Table of contents
1. The origin of the attention mechanism
2. Nadaraya-Watson kernel regression
With the popularity of the Transformer model in the fields of NLP, CV and even CG, the attention mechanism (Attention Mechanism) has been noticed by more and more scholars, and it is introduced into various deep learning tasks to improve performance. The team of Professor Hu Shimin of Tsinghua University recently published an Attention review on CVM [1], which introduced the progress of related research in this field in detail. For point cloud applications, introducing an attention mechanism and designing a new deep learning model is naturally a research hotspot. This article takes the attention mechanism as the object, outlines its development, and its successful application in the field of point cloud applications, and provides some reference for students who expect to make breakthroughs in this research direction.
1. The origin of the attention mechanism
Refer to Mr. Li Mu's in-depth learning textbook [2] for the introduction of the attention mechanism. Here is a simple explanation of the attention mechanism. The attention mechanism is a mechanism that simulates human visual perception and selectively screens information for reception and processing. When screening information, if no autonomous prompt is provided, that is, when a person reads a text, observes a scene, or listens to an audio without any thinking, the attention mechanism is biased towards abnormal information, such as a black and white scene A girl in red, or an exclamation point in a paragraph, etc. When autonomous prompts are introduced, such as when you want to read sentences related to a certain noun, or scenes associated with various objects, the attention mechanism introduces this prompt and increases the sensitivity to this information when information is screened. In order to mathematically model the above process, the attention mechanism introduces three basic elements, namely Query, Key and Value. These three elements together constitute the basic processing unit of the Attention Module. The key (Key) and value (Value) correspond to the input and output of information, and the query (Query) corresponds to the autonomous prompt. The basic processing unit of the Attention Module is shown in the figure below.
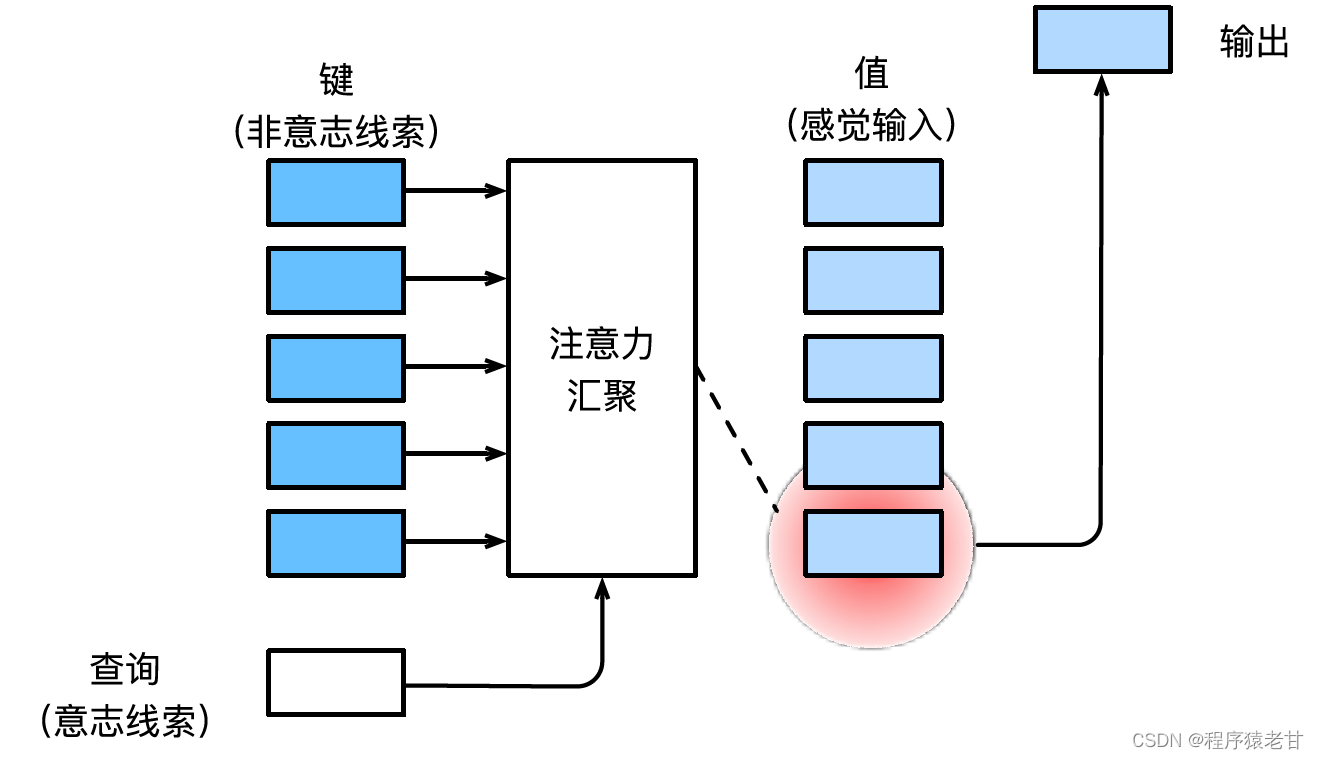
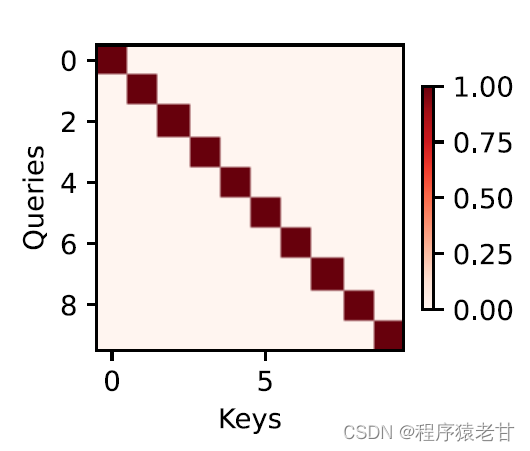
The attention mechanism combines the query and the key through attention pooling to realize the selection tendency of the value. The key and value are paired, just like the input and output in the training task, which is a known data distribution, or category correspondence. The attention mechanism enters the query in the attention pool, establishes the weight code from the query to each key, obtains the relationship between the query and the key, and then guides the output of the corresponding value. In short, when the query is closer to a key, the output of the query is closer to the value corresponding to the key. This process introduces attention to the key-value correspondence closer to the query to guide the attention-compliant output. If a two-dimensional relationship matrix is established corresponding to the query and the key, when the values are the same, it is 1, and when they are different, it is 0, and the visualization result can be expressed as:
2. Nadaraya-Watson kernel regression
Here is a classic attention mechanism model, Nadaraya-Watson kernel regression [3] [4], to understand the basic operating logic of the attention mechanism. Suppose we have a key-value correspondence data set {(x1,y1),(x2,y2),...(xi,yi)} controlled by a function f, the learning task is to establish f, and guide the new The evaluation of the x key. In this task, (xi, yi) corresponds to the key and value, the input x represents the query, and the goal is to obtain its corresponding value. According to the attention mechanism, it is necessary to establish the prediction of its value by examining the similarity relationship between x and each key value in the key value correspondence data set. When the input x is closer to a certain xi key, the output value is closer to yi. The simplest estimator for key-values here is averaging:
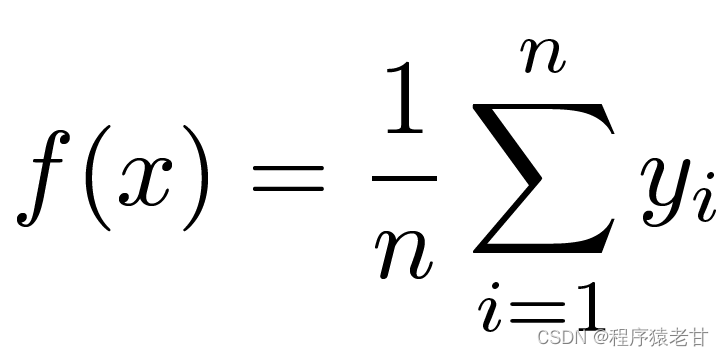
Obviously, this is not a good idea. Because the average pooling ignores the deviation of the sample in the key-value distribution. If the key-value difference is introduced into the evaluation process, the result will naturally become better. Nadaraya-Watson kernel regression uses such an idea and proposes a weighted evaluation method:
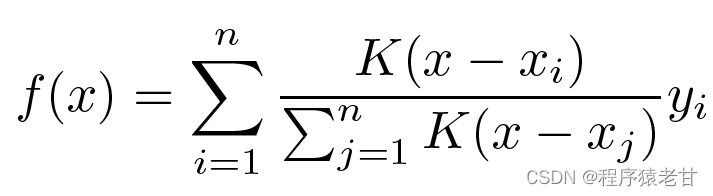
K is considered to be the kernel, i.e. understood as a weight to measure the deviation from the difference. If the above formula is rewritten according to the weight of the difference between the input and the key, its own formula can be obtained:
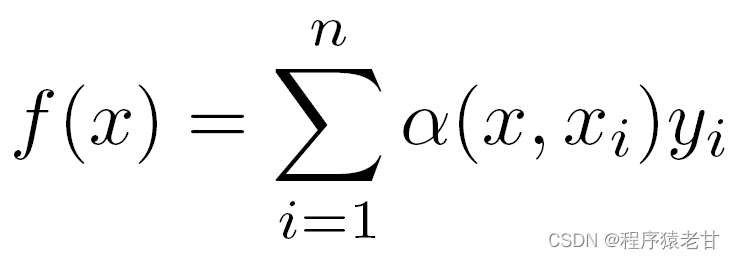
If the above weights are replaced by a Gaussian weight driven by a Gaussian kernel, then the function f can be expressed as:
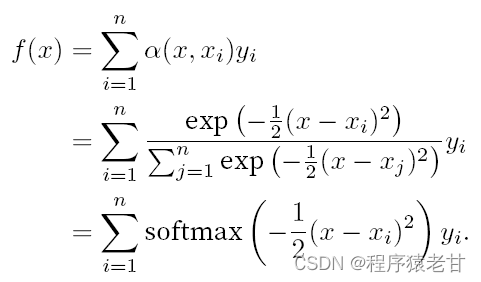
A schematic is given here to compare the fit of different f to sample key-value pairs derived from average pooling (left panel) and Gaussian kernel-driven attention pooling (right panel). It can be seen that the fitting performance of the latter is much better.
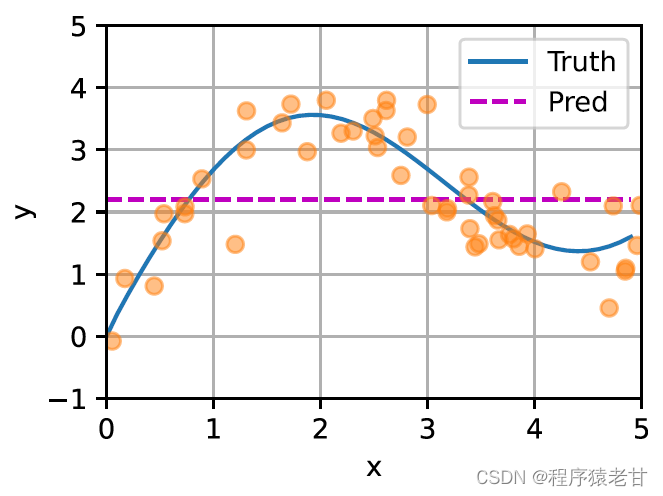
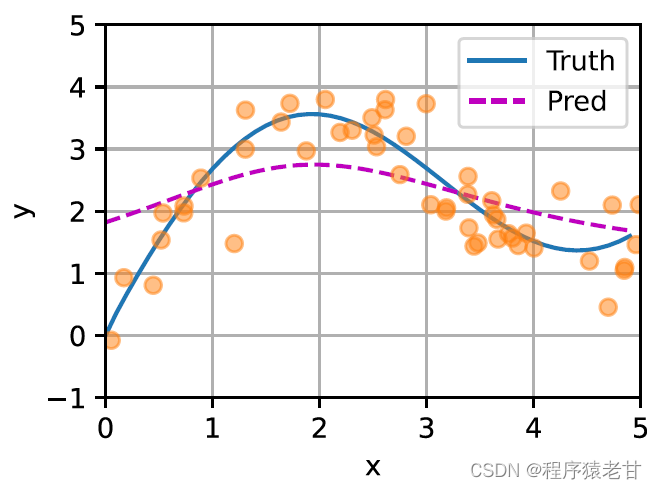
The above model is a non-parametric model. For the case with learnable parameters, it is recommended to read the attention mechanism chapter of [2]. The Gaussian kernel and its corresponding Gaussian weight used here are used to describe the relationship between the query and the key. In the attention mechanism, the quantitative representation of this relationship is the attention score. The above-mentioned process of establishing predictions for query values can be expressed as establishing a score based on key-value pairs for the query, and by assigning weights to the scores to obtain query values, expressed as:
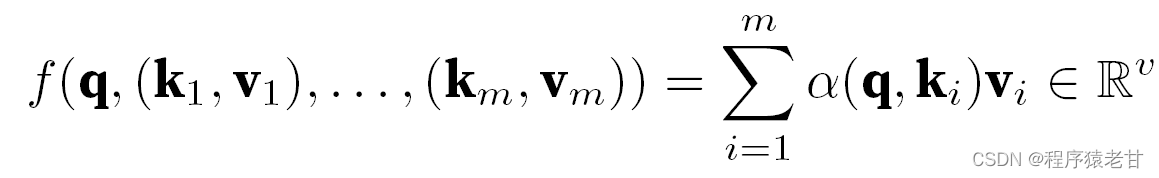
Where α represents the weight, q represents the query, and kv represents the key-value pair. In the textbook [2], it is also introduced how to deal with the additive attention processing method of query and key length mismatch time and the scaling dot product attention, which is used to define the attention score, and will not be detailed here.
3. Multi-head attention and self-attention
1) Multi-head attention
Multi-head attention is used to combine queries and subspace representations with different key values, and realize the organization of different behaviors based on the attention mechanism to learn structured knowledge and data dependencies. Different linear projections are learned independently to transform queries, keys and values. Then, the transformed query and key-value are sent to the attention pool in parallel, and then the outputs of multiple attention pools are stitched together, and transformed by another linear projection that can be learned, and the final output is generated. This design is called multi-head attention [5]. The figure below shows a learnable multi-head attention model:
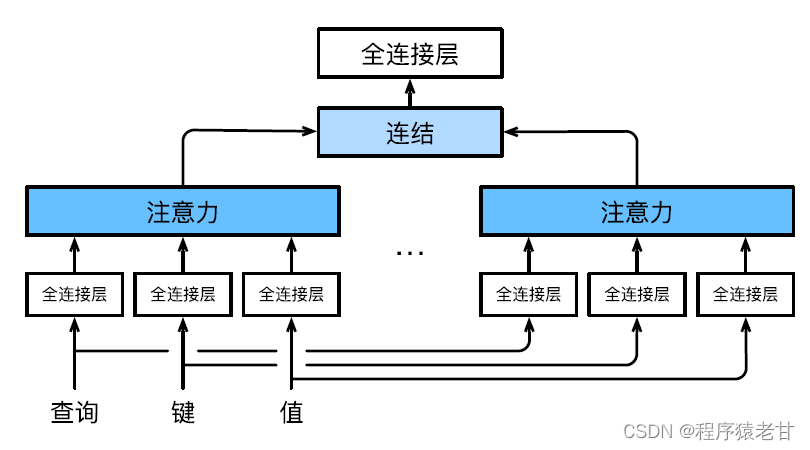
The mathematical definition of each attention head is given here. Given a query q, key k, and value v, the calculation method of each attention head h is:
![]()
Here f can be additive attention and scaled dot product attention. The output of multi-head attention undergoes another linear transformation to concatenate the outputs of multiple attention mechanisms to mimic more complex functions.
2) Self-attention and position encoding
Based on the attention mechanism, the lexical sequence in the NLP problem is input into the attention pool, and a group of lexical elements are used as queries and key values at the same time. Each query attends to all key-value pairs and produces an attention output. Since the query and key values all come from the same set of inputs, it is called a self-attention mechanism. A coding method based on the self-attention mechanism will be given here.
Given a token input sequence x1,x2,...,xn, the corresponding output is an identical sequence y1,y2,...,yn. y is expressed as:
![]()
I didn't quite understand this formula at first. However, combined with the specific task of text translation, it is easy to understand. The meaning here is that an element at a certain position of a token corresponds to the input and output. That is, the key-value is the element itself. We need to learn the function that builds the prediction of the value by learning the weights of each word and all the words in the token.
When dealing with tokens, sequential operations are abandoned due to the need for parallel computation of self-attention. In order to use sequence information, positional encodings can be added to the input representation to inject absolute or relative positional information. By adding a position embedding matrix of the same shape to the input matrix to achieve absolute position encoding , the elements corresponding to the rows and columns are expressed as:
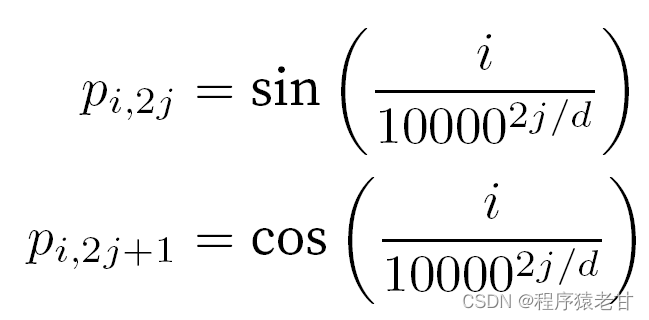
This trigonometry-based representation of positional embedding of matrix elements is not intuitive. We only know that there is a relationship between the encoded dimension and the frequency of the curves driven by the trigonometric functions. That is, the information of different dimensions inside each lexical unit has different frequencies of corresponding trigonometric function curves, as shown in the figure:
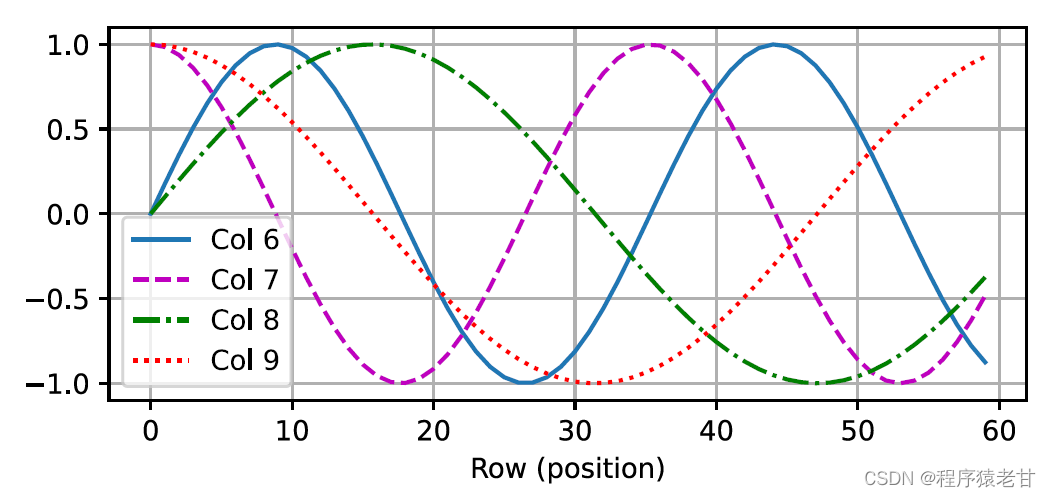
It seems that as the dimensionality of each lemma increases, the frequency corresponding to its interval decreases. In order to clarify the relationship between this frequency change and absolute position, an example is used here to explain. This prints out the binary representation of 0-7 (the frequency heatmap is on the right):

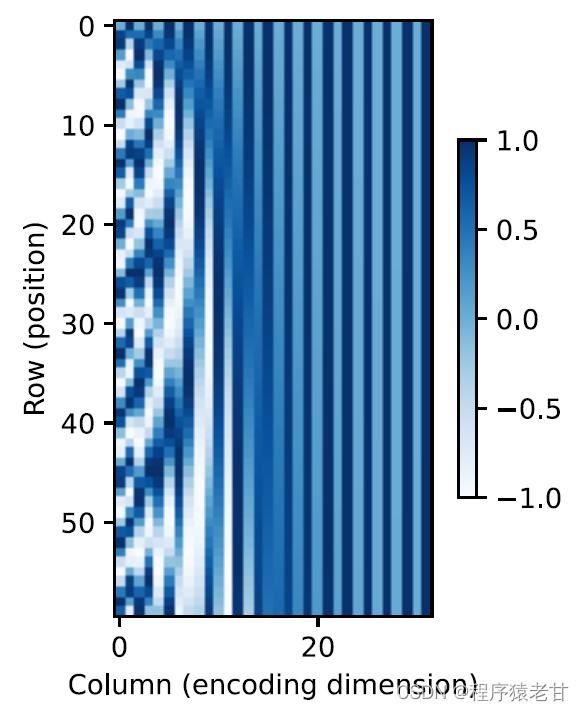
Here the higher bits are alternated less frequently than the lower bits. Through the use of positional encoding, the encoding of different dimensions of etymology based on frequency transformation is realized, and then the addition of positional information is realized. The relative position coding will not be described in detail here.
4. Transformer model
It's finally time to get excited! After we understand the above knowledge, we have laid the foundation for learning Transformer. Compared with the previous self-attention model that still relies on the cyclic neural network to realize the input representation, the Transformer model is completely based on the self-attention mechanism without any convolutional layer or cyclic neural network layer.
The Transformer model is a codec architecture, and the overall architecture diagram is as follows:
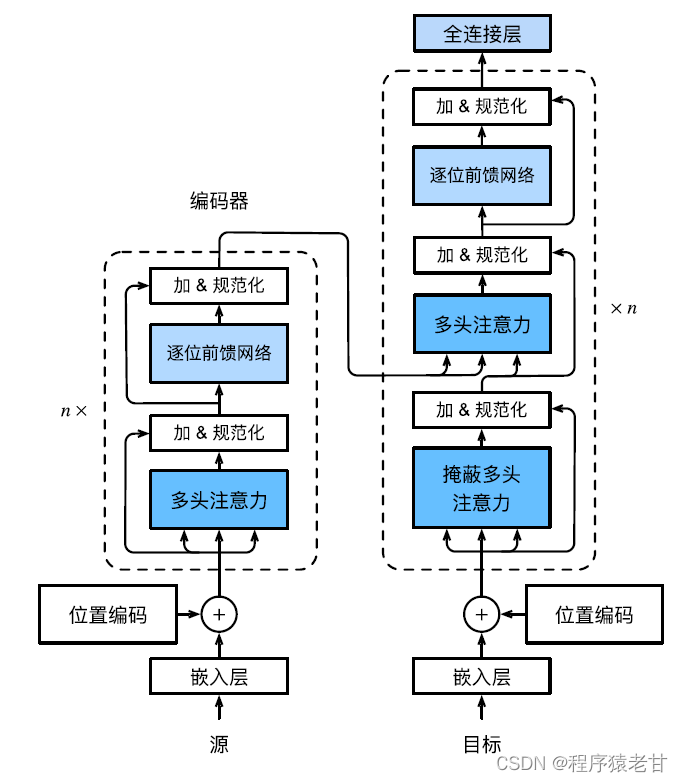
The Transformer is composed of an encoder and a decoder. It is built on the basis of a self-attention module. The source (input) sequence and target (output) sequence embedding representation will be added with positional encoding, and then input to the encoder and decoder respectively. The encoder is built by stacking multiple identical layers, each with two sublayers. The first sublayer is multi-head self-attention pooling, and the second sublayer is a position-based feedforward network. The queries, keys, and values computed by the encoder layer come from the output of the previous layer. Each sublayer uses residual connections. Similar to the encoder , the decoder is also composed of multiple identical layers, and uses residual connections and layer normalization. In addition to the two sublayers described in the encoder, the decoder adds an intermediate sublayer called the encoder-decoder attention layer. The queries in this layer come from the output of the previous decoder layer, while the keys and values come from the output of the entire encoder. In decoder self-attention, queries, keys and values are all derived from the output of the previous decoder layer. Each position in the decoder can only consider all previous positions. This masked attention preserves the autoregressive properties, ensuring that predictions only depend on output tokens that have been generated. The specific implementation of different modules will not be described in detail.
Note: The above term explanation, principle introduction and formula about the attention mechanism mainly refer to the textbook of Teacher Li Mu [2].
Based on the above-mentioned attention mechanism principle, an attention mechanism deep learning model for point cloud processing tasks is proposed. We will introduce related work in detail in the next blog, welcome to continue to pay attention to my blog.
Reference
[1] MH. Guo, TX, Xu, JJ. Liu, et al. Attention mechanisms in computer vision: A survey[J]. Computational Visual Media, 2022, 8(3): 331-368.
[2] A. Zhang, ZC. Lipton, M. Li, and AJ. Smola. Dive into Deep Learning [B]. https://zh-v2.d2l.ai/d2l-zh- pytorch.pdf .
[3] EA. Nadaraya. On estimating regression[J]. Theory of Probability & Its Applications, 1964, 9(1): 141-142.
[4] GS. Watson. Smooth regression analysis. Sankhyā: The Indian Journal of Statistics, Series A, pp. 359‒372.
[5] A. Vaswani, N. Shazeer, N. Parmar, et al. Attention is all you need. Advances in neural information processing systems, 2017,5998‒6008.