(Translated from:
https://www.ibm.com/developerworks/linux/library/j-zerocopy/
)
(Zero copy here refers to the copy that can be done without CPU participation)
Many web applications serve large amounts of static content, which means that the server reads the content from disk and writes the exact same content to the response socket. This activity looks like a small amount of cpu activity, but it's very inefficient: the OS kernel reads data from the hard disk, passes that data across the kernel-user boundary to the application, and the application reads the data Data is again written to sockets in the kernel across the kernel-user boundary. From this process we see that the application exists as a very inefficient medium when the entire data is read from the hard disk file and then written to the socket.
Every time the data crosses the kernel-user boundary, the data has to be copied once, which consumes a certain amount of cpu clock cycles and memory. Fortunately, with zero-copy technology you can completely omit these unnecessary copy operations. An application using zero-copy can request the kernel to directly copy the data from the hard disk to the socket without going through the middle layer of the application. Zero-copy greatly improves application performance and reduces the number of times the operating system switches between kernel mode and user mode.
The java class library supports zero-copy through the transferIo() method in the FileChannel class. This method allows direct transfer of bytes from one channel to another writable channel without going through the application. This article first demonstrates the overhead of a simple file transfer with traditional copy semantics, and then shows how the zero-copy technique brings performance improvements.
Data transfer: traditional implementation
Consider the scenario of reading data from a file and then transferring it over the network to another program (this scenario describes the behavior of many service applications, including web services that serve static pages, ftp services, mail services, and so on). The core of this operation is achieved through the two calls described in Listing1:
Listing 1:
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
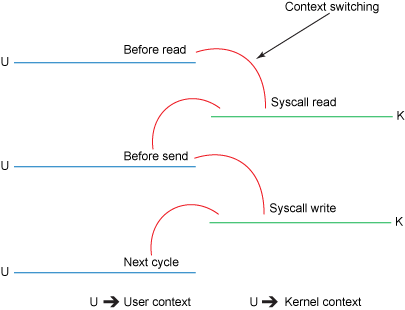
Although the operation of Listing 1 looks very simple, in fact, before the entire operation is completed, a total of four conversions between kernel mode and user mode and four copy operations are experienced. Figure 1 will show how data is transferred from the file to the socket.
Figure 1. Traditional data copy implementation
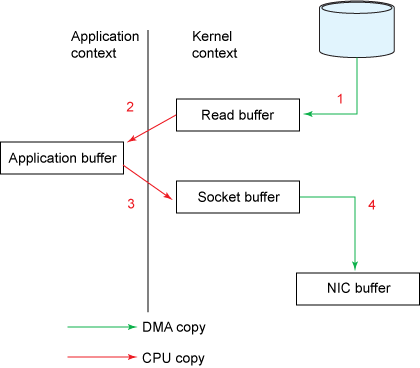
Figure 2 will show the context switch process in action:
Figure 2. Traditional context switching
The steps involved are as follows:
1. The read() call will cause a context switch from kernel mode to user mode (as shown in Figure 2). The internal implementation is to read data from the file by calling sys_read(). The first copy is done by the direct memory access (DMA) engine, which reads the file content from the hard disk and stores the read data in a read buffer in the kernel (the buffer is designed to improve the order access and small file access performance).
2. The requested data is then copied from the read buffer, which is the kernel buffer, to the user buffer, which is the user buffer, and then the read() method returns. The return operation will cause a second context switch from kernel mode to user mode. Now the data we need is stored in the user buffer, and now the application can directly manipulate this data.
3. The send() call of the socket will cause the third context transition from user mode to kernel mode. Then the third copy occurs, the data will be copied from the user buffer to the buffer in the kernel, but the address of this buffer is different from the read buffer in the first step, but a kernel buffer associated with the target socket, We call it a socket buffer.
4. The return of the send() system call will cause the fourth context switch from kernel mode to user mode. The fourth copy occurs when the DMA engine passes data from the kernel buffer to the protocol engine, which is done asynchronously (relative to the application's call instruction).
Through the above introduction, the cache area in the kernel seems to be very inefficient, it is better to transfer the data directly from the hard disk to the user cache area. But in fact, the kernel cache is very useful in many cases. It was introduced into the operating system to improve the performance of io. Because most io operations are sequential operations, when an io call is made, the kernel will put the data page where the data required for this call is located and the following data pages into the buffer area, so that the next io access will come. At this time, instead of inefficient hard disk access, you can directly hit the data in the cache area, and then copy the data in the cache area to the user cache area, which is a measure to balance the low efficiency of hard disk access. . In fact, the kernel's buffer area is very efficient when the requested data is a small file or the requested io operation is a sequential operation. Moreover, the existence of the kernel cache also provides a basis for asynchronous write operations.
Unfortunately, when the file where the requested data is located is much larger than the size of the kernel buffer, the existence of the kernel buffer itself will also become a performance bottleneck. Data is heavily copied on hard disk, kernel cache, user cache, before it is fully delivered to the application. (In fact, if it is sequential access, the copy from the hard disk to the kernel cache is asynchronous most of the time, even if it is a large file at this time, it will not have much performance impact, specific reference:
https://tech.meituan .com/about-desk-io.html
)
Zero-copy improves performance by omitting unnecessary copy operations.
Data transfer: zero-copy implementation
If you reconsider the traditional implementation method of data transmission introduced above, you will find that the second and third data replication is completely unnecessary, and the middle-tier application does not perform any operations on the data during this process. Just buffer the data in the kernel buffer and then transfer the buffered data to the socket buffer in the kernel. In fact, data can be transferred directly from the read buffer to the socket buffer. The transferInto() method function is actually the same as this. Listing 2 shows the method signature of transferInto():
Listing 1: the transferInto() method
public void transferTo(long position, long count, WritableByteChannel target);
The transferInto() method transfers data from one file channel to another writable byte channel. The internal implementation depends on the support of the underlying operating system for zero-copy; in unix and various types of linux, this method call will cause a sendfile() system call, as described in Listing 3 below, which will transfer data from A file descriptor is transferred to another file descriptor.
Listing 1: the sendfile() system call
#include <
sys
/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
The file.read() and socket.send() method calls in Listing 1 can
be replaced by transferInto() method calls, as in Listing 4:
Listing 4. Using transferInto
() to copy data from a disk file to a socket
transferTo(position, count, writableChannel);
Figure 3 shows the
data flow path when the transferInto() method is called:
Figure 3. Data copy with
transferInto()
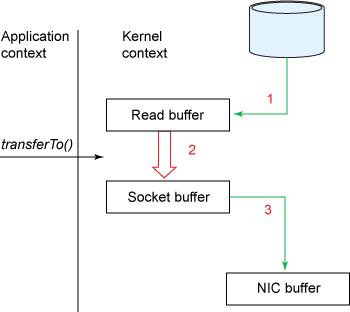
Figure 4 shows the
context switch when the transferInto() method is called:
Figure 4. Context switch with
transferInto()
When using the transferInto() method in Listing 4
, the internal main steps are as follows:
1. The transferInto() method causes the DMA engine to copy the file content data to the read buffer, and then the data in the read buffer is copied to the kernel buffer associated with an output socket.
In the storage area, it is what we called the socket buffer before.
2. The third copy happens when the DMA engine transfers the data from the socket buffer to the NIC buffer.
Now, compared to the previous traditional data transfer method, we have a little optimization: we reduce the number of context switches between the kernel mode and user mode from 4 to 2, and reduce the data copy from 4 to 3 ( Now only the second copy requires CPU resources, and other copies are performed by the DMA engine, which does not consume CPU resources). But that doesn't quite achieve our zero-copy purpose. If the underlying NIC supports gather operations, we can further reduce the data copying done by the kernel. In Linux kernel 2.4 and later, the socket buffer descriptor has been modified to accommodate this requirement. This not only reduces multiple context switches, but also eliminates duplicate data copies that require CPU involvement. The user-level use cases are the same as before, but the underlying implementation has changed a bit:
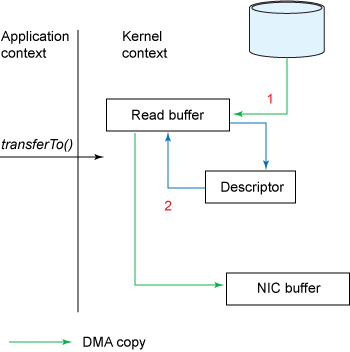
1.
The transferInto() method causes the DMA engine to copy the file content data to the read buffer
2. At this point, no data will be copied into the socket buffer, but instead a descriptor that carries information about the location and length of the data. The DMA engine directly transfers data from the read buffer
Transfer to NIC buffer. Thus, the last copy operation that requires CPU participation is eliminated.
Figure 5 shows the
data copy when the transferInto() method is called with gather operation support:
Figure 5. Data copy with
transferInto() and gather operation are used