1. Logical storage structure:


Table space (ibd file): A Mysql instance can correspond to multiple table spaces for storing records, indexes and other data.
Segment: divided into data segment, index segment, rollback segment,
InnoDB is an index organization table, the data segment is the leaf node of the B+ tree, the index segment is the non-leaf node of the B+ tree, and the segment is used to manage multiple (Extent) areas
Area: The unit structure in the table space. The size of each area is 1M. By default, the InnoDB storage engine page size is 16K, that is, there are 64 consecutive pages in one area.
Page: It is the smallest unit of InnoDB storage engine disk management. Each page size is 16KB. In order to ensure the continuity of the page, the InnoDB storage engine applies for 4-5 areas from the disk each time.
Row: InnoDB storage engine is stored by row
Trx_id: Every time a record is changed, the ID of the corresponding transaction will be assigned to the trx_id hidden column, which is the ID of the last operation transaction
Roll_pointer: Every time a record is modified, the old version will be written into the undo log, and then this hidden column is equivalent to a pointer, through which the information before the modification of the record can be found
2. InnoDB-architecture

2.1 Memory structure
2.1.1 BufferPool: buffer pool
The buffer pool is an area in the memory, which can cache the real data that is frequently operated on the disk. When performing additions, deletions, modifications, and queries, the data in the buffer pool will be operated first (if there is no data in the buffer at this time, it will be loaded from the disk and Cache), and then refresh to the disk at a certain frequency or rule to reduce the number of disk IOs and speed up the processing.
If there is no buffer, every addition, deletion, modification, and query operation will operate on disk space, and there will be a large number of disk IOs. In the business, disk IO is random IO, which is very time-consuming and performance-consuming, so it is necessary to reduce disk IO as much as possible.
The processing unit of the buffer pool is a page, and the bottom layer uses a linked list data structure to manage the Page. According to the state, the Page is divided into three types:
- free page: free page, not used
- clean page: used page, the data has not been modified
- Dirty page: Dirty page, used page, data has been modified, and the data is inconsistent with the data in the disk
2.2.2 Change Buffer: Change the buffer
When executing a DML statement, if the data pages are not in the Buffer Pool, the disk will not be directly operated, but the current data changes will be stored in the Change Buffer (change buffer), and when the data is read in the future , and then merge and restore the data to the Buffer Pool, and then refresh the merged data to disk.
Function: Every disk operation will cause a lot of disk IO. With ChangeBuffer, the merge process can be performed in the buffer pool, which will greatly reduce disk IO
2.2.3 Adaptive Hash Index:
Adaptive hash index is used to optimize the query of Buffer Pool (buffer pool) data. InnoDB will monitor the query of each index page on the table, and create a hash index if it finds that the hash index can improve the speed. Note: Adaptive Hash index, without manual intervention, is automatically completed by the system according to the situation.
Adaptive hash index has a flag switch to set whether to enable: adaptive_hash_index.
2.2.4 Log Buffer: log buffer
Log buffer, save the log data (redo log, undo log) to be written to the disk, the default is 16MB, the log will be periodically refreshed to the disk, if you need to update, insert or delete many rows of transactions, increase the size of the log buffer Can save disk IO
parameter:
InnoDB_log_buffer_size: buffer size,
InnoDB_flush_log_at_trx_commit: When the log is flushed to disk (this parameter has 3 values: 1, 0, 2)
1. Every time a transaction commits, it is flushed to disk
0. Logs are written and flushed to disk every second
2. After each transaction is committed, it is refreshed to disk every second
2.2 Disk structure
2.2.1 System Tablespace: The system tablespace is the storage area of [Change Buffer ] in the memory structure. Parameters: innodb_data_file_path
2.2.2 File-Per-Table Tablespace: The tablespace of each table file contains the data and indexes of a single InnoDB table and is stored in a single data file on the file system. Parameter: innodb_file_per_table (enabled by default)
2.2.3 General Tablespace: General tablespace , which needs to be created through the create TableSpace syntax, which can be specified when creating a table. (equivalent to the fact that we can manually create the tablespace ourselves, and then specify the tablespace we manually created when creating a new table)
2.2.4 Undo Tablespace: undo tablespace , the MySQL instance will automatically create two default undo tablespaces (default 16MB) during initialization to store undo log logs.
2.2.5 Temporary Tablespace: Temporary tablespace , InnoDB will use session temporary tablespace and global temporary tablespace to store temporary table data created by users, etc.
2.2.6 Doublewrite Buffer Files: Doublewrite buffer. Before the InnoDB engine flushes the data page from the Buffer Pool to the disk, it first writes the data page into the doublewrite buffer file, which is convenient for data recovery when the system is abnormal.
2.2.7 Redo Log: Redo log , which realizes the persistence of transactions, consists of redo log buffer (redo buffer) and redo log file (redo log) , the former is in memory, and the latter is in disk. When the transaction is committed, all modification information will be put into the log, which is used for data recovery when errors occur when flushing dirty pages to disk.
2.3 Background threads
Function: refresh the data in the InnoDB buffer pool to the disk file at the right time.
2.3.1 Master Thread
The core background thread is responsible for scheduling other threads, and is also responsible for asynchronously refreshing the data in the buffer pool to the disk to maintain data consistency. It also includes refreshing dirty pages, merging and inserting caches, and recycling undo pages.
2.3.2 IO Thread
In the InnoDB storage engine, AIO is widely used to process IO requests, which can greatly improve the performance of the database, and IO Thread is mainly responsible for the callback of these IO requests

2.3.3 Purge Thread
It is mainly used to recycle the undo log that has been submitted by the transaction. After the transaction is committed, the undo log may not be used, so it is used to recycle
2.3.4 Page Cleaner Thread
A thread that assists the Master Thread to flush dirty pages to disk, which can reduce the work pressure of the Master Thread and reduce blocking
3. Business principle
A transaction is a collection of operations. It is an indivisible unit of work. A transaction submits or revokes an operation request to the system as a whole. These operations either succeed or fail at the same time .
1. Atomicity A transaction must be regarded as an indivisible minimum unit. All operations in the entire transaction are either submitted successfully or all fail. For a transaction, it is impossible to perform only part of the operations
2. Consistency (Consistency) If the database is consistent before executing the transaction, then the database is still consistent after executing the transaction;
3. Isolation Transaction operations are independent and transparent without affecting each other. Transactions run independently. This is usually achieved using locks. If the result of a transaction processing affects other transactions, then other transactions will be withdrawn. 100% isolation of transactions requires sacrifice of speed.
4. Durability (Durability) Once the transaction is committed, the result is permanent. Even if a system failure occurs, it can be recovered.
Atomicity, consistency, and durability are controlled by redolog and undo log
Isolation is controlled by locks and MVCC
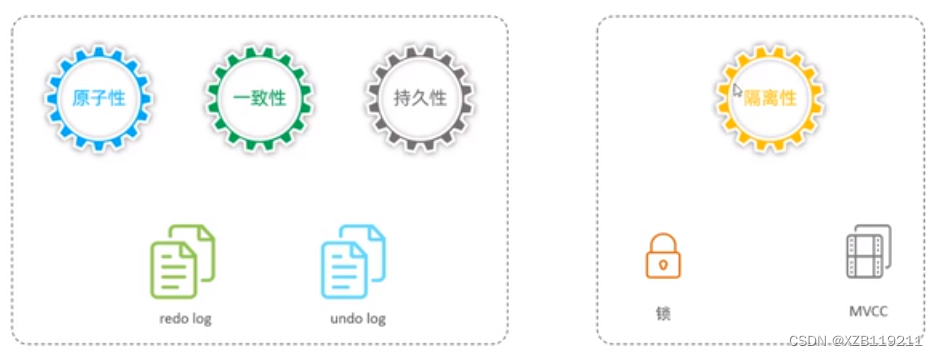
—> Persistence is guaranteed by redo log
Redo Log: redo log, which realizes the persistence of transactions. It consists of redo log (redo buffer) and redo log (redo log). The former is in memory and the latter is in disk. After the transaction is committed, all All modification information is put into the log, which is used for data recovery when an error occurs when flushing dirty pages to disk.

Explanation: The figure shows the processing mechanism in InnoDB to ensure the persistence of the transaction after a transaction is committed. First, after the transaction is committed, it will go to the corresponding data page in the Buffer Pool in the memory structure to modify the data. Wait for the operation, after the operation is completed, the transaction in the memory has been executed at this time, but has not been refreshed to the disk in time, the updated data page in the current memory is called a dirty page, and when the operation is performed in the Buffer Pool, the data page in the memory All operations will be recorded in the Redolog Buffer in the area, and then periodically refreshed to the Redo Log in the disk by the background thread, and then when an error occurs when the data in the Buffer Pool is refreshed to the disk, the data can be processed through the Redo Log in the disk recovery. When the Buffer Pool data is correctly synchronized to the disk, the redolog in the disk is useless, so the two redologs in the disk are copied to each other to achieve timely updates. This method of writing logs first and then synchronizing data is called WAL (Write-Ahead Log)
Then why bother, first write to the Redolog Buffer, and then transfer it to the Redo Log, wouldn’t it be enough to refresh the data from the Buffer Pool to the disk after each transaction? There is a problem here. Most of the operations on data pages in a transaction are random. If each transaction is immediately flushed to the disk, multiple disk IOs will be generated, which will consume a lot of performance. So we pass Redolog ensures data persistence in this way.
—> Atomicity is guaranteed by undo log
undo log: rollback log, used to record the information before the data is modified, the role includes: provide rollback and MVCC (multi-version control concurrency)
Undo log and redo log record physical logs differently. It is a logical log. It can be considered that when a record is deleted, a corresponding insert record will be recorded in the undo log, and vice versa. When a record is updated, a corresponding record will be recorded. update records, when executing rollback, you can read the corresponding content from the logical records in the undo log and roll back.
Undo log destruction: It is generated when the transaction is executed. When the transaction is committed, the undo log will not be deleted immediately. These logs may also be used for MVCC.
Undo log storage: It is managed and recorded in the form of segments, stored in the rollback rollback segment, which contains 1024 undo log segments.
4、MVCC
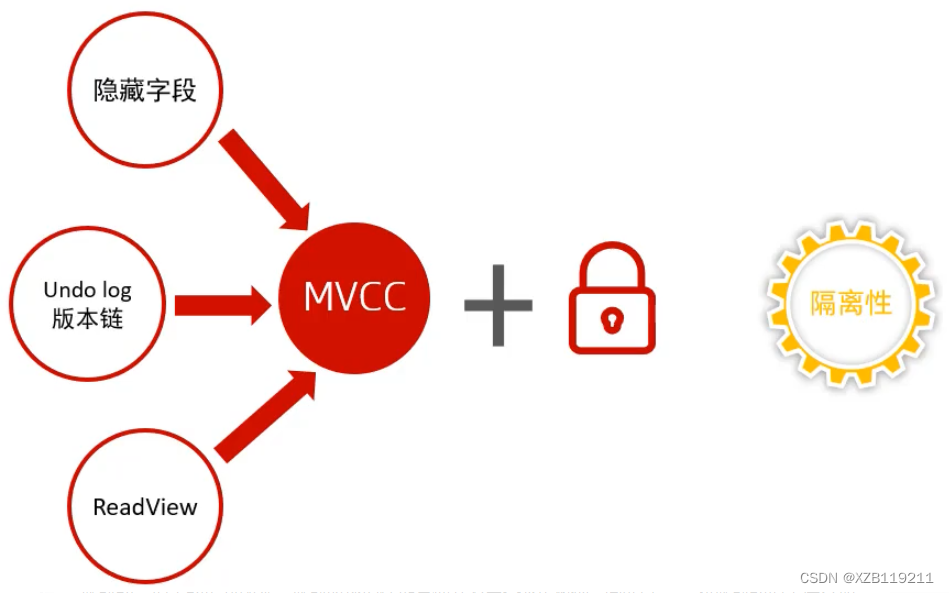
4.1 Concept
What is MVCC?
MVCC is to manage multiple versions of data when accessing the database concurrently, so as to avoid blocking the request to read data due to the need to add a write lock when writing data, resulting in the problem that data cannot be read when writing data.
In layman's terms, MVCC saves the historical version of the data and decides whether to display the data according to the version number of the compared data. It can achieve the isolation effect of the transaction without adding a read lock, and finally can read the data. Modify at the same time, when modifying data, you can read it at the same time, which greatly improves the concurrency performance of transactions.
4.2 Core Knowledge Points of InnoDB MVCC Implementation
4.2.1 Transaction version number
Before each transaction is started, a self-increasing transaction ID will be obtained from the database, and the execution sequence of transactions can be judged from the transaction ID.
4.2.2 Hidden columns of tables
| DB_TRX_ID | Record the transaction ID of the data transaction; |
| DB_ROLL_PTR | Pointer to the position pointer of the previous version data in the undo log; |
| DB_ROW_ID | Hidden ID, when creating a table without a suitable index as a clustered index, the hidden ID will be used to create a clustered index; |
4.2.3 Undo Log
Undo Log is mainly used to record the log before the data is modified. Before the table information is modified, the data will be copied to the undo log. When the transaction is rolled back, the data in the undo log can be restored.
Purpose of Undo Log
(1) Guarantee the atomicity and consistency when the transaction is rolled back. When the transaction is rolled back, the undo log data can be used for recovery.
(2) The data used for MVCC snapshot reading. In MVCC multi-version control, by reading the historical version data of the undo log, different transaction version numbers can have their own independent snapshot data versions.
4.2.4 Relationship between transaction version number, hidden column of table and undo log
We use a data modification simulation process to understand the relationship between the transaction version number, hidden columns, and undolog
(1) First prepare an original data table
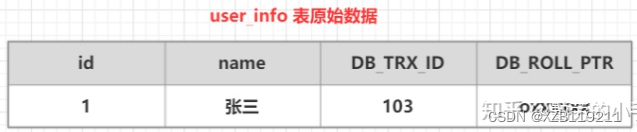
(2) Start a transaction A: execute update user_info set name = "Li Si" where id=1 on the user_info table, and the following process will be performed
| 1. First obtain a transaction number 104 |
| 2. Copy the data before modification of the user_info table to the undo log |
| 3. Modify the data of user_info table id=1 |
| 4. Change the modified data transaction version number to the current transaction version number, and point the DB_ROLL_PTR address to the undo log data address. |
(3) The result of the final execution is shown in the figure

4.2.5 undolog version chain
Modifying the same record by different transactions or the same transaction will cause the undo log of the record to generate a record version linked list. The head of the linked list is the latest old record, and the tail of the linked list is the earliest old record.

4.2.6 Read View
After each transaction is opened in InnoDB, you will get one (Read view). The copy mainly saves the ID numbers of transactions that are active (without commit) in the current database system. In fact, simply speaking, this copy saves a list of other transaction IDs in the system that should not be seen by this transaction. ( When each transaction is opened, it will be assigned an ID, which is incremented, so the latest transaction has a larger ID value )
So we know that Read View is mainly used for visibility judgment, that is, when we execute a snapshot read for a certain transaction, we create a Read View read view for the record, and compare it to a condition to judge whether the current transaction can see Which version of the data may be the latest current data, or a certain version of the data in the undo log recorded in this row.
Read View follows a visibility algorithm, mainly taking out the DB_TRX_ID (that is, the current transaction ID) in the latest record of the data to be modified, and comparing it with the IDs of other active transactions in the system (maintained by Read View), if DB_TRX_ID follows The attributes of Read View have made some comparisons, which do not conform to the visibility, then use the DB_ROLL_PTR rollback pointer to take out the DB_TRX_ID in the Undo Log and compare them again, that is, traverse the DB_TRX_ID of the linked list (from the beginning of the chain to the end of the chain, that is, from the most recent Modify and check), until you find a DB_TRX_ID that meets certain conditions, then the old record where this DB_TRX_ID is located is the latest old version that the current transaction can see
Several important properties of Read View:
| m_ids: current system active (uncommitted) transaction version number set |
| min_trx_id: Minimum active transaction ID |
| max_trx_id: Pre-allocated transaction ID, the current maximum transaction ID+1 (because the transaction ID is self-incrementing) |
| creator_trx_id: Create the transaction version number of the current read view |
Read view matching conditions:

1. Data transaction ID==creator_trx_id
If established, you can access this version, indicating that the data was changed by the current transaction
2. If the data transaction ID is <min_trx_id, it will be displayed
If the data transaction ID is less than the minimum active transaction ID in the read view, it is certain that the data already existed before the current transaction was started, so it can be displayed.
3. Data transaction ID>=max_trx_id will not be displayed
If the data transaction ID is greater than the maximum transaction ID of the current system in the read view, it means that the data is generated after the current read view is created, so the data will not be displayed.
4. If min_trx_id<=data transaction ID<max_trx_id, it matches the active transaction set trx_ids
If the transaction ID of the data is greater than the smallest active transaction ID and less than or equal to the largest transaction ID of the system, this situation indicates that the data may not have been submitted when the current transaction started.
So at this time we need to match the transaction ID of the data with the active transaction set trx_ids in the current read view:
Case 1: If the transaction ID does not exist in the trx_ids collection (it means that the transaction has been committed when the read view is generated), the data in this case can be displayed.
Case 2: If the transaction ID exists in trx_ids, it means that the data has not been submitted when the read view is generated, but if the transaction ID of the data is equal to creator_trx_id, then it means that the data is generated by the current transaction itself, and the data generated by itself can be seen by itself, so In this case the data can also be displayed.
Case 3: If the transaction ID exists in trx_ids and is not equal to creator_trx_id, it means that the data has not been submitted when the read view is generated, and it is not generated by itself, so the data cannot be displayed in this case.
5. When the condition of read view is not satisfied, the data is obtained from the undo log
When the transaction ID of the data does not meet the read view condition, the historical version of the data is obtained from the undo log, and then the transaction number of the historical version of the data is matched with the read view condition until a piece of historical data that meets the condition is found, or if it is not found, then returns an empty result;
4.3 The principle of InnoDB implementing MVCC

4.3.1 Simulate MVCC implementation process
Below we simulate the workflow of MVCC by opening two simultaneous transactions.
(1) Create a user_info table and insert an initialization data

(2) Transaction A and transaction B modify and query user_info at the same time
Transaction A: update user_info set name = "Lisi"
Transaction B: select * fom user_info where id=1
question:
Start transaction A first, and execute transaction B after transaction A modifies data but does not commit. What is the final return result.
The execution flow is as follows:

The execution flow description in the above figure:
1. Transaction A: To start a transaction, first get a transaction number 102;
2. Transaction B: Open the transaction and get the transaction number 103;
3. Transaction A: To modify the operation, first copy the original data to the undo log, then modify the data, mark the transaction number and the address of the last data version in the undo log.

4. Transaction B: At this time, transaction B obtains a read view, and the corresponding value of the read view is as follows

5. Transaction B: Execute the query statement, and the modified data of transaction A is obtained at this time

6. Transaction B: Match data with read view

It is found that the read view display conditions are not met, so the data of the historical version is obtained from undo lo and then matched with the read view, and finally the returned data is as follows.

4.4 Snapshot read and current read
Currently reading:
What is read is the latest version of the record. When reading, it must be ensured that other concurrent transactions cannot modify the current record, and the read record will be locked. For daily operations, such as: select ... lock in share mode (shared lock), select ... for update, update, insert, delete (exclusive lock) are all current read
Snapshot read:
A simple select (without lock) is a snapshot read. The snapshot read reads the visible version of the recorded data, which may be historical data. Unlocked is a non-blocking lock
Read Committed: Every time select, a snapshot read is generated
Repeatable Read: The first select statement after starting the transaction is where the snapshot is read
Serializable: snapshot read will degenerate into current read
There are three types of database concurrency scenarios:
read-read: no problems and no need for concurrency control
Read-write: There are thread safety issues, which may cause transaction isolation problems, and may encounter dirty reads, phantom reads, and non-repeatable reads
Write-write: There are thread safety issues, and there may be problems with lost updates, such as the first category