For more technical exchanges and job hunting opportunities, please pay attention to the WeChat official account of ByteDance Data Platform, and reply [1] to enter the official exchange group
ByteHouse is a cloud-native data warehouse on Volcano Engine, which brings users an extremely fast analysis experience and can support real-time data analysis and massive offline data analysis; convenient elastic expansion and contraction capabilities, extreme analysis performance and rich enterprise-level features , to help customers digital transformation.
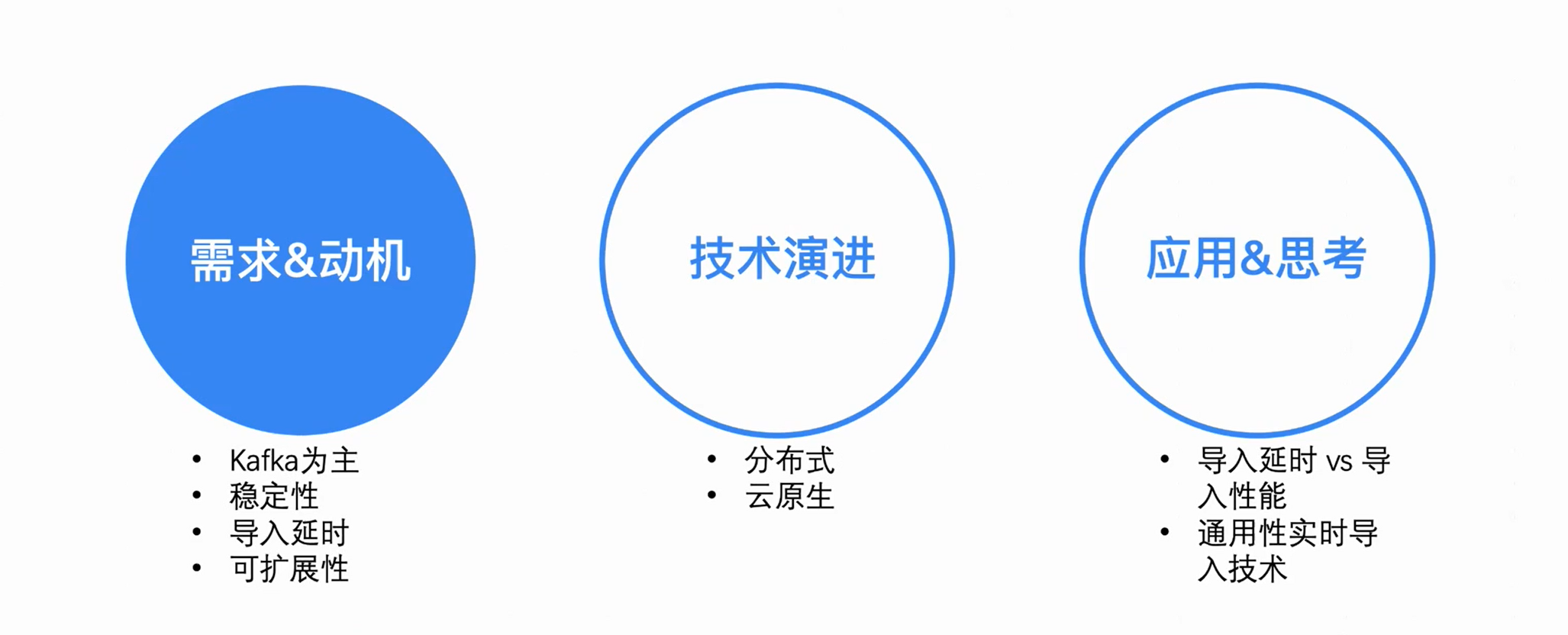
This article will introduce the evolution of ByteHouse real-time import technology based on different architectures from the perspectives of demand motivation, technology implementation and practical application.
Real-time import requirements of internal business
The motivation for the evolution of ByteHouse's real-time import technology originated from the needs of ByteDance's internal business.
Inside Byte, ByteHouse mainly uses Kafka as the main data source for real-time import ( this article uses Kafka import as an example to expand the description, which will not be repeated below ). For most internal users, the data volume is relatively large; therefore, users pay more attention to the performance of data import, the stability of services, and the scalability of import capabilities. As for data latency, most users can meet their needs as long as it is visible in seconds. Based on such a scenario, ByteHouse has carried out customized optimization.
High availability under distributed architecture

Community Native Distributed Architecture
ByteHouse first followed the distributed architecture of the Clickhouse community, but the distributed architecture has some natural architectural defects. These pain points are mainly manifested in three aspects:
-
Node failure: When the number of cluster machines reaches a certain scale, it is necessary to manually handle node failures every week. For single-copy clusters, in some extreme cases, node failure may even lead to data loss.
-
Read-write conflicts: Due to the read-write coupling of the distributed architecture, when the cluster load reaches a certain level, resource conflicts will occur in user queries and real-time imports—especially CPU and IO, imports will be affected, and consumption lag will occur.
-
Expansion cost: Since the data in the distributed architecture is basically stored locally, the data cannot be reshuffled after the expansion. The newly expanded machine has almost no data, and the disk on the old machine may be almost full, resulting in an uneven cluster load. , leading to expansion cannot play an effective effect.
These are the natural pain points of the distributed architecture, but due to its natural concurrency characteristics and the extreme performance optimization of local disk data reading and writing, it can be said that there are advantages and disadvantages.
Community real-time import design
-
High-Level consumption mode: rely on Kafka's own rebalance mechanism for consumption load balancing.
-
two levels of concurrency
The real-time import core design based on distributed architecture is actually two-level concurrency:
A CH cluster usually has multiple shards, and each shard will consume and import concurrently, which is the multi-process concurrency between the first-level shards;
Each shard can also use multiple threads to consume concurrently, so as to achieve high performance throughput.
-
Write in batches
As far as a single thread is concerned, the basic consumption mode is to write in batches—consume a certain amount of data, or write it at once after a certain period of time. Batch writing can better achieve performance optimization, improve query performance, and reduce the pressure on the background Merge thread.
unmet needs
The design and implementation of the above communities still cannot meet some advanced needs of users:
-
First of all, some advanced users have relatively strict requirements on data distribution. For example, they have specific keys for some specific data and hope that the data with the same key will be placed on the same shard (such as unique key requirements). In this case, the consumption model of the community High Level cannot be satisfied.
-
Secondly, the high level consumption form rebalance is uncontrollable, which may eventually lead to uneven distribution of data imported into the Clickhouse cluster among the various shards.
-
Of course, the allocation of consumption tasks is unknown, and in some abnormal consumption scenarios, it becomes very difficult to troubleshoot problems; this is unacceptable for an enterprise-level application.
Self-developed distributed architecture consumption engine HaKafka
In order to solve the above requirements, the ByteHouse team developed a consumption engine based on the distributed architecture - HaKafka.
High availability (Ha)
HaKafka inherits the consumption advantages of the original Kafka table engine in the community, and then focuses on the high-availability Ha optimization.
As far as the distributed architecture is concerned, in fact, there may be multiple copies in each shard, and HaKafka tables can be created on each copy. But ByteHouse will only select a Leader through ZK, let the Leader actually execute the consumption process, and the other nodes are in the Stand by state. When the Leader node is unavailable, ZK can switch the Leader to the Stand by node in seconds to continue consumption, thus achieving a high availability.
Low—Level consumption mode
The consumption mode of HaKafka has been adjusted from High Level to Low Level. The Low Level mode can ensure that Topic Partitions are distributed to each shard in the cluster in an orderly and even manner; at the same time, multi-threading can be used inside the shard again, allowing each thread to consume different Partitions. Thus, it fully inherits the advantages of the two-level concurrency of the community Kafka table engine.
In the Low-Level consumption mode, as long as the upstream users ensure that there is no data skew when writing to the topic, the data imported into Clickhouse through HaKafka must be evenly distributed among the shards.
At the same time, for advanced users who have special data distribution requirements—writing the data of the same Key to the same Shard—as long as the upstream ensures that the data of the same Key is written to the same Partition, then importing ByteHouse can fully meet the user's needs, and it is very easy Well support scenarios such as unique keys.
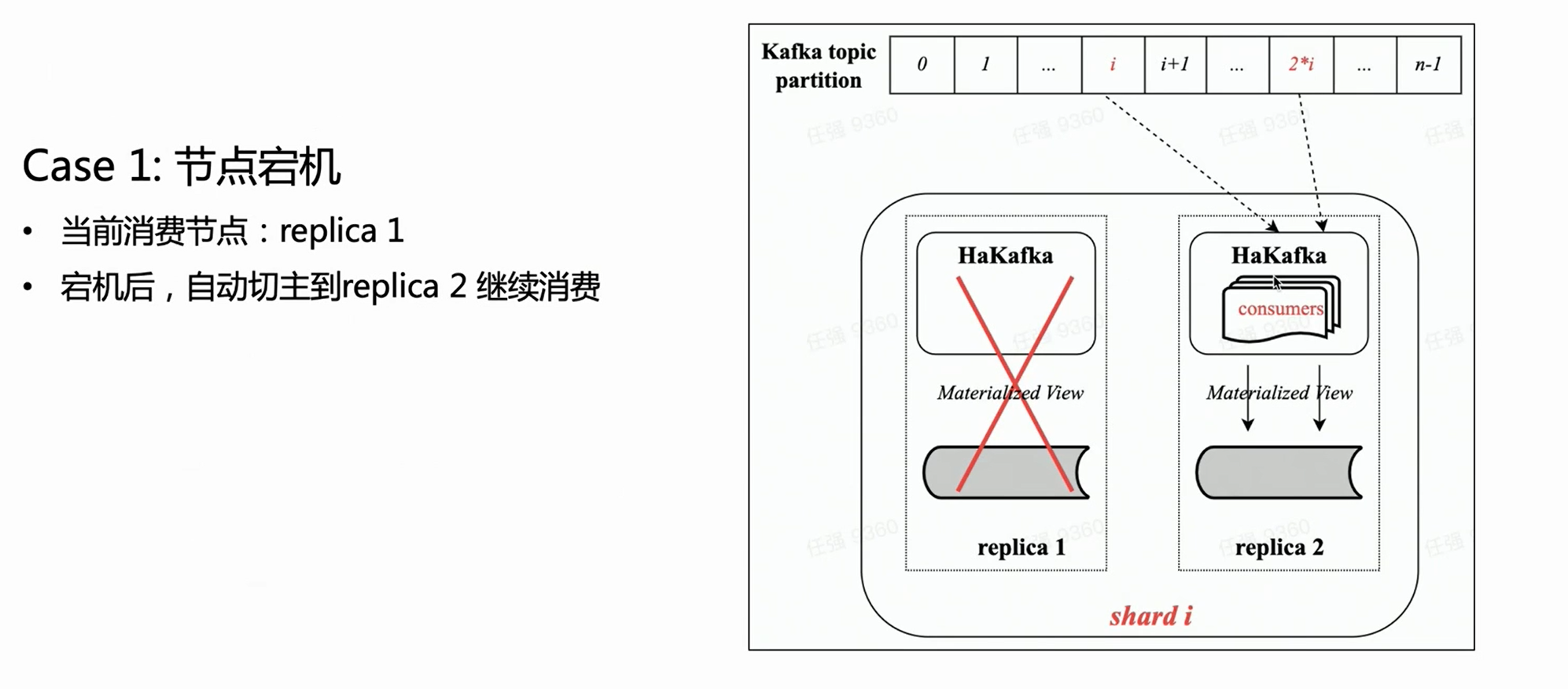
scene one:
Based on the above figure, assuming there is a shard with two copies, each copy will have the same HaKafka table in the Ready state. But only on the leader node that has successfully elected the leader through ZK, HaKafka will execute the corresponding consumption process. When the leader node goes down, the replica Replica 2 will be automatically re-elected as a new leader to continue consumption, thus ensuring high availability.
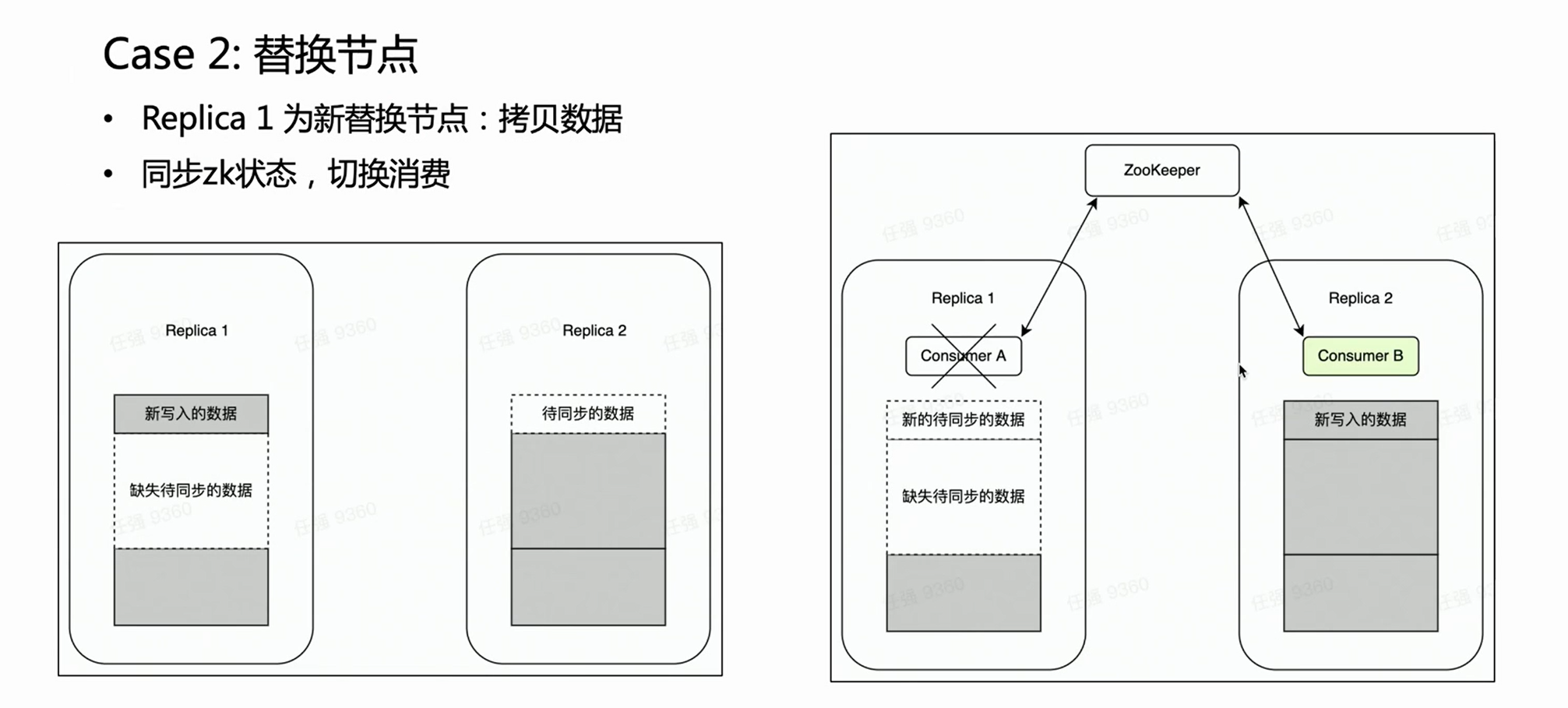
Scene two:
In the case of a node failure, it is generally necessary to perform the process of replacing the node. There is a very heavy operation for distributed node replacement - copying data.
If it is a multi-replica cluster, one copy fails and the other copy is intact. We naturally hope that during the node replacement phase, Kafka consumption is placed on the intact replica Replica 2, because the old data on it is complete. In this way, Replica 2 is always a complete data set and can provide external services normally. HaKafka can guarantee this. When HaKafka elects the leader, if it is determined that a certain node is in the process of replacing the node, it will avoid being selected as the leader.
Import performance optimization: Memory Table
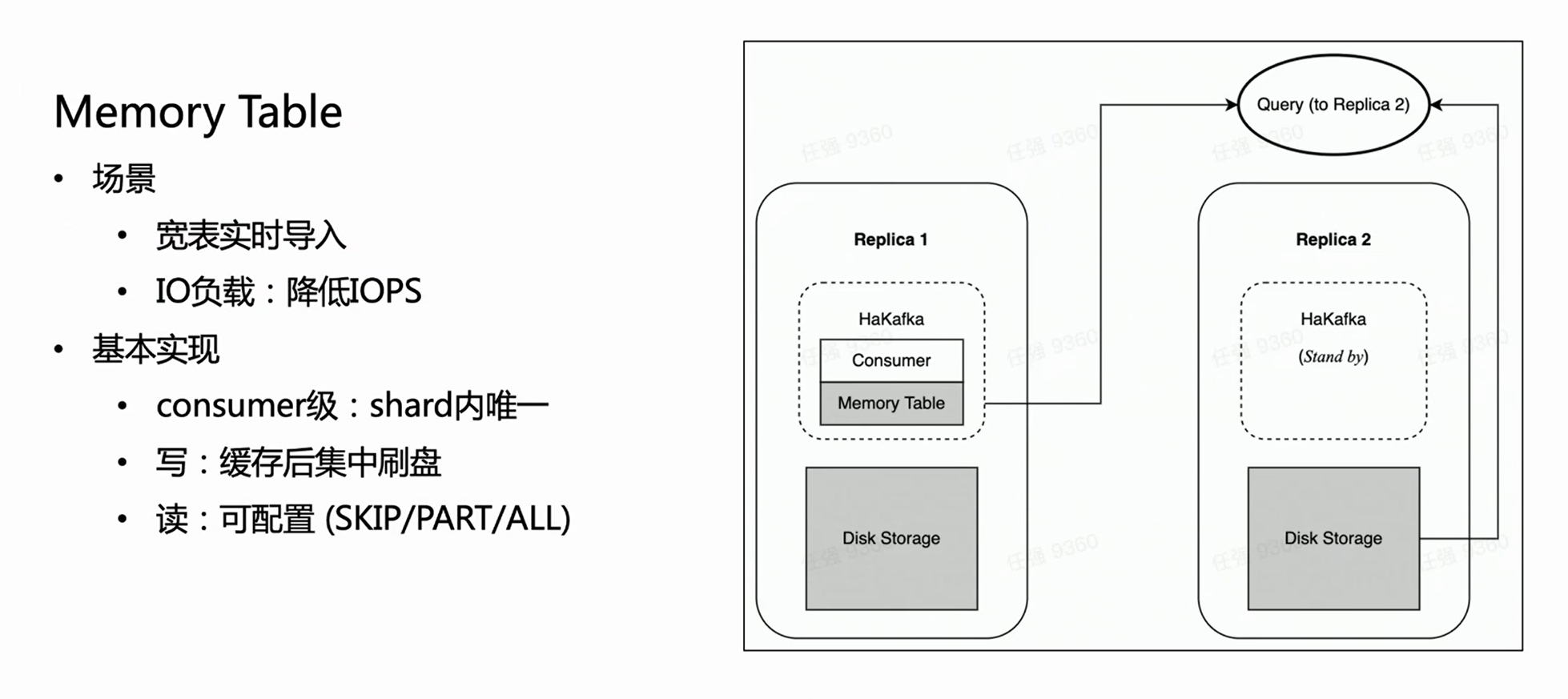
HaKafka also optimizes the Memory Table.
Consider such a scenario: the business has a large and wide table, which may have hundreds of fields or thousands of Map-Keys. Since each column of ClickHouse will correspond to a specific file, the more columns there are, the more files will be written for each import. Then, within the same consumption time, a lot of fragmented files will be written frequently, which is a heavy burden on the IO of the machine, and at the same time puts a lot of pressure on MERGE; in severe cases, it may even cause the cluster to be unavailable. In order to solve this scenario, we designed Memory Table to optimize import performance.
The method of Memory Table is that each time the imported data is not directly flashed, but stored in the memory; when the data reaches a certain amount, it is then concentrated on the disk to reduce IO operations. Memory Table can provide external query service, and the query will be routed to the copy where the consumer node is located to read the data in the memory table, which ensures that the delay of data import is not affected. From the internal experience, Memory Table not only satisfies some business import requirements of large and wide tables, but also improves the import performance by up to 3 times.
Cloud Native New Architecture
In view of the natural flaws of the distributed architecture described above, the ByteHouse team has been working on upgrading the architecture. We have chosen the cloud-native architecture that is the mainstream of the business. The new architecture will start serving Byte’s internal business in early 2021, and open source the code ( ByConity ) in early 2023.
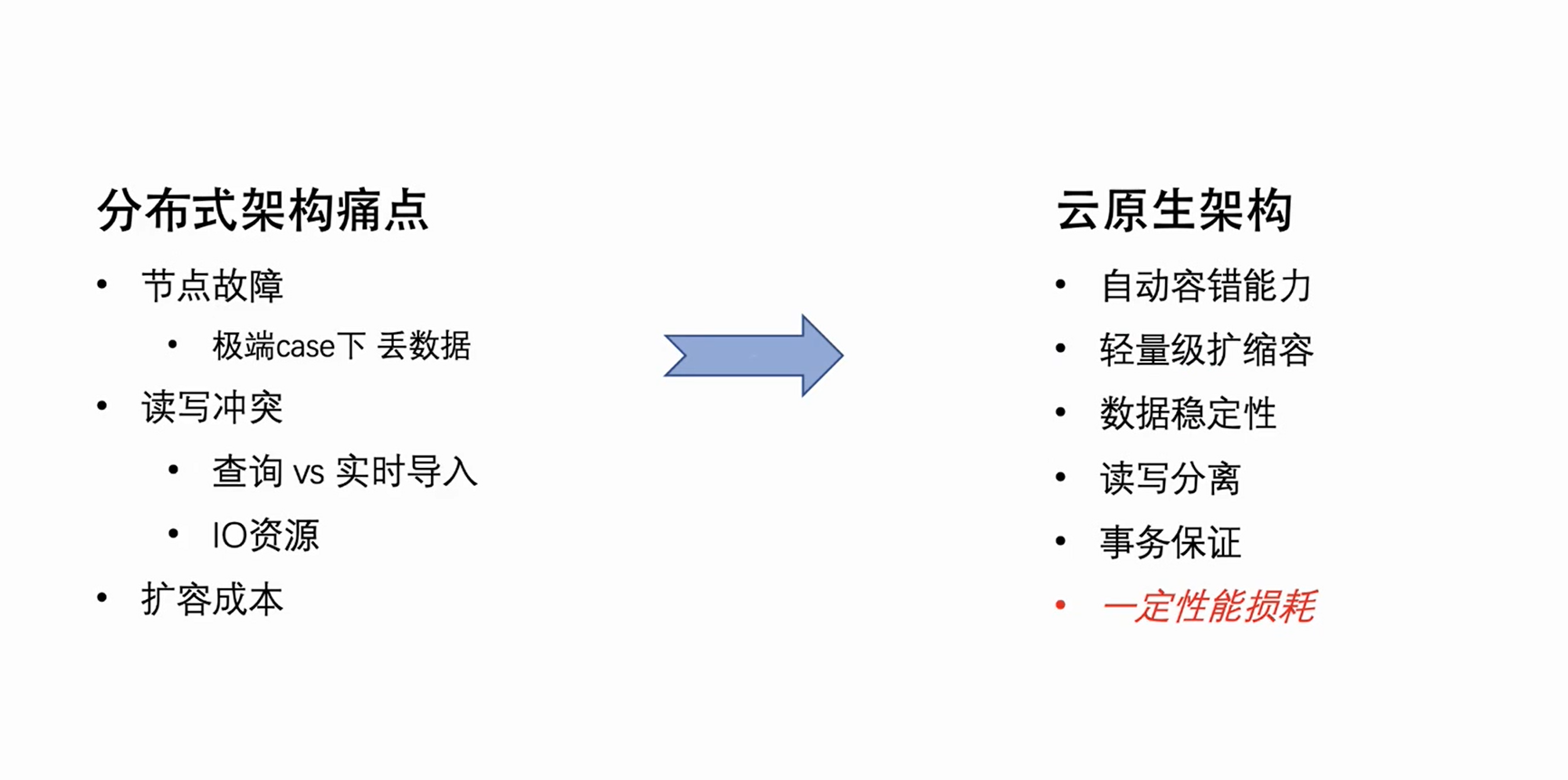
The cloud-native architecture itself has natural automatic fault tolerance and lightweight scaling capabilities. At the same time, because its data is stored in the cloud, it not only realizes the separation of storage and computing, but also improves the security and stability of data. Of course, the cloud-native architecture is not without its shortcomings. Changing the original local read and write to remote read and write will inevitably bring about a certain loss in read and write performance. However, exchanging a certain performance loss for the rationality of the architecture and reducing the cost of operation and maintenance actually outweigh the disadvantages.
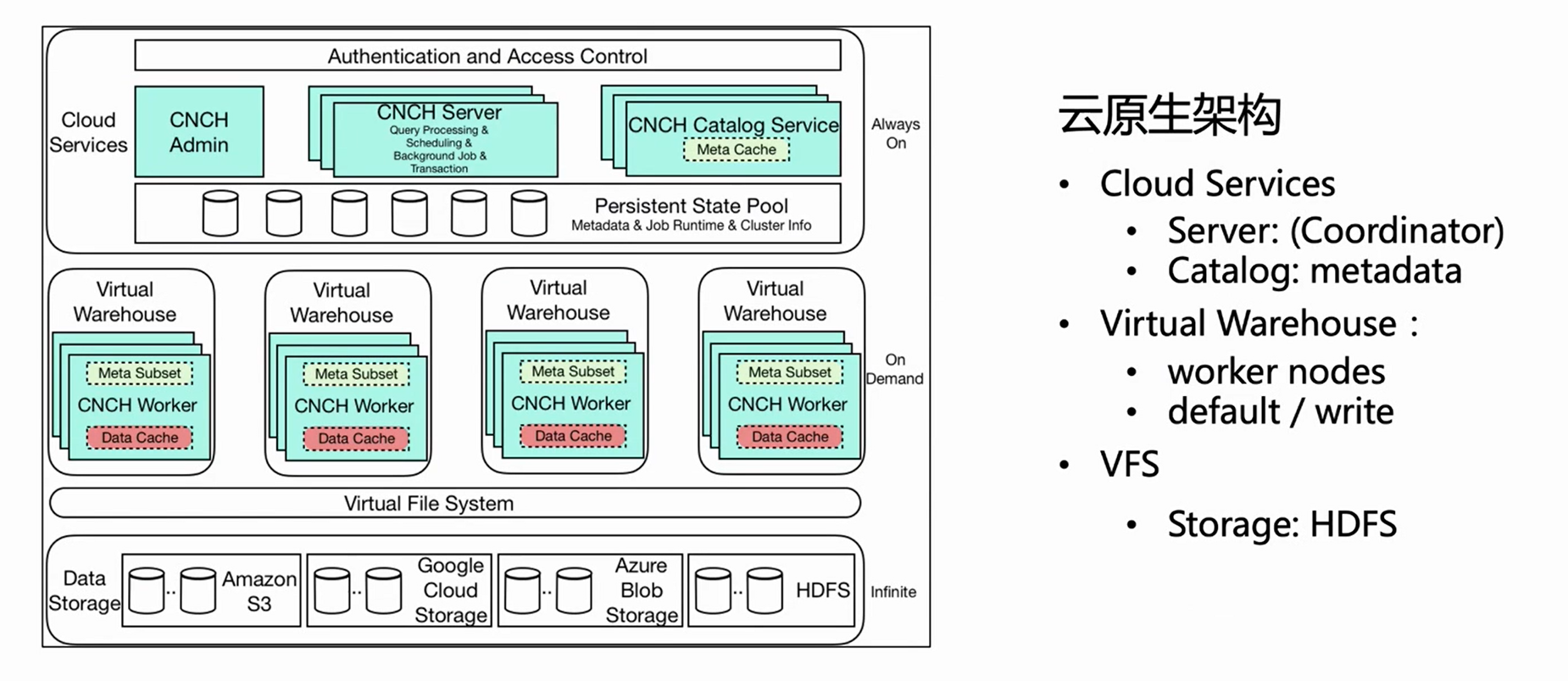
The above picture is the architecture diagram of ByteHouse cloud-native architecture. This article introduces several important related components for real-time import.
-
Cloud Service
First of all, the overall architecture is divided into three layers. The first layer is Cloud Service, which mainly includes two components, Server and Catlog. This layer is the service entrance, and all user requests, including query imports, enter from the server. The server only preprocesses the request, but does not execute it; after the Catlog queries the meta information, it sends the preprocessed request and meta information to the Virtual Warehouse for execution.
-
Virtual Warehouse
Virtual Warehouse is the execution layer. Different businesses can have independent Virtual Warehouses to achieve resource isolation. Now Virtual Warehouse is mainly divided into two categories, one is Default, and the other is Write. Default is mainly used for query, and Write is used for import to realize the separation of reading and writing.
-
VFS
The bottom layer is VFS (data storage), which supports cloud storage components such as HDFS, S3, and aws.
Real-time import design based on cloud native architecture
Under the cloud-native architecture, the server does not perform specific import execution, but only manages tasks. Therefore, on the server side, each consumption table will have a Manager to manage all consumption execution tasks and schedule them to be executed on the Virtual Warehouse.
Because it inherits HaKafka's Low Level consumption mode, the Manager will evenly distribute Topic Partitions to each task according to the configured number of consumption tasks; the number of consumption tasks is configurable, and the upper limit is the number of Topic Partitions.
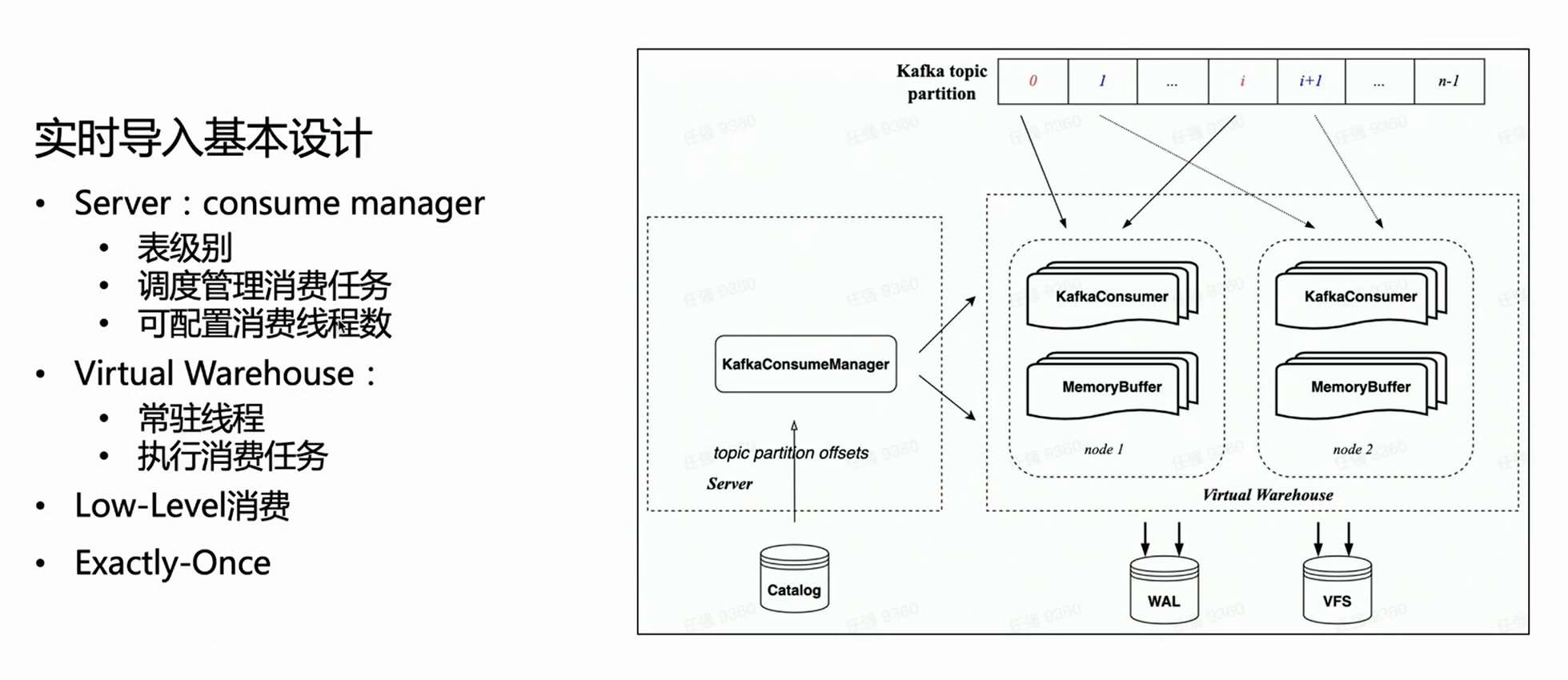
Based on the above figure, you can see that the Manager on the left gets the corresponding Offset from the catalog, and then allocates the corresponding consumption Partition according to the specified number of consumption tasks, and schedules them to different nodes of the Virtual Warehouse for execution.
New Consumption Execution Process
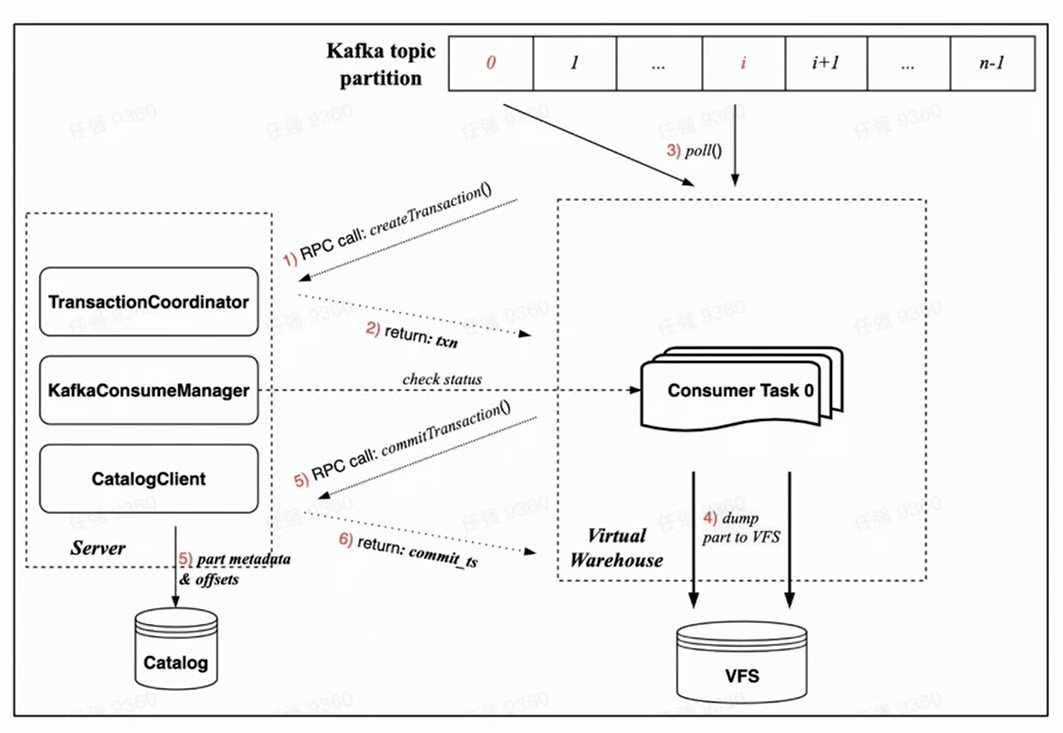
Because the new cloud-native architecture is guaranteed by Transaction, all operations are expected to be completed within one transaction, which is more rational.
Relying on the implementation of Transaction under the new cloud-native architecture, the consumption process of each consumption task mainly includes the following steps:
-
Before consumption starts, the task on the Worker side will first request the Server side to create a transaction through an RPC request;
-
Execute rdkafka::poll() to consume a certain amount of time (8s by default) or a block of sufficient size;
-
Convert block to Part and dump to VFS ( the data is not visible at this time );
-
Initiate a transaction Commit request to Server through RPC request
(Commit data in the transaction includes: dump completed part metadata and corresponding Kafka offset)
-
The transaction is committed successfully ( data is visible )
fault tolerance guarantee
From the above consumption process, we can see that the fault-tolerant guarantee of consumption under the new cloud-native architecture is mainly based on the two-way heartbeat of Manager and Task and the fast-failure strategy:
-
The Manager itself will have a regular probing, and check whether the scheduled Task is being executed normally through RPC;
-
At the same time, each Task will use the transaction RPC request to verify its validity during consumption. Once the verification fails, it can be automatically killed;
-
Once the manager fails to detect liveness, it will immediately start a new consumption task to achieve second-level fault tolerance guarantee.
Spending power
As for the consumption capacity, it is mentioned above that it is scalable, and the number of consumption tasks can be configured by the user, up to the number of Partitions of the Topic. If the node load in the Virtual Warehouse is high, the node can also be expanded very lightly.
Of course, the Manager scheduling task implements the basic load balancing guarantee - use Resource Manager to manage and schedule tasks.
Semantic Enhancement: Exactly—Once
Finally, the consumption semantics under the new cloud-native architecture has also been enhanced—from the At-Least-Once of the distributed book architecture to Exactly-Once.
Because the distributed architecture has no transactions, it can only achieve an At-Least-Once, which means that no data will be lost under any circumstances, but in some extreme cases, repeated consumption may occur. In the cloud-native architecture, thanks to the implementation of Transaction, each consumption can make Part and Offset atomically committed through transactions, so as to achieve the semantic enhancement of Exactly-Once.
Memory buffer
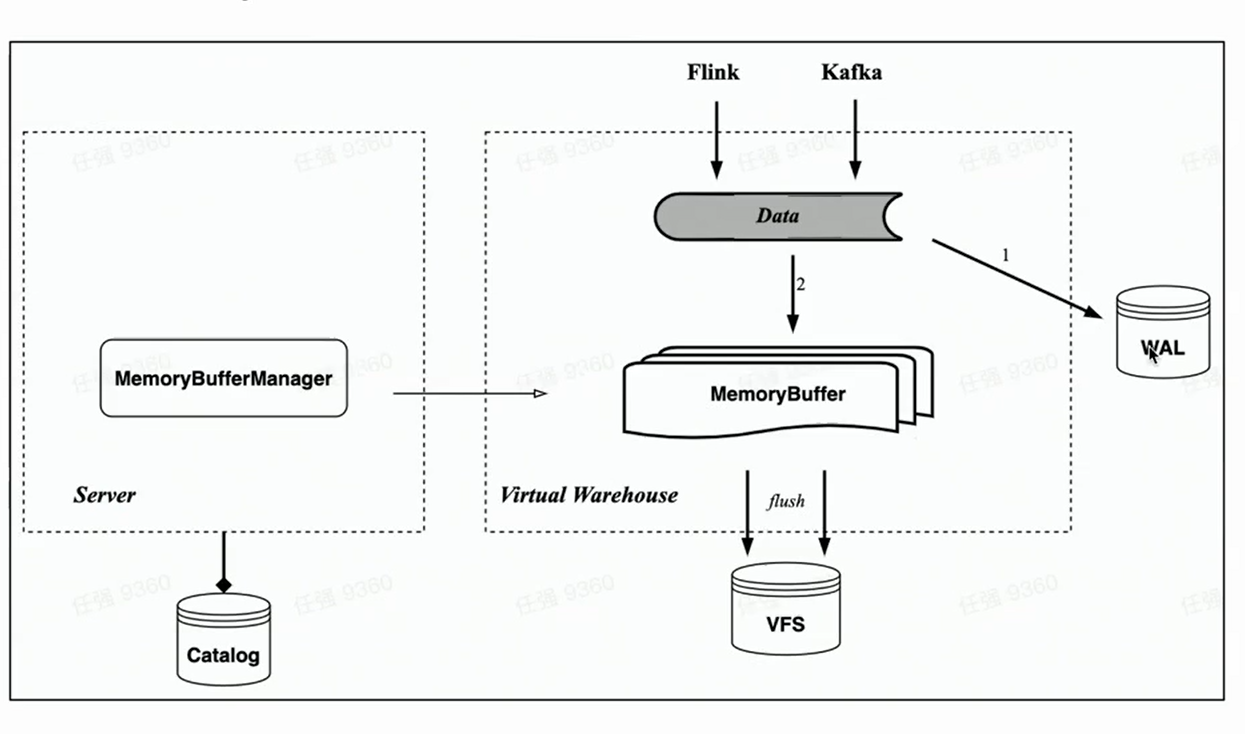
Corresponding to HaKafka's memory table, the cloud native architecture also implements the import of memory cache Memory Buffer.
Unlike Memory Table, Memory Buffer is no longer bound to Kafka's consumption tasks, but is implemented as a layer of cache for storage tables. In this way, Memory Buffer is more versatile. It can be used not only for Kafka import, but also for small batch import like Flink.
At the same time, we introduced a new component WAL. When data is imported, first write WAL, as long as the writing is successful, it can be considered that the data import is successful - when the service is started, you can first restore the data that has not been flashed from the WAL; then write the Memory buffer, and the data will be visible after the successful writing ——Because Memory Buffer can be queried by users. The data of the Memory Buffer is also periodically flushed, and can be cleared from the WAL after flushing.
Business application and future thinking
Finally, it briefly introduces the current status of real-time import in Byte, and the possible optimization direction of the next-generation real-time import technology.
ByteHouse's real-time import technology is based on Kafka, the daily data throughput is at the PB level, and the experience value of imported single thread or single consumer throughput is 10-20MiB/s. (The empirical value is emphasized here, because this value is not a fixed value, nor is it a peak value; consumption throughput largely depends on the complexity of the user table, as the number of table columns increases, the import performance may be significantly reduced, An accurate calculation formula cannot be used. Therefore, the experience value here is more the import performance experience value of most tables inside the byte.)
In addition to Kafka, Byte actually supports real-time import of some other data sources, including RocketMQ, Pulsar, MySQL (MaterializedMySQL), Flink direct writing, etc.
Simple thoughts on the next generation of real-time import technology:
-
A more general real-time import technology enables users to support more import data sources.
-
Data visibility is a tradeoff between latency and performance.
Click to jump to ByteHouse cloud native data warehouse to learn more