Face Recognition Based on PCA
1. Algorithm Description
The face recognition of this project only needs to be realized by the PCA algorithm. The main steps of the algorithm are as follows:
1. First of all, according to the requirements of the question, for all 40 people in the Faces set, 7 of the 10 images are randomly selected for training set, and the remaining 3 images are used for subsequent testing.
2. Then, stretch the 280 train_imgs into column vectors and put all the columns together. Since the total number of pixels in each image is 10304, a matrix X of 10304*280 is obtained.
3. Each column of X is centered by subtracting the mean vector.
4. Find the transpose of X and the matrix product of X, and find the eigenvector of the product 40*40 matrix, here is the eig function of matlab.
5. Filter out the eigenvector W corresponding to the eigenvalues with the largest K before, and then multiply X by W to map to V, and use each column vector of V as a set of basis vectors for the subsequent mapping relationship. There are K basis vectors in total, which can also be called are K eigenfaces.
6. Map each column of X to the corresponding feature space through the basis vector matrix V. This is equivalent to finding the corresponding position of each image train_imgs in the new space.
7. For each test image, do the same transformation as above: convert to column vector, subtract the mean vector for centering, and then map it into the feature space with a matrix of basis vectors.
8. To judge which of the 40 train_imgs is the best match for the test image, just compare the new coordinates of the test image in the feature space and the coordinates of the 40 train_imgs in the feature space. The direct Euclidean distance (or two-norm) size, find the corresponding train_img with the smallest two norm, and find the best matching training image.
9. To sum up, the main idea of this algorithm is to remove some irrelevant or less related vectors, and retain the vectors with greater influence as the basis, which reduces the number of basis vectors and thus reduces the amount of computation. The image details are also reduced, which can avoid unrelated vectors and changes in the protagonist's expression, face orientation and accessories in the test image from adversely affecting the test accuracy.
2. Matlab code
Function Get_Training_Set.m (used to randomly read 40*7 images and average them to generate training set):
function [ imgs ] = Get_Training_Set( input_path, index, height, width, output_path )
imgs = zeros(length(index), height, width);
for i = 1 : length(index)
imgs(i, :, :) = uint8(imread([input_path '/' num2str(index(i)) '.pgm']));
end
endThe function Test_Case.m (used to test a single image, loop calls to test all test set images):
function [ found ] = Test_Case( V, eigenfaces, indexes, i, j, mean_img )
f = imread(['Faces/S' num2str(i) '/' num2str(indexes(i, j)) '.pgm']);
[height, width] = size(f);
f = double(reshape(f, [height * width, 1])) - mean_img;
f = V' * f;
[~, N] = size(eigenfaces);
distance = Inf;
found = 0;
for k = 1 : N
d = norm(double(f) - eigenfaces(:, k), 2);
if distance > d
found = k;
distance = d;
end
end
endScript Eigenface.m (just run it directly, call the above function, the accuracy in the result data is the exact percentage of a single run):
N = 7 * 40; K = 90;
Test_Num = 3 * 40;
height = 112;
width = 92;
Test_Times = 100;
accuracy = zeros(100, Test_Times);
for K = 50 : 100
for T = 1 : Test_Times
indexes = zeros(N, 10);
train_imgs = zeros(N, height, width);
for i = 1 : 40
indexes(i, :) = randperm(10);
train_imgs((i - 1) * 7 + 1 : i * 7, :, :) = Get_Training_Set(['Faces/S' num2
end
train_imgs = uint8(train_imgs);
X = zeros(height * width, N);
for i = 1 : N
X(:, i) = reshape(train_imgs(i, :, :), [height * width, 1]);
end
mean_img = mean(X, 2);
for i = 1: N
X(:, i) = X(:, i) - mean_img;
end
L = X' * X;
[W, D] = eig(L);
W = W(:, N - K + 1 : N);
V = X * W;
eigenfaces = V' * X;
for i = 1 : 40
for j = 8 : 10
found = Test_Case(V, eigenfaces, indexes, i, j, mean_img);
found = floor((found - 1) / 7) + 1;
if found == i
accuracy(K, T) = accuracy(K, T) + 1;
end
end
end
accuracy(K, T) = double(accuracy(K, T) / (Test_Num));
end
end
Mean_Accuracy = mean(accuracy, 2);
plot(Mean_Accuracy); axis([50 100 0.9 1]); 3. Test performance table
As follows, the Test_Case function returns an integer between 1-280, indicating that this column best matches the current test image. But it still needs to be converted
into an integer between 1-40 to indicate which person is matched.
found = Test_Case(V, eigenfaces, indexes, i, j, mean_img);
found = floor((found - 1) / 7) + 1; Modify the code to not ask for 40 average faces initially, but use 280 faces for direct training and then test each K value 10 times. The obtained
test line chart is as follows. It can be seen that the test accuracy increases with K from 50 To a value of 100, it fluctuates between about 93% and 95%, and a relatively stable maximum value is obtained
around K at 83:

Test form:
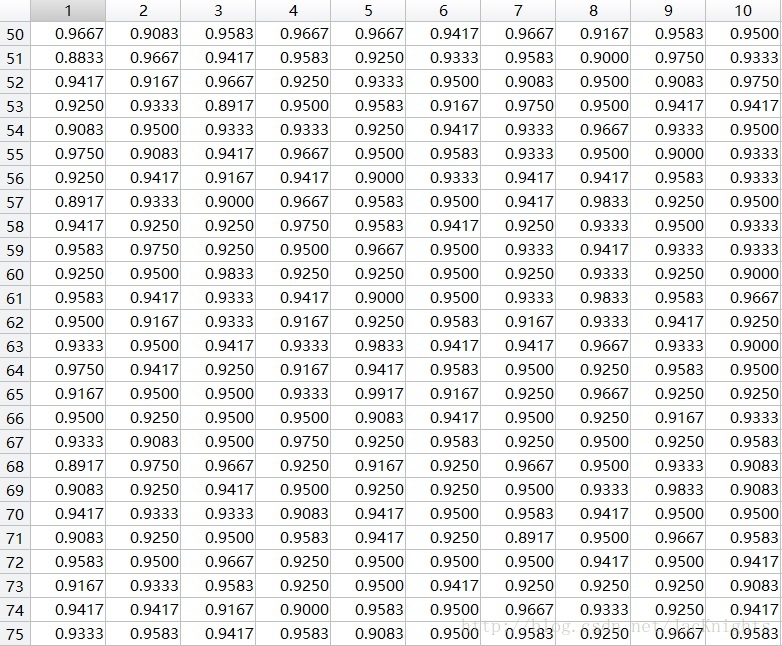
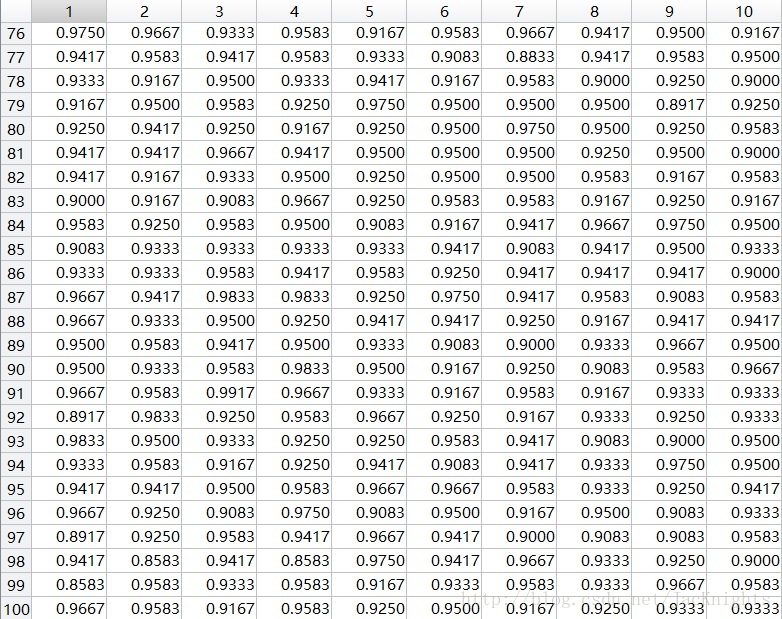
4. Process and result images
The following figure is to test each K value 100 times after direct training with 280 faces. The obtained test line chart is as follows. It can be seen that after the number of
tests is increased (10 times the previous test volume), the test accuracy As K takes values from 50 to 100, it fluctuates around 94%,
and gets a more stable maximum value of 94.5% around K at 87:
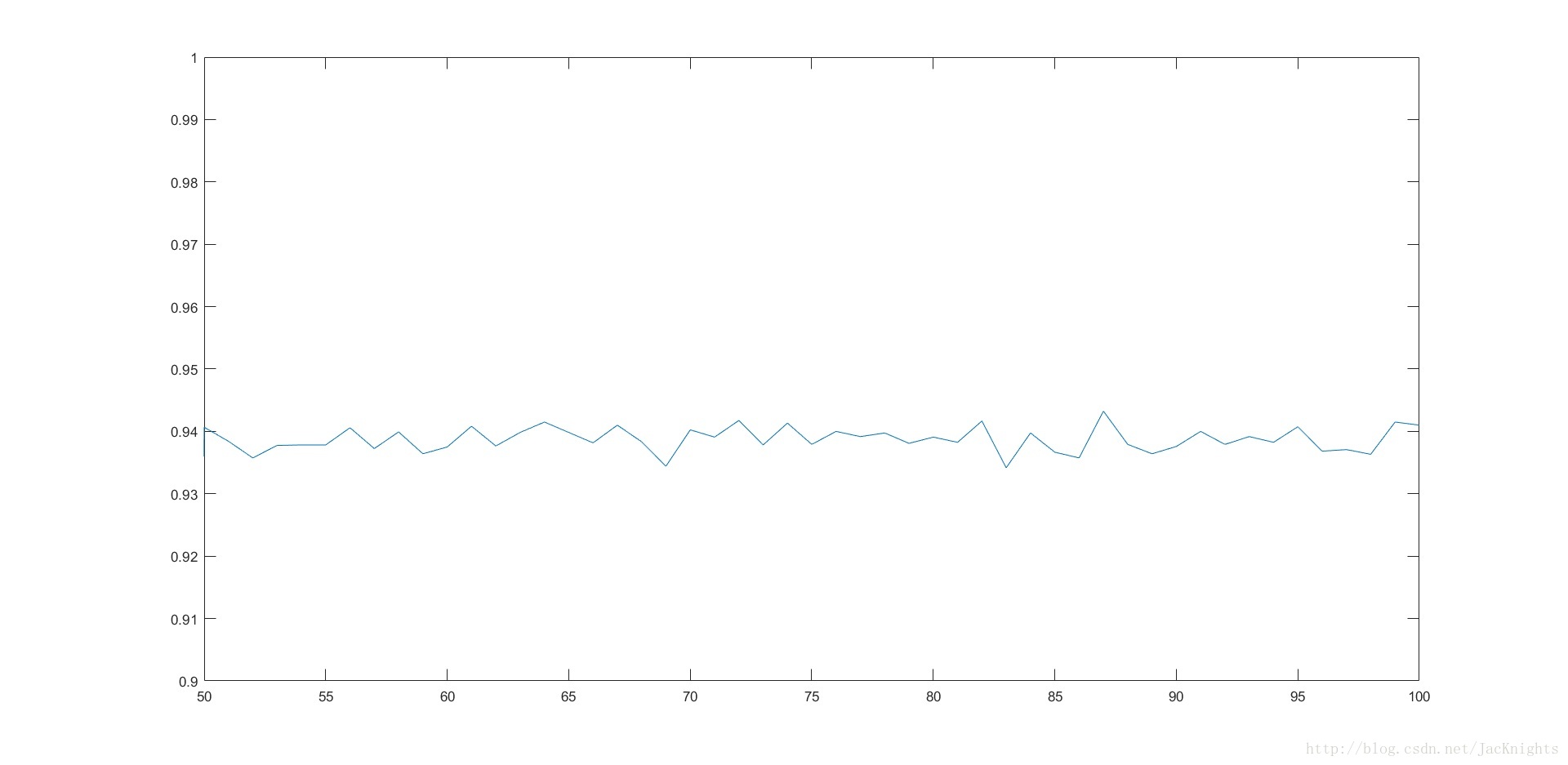
Considering that each K value is tested 100 times, chance cannot be completely ruled out, and the overall effect of K value on the accuracy is less obvious.
Therefore, the final test results show that if K is about 87, the test accuracy rate that can be obtained by the above method is about 94.5%.