To tell you the truth, I was a bit "backward" in this year's Double Eleven. The Kafka cluster I was in charge of had some idiots, but it was these idiots that made my Double 11 experience very fulfilling and made me realize that if I didn't systematically Chemically learning Kafka, it is impossible to warn the production cluster in time and stifle the failure in the cradle, so I also decided to study the core of kafka.
This article will first share a fault that I did not expect: Kafka production environment lost a large number of messages .
The first thing to explain is that the message loss is not due to power failure, and the number of replicas in the cluster is 3, and the acks=-1(all) set by the message sender.
With such strict settings, why is there still message loss? Please listen to the author slowly.
1. Fault phenomenon
When the failure occurred, I received feedback from multiple project teams that the location of the consumer group was reset to a few days ago. The screenshots are as follows:

Judging from the above consumer group delay monitoring curve, the backlog number soared from zero in an instant, and it was initially suspected that the location was reset.
Why is that point reset?
What? Didn't your article say that you want to talk about why Kafka loses messages? Why do you say that the consumer group site has been reset? Writer of sensational headlines! ! !
NO, NO, NO, all the officials, it is definitely not that the text is wrong, please take this question and explore it with me.
2. Problem analysis
When encountering problems, don’t panic, and be reasonable. For MQ-based applications, the consumer side generally implements idempotency, that is, messages can be processed repeatedly without affecting the business. Therefore, the solution is to ask the project team to evaluate first. Manually set the site to about 30 minutes before the problem occurs to quickly stop the bleeding.
A wave of operations is as fierce as a tiger, and then it is necessary to analyze the reasons for the problem.
By viewing the log (server.log) of the Kafka server at that time, you can see the following logs:

The above log has been modified "beyond recognition", and its key log is as follows:
- Member consumer-1-XX in group consumerGroupName has failed, removing it from the group
- Preparing to rebalance group XXXX on heartbeat expiration
The directivity of the above log is very obvious: due to the expiration of the heartbeat detection, the consumer group coordinator removes the consumer from the consumer group, which triggers rebalancing.
Consumer group rebalancing : When the number of topic partitions or the number of consumers changes, the partitions need to be redistributed among consumers to achieve load balancing on the consumer side.
During the rebalancing period, the consumption of message consumers will all be suspended. When the consumer re-completes the load balancing of the partition, it continues to pull messages from the server. At this time, the consumer does not know where to start, so it needs to query the bit from the server. point, so that consumers can continue to consume from the point of last consumption.
Now that the consumption site is reset to the earliest site, can it be understood that the site is lost? So why is the site missing?
Nothing more than two reasons:
- The server loses the location, so the client cannot query the location
- The client actively submitted -1 to the server, resulting in the loss of the site
At present, the Kafka version used by our company is 2.2.x. The location of the consumer group is stored in a system topic (__consumer_offsets). Whether it is at the server level or the topic level, the parameter unclean.leader.election.enable is set to false. Indicates that only the replicas in the ISR set can participate in the leader election, which can strictly ensure that the site message will not be lost or returned to a certain site in history.
Looking at the API of the client's submission site, it is found that the entity class used to encapsulate the client site will verify the site. The code screenshot is as follows:
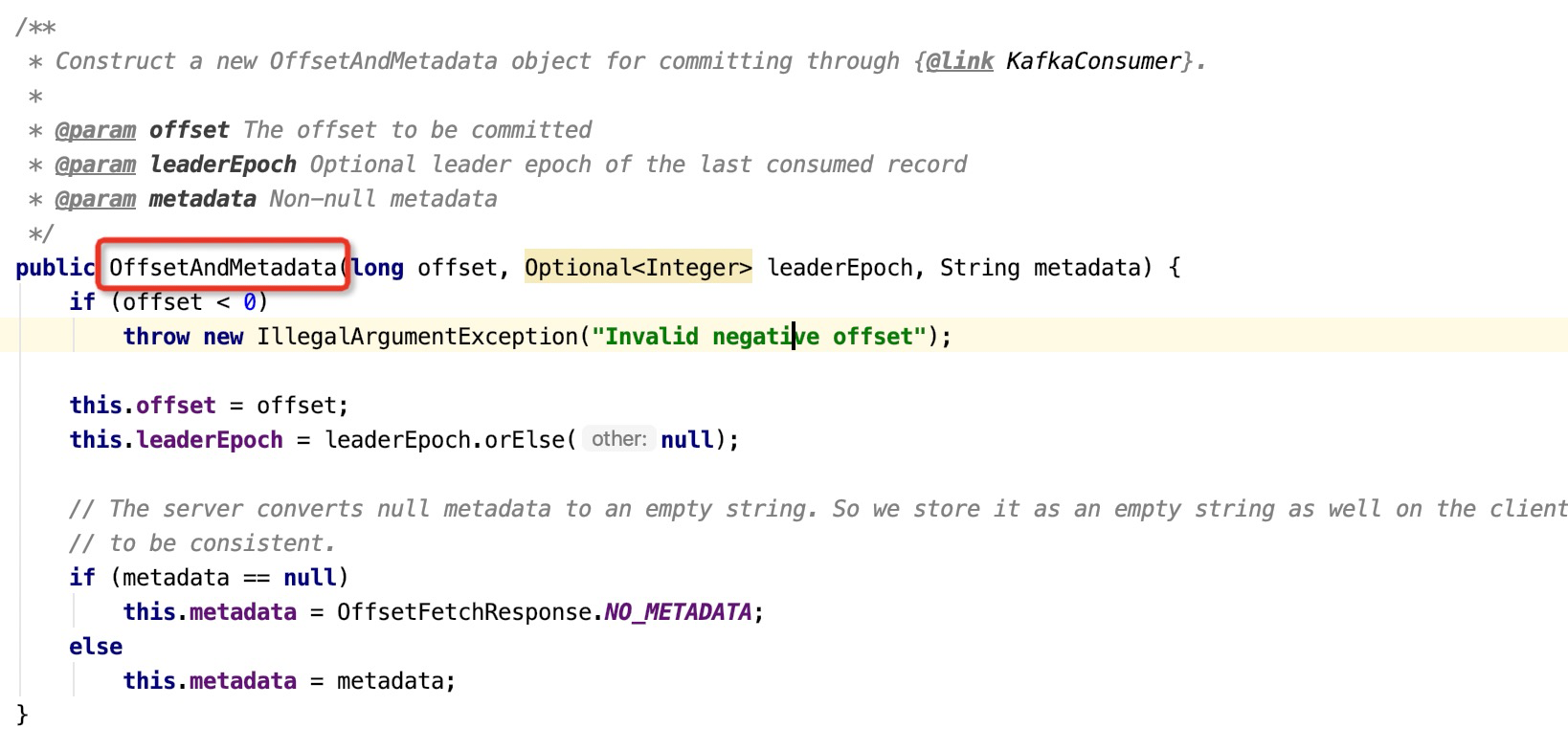
If the incoming site is -1, an exception will be thrown directly, so the client has no chance to submit the site of -1 to the server. Why is the site lost?
In order to explore further, we have to look at how the consumer group obtained the site for the first time, analyze it from the perspective of source code, find key logs, and compare the log files to try to get the solution to the problem.
2.1 Client Site Search Mechanism
In order to explore the client's site acquisition mechanism, the author read in detail the process of the consumer at startup. The specific entry is the poll method of KafkaConsumer. The detailed flow chart is as follows:.png)
The above core points are explained as follows:
- In the poll method message of the consumer (KafkaConsumer), the updateAssignmentMetadataIfNeeded method is called. This method mainly performs metadata-related work such as consumer group initialization, consumer group rebalancing, and acquisition of consumption sites.
- If all the partitions subscribed by the current consumer group (partitions allocated after rebalancing) have sites, return true, indicating that there is no need to update sites.
- If the currently allocated partition does not have the correct location (such as a newly added partition after a rebalance), you need to send a request to the server to find a location, and the server queries the __consumer_offsets topic and returns location information.
- If the location is queried, the DEBUG level log ( Setting offset for partition ) is output, and the location queried from the server is output; if the location is not queried, the DEBUG level log ( Found no committed offset for partition ) is also output.
- If the location is not queried, you need to reset the strategy according to the location configured by the consumer group. Its specific configuration parameters are: auto.offset.reset, and its optional values are:
- latest latest site
- earliest earliest site
- none do not reset the site
- If the reset point is none, a NoOffsetForPartitionException will be thrown.
- If the reset site selects latest or earlyliest, the consumer will start consumption from the queried site and output DEBUG level logs ( Resetting offset for partition XX to offset XXXX. )
Unfortunately, the location search mechanism of consumers and the process log printed by the Kafka client are at DEBUG level, which is basically not output in the production environment, which brings inconvenience to my troubleshooting (finding enough evidence).
Here I have to complain about Kafka's strategy for outputting logs : the change of location is a very critical state change , and the frequency of outputting these logs is not very large, and the log level should be INFO instead of DEBUG.
Kafka's log is Debug, so at that time, no evidence could be found for auxiliary explanation, and we could only find out why the rebalancing was triggered due to the heartbeat timeout.
> Tips: The reason why the heartbeat times out and thus triggers the rebalancing will be explained in detail in the subsequent articles related to failure analysis.
After finding the reason for triggering the rebalancing, perform a stress test in the test environment and reproduce it, and set the client log level to debug to find evidence.
-
Setting offset for partition The location was found at the first query, and it was not -1, nor was it the earliest location.
-
Found no committed offset for partition After repeated rebalancing and repeated querying of the log, the location cannot be correctly queried later, but no location is found (return -1).
-
Resetting offset for partition XX to offset XXXX. The site was reset according to the reset strategy.
From the above log analysis, it can also be clearly concluded that the server has a site for storing consumer groups, otherwise the first log will not appear, and an effective site is successfully found, but only in the subsequent rebalancing process. , when the site needs to be queried many times, it returns -1 instead. Under what circumstances does the server return -1 ?
The entry for the Broker server to process heartbeat packets is the handleOffsetFetchRequest method of kafkaApis, and find the key code for obtaining the location, as shown below:
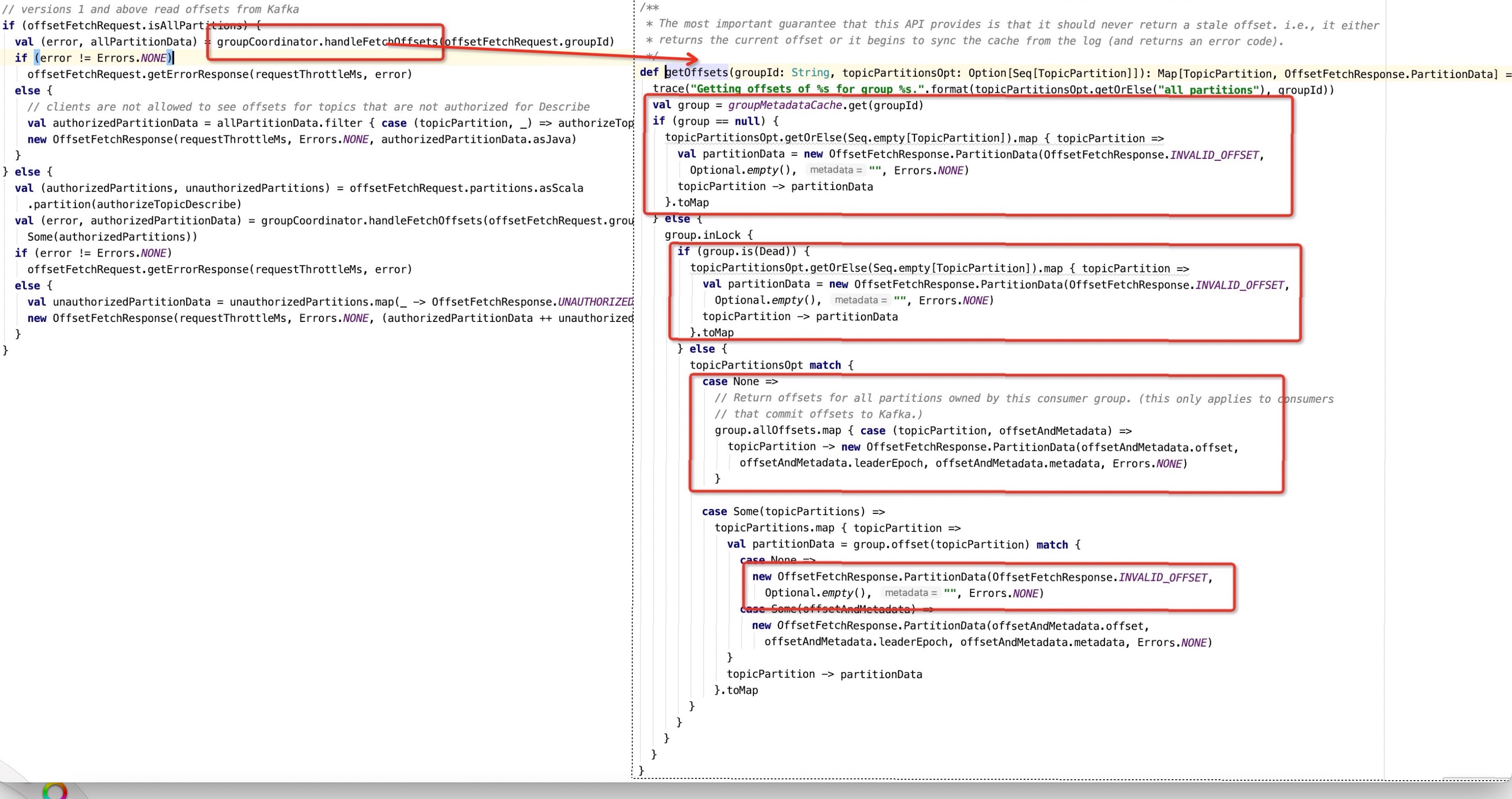
From the above, the server returns INVALID_OFFSET = -1L as follows:
-
If the consumer group does not exist in the cache (memory) of the consumer group meta information manager, it will return -1. Then under what circumstances will the server not have the consumer group meta information in use?
-
The partition of the __consumer_offsets topic has a leader election. After the partition currently owned by the broker is changed to a follower, the meta information of the consumer group corresponding to the partition will be removed. Why is this so? The reason behind this is that the consumer group in Kafka needs to elect a group coordinator on the broker side to coordinate the rebalancing of the consumer group. The election algorithm is to take the name of the consumer group as hashcode, and the obtained value is the number of partitions of the consumer_offsets topic. Take the modulo to get a partition number, and then the broker where the leader node of the partition is located is the group coordinator of the consumer group, so the partition leader changes, and the group coordinator of the associated consumer group needs to be re-elected .
-
Remove the device when the consumer group is deleted.
-
-
The status of the consumer group is GroupState.Dead The status of the consumer group is changed to Dead, usually in the following situations:
- consumer group deleted
- The __consumer_offsets partition leader changes, triggering the reloading of the site. First, change the status of the consumer group to Dead, and then the new site will be loaded on the machine where the new partition leader is located, and then the consumer group will be rebalanced.
-
The server does not store the location information of the consumer group, indicating that the consumer group has not submitted the location
The above situation, for a consumer group that has been running for a long time, will the above situations happen? Looking up the relevant logs of the server, you can clearly see that a large number of __consumer_offsets related partitions have leader elections, which is easy to trigger the first situation above. In this way, the Offset Fetch request initiated by the consumer group may return -1, which will guide the consumer group to reset according to Strategies for site relocation.

Looking at the beginning of the article, the reset strategy set by the consumer group is earliest, and the consumer group's consumption backlog soars from 0 to several hundred million in an instant, which can be explained.
Seeing this, will everyone suddenly get a "cold back"? If the location reset policy (auto.offset.reset) configured by the consumer group is latest, is it easy to cause message loss , that is, part of the consumption is skipped ? Instead of being consumed, the schematic illustration is as follows:
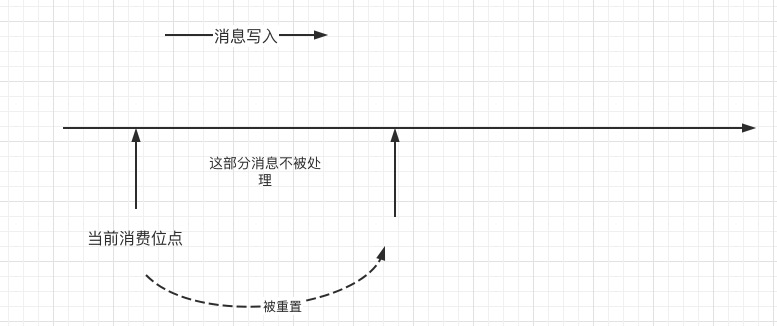
That's all for this article. Regarding why there are a large number of __consumer_offsets in the Kafka cluster for leader election, the follow-up articles will be launched one by one, so please continue to pay attention to me.
3, impression
To be honest, since the programming language used by the Kafka server is scala, the author did not try to read the source code of Kafka, but only analyzed the message sending and message consumption mechanism of Kafka in detail. Problem, but in fact it is the same. I deal with the consultation of the project team with ease, but once there is a problem on the server side, I will still be a bit at a loss. Of course, we have a complete set of emergency plans for cluster problems, but once a problem occurs, although you can Quick recovery, but once a fault occurs, losses are unavoidable. Therefore, we still need to thoroughly study the content we are responsible for, conduct inspections in advance, and avoid faults in advance based on systematic knowledge.
For example, most friends should know that the consumption site of kafka in subsequent versions is stored in the system topic __consumer_offsets, but how many people know that once the leader election occurs in the partition of this topic, it will be accompanied by a lot of consumption All the groups are rebalanced, causing the consumer group to stop consuming?
Therefore, the author will make up his mind to read the relevant source code of the kafka server, understand Kafka systematically, and better control Kafka at work. The column "Kafka Principles and Practice" is on the way. Interested friends can click on the label before the article. pay attention.
Finally, I look forward to your likes. Your likes are also my biggest motivation. See you next time.
Article first published: https://www.codingw.net/posts/6d9026c7.html
Well, this article is introduced here, following, like, and comments are the greatest encouragement to me .
Mastering one or two mainstream Java middleware is a necessary skill to knock on BAT and other big companies. I will give you a Java middleware learning route to help you realize the transformation of the workplace.
Finally, share the author's hard-core RocketMQ e-book, and you will gain the operation and maintenance experience of 100 billion-level message flow.
How to get it: RocketMQ eBook .