Multithreading is widely used in crawlers, and it is necessary for medium and large projects. Today I will complete a simple multithreaded crawler program as a beginner.
1. How to understand multithreading
When a computer completes one or more tasks, it can often have a high degree of parallelism: if it is a multi-core processor, it can naturally process multiple transactions at the same time, and if it is a single processor, it can actually process multiple tasks in time slots. At a certain point in time, it is indeed impossible to use one brain for multiple purposes, but it can save a lot of waiting time outside the processor, realize a certain sense of parallelism, or multi-threading, and then bring about an increase in efficiency. In fact, if multi-threading is not supported, then our computer seems to be able to do only one thing at the same time, how low it would be.
When a crawler meets multi-threading, parallel crawling can be realized. Originally, one worm was crawling data, but now it has become multiple worms crawling at the same time, and the efficiency is naturally much higher. Therefore, the threading library came into being.
Ps: Regarding the difference between processes and threads, simply put: the process level is higher, closer to the task level, while the thread level is relatively lower, closer to the real processing process on the processor side. Inclusion relationship: a task can contain multiple processes, and a process can contain multiple threads.
2. How to implement multi-threaded python crawler
The following is just a brief summary.
(1) Create a thread
#1.创建函数,引入线程
deffun():
pass
thread-1= threading.Thread(target=fun,args=[],name='thread-1')
#2.直接继承线程类
classmythread(threading.Thread):
def __init__(self):
Thread.__init__(self):
#加这一步后主程序中断退出后子线程也会跟着中断退出
self.daemon = True
def run(self):
#线程运行的函数
pass
thread-1= mythread()
(2) Open the thread
thread_1.start() #Start thread
thread_1.join() #Block until the thread finishes running
3. Realize functions in threads
If you use the construction function to introduce threads, you can directly complete the specific functions in the function fun()
If you use the inherited thread class, you can complete the specific functions in the run() method in the class
4. Synchronization between threads
Inter-thread synchronization is required because of contention and conflict among threads. Considering that the queue (queue) has a built-in synchronization function, it is often implemented with a queue when assigning tasks to multiple threads. Therefore, some people say that the key to implementing multi-threaded crawlers is the queue. Queue users understand multi-threading naturally.
5. Efficiency comparison
Let's do a simple efficiency comparison. Given about 100 webpage links, download the text from these webpages and save them to a local txt file. Obviously, this is a typical task that can be operated in parallel. The efficiency of completing this task is compared as follows:
线程数1:耗时45.9s
线程数2:耗时25.2s
线程数4:耗时13.5s
线程数8:耗时8.2s
It can be seen that the efficiency improvement in the case of multi-threading is still very obvious. Of course, the more threads the better.
Common modules for python crawlers
The urllib module of the python standard library
When it comes to the network, the essential mode is urllib.request. As the name suggests, this module is mainly responsible for opening URLs and HTTP protocols.
The simplest application of urllib is
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
url URL to open
data Post submitted data
timeout Set the access timeout of the website
urlopen returns object providing method
read() , readline() , readlines() , fileno() , close() : operate on HTTPResponse type data
The geturl() function returns the url information of the response, which is often used in the case of url redirection
The info() function returns the basic information of the response
The getcode() function returns the status code of the response. The most common codes are 200, the server successfully returns the webpage, 404, the requested webpage does not exist, and 503, the server is temporarily unavailable.
Write a testurllib.py to experiment, the code is as follows
#!/usr/bin/env python
# coding: utf-8
__author__ = 'www.py3study.com'
import urllib.request
import time
import platform
import os
def clear():
'''该函数用于清屏'''
print(u'内容较多,显示3秒后翻页')
time.sleep(3)
OS = platform.system()
if (OS == u'Windows'):
os.system('cls')
else:
os.system('clear')
def linkbaidu():
url = 'https://www.baidu.com'
try:
response = urllib.request.urlopen(url, timeout=3)
except urllib.request.URLError:
print(u'网络地址错误')
exit()
with open('baidu.txt','w') as fp:
fp.write(response.read().decode('utf-8'))
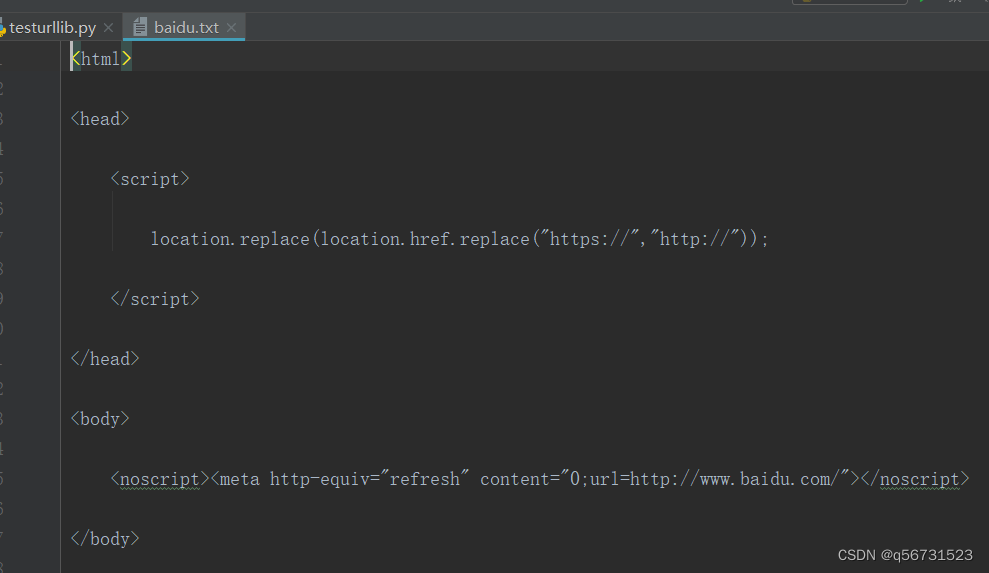
print(u'获取url信息,response,geturl() \n: {}'.format(response.geturl()))
print(u'获取返回代码,response.getcode() \n:{}'.format(response.getcode()))
print(u'获取返回信息,response.info() \n:{}'.format(response.info()))
print(u'获取的网页内容以存放当前目录baidu.txt中,请自行查看')
if __name__ == '__main__':
linkbaidu()
should see the effect

The content of baidu.txt is as follows