
Now we have understood the characteristics and basic operations of TensorFlow (see article: Quickly master TensorFlow (1) ), as well as the operations of TensorFlow computation graphs and sessions (see article: Quickly master TensorFlow (2) ), and we will continue to learn Master TensorFlow.
This article is mainly to learn and master the excitation function of TensorFlow .
1. What is the excitation function?
The excitation function is an essential artifact of all neural network algorithms. By adding the excitation function, the nonlinearity of the tensor calculation can be realized, thereby improving the generalization ability of the neural network model.
The input and output of directly constructing a neural network have a linear relationship, as shown in the figure below.
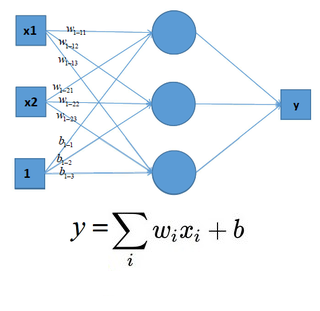
After adding a nonlinear excitation function to the neural network, the neural network has the ability to process nonlinearly and can process nonlinear data, as shown in the figure below
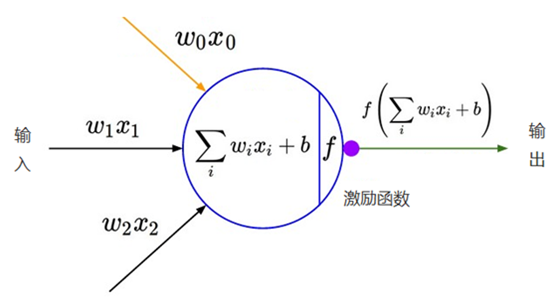
. , the role of the excitation function is to convert multiple linear inputs into nonlinear relationships. If the excitation function is not used, each layer of the neural network is only a linear transformation, even if the multi-layer input is superimposed, it is still a linear transformation. By using the excitation function to introduce nonlinear factors, the representation ability of the neural network is stronger.
Commonly used excitation functions are: ReLU, ReLU6, sigmoid, tanh, softsign, ELU, etc.
If you want to understand the activation function in more detail, please refer to the article: Activation functions commonly used in deep learning
2. How to use
the excitation function It is very convenient to use the excitation function in TensorFlow. The excitation function is located in the neural network library (tensorflow.nn). The following describes how to use it.
(0) Create a session and call the default computational graph
import tensorflow as tf
sess = tf.Session()(1) ReLU function
ReLU (Rectifier linear unit, rectifier linear unit) is the most commonly used excitation function in neural networks. The function is as follows:

The calling method in TensorFlow is as follows:
df=tf.nn.relu([-5., 0., 5., 10.])
print(sess.run(df))The output is:
[0. 0. 5. 10.]
(2) ReLU6 function The
introduction of ReLU6 is mainly to offset the linear growth part of the ReLU function. On the basis of ReLU, min is added. The function is as follows:
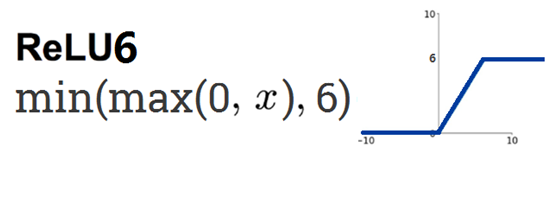
The calling method in TensorFlow is as follows:
df=tf.nn.relu6([-5., 0., 5., 10.])
print(sess.run(df))The output is:
[0. 0. 5. 6.]
(3) Leaky ReLU function
The introduction of Leaky ReLU is mainly to avoid the disappearance of the gradient. When the neuron is in an inactive state, a non-zero gradient is allowed to exist, so that the gradient does not disappear and the convergence speed is fast. The function is as follows:
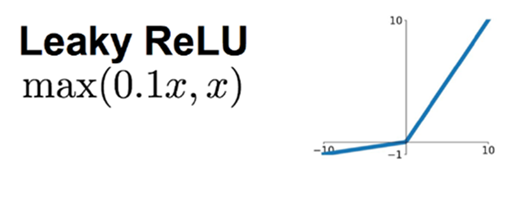
The calling method in TensorFlow is as follows:
df=tf.nn.leaky_relu([-3., 0., 5.])
print(sess.run(df))The output is:
[-0.3 0. 5.]
(4) sigmoid function
The sigmoid function is the most commonly used excitation function in neural networks. It is also called a logic function. It causes the gradient to disappear during the training process of deep learning, so it is not used very much in deep learning. The function is as follows:

The calling method in TensorFlow is as follows:
df=tf.nn.sigmoid([-1., 0., 1.])
print(sess.run(df))The output is:
[0.26894143 0.5 0.7310586]
(5) tanh function
The tanh function is the hyperbolic tangent function. tanh is similar to the sigmoid function, but the value range of tanh is 0 to 1, and the value range of the sigmoid function is -1 to 1. The function is as follows:
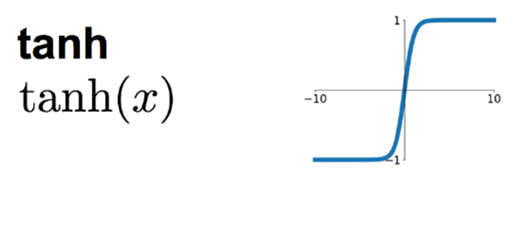
The calling method in TensorFlow is as follows:
df=tf.nn.tanh([-1., 0., 1.])
print(sess.run(df))The output is:
[-0.76159418 0. 0.76159418]
(6) ELU function
The value of ELU in the positive range is x itself, while in the negative range, ELU has the characteristics of soft saturation when the input takes a small value, which improves the robustness to noise. The function is as follows:
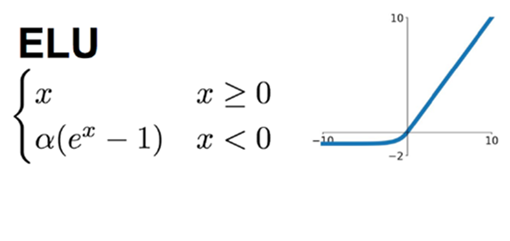
In TensorFlow The calling method in is as follows:
df=tf.nn.elu([-1., 0., 1.])
print(sess.run(df))The output is:
[-0.63212055 0. 1.]
(7) softsign function
The softsign function is a continuous estimation of the sign function and is defined as follows:
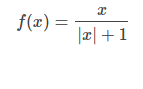
The calling method in TensorFlow is as follows:
df=tf.nn.softsign([-1., 0., 1.])
print(sess.run(df))The output is:
[-0.5 0. 0.5]
(8) softplus function
softplus is a smoothed version of the ReLU excitation function, which is defined as follows:
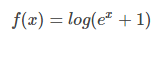
The calling method in TensorFlow is as follows:
df=tf.nn.softplus([-1., 0., 1.])
print(sess.run(df))The output is:
[0.31326166 0.69314718 1.31326163]
So far, we have understood the role of the excitation function, as well as the principle of the commonly used excitation function and the method of calling it in TensorFlow.
In the next series of articles on "Mastering TensorFlow Quickly", there will be more exciting content to explain TensorFlow, so stay tuned.
Welcome to follow my WeChat public account "Big Data and Artificial Intelligence Lab" (BigdataAILab) for more information
Recommended related reading
- [AI combat] Quickly master TensorFlow (1): basic operations
- [AI combat] Quickly master TensorFlow (2): Computational graph, conversation
- [AI combat] Quickly master TensorFlow (3): Incentive function
- [AI combat] Quickly master TensorFlow (4): loss function
- 【AI combat】Build a basic environment
- [AI combat] Training the first model
- 【AI combat】Write a face recognition program
- [AI combat] hands-on training target detection model (SSD)
- [AI combat] hands-on training target detection model (YOLO)
- [Essential finishing] CNN evolution history
- Dahua Convolutional Neural Network (CNN)
- Dahua Recurrent Neural Network (RNN)
- Dahua Deep Residual Network (DRN)
- Dahua Deep Belief Network (DBN)
- Big talk CNN classic model: LeNet
- Big talk CNN classic model: AlexNet
- Big talk CNN classic model: VGGNet
- Big talk CNN classic model: GoogLeNet
- The classic model of big talk target detection: RCNN, Fast RCNN, Faster RCNN
- Classic model of big talk target detection: Mask R-CNN
- 27 classic deep learning models
- A brief introduction to "transfer learning"
- What is "Reinforcement Learning"
- Analysis of the Principle of AlphaGo Algorithm
- How many Vs are there in big data?
- Apache Hadoop 2.8 fully distributed cluster building super detailed tutorial
- Apache Hive 2.1.1 installation and configuration super detailed tutorial
- Apache HBase 1.2.6 fully distributed cluster building super detailed tutorial
- Offline installation of Cloudera Manager 5 and CDH5 (latest version 5.13.0) super detailed tutorial