
Author | ANTI
guide
As the confrontation between anti-cheating and cheating black products becomes more and more fierce, and cheating methods are changing with each passing day, we are also constantly trying new methods to solve new cheating problems. This paper mainly introduces the application of graph algorithm to solve the problem of community type cheating in the event scenario. The graph model can not only integrate the topological structure of the graph and the characteristics of the nodes for learning at the same time, but also as a semi-supervised model, it can make better use of unlabeled data and improve the recall effect. Both the GCN graph model and SCGCN (multi-graph concatenation model) mentioned in the article have achieved good results in cheating recall.
The full text is 4102 words, and the expected reading time is 11 minutes.
01 Introduction
Operational activities are an important means for enterprises to ensure user growth and retention, and are also one of the core competitiveness of enterprises. Its main forms include attracting new users and promoting activation. Acquiring new users is to acquire new users by inviting new users from old users to increase the user resource pool; promoting activation is to increase DAU and increase user stickiness by doing tasks. For example, we usually participate in the activity of doing tasks and receiving red envelopes on an APP, which is one of the specific forms of operation activities. By combining their own product characteristics to carry out operational activities, enterprises can achieve the purpose of improving user retention and conversion rates, thereby increasing corporate income and influence. There are also various activities on the Baidu APP, such as "invite friends to receive red envelopes", "do tasks to receive red envelopes", etc. However, there will be a large number of cheaters (such as Internet hackers) in the event to obtain illegitimate benefits through cheating, which will affect the marketing effect of the event. At this time, the anti-cheating system needs to identify black products through multi-dimensional information such as user portraits, user behaviors, and device information, so as to escort the company's operating activities. In recent years, with the continuous offensive and defensive confrontation between anti-cheating and black industry, the cheating methods of black industry have also been iteratively upgraded, from large-scale computer-based cheating to crowdsourcing cheating, and even small-scale real-person cheating, which makes anti-cheating The difficulty of cheating and cheating identification is also increasing. Therefore, we need to constantly iterate new methods to identify and block black products.
02 Difficulty
In operational activities, take the activity of attracting newcomers as an example. In activities of pulling new types, once the invitation occurs, a relationship between users will be automatically established, here we call it a "master-student relationship" (the inviter is regarded as "master", and the invitee is regarded as "apprentice"). For example, Pic.3 is a user relationship diagram generated through the "invite new" operation. We call the upper-level characters the "master" of the lower-level characters, and the lower-level characters as the "apprentices" of the upper-level characters. In the picture, the master can recruit multiple apprentices, and at the same time, he will receive corresponding rewards. Usually, the more apprentices, the more rewards.


△Pic.1 Friends invitation activity, Pic.2 National Day activity
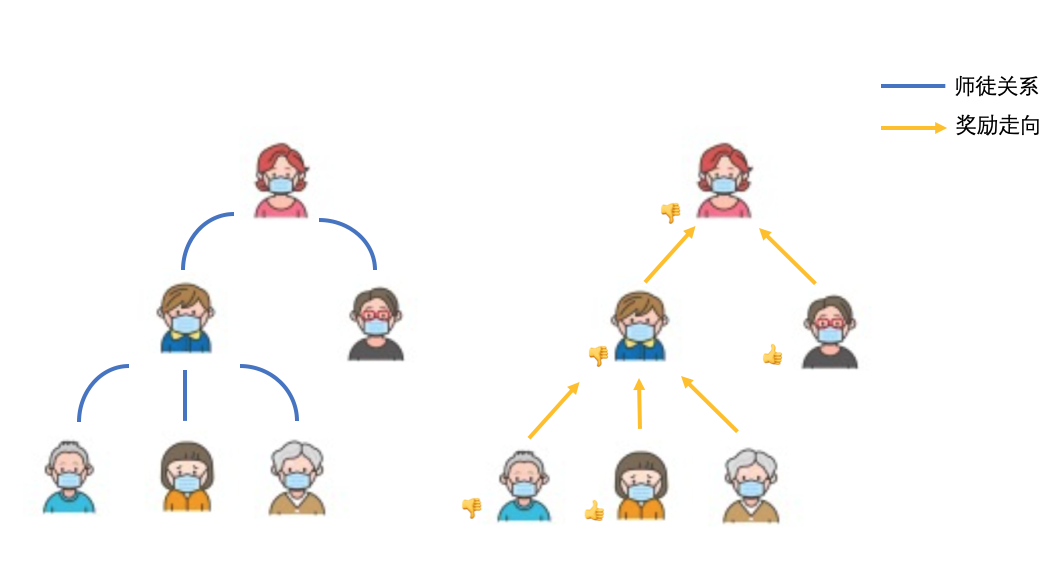
△Pic.3 Description of the relationship between the invited event characters
At present, anti-cheating modeling in pulling new scenarios faces the following two problems:
1. Lack of ability to describe contact information between users : The current application model of the activity anti-cheating business includes tree model, DNN and machine learning model. If we regard users as nodes, we will find that the learning and training of these models pay more attention to the characteristics of the nodes themselves, but lack the ability to learn the characteristics of the relationship between nodes. In several recent cheating attacks, it was found that the "community" is a form of cheating with a large-scale attack as the basic unit. They have obvious sharing in behavior and equipment information, and there is a strong correlation between information among cheaters. We There is a need for better models to learn this "association" capability.
2. Low sample purity leads to limited recall : Generally, black samples are obtained through manual sampling evaluation and customer complaint feedback enrichment, while white samples are obtained by random sampling in a certain proportion. However, there is a problem that is not easy to solve in this way, that is, these white samples may be mixed with unknown cheating data, which will reduce the purity of the white samples and affect the training effect of the supervised model.
Below we introduce the graph model algorithm that can effectively solve the above two problems.
03 Graph Algorithm Application
In order to solve the two business problems raised above, the graph neural network model is selected for business modeling. The advantage of the graph model is that it can integrate the topological structure of the graph and the characteristics of the nodes to learn at the same time. It can not only connect information through the edge relationship established between nodes, supplement the model's ability to learn edge relationships, thereby expanding the recall, but also As a semi-supervised model, the graph model can make better use of unlabeled data and improve the recall effect.
3.1 Introduction to Graphical Models
The currently commonly used graph neural network models can be divided into two categories: one is based on graph walk methods, such as random-walk walk models; the other is based on graph convolution methods, such as GCN, GAT and GraphSAGE Isograph Convolutional Neural Network Model. From the perspective of the whole graph, GCN breaks through the barriers between the original graph structure and the neural network, but the huge amount of calculation based on the whole graph makes it encounter bottlenecks in large-scale scene applications, while GraphSAGE from the perspective of local graphs can solve this problem to some extent. Another commonly used graph model, GAT, has added an attention mechanism. More model parameters not only enhance the learning ability, but also increase the time and space complexity, which makes model training require more sufficient sample information and computing resources. In real business scenarios, since the sample size is controllable, the GCN graph algorithm is directly selected for training. The following briefly introduces the principle of GCN.
GCN is a multi-layer graph convolutional neural network. Each convolutional layer only processes first-order neighborhood information. By stacking several convolutional layers, information transmission in multi-order neighborhoods can be achieved.
The propagation rules of each convolutional layer are as follows [1]:
\(H^{(l+1)}=σ(\tilde{D}^{-{\frac 1 2}}\tilde{A}\tilde{D}^{-{\frac 1 2}}H ^{(l)}W^{(l)})\)
in
- \(\tilde{A}=A+I_{N} \) is the adjacency matrix of the undirected graph \(G\) plus self-connection (that is, each vertex and itself plus an edge), \(I_{N} \) is the identity matrix.
- \(\tilde{D}\) is the degree matrix of \(\tilde{A} \) , that is , \(\tilde{D}{ii}=\sum_j\tilde{A}{ij}\)
- \(H^{(l)}\) is the activation unit matrix of the \(I\) layer, \( H^0=X\)
- \(W^{(l)}\) is the parameter matrix of each layer
The adjacency matrix \(A\) transmits the information of the neighbors of the node, and the identity matrix \(I_{N}\) represents the transmission of the node's own information. Because of this, the GCN model can learn both the characteristics of the node itself and the Its associated information with other nodes, and the information of itself and neighboring nodes are aggregated for training and learning.
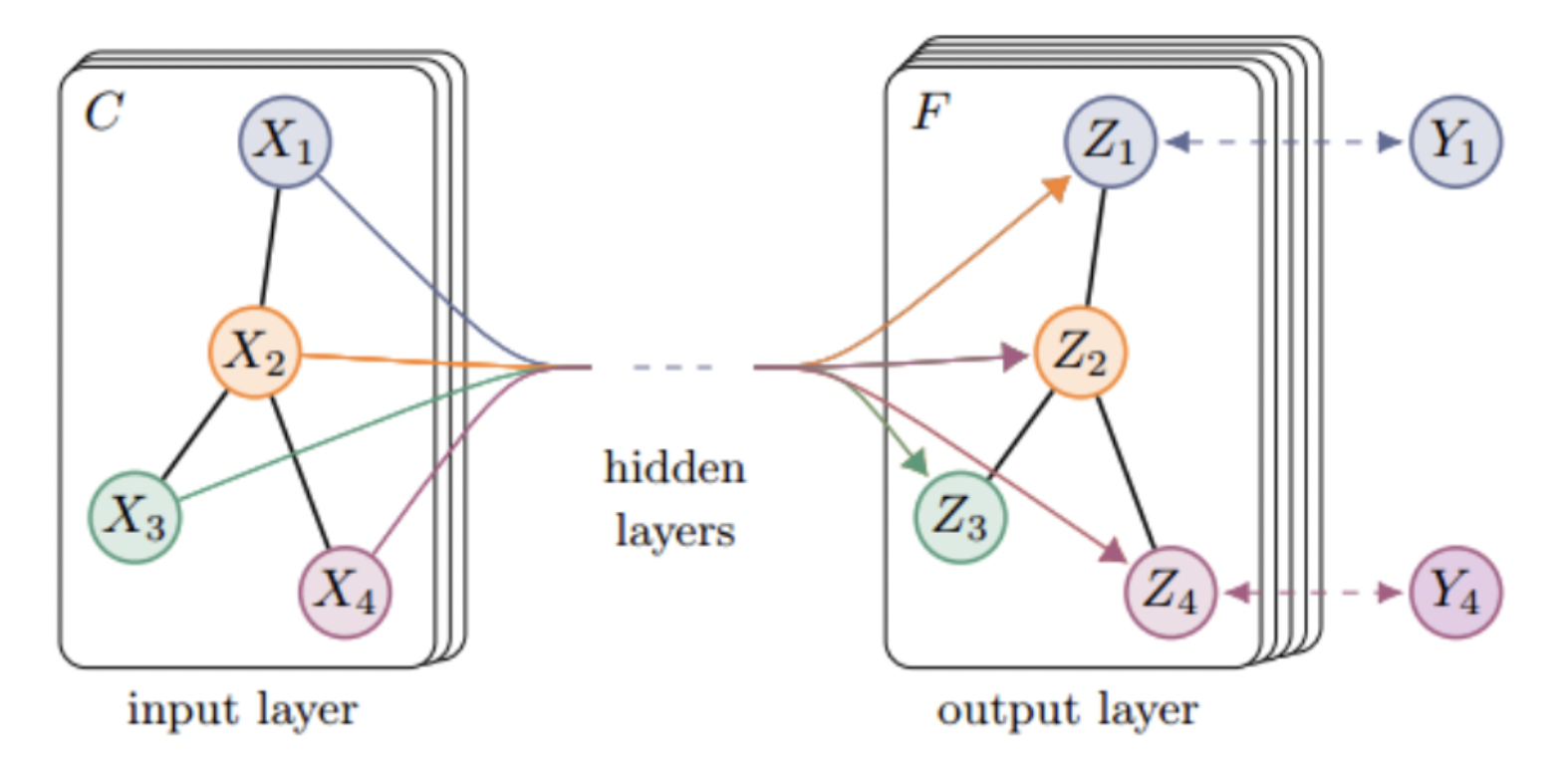
△Pic.4 Schematic diagram of GCN

△Pic.5 Example
As one of the research hotspots, the graph neural network field has been widely used in various industrial scenarios in recent years and achieved good results.
3.2 Graph Algorithm Application
3.2.1 GCN recall model based on the cheating scenario of new pull activities
Pull new event scene modeling
The new event scene is one of the main cheating scenes of the event. Taking the "Master and Apprentice Invitation Scenario" as an example, if the master user successfully invites the apprentice user to become a new user, both the master user and the apprentice user will receive corresponding rewards. Black industry will use batches of fake apprentice accounts to help the master complete the behavior of inviting new students to obtain benefits. Through statistical analysis of the data, it was found that these false apprentice users shared IPs and overlapped models. Based on this, try to use "Master User" as the basic node in the graph, and respectively use "city + model" and "IP+ model" as edge relationships to construct a graph model.
Figure cropping
Since not all masters sharing IP-models have cheating signals, only the edges whose weight is greater than the threshold T are kept to achieve the effect of feature enhancement.
model effect

△table 1 Comparison of model effects
The experimental results show that the GCN algorithm has a significant effect, increasing the recall rate of cheating samples by 42.97%.
3.2.2 Application exploration of multi-image fusion method
From the above experiments, it can be seen that different composition methods will recall different cheating groups. If information on the differences between these groups were fused together, would more recall be obtained? Therefore, try to find an effective way to integrate different graph information into the same model to improve the recall rate of cheating samples. Following the idea of multi-image fusion, the following three methods are proposed to conduct experiments respectively.
fusion method
Edge_union merges the two images with the idea of "mixing image A and image B in the same image for training and learning", and in this way, the information contained in image A & image B is fused together.
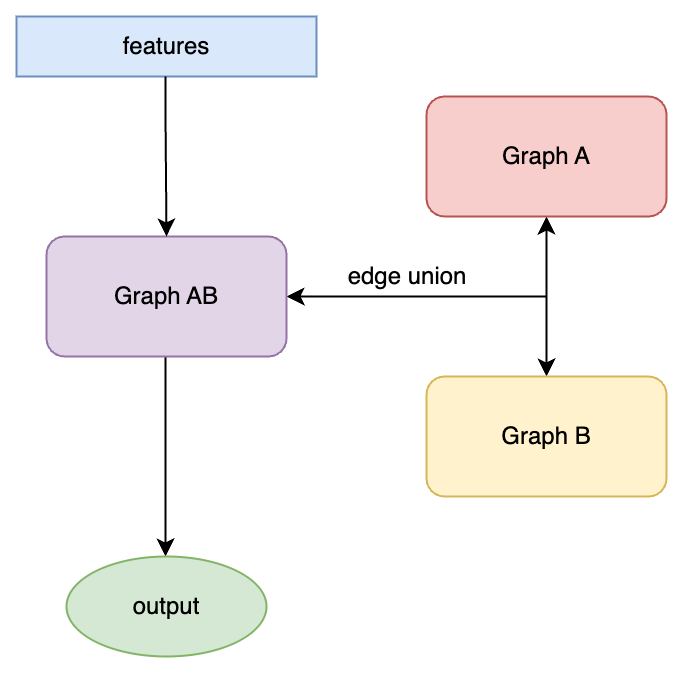
△Pic.6 edge_union model
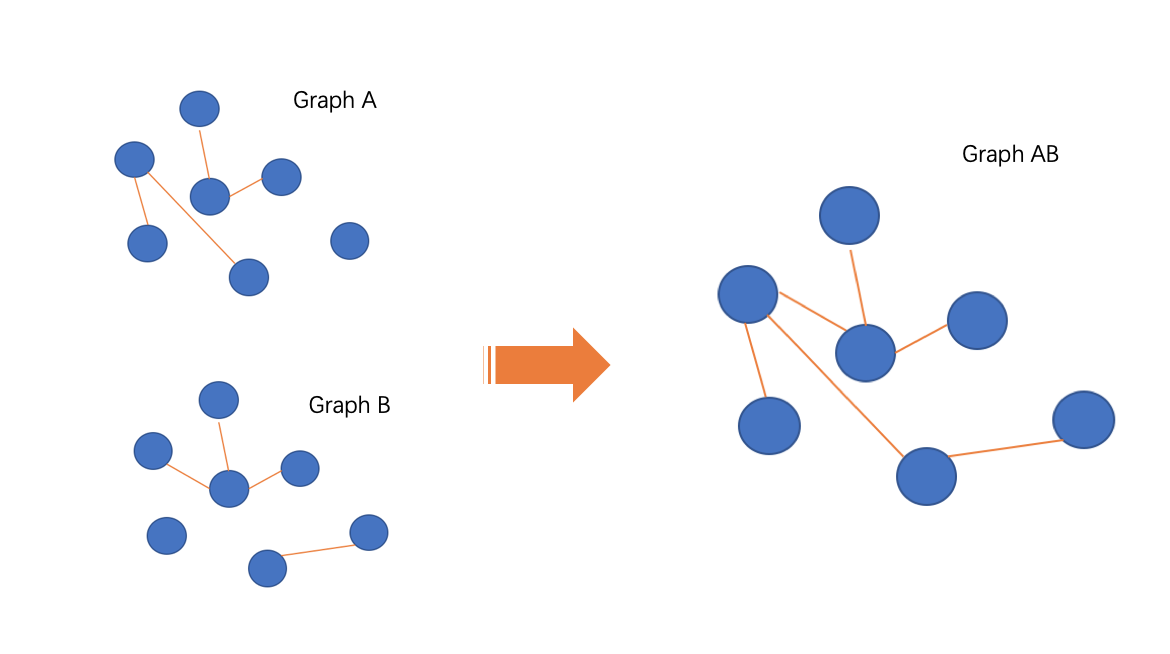
△Pic.7 edge_union composition method
scgcn-split embedding feature inheritance
The idea of fusing the two images is to "take the embedding representation of the trained image A as the input feature of image B for training and learning", and in this way, the information contained in image A & image B will be fused together.
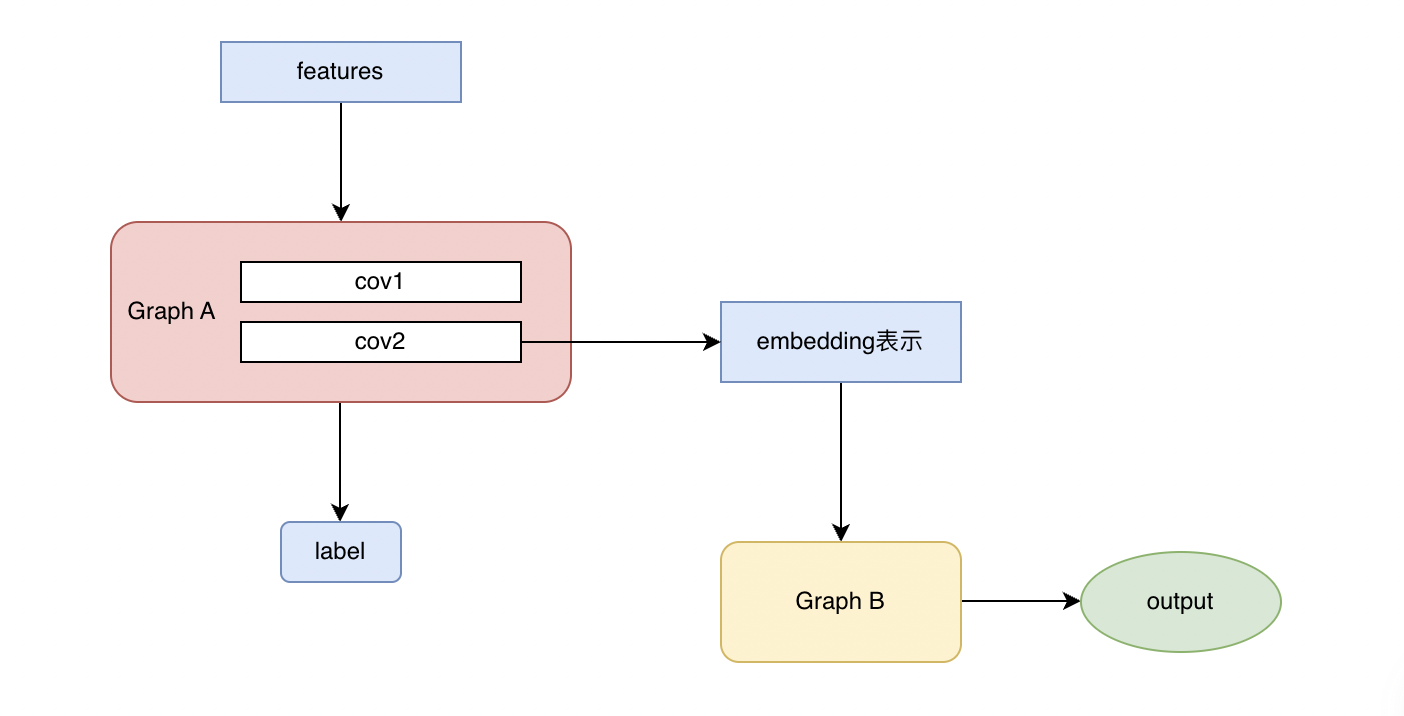
△Pic.8 scgcn-split model
scgcn serial graph merge training
Based on the scgcn-split scheme, graph A & graph B are connected in series for training and learning at the same time.
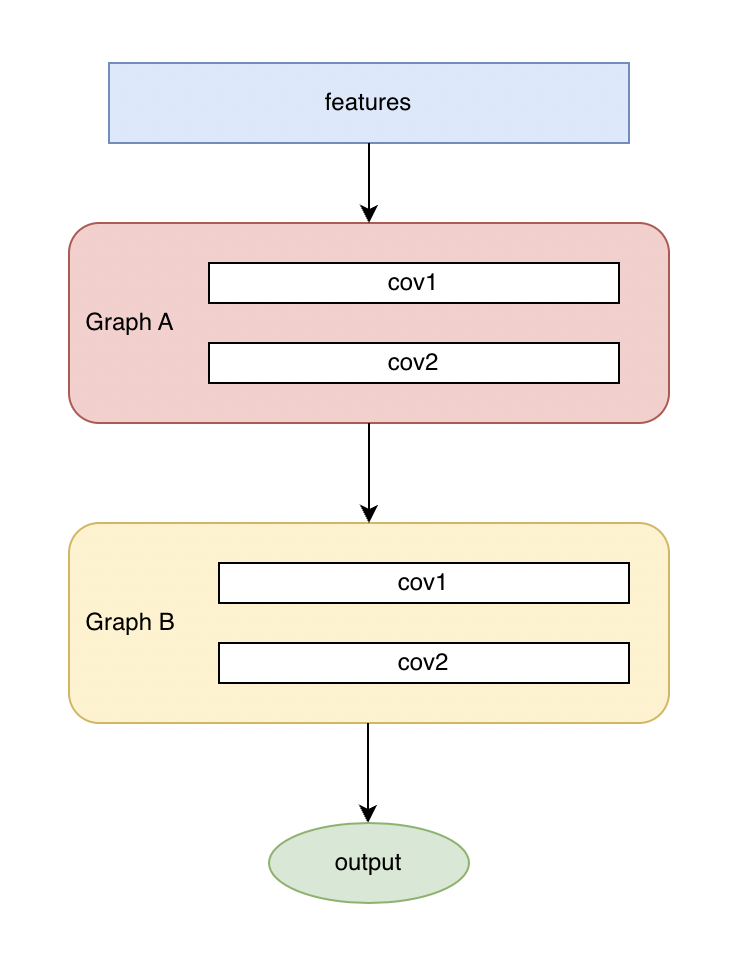
△Pic.9 scgcn model
model effect
The following are the performance comparison results of different methods on the same data set:

△table 2 Comparison of model effects
From the point of view of the magnitude of the new recall, the scgcn method is the best, recalling the most cheating samples; the edge_union method performs poorly, and its recall magnitude is not even as good as the GCN single image. Simply analyze the reason. The edge_union method merges different types of edges into the same graph structure. In this process, the type and importance of edges are not distinguished, which is equivalent to homogenizing the edges of the graph, thus losing some edge information. From the experiment As a result, part of the recall was lost. At the same time, the edge_union model is limited by semi-supervised learning scenarios and insufficient sample purity. While adding edge connections between nodes, it also has the risk of transmitting wrong information. In addition to the above experiments, methods of image fusion such as concat/max-pool/avg-pool have also been tried on the embedding layer. These methods all have recall losses, indicating that the "parallel" image fusion method cannot enable the model to learn more Information, on the contrary, will be recalled due to the loss of information mutual exclusion effect. On the contrary, the method of "serial" graph fusion appears to be more effective. Both scgcn-split and scgcn have more recall than the single-image model, especially the scgcn model, which trains the multi-image parameters at the same time, can truly integrate the multi-image information together, and recalls more than the single-model recall union. many samples.
04 Summary and Outlook
Compared with the traditional model, the graph model can not only obtain node information, but also capture the relationship information between nodes. Through the edge relationship established between the nodes, the information is interconnected, and more information is learned, thereby expanding the recall. In the anti-cheating master-apprentice activity scene of the new promotion activity, through the application of the graph algorithm, the newly recalled cheating samples are increased by 50% on the basis of the original cheating samples, and the recall rate is greatly improved.
In the future, further exploration will be carried out in the following directions:
1. From the previous work, it can be seen that the edge relationship plays an important role in the learning of the graph model. The edge weight will be processed and learned later, and the node information will also be supplemented. By adding data information and effective features, the model is enhanced. recall capability.
2. With the continuous upgrading of cheating methods, the form of cheating is gradually transitioning from machine operation to human operation, and the scale of cheating is reduced, resulting in sparse cheating features and increasing the difficulty of identification. In the future, more graph algorithms will be tried, such as the GAT[2] model that introduces the attention mechanism, the Deepgcn[3] model that can stack multi-layer networks, etc., to improve the sensitivity of cheating detection.
——END——
References :
[1]Kipf, Thomas N., and Max Welling. "Semi-supervised classification with graph convolutional networks." arXiv preprint arXiv:1609.02907 (2016).
[2] Veličković, Petar, et al. "Graph attention networks." arXiv preprint arXiv:1710.10903 (2017).
[3]Li, Guohao, et al. "Deepgcns: Can gcns go as deep as cnns?." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
Recommended reading :
Serverless: Flexible Scaling Practice Based on Personalized Service Portraits
Action decomposition method in image animation application
Performance Platform Data Acceleration Road
Editing AIGC Video Production Process Arrangement Practice
Baidu engineers talk about video understanding
Baidu engineers take you to understand Module Federation