
Author | lhy12138
guide
At present, Baidu Dasou mainly has two-way retrieval based on sparse representation and semantic retrieval based on dense representation. With the development of deep learning technology, the recall effect of semantic retrieval has been significantly improved; at the same time, because sparse representation has the advantages of precise matching, indexing efficiency and interpretability, the academic community has recently returned to the sparse representation architecture. How sparse representations benefit from large-scale language models. This article will introduce the latest progress of the academic community in inverted recall and semantic recall.
The full text is 6386 words, and the expected reading time is 16 minutes.
1. Recall in search
Recall generally selects documents related to the query from the massive candidate library and sends them to the upper-level sorting module. Due to efficiency reasons, it is often impossible to perform query-url fine-grained interaction. At present, the recall mainly includes term-based traditional inverted recall and vector representation-based semantic recall. This article will introduce some of the latest progress in the academic field in the two directions.
2. How to view the relationship between semantic recall and traditional inverted recall?
With the update of the pre-training model and sample technology, semantic recall has shown a strong retrieval effect, while the traditional inversion technology has not achieved a significant improvement in the effect due to cost and efficiency issues. Inverted recall is based on term merging, so it has strong interpretability; while semantic recall searches for documents that are most similar to query semantics in the vector space, and has a stronger ability to express semantics. How should we view the relationship between the two on the recall link?
Are We There Yet? A Decision Framework for Replacing Term Based Retrieval with Dense Retrieval Systems
This paper proposes a framework, including a set of metrics (not only in terms of performance), to thoroughly compare the two retrieval systems.
Primary criteria
(effectiveness/cost) and
secondary criteria
(robustness):
Secondary criteria: the effect of the sub-problem set (such as the length of q in a certain range, the frequency of q in a certain range, the ability of lexical matching, the generalization ability of the model, the proportion of significant differences in decision-making, and even system maintainability, Future iteration space, cost)
The final paper gives a corresponding conclusion on a retrieval evaluation set: that is, on the premise that the cost of vectorization is acceptable, the semantic recall system can replace the inverted recall system. The corresponding problems in the actual industry are often more complicated, but the analytical framework proposed in the paper is exactly what we need to re-examine and think about.
BEIR: A heterogenous benchmark for zero-shot evaluation of information retrieval models
This paper summarizes existing retrieval-related data sets in academia, and summarizes the requirements for retrieval capabilities in different downstream tasks from various fields to comprehensively evaluate the effect of existing recall models.
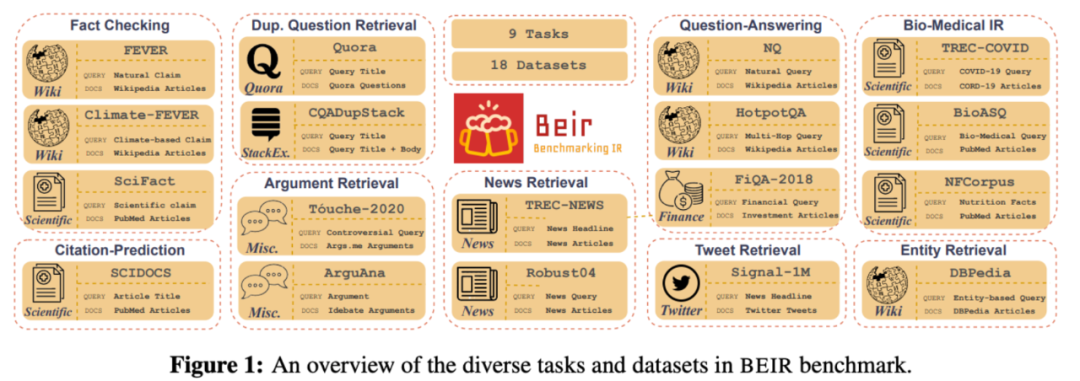
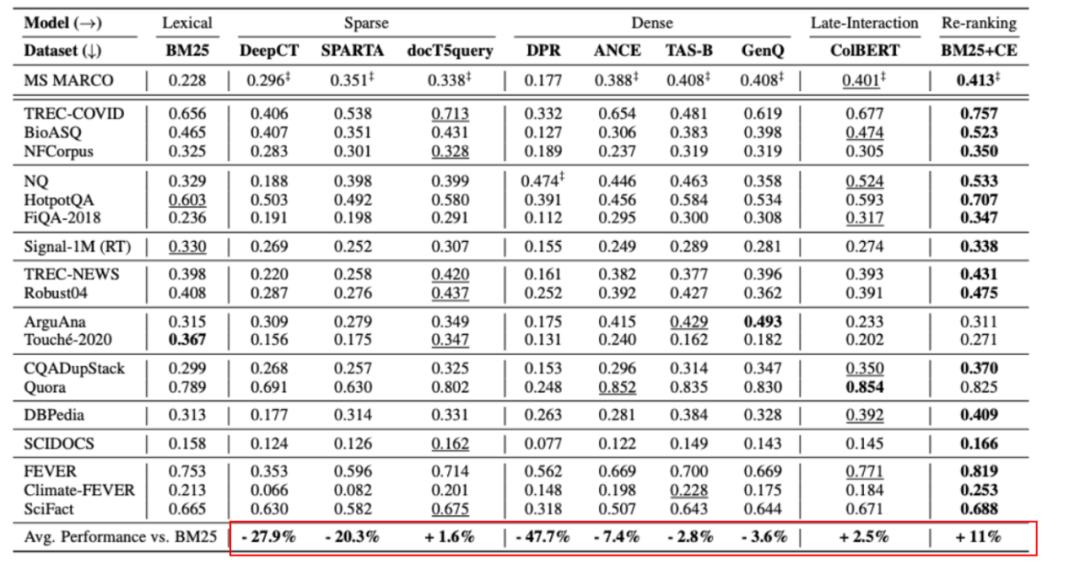
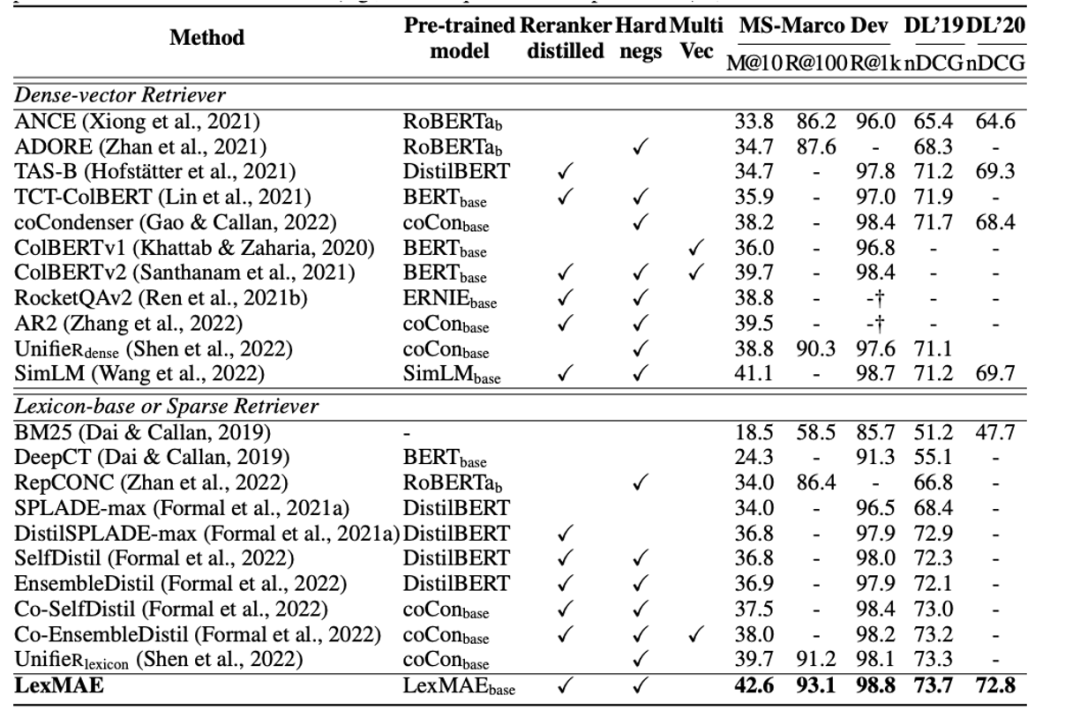
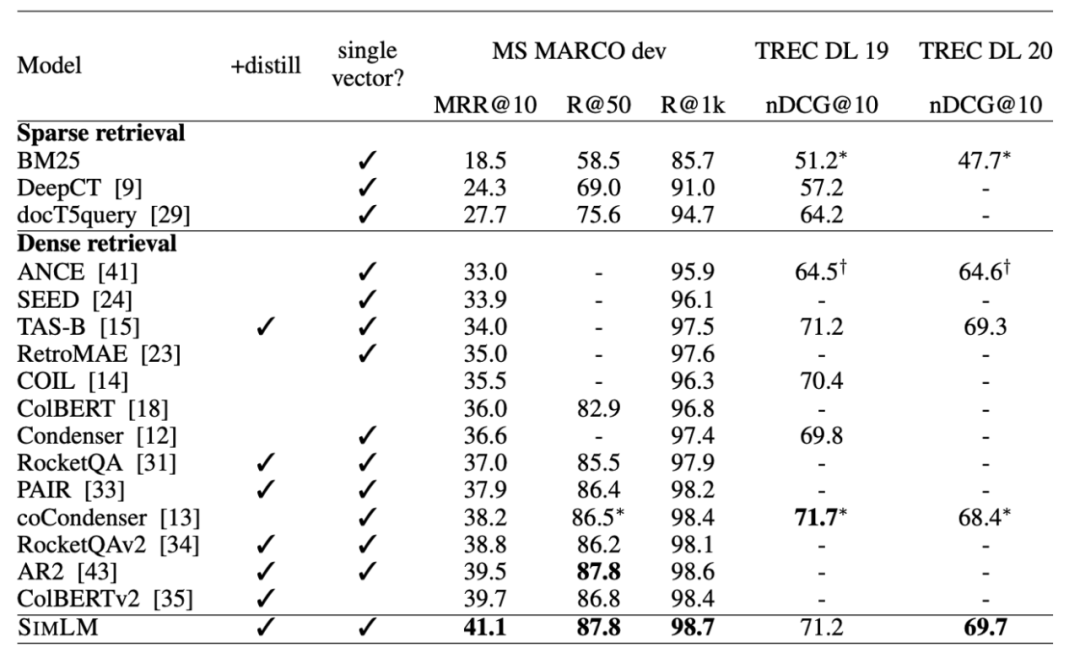
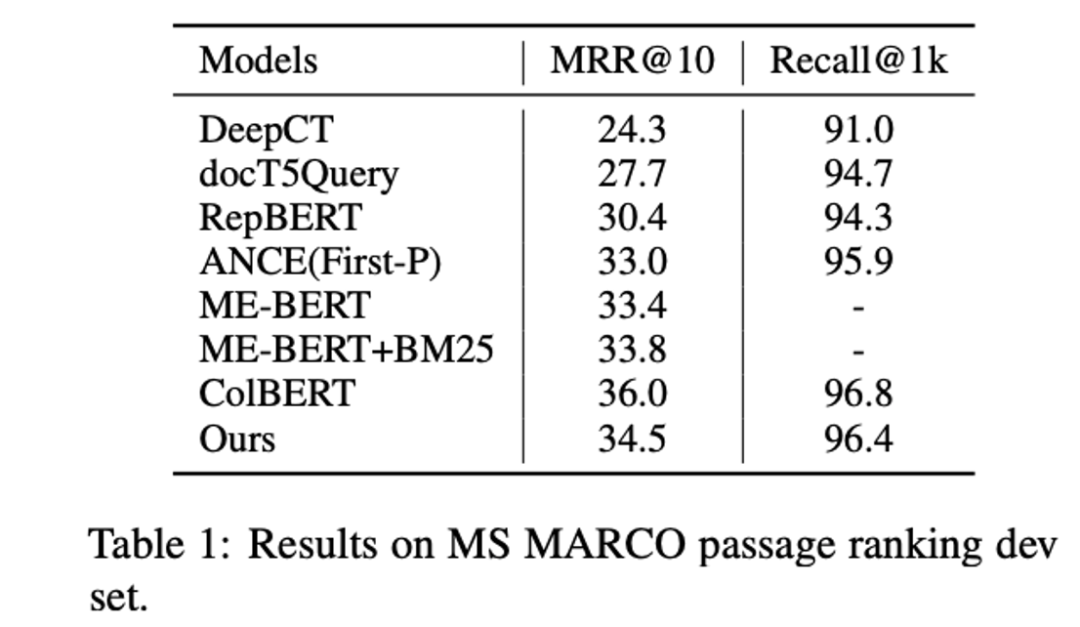
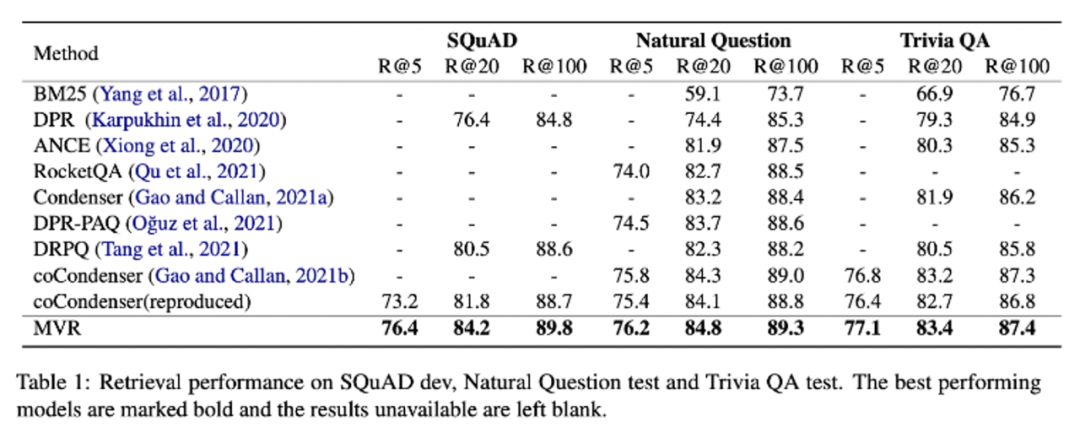
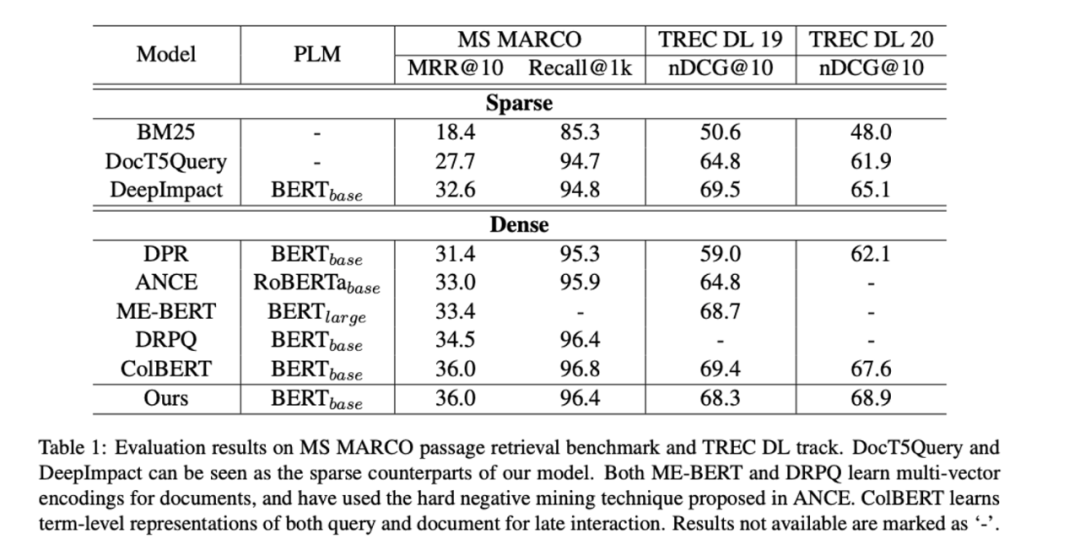
Some interesting conclusions can be seen from the table: In the zero-shot scenario, BM25 is a very robust retrieval system. The two methods based on term fine-grained semantic interaction (colbert/BM25+CE) still show consistent superiority. But the twin-tower model of sparse and dense representations seems to underperform. At the same time, it is observed that doc2query is a stable improvement, because it only expands words, more like a reasonable change to BM25, and the retrieval method and scoring logic are consistent with BM25.
At the same time, the author also mentioned that there is a problem of lexical bias in the data set: the annotation candidates come from BM25 retrieval, so there may be a problem of missing annotations for good results for models that do not rely on vocabulary matching. After annotating the new recall results:

Among them, the indicators of semantic recall models (such as ANCE) are significantly improved.
Through the above two papers, it is found that both inverted recall and semantic recall have their own independent advantages in different scenarios, so we will introduce related progress in the two directions in the following article.
3. New development of inverted recall
If we want to promote the development of inverted layout through existing technology, what solutions can we try?
latest progress:
Learnable sparse representation (integrating query analysis, doc understanding, and retrieval matching into an end-to-end task, but representing query and doc with sparse vectors), still relies on the inverted retrieval method, so retains the advantages of inversion (explainable , term matching ability), and further improve the semantic generalization ability.
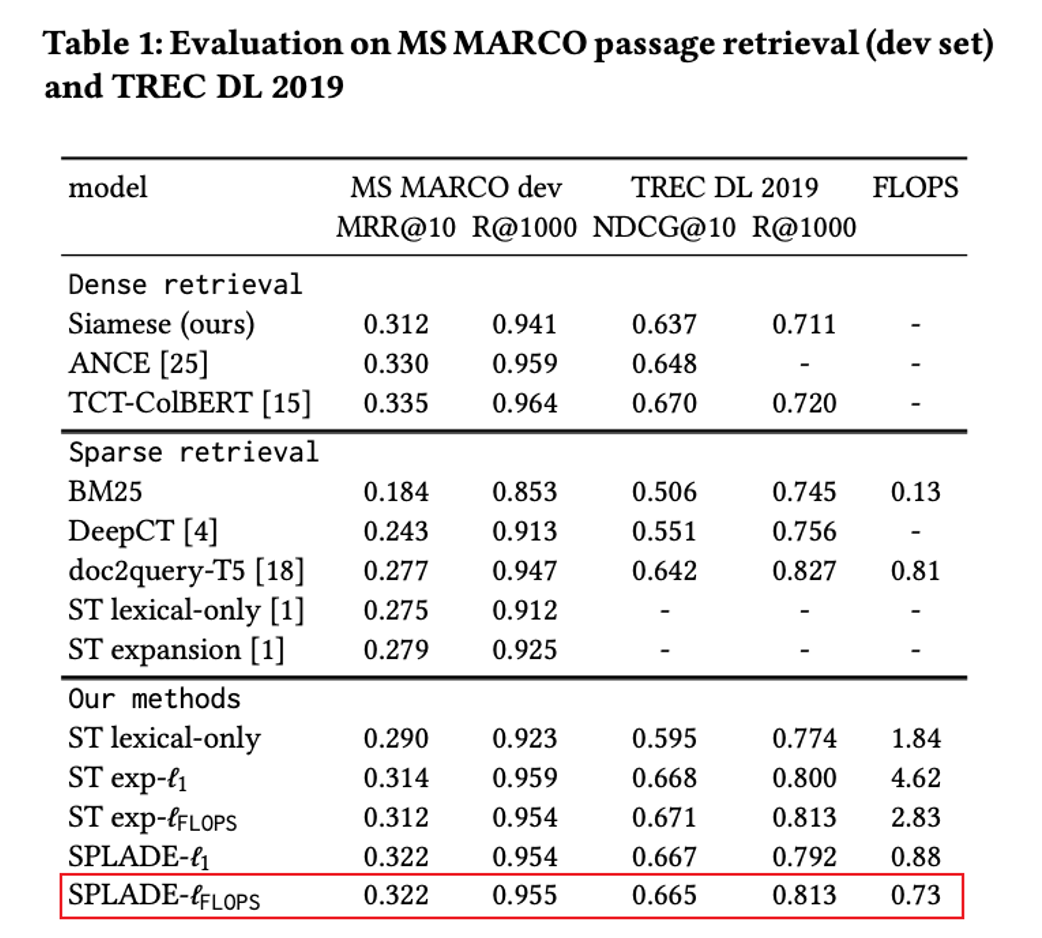
SPLADE: Sparse lexical and expansion model for first stage ranking
Sparse representation: Re-describe doc with the entire vocabulary, while achieving term weight and term expansion.

It can be seen that each document is finally described in the form of term and score, and redundant words existing in the document will be deleted and corresponding extended words will be added.
The sparse representation is very similar to the mask language model task in the pre-training task. Each token is represented by a transformer and finally restored to the vocabulary information, so the sparse representation reuses the head of the mlm task.
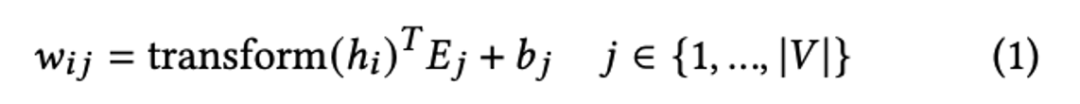
By summarizing (pooling) all the sparse representations in the original query/doc, the query/doc is represented as a sparse vector of vocabulary dimension, and the flops regularization is introduced to control the number of extended terms. At the same time, the qu matching score is calculated in the form of a dot product based on the sparse representation.

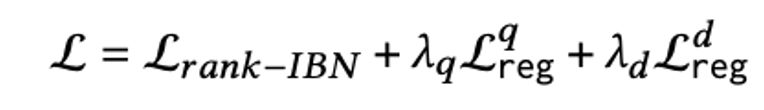
The final loss is expressed as the common in-batch CE loss and the corresponding flops regular loss.
From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective
This article is to verify whether various optimization ideas proposed under dense representation (corresponding to the semantic recall model mentioned above) can be migrated to sparse representation:
Including: distillation technology (margin-mse), difficult sample mining technology (single tower mining hard-neg) and pre-training technology (cocondenser strengthens cls ability).
Finally, it is proved through experiments that various methods can be transferred to sparse representation scenarios.
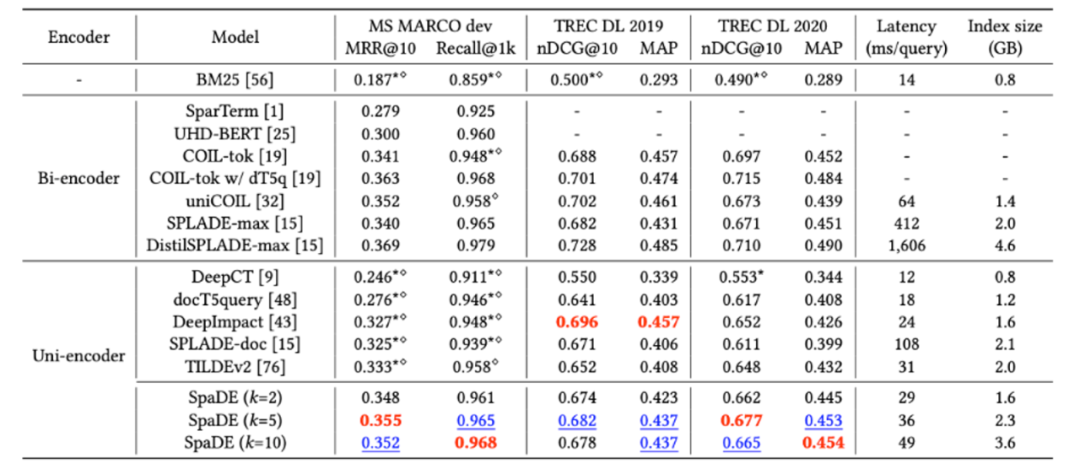
SpaDE: Improving Sparse Representations using a Dual Document Encoder for First-stage Retrieval
Starting point: Compared with unified modeling term weight and term expansion, dual encoders are used to model independently, and a joint training strategy is proposed to promote each other.
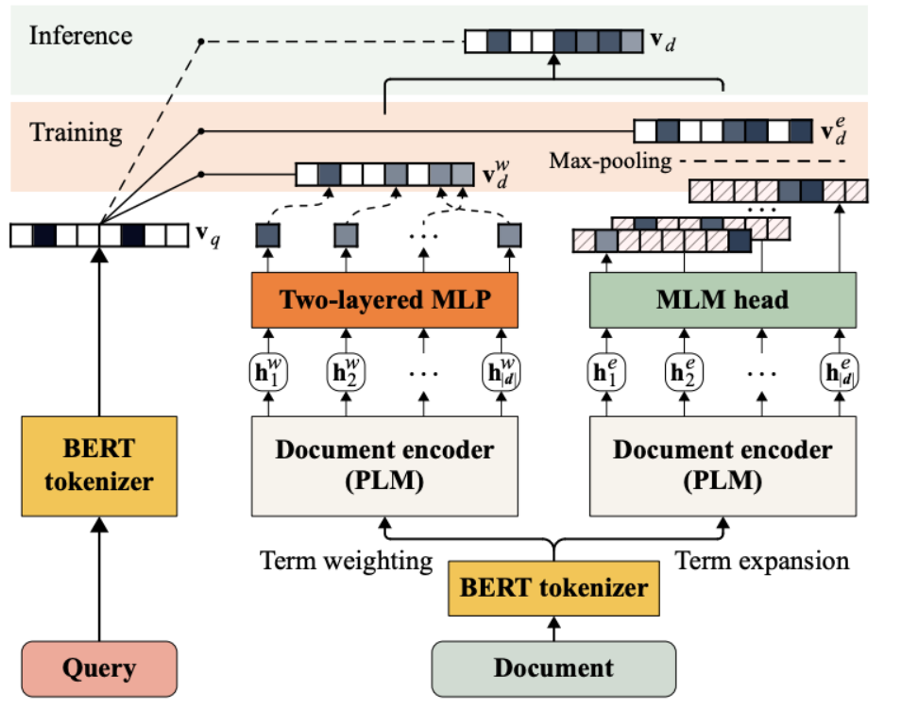
Split the entire model structure into three parts:
Query side: In order to improve the inference efficiency of the query side, only the tokenizer is used, that is, there is only one-hot information.
The term weight module on the doc side: predict the weight of the term.
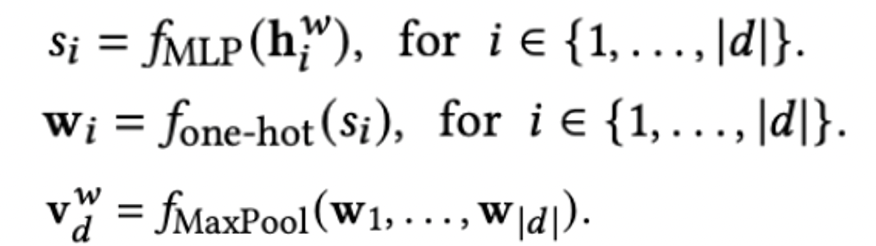
The term expansion module on the doc side: predict top-k expanded words and their weights.
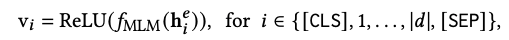
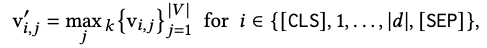
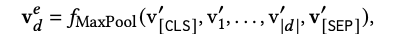
Finally, the overall sparse representation of the doc side is summarized:
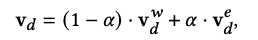
At the same time, a collaborative training strategy is proposed:
The author observed that joint training (obtaining the final merge representation vd first and then training directly) hardly brought about the effect gain.
Therefore, the model adopts the collaborative training method:
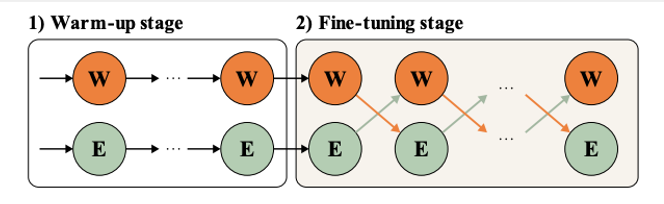
Hot start phase
: train two doc-side encoders independently using different objective functions.
term weight
: Normal in-batch loss to describe the relevance scores of query and doc.
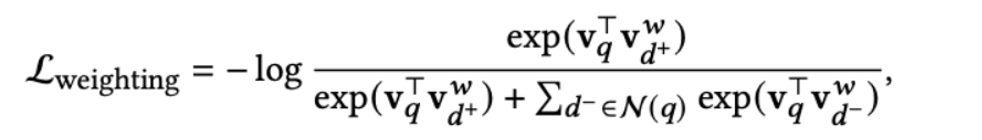
term expansion: because the query is not expanded, if the doc fails to expand the query word, it corresponds to the query
Words do not get a relevance score, so it is desirable to expand words as much as possible to query and try not to expand non-query words.
Therefore, a separate constraint item is added. On the basis of the standard recall loss, the capabilities of the query sparse representation and the doc sparse representation on word hits are strengthened, and the doc is required to expand the extended words required by the query as much as possible.
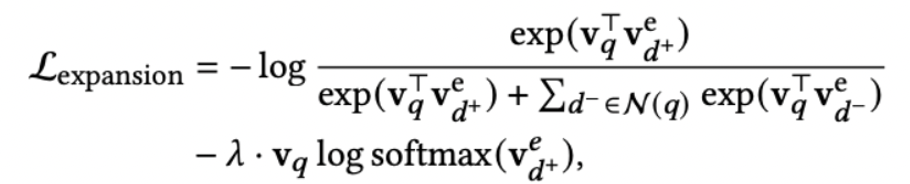
Finetune stage
: Each encoder provides topr% large loss samples for the other to strengthen complementarity. (The large loss sample of the weight model may be a vocabulary mismatch, and the large loss sample of the extended model may be that the current model has a poor description of weight)
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval.
Starting point: MLM is not suitable for sparse representation, mlm tends to assign high scores to low-entropy words, and sparse representation can hope to focus on high-entropy words that are important to semantics. (The loss of mlm is more extreme, it only predicts the original word, and it is easier to mask low-entropy words, while the sparse representation hopes that the predicted value is softer to reflect the importance of term + the ability to expand words)
The following framework is therefore proposed, consisting of three components:
-
Encoder(BERT)
-
Dictionary Bottleneck Module
-
Weak mask decoder
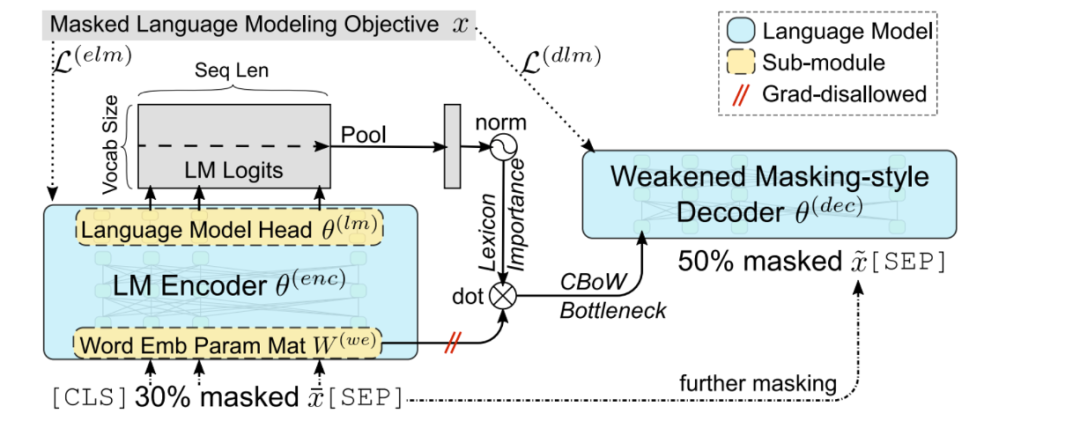
Encoder: After the input text passes through a certain proportion of the mask, the output of the MLM-head is a sparse representation.
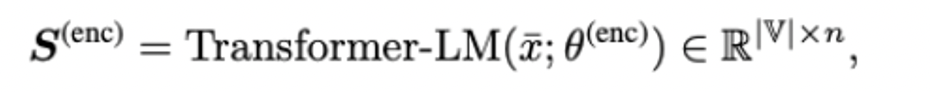
Dictionary bottleneck module: use the sparse representation a of doc to obtain the sentence dense representation b.
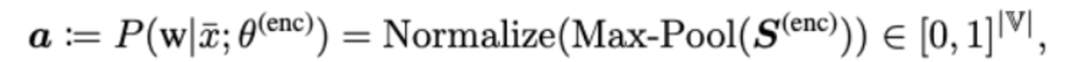
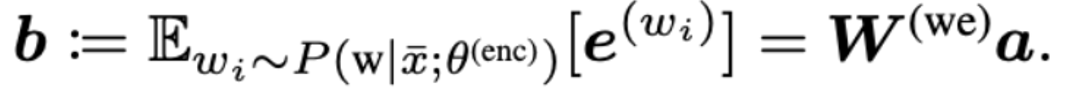
where W is the original BERTword embedding representation.
Weak mask decoder: Use dense representation b to restore mask information, replace CLS with b, and restore masked words through two-layer decoder. (It is hoped that the sparse representation will bear the corresponding information capability of CLS, and the expressive ability of the sparse representation will be strengthened in the pre-training stage.)
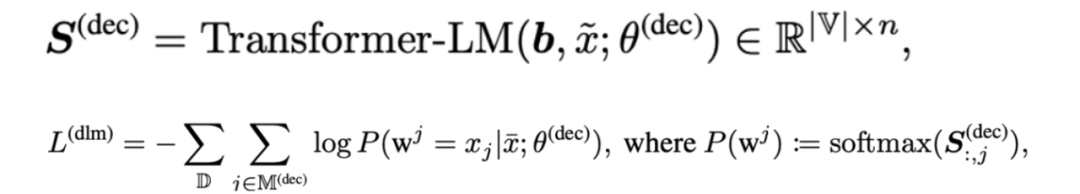
4. New Development of Semantic Recall
Although semantic recall has powerful semantic capabilities, there are still several types of problems in practice (including but not limited to):
1. The ability to express single-representation information is weak.
2. Exact matches cannot be modeled.
3. How to ensure the validity of multiple representations
Single representation information compression problem:
Simlm: Pre-training with representation bottleneck for dense passage retrieval.
Point of departure:
Reduce the inconsistency between pre-training and finetune, improve sample efficiency, and hope that cls encodes the information in doc as much as possible.
practice:
1. Randomly mask the original sequence twice, and use the generator to restore two new sequences.
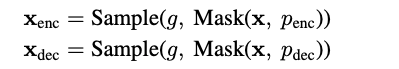
2. For the enc sequence, use multi-layer transformer encoding to obtain a sentence-level CLS representation, where the loss constraint is whether the current word has been replaced.
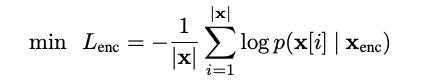
3. For the dec sequence, use a 2-layer transformer to encode the sentence representation of the entire sequence and the enc sequence, and the same loss constraint is whether the current word has been replaced.
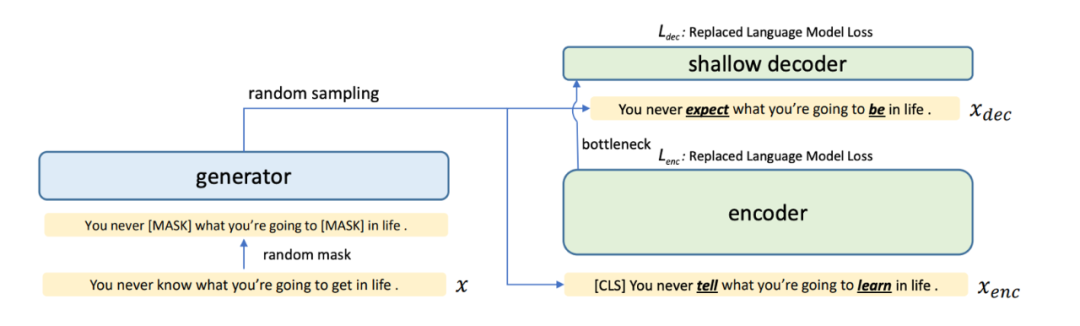
Since the dec sequence only uses a 2-layer transformer, it forces the sentence-level cls signal to capture more semantic information of the original enc sequence.
Exact match problem:
Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
Starting point: dense retrieval is not as good as the sparse method in terms of word matching and low-frequency entities. It is hoped that it can have the vocabulary matching ability of the sparse model and simulate sparse retrieval.
Idea: Use sparse teacher to distill to dense retrieval (imitation model), and then concat with normal dense retrieval.
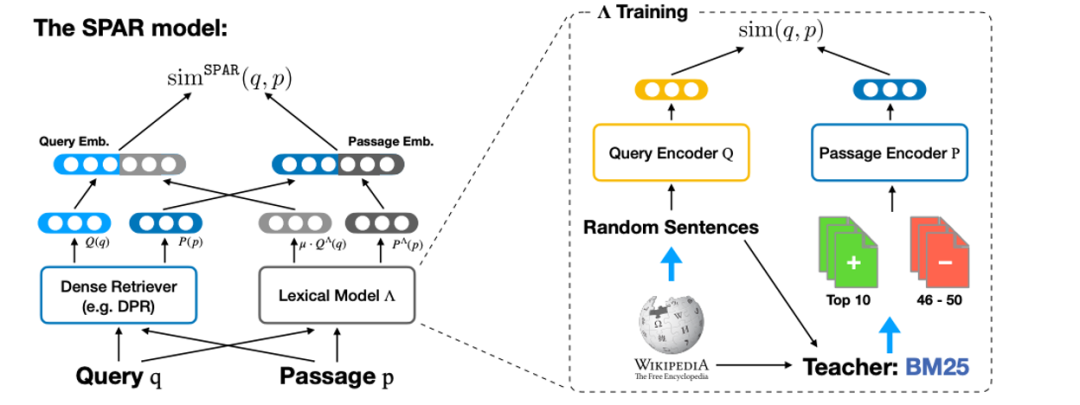
Experience:
-
When the sparse teacher is distilled to imitate the model, mse and kl loss fail to work. Finally, the sparse teacher is used to generate pos and neg, and it is better to use the conventional comparison loss for sample-level distillation instead of soft-label distillation.
-
At the same time, I tried to use imitation as a hot-start model of dense, but the effect was mediocre, so I chose two representations for joint training, and tried the scheme of summation/concat and freeze imitation model only updating the dense model and weighting coefficients.
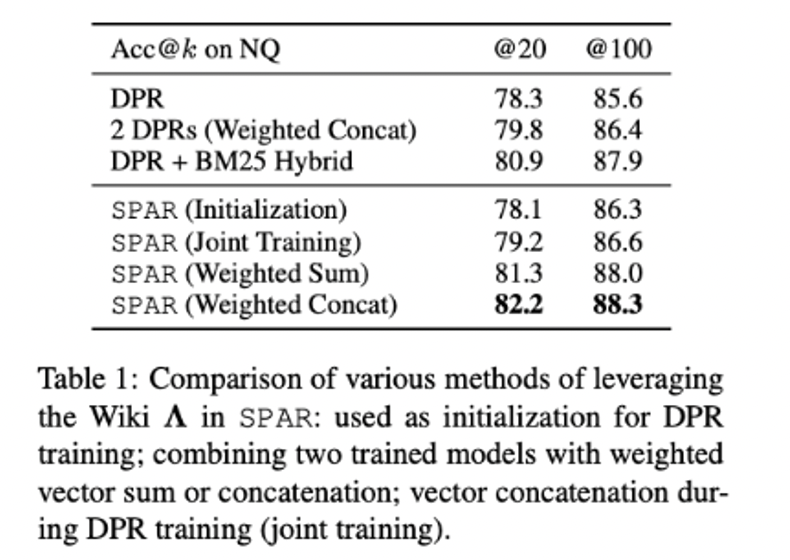
At the same time, the author verified whether the imitator has really learned the ability of vocabulary matching, and found that the consistency between the modeler and BM25 ranking has been greatly improved.
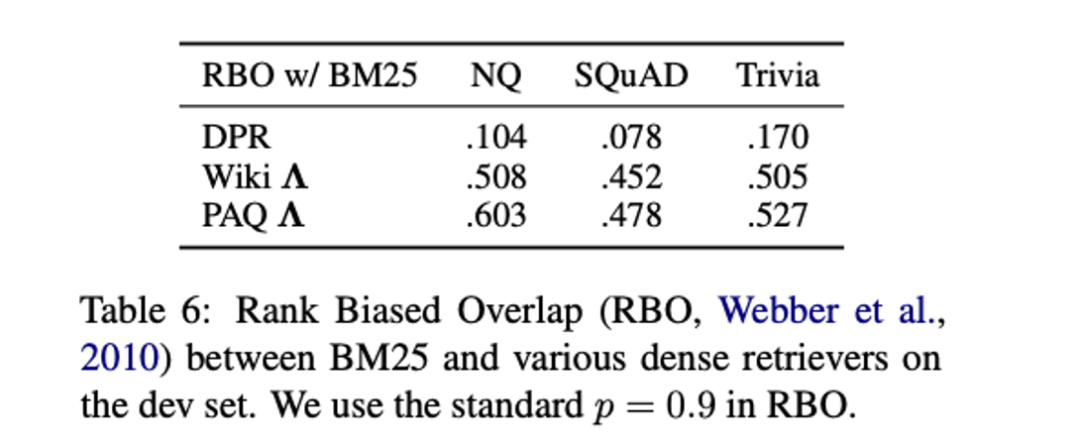
LED: Lexicon-Enlightened Dense Retriever for Large-Scale Retrieval
Starting point: lack of local modeling of term matching and entity mentioning
Ideas:
1. Increase the difficult negative samples of lexical and update the lexical model and the dense model at the same time. (The lexical model is the SPLADE model mentioned above)
2. Compared with KL loss loss, only weak supervision is required to ensure rank consistency.
(The idea is consistent with the previous paper, and I want to use a better vocabulary model to integrate knowledge into the dense model)
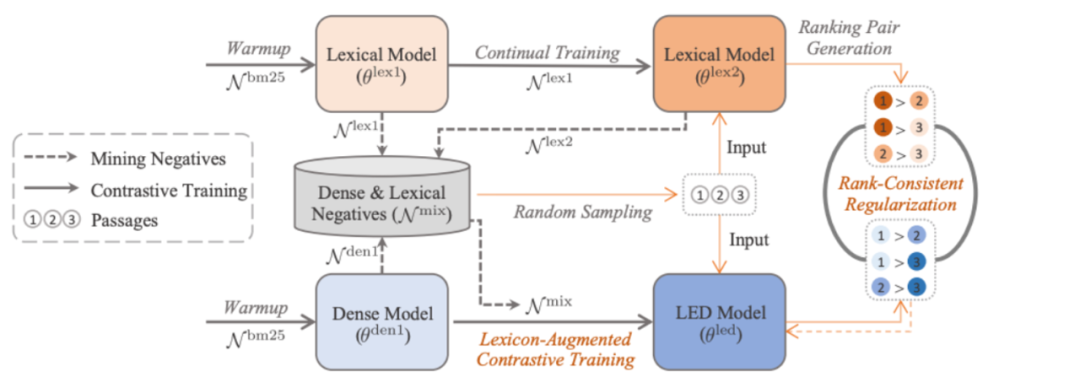
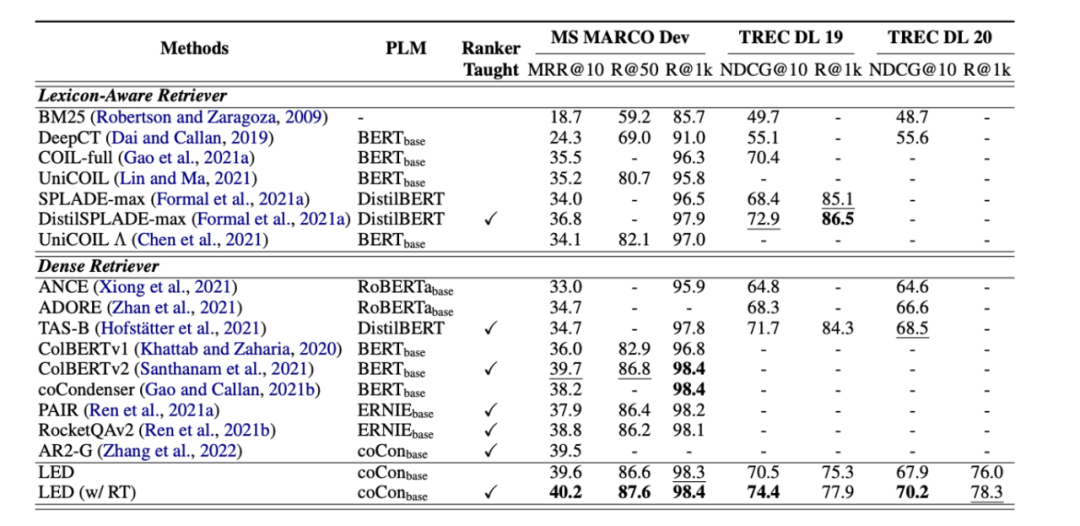
Multi-representation modeling problems:
Improving document representations by generating pseudo query embeddings for dense retrieval
Starting point: a single representation needs to compress all the information of the document, which may be suboptimal
(Background premise: Part of the evaluation set doc will extract multiple questions based on the content, and there are inherently many query requirements)
Solution: Get the final representation of all tokens, perform k-means clustering, and then extract multiple representations from each doc.
K-means algorithm: find the cluster centers of all tokens of doc (initialization: randomly select token representation or select equidistant for doc cutting)
After the final convergence of multiple steps, the remaining cluster centers are considered to reflect "potential" query queries.
Training phase: k-means obtains multiple cluster centers, query makes attention to multiple cluster centers of doc, and then accumulates scores.

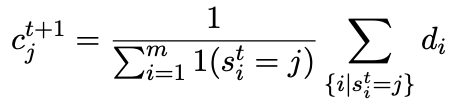
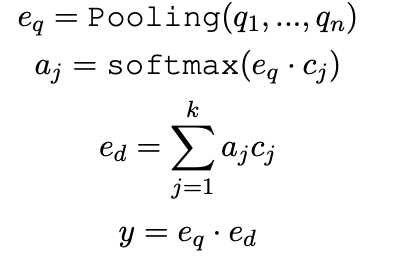
Reasoning stage: first execute an ann query separately, find top-k candidates, and then use all representations of the corresponding doc to calculate the attention representation and reordering scores.
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
Starting point: doc needs multiple representations, hope that a certain representation in doc is aligned with query, and find that multiple representations in MEBERT will degenerate to [CLS].
Idea: Replace [cls] with multiple [viewers] for multi-representation of documents, and propose a local uniform loss + annealing strategy to match different potential queries.
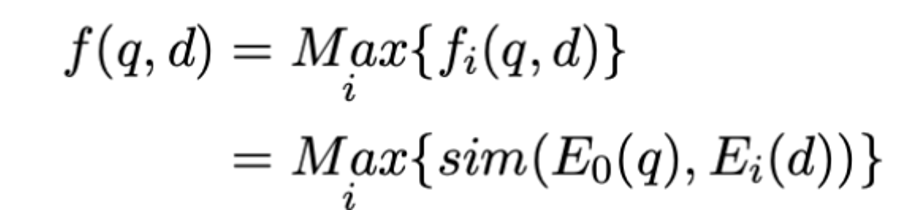
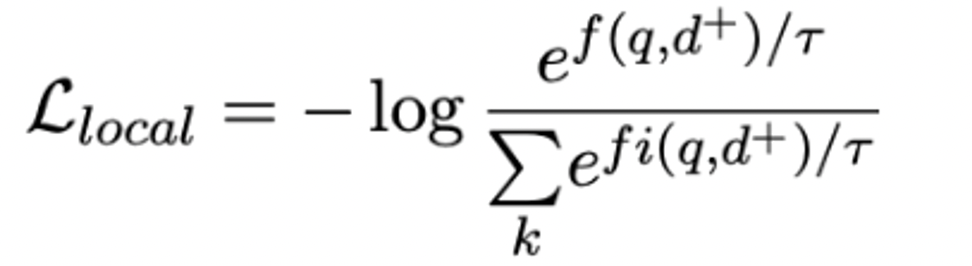
Annealing strategy:
At the beginning, the temperature coefficient is large, and after softmax, the distribution is uniform, and each viewer vector can obtain a gradient. After each epoch, the temperature coefficient is adjusted to highlight the truly matching view.
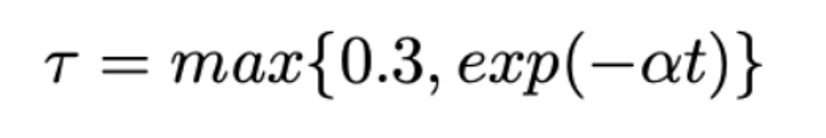
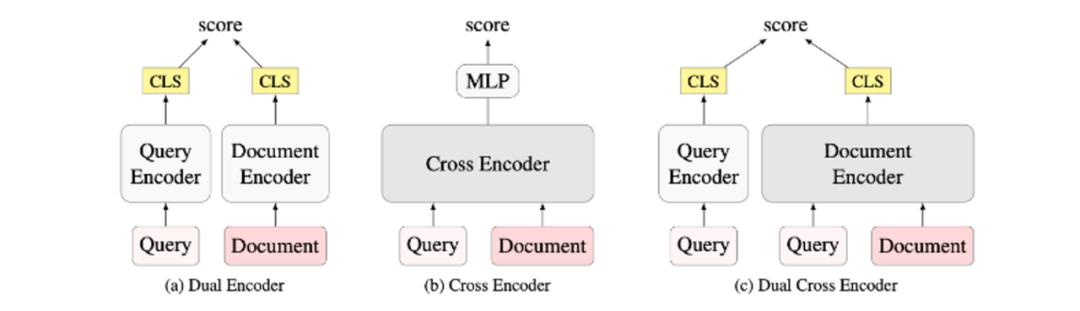
Learning Diverse Document Representations with Deep Query Interactions for Dense Retrieval
Starting point: Multiple documents may be queried by multiple potential queries, whether direct doc2query can simulate potential interactions.
Idea: Use the generated query to learn document representation, T5 finetune doc2query, and decode10 queries.
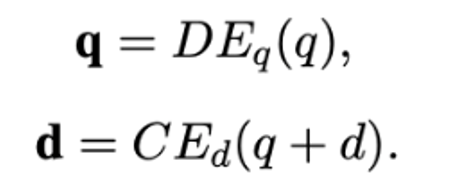
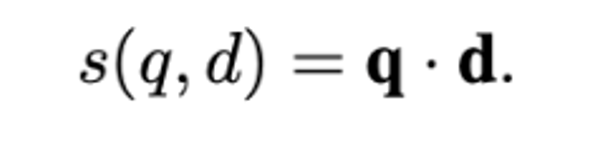
Execute doc2query only on all positive samples, and use the generated query as the query signal for hard negative samples
Hard neg:
Positive sample: (q+ d+) negative sample (q+ d-) prevents the model from taking shortcuts on the query side and emphasizes doc information
In-batch neg:
Positive sample: (q+ d+) negative sample (other q+ d-) learning topic signal
Reasoning: Multiple queries are generated to represent the multi-representation of doc, which are spliced with doc and sent to the doc-side twin-tower model.
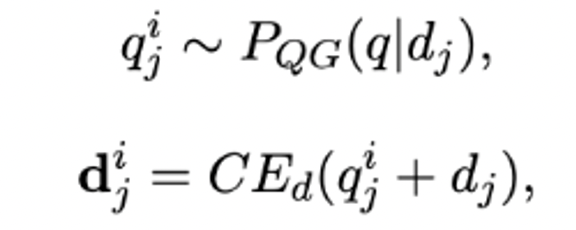
In addition to the three problems mentioned above, the semantic model also has the following problems (including but not limited to), but due to space limitations, it cannot be introduced in this sharing:
-
Semantic Model Distillation Technology
-
Entity-based (multi)representation techniques
-
Semantic Modeling for Modeling Multi-Object Scenes
V. Summary
Above, we have summarized the latest progress in the recent academic circles on inversion and semantic recall. We can see that with the development of large-scale pre-training models, both inversion and semantic recall can benefit from it.
——END——
{{o.name}}
{{m.name}}