Click on "Uncle Wheat" above and select "Top/Star Public Account"
Welfare dry goods, delivered as soon as possible
Finding and eliminating potential bugs in embedded development software is a daunting task.
It often takes heroic effort and expensive tools to trace back to the root cause from an observed crash, freeze, or other unplanned runtime behavior.
In the worst case, the root cause corrupts code or data, making the system appear to still be working properly or at least for a while.
Engineers often give up trying to discover the cause of uncommon anomalies that are not easily reproducible in the lab, treating them as user errors or "glitches."
However, these ghosts in the machine still exist. Here's a guide to the most common root causes of hard-to-reproduce bugs. Whenever you read firmware source code, look for the following five major bugs. And follow the recommended best practices to prevent them from happening to you again.
Mistake 1: Race Conditions
A race condition is any situation where the combined result of two or more threads of execution (which can be RTOS tasks or main() and an interrupt handler) changes depending on the exact order of interleaved instructions. Each executes on the processor.
For example, suppose you have two threads of execution, one of which regularly increments a global variable (g_counter += 1; ) and the other zeroes it out by chance (g_counter = 0; ). A race condition exists if the increment cannot always be performed atomically (ie, within a single instruction cycle).
As shown in Figure 1, consider the task as a car approaching the same intersection. Conflicts between two updates of the counter variable may never occur, or they may rarely occur. However, when doing so, the counter is not actually zeroed out in memory. Its value is corrupted at least until the next clear. This effect could have serious consequences for the system, although it may not appear until long after the actual collision.

Best practice: Race conditions can be avoided by having to execute critical sections of code atomically with appropriate preemptive restricted behavior. To prevent race conditions involving ISRs, at least one interrupt signal must be disabled for the duration of another critical section of code.
For contention between RTOS tasks, the best practice is to create a mutex specific to that shared library, which each must acquire before entering a critical section. Note that it's not a good idea to rely on the capabilities of a specific CPU to ensure atomicity, as this will only prevent race conditions until you change compilers or CPUs.
The random timing of shared data and preemption is the culprit behind the race condition. But mistakes may not always happen, making it incredibly difficult to track racial status from observed symptoms to underlying causes. Therefore, it is important to remain vigilant to protect all shared objects. Every shared object is an accident waiting to happen.
Best practice: Name all potentially shared objects (including global variables, heap objects or peripheral registers and pointers to that object) so that the risks are obvious to all future readers of the code; in Netrino Embedded C Coding standards advocate the use of the "G_ for this," prefix. Finding all potentially shared objects will be the first step in a race condition code review.
Mistake 2: Non-reentrant functions
Technically, the problem with non-reentrant functions is a special case of the race condition problem. And, for related reasons, runtime errors caused by non-reentrant functions often don't occur in a reproducible way - making them equally difficult to debug.
Unfortunately, non-reentrant features are also harder to spot in code reviews than other types of race conditions.
Figure 2 shows a typical scenario. Here, the software entity to be preempted is also an RTOS task. However, they operate not by direct calls to shared objects but indirectly by function calls.
For example, suppose task A calls a socket layer protocol function, which calls a TCP layer protocol function, which calls an IP layer protocol function, which calls an Ethernet driver. In order for the system to function reliably, all of these functions must be reentrant.
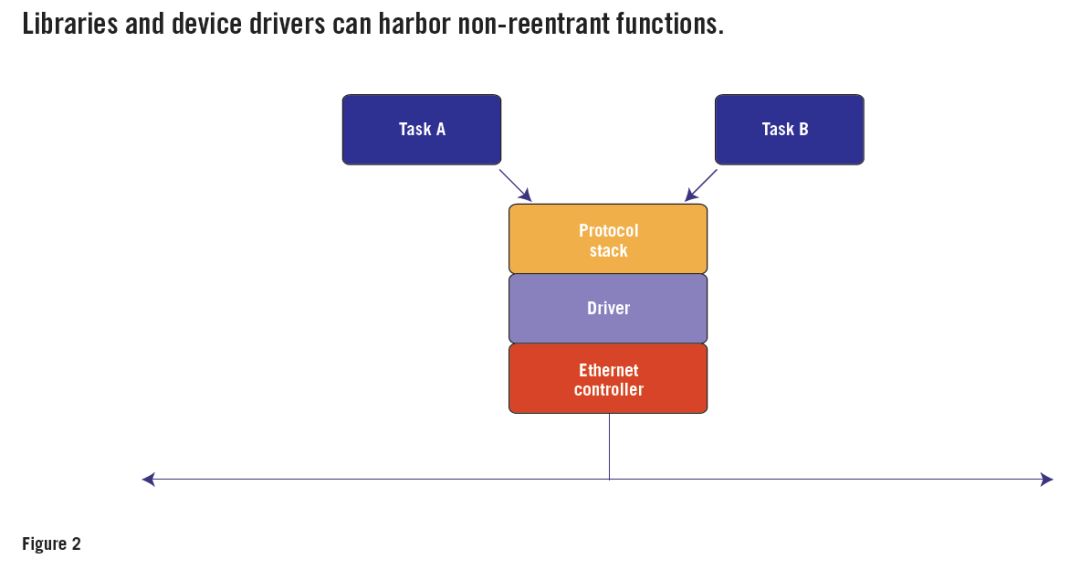
However, all functions of the Ethernet driver operate on the same global objects in the form of registers of the Ethernet controller chip. If preemption is allowed during these register operations, task B can preempt task A after queuing packet A but before transmission begins.
Task B then calls a socket layer function, which calls a TCP layer function, which calls an IP layer function, which calls an Ethernet driver, and the queue queues and transmits packet B. When control of the CPU returns to task A, it will request the transfer. Depending on the design of the Ethernet controller chip, this could either retransmit packet B or generate an error. Packet A is lost and not sent on the network.
In order to be able to call the functions of this Ethernet driver from multiple RTOS tasks at the same time, they must be made reentrant. If they each only use stack variables, there is nothing to do.
Therefore, the most common style of C functions is inherently reentrant. However, drivers and some other functionality will not be reentrant unless carefully designed.
The key to making a function reentrant is to suspend the preemption of all accesses to peripheral registers, global variables including static local variables, persistent heap objects, and shared memory regions. This can be done by disabling one or more interrupts or acquiring and releasing a mutex. The details of the problem determine the best solution.
Best practice: Create and hide a mutex in each library or driver module, which are not inherently reentrant. Make acquiring this mutex a prerequisite for manipulating any persistent data or shared registers used throughout the module.
For example, the same mutex can be used to prevent race conditions involving Ethernet controller registers and global or static local packet counters. All functions in the module that access this data must follow the protocol to acquire the mutex before accessing this data.
Be aware that non-reentrant functions may make their way into your codebase as part of third-party middleware, legacy code, or device drivers.
Disturbingly, a non-reentrant function might even be part of the standard C or C++ library that comes with the compiler. If you are using the GNU compiler to build RTOS based applications, please note that you should use the reentrant "newlib" standard C library, not the default library.
Mistake 3: Missing volatile keyword
If certain types of variables are not marked with C's volatile keyword, this can lead to many unexpected behaviors on systems that only work correctly with the compiler's optimizer set to low level or with the compiler disabled. The volatile qualifier is used during variable declarations, where its purpose is to prevent optimized reads and writes of variables.
For example, if you write the code shown in Listing 1, the optimizer may harm the patient's health by eliminating the first line in an attempt to make the program faster and smaller. However, if g_alarm is declared volatile, then this optimization will not be allowed.

Best Practice: The volatile keyword should be used to declare each:
global variables accessed by the ISR and any other part of the code,
global variables accessed by two or more RTOS tasks (even if race conditions in those accesses are prevented),
a pointer to a memory-mapped peripheral register (or set or set of registers), and
Delay loop counter.
Note that in addition to ensuring that all reads and writes are to a given variable, using volatile also constrains the compiler by adding additional "sequence points". A volatile access other than a read or write of a volatile variable must be performed before this access.
Mistake 4: Stack Overflow
Every programmer knows that stack overflow is a bad thing. However, the impact of each stack overflow is different. The nature of the corruption and the timing of the misconduct depends entirely on which data or instructions are corrupted and how they are used. Importantly, the length of time between when the stack overflows and when it negatively affects the system depends on the time before the blocking bit is used.
Unfortunately, Stack Overflow suffers more from embedded systems than desktop computers. There are several reasons for this, including:
(1) Embedded systems usually only occupy less RAM;
(2) Usually there is no virtual memory to fall back on (because there is no disk);
(3) RTOS task-based firmware designs utilize multiple stacks (one for each task), each of which must be large enough to ensure that there is no unique worst-case stack depth;
(4) Interrupt handlers may try to use these same stacks.
Further complicating the issue is that there is no extensive test to ensure that a particular stack is large enough. You can test the system under various loading conditions, but only for a long time. Tests that only run in "half a blue moon" may not witness stack overflows that only happen in "one blue moon". Under algorithmic constraints (e.g. no recursion), a top-down analysis of the control flow of the code can prove that a stack overflow does not occur. However, every time the code is changed, the top-down analysis needs to be redone.
Best practice: At startup, draw unlikely memory patterns on the entire stack. (I like to use hex 23 3D 3D 23, it looks like a fence '#==#' in an ASCII memory dump.) At runtime, have the admin task periodically check if there isn't any paint in the preset The marking above the high water mark has been changed.
If you find a problem with a stack, log the specific error in non-volatile memory (such as which stack and the height of the flood) and do something safe for the user of the product (such as a controlled shutdown or reset) A real overflow may occur. This is a nice additional safety feature to add to the watchdog task.
Mistake 5: Heap Fragmentation
Embedded developers don't make good use of dynamic memory allocation. One of them is the problem of heap fragmentation.
All data structures created via C's malloc() standard library routine or C++'s new keyword reside on the heap. The heap is a specific area in RAM with a predetermined maximum size. Initially, each allocation in the heap reduces the remaining "free" space by the same amount of bytes.
For example, the heap in a particular system might span 10 KB starting at address 0x20200000. An allocation of a pair of 4 KB data structures will leave 2 KB of free space.
Storage of data structures that are no longer needed can be returned to the heap by calling free() or by using the delete keyword. In theory, this makes that storage space available for reuse during subsequent allocations. But the order of allocations and deletions is usually at least pseudo-random, which causes the heap to become a bunch of smaller fragments.
To see if fragmentation might be an issue, consider what would happen if the first of the above 4 KB data structures were free. Now the heap consists of a free block of 4 KB and another free block of 2 KB. They are not adjacent and cannot be merged. So our heap has been split. Allocations above 4 KB will fail despite the total free space being 6 KB.
Fragmentation is similar to entropy: both increase over time. In long-running systems (in other words, most embedded systems ever created), fragmentation can eventually cause some allocation requests to fail. and then? How should your firmware handle failed heap allocation requests?
Best Practice: Avoiding using the heap entirely is a surefire way to prevent this error. However, if dynamic memory allocation is required or convenient in your system, there is another method of structuring the heap to prevent fragmentation.
The key observation is that the problem is caused by variable size requests. If all requests are the same size, any free block will be as good as any other block, even if it doesn't happen to be adjacent to any other free block. Figure 3 shows how the use of multiple "heaps" (each for allocation requests of a specific size) is implemented as a "memory pool" data structure.
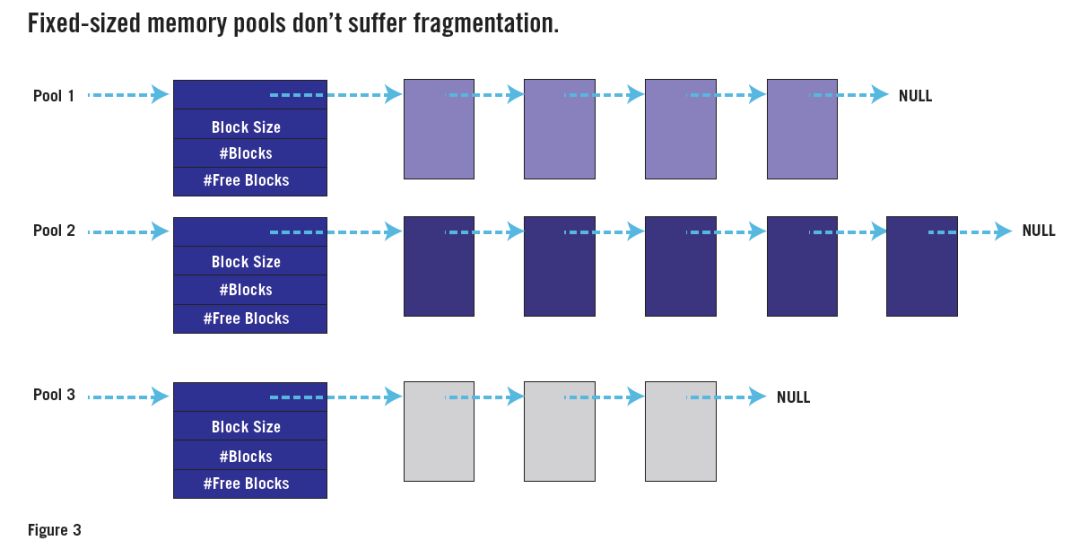
Many RTOSs have fixed-size memory pool APIs. If you have access to one of them, use it instead of malloc() and free(). Or write your own fixed size memory pool API. You only need three functions: one to create a new pool (M blocks N bytes in size); another to allocate a block (from the specified pool); one third instead of free().
Code review is still a best practice,
A lot of debugging headaches can be avoided by first ensuring that these bugs do not exist in the system. The best way to do this is to have someone inside or outside the company conduct a comprehensive code review. Enforcing standard rules coding with the best practices I describe here should also help. If you suspect one of these nasty bugs in your existing code, it's probably faster to perform a code review than trying to trace the observed failure back to the root cause.
Source:
Original article by a blogger of Huaqing Vision Chengdu Center,
Follow the CC 4.0 BY-SA copyright agreement, please attach the original source link and this statement for reprinting.
https://blog.csdn.net/weixin_44059661/article/details/107839764
The copyright belongs to the original author and is only for everyone's learning and reference. If it involves copyright issues, please contact me to delete it, thank you~
—— The End ——
Recommended in the past
How to DIY a retro picture tube clock?
An interesting project, OLED realizes "naked eye 3D"
Have you mastered the embedded basic knowledge points that novices often overlook?
A collection of domestic alternative selections for single-chip microcomputers, it is imperative!
Walk into the fab and gain an in-depth understanding of the chip manufacturing process
The degree of automation of the DJI factory is really a bit high
Click on the business card to follow me

Everything you ordered looks good , I take it seriously as I like it