Introduction to MySQL
MySQL is a relational database, mainly used to persistently store some data in our system such as user information.
MySQL is an open source software, and there is no need to pay when using it, and it is still a relatively mature database, which is widely used in various systems. The default port number for MySQL is 3306.
Get the current Mysql version:
SELECT VERSION();
What are the parts of MySQL and what are they used for?
- Server
Connector: Manage connections, Permission Verification
Analyzer: Lexical Analysis, Syntax Analysis
Optimizer: Execution Plan Generation, Index Selection
Executor: Operation Storage Engine, Return Execution Results - Storage engine: store data, provide read and write interfaces
Execution engine in MySQL
Commonly used storage engines are as follows:
- Innodb engine: The Innodb engine provides support for database ACID transactions. And also provides row-level locking and foreign key constraints. It is designed to handle database systems with large data volumes.
- MyIASM engine (original Mysql's default engine): does not provide support for transactions, nor does it support row-level locks and foreign keys.
- MEMORY engine: All data is in memory, and the data processing speed is fast, but the security is not high.
Differences between MyISAM and InnoDB:
| MyISAM | Innodb | |
|---|---|---|
| Whether to support transactions | Transactions are not supported, but each query is atomic | Transactions that support ACID, support four isolation levels of transactions |
| lock support | Support table level locking | Support row-level locking and table-level locking, with low locking force and high concurrency capability |
| Whether to support foreign keys | Foreign keys are not supported | Support foreign keys |
| storage structure | Each table is stored in three files: index file MYI, data file MYD, frm table structure file | All tables are stored in the same data file (or multiple), the size of the InnoDB table is only limited by the size of the operating system file, generally 2GB |
| storage | MyISAM can be compressed and has less storage space | InnoDB tables require more memory and storage, it builds its dedicated buffer pool in main memory for caching data and indexes |
| file format | Data and index are stored separately, data.MYD, index.MYI | Data and indexes are stored centrally, .ibd |
| Portability, Backup and Recovery | It is very convenient in cross-platform data transfer, and can operate on a table separately during backup and recovery | You can copy data files, backup binlog, or use mysqldump, which is relatively painful when the amount of data reaches tens of gigabytes |
| record storage order | Save in record insertion order | Insert in order by primary key size |
| hash index | not support | support |
| full text index | support | Not supported (but can use Sphinx plugin) |
Most of the time we are using the InnoDB storage engine, in some read-intensive situations, using MyISAM is also appropriate. However, the premise is that your project does not mind the shortcomings of MyISAM not supporting transactions, crash recovery, etc.
MyISAM: Applications based on read-write insertion, such as blog systems, news portals.
Innodb: The frequency of update (delete) operations is also high, or the integrity of the data must be guaranteed; the concurrency is high, and transactions and foreign keys are supported. Such as OA automated office system.
The difference between field types CHAR and VARCHAR in MySQL?
| char | varchar | |
|---|---|---|
| length | Fixed length (1-255) | variable length |
| When the length is insufficient | When the inserted length is less than the defined length, it is filled with spaces, and trailing spaces need to be removed when retrieving CHAR values | When it is less than the defined length, it is stored according to the actual insertion length |
| performance | Much faster access than varchar | access is much slower than char |
| scenes to be used | Suitable for storing very short, fixed-length strings, such as mobile phone numbers, MD5 values, etc. | Suitable for use in scenarios where the length is not fixed, such as delivery address, email address, etc. |
The difference between the field types DATETIME and TIMESTA in MySQL?
| Types of | occupy bytes | Scope | time zone issue |
|---|---|---|---|
| datetime | 8 bytes | 1000-01-01 00:00:00 to 9999-12-31 23:59:59 | Storage is time zone independent and does not change |
| timestamp | 4 bytes | 1970-01-01 00:00:01 | to 2038-01-19 11:14:07 |
If a table has a column defined as TIMESTAMP, the timestamp field will get the current timestamp whenever the row is changed.
The three paradigms of database
- First Normal Form: Attributes are not subdividable
- Second normal form: On the basis of a normal form, some dependencies are eliminated, and attributes are completely dependent on the primary key
- The third normal form: On the basis of the second normal form, the transitive dependency is eliminated, and the attribute does not depend on other non-primary attributes. The attribute directly depends on the primary key
What is a transaction in a database? What are the characteristics of a transaction?
A transaction is an ordered set of database operations. If all operations in the group succeed, the transaction is considered successful and the transaction is committed. If an operation fails, the transaction is rolled back and the effects of the operation on the transaction are cancelled. (A transaction is a logical set of operations, either all or none)
Characteristics of Transactions: ACID
- Atomicity: A transaction is the smallest unit of execution and does not allow division. The atomicity of transactions ensures that actions either complete or do nothing at all;
- Consistency: Before and after the transaction is executed, the data is consistent. For example, in the transfer business, the total amount of the transferor and the payee should be the same regardless of whether the transaction is successful or not;
- Isolation: When accessing the database concurrently, a user's transaction is not interfered by other transactions, and the database is independent between concurrent transactions;
- Durability: After a transaction is committed. Its changes to the data in the database are persistent and should not have any effect on the database even if it fails.
# 开启一个事务
START TRANSACTION;
# 多条 SQL 语句
SQL1,SQL2...
## 提交事务
COMMIT;
What does ACID rely on to guarantee?
- Atomicity: The MySQL InnoDB engine uses the undo log (rollback log) to ensure the atomicity of the transaction, records the log information that needs to be rolled back, and undoes the successfully executed SQL when the transaction is rolled back.
- Consistency: Consistency can only be guaranteed after the durability, atomicity, and isolation of transactions are guaranteed.
- Isolation: The MySQL InnoDB engine ensures transaction isolation through lock mechanism, MVCC and other means (the default supported isolation level is REPEATABLE-READ).
- Persistence: Use redo log (redo log) to ensure the durability of the transaction. When mysql modifies the data, it records the operation in memory and redo log, and the redo log can be restored when it is down. The flushing of the redo log will be performed when the system is idle.
The InnoDB redo log is written to the disk, and the InnoDB transaction enters the prepare state. If the previous prepare is successful, binlog writes to the disk, and continues to persist the transaction log to binlog. If the persistence is successful, the InnoDB transaction enters the commit state (write a commit record in the redo log)
What is MVCC
Multi-version concurrency control: When reading data, the data is saved in a way similar to a snapshot, so that the read lock does not conflict with the write lock, and different transaction sessions will see their own specific versions of the data, version chain
MVCC only works under two isolation levels, READ COMMITTED (read committed) and REPEATABLE READ (repeatable read). The other two isolation levels are not compatible with MVCC, because READ UNCOMMITTED always reads the latest data row, not the data row that conforms to the current transaction version. SERIALIZABLE (serialization) locks all rows read.
There are two necessary hidden columns in the clustered index record:
trx_id: used to store the transaction id
each time a clustered index record is modified roll_pointer: each time a clustered index record is modified, The old version will be written to the undo log. This ro‖_pointer stores a pointer, which points to the location of the previous version of the clustered index record, and uses it to obtain the record information of the previous version. (Note that the undo log of the insert operation does not have this attribute, because it does not have an old version)
Mysql's MVCC implements multiple versions through the version chain, which can be read and written concurrently. Different isolation levels are achieved through different Readview generation strategies:
- The readview is created when the transaction is started, and the readview maintains the currently active transaction id, that is, the uncommitted transaction id, and sorts to generate an array.
- Access the data to obtain the transaction id in the data (the record with the largest transaction id is obtained), and if the readview is on the left side of the readview (smaller than the readview), it can be accessed (the left side means that the transaction has been committed)
- If it is on the right side of the readview (larger than the readview) or in the readview, it is not accessible, get the roll_ pointer, take the previous version and compare it again (on the right means, the transaction occurs after the readview is generated, in the readview means The transaction has not yet been committed)
- The difference between committed read and repeatable read lies in their strategies for generating Readviews:
a transaction under the committed read isolation level generates an independent readview at the beginning of each query, while the repeatable read isolation level generates a separate readview at the first time. A Readview is generated when reading, and subsequent reads reuse the previous Readview
MySQL master-slave synchronization principle
There are three main threads in MySQL master-slave replication: master (binlog dump thread), slave (I/O thread, SQL thread), Master-thread and two threads in Save.
- Master node binlog: The basis of master-slave replication is that the master database records all changes in the database to binlog. The binlog is a file that saves all modifications to the database structure or content from the moment the database server is started.
- The master node log dump thread, when the binlog changes, the log dump thread reads its content and sends it to the slave node.
- Receive binlog content from the node I/O thread and write it to the relay log file.
- The SQL thread of the slave node reads the content of the relay log file to replay the data update, and finally ensures the consistency of the master-slave database
Since the default replication method of mysql is asynchronous, the master library does not care whether the slave library has processed the log after sending the log to the slave library. This will cause a problem that if the master library hangs and the slave library processing fails, then the slave library upgrades After the main library, the log is lost. Two concepts arise from this:
- Full synchronous replication: After the main library writes to binlog, the log is forced to synchronize the log to the slave library, and all the slave libraries are executed before returning to the client, but obviously this method will seriously affect the performance.
- Semi-synchronous replication: Different from full synchronization, the logic of semi-synchronous replication is as follows. After the slave library successfully writes the log, it returns an ACK confirmation to the master library, and the master library considers the write operation complete when it receives at least one confirmation from the slave library.
What problems do concurrent transactions bring?
- Dirty read: When a transaction modifies data, another transaction reads the data. Because this data is uncommitted data (rollback may occur), the data read by another transaction is "dirty data".
- Unrepeatable read: The same data is read multiple times within a transaction, and the data is inconsistent. It is possible that a transaction modified the data during multiple reads of the data by the transaction. (modify operation)
- Phantom read: The same data is read multiple times within a transaction, and the number of data rows is inconsistent. It is possible that during the multiple reads of data by the transaction, a transaction inserted data, resulting in data that should not have appeared. (insert delete operation)
- Lost to modify: A transaction reads a piece of data and modifies the data, during which another transaction also accesses the data and modifies the data. The operation that resulted in the modification by the first transaction was unsuccessful and is therefore called lost modification. For example: transaction 1 reads data A=20 in a table, transaction 2 also reads A=20, transaction 1 modifies A=A-1, transaction 2 also modifies A=A-1, the final result A=19, transaction The modification of 1 is lost.
Four transaction isolation levels
- READ-UNCOMMITTED: The lowest isolation level that allows reading of data changes that have not yet been committed, which may lead to dirty reads, phantom reads, or non-repeatable reads.
- READ-COMMITTED (read committed): Allows to read data that has been committed by concurrent transactions, which can prevent dirty reads, but phantom reads or non-repeatable reads may still occur.
- REPEATABLE-READ (repeatable read): The results of multiple reads of the same field are consistent, unless the data is modified by its own transaction, which can prevent dirty reads and non-repeatable reads, but phantom reads may still occur.
- SERIALIZABLE (serializable): The highest isolation level, fully compliant with the ACID isolation level. All transactions are executed one by one, so that there is absolutely no possibility of interference between transactions, that is, this level can prevent dirty reads, non-repeatable reads, and phantom reads.
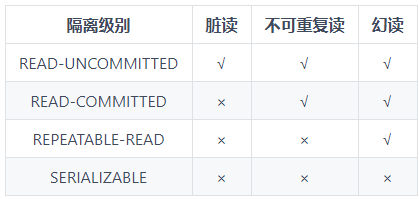
The default supported isolation level for the MySQL InnoDB storage engine is REPEATABLE-READ (repeatable). We can view it by SELECT @@transaction_isolation;
What is an index? Fundamentals of Indexing
An index is a data structure for quickly querying and retrieving data. Common index structures are: B tree, B+ tree and Hash.
索引的作用就相当于目录的作用。其本身是一种特殊的文件,它们包含着对数据表里所有记录的引用指针。会占据一定的物理空间。
索引的优缺点:
- 优点 :使用索引可以大大加快数据的检索速度(大大减少检索的数据量)
- 缺点 :创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。另外,索引需要使用物理文件存储,也会耗费一定空间。
索引的原理:把无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表的内容,再取出数据地址链,从而拿到具体数据
使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
索引类型
- 普通索引(Index) :用来快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 唯一索引(Unique Key) :可以保证数据记录的唯一性,允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
- 主键索引(Primary Key):数据表的主键列使用的就是主键索引。是一种特殊的唯一索引,一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。(前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同)
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,通过建立倒排索引,可以极大提升索引效率,解决判断字段是否包含问题,是目前搜索引擎使用的关键技术。
唯一索引比普通索引快吗,为什么?
对于写多读少的情况, 普通索引利用 change buffer 有效减少了对磁盘的访问次数,而唯一索引需要校验唯一性,此时普通索引性能要高于唯一索引
MySQL 如何为表字段添加索引?
添加 PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
添加 UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
添加 INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
添加 FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
添加多列索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
select count(*)/count(distinct left(password,prefixLen));
通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
二级索引(辅助索引):
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。唯一索引,普通索引,前缀索引等索引属于二级索引。
二级索引属于非聚簇索引
聚集索引与非聚集索引
两者都是B+树的数据结构,依赖于有序的数据。
聚集索引:聚集索引即索引结构和数据一起存放,并按一定的顺序进行排序的索引,找到了索引进找到了数据。
主键索引属于聚集索引。
优点:
聚集索引的范围查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
缺点:
- 依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
- 更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改, 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的, 所以对于主键索引来说,主键一般都是不可被修改的。
非聚集索引:非聚集索引即索引结构和数据分开存放的索引。非聚集索引的叶子节点并不存放数据,存储的数据行地址,根据数据行地址再回表查数据。
优点:
更新代价比聚集索引要小 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
缺点:
- 跟聚集索引一样,非聚集索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
MyISAM:采用非聚集索引, 索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致, 但是辅索引不用保证唯一性。
InnoDB:主键索引采用聚集索引( 索引的数据域存储数据文件本身), 辅助索引的数据域存储主键的值; 因此从辅助索引查找数据, 需要先通过辅助索引找到主键值, 再访问辅助索引; 最好使用自增主键, 防止插入数据时, 为维持 B+树结构, 文件的大调整。
创建索引的一些原则
适合索引:频繁查询、范围查询、排序、连接的字段
不适合索引:基数较小、频繁更新、重复值多的、字段为NULL的字段
选择合适的字段创建索引:
- 被频繁查询的字段 :我们创建索引的字段应该是查询操作非常频繁的字段。
- 被作为条件查询的字段 :被作为 WHERE 条件查询的字段,应该被考虑建立索引。(避免在查询条件中对字段施加函数,这会造成无法命中索引)
- 频繁需要排序的字段 :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- 被经常频繁用于连接的字段 :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
被频繁更新的字段应该慎重建立索引:虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
取值离散大的字段的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;比如性别就不适合做索引。
索引不为 NULL 的字段 :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
考虑在字符串类型的字段上使用前缀索引代替普通索引。前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
尽可能的考虑建立联合索引而不是单列索引:因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
注意避免冗余索引 :冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
一些建议:
- 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引。
- 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
- 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗
- 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
索引失效的原因可能是什么?
索引失效这个问题的前提应该是建立了索引,却没有使用到,或者没有完全使用到,下面列举了一些常见原因,面试中可能也会闻到。
- 原因一:复合索引没有遵守最左前缀原则,复合索引必须遵守最左前缀,也就是按照复合索引创建的顺序,左边的列必须按顺序出现。
- 原因二:在索引列上做了任何操作(计算、函数、类型转换)
- 原因三:出现范围条件,往后全部失效
- 原因四:没有充分利用覆盖索引
- 原因五:使用了不等于(!= 或者 <>) 作为条件
完整性约束包括哪些?
约束:保证数据的完整性而实现的摘自一套机制,即(约束是针对表中数据记录的)
数据完整性(Data Integrity)是指数据的精确(Accuracy)和可靠性(Reliability)。分为以下四类:
- 实体完整性: 规定表的每一行在表中是惟一的实体。
- 域完整性:是指表中的列必须满足某种特定的数据类型约束,其中约束又包括 取值范围、精度等
规定。 - 参照完整性: 是指两个表的主关键字和外关键字的数据应一致,保证了表之间的数据的一致性,
防止了数据丢失或无意义的数据在数据库中扩散。 - 用户定义的完整性:不同的关系数据库系统根据其应用环境的不同,往往还需 要一些特殊的约束
条件。用户定义的完整性即是针对某个特定关系数据库的约束条件, 它反映某一具体应用必须满足的语
义要求。
与表有关的约束:
- 非空约束:NOT NULL 保证某列数据不能存储NULL 值;
- 唯一约束:UNIQUE(字段名) 保证所约束的字段,数据必须是唯一的,允许数据是空值(Null),但只允许有一个空值(Null);
- 主键约束:PRIMARY KEY(字段名) 主键约束= 非空约束 + 唯一约束 保证某列数据不能为空且唯一;
- 外键约束:FOREIGN KEY(字段名) 保证一个表中某个字段的数据匹配另一个表中的某个字段,可以建立表与表直接的联系;
- 自增约束:AUTO_INCREMENT 保证表中新插入数据时,某个字段数据可以依次递增;
- 默认约束:DEFALUT 保证表中新插入数据时,如果某个字段未被赋值,则会有默认初始化值;
- 检查性约束:CHECK 保证列中的数据必须符合指定的条件;
B树和B+树的区别
B 树& B+树两者有何异同呢?
- B 树也称 B-树,全称为多路平衡查找树 ,在B树中,所有节点既存放键(key) 也存放数据(data),叶子节点各自独立。
- B+树是B树的一种变体,内部节点都是键(key),没有值,叶子节点同时存放键(key)和值(value)。而且所有的叶子结点中增加了指向下一个叶子节点的指针, 因此 InnoDB 建议为大部分表使用默认自增的主键作为主索引。
使用B树的好处:
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处:
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可(检索效率很稳定)。而B树则需要对树的每一层进行遍历(当于对范围内的每个节点的关键字做二分查找),这会需要更多的内存置换次数,因此也就需要花费更多的时间
数据库为什么使用B+树而不是B树?
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。
- B+树的查询效率更加稳定,B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
- 增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
Hash索引与B+树?
在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
- hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。B+树底层实现是多路平衡查找树。对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
- hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),支持范围查询。
- hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
- hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
什么是最左前缀匹配原则?
最左前缀匹配原则:最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
mysql会一直从左向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
MySQL锁的类型
按照锁的粒度把数据库锁分为行级锁、表级锁和页级锁
- 行级锁:行级锁是MySQL中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 - 表级锁:表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。 - 页级锁:页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
基于锁状态分类:共享锁、排它锁
- 共享锁( Share Lock) 又称读锁,简称S锁;当一个事务为数据加上读锁之后,其他事务只能对该数据加读锁,而不能对数据加写锁。直到所有的读锁释放之后其他事务才能对其进行加持写锁,共享锁的特性主要是为了支持并发的读取数据,读取数据的时候不支持修改,避免出现重复读的问题
- 排他锁( exclusive Lock) 又称写锁,简称X锁;当一个事务为数据加上写锁时,其他请求将不能再为数据加任何锁,直到该锁释放之后, 其他事务才能对数据进行加锁,排他锁的目的是在数据修改时候,不允许其他人同时修改,也不允许其他人读取,避免了出现脏数据和脏读的问题
锁的优化策略:
读写分离、分段加锁、减少锁持有的时间
InnoDB 存储引擎的锁的算法
- Record lock:记录锁(行锁),单条索引记录上加锁,锁住的永远是索引,而非记录本身。
- Gap lock:间隙锁,在索引记录之间的间隙中加锁(锁定一个范围),并不包括该索引记录本身。
- Next-key lock:临键锁,Record lock 和 Gap lock 的结合,即除了锁住记录本身,也锁住索引之间的间隙(一个范围)。
InnoDB 中的行锁的实现依赖于索引,一旦某个加锁操作没有使用到索引,那么该锁就会退化为表锁。记录锁存在于包括主键索引在内的唯一索引中,锁定单条索引记录。
间隙锁存在于非唯一索引中,锁定开区间范围内的一段间隔,它是基于临键锁实现的。在索引记录之间的间隙中加锁,或者是在某一条索引记录之前或者之后加锁,并不包括该索引记录本身。
临键锁存在于非唯一索引中,该类型的每条记录的索引上都存在这种锁,它是一种特殊的间隙锁,锁定一段左开右闭的索引区间。即,除了锁住记录本身,也锁住索引之间的间隙。
MySQL怎么恢复一个月前的数据?
通过整库备份+binlog进行恢复. 前提是要有定期整库备份且保存了binlog日志
千万条数据的表, 如何分页查询?
数据量过大的情况下,limit offset 分页会由于扫描数据太多而越往后查询越慢。 可以配合当前页最后一条ID进行查询, SELECT * FROM T WHERE id > #{ID} LIMIT #{LIMIT} 。 当然, 这种情况下ID必须是有序的, 这也是有序ID的好处之一。
一天万条以上的增量, 预计运维三年,怎么优化?
- 设计良好的数据库结构, 允许部分数据冗余, 尽量避免 join 查询, 提高效率。
- 选择合适的表字段数据类型和存储引擎, 适当的添加索引。
- MySQL 库主从读写分离。
- 找规律分表, 减少单表中的数据量提高查询速度。
- 添加缓存机制, 比如 memcached, apc
等。 - 不经常改动的页面, 生成静态页面。
- 书写高效率的 SQL。比如 SELECT * FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE
慢查询如何优化?
慢查询的优化首先要搞明白慢的原因是什么?是查询条件没有命中索引?是load了不需要的数据列?还是数据量
所以优化也是针对这三个方向来的:
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改素引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表
分库分表:
以订单为例:由于历史订单使用率并不高, 高频的可能只是近期订单, 因此, 将订单表按照时间进行拆分, 根据数据量的大小考虑按月分表或按年分表。 订单ID最好包含时间(如根据雪花算法生成), 此时既能根据订单ID直接获取到订单记录, 也能按照时间进行查询。