Summary: When sending a message, when the Broker hangs up, can the message body still be written to the message cache?
This article is shared from HUAWEI CLOUD Community " Illustrating Kafka Producer Message Cache Model ", author: Shi Zhenzhen's grocery store.
Before reading this article, I hope you can think about the following questions, and read the article with questions to get better results.
- When sending a message, when the Broker hangs up, can the message body still be written to the message cache?
- When the message is still stored in the cache, if the Producer client hangs, will the message be lost?
- When the latest Producer Batch still has free memory, but the next message is too large to be added to the previous Batch, what should I do?
- So how much memory should be allocated when creating a Producer Batch?
What is the message accumulator Record Accumulator
In order to improve the sending throughput and performance of the Producer client, Kafka chooses to temporarily cache messages, wait until certain conditions are met, and then send them in batches, which can reduce network requests and improve throughput.
The one that caches this message is the Record Accumulator class.
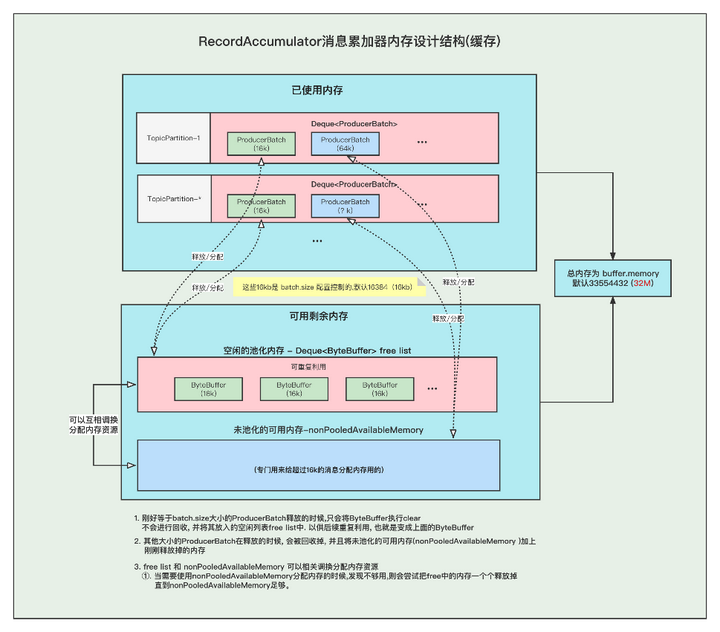
The above picture is the cache model of the entire message storage, we will explain them one by one.
message caching model
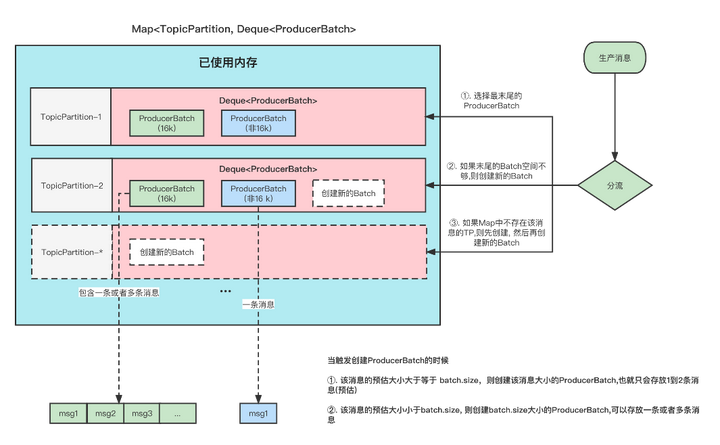
The above figure shows the model of the message cache, and the produced messages are temporarily stored in this.
- For each message, we put them in different Deque<ProducerBatch> queues according to the TopicPartition dimension.
The TopicPartition is the same and will be in the same Deque<ProducerBatch>. - ProducerBatch : Indicates the same batch of messages. When the messages are actually sent to the Broker, they are sent in batches.
This batch may contain one or more messages. - If the ProducerBatch queue corresponding to the message is not found, a queue is created.
- Find the Batch at the end of the ProducerBatch queue, and find that the Batch can also plug this message, then plug the message directly into this Batch
- Find the Batch at the end of the ProducerBatch queue, and find that the remaining memory in the Batch is not enough to hold the message, and a new Batch will be created
- When the message is sent successfully, the Batch will be released.
ProducerBatch memory size
So when creating a ProducerBatch, how much memory should be allocated?
Let's talk about the conclusion first: when the estimated memory of the message is greater than batch.size, it will be created according to the estimated memory of the message, otherwise it will be created according to the size of batch.size (default 16k).
Let's look at a piece of code, this code is to estimate the size of the memory when creating the ProducerBatch
RecordAccumulator#append
/**
* 公众号: 石臻臻的杂货铺
* 微信:szzdzhp001
**/
// 找到 batch.size 和 这条消息在batch中的总内存大小的 最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 申请内存
buffer = free.allocate(size, maxTimeToBlock);- Assuming that a message M is currently produced, and just the message M cannot find a ProducerBatch that can store the message (does not exist or is full), then a new ProducerBatch needs to be created at this time.
- The estimated message size is compared with the batch.size default size of 16384 (16kb). Take the maximum value for the requested memory size.
Original address: Illustrating the Kafka Producer message caching model
So, how is the estimate of this news estimated? Is it purely the size of the message body?
DefaultRecordBatch#estimateBatchSizeUpperBound
The estimated batch size required is an estimated value, because the compression algorithm is not considered from the extra overhead
/**
* 使用给定的键和值获取只有一条记录的批次大小的上限。
* 这只是一个估计,因为它没有考虑使用的压缩算法的额外开销。
**/
static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers);
}
- Estimate the size of this message M + the size of a RECORD_BATCH_OVERHEAD
- RECORD_BATCH_OVERHEAD is some basic meta information in a Batch, occupying a total of 61B
- The size of the message M is not only the size of the message body, the total size = the size of (key, value, headers) + MAX_RECORD_OVERHEAD
- MAX_RECORD_OVERHEAD : The maximum space occupied by a message header, the maximum value is 21B
That is to say, to create a ProducerBatch, at least 83B.
For example, if I send a message "1", the estimated size is 86B, which is the maximum value compared to batch.size (default 16384). Then when applying for memory, take the maximum value of 16384.
memory allocation
We all know that the cache size in the RecordAccumulator is defined at the beginning, controlled by buffer.memory, the default is 33554432 (32M)
When the production speed is greater than the sending speed, the producer write blocking may occur.
Moreover, the frequent creation and release of ProducerBatch will lead to frequent GC. There is a concept of buffer pool in all kafka. This buffer pool will be reused, but the buffer pool can only be used with a fixed (batch.size) size.
PS: The following 16k refers to the default value of batch.size.
Original address: Graphical Kafka Producer message caching model
Batch creation and release
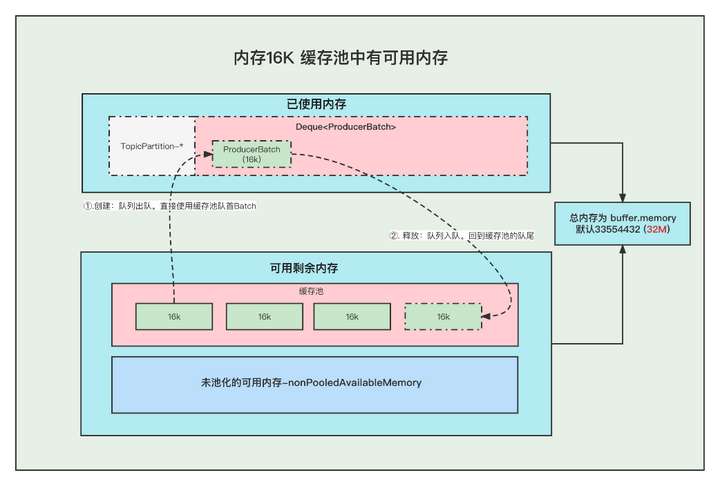
1. There is available memory in the memory 16K buffer pool
①. When creating a Batch, it will go to the buffer pool to obtain a memory ByteBuffer at the head of the team for use.
②. When the message is sent and the Batch is released, the ByteBuffer will be placed in the queue tail of the buffer pool, and ByteBuffer.clear will be called to clear the data. for reuse next time
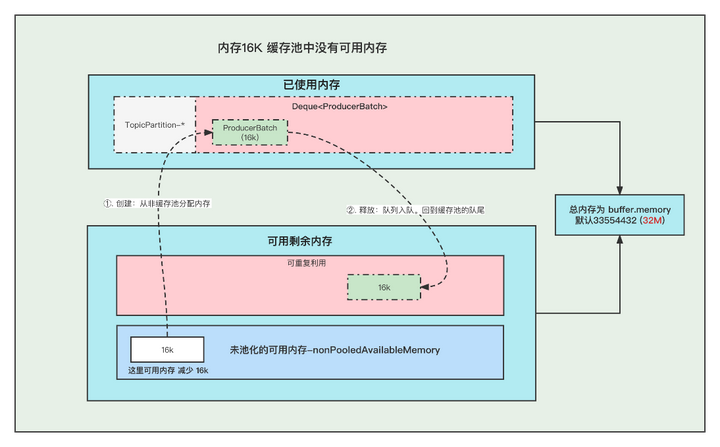
2. There is no free memory in the memory 16K buffer pool
①. When creating a Batch, go to the memory in the non-buffer pool to get a part of the memory for creating the Batch. Note: The acquisition of memory for the Batch here is actually to reduce the memory of the non-buffer pool nonPooledAvailableMemory by 16K, and then the Batch can be created normally. , Do not mistake it as if the transfer of memory really occurred.
②. When the message is sent and the Batch is released, the ByteBuffer will be placed in the queue tail of the buffer pool, and ByteBuffer.clear will be called to clear the data so that it can be reused next time
Original address: Graphical Kafka Producer message caching model
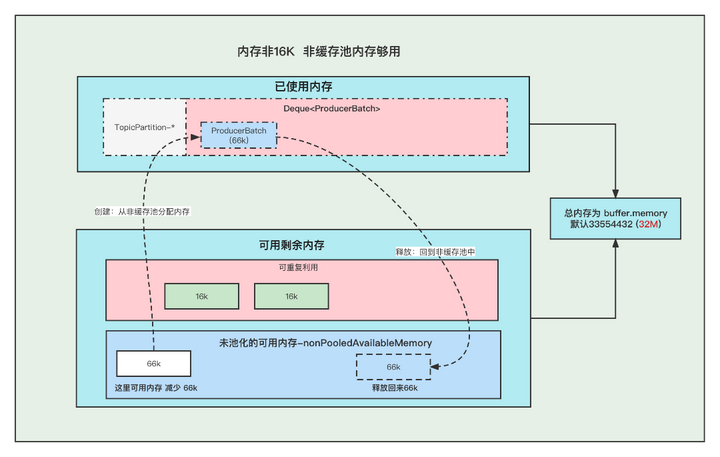
3. The memory is not 16K and the memory in the non-buffer pool is sufficient
①. When creating a Batch, go to the non-buffered pool (nonPooledAvailableMemory) memory to obtain a part of the memory for creating the Batch. Note: The acquisition of memory for the Batch here is actually to reduce the corresponding memory from the non-buffered pool (nonPooledAvailableMemory) , and then the Batch is normal Just create it, don't mistake it as if the memory transfer really happened.
②. After the message is sent, the Batch is released, which is purely by adding the newly released Batch memory size to the non-buffered pool (nonPooledAvailableMemory). Of course, this Batch will be GC'd
4. The memory is not 16K and the non-buffer pool memory is not enough
①. First try to release the memory in the buffer pool to the non-buffer pool one by one, until the memory in the non-buffer pool is enough to create a Batch
②. When creating a Batch, go to the non-buffered pool (nonPooledAvailableMemory) memory to get a part of the memory to create the Batch. Note: The acquisition of memory for the Batch here is actually to reduce the corresponding memory from the non-buffered pool (nonPooledAvailableMemory), and then the Batch is normal Just create it, don't mistake it as if the memory transfer really happened.
③. After the message is sent, the Batch is released, which is purely to add the newly released Batch memory size to the non-buffered pool (nonPooledAvailableMemory). Of course, this Batch will be GC'd
For example: Next, we need to create a batch of 48k, because it exceeds 16k, so we need to allocate memory in the non-buffer pool, but the current available memory in the non-buffer pool is 0, which cannot be allocated. At this time, we will try to release part of the buffer pool. Memory to non-buffered pool.
If the release of the first ByteBuffer (16k) is not enough, continue to release the second one, until after 3 are released, a total of 48k, and find that the memory is enough at this time, and then create a Batch.
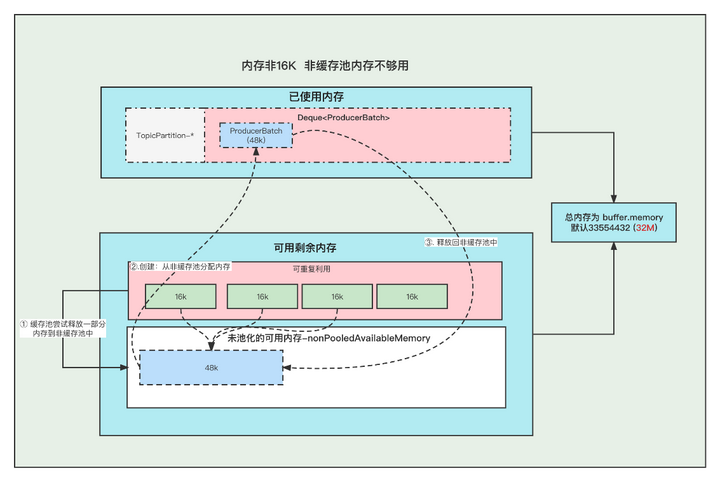
Note: The memory allocations in the non-buffer pool we are referring to here only refer to the increase and decrease of memory numbers.
question and answer
1. When sending a message, when the Broker hangs up, can the message body still be written to the message cache?
When the Broker hangs up, the Producer will prompt the following warning⚠️, but in the process of sending the message
The message body can still be written to the message cache , but only to the cache.
WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available
2. When the latest ProducerBatch still has free memory, but the next message is too large to be added to the previous Batch, what should I do?
Then a new ProducerBatch will be created.
3. When creating a ProducerBatch, how much memory should be allocated?
If the estimated size of the message that triggers the creation of ProducerBatch is greater than batch.size, it will be created with estimated memory.
Otherwise, create with batch.size.
One more question for you to think about:
When the message is still stored in the cache, if the Producer client hangs, will the message be lost?
Click Follow to learn about HUAWEI CLOUD's new technologies for the first time~