I. Introduction
For distributed computing based on the MapReduce programming paradigm, in essence, it is the process of computing the intersection, union, difference, aggregation, and sorting of data. The idea of distributed computing divide and conquer allows each node to calculate only part of the data, that is, to process only one shard. If you want to obtain the full amount of data corresponding to a key, you must collect the data of the same key into the same one. Reduce task nodes to process, then the Mapreduce paradigm defines a process called Shuffle to achieve this effect.
2. Purpose of writing this article
This article aims to analyze the Shuffle process of Hadoop and Spark, and compare the differences between the two Shuffle.
3. Shuffle process of Hadoop
Shuffle describes the process of data from the Map side to the Reduce side, which is roughly divided into several processes: sort, spill, merge, copy, and merge sort. The general process is as follows:
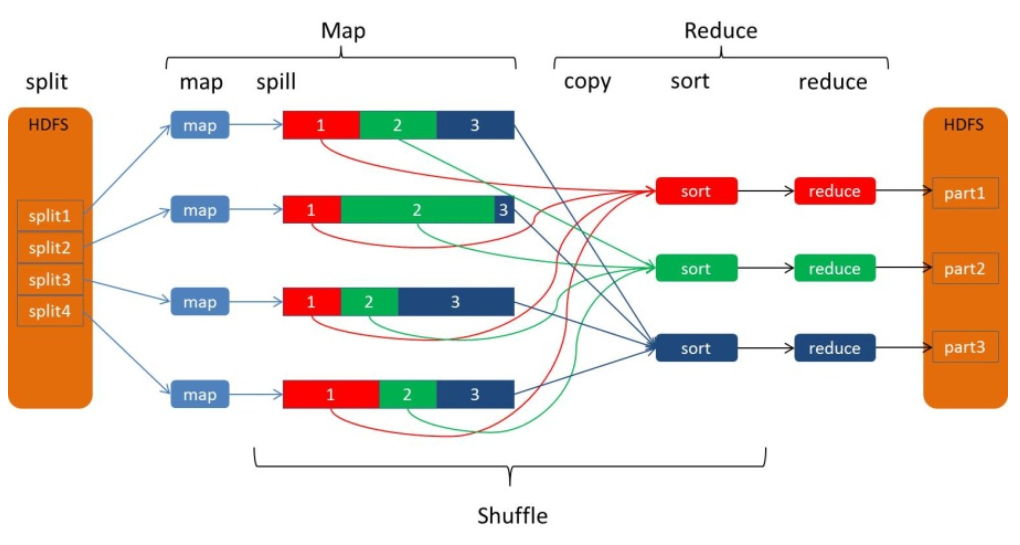
The output file of the Map in the above figure is sharded into three shards of red, green and blue. This shard is sharded according to the key condition. The sharding algorithm can be implemented by itself, such as Hash, Range, etc., and the final Reduce task Only the data of the corresponding color is pulled for processing, and the function of pulling the same Key to the same Reduce node for processing is realized. Let's talk about the various processes of Shuffle separately.
The Map side performs the operations shown in the following figure:
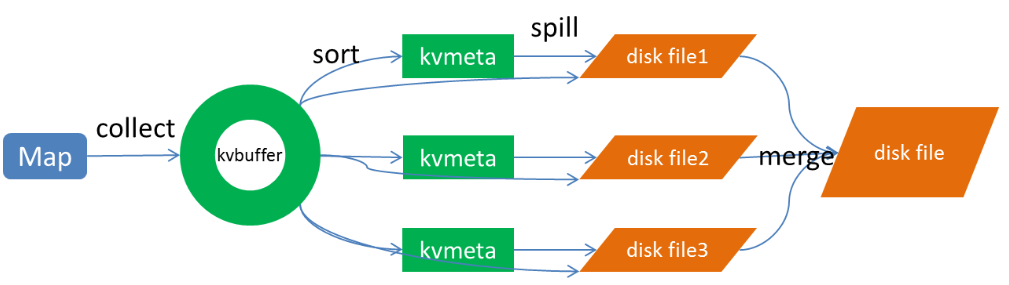
1. Map-side sort
For the output data on the Map side, write the ring buffer kvbuffer first. When the ring buffer reaches a threshold (which can be set through the configuration file, the default is 80), overflow writing will begin, but there will be a sort operation before overflow writing. This sort operation First, sort the data in Kvbuffer according to the partition value and key, and move only the index data. The result of sorting is that the data in Kvmeta are aggregated by partition, and the data in the same partition are sorted by key.
2, spill (overwrite)
When the sorting is completed, the data will be flushed to the disk. The process of flushing the disk is based on the partition. After one partition is written, the next partition is written. The data in the partition is ordered. document
3, merge (merge)
Spill will generate multiple small files, which is quite inefficient for the Reduce side to pull data. Then there is a merge process. The merge process is also merging the same shards into a segment (segment), and finally all the segments. Assembled into a final file, then the merging process is complete, as shown in the following figure
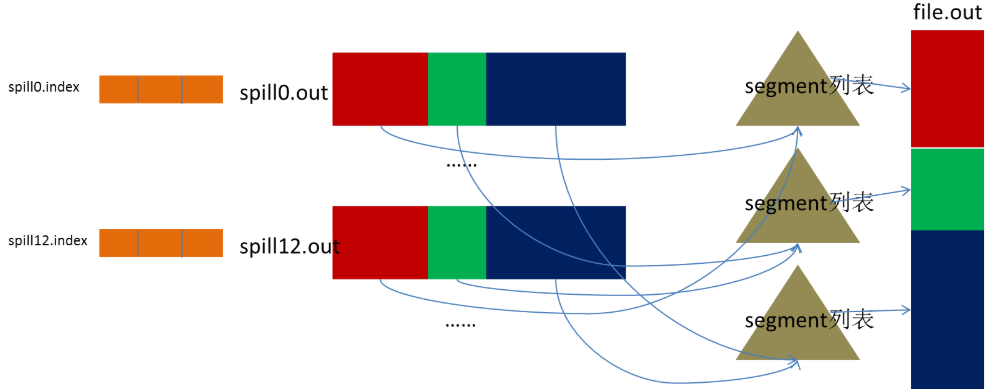
At this point, the Map operation has been completed, and the Reduce side operation is about to debut
Reduce operation
The overall process is shown in the red box in the following figure:
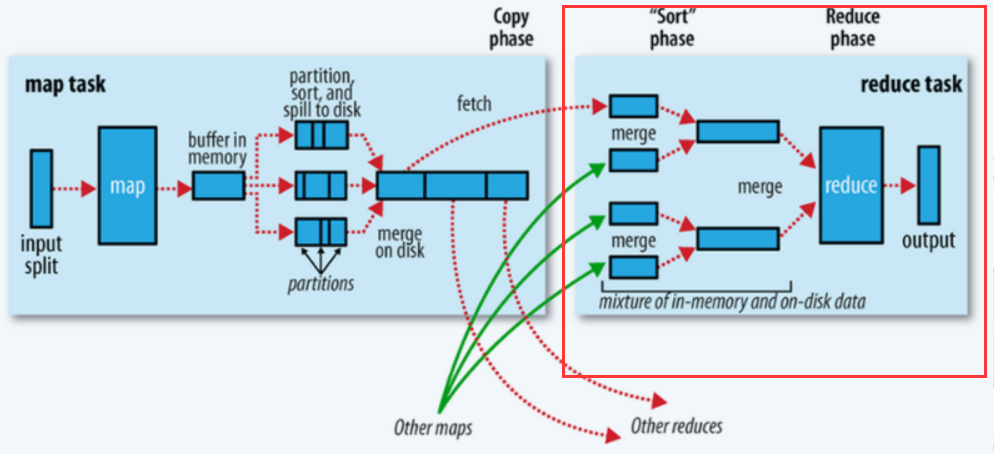
1. fetch copy
The Reduce task pulls the corresponding shards from each Map task. This process is completed by the Http protocol. Each Map node will start a resident HTTP server service, and the Reduce node will request the Http Server to pull data. This process is completely transmitted through the network, so it is a very heavyweight operation.
2. Merge sort
On the Reduce side, after pulling the data of the corresponding shards of each Map node, it will be sorted again, the sorting is completed, and the result will be thrown to the Reduce function for calculation.
4. Summary
At this point, the entire shuffle process is completed, and finally summarize the following points:
1. The shuffle process is for global aggregation of keys
2. The sorting operation is accompanied by the entire shuffle process, so Hadoop's shuffle is sort-based