1. Gan's thought
What Gan does at its core is to solve an argminmax problem, the formula: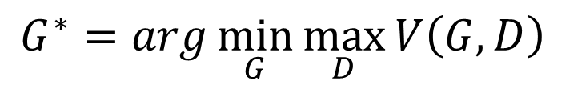
1. Solve a Discriminator, which can measure the distribution distance between the data generated by the Generator and the real data at the largest scale
2. Solve a Generator, which can minimize the distance between the generated data and the real data
The original formula for gan is as follows:
![]()
In fact, we can't really find the expectation, we can only sample the data to approximate the solution, so the formula becomes as follows:

Therefore, finding the maximum value of V becomes a binary classification problem, which becomes the minimum value of cross entropy.
2. Code
public class Gan {
static double lr = 0.01;
public static void main(String[] args) throws Exception {
final NeuralNetConfiguration.Builder builder = new NeuralNetConfiguration.Builder().updater(new Sgd(lr))
.weightInit(WeightInit.XAVIER);
final GraphBuilder graphBuilder = builder.graphBuilder().backpropType(BackpropType.Standard)
.addInputs("input1", "input2")
.addLayer("g1",
new DenseLayer.Builder().nIn(10).nOut(128).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"input1")
.addLayer("g2",
new DenseLayer.Builder().nIn(128).nOut(512).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"g1")
.addLayer("g3",
new DenseLayer.Builder().nIn(512).nOut(28 * 28).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"g2")
.addVertex("stack", new StackVertex(), "input2", "g3")
.addLayer("d1",
new DenseLayer.Builder().nIn(28 * 28).nOut(256).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"stack")
.addLayer("d2",
new DenseLayer.Builder().nIn(256).nOut(128).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"d1")
.addLayer("d3",
new DenseLayer.Builder().nIn(128).nOut(128).activation(Activation.RELU)
.weightInit(WeightInit.XAVIER).build(),
"d2")
.addLayer("out", new OutputLayer.Builder(LossFunctions.LossFunction.XENT).nIn(128).nOut(1)
.activation(Activation.SIGMOID).build(), "d3")
.setOutputs("out");
ComputationGraph net = new ComputationGraph(graphBuilder.build());
net.init();
System.out.println(net.summary());
UIServer uiServer = UIServer.getInstance();
StatsStorage statsStorage = new InMemoryStatsStorage();
uiServer.attach(statsStorage);
net.setListeners(new ScoreIterationListener(100));
net.getLayers();
DataSetIterator train = new MnistDataSetIterator(30, true, 12345);
INDArray labelD = Nd4j.vstack(Nd4j.ones(30, 1), Nd4j.zeros(30, 1));
INDArray labelG = Nd4j.ones(60, 1);
for (int i = 1; i <= 100000; i++) {
if (!train.hasNext()) {
train.reset();
}
INDArray trueExp = train.next().getFeatures();
INDArray z = Nd4j.rand(new long[] { 30, 10 }, new NormalDistribution());
MultiDataSet dataSetD = new org.nd4j.linalg.dataset.MultiDataSet(new INDArray[] { z, trueExp },
new INDArray[] { labelD });
for(int m=0;m<10;m++){
trainD(net, dataSetD);
}
z = Nd4j.rand(new long[] { 30, 10 }, new NormalDistribution());
MultiDataSet dataSetG = new org.nd4j.linalg.dataset.MultiDataSet(new INDArray[] { z, trueExp },
new INDArray[] { labelG });
trainG(net, dataSetG);
if (i % 10000 == 0) {
net.save(new File("E:/gan.zip"), true);
}
}
}
public static void trainD(ComputationGraph net, MultiDataSet dataSet) {
net.setLearningRate("g1", 0);
net.setLearningRate("g2", 0);
net.setLearningRate("g3", 0);
net.setLearningRate("d1", lr);
net.setLearningRate("d2", lr);
net.setLearningRate("d3", lr);
net.setLearningRate("out", lr);
net.fit(dataSet);
}
public static void trainG(ComputationGraph net, MultiDataSet dataSet) {
net.setLearningRate("g1", lr);
net.setLearningRate("g2", lr);
net.setLearningRate("g3", lr);
net.setLearningRate("d1", 0);
net.setLearningRate("d2", 0);
net.setLearningRate("d3", 0);
net.setLearningRate("out", 0);
net.fit(dataSet);
}
}illustrate:
1. dl4j does not provide a method for freezing some layer parameters like keras. Here, the method of setting learningrate to 0 is used to freeze the parameters of some layers
2. This updater uses sgd, and cannot use other (such as Adam, Rmsprop), because these adaptive updaters will consider the gradient of the previous batch as the gradient of this update, which cannot be updated without parameters. Purpose
3. StackVertex is used here to merge tensors along the first dimension, that is, merge real data samples and data samples generated by Generator, and jointly train Discriminator
4. During the training process, update the parameters of the Discriminator several times in order to measure the maximum distance, and then update the Generator once
5. Perform 10w iterations
3. Generator generates handwritten numbers
Load the trained model, randomly take some noise data from NormalDistribution, throw it to the model, and after feedForward, take out the activation value of the last layer of Generator, which is the result we want. The code is as follows:
public class LoadGan {
public static void main(String[] args) throws Exception {
ComputationGraph restored = ComputationGraph.load(new File("E:/gan.zip"), true);
DataSetIterator train = new MnistDataSetIterator(30, true, 12345);
INDArray trueExp = train.next().getFeatures();
Map<String, INDArray> map = restored.feedForward(
new INDArray[] { Nd4j.rand(new long[] { 50, 10 }, new NormalDistribution()), trueExp }, false);
INDArray indArray = map.get("g3");// .reshape(20,28,28);
List<INDArray> list = new ArrayList<>();
for (int j = 0; j < indArray.size(0); j++) {
list.add(indArray.getRow(j));
}
MNISTVisualizer bestVisualizer = new MNISTVisualizer(1, list, "Gan");
bestVisualizer.visualize();
}
public static class MNISTVisualizer {
private double imageScale;
private List<INDArray> digits; // Digits (as row vectors), one per
// INDArray
private String title;
private int gridWidth;
public MNISTVisualizer(double imageScale, List<INDArray> digits, String title) {
this(imageScale, digits, title, 5);
}
public MNISTVisualizer(double imageScale, List<INDArray> digits, String title, int gridWidth) {
this.imageScale = imageScale;
this.digits = digits;
this.title = title;
this.gridWidth = gridWidth;
}
public void visualize() {
JFrame frame = new JFrame();
frame.setTitle(title);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
JPanel panel = new JPanel();
panel.setLayout(new GridLayout(0, gridWidth));
List<JLabel> list = getComponents();
for (JLabel image : list) {
panel.add(image);
}
frame.add(panel);
frame.setVisible(true);
frame.pack();
}
public List<JLabel> getComponents() {
List<JLabel> images = new ArrayList<>();
for (INDArray arr : digits) {
BufferedImage bi = new BufferedImage(28, 28, BufferedImage.TYPE_BYTE_GRAY);
for (int i = 0; i < 784; i++) {
bi.getRaster().setSample(i % 28, i / 28, 0, (int) (255 * arr.getDouble(i)));
}
ImageIcon orig = new ImageIcon(bi);
Image imageScaled = orig.getImage().getScaledInstance((int) (imageScale * 28), (int) (imageScale * 28),
Image.SCALE_DEFAULT);
ImageIcon scaled = new ImageIcon(imageScaled);
images.add(new JLabel(scaled));
}
return images;
}
}
}The actual effect is relatively clear

Happiness comes from sharing.
This blog is original by the author, please indicate the source for reprinting