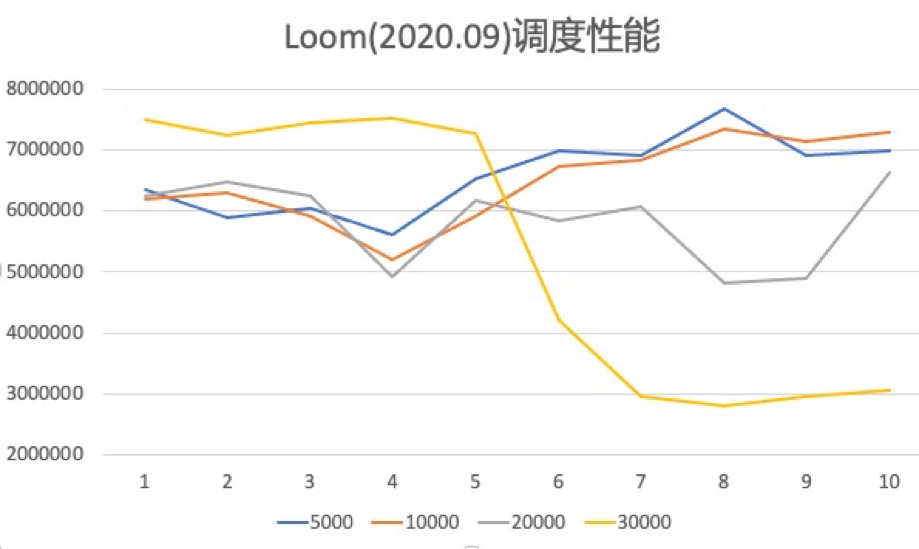
Figure 6.4
Figure 6.3 and Figure 6.4 show the scheduling performance of Kona Fiber and Loom respectively when using the default scheduler ForkJoinPool. The horizontal axis represents the number of carrier threads in the scheduler, the vertical axis represents the number of times the scheduler completes switching operations per second, and the lines of different colors represent different numbers of coroutines. It can be seen that Loom has obvious performance jitter when the number of coroutines is large. Kona Fiber's performance is stable under different numbers of coroutines. This difference may be related to Loom's stack walk and stack copy when switching.
Note:
1. All performance data about Loom is based on Loom code as of September 2020.
2. All performance test cases can be obtained in the open source code, and the corresponding directory (relative to the root directory of jdk) is demo/fiber
7. Kona Fiber's business landing
7.1 Business Coroutine Transformation
If a business wants to switch from thread to coroutine, the following three steps are usually required:
1. Change thread creation to coroutine creation; change thread pool to coroutine pool. The first step is very simple, just replace the use of threads with the use of coroutines (replace according to Section 3.2 "Virtual Thread Use")
2. Replace some synchronous interfaces with asynchronous frameworks. Currently Kona Fiber still has some interfaces that are not supported, such as Socket and JDBC-related interfaces. Using these interfaces will cause the coroutine to not switch normally (Blocking lives in native code or Pin), and the coroutine will degenerate into a thread, so the advantages of the coroutine will not exist. At present, Kona Fiber does not support some native interfaces of the network and database. Fortunately, the corresponding asynchronous framework can be found for general network and database operations, such as Netty for network operations and asynchronous redis for databases. Figure 7.1 takes the replacement of Netty as an example to introduce how to use the asynchronous framework to effectively use coroutines. First, create a CompletableFuture, then submit the task to Netty, and then the current coroutine calls Future.get() to wait for the completion of Netty execution. Call Future.complete() in the callback function of Netty's execution completion, so that the coroutine can resume execution.
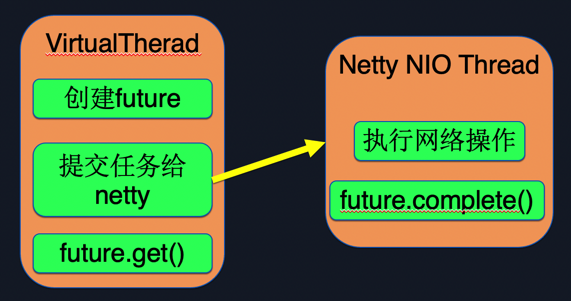
Figure 7.1
3. Coroutine performance optimization: Pin solution. Section 3.3 introduced Pins. Although Pins will not cause the entire system to deadlock, frequent Pins will still significantly reduce service throughput. For the solution of Pin, there are mainly two aspects, that is, two reasons for Pin generation: synchronized lock and native frame. The first step is to open -Djdk.tracePinnedThreads in the debugging phase, so that you can find all call stacks that cause Pins. If the Pin is caused by the business code using the synchronized lock, then you only need to replace the synchronized lock with ReentrantLock; if the Pin is caused by the inclusion of the native frame or the third-party code includes the synchronized lock, you can only submit the task to a The method of independent thread pool is solved, which can ensure that the execution of the coroutine is not affected.
7.2 Qidian Open Platform - Unified Push Service
Qidian open platform - unified push service is Tencent's business, and there is a natural need for high concurrency. Initially, the business side tried to use WebFlux responsive programming, but because the business side had many third-party outsourcers, and the development and maintenance of WebFlux was difficult, the business side gave up using WebFlux. Later, after learning about the Kona Fiber developed by Tencent, the business side decided to try to switch Kona Fiber.
The adaptation of the business side to Kona Fiber is mainly by replacing bio with nio+Future, replacing all blocking operations with nio, and executing Future.complete() to wake up the coroutine when the blocking operation is completed; the work of replacing the coroutine as fed back by the business side The amount is: three days, 200+ lines of code adaptation and testing work. In the end, compared with the Servlet threading scheme, the overall throughput of the system is increased by 60%.
The following code is the code fragment modified by the business side, which respectively means creating a coroutine pool and adding an annotation to let the function run on the coroutine pool:
@Bean(name = "asyncExecutor")
public Executor asyncExecutor() {
ThreadFactory threadFactory = Thread.ofVirtual().factory();
return Executors.newFixedThreadPool(fiberCount, threadFactory);
}
@Async("asyncExecutor")
public CompletableFuture<ResponseEntity<ResponseDTO>> direct() {
···
}7.3 SLG game background service
SLG (Simulation Game) games are mainly strategy games, which do not require very high real-time performance like some battle games. Strategy games are characterized by complex logic, and game business usually requires high concurrency and high performance. The business side customized a single concurrent coroutine scheduler based on Kona Fiber.
As shown in Figure 7.2, multiple coroutines only run on one playerService Thread. Since the Carrier Thread has only one thread, only one coroutine running on the playerService Thread can be executed at the same time; this can save a lot of synchronization operations and improve the Developer programming efficiency. After replacing Kona Fiber, the overall throughput of the system is also increased by 35% compared to the thread solution.
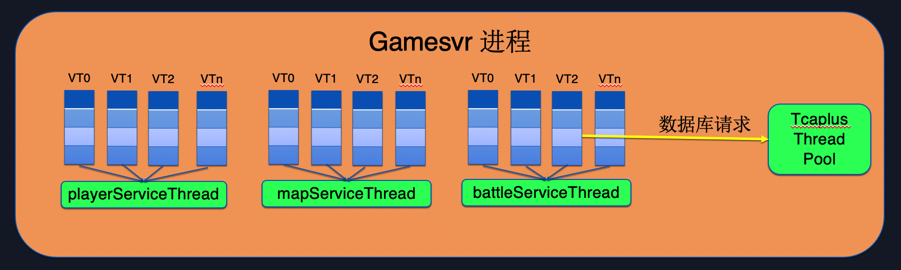
Figure 7.2
The battleService Thread on the right has a request to access the database. The business side uses the Tcaplus database developed by Tencent. In order to prevent the coroutine from degenerating into a thread, the business side submits database operations to an independent thread pool for execution.
7.4 trpc-java
trpc is a high-performance RPC framework developed by Tencent, which is easy to communicate with new and old frameworks, and facilitates business testing. Some users who use trpc-java have requirements for high concurrency + IO intensive programs. Before the emergence of coroutines, they could only solve performance problems through the asynchronous framework provided by trpc-java. Although the asynchronous framework can solve the performance problems of high concurrency + IO-intensive programs, due to its high requirements for developers, users often accidentally write asynchronous code into synchronous code, resulting in performance degradation.
At present, trpc-java has launched the trpc-java coroutine version in combination with Kona Fiber. Users can obtain the performance of asynchronous code in the way of writing synchronous code. At present, there are big data feature middle-end services and trpc-gateway services being adapted to coroutines.
8. Future Plan
-
Kona Fiber's source github link on Kona8:
-
Kona Fiber's source github link on Kona11:
-
Continue to follow up with the Loom community and port Loom's optimizations to Kona Fiber.
references
portal
Kona 8 is an open source version, welcome to star:
Kona11 external open source version, welcome star:
- Title image source: Pexels -